Как мы искали свой Vector в построении высоконагруженной системы логирования

Логов много не бывает, а если бывает?! Расскажем, как мы внедряли новую систему логирования на основе EFK (Elasticsearch-Fluetnd-Kibana), как страдали, когда FluentD перестал держать нагрузку, как мы переходили на Fluentbit (спойлер: неудачно) и почему смогли найти свой Vector. А в конце дадим пару советов о культуре логирования: как к ней относиться, чтобы не страдали вы, ваши коллеги, тестировщики и разработчики.
Этот пост — расшифровка доклада, который мы представили на конференции HighLoad++ Foundation 2022 в Москве. Видео можно найти по ссылке, а здесь — почитать доклад и посмотреть слайды из презентации.
Всем привет, меня зовут Илья. Я работаю в маркетплейсе СберМегаМаркет, отвечаю за всю инфраструктуру и эксплуатацию в компании.
СберМегаМаркет — это онлайн-платформа, объединяющая продавцов и покупателей. Она состоит из множества микросервисов, работающих в гибридной инфраструктурой. Высоконагруженной платформу делают вот эти показатели:

Graylog: как мы не замечали проблем и к чему это привело
В 2018 году, когда я только пришел в компанию, объем данных по логированию был в районе 15 ГБ в сутки, количество сообщений в секунду — примерно 400. Все находилось на одной ноде: Graylog вместе с MongoDB и Elasticsearch. И кажется, что никаких проблем вообще не существовало.
У нас было подозрение, что так будет не всегда. Компания росла, с ней рос и трафик, который при генерации влиял на количество заказов. Заказы обслуживались многими сервисами, мы регулярно выкладывали новые фичи, которые, в свою очередь, тоже крутились на новых серверах — и вместе с этим росли логи, которые оседали в общем объеме данных.
Данные росли, а схема оставалась прежней. И, конечно, проблемы нас нашли — стало не хватать ресурсов. Какое-то время мы еще масштабировались вертикально, но уперлись в границы гипервизора. Начала копиться очередь в буфере, мы толкали ее в ручном режиме, теряя логи, которые к тому же пропадали сами.
Мы поступили просто — взяли обычный Elasticsearch версии 5.0, развернули его на трех нодах и запустили на дефолтных настройках. И вроде бы все ок, но через полгода те же проблемы дружески похлопали нас по плечу.
Тогда мы еще верили в силу простых решений: добавили ноды, перешли на использование Rack ID. За манипуляцию с ними у нас отвечал Curator — простейшая утилита, менеджер индексов, работающий по заданному сценарию. Он переносил индекс с горячих на холодные ноды.
Угадайте с трех раз, что случилось еще через некоторое время? Да, наша схема опять перестала вывозить: данных стало в районе 1 ТБ в сутки, сообщений — около 20 тысяч.
И вот тогда мы решили остановиться и разобраться, что нам мешает.

Мы додумались до следующего:
У нас была старая версия graylog v. 2, в которой отсутствовала кластеризация. Можно было собрать федерацию костыльным способом, но мы этого не делали (читай: не хотели).
Мы использовали Elasticsearch v. 5, который славится своей нестабильностью, отсутствием индекс-менеджмента и еще рядом потрясающих особенностей.
Про curator, который у нас был, нельзя было сказать ничего плохого — он работал, как топорная машина по заданному сценарию. Но нам хотелось кастомизацию и больше функционала.
А еще в graylog отсутствовал модуль парсинга логов. Мы нашли в комьюнити graylog«а скрипт, добавили его, но это был, скорее, костыль, а не решение проблемы.
После изучения сравнений Logstash и FluentD мы решили попробовать последний.
FluentD: первый подход и все его косяки
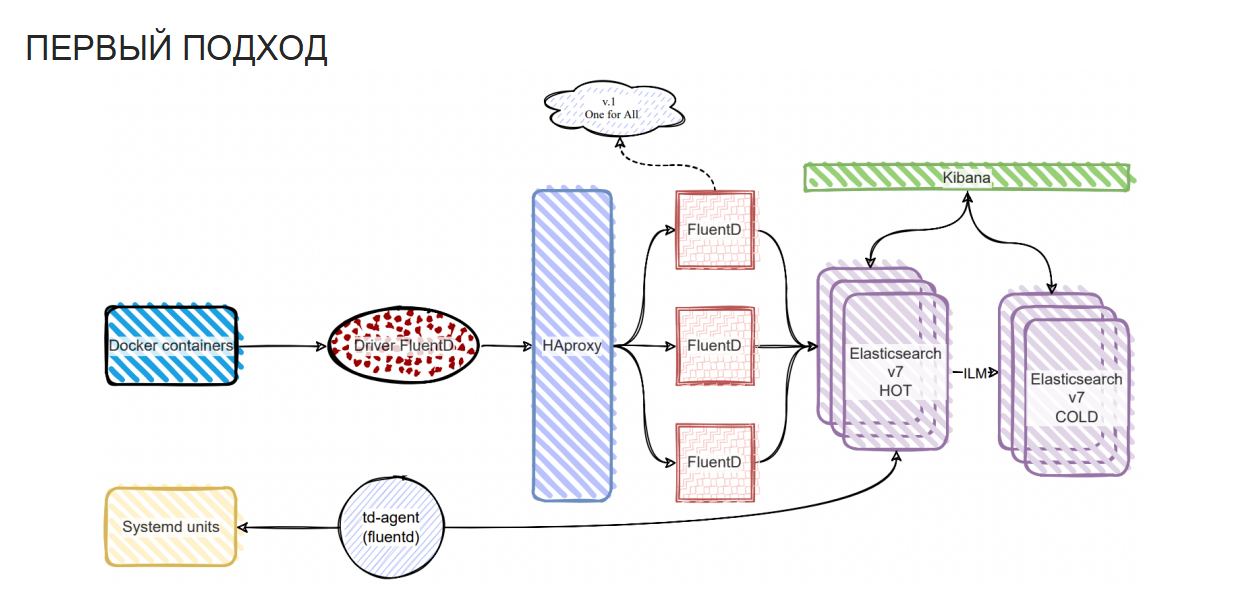
Вот что мы сделали:
собрали логи с контейнеров, используя драйвер (ранее это был GELF, а мы взяли драйвер FluentD);
Graylog мы выбросили, вместо него встали балансеры на HAProxy, бэкендом у которых является нода с FluentD;
все это мы записали в седьмой Elastic, с ILM-ом, с ролями, и «сменеджерили» за счет Kibana. Там же мы визуализировали свои объемы;
кроме того, надо было забрать логи из файлов — для этого мы использовали модуль FluentD под названием td-agent, который эти объемы хорошо переваривает.
Для Graylog у нас была виртуальная машина, на которой он крутился в единственном экземпляре. Мы сделали то же самое с контейнерами — у нас имелась одна виртуальная машина с одним контейнером, которая обслуживала логирование всех систем. И вот из этого выросли две проблемы.
Проблема первая:
Обслуживая все системы одним набором контейнеров, мы писали в один индекс, который рос и становился неуправляемым. Elastic, какой бы версии он ни был, от этого страдал.
Проблема вторая:
Когда нужно было внести изменения в конфигурацию логирования одного сервиса, приходилось перекатывать все флюенты: набор был один, а вот конфигурационный файл состоял из множества конфигов.
Решение:
Мы использовали подход номер 2.
FluentD: второй подход и чем он нас озадачил
Мы взяли один набор контейнеров с FluentD, который обслуживает один сервис, и получили множество индексов: каждый сервис пишет свой индекс, который удобно обслуживать. А когда нам нужно изменить конфигурацию, произвести какой-то апдейт или что-то выключить, мы влияем только на один сервис, который нам нужен.

Но и здесь регулярно происходило то, над чем нам пришлось поломать голову.
Иногда мы попадали под агрессивное давление потоков логов. Наш заданный буфер забивался, а сервис, который крутился в этом контейнере, испытывал шок: он мог завершиться с неочевидной ошибкой и кодом возврата ответа.
Чтобы этого не происходило, мы решили использовать режим non-blocking. В критичных ситуациях для нас было лучше подтереть немного логов, чем потерять сервис.
Еще одна головная боль — это теги. Они добавляют уникальности сообщению, маршрутизируют его, за счет тегов мы фильтровали области по нужным пространствам в Elastic и Kibana. А многие плагины FluentD просто не умеют работать с воркерами, используя по дефолту только один, например, td-agent. Но есть сервисы щедрые на поток логов, для обработки которых не хватает одного ядра. В этом случае мы использовали опцию «worker» в нужном количестве и благодаря этому удачно утилизировали ЦПУ на виртуальной машине, где крутился наш контейнер.
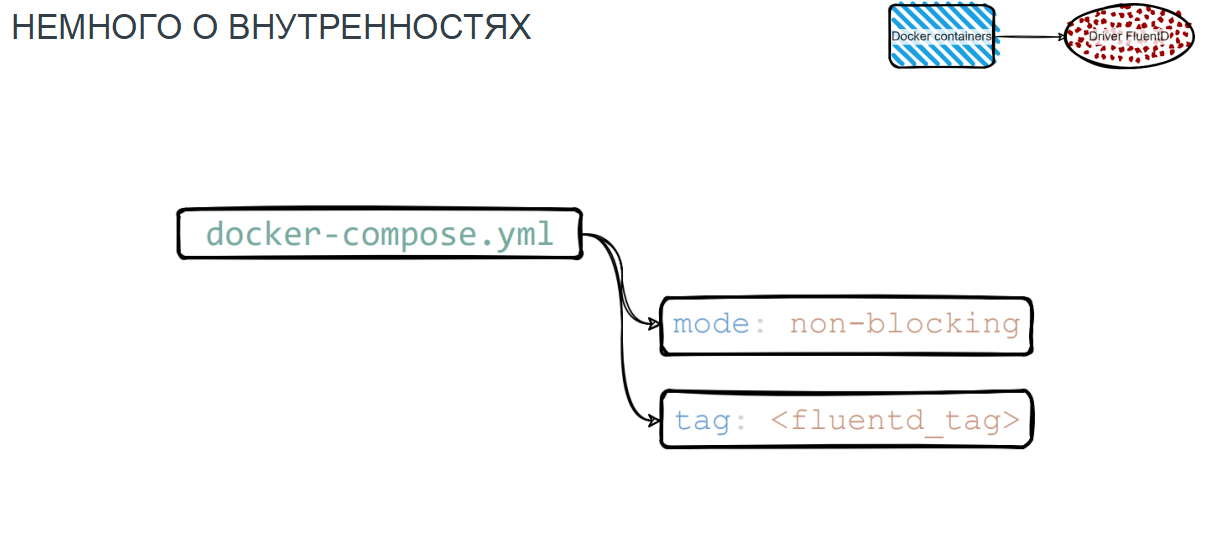
Лейбл, в отличие от тега, помогает смаршрутизировать набор конфигов, объединяясь в общий конфигурационный файл FluentD. При сборке он включает в себя конфигурации сервисов и различные вложения с настройками.
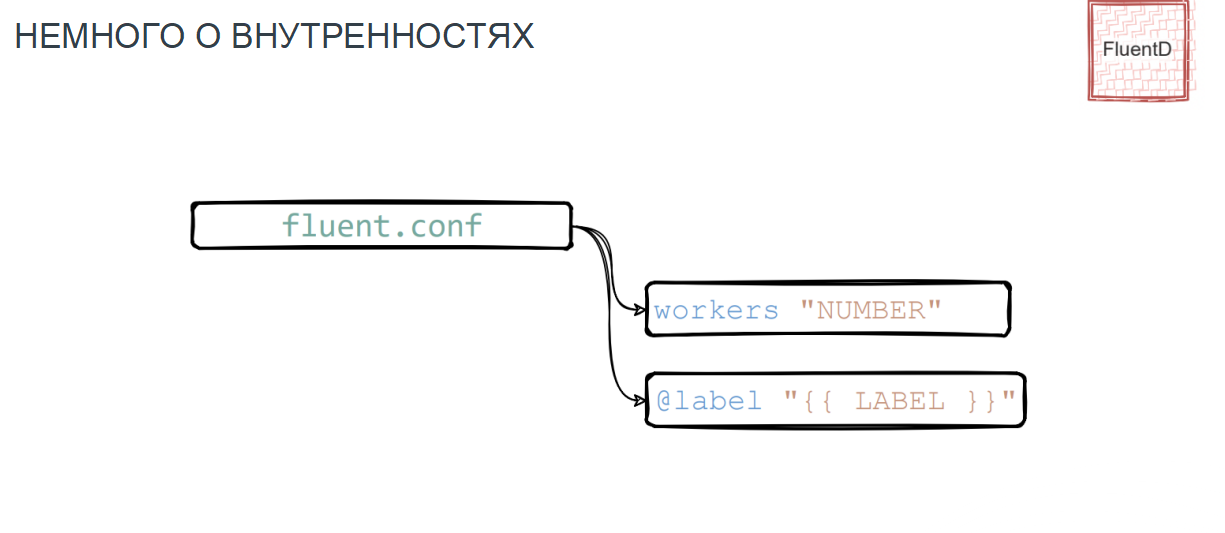
Как выглядела конфигурация сервиса:
Лейбл, который используется для идентификации сервера.
Блок «фильтр», в котором два модуля:
Модуль 1 — concat, который конкатенирует, то есть склеивает сообщения, если драйвер FluentD при отправке разорвал их.
Модуль 2 генерирует те самые id-хеши, для однозначной идентификации сообщений в будущем используя его для отправки в эластик.
Match, в который входит:
плагин Elastic«а с набором параметров, необходимых для отправки;
id_key_hash, с помощью которого мы решаем вопрос дедупликации и наши сообщения становятся уникальными;
буфер;
и pipeline.

С pipeline все получилось интересно. В первом подходе использования FluentD мы понадеялись на его встроенный парсинг JSON-логов — в Graylog его не было, а тут был. Но уже при средней нагрузке и чуть больших потоках логов он начинал сжирать огромные ресурсы. При этом его эффективность была более чем скромной.
И тогда при парсинге на стороне Elastic мы решили использовать pipeline. Мы осознавали, что тем самым перегружаем Elastic, но его процессоров хватило и переварить сообщения, если они приходили с правильной структурой JSON, и складывать их. В то время мы прописывали конкретный pipeline, который будем использовать в Elastic, а сейчас делаем еще проще: задавая дефолтную структуру шаблона индекса, мы сразу в ней указываем нужный ingest_pipeline, который будет использован для сообщения от конкретного сервиса.
Как мы готовили структуру Elasticsearch
Структуру Elastic мы готовили просто:
создавали шаблон индекса;
назначали ему нужную политику ILM (index lifecycle management);
указывали корректный ingest_pipeline, который будет раскладывать нашу структуру по нужным полям;
создавали пространство в Kibana;
формировали первый индекс с отчетным номером, который будет нам нужен для ротации.

Изменения мы выкатывали с помощью триггеров GitLab, которые запускают джобы по изменению в конфигурационных файлах сервиса. Настройки логирования находились у нас рядом с сервисом репозитория. Сам pipeline состоял из таких шагов:
Формируем конфигурационный шаблонный файлик для HAProxy, который включает в себя связку front — принимаемая сторона и back — у нас это контейнеры FluentD.
Создаем структуру конфигурационного файла FluentD, в котором есть инклюды сервисов конфигурации и дополнительные опции настроек логирования.
Задаем структуру будущего шаблона в индексе и спейс, используя API Kibana и Elastic.
Все это убираем в докерный образ, который понадобится для деплоя в нужное окружение.
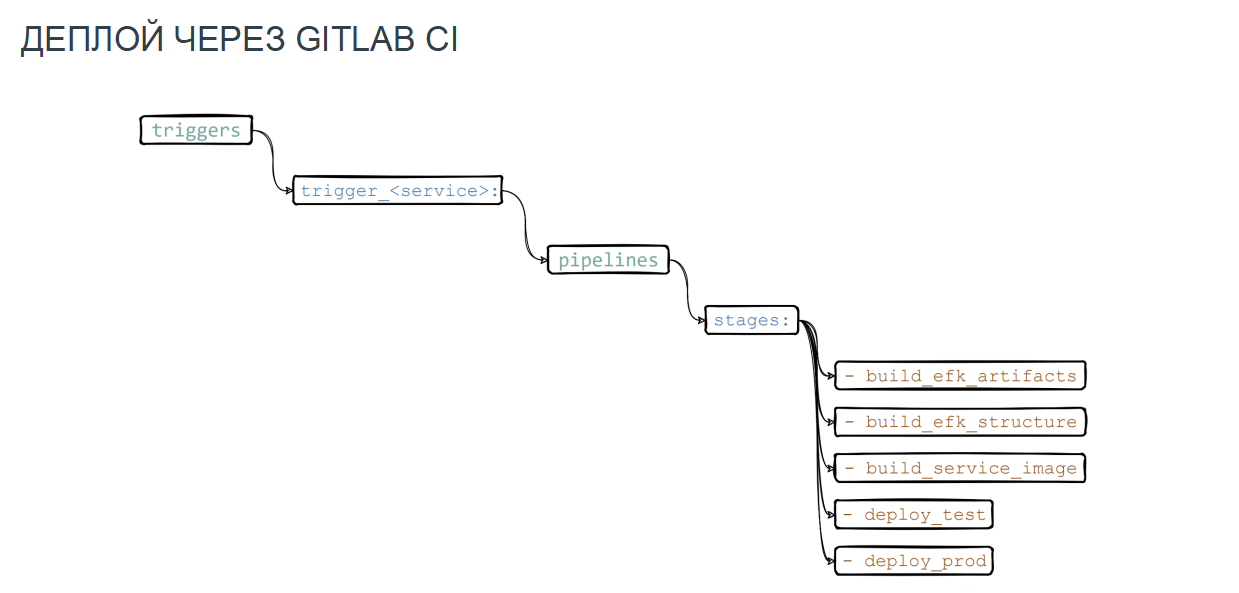
Вот что у нас получилось в итоге:
Простое масштабирование: можно создавать сколько угодно контейнеров и виртуальных машин.
Все преимущества Elastic v7.
Хороший функционал управления индексами, IML.
Ложка дегтя в бочке меда FluentD — парсинг json-логов лучше не использовать.
Так прошел год. Казалось, что все хорошо, но с ростом объема данных нас опять догнали проблемы.

Первая из них — тот самый встроенный модуль парсинга JSON-логов. Вторая — это непрозрачность FluentD-буфера, который при хорошем интенсивном потоке логов мог экспоненциально взлетать вверх. Буфер съедал всю оперативную память, что у него была указана в лимитах, и тем самым замедлял работу всего логера. Отчего это происходило, было непонятно. Из-за этого возникали ретраи при попытке отправить сообщения, которые закольцовывались, давление на буфер усиливалось, и режим non-blocking не справлялся.
У нас просили хорошую систему логирования, а мы постоянно теряли логи. Надо было опять что-то делать.
FluentBit: попытка номер три
FluentBit был тогда актуален, и мы решили посмотреть на него повнимательнее. Он практически не отличался от FluentD, и мы быстро перешли на него. Результаты приятно удивили.

При одних и тех же потоках логов, для одних и тех же сервисов FluentD потреблял от 200 Мб до 4 Гб памяти. FluentBit, обслуживая логи этих же сервисов, потреблял 5Мб и 35 Мб соответственно.
Мы были счастливы — казалось, это то, что всем нам было нужно.

Но проблемы FluentD никуда не исчезли. Время шло, а мы продолжали бороться с буфером и терять логи. Не все ладно было и c FluentBit. Борьбы с буфером там не было, и логи пролетали быстро. Но вот куда они улетали, для нас оставалось загадкой.
Итог — потеря логов.

В то время одна из самых критичных систем процессинга заказов, которую мы использовали, была написана на 1С. В ней логи нужны были не только для аналитики и дебага, но и для решения рабочих задач. Но обслуживание базы на железе, где хранились логи, обходилось слишком дорого. И нужно было срочно изобрести какое-то решение.
Мы решили отказаться от td-агента и предложили разработчикам написать свой прокси, который будет забирать логи у 1С. Самописная прокси на Go от наших разрабов в реалтайме снифила каталог с логами, сканировала его и закидывала в HAproxy, который уже своей балансировкой отправлял в нужный FluentD. И вроде бы все работало.
Но мы решили еще раз потестить FluentBit: провели тестирование, отправляя балками в секунду 1 000, 10 000 и 100 000 сообщений, и … получили экспоненциальный рост потерянных логов.

Внедрение Vector
И тут мы обратили внимание на это творение Datadog на Rust. Это был новоиспеченный вектор, который находился еще в бета-версии и его практически никто не использовал. Он очень быстрый, эффективно использует память, а еще одинаково хорошо работает с метриками, и с логами.
Мы провели тесты контейнеров FluentD, FluentBit и Vector на мощном железе — все в равных условиях. С помощью утилиты Locust задали стандартные параметры и гоняли все в рамках одного контейнера 10 минут.
И вот что мы увидели:

Первый график — это Kibana, он показывает число сообщений, которое полетело за 10 минут через один контейнер.
У Vector оно больше, чем у FluentD, в 2,5 раза.Следующие графики — общий RPS. По результатам Vector почти в 3 раза выше FluentD.
Ответы контейнеров ниже: FluentD — в районе 220 мс, а Vector — 65 мс, в режиме стресс-теста.
FluentBit вообще не пробежал этот 10-минутный марафон. Сколько бы мы его не пинали, не реанимировали, но как только мы запускали тест, он падал.
Так мы внедрили Vector. Он отлично справляется с текущими объемами данных порядка 7 терабайт в сутки и количеством сообщений около 240 000 в секунду.
Можно сказать, что в общей схеме ничего особо не изменилось. Просто вместо драйвера FluentD используем драйвер syslog, а вместо нод с контейнерами FluentBit и FluentD — контейнеры с вектором. Файлы с хостов собираем тоже с помощью Vector.
Не нарадуемся — все собирается, парсится и улетает. Мы подружили 1С и Vector. Он залетает на ура, и логи мы не теряем. У нас даже появилась возможность «открыть кран на полную». Открывая его, мы были с одной стороны приятно удивлены, что система выдерживает, но с другой стороны, нас это немного озадачило. Объемы логов буквально за несколько дней-неделю достигли 100 ТБ. В сутки это вроде бы немного, но был один сервис, который в сутки слал 1 ТБ логов.
Мы попросили разработчиков придумать, как сохранить то, что нам нужно. И разработка нас услышала — они добавили в самописный прокси механизм, который помещает определенные сообщения в поле «значения» с нужным приоритетом. На это поле мы делаем свой ingest pipeline, добавляем условие парсинга. Сообщения, которые нужно хранить долго, попадают в один индекс, в другой попадают сообщения, которые удаляются через 1–2 дня. Так у нас появилась возможность ротировать информацию из множества индексов, и назначить ту политику, которая решит нашу задачу.
Благодаря своей простоте Vector прекрасно интегрируется в Кубер. Можно использовать его как DaemonSet, sidecar-контейнер или просто как агрегатор. Мы остановились на решении с DaemonSet.
Это позволило нам получить:
простую настройку;
удобство обновления;
масштабируемость;
готовность к большим нагрузкам;
эффективное использование ресурсов.
Культура логирования: договаривайтесь с разработкой и стройте простые системы
Система может быть прекрасной — высоконагруженной, отказоустойчивой, но с непонятным потоком логов, состоящим из невразумительного: текста, ошибок, метаданных и так далее. У разработки иногда нет времени на логирование — им интереснее внедрять фичи, чем следить за логами. Это ошибочный путь.

В нашем понимании идеальный подход к логированию выглядит так:
Если мы хотим парсить JSON, то все без исключения сообщения должны быть в формате JSON.
Мы точно знаем состав нашего JSON«a, под который мы настраиваем маппинг — все поля и все типы полей.
Мы выносим этот состав в качестве маппинга в шаблон индекса, который со временем никак не меняется — мы не добавляем в него новые поля просто потому, что этого кому-то очень захотелось. Мы сохраняем четкую статичную структуру.
Если с разработкой договориться не получается, возможен альтернативный вариант: заниматься более сложным парсингом и писать сложные pipeline. А для слаженной работы нужно будет хорошо понимать, где JSON, а где все остальное. Если вы все парсите JSON«ом — прекрасно. Если нет, создавайте новое поле message_text, копируйте в него данные из поля log для сообщений формата text — и пусть считают логи, как хотят, если не хотят следовать правилам.
А еще мы иногда записываем в отдельный индекс метаинформацию об ошибке, которую потом анализируем, почему, от кого и как она пришла — то есть действуем точечно.
Одним словом, используйте неизменную систему логов, статичный маппинг полей и статичный шаблон индекса. И тогда ваша «печка» будет радоваться — можно лить в нее сколько угодно всяких сложных решений и приблуд, она все переживет и со всем справится.

Если подытожить совсем кратко, то:
Чем лучше и ближе вы общаетесь с разработкой, тем интереснее и качественнее результат.
Стройте простые системы. Чем система проще, тем выносливее и стабильнее. Чем она сложнее, тем сложнее получать кайф от работы :)
Disclaimer: Мы — не фанатичные последователи Vector, а всего лишь рассказали, как живем с этой системой. Она стабильна и выдерживает высокие нагрузки. Но если на рынке появится более интересное решение, которое будет эффективнее решать наши задачи — мы переметнемся на его сторону.
