Как LLM учат понимать синтаксис
Скорее всего, вы поняли заголовок правильно, хотя в нём есть стилистическая ошибка — двусмысленность (кто-то учит LLM, или они учат кого-то?).
Человеческое понимание языка остается ориентиром и пока недостижимой целью для языковых моделей. При всей небезошибочности первого и при всех невероятных успехах последних. Например, человеку обычно не составляет труда однозначно трактовать двусмысленные фразы исходя из контекста. Более того, мы с удовольствием используем такие каламбуры в шутках разного качества. Из самого известного приходит на ум только «В Кремле голубые не только ели, но и пили» (предложите свои варианты в комментариях — будет интересно почитать). Есть ещё «казнить нельзя помиловать», но эта двусмысленность разрешается запятой.
Самый известный пример в английском: »Time flies like an arrow; Fruit flies like a banana».
Человек скорее всего после некоторых раздумий поймёт это как »Время летит как стрела, мухи любят банан» (хотя мне, например, понадобилось на это несколько секунд). Яндекс переводчик понимает эту фразу так: »Время летит как стрела, фрукты разлетаются как бананы». Google translator демонстрирует зоологическую эрудированность:»Время летит как стрела; Фруктовые мушки, как банан», а ChatGPT предлагает »Время летит как стрела; Мухи на фруктах летают как бананы». В общем, никто не справился.
В отличие от LLM человек понимает (или чувствует) структуру предложения, его синтаксис. Это и помогает различать мух и фрукты. Поэтому возникает логичное желание обучить синтаксису языковые модели. В 2016 году предлагались синтаксические языковые модели (SLM), в основе которых было совместное распределение токенов и синтаксической структуры (статья). Теоретические основы восходят к работам Елинека и Лафферти из IBM Research (статья 1, статья 2) и Марка Паскина из Калифорнийского университета в Беркли (статья). SLM показывали хорошие результаты, но плохо масштабировались, поэтому с 2016 года они не обрели особого успеха. Сейчас началась вторая волна SLM на фоне успехов трансформеров, которая пытается объединить качество SLM и масштабируемость LLM.
Tree-Planted Transformers
В Токийском университете предложили архитектуру Tree-Planted Transformers (TPT), в которой синтаксические деревья «сажают» в модули внимания в трансформерах. Такие «рощи-трансфомеры» обучают на небольшом количестве деревьев, а затем масштабируют на большие корпусы текстов.

Слабое место SLM — само её пространство, так как моделируется совместное распределение (слов и синтаксиса). Поэтому авторы TPT нацелились на то, чтобы создать некоторую синтаксическую надстройку над трансформером, которая не тронула бы его модельное пространство.
Для этого сначала предлагают использовать двумерный аналог синтаксического расстояния. В одномерном предполагается расстояние между соседними токенами, а в двумерном рассматриваются все пары слов. Например, для фразы «birds in a cage sing» будут рассчитаны синтаксические расстояния для всех пар слов: «birds in», «birds a», «birds cage» и так далее.

Из этой матрицы D получается матрица S, которая, собственно, контролирует веса внимания трансформера. В расчет S входят экспоненты, которые обеспечивают затухание по мере увеличения расстояния между словами.
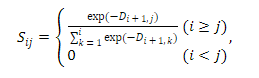
Это почти позволяет масштабировать SLM до большой модели, но остается только решить вопрос с тем, что инференс должен происходить без дополнительного парсера, который выполняет синтаксический анализ.
Этого авторы предлагаются добиться с помощью функции потерь. Используется расстояние Кульбака — Лейблера между матрицей контроля и матрицей весов внимания. Внимание перед этим пересчитывается с субтокенов до уровня токенов. Такая функция рассчитывается для каждого посаженного дерева, а затем усредняется и суммируется с лоссом предсказания следующего слова. Таким образом контроль за весами внимания встроен неявным образом.
На бенчмарке SyntaxGym обошли большинство других SLM. Лучше оказалась только TG (модель Transformer Grammars), которая при этом тяжеловесенее TPT. С LLM соперничать тоже не особо получилось, однако авторы пишут, что результаты вполне позволяют считать TPT основанием для создания больших SLM.

Generative Pretrained Structured Transformer
Другой подход появился в марте этого года. Вновь предлагается объединить архитектуру трансформеров и SLM, но в этот раз без контроля (unsupervised). Обычно в таком варианте синтактическое дерево строится с помощью однонаправленной модели (в предыдущей статье — тоже), то если проход осуществляется один раз справа налево. Из-за этого асимметричного процесса ветвление дерева не будет непредвзятым. Поэтому Generative Pretrained Structured Transformers (GPST) состоит из двух частей: сначала структурная модель проводит синтаксический анализ с помощью двусторонней функции потерь, а затем уже происходит генерация с однонаправленной моделью.
Этот подход повторяет ЕМ-алгоритм. На E-шаге создается синтаксическое дерево. На M-шаге оптимизируется совместная целевая функция на основе этого дерева. Поиск дерева происходит с помощью inside-outside алгоритма. Сначала внутренний проход — рассчитываются составные репрезентации для всех пересечений. Например fruit flies/like a banana, like/ a banana. Затем таким же образом внешний проход, но в другую сторону.
Представления, рассчитанные на внутреннем проходе, передаются как суррогат на вход трансформеров генеративной модели. Таким образом появляется возможность параллельного обучения всей архитектуры. После того, как дерево построено, одновременно обновляются параметры генеративной и структурной модели.

Чтобы сравнить GPST и GPT-2, их предобучили на одном корпусе с одинаковыми установками и примерно одинаковым количеством параметров. Обучение проводили на WikiText-103 и OpenWebText. Способности к пониманию сравнивали на бенчмарке GLUE. Также авторы проверили возможности генерации и синтаксического обобщения. В размерах small и medium GPST превзошла GPT-2 почти на всех задачах GLUE.

Также авторы проверили возможности генерации и синтаксического обобщения. И там, и там результаты близки к GPT-2 c небольшим преимуществом в сторону GPST. То есть улучшить понимание удается, но на выходе это пока не особо сказывается. В любом случае, задел есть, исследовать его интересно. Особенно, если рассматривать структурную модель из GPST как усовершенствованный слой эмбеддингов.
Больше наших обзоров AI‑статей на канале Pro AI.
