Как мы 40% RAM освободили
На входе: маркетплейс на 1C-Битрикс с большим количеством легаси, в сезон около 1 млн уникальных посетителей в месяц, RAM — 54GB выделено на сервере под работу сайта, rps — ~150.
Текущая проблематика: неоптимальный механизм фильтрации, а именно не хватает ресурсов памяти, постоянно вылетаем в 502/503/504 ошибки, падает конверсия, блокируется работа фильтрации.
Тимлид — @guriianova
Изначальный механизм работы
Ресурсозатратность. Redis
Работа с товарами на сайте происходила не напрямую через mySQL, а с помощью Redis. При обновлении/добавлении товаров, они добавляются в БД, затем обновляются в Redis.
Список товаров в Redis дублирует многомерную структуру (рис. 1) CIBlockElement: GetList (API Bitrix). Но поскольку фильтровать товары с такой структурой было не очень удобно (так как на основе ключа нужно и фильтровать товары, и в последующем рендерить), был реализован еще один список в одномерном представлении (рис. 2) «ключ-значение», где ключ — код свойства, а значение — непосредственно значение этого ключа. На этом этапе около 7 лет назад объем занимаемой оперативной памяти увеличивается из-за дубля данных. Стоит отметить, что тогда номенклатура насчитывала ~50к товаров, а сейчас их ~300к, что уже становится ресурсозатратным.
 Рисунок 1. Многомерная структура
Рисунок 1. Многомерная структура Рисунок 2. Одномерная структура
Рисунок 2. Одномерная структура
Node.js
Механизм фильтрации был реализован на Node.js причем достаточно неоптимально. Приложение обращалось в Redis, считывало всю информацию по товарам в переменную для последующего использования в фильтрации. Фильтрация происходила на уровне приложения, оперируя данными по товарам в переменной: итеративно пробегает по каждому свойству каждого товара для проверки совпадения по выбранному пользователем фильтру. Когда товарная база была небольшой, один экземпляр приложения вполне справлялся с этой задачей, но к 2021 г. мы пришли к пяти (!) запущенным экземплярам. А поскольку каждый из них занимает объем оперативной памяти для хранения информации по товарам в переменной — мы имеем 5 дублей данных в памяти (по одному на каждый запущенный экземпляр приложения). Один экземпляр приложения при старте потреблял ~8Gb, далее во время работы 3,5–4,5Gb, что в сумме давало ~17,5 — 40Gb занятых только на процесс фильтрации.
Также бизнесу важно иметь техническую возможность по увеличению товарной базы и трафика, что приведет к тому, что и пять запущенных экземпляров нам не хватит.
А что по поддержке?
Поддержка также была трудозатратной.Например, чтобы просто добавить тултип к значению фильтра, нужно было:
добавить свойство обмена на стороне bitrix в процесс обновления ключа, содержащего настройки фильтрации (настройки, определяющие фильтров к разделам, их названия и типы)
внести изменения в компонент работы с фильтром на стороне bitrix
внести изменения в интерфейс и логику приложения настройки фильтров (yii)
внести изменения в приложении Node.js при получении данных от сервиса настройки фильтров и передаче их в bitrix.
Помимо вышеперечисленных задач внешний сервис, на котором контент-менеджеры настраивали фильтрацию был интуитивно непонятен.
И самой большой проблемой стало то, что при некорректной работе фильтра найти исходную проблему и отладить ее достаточно проблемно. То есть контент-менеджер приходит с проблемой «не работает», а где именно и что не работает — идешь и ищешь, не представляя с чего начать.

В связи с вышеперечисленными проблемами было принято решение перерабатывать процесс фильтрации.
Выделили 3 основных цели переработки фильтрации:
уменьшить затрачиваемые ресурсы сервера
упростить поддержку
не усложнять процесс редактирования фильтров
В качестве технологий было принято решение использовать:
mySQL как хранилище настроек фильтров для отображения колонки фильтров по разделам под кешем
Redis как хранилище товаров, соответствующих фильтру или набору фильтров
RabbitMQ как брокер очередей, чтобы убрать с хитов индексацию товаров подходящих под тот или иной фильтр
Спойлер: в дальнейшем нам понадобится ElasticSearch, но мы пока об этом не знаем.
Процесс переработки.
Логическая модель данных.
Поскольку у нас не было задачи визуально менять публичный интерфейс, было принято решение построить структуру в базе на основе текущего. В соответствии с чем мы получили 4 таблички в mySQL (рис. 3).
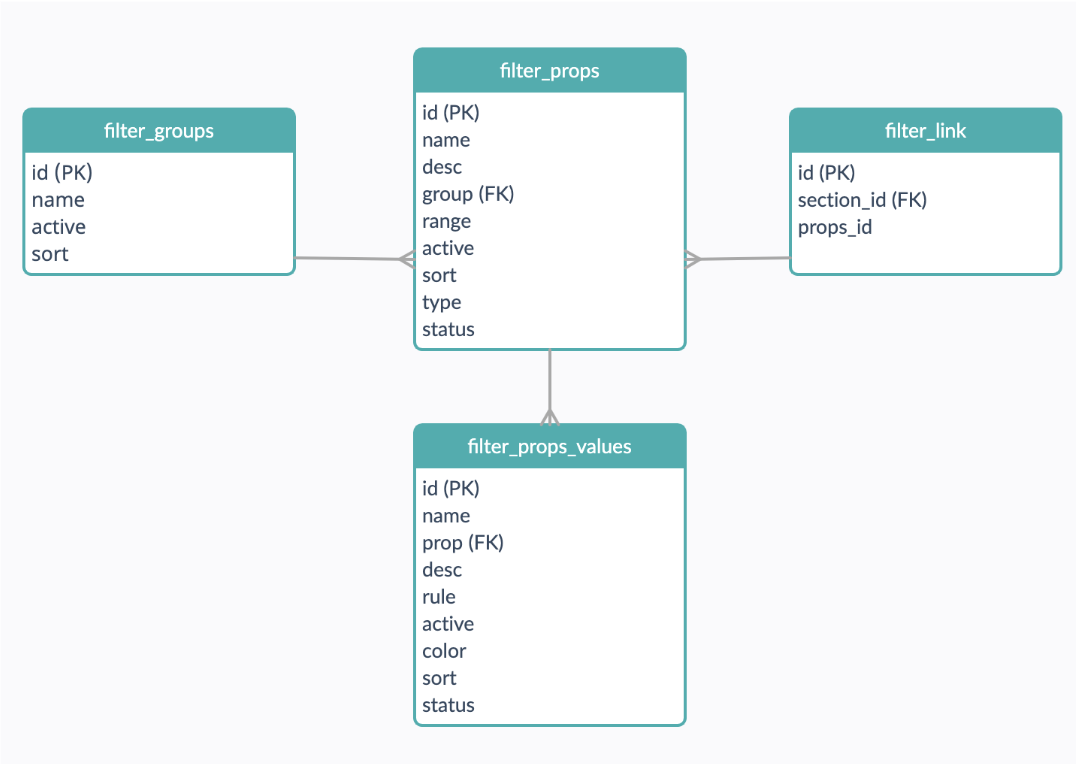 Рисунок 3. Структура таблиц для настроек фильтрации
Рисунок 3. Структура таблиц для настроек фильтрации
Группа фильтров: основные группы фильтрации для визуального разграничения фильтров по группам в публичной части. Например, размеры (ширина, длина), производитель (страна, бренд) и т.д.
Свойства фильтров: таблица с содержанием самих фильтров с типами. Например, цена — диапазон, цвет — чекбокс и т.д.
Значения свойств фильтров: значения чекбокс фильтров. Например, фильтр «цвет» содержит значения «синий», «красный» и т.д.
Привязка фильтров к разделам: указание фильтров для отображения в разделе. Например, в разделе «люстры» отображается фильтр «цоколь лампы», а в разделе комоды «цвет фасада» и тд.
Корневым разделам (на текущем сайте это «свет», «мебель» и тд) задаются фильтры для отображения. Если каким-то из дочерних разделов (например, «настольные лампы» или «шкафы») нужны иные фильтры, их можно переопределить. Признак наличия привязки фильтров у раздела отображается соответствующей иконкой.
Управление настройками фильтров
Контент-менеджеры используют человеко-понятные правила для создания фильтров на основе базовых свойств. Это решение хорошо прижилось, позволяет настраивает абсолютно любые фильтры в абсолютно любом разделе, поэтому было принято оставить текущую логику по настройкам правил подбора товаров к фильтру. Именно по этой причине при принятии решения о переработке мы не могли воспользоваться готовыми решениями типа «умный фильтр» bitrix. Это решение позволяет на основе базовых свойств создавать любые фильтры. Например, комоды имеют свойство «цвет», используя его, мы можем создать фильтр «оттенок» со значениями «светлый», «темный», «детский», используя правило и последующую индексацию товаров под правило.
Правила контент-менеджерами пишутся, используя определенные конструкции, а впоследствии проверяются на синтаксис и переводятся в синтаксис PHP.
Как происходит индексация товаров
На этапе, когда контент-менеджер сохраняет данные (например, правило для фильтра «оттенок светлый») нам нужно проверить 300к товаров (если фильтр задан для всех разделов каталога): подходит ли каждый из них под это правило. Но мы не можем позволить себе делать такое количество запросов в БД, так как это даст большую нагрузку на саму БД.
В соответствии с чем, было принято решение хранить подходящие для фильтра товары в Redis. При сохранении/обновлении фильтра мы имеем php правило, по которому можем проверить подходит ли под правило каждый из товаров каталога. Пачками получаем товары (опять же из Redis) и итеративно проверяем соответствие товара правилу.
В итоге в redis по каждому из фильтров мы имеем множество подходящих товаров. %filter.id%:{2,3,5,7,168}. При запросе пользователя на сервер во время фильтрации приходит список запрашиваемых id фильтров (%filter.id%), на сервере выполняется запрос к Redis по получению множеств (с пересечением и/или объединением в зависимости от запрашиваемых фильтров) с соответствующими ключами (%filter.id%), в результате мы получим одно множество подходящих товаров под запрос пользователя.
И казалось бы всё ок, но что делать с диапазонами, ведь Redis не умеет отдавать товары по запросам ><=, а мы помним, что пользователю нужны диапазоны в таких фильтрах как "цена”, "ширина”, "длина” и тд.
Мы могли бы выделить ключи диапазонов по каждому из свойств 0–5000 у.е., 5001–10000 у.е., забирать по ним множества, а далее фильтровать на основе прямых значений по свойствам, но это все слишком сложно и увеличит время операции подбора товара под диапазон, так как внутри диапазона придется отбирать товары на ходу, потому что если пользователь выберет ценовой диапазон, к примеру, 2500–3600, нам придется забрать все товары из ключа-диапазона »0–5000» и далее отсеивать лишнее на уровне php. Вариант оставить доступные диапазоны чекбоксами вместо ввода «от» и «до» для пользователя нам тоже не подходит, так как это ограничит пользователя в выборе диапазона и маркетинг не одобрил такой подход.
Тут на помощь к нам приходит ElasticSearch. Собираем товары со свойствами типа «диапазон», создаем индекс, индексируем товары со свойствами диапазонов. При запросе диапазона пользователем, например, «цена от 3000 до 5000 руб.» генерируем запрос в elasticsearch (><= ), полученное множество пересекаем с дальнейшими полученными из Redis, если такие есть в запросе.
Таким образом мы избавились от необходимости перебирать товары на ходу.
Вынесение индексации на фон
При всех доработках выше мы получаем список необходимых к выполнению процессов:
индексация всех товаров, подходящих под правила при их изменении/добавлении и для первого релиза
индексация товара под все правила при изменении/добавлении товаров
Такие процессы мы не можем оставить на хит по факту происхождения события, так как они достаточно ресурсозатратны (ведь нужно проверить под 1 правило около 300к. товаров, а эта операция в худшем случае занимает 3 минуты). Контент-менеджеру при этих условиях, редактируя фильтры, придется ждать по несколько часов. Поэтому было принято решение унести их на фон с помощью брокера очередей.
При работе мы выделили 3 процесса:
Обработка правил, т.е. если кто-то из контент-менеджеров меняет/редактирует какое-то правило нам нужно переиндексировать до 300к. товаров (прогнать под это правило товары, 300к — если фильтр общий и имеет отношение ко всем разделам каталога)
Обработка изменений диапазонных характеристик товара — переиндексация в ElasticSearch. Изменение диапазонных характеристик товара (цена, размер и тд), т.е. необходимо переиндексировать товар под все правила для сохранения актуальной выдачи фильтров
Обработка изменений чекбокс характеристик товара — переиндексация в Redis.
Таким образом контент-менеджер при сохранении свойства увидит статус «в обработке» и сможет приступить к редактированию других фильтров. Когда сообщение будет обработано брокером, статус свойства изменится на «обработано» и результат можно будем проверить в публичной части.
Вместо заключения
Почему мы не переложили всю работу фильтра на ElasticSearch? В таком случае нам пришлось бы индексировать в elastic все свойства каталога, а поскольку все товары у нас уже есть в redis — в этом нет смысла, мы только продублируем данные, поэтому нам достаточно проиндексировать товары и сохранить фасетные индексы в redis.
Полностью переработав механизм фильтрации мы:
Упростили поддержку и, как следствие, сократили затраты на последующую доработку
Обеспечили контент-менеджерам удобство редактирования
Избавились от блокера для дальнейшего масштабирования системы
Ну и, конечно, освободили в среднем 40% RAM (от 17,5 GB до 40GB)
На текущий момент фоновые процессы по переиндексации правил при наличии сообщений в очереди потребляют в пределах 190MB на переиндексацию товаров по правилам.
