Как мы искали признаки врачебных ошибок
В 2006 году в голове моего тестя разорвалась аневризма и его свалил инсульт. К вечеру того дня он уже шутил и порывался ходить по больничной палате. Повторный инсульт, который случился под наблюдением врачей, его мозг не выдержал — тесть перестал разговаривать, ходить и узнавать родных. В другом госпитале его поставили на ноги, но из-за врачебной ошибки при первоначальном лечении он навсегда лишился речи, а его личность изменилась до неузнаваемости.
То, что с ним произошло, называется внутрибольничным инсультом и это один из маркеров (или иначе — триггеров) системных проблем в медицинской организации. Их нужно анализировать, чтобы снизить число предотвратимых врачебных ошибок в стационарах и повысить качество лечения пациентов.
В США этим вопросом озадачились в начале 2000-х. Массачусетский Institute for Healthcare Improvement (IHI) разработал методику IHI Global Trigger Tool for Measuring Adverse Events, которую затем внедрили передовые клиники США и Европы.
В 2016 году мы (российский офис SAS) попытались создать систему анализа медицинских триггеров по методике IHI в России. Расскажу, что из этого вышло.
С чего начали
Первым делом мы стали искать врачей-единомышленников, разделяющих идею анализа качества медицинского обслуживания. Пригласили на SAS Forum Russia 2016 руководителей нескольких московских стационаров, коллег из нашего европейского офиса и представителей датской больницы Lillebaelt, создавшей на базе аналитической платформы SAS систему выявления триггеров по методике IHI в 2015 году.
Рассказ датчан заинтересовал главврача крупного московского многопрофильного стационара, и мы договорились о проведении эксперимента по анализу медицинских записей. По условиям NDA мы не можем разглашать детали проекта, поэтому стационар далее буду называть просто Клиникой, а его руководителя — Главврачом.
В июне — июле 2016-го мы обсудили с руководством Клиники содержание и рамки проекта, в августе оформили техническое задание и с сентября приступили к работе. Костяк команды со стороны SAS состоял из Александра Жукова (al_undefined) и Дмитрия Каютенко.
Методика IHI содержит 51 триггер. Для проекта вместе с руководством Клиники мы отобрали следующие:
- Лейкоциты крови < 3 000 x 10^6 / мкл (кроме пациентов на химиотерапии)
- Тромбоциты крови < 50 000 × 10^6 / мкл (кроме пациентов на химиотерапии)
- Внутрибольничный инсульт
- Внутрибольничный инфаркт
- Повторные незапланированные переводы в отделение реанимации и интенсивной терапии (ОРИТ) в течение 24 часов
- Реанимационные мероприятия в течение 24 часов после операции
- Реанимационные мероприятия в коечных отделениях
Как это часто бывает в аналитике, львиную долю времени заняла подготовка исходных данных и выделение в них значимой информации.
Как извлекали записи
Данные медицинской информационной системы (МИС) Клиники были размещены в оракловой базе с запутанной структурой. Описания схем найти не удалось, поэтому пришлось восстанавливать структуру данных и связи сущностей, сопоставляя сведения из БД с информацией из графического интерфейса МИС.
Для проекта нам понадобились следующие виды медицинских записей:
- Данные осмотра врача приемного отделения
- Таблица диагнозов
- Дневниковые записи
- Протоколы операций и предоперационные концепции
- Назначения и сведения об исполнении назначений
- Этапные и выписные эпикризы
- Переводные эпикризы
- Посмертные эпикризы
Эти данные (кроме таблицы диагнозов), лежали в XML в CLOB-ах. Описания структуры XML в Клинике не было, поэтому их содержание пришлось устанавливать опытным путём в ходе долгих дискуссий.
Внутри XML-документов был бардак. Например, в узле «Общее состояние» могла находиться информация о жалобах пациента, а сам узел «Жалобы» оставался пустым. Часто врачи записывали все данные о пациенте (жалобы, результаты осмотра, рекомендации к дальнейшему лечению и назначения лекарств и др.) в одно поле, например, в «Комментарий».
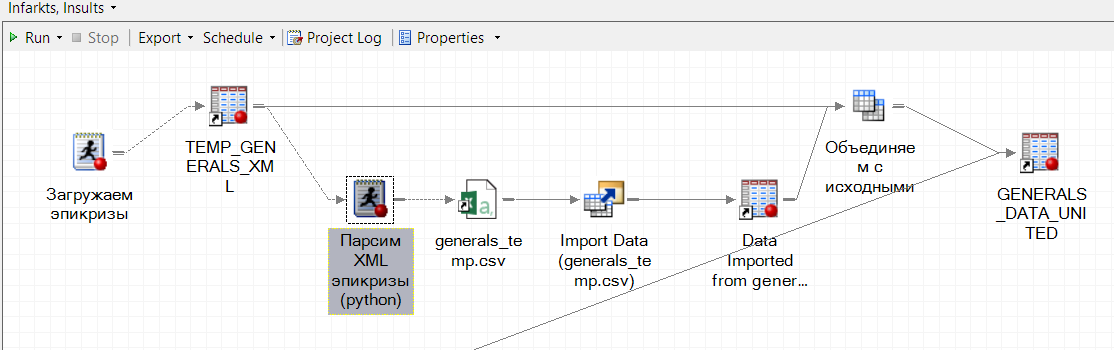
Развёртку XML в плоские таблицы делали штатным SAS XML Mapper. Наиболее сложные документы, у которых нужные сведения находились на разных уровнях вложенности, разбирали самописным парсером на Python. Он запускался из SAS и был интегрирован в единый исполняемый процесс SAS Enterprise Guide:
Чтобы не вытаскивать результаты лабораторных исследований из текста эпикризов (то ещё удовольствие, учитывая привычку некоторых врачей документировать на скорую руку), мы взяли данные по ним из лабораторной информационной системы (ЛИС). Они тоже были завёрнуты в XML, но простого вида — «анализ», «показатель», «значение».
Как исследовали данные
Когда мы привели медицинские записи в понятный и пригодный для обработки вид, оказалось, что формализованными были только 2 триггера из 7 — содержание «лейкоцитов» и «тромбоцитов». Они выражались числами, которые можно было сравнивать с пороговым значением.
Нам пришлось отказаться от анализа такого триггера, как «Повторные незапланированные переводы в ОРИТ в течение 24 часов». Этот маркер опирается на отметки даты-времени, а их вносили в МИС Клиники как бог на душу положит — могли промахнуться на пару дней или даже поставить дату из будущего.
Внутрибольничные инсульты, инфаркты и реанимационные мероприятия никак не кодировались и не фиксировались в таблице в привязке к ID пациента. Их следовало искать в эпикризах и дневниковых записях. Поэтому оставшиеся 4 триггера были неформализованными, то есть требовали разбора неструктурированного текста.
Для этого мы применили инструмент обработки естественного языка (natural language processing) — SAS Contextual Analysis. Это web-based решение с визуальным интерфейсом, позволяющее создавать модели обработки текста даже при отсутствии навыков программирования и познаний в лингвистике (впрочем, без знания предметной области и языка, на котором написан текст, все равно не обойтись).
Сейчас подобные вопросы стало модно решать с помощью нейронных сетей. Но мы сознательно от них ушли и применили механизм лингвистических правил, потому что:
- хороший результат у нейросетей возможен только на качественной, предварительно размеченной врачами выборке из десятков тысяч записей, а её у нас не было от слова совсем
- нейронная сеть не даёт внятного объяснения своему решению (его нельзя интерпретировать), а врачи не могут работать с чёрным ящиком — они должны понимать, какие именно симптомы, показатели или действия указывают на неблагоприятные события
Как обучали систему
Хотя мы занимались всеми триггерами из перечня, основные усилия были сосредоточены на выявлении внутрибольничных инсультов и инфарктов (и то, и другое для краткости будем именовать ВБИ). Это одни из самых опасных триггеров, которые, помимо ущерба здоровью пациентов, ужасны тем, что не афишируются медперсоналом. А если менеджмент не знает о проблеме, он не может с ней справиться.
С ВБИ всё было непросто. Не существовало какого-то стандарта или регламента, который обязывал документировать факты инсультов или инфарктов в единообразной форме: одни врачи описывали инсульт как «острое нарушение мозгового кровообращения», другие — как (о, да!) «инсульт», третьи — как «ОНМК». Иногда ВБИ было видно только по назначенному лечению.
В принципе, мы могли:
- Опросить всех врачей, как они описывают инсульты и инфаркты. Однако был риск что-то упустить — никто не держит в голове перечень сделанных когда-то записей и справочник сокращений. И говорить на эту тему было немного желающих.
- Вместе с врачами руками перебрать все эпикризы и проанализировать, есть ли в них признаки ВБИ или нет. Но такого количества времени не было ни у нас, ни у них.
Мы поступили иначе: загрузили коллекцию текстов в Contextual Analysis и построили тематические модели, которые для каждой записи выделяли ключевые идеи. Не залезая в текст документа (например, эпикриза), можно было отобрать только записи с темой «инсульт» или «НМК» и отдельно исследовать их на предмет того, как ВБИ описан в тексте: какие слова используются, на каком расстоянии друг от друга они находятся и т. д. Плюс модели сами предлагали возможные формулировки для описания ключевых идей.
После тематической разметки документов мы общались с врачами, уточняли и разрабатывали лингвистические правила для выявления событий, указывающих на триггеры. Правила учитывали грамматические формы слов, расстояние между ними, порядок их следования, положение (в одном предложении, абзаце, начале/конце текста) и т.д.
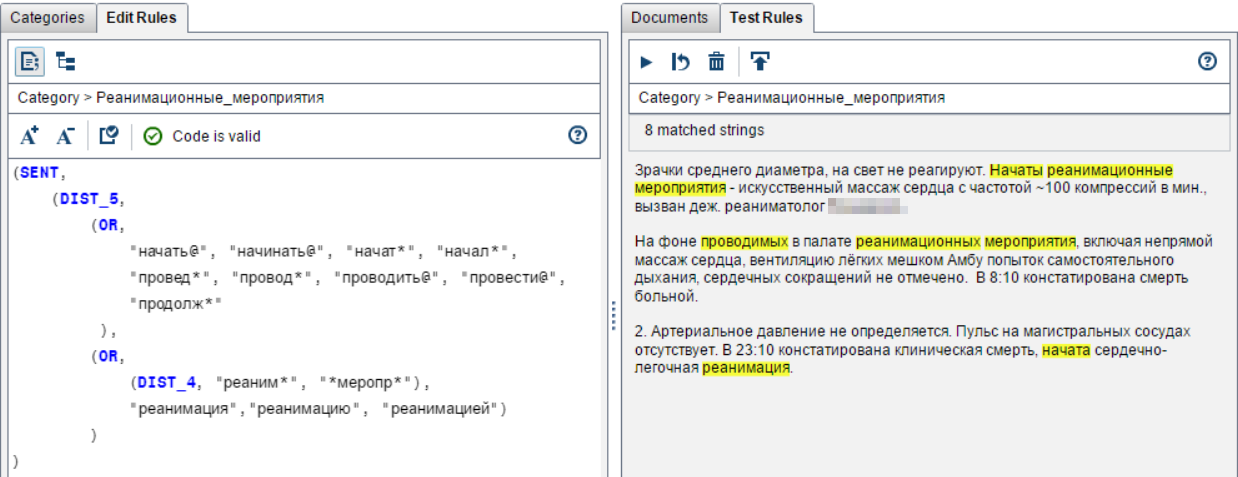
Так мы искали реанимационные мероприятия:
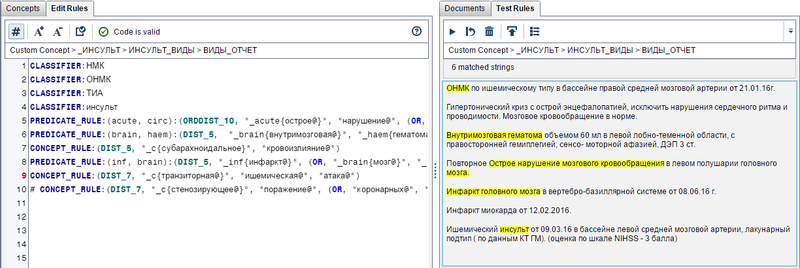
А так — инсульты:
При анализе текста всегда нужно оценивать расстояние между ключевыми словами и их порядок, чтобы не захватить лишнего. Вот пример, когда все нужные слова («острое», «нарушение», «мозговое», «кровообращение») во фразе есть, а внутрибольничного инсульта — нет:

Очень важно было отделить описание факта внутрибольничного инсульта от описания последствий ранее перенесенного инсульта, в котором употреблялись те же ключевые слова:
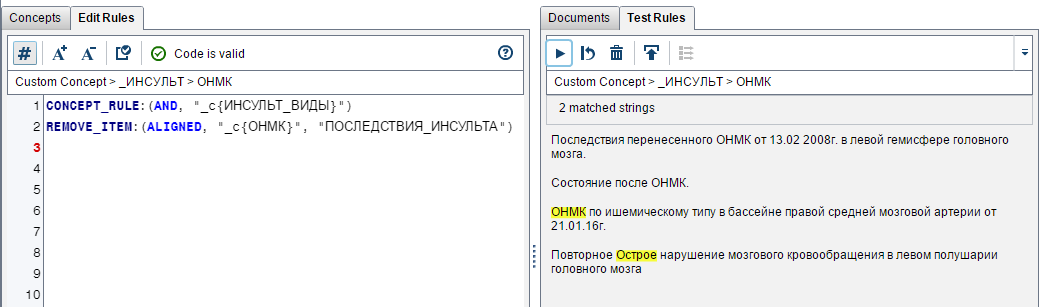
Исключаемое правило «Последствия инсульта» (выше в Remove_item):

Вместе с врачами мы разработали порядка 30 лингвистических правил, которые определяли, есть ли признаки триггеров в эпикризах. Они выгружались из Contextual Analysis в виде скорингового кода, который подключался в исполняемый процесс оценки записей в SAS Enterprise Guide.
Однако для внутрибольничных инсультов и инфарктов процесс принятия решения о наличии триггера на этом не заканчивался. Нам следовало убрать из числа кандидатов на триггер те случаи, которые можно было спрогнозировать при поступлении пациента. Для этого мы сопоставляли результаты отработки правил с таблицей диагнозов.
Напомню, триггер — событие (ухудшающее состояние пациента), неожиданное с точки зрения диагноза при поступлении. Это сигнал о врачебной ошибке или проблеме стационара, требующей принятия системных мер для исключения осложнений в будущем, а не просто любое ухудшение здоровья больного.
Допустим, Contextual Analysis присвоил метку «внутрибольничный инфаркт» какой-то записи. Проверяем диагноз: если пациент поступил с ишемической болезнью сердца, то риск инфаркта миокарда и так был высоким. Событие это хоть и не благоприятное, но, увы, ожидаемое. Признак триггер записи не присваиваем.
Если же пациент поступил с аппендицитом и у него в ходе лечения случился инсульт, то это могла быть врачебная ошибка. Например, не уследили за давлением или спровоцировали его скачок какими-то препаратами или действиями. Записи присваиваем признак «триггер».
В итоге получился такой бизнес-процесс:
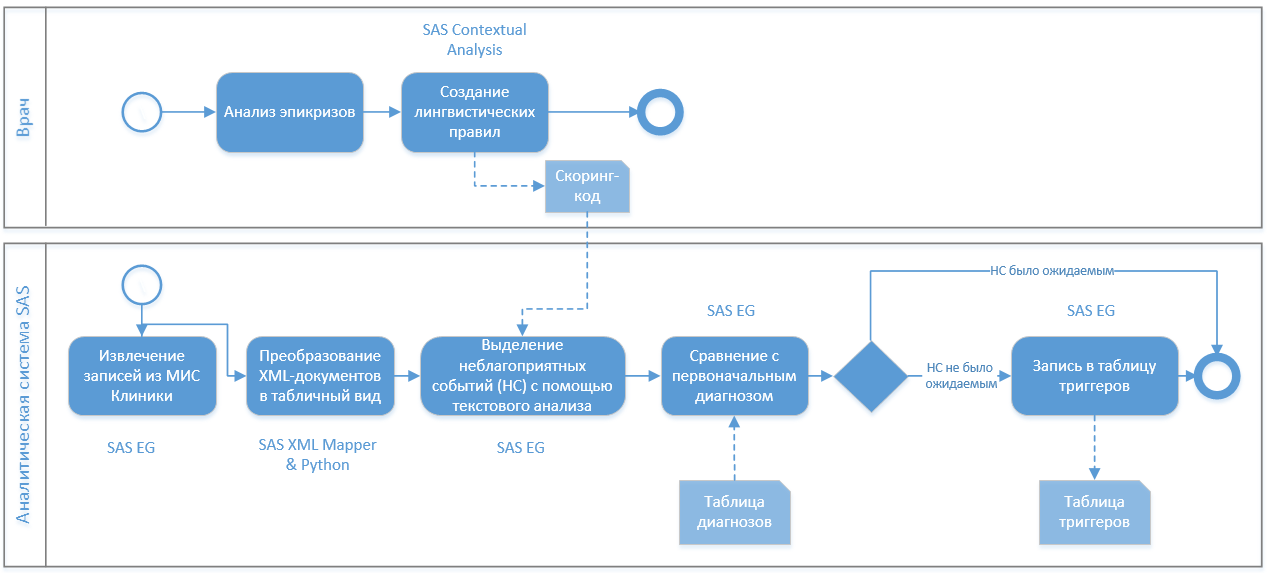
Он был удобен для врачей — они могли самостоятельно дополнять лингвистические правила разбора эпикризов, которые затем выгружались в скоринговый код и подхватывались аналитической системой.
Как визуализировали данные
На последнем этапе мы настроили отчёт в SAS Visual Analytics — это наш web-based продукт для задач визуализации и BI. Он обновлялся каждые 5 минут и показывал статистику возникновения триггеров в разрезе отделений, врачей и пациентов. Ответственный врач (например, заведующий отделением кардиологии) заходил в отчёт и смотрел, какие триггеры выявлены за последний час, день, неделю. Мог «провалиться» в отделение, посмотреть динамику триггера за период и т. п.:
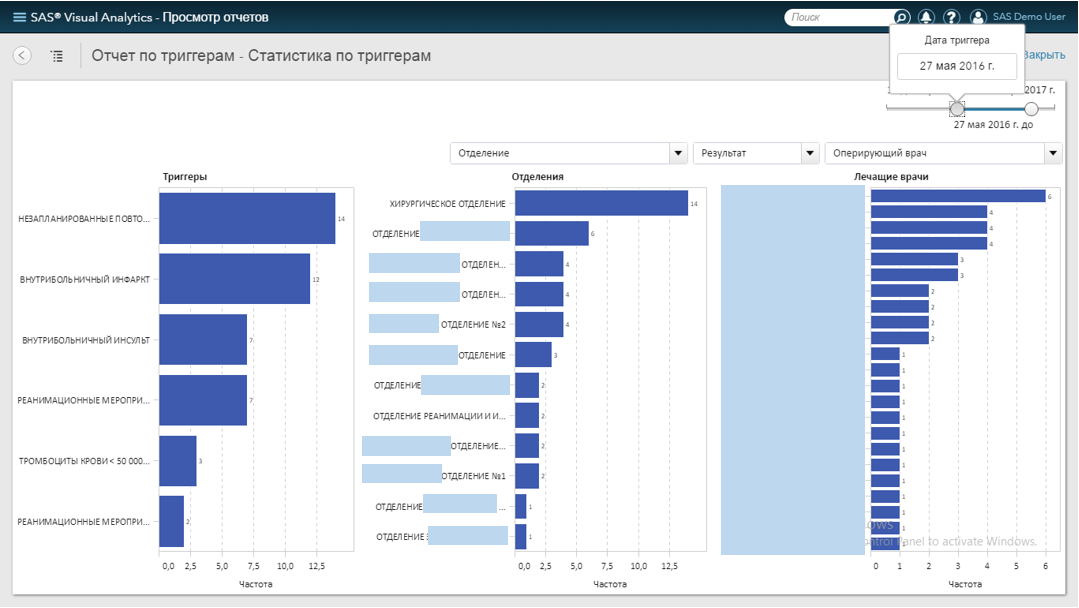
Чтобы не грузить статью скриншотами (тем более «замазанными»), мы записали небольшую демонстрацию на деперсонализированных данных:
Ещё мы хотели настроить автоматическую рассылку уведомлений о триггерах — это хороший тон для аналитических систем, отслеживающих критически важные показатели. Тем более что функционал почтовой рассылки встроен в SAS Visual Analytics. Но Клиника не захотела давать доступ к почтовому серверу, также как отказалась от организации СМС-рассылки через сопряжение с внешними сервисами.
Чем все закончилось
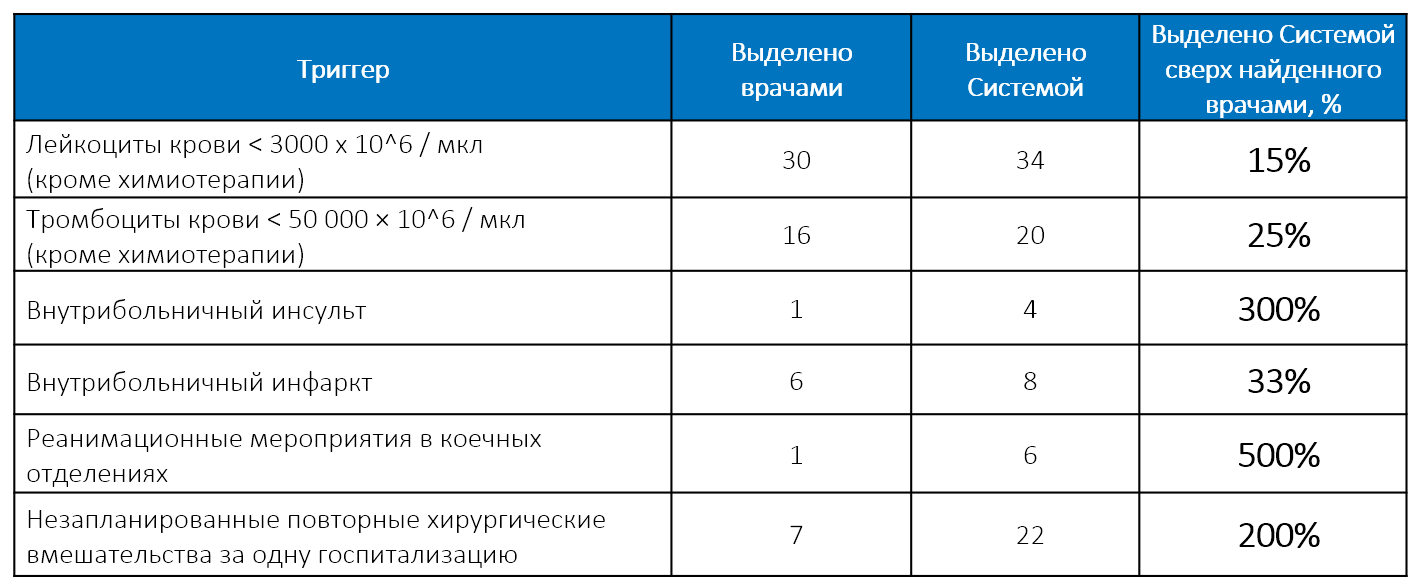
Руководство больницы провело эксперимент, сравнив результаты ручного выявления триггеров неблагоприятных событий коллективом врачей-экспертов и автоматического анализа, проведённого системой SAS. Результат оказался не в пользу людей: система SAS обнаружила больше, чем врачебная комиссия. Для некоторых триггеров — в несколько раз больше:
Но повышенная точность — не главное, что давала система выявления триггеров. Важнее всего, что она позволяла:
- Обеспечить постоянный сплошной контроль всех медицинских записей. Не случайно выбранных или самых вопиющих случаев, а всех до единого. Не только раз в квартал, а в режиме, приближенном к реальному времени.
- Высвободить время высококвалифицированного персонала для занятия профильной деятельностью. Лишь в рамках эксперимента можно было озадачить медперсонал полномасштабным ручным аудитом. В обычном режиме заниматься этим некогда — если врачи будут возиться с записями, некому будет лечить людей.
Важным для успеха проекта была полная поддержка администрации — Главврача, его заместителей и заведующих отделениями. Руководитель Клиники получил образование в США, поэтому идея управления на основе менеджмента качества и автоматизированного анализа данных ему оказалась близка и понятна
Увы, незадолго до полномасштабного внедрения аналитической системы, Главврач ушел с поста. Его сменщик был откровенно консервативен и не любил выносить сор из избы. Клиника списала результаты перспективного проекта «в стол» и вернулась к методам работы, проверенным годами практики.
Хотя мало приятного в том, чтобы делать невостребованный продукт, наработки по эксперименту в Клинике нам очень пригодились в следующем проекте по аудиту медкарт в системе ОМС. Но об этом в другой раз.
