Как и зачем мы парсим XML
Большинство разработчиков рано или поздно сталкиваются с XML. Этот язык разметки настолько глубоко вошел в нашу жизнь, что сложно представить систему, в которой не используется он сам или его подмножества. Разбор XML — достаточно типовая задача, но даже в ней можно выделить несколько основных подходов. В этой статье мы хотим рассказать, зачем нам потребовалось парсить XML, какие подходы мы опробовали, а заодно продемонстрировать замеры производительности для самых популярных реализаций на C++.

О нас
Основной наш продукт — это Saby, экосистема для бизнеса, которая позволяет общаться и обмениваться электронными документами с компаниями, государственными органами и обыкновенными людьми.
XML-файлы — один из основных видов электронных документов. Именно в этом формате происходит отправка большинства отчетов в государственные органы, обмен складскими документами между контрагентами. Кроме того, внутренний документооборот в крупных компаниях зачастую тоже происходит через этот формат данных.
Еще на заре разработки мы поняли, что пользователям нужны одни и те же операции с файлами:
Просмотр — для отображения в браузере.
Печать — для любителей бумажных носителей данных.
Редактирование — для внесения изменений в удобной форме.
Проверка — для контроля данных на соответствие требованиям.
Текстовое представление XML-документов нечитаемо для обычных пользователей — бухгалтеров, менеджеров, директоров. Зато их структура отлично описывается, например, с помощью XML-схем.
Так родилась идея создать систему, которая будет предоставлять механизмы обработки формализованных электронных документов.

Такие разные взгляды пользователя на обычную счет-фактуру
Как было сказано выше, все начинается с описания.
Спецификацией мы называем описание конкретных форматов документов (НД по НДС, счет-фактура и т.д.) в нашей системе. Спецификация состоит из следующих компонентов:
Структура документа.
Печатная форма (при необходимости).
Правила проверки (при необходимости).
Форма редактирования (при необходимости).
Формализованный документ — документ, имеющий спецификацию определенного формата, что позволяет обрабатывать его автоматически.

Настройка формата документа XML. Просто и со вкусом.
Формализовать можно не только XML. Подобным образом могут быть строго описаны и другие форматы файлов (JSON, TXT и т.д.). Но в данной статье мы сосредоточимся на парсерах XML и истории их применения в наших продуктах.
История обработки XML в Saby
Общая схема обработки документов
Любая операция с документом имеет свои особенности. Но если отбросить все обертки, кэширование и прочую специфику, то все операции можно свести к следующим этапам:
Получение файла
Определение типа документа (НДС перед нами или счет-фактура)
Получение спецификации
Парсинг файла и прикладная обработка
Формирование ответа
Основное время приходится именно на парсинг файла и прикладную обработку.
Этап 1. Начало.
В то время XML-документы были небольшие, очень далеко в будущее загадывать мы не умели, поэтому было принято решение обрабатывать файлы с помощью DOM-интерфейсов. Они предоставляли все, что нам было нужно:
Если сравнить разбор XML через DOM-интерфейсы с разбором шкафа, то ты уже вытащил все вещи из шкафа, запомнил, где и что лежит, и теперь начинаешь делать с ними то, что собирался изначально.
В качестве основной библиотеки остановились на Xerces-C, предоставляющей наиболее полную поддержку стандартных API для работы с XML. Рассматривали также PugiXml, но решили, что не готовы жертвовать функционалом ради скорости обработки.
Сравнение производительности DOM-парсеров

Время

Скорость парсинга
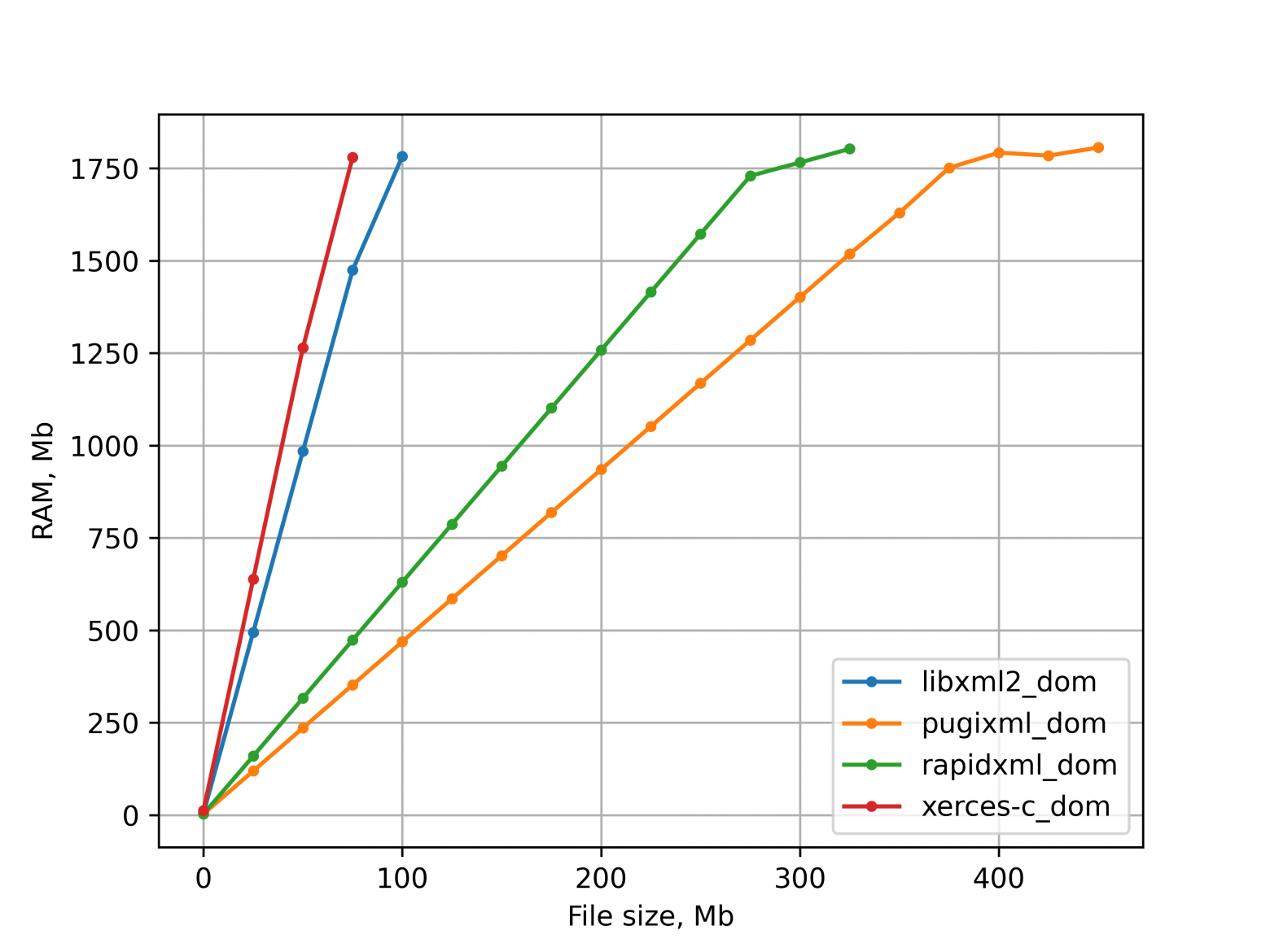
Выделение памяти
Ох, сколько же полезного функционала мы тогда реализовали:
Проверка документов с помощью XPath-выражений и собственного мнемоязыка
Упрощенное API работы с DOM-деревом для прикладного кода
API редактирования документов.
И многое-многое другое.
Если бы мы только знали, что нас ждет…
Этап 2. Поиск альтернатив.
В какой-то момент к нам пришли обеспокоенные разработчики из соседнего отдела. Налоговая запросила новый тип отчетов (Уведомление о контролируемых сделках), и наша обработка стала падать на некоторых документах, которые мы получали для тестирования. Оказалось, что пользователи стали загружать отчеты в сотни мегабайт. А они превращались в гигабайты оперативной памяти при обработке (см. графики выше). И несколько таких документов, обрабатываемых одновременно, роняли сервер!
Оперативного решения у нас не было, поэтому прикладникам пришлось сделать быструю склейку/расклейку таких отчетов на небольшие документы на своей стороне (за что им огромное спасибо). А мы ушли искать альтернативное решение, которое бы всех устроило. Наткнулись на библиотеку VTD-XML, которая по предварительным тестам неплохо подходила нам для проверки документов (произвольный доступ, поддерживает XPath, малые затраты по памяти), но лицензия GPL не позволяла использовать данное решение в наших продуктах.
Если сравнивать VTD с разбором шкафа, то ты оставил по шкафу записки, и дальше быстро ориентируешься в вещах с помощью этих записок.
Сравнение производительности VTD и DOM-парсеров

Время

Скорость парсинга

Выделение памяти
Так мы пришли к очевидному, хоть и не столь удобному для нас решению.
Этап 3. Обработка на высокой скорости.
Парсеры с последовательным доступом (событийные и потоковые) позволяют работать исключительно с текущим элементом XML-документа. Скорость обработки документов у них примерно одинаковая, при этом они не проседают по памяти в процессе парсинга. В своем решении мы решили использовать событийный SAX-парсер. Из хорошего — в Xerces-C он уже был, поэтому нам не пришлось подключать новые библиотеки. Из плохого было все остальное — ни один наш механизм не был заточен под последовательное чтение данных.
Если сравнить подобные парсеры с разбором шкафа, то ты его в первый раз видишь, и проходишь последовательно, полка за полкой, не зная, сколько же еще осталось.
Сравнение производительности DOM и парсеров с последовательным доступом

Время

Скорость парсинга

Выделение памяти
Отложив на несколько месяцев всю прочую разработку, мы занялись переводом на SAX-парсер всех существующих механизмов. Наши цели были максимально просты:
Обрабатывать документы любого размера.
По возможности — поддержать весь существующий функционал, чтобы не переписывать уже разработанные спецификации форматов документов и не переучивать прикладников.
И надо сказать, что у нас получилось!
Наши клиенты загружают, проверяют, печатают и отправляют документы в несколько гигабайт.
Где-то мы стали сами «на лету» разбивать файл и выполнять операции с меньшими документами. Где-то отказались от хранения XML вовсе. Где-то — по-прежнему обрабатываем документ целиком, работая в памяти только с нужными нам данными в процессе выполнения операций.
Мы даже частично поддержали функционал XPath-выражений в рамках потокового чтения SAX’ом, но это уже материал для отдельной статьи…
Методика измерений
Выше мы привели графики сравнения производительности различных парсеров, но не рассказали о методике измерений. Сравнение парсеров производились на одинаковых файлах. Размер файла изменялся от 1 до 1000 Мб. Сравнение производилось по следующим метрикам:
Время работы
Пиковое потребление оперативной памяти
Скорость парсинга
При помощи псевдокода эксперимент можно представить следующим образом:
for file_size in <размер файла от 1 до 1000 с шагом 25>:
# Генерируем XML-файл
for parser in <список парсеров>:
# Запускаем парсер
# Измеряем время работы и потребляемую память
# Записываем результатыВ качестве полезной нагрузки для парсера мы выбрали задачу: посчитать количество узлов и атрибутов в XML-файле. Такая постановка задачи требует прохода по всему файлу и ставит все парсеры в одинаковые условия.
Характеристики тестовой среды
Модель ноутбука: MacBook Air M1 2020
Процессор: Apple M1
OS: 13.4.1 (22F82)
RAM: 16 Gb
SSD: Apple SSD AP0256QВ сравнении принимали участие следующие библиотеки:
xerces-c 3.2.3 (DOM/SAX)
libxml2 2.9.13 (DOM/SAX)
pugixml 1.12.1
expat 2.4.7
rapidxml 1.13
vtd-xml 2.12
Исходный код парсинга
Ниже выложен код наших программ на C++.
expat_sax
#include
#include
struct XMLData
{
int nodeCount;
int attributeCount;
};
void startElement(void* data, const XML_Char* element, const XML_Char** attribute)
{
XMLData* xmlData = static_cast(data);
xmlData->nodeCount++;
for (int i = 0; attribute[i]; i += 2)
{
xmlData->attributeCount++;
}
}
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
// Открытие файла
FILE* file = fopen(args[1], "r");
if (!file)
{
std::cout << "Failed to open file: " << args[1] << std::endl;
return 1;
}
// Создание парсера Expat
const auto& parser = XML_ParserCreate(NULL);
if (!parser)
{
std::cout << "Failed to create XML parser" << std::endl;
return 1;
}
XMLData xml_data;
xml_data.nodeCount = 0;
xml_data.attributeCount = 0;
XML_SetUserData(parser, &xml_data);
// Установка обработчика начала элемента
XML_SetElementHandler(parser, startElement, nullptr);
char buffer[4096];
int bytes_read;
// Чтение и парсинг XML-файла
while ((bytes_read = fread(buffer, 1, sizeof(buffer), file)) > 0)
{
if (XML_Parse(parser, buffer, bytes_read, feof(file)) == XML_STATUS_ERROR)
{
std::cout << "XML parsing error" << std::endl;
return 1;
}
}
// Вывод результатов
std::cout << xml_data.nodeCount << std::endl;
std::cout << xml_data.attributeCount << std::endl;
// Освобождение ресурсов
XML_ParserFree(parser);
fclose(file);
return 0;
} libxml2_dom
#include
#include
#include
// Рекурсивная функция для подсчета узлов и атрибутов
void countNodesAndAttributes(xmlNode* node, int& nodes_count, int& attributes_count)
{
if (node->type == XML_ELEMENT_NODE)
{
nodes_count++;
xmlAttr* attribute = node->properties;
while(attribute)
{
attributes_count++;
attribute = attribute->next;
}
}
// Рекурсивный вызов для каждого потомка узла
for (xmlNode* child = node->children; child != nullptr; child = child->next)
{
countNodesAndAttributes(child, nodes_count, attributes_count);
}
}
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
const char *filename = args[1];
// Открытие XML файла
xmlDoc* doc = xmlReadFile(filename, nullptr, 0);
if (doc == nullptr)
{
std::cout << "Failed to parse xml file." << std::endl;
return 1;
}
xmlNode* root = xmlDocGetRootElement(doc);
int num_nodes = 0;
int attributes_count = 0;
// Вызов рекурсивной функции для подсчета узлов и атрибутов
countNodesAndAttributes(root, num_nodes, attributes_count);
std::cout << num_nodes << std::endl;
std::cout << attributes_count << std::endl;
// Освобождение ресурсов
xmlFreeDoc(doc);
xmlCleanupParser();
return 0;
} libxml2_sax
#include
#include
#include
#include
// Структура для хранения информации о количестве узлов и атрибутов
struct CountData
{
int nodeCount = 0;
int attributeCount = 0;
};
void startElementCallback(void *user_data, const xmlChar *name, const xmlChar **attrs)
{
CountData *countData = static_cast(user_data);
countData->nodeCount++;
while (NULL != attrs && NULL != attrs[0])
{
countData->attributeCount++;
attrs = &attrs[2];
}
}
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
xmlSAXHandler sh = {0};
CountData countData;
// Регистрация функции обратного вызова
sh.startElement = startElementCallback;
xmlParserCtxtPtr ctxt;
// Создание контекста
if ((ctxt = xmlCreateFileParserCtxt(args[1])) == NULL)
{
std::cout << "Failed to create XML parser context." << std::endl;
return EXIT_FAILURE;
}
ctxt->sax = &sh;
ctxt->userData = &countData;
// Парсинг документа
xmlParseDocument(ctxt);
std::cout << countData.nodeCount << std::endl;
std::cout << countData.attributeCount << std::endl;
return 0;
} pugixml_dom
#include
#include
// Функция для рекурсивного подсчета количества узлов и атрибутов
void countNodesAndAttributes(const pugi::xml_node& node, int& node_count, int& attribute_count)
{
// Увеличение счетчика узлов
node_count++;
const auto& attrs = node.attributes();
// Подсчет атрибутов
attribute_count += std::distance(attrs.begin(), attrs.end());
// Рекурсивный вызов для дочерних узлов
for (const auto& child : node.children())
{
if (child.type() == pugi::node_element)
{
countNodesAndAttributes(child, node_count, attribute_count);
}
}
};
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
pugi::xml_document doc;
const auto& result = doc.load_file(args[1]);
if (!result)
return 1;
// Получение корневого узла
const auto& root = doc.first_child();
int node_count = 0;
int attribute_count = 0;
// Вызов функции для корневого узла
countNodesAndAttributes(root, node_count, attribute_count);
std::cout << node_count << std::endl;
std::cout << attribute_count << std::endl;
return 0;
} rapidxml_dom
#include // std::cout
#include "rapidxml/rapidxml.hpp" // rapidxml::xml_document, rapidxml::xml_node
#include "rapidxml/rapidxml_utils.hpp" // rapidxml::count_attributes, rapidxml::file
// Рекурсивная функция для подсчета узлов и атрибутов
void countNodesAndAttributes(rapidxml::xml_node<>* node, int& nodes_count, int& attributes_count)
{
++nodes_count;
attributes_count += rapidxml::count_attributes(node);
for (rapidxml::xml_node<>* child = node->first_node(); child; child = child->next_sibling())
{
if (child->type() == rapidxml::node_element)
{
countNodesAndAttributes(child, nodes_count, attributes_count);
}
}
}
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
// Читаем файл
rapidxml::file<> xmlFile{args[1]};
// Парсим XML-документ
rapidxml::xml_document<> doc;
doc.parse<0>(xmlFile.data());
int node_count = 0;
int attribute_count = 0;
countNodesAndAttributes(doc.first_node(), node_count, attribute_count);
std::cout << node_count << std::endl;
std::cout << attribute_count << std::endl;
return 0;
} vtd-xml
#include
#include
#include "vtd-xml/vtdNav.h"
#include "vtd-xml/vtdGen.h"
#include "vtd-xml/autoPilot.h"
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
try
{
// Открываем XML-файл
std::ifstream xml_file(args[1]);
if (!xml_file.is_open())
{
std::cout << "Failed to open file." << std::endl;
return 1;
}
// Определяем размер файла
xml_file.seekg(0, std::ios::end);
int file_size = xml_file.tellg();
xml_file.seekg(0, std::ios::beg);
// Читаем содержимое файла
char* xml_data = new char[file_size];
xml_file.read(xml_data, file_size);
xml_file.close();
// Инициализируем VTD-XML
com_ximpleware::VTDGen vg;
vg.setDoc(xml_data, file_size);
vg.parse(true);
// Создаем VTD-навигатор
const auto& vn = vg.getNav();
com_ximpleware::AutoPilot ap(vn);
ap.selectXPath((com_ximpleware::UCSChar*) L"//*"); // Получаем все узлы
// Подсчет узлов
int node_count = 0;
int attr_count = 0;
while(ap.evalXPath() != -1)
{
node_count++;
attr_count += vn->getAttrCount();
}
std::cout << node_count << std::endl;
std::cout << attr_count << std::endl;
// Освобождаем ресурсы
delete[] xml_data;
}
catch (com_ximpleware::VTDException& e)
{
std::cerr << e.what() << ":" << e.getMessage() << endl;
}
return 0;
} xerces-c_dom
#include
#include
#include
#include
// Рекурсивная функция обхода DOM-дерева для подсчета узлов и атрибутов
void countNodesAndAttributes(const xercesc::DOMNode* node, int& numNodes, int& numAttributes)
{
if (node->getNodeType() == xercesc::DOMNode::ELEMENT_NODE)
{
// Подсчет узлов
numNodes++;
// Получение атрибутов текущего узла
const auto& attributes = node->getAttributes();
if (attributes)
{
// Подсчет атрибутов
numAttributes += attributes->getLength();
}
}
// Рекурсивный обход дочерних узлов
for (const xercesc::DOMNode* child = node->getFirstChild(); child != nullptr; child = child->getNextSibling())
{
countNodesAndAttributes(child, numNodes, numAttributes);
}
}
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
// Инициализация Xerces-C++
xercesc::XMLPlatformUtils::Initialize();
{
// Создание парсера
xercesc::XercesDOMParser parser;
parser.setDoNamespaces(false);
parser.setDoSchema(false);
parser.setValidationScheme(xercesc::XercesDOMParser::Val_Never);
try
{
// Парсинг файла
parser.parse(args[1]);
// Получение корневого элемента документа
const xercesc::DOMDocument* doc = parser.getDocument();
const xercesc::DOMElement* root = doc->getDocumentElement();
// Переменные для подсчета узлов и атрибутов
int numNodes = 0;
int numAttributes = 0;
// Вызов рекурсивной функции обхода дерева
countNodesAndAttributes(root, numNodes, numAttributes);
// Вывод результатов
std::cout << numNodes << std::endl;
std::cout << numAttributes << std::endl;
}
catch (...)
{
std::cerr << "Parsing error." << std::endl;
return 1;
}
}
// Освобождение ресурсов и завершение программы
xercesc::XMLPlatformUtils::Terminate();
return 0;
} xerces-c_sax
#include
#include
#include
#include
#include
#include
#include
using namespace xercesc_3_2;
class CounterSaxHandler : public HandlerBase
{
public:
void startElement(const XMLCh* const, AttributeList& attributes)
{
++m_nodesCount;
m_attributesCount += attributes.getLength();
}
size_t NodesCount()
{
return m_nodesCount;
}
size_t AttributesCount()
{
return m_attributesCount;
}
private:
size_t m_nodesCount = 0;
size_t m_attributesCount = 0;
};
int main(int argc, char *args[])
{
// Проверка наличия аргумента командной строки
if (argc < 2)
{
std::cerr << "You must pass the filename as an argument." << std::endl;
return 2;
}
try
{
XMLPlatformUtils::Initialize();
}
catch (const XMLException& e)
{
char* message = XMLString::transcode(e.getMessage());
std::cout << "Error during initialization! : " << message << std::endl;
XMLString::release(&message);
return 1;
}
SAXParser parser;
parser.setDoNamespaces(true); // optional
CounterSaxHandler handler;
parser.setDocumentHandler(&handler);
parser.setErrorHandler(&handler);
try
{
parser.parse(args[1]);
std::cout << handler.NodesCount() << std::endl;
std::cout << handler.AttributesCount() << std::endl;
}
catch (const XMLException& e)
{
char* message = XMLString::transcode(e.getMessage());
std::cout << "Exception message is: " << message << std::endl;
XMLString::release(&message);
return -1;
}
catch (const SAXParseException& toCatch)
{
char* message = XMLString::transcode(toCatch.getMessage());
std::cout << "Exception message is: " << message << std::endl;
XMLString::release(&message);
return -1;
}
catch (...)
{
std::cout << "Unexpected Exception." << std::endl;
return -1;
}
return 0;
} Генератор тестовых XML-файлов
Для генерации тестовых файлов мы написали скрипт на Python.
В качестве параметров задаются:
Имя файла (параметр
--file_name)Размер файла в мегабайтах (параметр
--file_size)Высота дерева (константа
HEIGHT)Длина названии узлов и атрибутов (константы
NODE_NAME_LENGTHиATTRIBUTE_NAME_LENGTHсоответственно)Количество атрибутов в узле (константа
NUM_ATTRIBUTES)Количество атрибутов в самом глубоком узле (константа
DEEPEST_LEVEL_SIZE)
Имена узлов и атрибутов генерируются случайным образом.
Сначала формируется шаблон — дерево заданной структуры. Затем этот шаблон многократно копируется до тех пор, пока не получится файл нужного размера.
Код генератора
"""Генератор тестовых XML-файлов"""
import argparse
import os
import random
import string
import xml.etree.ElementTree as ET
# Высота дерева
HEIGHT = 5
# Длины названий узлов и атрибутов
NODE_NAME_LENGTH = 5
ATTRIBUTE_NAME_LENGTH = 3
# Количество атрибутов в узле
NUM_ATTRIBUTES = 2
# Количество атрибутов в самом глубоком узле
DEEPEST_LEVEL_SIZE = 10
def random_string(length):
"""Генерация случайной строки заданной длины"""
letters = string.ascii_lowercase
return ''.join(random.choice(letters) for _ in range(length))
def generate_xml_tree(height, node_name_length, attribute_name_length, num_attributes):
"""Генерация XML-дерева"""
if height <= 0:
return None
root = ET.Element(random_string(node_name_length))
for _ in range(num_attributes):
attr_name = random_string(attribute_name_length)
attr_value = random_string(attribute_name_length)
root.set(attr_name, attr_value)
level_size = 1
if height == 2:
level_size = DEEPEST_LEVEL_SIZE
for _ in range(level_size):
child = generate_xml_tree(height - 1, node_name_length, attribute_name_length, num_attributes)
if child is not None:
root.append(child)
return root
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Fake XML generator')
# Опциональные аргументы
parser.add_argument('--file_size', type=int, default=1, help='Size of file in megabytes')
parser.add_argument('--file_name', type=str, default='output.xml', help='File name')
args = parser.parse_args()
args.file_size = args.file_size * 1024 * 1024
# Генерация шаблона xml_str
tree = generate_xml_tree(HEIGHT, NODE_NAME_LENGTH, ATTRIBUTE_NAME_LENGTH, NUM_ATTRIBUTES)
xml_tree = ET.ElementTree(tree)
ET.indent(xml_tree)
xml_str = ET.tostring(tree, encoding='utf8', xml_declaration=False).decode()
# Сохранение XML-документа в файл
with open(args.file_name, 'w', encoding='utf8') as f:
f.write('')
f.write(os.linesep)
f.write('')
while os.path.getsize(args.file_name) < args.file_size:
f.write(xml_str)
f.write(os.linesep)
f.flush()
f.write(' ')Функциональное сравнение парсеров
Скорость работы — важный показатель парсера XML, но не стоит забывать и о функциональных возможностях. Парсер может быть быстрым, но если он не сможет решить поставленную задачу, то его использование не представляется возможным. Ниже приведена таблица сравнения функциональных возможностей для парсеров, участвующих в нашем обзоре.
DOM и VTD
libxml2 | pugixml | rapidxml | vtd-xml | xerces-c | |
Поддержка пространств имен | + | - | - | только чтение | + |
Поддержка processing instruction | + | + | только чтение | только чтение | + |
Поддержка кодировок | UTF-8, UTF-16 (LE/BE), ISO-8859–1, ASCII, можно добавлять свои | UTF-8, UTF-16 (LE/BE), UTF-32 (LE/BE), ISO-8859–1, ASCII, можно добавлять свои | UTF-8 | UTF-8, UTF-16 (LE/BE), ISO-8859–1, ASCII, ISO--8859-{2–10}, Windows {1250–1258} | UTF-8, UTF-16 (LE/BE), ISO-8859–1, ASCII, UCS4BE/LE, IBM037, IBM1047, IBM1140, Windows-1252, можно добавлять свои |
Поддержка XPath | + | + | - | + | + |
Потоковые парсеры
Expat, Xerces-C и libxml2 предлагают схожий функционал, отличаясь лишь набором кодировок, которые они поддерживают по умолчанию.
libxml2 | expat | xerces-c | |
Поддержка пространств имен | + | + | + |
Поддержка processing instruction | + | + | + |
Поддержка кодировок | UTF-8, UTF-16 (LE/BE), ISO-8859–1, ASCII, можно добавлять свои | UTF-8, UTF-16 (LE/BE), ISO-8859–1, ASCII, можно добавлять свои | UTF-8, UTF-16 (LE/BE), ISO-8859–1, ASCII, UCS4BE/LE, IBM037, IBM1047, IBM1140, Windows-1252, можно добавлять свои |
Поддержка XPath | - | - | - |
Выводы
В этой статье мы поделились своим опытом и результатами замеров. Надеемся, что это поможет читателям при выборе технологий парсинга XML-документов.
Мы же в процессе изменения кодовой базы пришли к достаточно очевидным выводам относительно общих подходов к проектированию и разработке:
Используйте технологии, которые отвечают вашим текущим требованиям. Но помните, что требования могут меняться, и это стоит учитывать при проектировании архитектуры.
Чаще получайте обратную связь от заказчиков и обкатывайте свои решения на реальных данных.
Заботьтесь о безопасном внесении изменений. Пишите тесты и применяйте подходящие паттерны проектирования.
Относитесь критично к существующим решениям. В процессе внесения изменений мы нашли несколько древних ошибок в legacy-коде, о которых даже не задумывались.
