Как ленивый работящему помог. Ещё один скрипт для релиза подкаста
Но на курсы я тогда всё же сходил.
С тех пор прошли годы, число детей выросло, работу поменял, бассейн бросил, а автоматизирую теперь всё, до чего дотягиваются беспокойные руки.
Ниже старая как кости мамонта история о появлении yet another убер-скрипта для механизации рутины. Началась она с попытки распарсить RSS, а закончилась системой полного релизного цикла подкаста.
Итак, всё началось с того, что никак нам не давал покоя тот факт, что на ютубе наши подкасты слушают (сами в шоке, честно!), но эпизодов за предыдущие 8 лет там нет.
А меж тем наши неустанные рты наговорили порядка двухсот штук по всем рубрикам, коих тоже уже больше полудюжины.
Настолько намозолило это наш коллективный натруженный мозг, что вызвался самоотверженный доброволец готовить по одному эпизоду в день. Но для этого нужно обладать космическим уровнем дисциплины и резиновым временем.
Ведь как выглядит релиз видео:
1. Собрать в фигме обложку подкаста.
2. Собрать в одном месте обложку, mp3 и запустить рендер в ffmpeg
3. Вручную залить готовое видео на ютуб
4. Заполнить название, описание, теги, дать ссылку на пост на сайте, добавить в нужный плейлист.
5. Опубликовать в день релиза
Неупомянутым здесь особняком стоит релиз подкаста на сайте и в RSS, где тоже длинный список операций.
И я подумал, почему бы не помочь товарищу дружеским скриптом, который соберёт всё в одном месте в удобном виде.
Примерно таком.
Жисон:
{
"kdpv": "https://fs.linkmeup.ru/images/podcasts/linkmeup-V089(2020-07).jpg",
"link": "https://linkmeup.ru/blog/571.html",
"podcast_url": "https://dts.podtrac.com/redirect.mp3/https://fs.linkmeup.ru/podcasts/telecom/linkmeup-V089(2020-07).mp3",
"title": "telecom №89. Транспорт и управление перегрузками",
"body": "Some body that I used to know"
}
Хотя бы копировать из одного места, и картинка — вот она — уже подспорье.

Говорят, мир едет на ленивых. Но в самом низу ногами гребут ленивые и глупые. Зачем искать существующие парсеры RSS, если можно написать чуть похуже, но свой?
Так появился get_podcasts.py.
Всё что он делал: собирал в один словарь title, podcast_url, body и kdpv. В качестве последнего он брал первый попавшийся img src, если им была не картинка с патреон.
Словарь пишется в файл all_podcasts.json.
Следующая светлая мысль, обещающая непыльную работу и драматическое упрощение труда энтузиаста, не заставила себя ждать:
Ну когда уже URL есть, почему бы файлики не скачать и не положить рядышком?
Так появился download_podcasts.py, который скачивал звук и изображение, выделял им случайное имя, сохранял в соответствующих директориях, и обогащал словарь all_podcasts этими именами, сохраняя результат в all_podcasts_w_files.json.
И тут же ещё категорию подкаста укажем.
Жисон:
{
"category": "telecom",
"img": "img/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.jpg",
"kdpv": "https://fs.linkmeup.ru/images/podcasts/linkmeup-V089(2020-07).jpg",
"link": "https://linkmeup.ru/blog/571.html",
"mp3": "mp3/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp3",
"podcast_url": "https://dts.podtrac.com/redirect.mp3/https://fs.linkmeup.ru/podcasts/telecom/linkmeup-V089(2020-07).mp3",
"title": "telecom №89. Транспорт и управление перегрузками",
"body": "Some body that I used to know"
}
На случай если картинки нет, я нарисовал шаблоны, которые можно взять в качестве обложки.

И вот казалось бы всё — бери ffmpeg двумя руками на полчасика в день — и ты чуть ближе к счастью.
Ну вот ещё командочку сгенерю, чтобы уж совсем просто было вставлять.
ffmpeg -loop 1 -i "img/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.jpg" -i "mp3/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp3" -c:a copy -c:v libx264 -shortest "mp4/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp4"
»Постой» — скажет практикующий скриптинг читатель — »Ну ты же ленивый, но не настолько глупый — запусти команду через subprocess».
Ну вот и я так подумал. И отсюда начинается захватывающая дух история.
»Только «Hello world» может быть проще, чем запустить команду linux из питона» — считал я на основе своего более чем скромного опыта. Импорт сабпроцесс, сабпроцесс.попен — и погнали.
Но засада оказалась там, где её не ждали: ffmpeg отдавал какой-то код возврата питону, а сам продолжал считать в фоне. Питон же считал, что команда отработала, и исполнял дальше. А дальше — цикл по всем эпизодам.
При первом же запуске окно терминала превратилось в какую-то манку с комочками. Я подозреваю, что наши 200 подкастов даже отрендерелись бы за какой-то необозримый промежуток времени.
Но такой жгучий дискомфорт я почувствовал в области органа тотального контроля, что пришлось стопнуть и поставить input (). Чего уж там — 200 раз нажать на энтер — мне не сложно.
render_video.py
И я запустил РЕНДЕР. Ноутбук зашуршал вентиляторами, пытаясь остудить горячее своё нутро. На следующие несколько суток этот звук стал верным моим спутником.
Он считал видео и обогащал all_podcasts_w_mp4.json именем файла mp4.
Жисон:
{
"category": "telecom",
"img": "img/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.jpg",
"kdpv": "https://fs.linkmeup.ru/images/podcasts/linkmeup-V089(2020-07).jpg",
"link": "https://linkmeup.ru/blog/571.html",
"mp3": "mp3/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp3",
"mp4": "mp4/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp4",
"podcast_url": "https://dts.podtrac.com/redirect.mp3/https://fs.linkmeup.ru/podcasts/telecom/linkmeup-V089(2020-07).mp3",
"title": "telecom №89. Транспорт и управление перегрузками",
"body": "Some body that I used to know"
}
Но тут наступила ночь — время, когда я обычно не нажимаю на клавишу энтер. Но нельзя ведь терять столько драгоценное время — поэтому меняем input () на time.sleep (1800) — за полчаса должно же посчитаться.
Добавил условие, что рендерить видео нужно, только если mp4 в словаре ещё отсутствует, и ушёл спать.
Нет, тут всё хорошо — без подвоха, за недолгих три дня оно посчиталось. Ни один вентилятор не пострадал. Но без подключения к сети электропитания ноутбук можно было перенести только в другую комнату, батер выживал не более получаса и рассыпался в благодарностях, когда чувствовал поддержку 220В.
За это время я научился по звенящей тишине определять, что пора нажимать энтер и запускать расчёт дальше.
Я настолько привык к этому фоновому шуму, отсылавшему меня назад в нулевые, когда на ЭЛТ-мониторе NFS Porsche Unleashed сменял Max Payne, а в ногах шумел неистово биг-тауэр c селероном, что весь день, когда последний эпизод отрендерился, и в комнате повисла зловещая тишина, мне навязчиво казалось, что что-то вышло из строя.
К этому моменту у меня были директории с mp3, img, mp4, и заполненный файлик all_podcast_w_mp4.json со всеми необходимыми ссылками.
Но вместо заслуженного отдыха я уже 2 дня к этому моменту изучал YouTube Data API.
Самый поверхностный гуглёжь навёл на готовый скрипт на питон2 upload_video.py, который можно запустить с ограниченным списком аргументов.
python upload_video.py --file="/tmp/test_video_file.flv"
--title="Summer vacation in California"
--description="Had fun surfing in Santa Cruz"
--keywords="surfing,Santa Cruz"
--category="22"
--privacyStatus="private"
Не без бубенчика я его попробовал, залил тестовое видео на тестовый аккаунт, получил свою порцию дофамина, достаточную, чтобы начать борьбу с фейспалмом от python2. Ну не может в 2021 не быть нормального богатого API.
И да, конечно, это я был кротслеповат. А по ссылке открывается богатейшая документация к API на все ручки. Тут вам и дата публикации, и дата записи, и плейлист, и тегами можно всё обмазать. И какой хошь ЯП.
И мы подумали, что будем загружать все видосы в скрытом режиме и публиковать раз в месяц все эпизоды одного года.
Поэтому появился скрипт get_pub_dates.py, который ещё раз парсит RSS и собирает из него даты публикации эпизода на сайте, которые затем транслируются в запланированную дату публикации на ютубе.
Жисон:
{
"category": "telecom",
"img": "img/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.jpg",
"kdpv": "https://fs.linkmeup.ru/images/podcasts/linkmeup-V089(2020-07).jpg",
"link": "https://linkmeup.ru/blog/571.html",
"mp3": "mp3/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp3",
"mp4": "mp4/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp4",
"podcast_url": "https://dts.podtrac.com/redirect.mp3/https://fs.linkmeup.ru/podcasts/telecom/linkmeup-V089(2020-07).mp3",
"publishAt": "2021-09-30T12:00:03.000Z",
"recordingDate": "2020-07-25T08:25:14.000Z",
"title": "telecom №89. Транспорт и управление перегрузками",
"body": "Some body that I used to know"
}
all_podcasts_w_pd.json
И вот готов скриптецкий, заливающий килотонны видео в наш доселе камерный канал: upload_video.py (на python3).
И вот что получилось.
Жисон:
{
"category": "telecom",
"img": "img/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.jpg",
"kdpv": "https://fs.linkmeup.ru/images/podcasts/linkmeup-V089(2020-07).jpg",
"link": "https://linkmeup.ru/blog/571.html",
"mp3": "mp3/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp3",
"mp4": "mp4/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp4",
"podcast_url": "https://dts.podtrac.com/redirect.mp3/https://fs.linkmeup.ru/podcasts/telecom/linkmeup-V089(2020-07).mp3",
"publishAt": "2021-09-30T12:00:03.000Z",
"recordingDate": "2020-07-25T08:25:14.000Z",
"title": "telecom №89. Транспорт и управление перегрузками",
"youtube_id": "jFvFIpWDjKM",
"body": "Some body that I used to know"
}
Кстати, пользуясь случаем, шлю лучи добра в корпорацию зла за дружелюбные интерфейсы. Более удобных мест и способов получения ключей я нигде не видел. Получил качественное эстетическое удовольствие.
Ну и ещё, чтобы вы поняли, насколько вам хорошо живётся, если не приходится использовать YouTube API:
— Нельзя добавить видео в плейлист, если он отсортирован по дате добавления.googleapiclient.errors.HttpError:
— Зато если уж можно, то добавить можно хоть 1000 раз одно и то же видео.
— Если видео добавлены в плейлисты, то в админке они исчезают с главной (а у обычного пользователя — нет).
— Официальные видео по IAM и документация к API не совсем соответствует действительности.
К слову, каждый сеанс связи с гугл-АПИ авторизуется отдельно. Вам выдаётся ссылка, на которую нужно тыкнуть, а потом в интерфейсе тыкнуть ещё 6 (6, НАТАША!!!) раз, чтобы получить код авторизации. Действует он только на этот запуск скрипта, потом нужно получать новый.
Я читал, что есть некий REFRESH Token, который не протухает, но, спасибо интерфейсам, я так и не постиг мрачную тайну его использования.
Ещё у ютуба, оказалось, имеется квота на количество операций по API. 10 000 енотов в день.
И прайс такой: загрузка видео — 1600 за каждую попытку, обновление плейлиста — 50. Узнал я об этом после 6-го видео. Весь список, пожалуйста.
googleapiclient.errors.HttpError: quota.". Details: "The request cannot be completed because you have exceeded your quota.">
И я должен сказать, хорошо, что эта квота была. Потому что в канал нагрянула миссия от нашей команды и признала, что коллективное чувство прекрасного ущемлено такими безликими изображениями. И предложила не заливать пока дальше.

Мне потребовалось время, чтобы смириться с мыслью, что трое суток рендера и мучений моего ноутбука были напрасны. Что 200 моих детищ ждёт /dev/null с распростёртыми файл-дескрипторам. И их нужно будет в муках рожать заново.
Но!
Воистину большим препятствием была лень рисовать обложки. Их же не 1 и не 2 — их 200!
Шаблон обложки у нас лежит в фигме. И набор действий для создания оной под каждый эпизод в целом механический.
»Ну наверняка есть API у фигмы, через который можно проделать те же манипуляции» — опять подумал я (всё же, похоже, что думать — это не моё). Цена тому — научиться в ещё один API. Что? Мало разве их было в моей грешной жизни?
Увы, API фигмы Read Only — надежды рассыпались.
Мы сели с нашим дизайнером и начали думать что же можно поделать. Он сказал, что может написать веб-сервис, который нам такую картинку сгенерит. И после мгновения радости от найденного решения, сразу в голову полезли мысли о том, что его нужно где-то разворачивать, поддерживать, мониторить — чуть больше головняка, чем хотелось бы. Но эта идея склонила мою мысль на подушку, в смысле Pillow — форк библиотеки PIL (Python Imaging Library) для работы с изображениями. Там вообще чудеса можно творить и на голове стоять.
Всё, что было нужно сделать:
— Иметь два изображения: шаблон обложки и картинку эпизода.
— Отресайзить последнюю и обрезать до нужного размера
— Скруглить ей углы
— Наложить её на шаблон обложки
— Добавить текст с названием эпизода.

Делов-то: сесть и сделать.
Думал я так, и это даже оказалось недалеко от истины — дело техники.
И опыта, которого у меня не было. Я с удивлением для себя открыл, как работает прозрачность в png. Я около часа боролся с этой квадратурой круга: все углы у изображения скруглил, а оно вставляется в шаблон обложки ровным прямоугольником. Я уже проверял из каких файлов берутся эти изображения, пробовал другие, сохранял картинку со скруглёнными углами в файл, чтобы проверить, что они действительно скруглены. Я даже сам в гимпе нарисовал пнг с большим прозрачным пятном посередине. Но чертовщина продолжалась.
Пока не пришло просветление, что прозрачность задаётся маской поверх полного изображения, а Image.paste по умолчанию это дело игнорирует (или не умеет работать).
В итоге нужно было маску извлечь из изображения и накладывать с её учётом. Фьюх.
r, g, b, m = img.split()
top = Image.merge("RGB", (r, g, b))
mask = Image.merge("L", (m,))
cover.paste(top, (44,83), mask)

Вторая техническая задачка — вписать текст в обложку.
Тут всё сравнительно легко — в зависимости от количества символов выбрать шрифт и рассчитать расстановку слов — сколько символов допустимо в одной строке.
if len(text) < 50:
letters = 17
elif len(text) < 80:
letters = 21
else:
letters = 26
text = ''
row = ''
for word in words:
if len(row+word)+1 <= letters:
row += f'{word} '
text += f'{word} '
else:
row += f'\n{word} '
text += f'\n{word} '
row = word

Полный код скрипта: gen_kdpv.py.
Жисон:
{
"category": "telecom",
"cover": "img/covers/afc5a3cf-cbcf-4c3f-8a64-9cc8df589ba3.png",
"img": "img/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.jpg",
"kdpv": "https://fs.linkmeup.ru/images/podcasts/linkmeup-V089(2020-07).jpg",
"link": "https://linkmeup.ru/blog/571.html",
"mp3": "mp3/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp3",
"mp4": "mp4/ef684cbd-9fb0-4226-8a8c-b1c6ff4ae908.mp4",
"podcast_url": "https://dts.podtrac.com/redirect.mp3/https://fs.linkmeup.ru/podcasts/telecom/linkmeup-V089(2020-07).mp3",
"publishAt": "2021-09-30T12:00:03.000Z",
"recordingDate": "2020-07-25T08:25:14.000Z",
"title": "telecom №89. Транспорт и управление перегрузками",
"youtube_id": "jFvFIpWDjKM",
"body": "Some body that I used to know"
}
Я пожалел своего Боливара и решил воспользоваться виртуалочкой, любезно запущенной моим соратником на производственных мощностях linkmeup.
Но для этого нужно было решить один вопрос — как не нажимать на проклятый энтер. Не то чтобы это было невозможно на вируталке или я смертельно устал. Нет! Это был уже вопрос моей чести как скриптоинвестора — нельзя было после такой работы идти на компромиссы.
Для питона, конечно же, есть батарейка с ffmpeg. Этому я даже не удивился, я шёл на stackoverflow в поисках именно её.
Вообще пусть славятся в веках имена создателей stackoverflow, которые обеспечили бутерброд с икрой таким как я!
Но как-то то ли контакта на батарейке не два, то ли я просто не догадался, какой стороной её вставлять. Одним словом переложить знакомые команды даже после обращения к более опытным в питоне товарищам, не получилось.
И тут элегантное, как валенки, решение осветило внутреннюю поверхность черепа. Subprocess, наверняка, возвращает ID процесса. А что если просто дождаться его завершения, прежде чем выполнять код дальше?
И вот это озарило своим присутствием мой скрипт:
while True:
if psutil.Process(run_cmd.pid).status() == 'zombie':
break
render_video_norm.py
После этого я со спокойной душой залил всё это барахло на виртуалочку, в tmux’е запустил скрипт и ушёл писать этот пост на следующие 5 дней.
Единственное, что оставалось ручного — это каждый день запускать скрипт загрузки видосов, потому что квота, и потому что сессионные ключи.
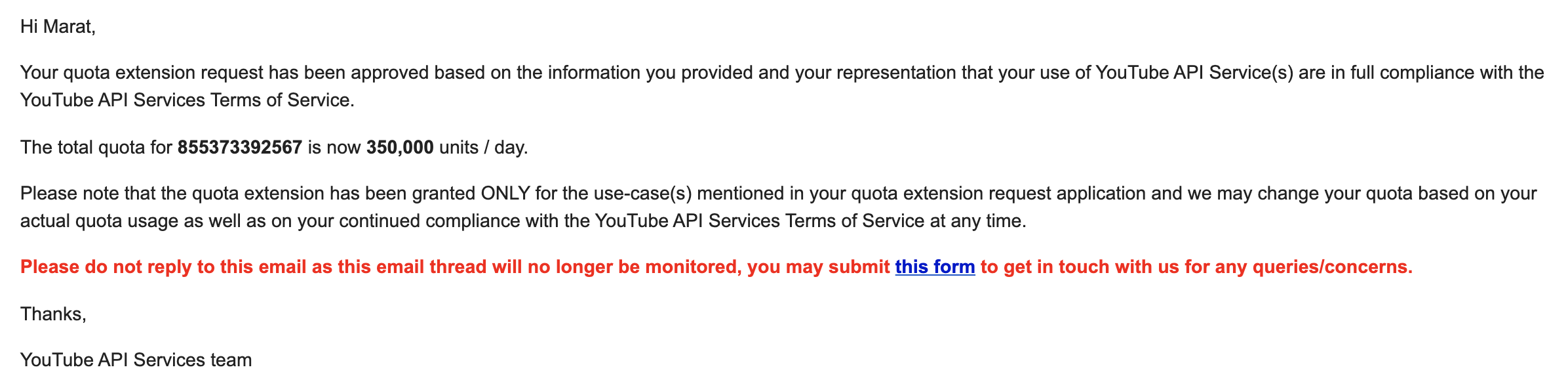
Однако довольно быстро была найдена секретная форма с заявкой на расширение квоты.
Сделана она прицельно так, чтобы ты дошёл до её конца, только если у тебя действительно очень острая необходимость квоту увеличить.
Без какой-либо надежды я заполнил эту форму минут за 20, расписав каждого необходимого мне енота, и без надежды ушёл спать. 14 раз. А через 2 недели мне пришло письмо счастья от гугла, где моя квота была повышена до 350000. И далее за один день я уже залил всё, что хотел.
Теперь последний день каждого месяца в течение полугода пачка видосов будет сама по себе улетать в паблик. Первая партия — завтра.
Ну и апофеозом всей этой волнительной истории должен стать готовый продукт для релиза новых подкастов. Ведь мы же не прекращаем ртом в микрофон говорить. А для продукта уже почти всё готово.
В итоге получился вот такой скрипт, написанный в лучших традициях экскриментального кодинга.
podcast_release.
Теперь, чтобы зарелизить подкаст, надо (кроме его записи и обработки, конечно же):
Найти картинку к выпуску, придумать название и подготовить описание.
А дальше:
./release.py -i 'img/test.jpg' -m 'mp3/test.mp3' -t 'telecom №196. Лист и феоктист' -d description.html
И оно само:
- Нарисует обложку для ютуб,
- отмасштабирует в обложку для RSS и для ВК,
- зальёт все файлы на хостинг
- Отрендерит видео
- Зальёт его на ютуб с описанием в нужный плейлист
- Подготовит текст для поста на сайт
Последнее — это временная полумера, пока мы не переедем на ипси-дипси новый сайт на вордпрессе с адекватным REST API.
И в целом останется только вопрос кросспостинга его в вк, телегу и менее привлекательные каналы.
И да, автор отдаёт себе отчёт в том, что в сети есть сервисы, делающие нечто подобное. Но это для слабаков и за деньги любой дурак сможет. Впрочем немножечко специфичных задач у нас есть — например, обложка, зависящая от категории подкаста, которую можно извлечь только из названия.
Всем спасибо за внимание. На то, что мой скрипт будет полезен кому-то я надежды не питаю, однако любой обратной связи и пуэрам в репу linkmeup я буду рад.
