Как измерить успех. Стратегии мониторинга и их связь с бизнес-проблемами
Перед тем, как ответить на вопрос «Как измерить успех?», надо понять, что значит «успех» именно для вас. Для Dev и Ops определение успеха отличается. Для Dev успешный проект полностью проходит тестирование. Для эксплуатации — мониторинг. Тестирование и мониторинг нужны, но тесты никогда не дают 100% покрытия проблемы, а ответа 200 от HTTP недостаточно, чтобы быть уверенным в том, что система хорошо работает. Leon Fayer на РИТ++ отстаивал точку зрения, что DevOps платят не за то, чтобы все метрики в мониторинге были в зеленой зоне. Платят за то, чтобы пользователи были довольны. Если недовольны — бизнес теряет деньги, и никого не волнует, что все зеленое.
Под катом много примеров из практики, которые доказывают эту точку зрения. Разберем, зачем понимать бизнес, как следить за успехом с точки зрения бизнеса, и зачем это нужно простым разработчикам.

О спикере: Leon Fayer родился в когда-то дружественной республике, но вырос в США. Начал заниматься программированием очень много лет назад, и за это время работал программистом, менеджером — кем только не работал. Участвовал в стартапах — некоторые были более удачные, а некоторые не очень.
Много лет Леон работает в OmniTI. Эта компания специализируется на разработке масштабируемых систем, поэтому Леон имеет уникальную возможность проектировать и строить системы для самых посещаемых сайтов в мире — Wikipedia, National Geographic, White House, MTV и т.д.

Перед тем, как ответить на вопрос «Как измерить успех?», надо понять, что значит «успех» именно для вас. Для каждого человека ответ будет разный.
Если вы читаете эту статью, скорее всего, вы имеете отношение к DevOps. Вы больше Dev, чем Ops? Или, наоборот, больше Ops, чем Dev? Для Dev и Ops определение успеха немного разное: для Dev — это, естественно, тестирование.
Тестирование
Для меня, как для программиста, успешное тестирование означает, что все в порядке, все хорошо, все работает — можно запускать в production. Проблема в том, что я еще и циник, и не фанат тестирования как такового. Не потому, что это трудно, и не потому, что это долго —, а потому, что тестирование не дает то, что я хочу.

Поймите меня правильно, тестирование — это обязательный процесс, оно должно быть включено в любой проект, но его явно недостаточно, чтобы гарантировать успех.
Есть много разных вариантов тестирования:
- performance-тесты;
- user-тесты;
- автоматическое тестирование…

Сколько вы используете методов тестирования — 1, 2, 3, 5? И что, вас не будят по ночам алерты? Все работает в production?
Проблема в том, что тестирование дает иллюзию успеха. Оно предопределено: мы знаем, что поезд должен выйти из пункта А и дойти в пункт В, на это мы и тестируем. Есть варианты, которые мы продумываем. Если у поезда отвалится колесо или закончатся дрова, это не будет неожиданностью. Но мы не тестируем, например, ограбление поезда. Мы не можем это тестировать, потому что мы не знаем, что такой вариант возможен.
Есть парочка проблем, из-за которых тестирования просто недостаточно. Первая из них, естественно, проблема с данными. То, что задача работает локально, но почему-то не работает в production — стандартная проблема.
Неважно, насколько мы стараемся. Неважно, сколько репликаций мы делаем вживую —development и production никогда не будет равен. Будет ли еще одна строка в базе данных, будет ли еще один лишний запрос — в production всегда будет что-то, на что мы не рассчитывали.
Wolfe+585 — самая длинная фамилия в мире:
Hubert Blaine
Wolfeschlegelsteinhausenbergerdorffwelchevoralternwaren-gewissenhaftschaferswessenschafewarenwohlgepflegeundsorgfaltigkeitbeschutzen-vorangreifendurchihrraubgierigfeindewelchevoralternzwolfhunderttausendjahres-vorandieerscheinenvonderersteerdemenschderraumschiffgenachtmittungsteinund-siebeniridiumelektrischmotorsgebrauchlichtalsseinursprungvonkraftgestartsein-langefahrthinzwischensternartigraumaufdersuchennachbarschaftdersternwelchege-habtbewohnbarplanetenkreisedrehensichundwohinderneuerassevonverstandig-menschlichkeitkonntefortpflanzenundsicherfreuenanlebenslanglichfreudeundruhe-mitnichteinfurchtvorangreifenvorandererintelligentgeschopfsvonhinzwischensternartigraum,
Sr.Немногие системы выдержит, если кто-то введет такую фамилию в форму. Я знаю минимум 5 разных точек, в которых может полететь вся система.
Поэтому вторая проблема — это проблема с пользователями.

Это такие интересные люди, которые поломают все, что угодно. Если бы не было пользователей, все было бы гораздо легче, честно скажу.
Даже если в вашем UI будет одна кнопка, они все равно найдут метод, как поломать то, что мы делаем.
Самый лучший пример — это World of Warcraft.

Для тех, кто не знает, — это онлайн игра, в которую играли 10 млн людей. В свое время там были довольно легендарные баги. Corrupted blood bug — это идеальный пример того, насколько пользователи все портят.
Как и в любой игрушке, в World of Warcraft постоянно появлялся новый контент, новые идеи, новые боссы. Один из новых боссов ставил проклятие на одного из 40 игроков в группе. Принцип проклятия был как бомба замедленного действия — оно потихоньку забирало жизни всех вокруг. То есть надо было отбежать в сторону — там была целая механика. И все было хорошо, пока в какой-то момент один из игроков не решил во время боя телепортироваться в город…

В городе находились тысячи людей любых уровней, самых маленьких тоже. Мало того, там были еще неигровые персонажи, которые тоже заражались проклятьем. В течение суток серверы опустели. Нельзя было выйти никуда, где еще были другие игроки. Это стало игровой чумой в прямом смысле этого слова. Пришлось сделать round restart всех серверов для того, чтобы убрать проклятье и поменять механику. И все из-за одного тестировщик — даже не знаю, как его назвать.
Третья основная проблема — это проблема с внешней зависимостью. Мы все с этим сталкивались: API, от которого ты зависишь, вдруг перестает работать; или ты перестаешь контролировать API.
Но есть еще бо́льшая проблема с этим. Внешняя зависимость может быть не только прямая, но еще и косвенная. Мы все сейчас используем OpenSource. Каждый OpenSource продукт зависит от каких-то библиот6ек, которые тоже OpenSource и которые поддерживает кто-то другой. Когда что-то ломается, оно ломается не только в этом маленьком модуле, но и во всем, что зависит от него.
Наверное, самый идеальный пример этому был недавно, примерно год назад — это left-pad. Это npm модуль на node.js, который выставляет пробелы перед string (в начале строки). Не будем обсуждать, зачем этот модуль был сделан. Но оказывается, его включили в очень много популярных модулей. В какой-то момент автор решил, что с него хватит, убрал этот модуль из npm, и полетело 70% кода, написанного на node.js.
Если вы думаете, что это единичный случай, — вы ошибаетесь.
Есть еще модуль is-odd, который и сейчас есть в npm. Этот модуль определяет четное число или нет.
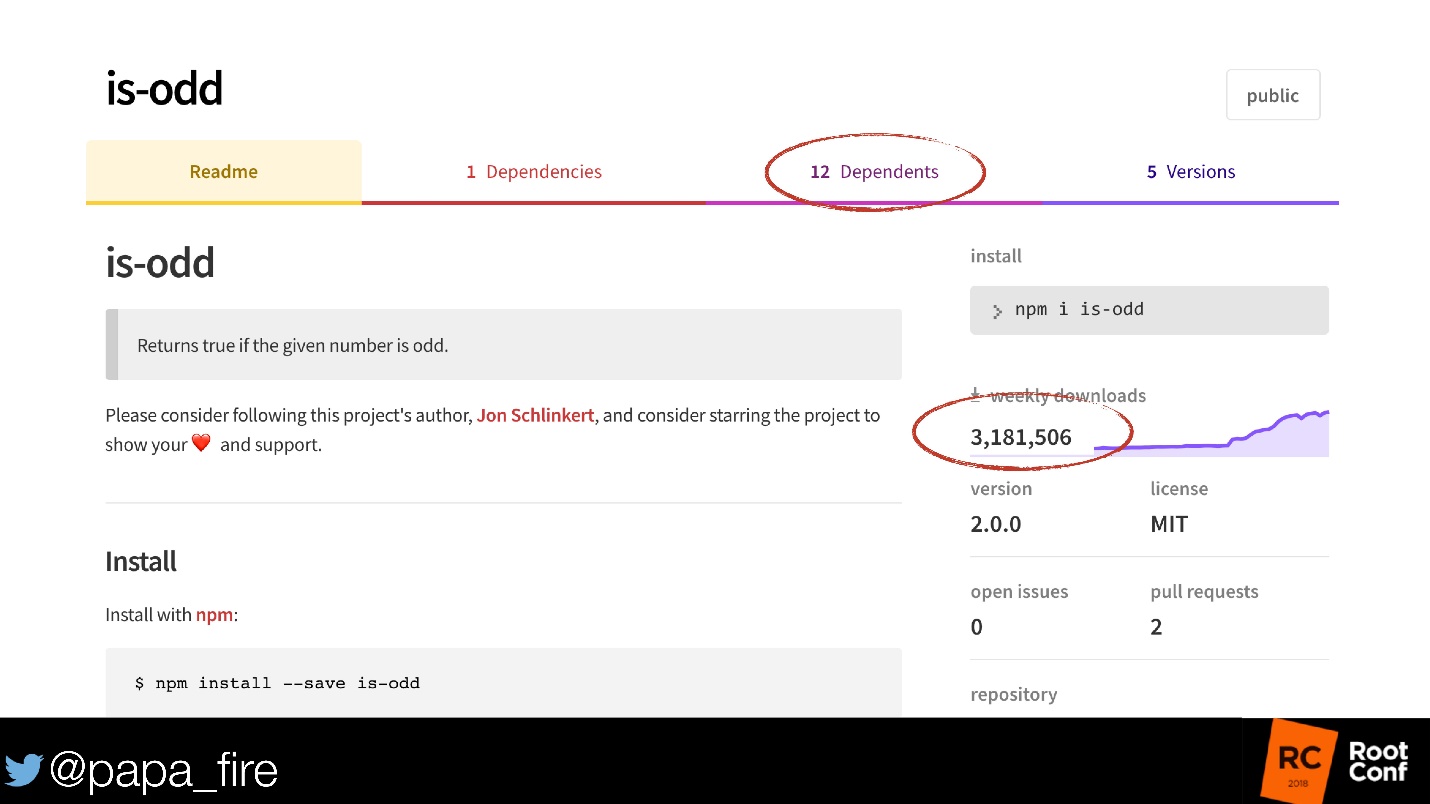
Не будем обсуждать то, что 3 миллиона людей не знают, как проверять четность/нечетность. Но там еще 12 модулей, которые его используют! И неизвестно, сколько этих модулей используют еще модули. Если вам кажется, что в нем нечему ломаться — там 5 версий!
Возвращаясь к нашим баранам — есть еще много вариантов:
- Недальновидность — мы не знаем, что будет в будущем. Y2K — это идеальный пример. Никто просто не подумал, что в 2000 году полетит все написанное в Коболе.
- Количество вариантов тестирования.
Есть хороший пример снова с World of Warcraft — у них много хороших примеров на эту тему.
Спустя полгода после выхода игры, в поддержку начали приходить обращения, что в одну пещеру не могут зайти некоторые игроки. Обнаружилось, что только один вариант расы и пола не мог войти в эту пещеру — это были таурены женского пола.
Почему потребовалось 6 месяцев, чтобы найти эту ошибку — ведь играют миллионы людей? Потому, что таурены — это вымышленная раса, смесь человека и быка. Таурен-женщина — это говорящая корова. Никто не хотел играть коровой, поэтому за 6 месяц ни один человек не дошел до максимального уровня, чтобы зайти в пещеру и найти этот баг. Соответственно, никто его не протестировал.
- Изменение в исходных данных. Мы действительно не знаем, что будет происходить завтра.
В любом случае тестов мало не бывает. Но тесты не дают 100% покрытия. Поэтому тестирование не дает гарантию успеха. Это постепенно подводит нас ко второй части — Ops. Для эксплуатации успех — это мониторинг.
Мониторинг
Есть много причин, зачем нужен мониторинг:
- совершенного кода не существует;
- системы становятся сложнее;
- растущая внешняя зависимость;
- упреждение → реагирование;
- …
Мониторинг нужен потому, что все меняется. Это основная причина. Причем именно в production, там все меняется постоянно, и нам нужно это обнаруживать.
Что должен покрыть мониторинг? — Все! Это короткий ответ, но он должен покрыть все.

Это все немного абстрактно. На самом деле, у нас всех есть чек-лист, что мы мониторим:
- инфраструктуру;
- базы данных;
- приложения;
- точки интеграции;
- время обработки запросов;
- нагрузку;
- …
Там может быть миллион вещей. Многие собирают сотни, тысячи и десятки тысяч метрик на своих системах.
Мы соберем очень много метрик для вот этого:
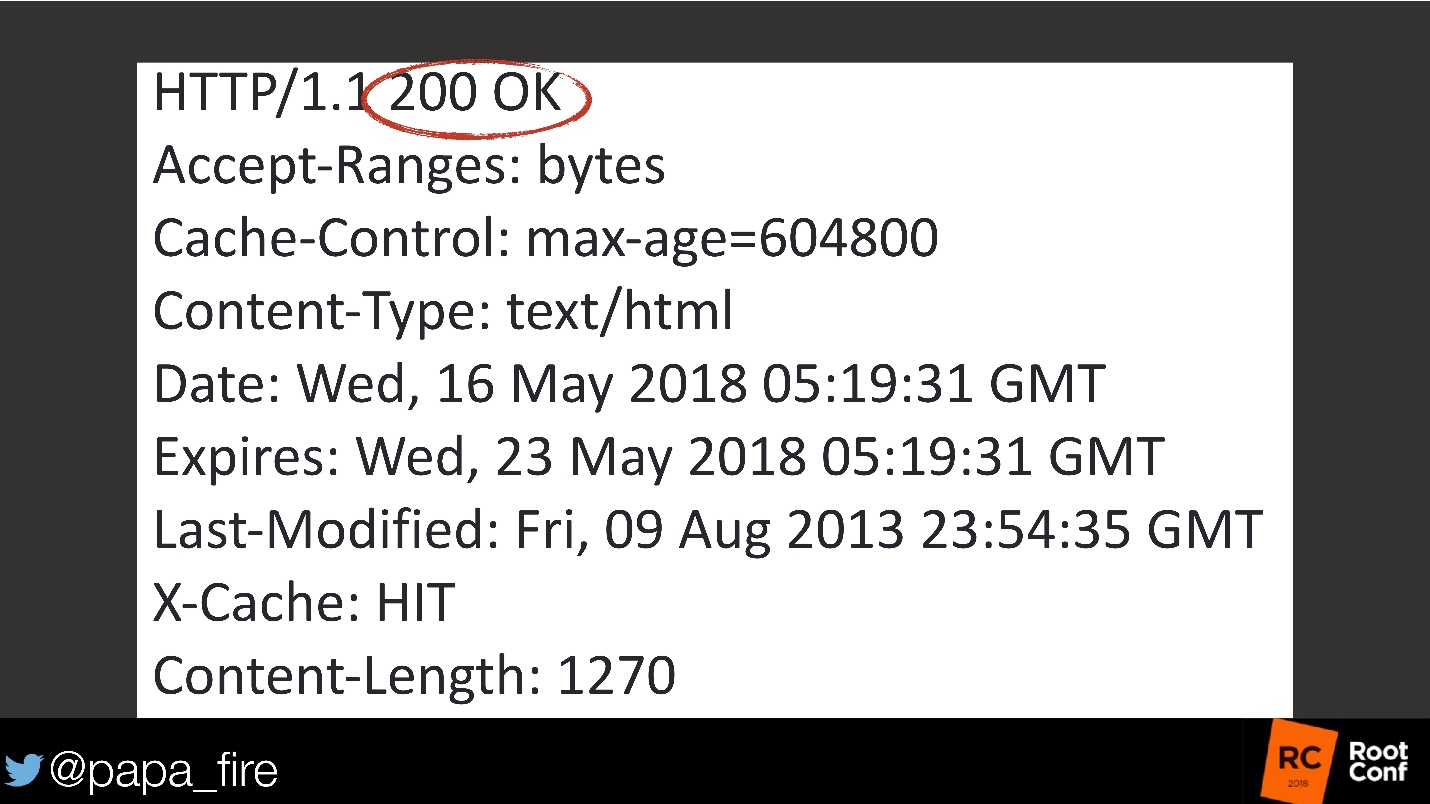
Конечно, я утрирую, но все, что нам нужно с точки зрения Ops — это чтобы HTTP вернуло 200. Это значит, что с сайтом все хорошо. Раз сайт работает, значит, базы данных работают, приложения работают — все в порядке. С точки зрения Ops успех — это именно это: все графики в зеленой зоне, все работает правильно — все хорошо!

Все знают, что такое Twitter. Они обрабатывают 500 миллионов твитов в день —сумасшедшая цифра.

Но они также известны своими ошибками. Ошибки легендарные по своей сложности или легкости — с какой стороны посмотреть.
У них была ошибка: сайт работал, клиент мог написать твит, нажать кнопочку, ему говорили спасибо, твит отсылался — и все! Он нигде не появлялся и просто пропадал, а мониторинг показывал, что все в порядке. Сайт возвращает на запрос 200 — API работает. А твитов нет!
У меня есть любимая цитата одного заказчика. Я в течение часа на трех экранах чинил проблемы, а он орал, почему ничего не работает. Когда я пытался объяснить, какие проблемы я чиню, человек, который печатал двумя пальцами и не понимал, как пользоваться компьютером, мне сказал:
«Пока я продолжаю делать деньги, мне по***, что сервера горят».
В чем-то это очень правильно, и пример Твиттера это подтверждает: все метрики показывали, что все было в порядке с точки зрения разработчиков, но с точки зрения работы именно бизнеса — совсем не в порядке.
Если честно, виноваты в этом мы все. Конечно, в основном виноваты компании, которые выпускают продукты для мониторинга. Но мы тоже, потому что традиционно мы собираем системные метрики. Мы привыкли работать с маленькими системами — один, может быть, два сервера. Если они работают, значит, все в порядке.
Теперь серверов у нас чуть-чуть больше, чем два, или даже 10, и просто измерять здоровье системы или здоровье программы — мало. Мы должны отслеживать работу чего-то другого.
Возвращаясь к цитате — мне платят не за то, чтобы все было зеленым. Мне платят за то, чтобы мои пользователи или мои менеджеры были довольны — кто-то должен быть доволен результатом. Если все пользователи недовольны, никого это не волнует, что все зеленое.
Бизнес-мониторинг
Мы говорили, что мониторинг нужен, потому что все меняется. Но когда все меняется, изменения влияют на бизнес: что-то поломалось — перестали приходить деньги, что-то починилось — деньги начали опять идти — прямая корреляция. Или не влияют — но, если мы не мониторим бизнес, мы этого не знаем.
Как живой пример — график чтения кэша, знакомый всем.
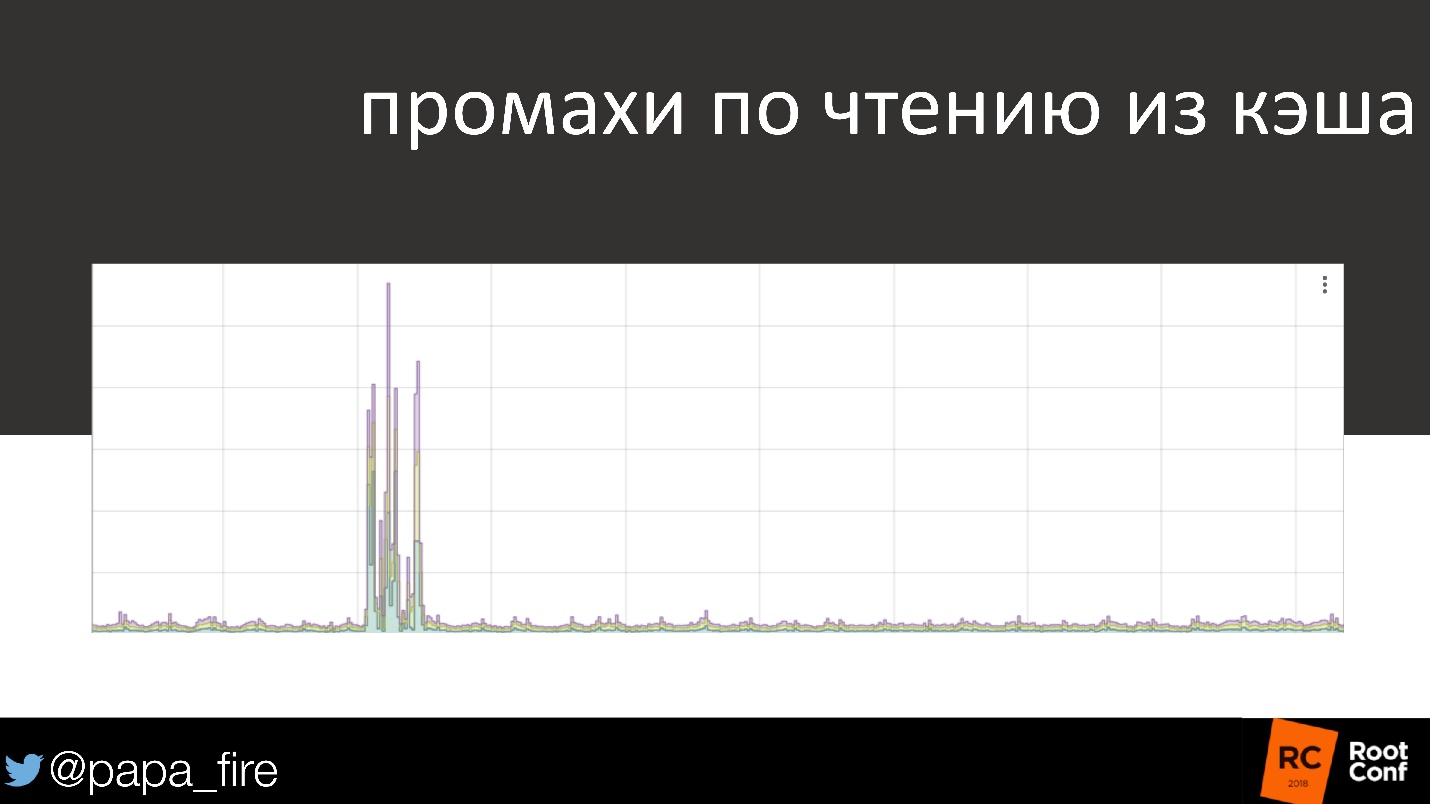
90% времени все в порядке, почти все запросы идут в кэш. И вдруг что-то случилось — причем очень серьезное. Это проблема, которая должна разбудить в 3 часа ночи кого-то, кто ее решит. Но, если скорость загрузки для пользователей не меняется, действительно ли это проблема?
В английском есть термин Observability — наблюдаемость. Это: monitoring, logging, alerting. Поэтому термин мониторинг немного. Мы хотим наблюдать за всем — собирать системные метрики на каждом узле, если нужно. Но мониторить мы хотим именно бизнес, потому что он волнует всех. Это показатель успеха.
Чтобы это сделать, мы должны:
1. Понять проблему — что именно нам нужно мониторить.
2. Определить базовую линию — то есть достаточно ли того, что скорость загрузки у пользователя не изменилась для того, чтобы никто не просыпался посреди ночи, когда чтение из кэша перестало работать.
3. Коррелировать данные — один из самых важных факторов. Если маркетинг собирает данные по доходу, а вы собираете данные по серверам и не можете сопоставить эти два наблюдения, то в них очень мало смысла.
Обычно я привожу очень много примеров. Насколько абсурдными они бы не выглядели, они все из моей жизни, и я на них потратил очень много нервов.
Пример: у меня был клиент со 100 млн пользователей. Это была интернет-маркетинговая компания, которая отправляла много e-mail и использовала A/B тестирование. Для них мы собирали 6 тысяч метрик.
Все, как всегда, началось со звонка. Звонит телефон — значит, что-то случилось.
— У нас проблемы. Что-то не работает.
— ОК, что именно не работает? В чем это выражается?
— Мы стали получать меньше дохода.
— И?
— Что-то не работает в системе.
— Не понял. Если меньше доход — поговори со своим отделом продаж. Зачем ты звонишь мне?
— Нет, я уверен, что это что-то в системе не работает!
— Хорошо, давай посмотрим.
Слава Богу, у нас была метрика дохода, поэтому мы могли посмотреть. На графике действительно видно, что в какой-то момент доходы у них упали на 15%. Учитывая количество пользователей, это довольно существенно.
Ладно, надо посмотреть. Первым делом проверяю скорость загрузки — нормальная.
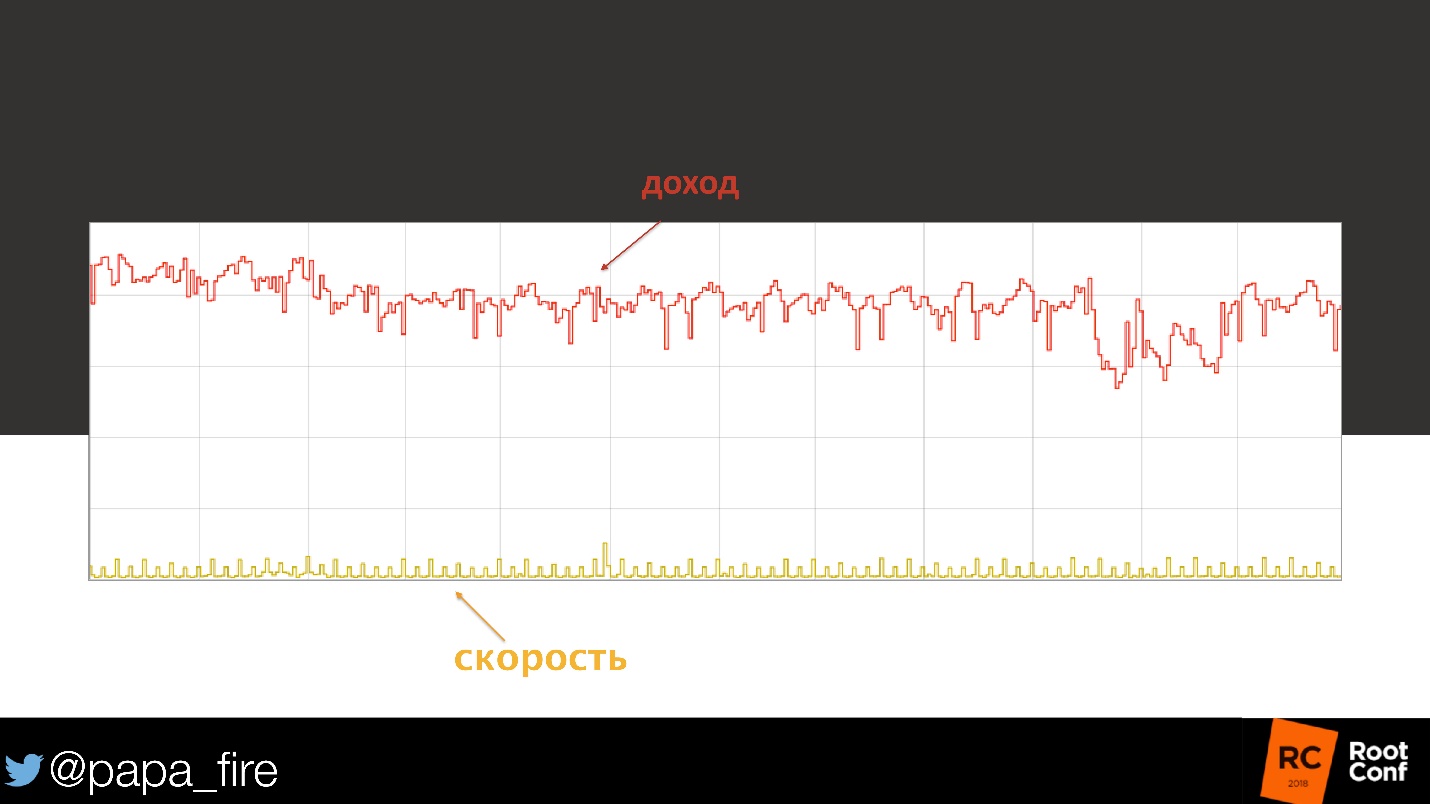
Посмотрели на нагрузку на базу данных — все в разумных пределах, вроде бы ничего не изменилось. Дальше мы начали смотреть на cpu-нагрузку, на отдельные узлы, на кэши.
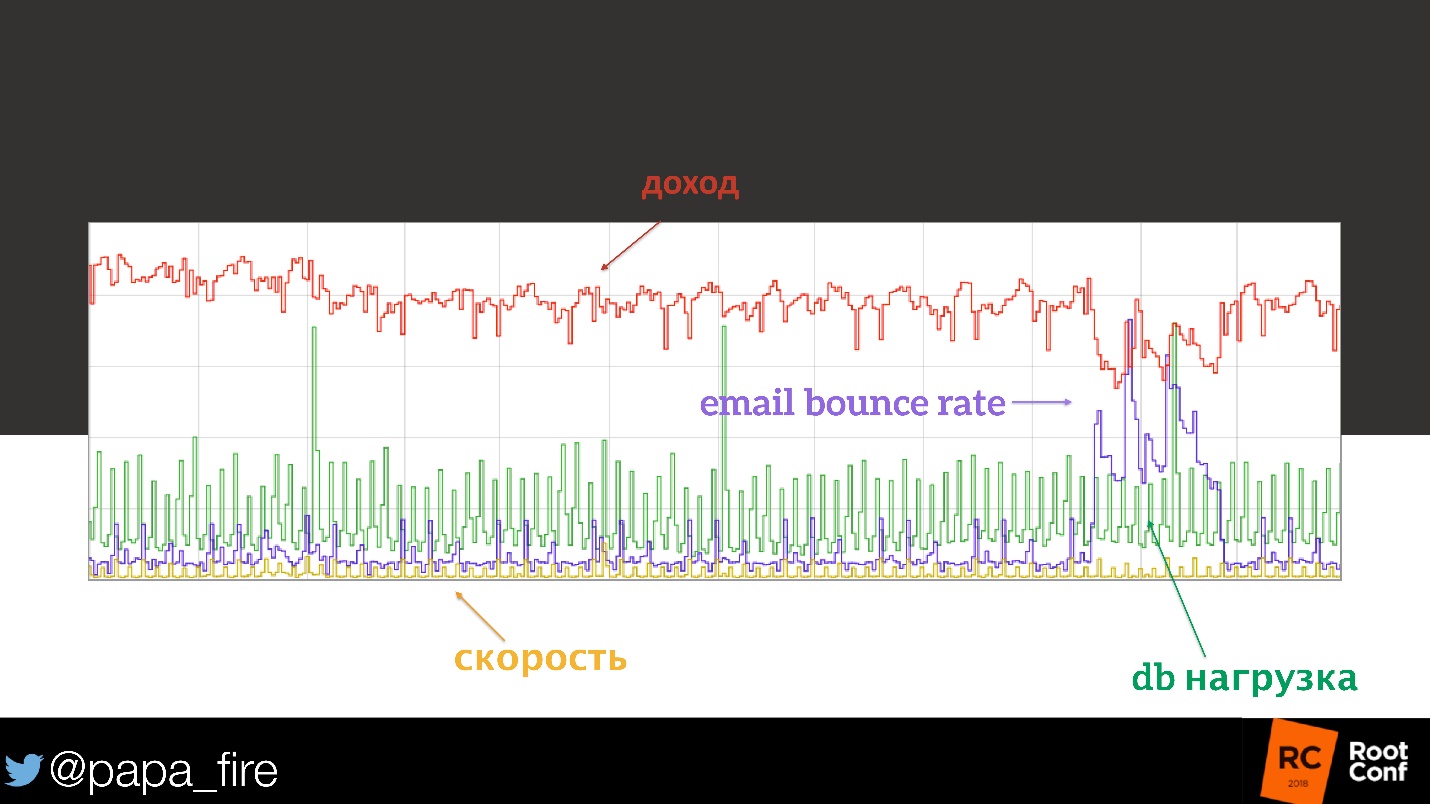
Все было в порядке., пока мы не дошли до метрик e-mail рассылки. Один из больших провайдеров случайно поставил их домен в black-list. Процент их e-mail маркетинга перестал доходить до пользователей, что означает, что меньше людей: получили письма, нажали на кнопочку, зашли на сайт и что-то купили.
Вот такая корреляция!
Нам повезло, что у нас были эти метрики. Если бы у нас их не было, мы бы их добавили — это очень простой ответ.
Самая большая ошибка, которую люди делают — это считают, что мониторинг можно поставить в конце проекта. Это как фича: сделать свой проект, поставить мониторинг — и все, мы готовы!
Инструментовка никогда не может быть закончена. Всегда находятся проблемы, о которых неизвестно с самого начала. Как и с тестированием — нельзя написать тесты и покрыть все, потому что ты не знаешь, что такое «все». Мы не умеем предсказывать будущее и не умеем предсказывать бизнес, поэтому мы не знаем, что такое «все».
Абсолютно идентичный пример тому, о чем я говорю. Это был CEO, который на конференции в Париже проснулся утром, выпил кофе, просмотрел свою почту и отчет о доходах, и позвонил мне с той же проблемой: доход упал.
Я это хорошо помню, потому что у него было 9 утра, а у меня на 6 часов раньше, еще и в субботу. Меня только что транспортировали домой с празднования дня рождения —, но это не важно. Так вот, в 3 утра я сажусь за компьютер, и мы начинаем идти теми же шагами. То есть смотрим на нагрузку на систему, на номер регистрации, на все.
Единственное отклонение от нормы, которое мы нашли, — это ниже процент успешных авторизаций. То есть количество такое же, а процент чуть-чуть ниже. Я знаю, что это может быть спам и т.д. Но все остальные технические метрики абсолютно в норме. Причем мы дошли до того, что уже чуть ли не по строкам в базе данных шли и пытались свериться — есть ли что-то, что можно глазом поймать. Абсолютно ничего!
Просидели мы полвоскресенья, в понедельник тоже продолжили, но уже были уверенны, что проблема не техническая. Пусть сами ее решают. И вот в понедельник я сижу на работе и мне звонит сотрудник из их бухгалтерии:
— Слушай, можешь быстренько мне помочь?
— Что нужно?
— Можешь снять значок «American Express» с сайта?
— Конечно могу! А чего вдруг?
— Знаешь, мы здесь с ними спорим, и пока мы не принимаем American
Express вообще.— Извиняюсь спросить, а когда вы перестали их принимать?
— Перед выходными, по-моему — в пятницу или в субботу.
Ни один человек в здравом уме никогда бы не поставил сбор метрики на процент авторизаций с определенного вида кредитной карточки! После этого случая мы, конечно, поставили.
К чему я это рассказываю? Надо сначала смотреть на бизнес, потому что все эти системные проблемы были просто невидимы. Они никого не будили посреди ночи, мы не видели, что это проблемы. Легко заметить падение дохода, а все остальное нужно отслеживать, чтобы можно было коррелировать эти данные с данными бизнеса.
Успех для бизнеса
Для бизнеса успех может быть разным, он зависит от целей. Самое важное — как это можно измерить? Традиционно мы измеряем системные показатели, иногда, как инженеры, забывая, что измерить можно все, что угодно.
Например, можно измерить собственный алкоголизм. Кстати, я не шучу. У нас в офисе стоит бочковое пиво с четырьмя краниками. Так как мы все инженеры, мой коллега решил на поставить сенсоры Raspberry Pi, чтобы посмотреть, сколько пива мы пьем и какого.

Это выглядит как простая шутка, но на самом деле это удобно, потому что мы видим, когда пиво подходит к концу и надо заменить бочку. И вообще мы можем посмотреть, когда народ пьет, какое ему больше нравится пиво — темное, светлое и т.д. Кстати, пик — это мой день рождения.
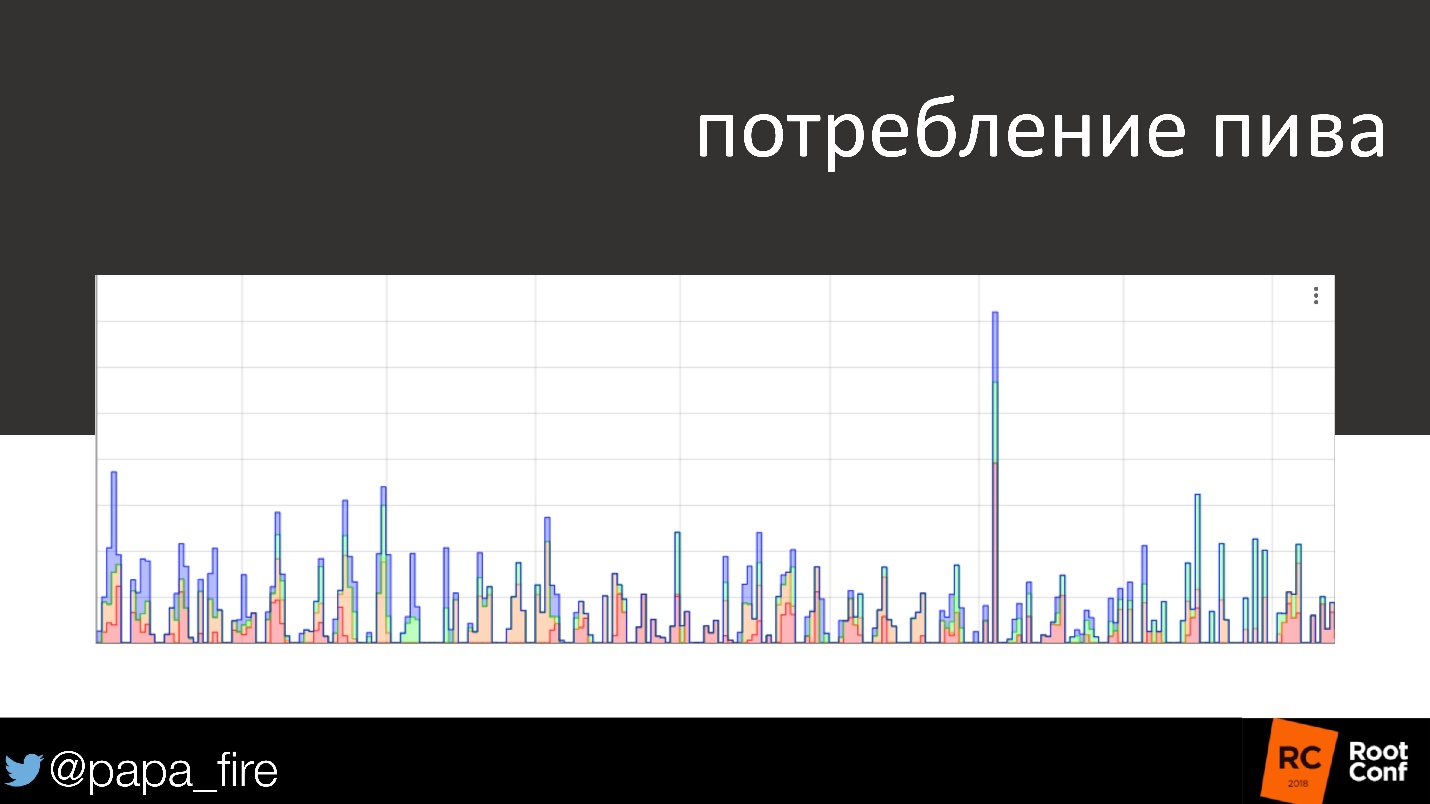
Абсолютно случайно мы нашли еще одно применение этому.
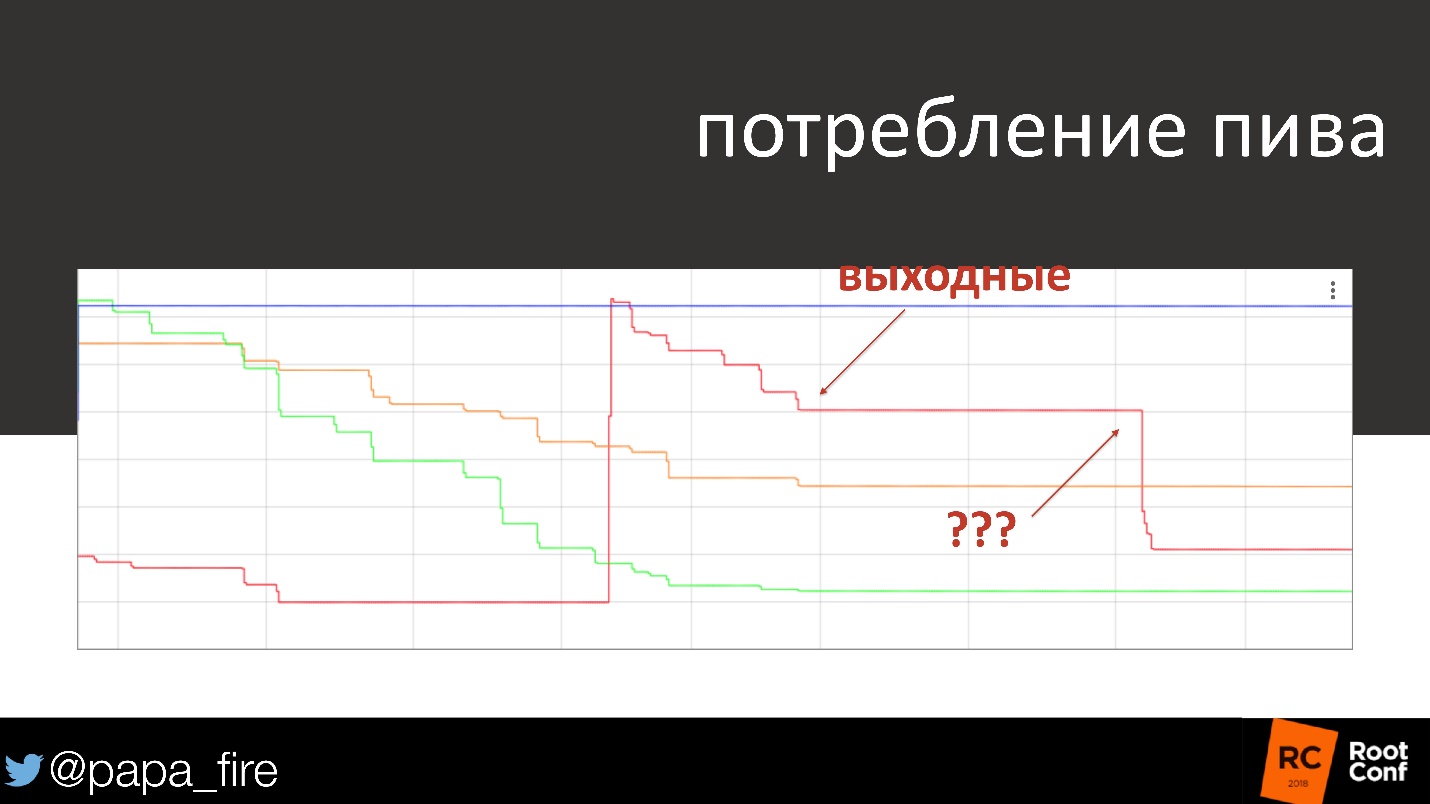
На графике потребление пива за несколько дней и в выходные. К выходным потребление алкоголя обычно уменьшается, практически сходит на нет. Однажды мы приходим в понедельник, смотрим на график и видим, что кто-то в субботу выпил четверть бочки пива. На графике видно точное время в пределах получаса. Оказалось, что уборщикам, которые приходили в субботу, надо было похмелиться, вот они и похмелялись.
Шутка шуткой, но в конце концов у них были серьезные проблемы, потому что вообще плохо пить на работе, да еще и чужое пиво!
В конце концов любые метрики могут быть полезными. Даже эта метрика, которую мы собирали чисто для собственного фана, оказалась важной в чем-то другом. Но в основном действительно нужные метрики сводятся к деньгам. Деньги для бизнеса важнее всего.
Обычно критерии успеха бизнеса — это что-то, что в конечном итоге связано с деньгами:
- прибыль;
- доход;
- затраты;
- эффективность.
Бизнес метрики:
- регистрации;
- покупки;
- просмотры рекламы;
- конвертации;
- процент возвратов;
- количество выпитого пива
Все это имеет денежный эквивалент. Кстати, скорее все, все эти метрики уже собираются в вашей компании — либо продажами, либо маркетингом. Так что не нужно придумывать колесо, можно просто взять уже имеющиеся метрики в собственную систему.
Все должно рассматриваться в контексте бизнеса. Мы говорили про специальные метрики для бизнеса. Другие, именно технические метрики, тоже могут рассматриваться в этом контексте.
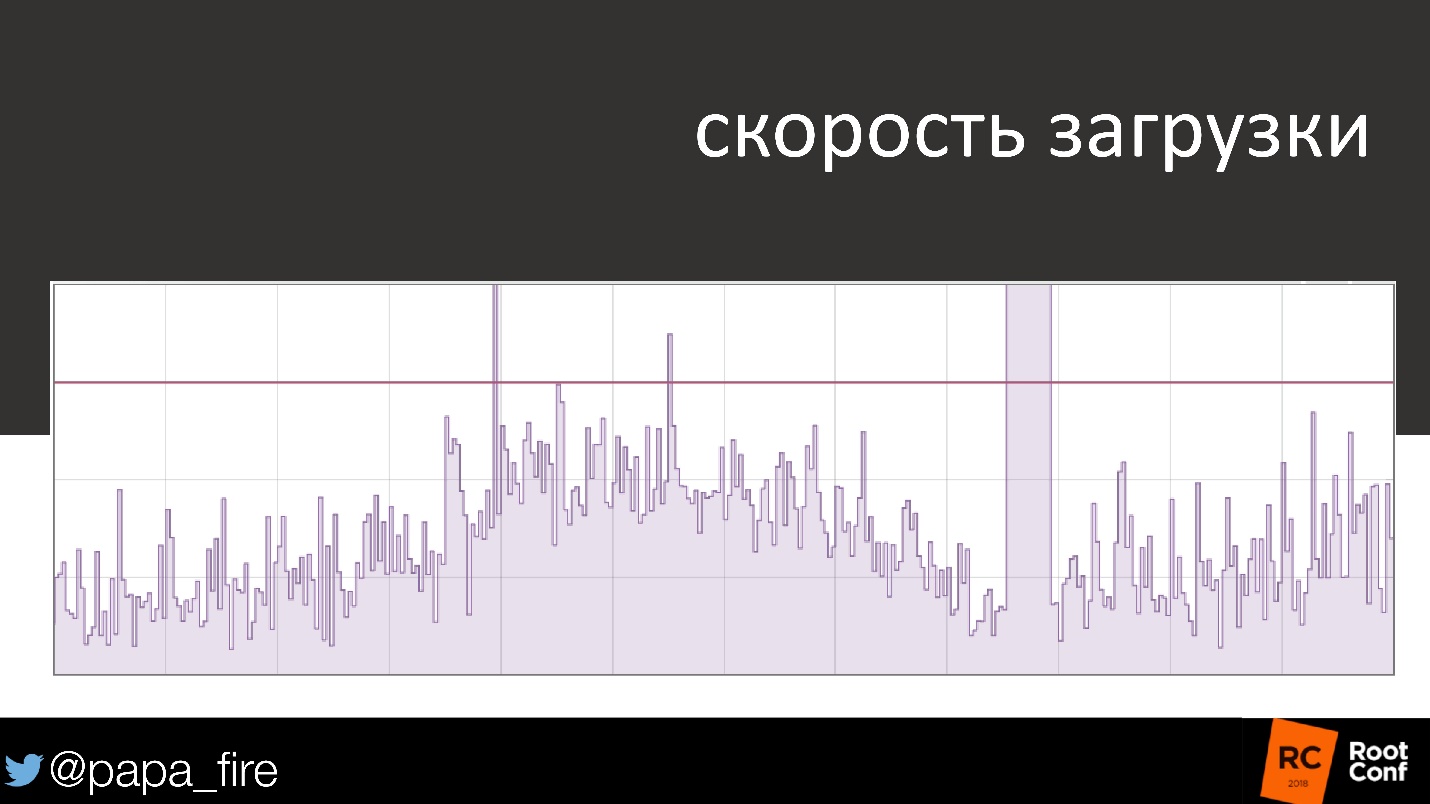
Например, скорость загрузки —довольно стандартный график. Сначала все в порядке, идет вверх — вниз, вверх — вниз, и вдруг явная проблема. Ее починили, и график вернулся к стандартному виду — 99-й процентиль ниже порога, SLA не нарушается.
Если взять тот же график и посмотреть на количество пользователей, которые были затронуты, проблема сразу смотрится по-другому.
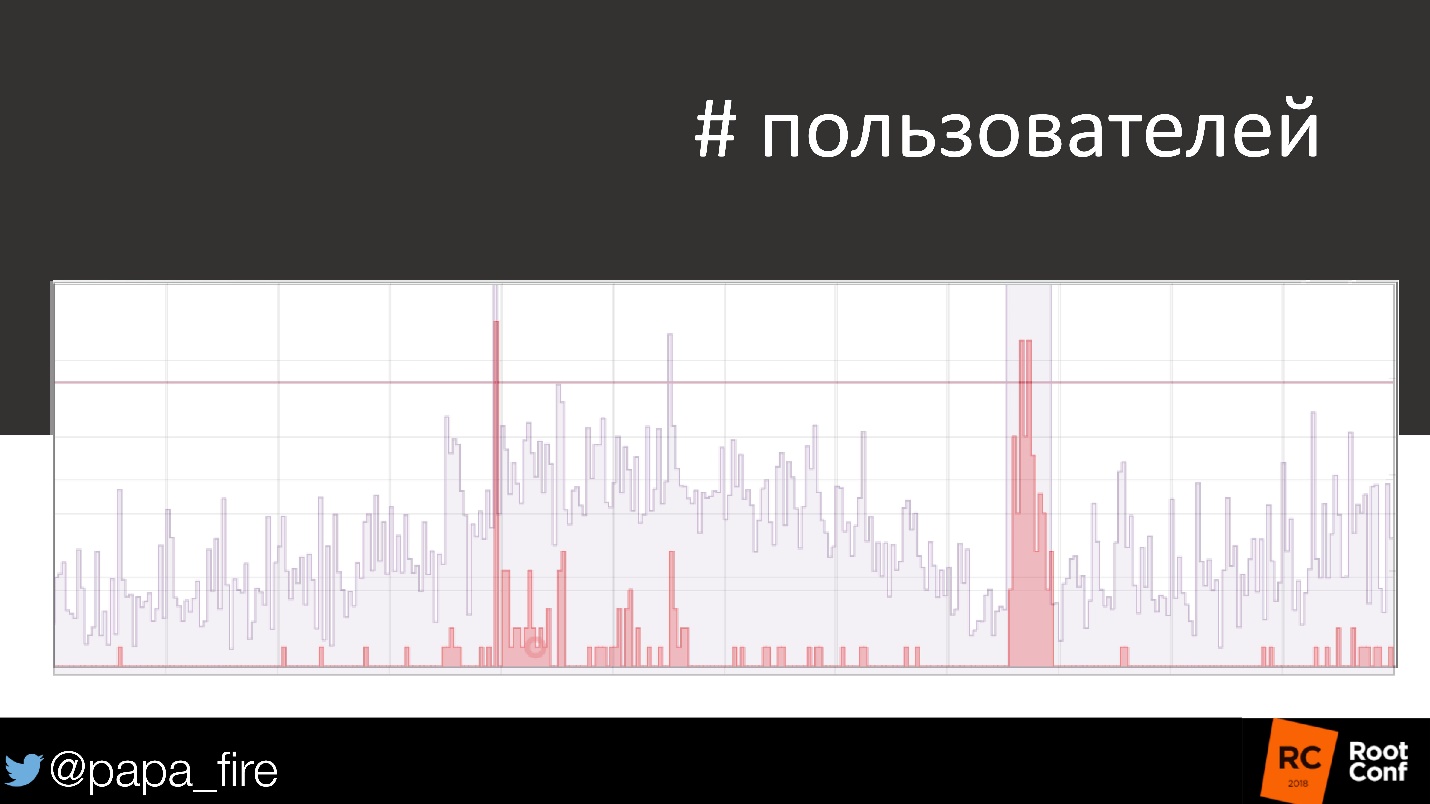
Эти пользователи не потратили деньги, то есть принесли убытки. Более того, когда никакие алерты не пришли и считалось, что все в порядке, тоже были проблемы. Здесь это видно гораздо лучше, чем на графиках системных метрик.
Каждый пользователь важен. Мы это забываем, потому что мы смотрим на среднее количество на интервале времени. Но каждый пользователь несет определенную ценность. Маркетинг об этом очень хорошо знает. Сумму, которую каждый пользователь потратит в следующие 3 месяца, маркетологи очень хорошо знают.
Среднее величина — это зло. Не то чтобы она не нужна, она дает нам информацию, которая действительно необходима, когда мы пытаемся найти проблему, но как измерения ее недостаточно.
На графике средняя скорость загрузки.
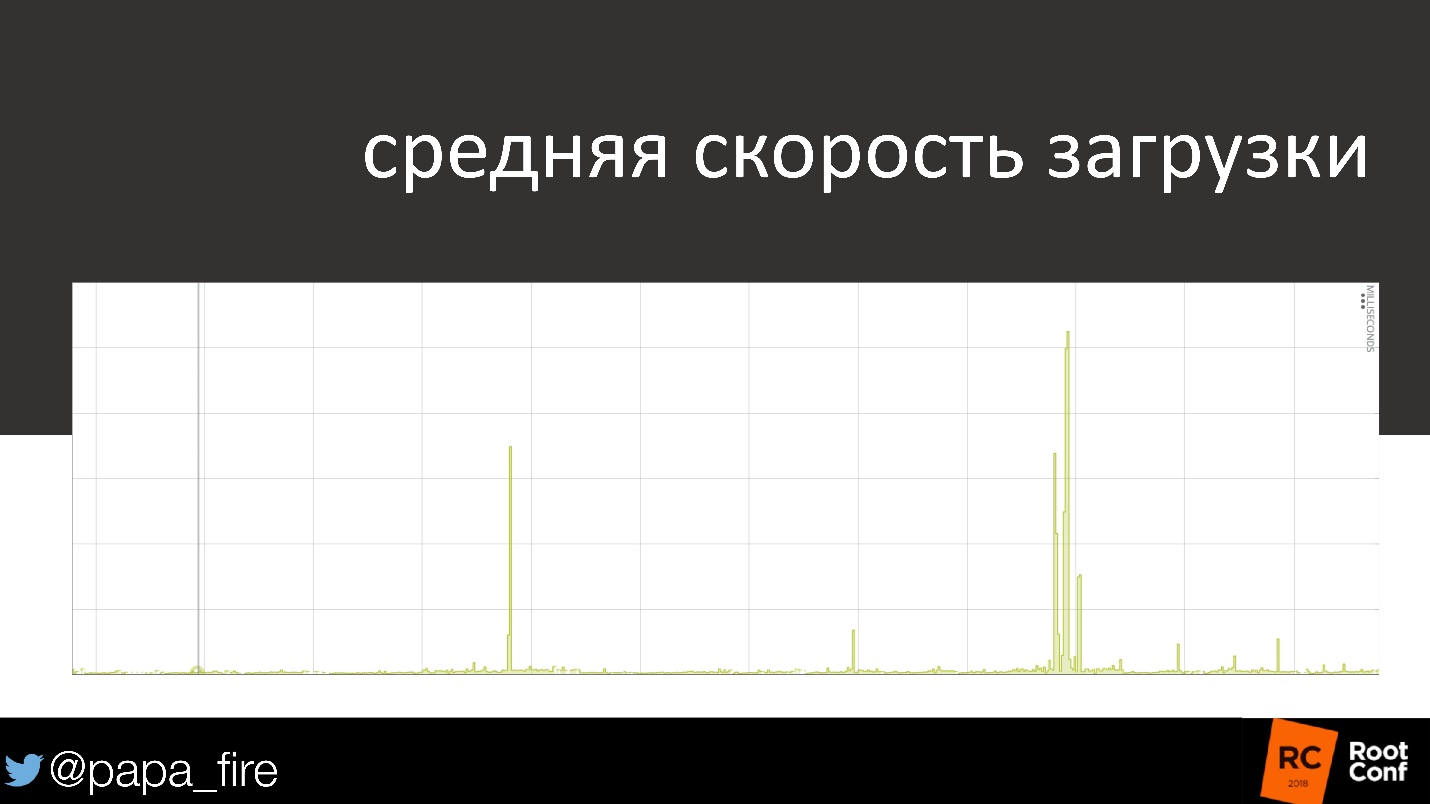
Опять все стандартно: сначала все в порядке, потом маленькая проблема, и дальше серьезная проблема, которую кто-то решал.
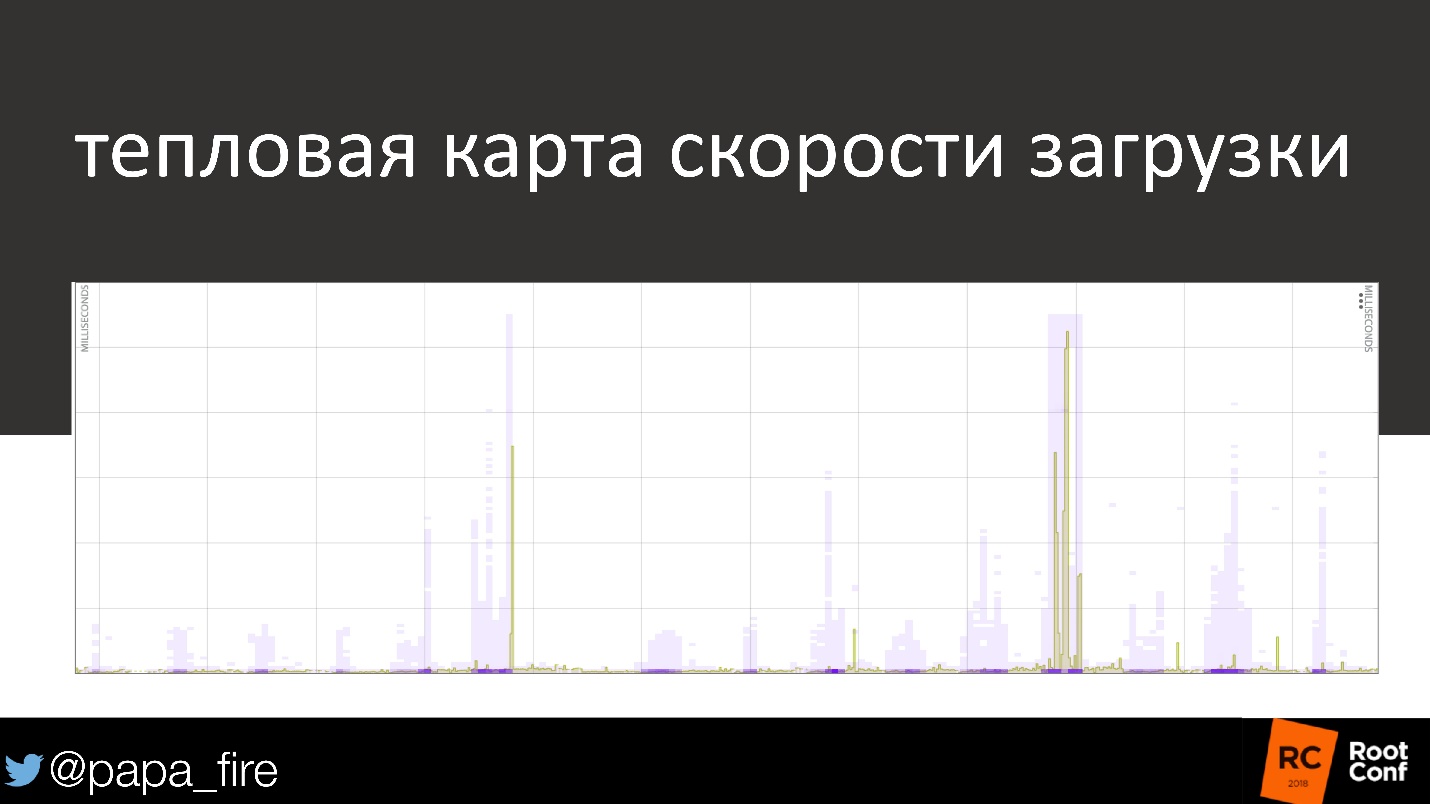
Это тепловая карта, которая касается индивидуальных пользователей в каждую секунду. Там, где график средней скорости загрузки показывает, что все в порядке, 50% пользователей действительно попадают в категорию «все в порядке», но у остальных загрузка либо медленнее, либо вообще не происходит.
Насколько ценна 1 секунда?
Сейчас мало систем с 1–2 запросами в секунду. Мы работаем в системах десятки тысяч запросов в секунду. Там есть 10 000 разных вариантов, что может пойти не так. Скорее всего, это 10 000 разных пользователей, которые могут быть как-то затронуты.
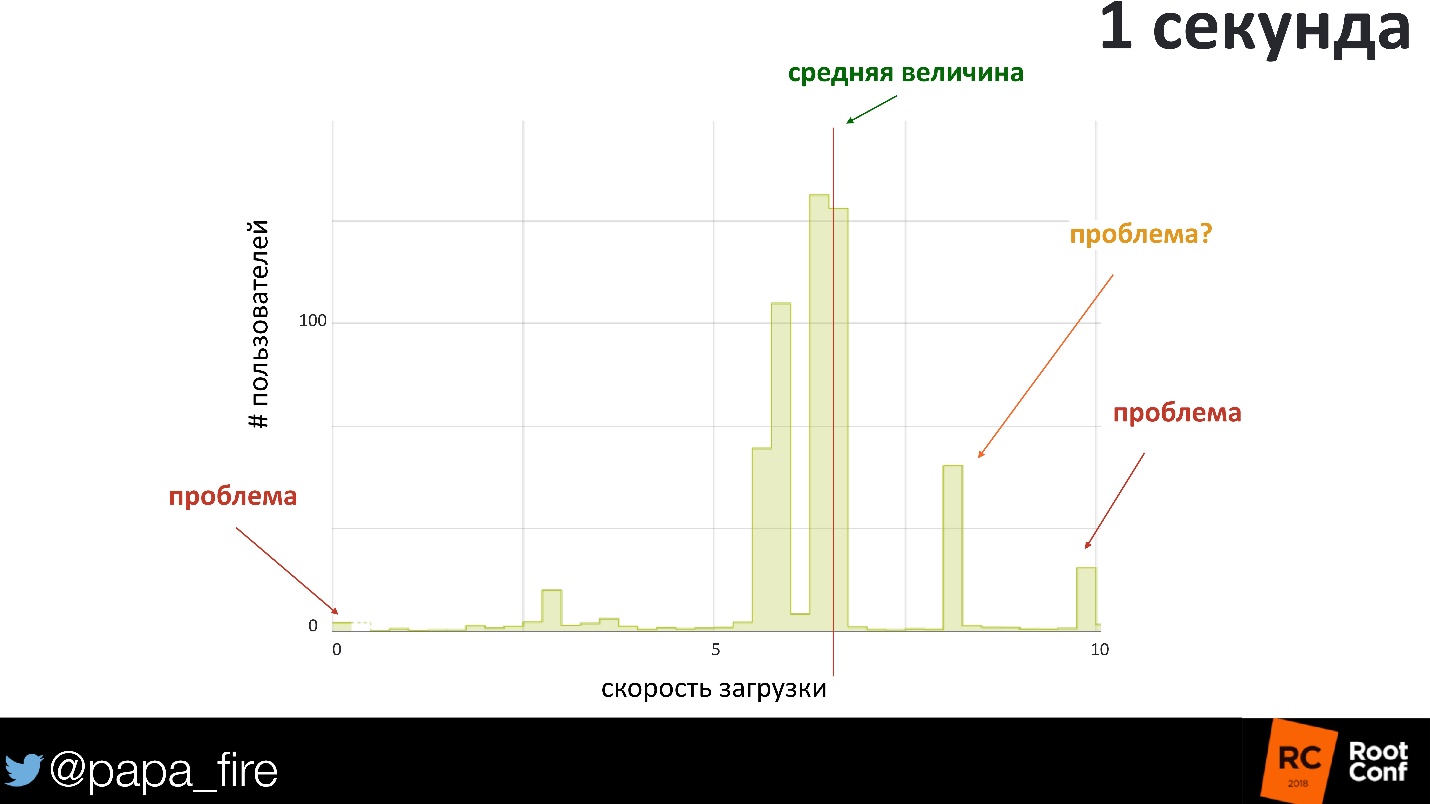
Построим распределение скорости ответа на 1 секунду. Загрузка страницы для каждого пользователя в среднем занимает 600–700 мс. Конечно, 600 мс — это не самое лучшее время, но вроде бы в разумных пределах. Но если посмотреть детально, то видны пользователи, у которых загрузка заняла больше секунды. Уже с 800 мс начинается область, где можно терять деньги, потому что пользователи будут просто уходить — грузится слишком медленно.
Интересно, что проблема может быть и там, где время загрузки близко к нулю. Если ответ вернулся за 0 секунд, явно что-то пошло не так, совсем не так! Но по среднему никакие алерты не пойдут.
Каждый пользователь важен, поскольку несет какую-то сумму. Гистограммы и тепловые карты — это самый лучший способ отследить картину, поскольку они показывают разброс индивидуальных пользователей и как он соотносятся с метрикой.
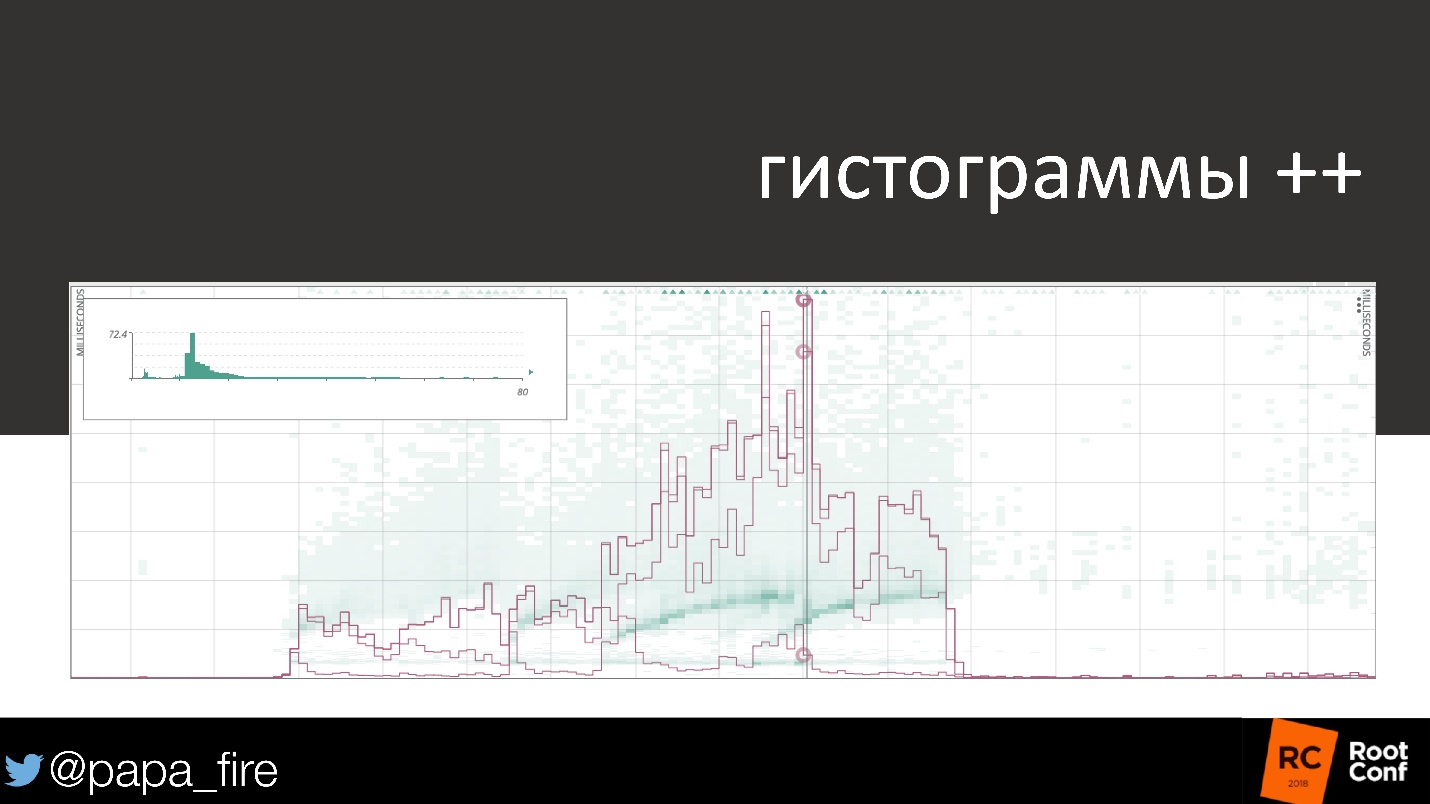
На этой карте показаны 99-й и 50-й процентили, среднее и разброс индивидуальных пользователей. Можно посмотреть, насколько они отличаются друг от друга.
Еще один момент, о котором хотелось бы поговорить — это то, о чем говорят в DevOps в последнее время — это измерение эффективности процесса.
Эффективность процесса
В каждом процессе есть много маленьких процессов, в каждой компании есть разные процессы, и каждый этап этих процессов может быть оптимизирован.
Value stream mapping — это разбиение процесса на составляющие и оптимизация индивидуальных шагов. Берешь весь процесс и записываешь, что именно происходит пошагово. Например, кто должен поставить галочку, где работал автоматический тест, сколько он занимает, что случается после этого, какой процент ошибок. После этого смотришь, где лучше всего оптимизировать этот процесс, чтобы увеличить доходы.
Есть четыре основные метрики:
- MTTD (mean time to discovery) — сколько в среднем нужно времени, чтобы найти ошибку.
- MTTR (mean time to recovery) — сколько в среднем нужно времени, чтобы исправить ошибку.
- Время от начала процесса до момента, когда результат приходит в руки пользователя.
- Время/ресурсы каждого шага.
На паре своих проектов, я вычислял, сколько денег компания делает в час, и потом из этого экстраполировал, сколько денег приносит один пользователь. Путем нехитрых вычислений получалось: «Если просто регистрация будет не работать час — вот сколько денег потеряет компания. Не теоретических или потенциальных, а физических денег теряет компания, если регистрационная страница не работает».
Если процесс можно оптимизировать, он отнимает меньше ресурсов, стоит меньше. Это в конце концов повышает доходы компании, которые тоже нужно измерять.
Таким образом ваша работа заключается в поддержке бизнеса. Мы это иногда забываем и считаем, что наша работа — в том, чтобы написать лучше программу, сделать самую прикольную архитектуру. В конце концов все это делается для того, чтобы поддержать бизнес. Научитесь понимать бизнес.
Как понимать бизнес — это отдельный разговор, который может занять гораздо больше времени, потому что мы с ними говорим на разных языках. Но поймите, какие данные нужно собирать, что именно важно, что должно будить вас среди ночи. Потому что успех для вас — это успех для бизнеса.
1 и 2 октября в Москве состоится профессиональная конференция по интеграции процессов разработки, тестирования и эксплуатации DevOpsConf Russia.
Если вы только начинаете работать по принципам DevOps, это будет отличной возможностью посмотреть на реальные работающие примеры от старта и до успешного внедрения, и проникнуться такими идеями, как в докладе Леона. Для продвинутых специалистов, будут доклады с глубоким погружением в тему и важными подробностям, и обсуждения новинок.
Приходите и увидите, как разработка, тестирование и эксплуатация могут быть нераздельны.
