Как и почему мы переехали с собственного npm-репозитория на Verdaccio
Всем привет. Меня зовут Андрей Фримучков, я работаю в команде инфраструктуры разработки интерфейсов Яндекса. Последние два месяца участвовал в запуске нового хранилища пакетов. Около года назад мы упёрлись в ограничения собственного решения и после череды экспериментов пришли к выводу, что дальше масштабироваться под растущие нагрузки не получится.
Нужно было искать что-то новое. Выбор пал на опенсорсное решение под названием Verdaccio. Это может показаться странным, потому что им чаще пользуются небольшие компании. Скажу честно, настроить работу оптимально и внести необходимые доработки было непросто, но интересно. И стоило того. А теперь — обо всём по порядку.
Как пакеты хранились раньше?
Хорошая практика при разработке на JS — хранить внутренние пакеты в собственном репозитории и сохранять копии внешних пакетов. Это снижает зависимость от внешнего npm и позволяет ограничить выходы во внешнюю сеть в системах сборки. Исторически Яндекс использовал своё решение для хранения внутренних пакетов. Долгое время оно всех устраивало, но компания росла. Росли нагрузки, репозиторий стало сложно масштабировать и поддерживать. Например, при регламентных работах в датацентрах приходилось вручную переключать мастер у CouchDB. Схема выглядела следующим образом: 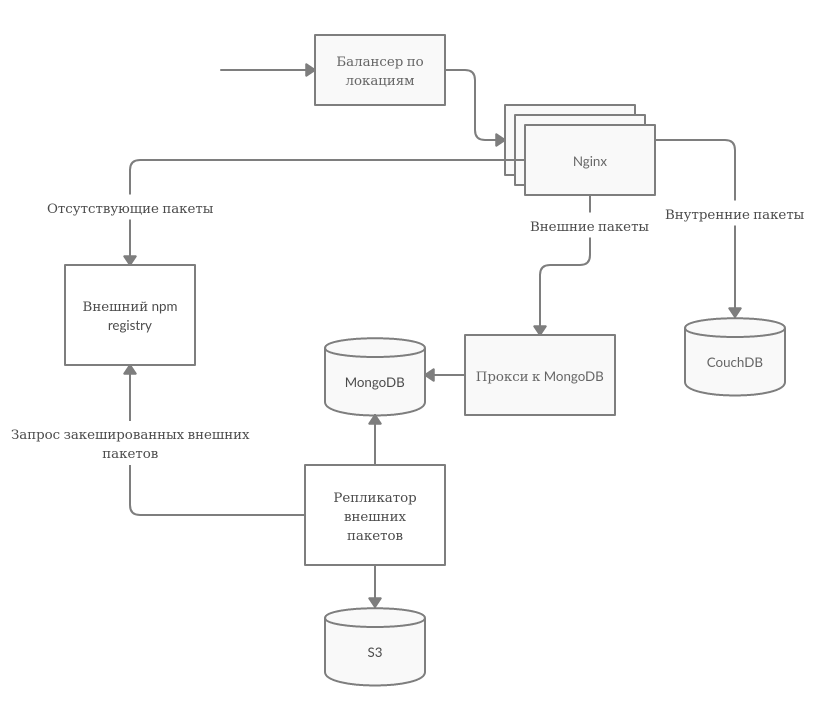
Примерно год назад стало очевидно, что если нагрузка продолжит расти, мы упрёмся в потолок. К тому же накопилась критическая масса нереализованных запросов от внутренних пользователей. Мы решили всё переписать разработать инструмент, который будет выдерживать необходимую нагрузку, легко дорабатываться и отвечать требованиям разработчиков.
Внутри Яндекса часто появляются самописные инструменты, и это в большинстве случаев оправдано. Но, наученные своим предыдущим опытом, мы выбрали другой путь: изучить, что есть в опенсорсе, и докрутить самый подходящий вариант под свои требования. После обсуждения и сравнения открытых решений остановились на Verdaccio. Несмотря на то, что этот репозиторий обычно используется при небольших нагрузках, нам понравилась система плагинов — открывались возможности для тонкой настройки и доработки под себя.
Аргументы, которые нас убедили:
- опенсорс,
- Node.js + TypeScript (за сервис отвечает команда, где трудятся в основном node.js-разработчики),
- есть возможность расширять решение плагинами,
- много звёздочек на GitHub и регулярные релизы,
- готовый плагин для S3.
Для тех, кто не знаком с Verdaccio, это — прокси для приватных пакетов. Почему прокси? Всё просто: пакеты, которые не находятся внутри, загружаются из внешнего registry. Verdaccio пользуется популярностью и уважением среди JS-разработчиков, так что подробно на нём останавливаться не будем.
Разработка плана
В мае 2020 года началась подготовка к доработке и внедрению нового продукта.
К концу июня появилось представление о том, как всё должно работать:
- Пакеты будем хранить во внутреннем S3 (да, в Яндексе есть и такое).
- Для внешних пакетов установим время жизни 5 минут, чтобы не создавать лишнюю нагрузку на внешний npm.
- Авторизация через внутренние сервисы.
Мы даже успели развернуть Verdaccio и настроили интеграцию с внутренними сервисами, но оставалось несколько вопросов:
- Как начать переводить разработчиков на новое решение?
- Как сохранить согласованность между старым и новым хранилищами?
- Как перенести данные из CouchDB в новое хранилище и ничего не потерять?
Просто перелить часть трафика с балансера нельзя, потому что у тех, кто пользуется внутренним репозиторием, начнут в случайном порядке меняться лок-файлы, а при возникновении проблем пострадают разработчики внутри всего Яндекса. Роутинг на основе имён пакетов не подходит по похожим причинам. Да, можно попросить пользователей руками прописать у себя новое решение, но тогда не получится управлять трафиком и придётся раздавать доступы к новому балансеру (в Яндексе все доступы строго определены). В итоге решили, что пользователи могут сами переключиться на Verdaccio, не меняя при этом домен, выставив нужный user-agent в .npmrc — оказалось, что так можно. Так мы сами сможем роутить пользователей, оставляя себе возможность переключить всех обратно.
Отлично, людей можно переводить, но что делать, чтобы пакеты были синхронизированы между старой и новой версиями? Первая идея самая очевидная — настроить очередь и воркера, который будет синхронизировать и отправлять пакеты, опубликованные в Verdaccio, в старый npm. Тут же возник вопрос атомарности публикации, но после долго обдумывания мы пришли к тому, что проблем не будет, если не будет публикаций в Verdaccio. То есть сначала на Verdaccio переключаются все GET-запросы, а POST-запросы — уже после них. Старый npm в этом случае используется как upstream.
Раз через Verdaccio можно получать пакеты из внутреннего npm и производить синхронизацию, а список этих пакетов легко вытащить из CouchDB, то почему бы скриптом не запросить все существующие пакеты и их тарники? Пакетов оказалось всего 2700, так что на полную первичную синхронизацию ушло два часа. Чтобы синхронизировать новые пакеты и архивы, мы решили переключить POST-запросы, вновь пробежаться по списку и запросить только тарники, созданные после первичной синхронизации. Звучит отлично, но стоит добавить, что в Verdaccio у каждого пакета есть метаданные и тарболы с самими пакетами.
Разрешив первые вопросы, начали переключать людей, ругаясь на высокое (по нашим ощущениям) потребление памяти и процессора. Это было в конце июля — на тот момент мы ещё не до конца осознавали причины такого поведения системы и считали, что это просто особенность Verdaccio.
Что-то идёт не так
Первые проблемы всплыли в начале августа, когда мы тестировали и проверяли POST-запросы. Оказалось, что наш плагин S3 для Verdaccio работает так:
- Список пакетов хранится в файле под названием verdaccio-s3-db.json.
- При запуске этот файл загружается в память.
- Он используется для поиска по пакетам и отдачи списка пакетов.
- При добавлении или удалении пакетов файл модифицируется и сохраняется в S3.
Мы поняли, что в плагине нет блокировок на публикацию, то есть, если один пакет одновременно публикуется 2 раза, результат не будет определён. Скорее всего, кто-то из пользователей получит ошибку, а это плохо. Получалось, что выбранный нами плагин не будет корректно работать, если инстансов несколько, а у нас их было уже по 32 в каждой из трёх локаций.
Выход — разработка своего плагина с блекджеком, алкоголем и централизованным хранилищем в виде PostgreSQL, разделением пакетов на внутренние и внешние на уровне базы и, что самое главное, с блокировками на публикацию пакетов через транзакции.
Первым делом пришлось разбираться, как Verdaccio работает внутри: как обращается за пакетами, что и куда сохраняет. Для этого мы провели отладку при помощи console.log при помощи средств отладки разобрались, как Verdaccio осуществляет работу с плагинами. Например, выяснили, что при синхронизации пакета с внешним registry или паблишем метаданные обновляются 3 раза. Алгоритм такой:
- Запись пустой меты — шаблона на случай, если пакета нет.
- Получение пустой меты из хранилища.
- Загрузка тарбола и запись меты с тарболом.
- Получение меты.
- Запись тегов в мету.
- Отдача ответа пользователю.
Такое поведение смущало, но на разработку не влияло. Поэтому мы продолжили работу и завершили плагин, который нас во всём устраивал, к концу августа.
Стоит отметить, что тарболы не прогонялись через Verdaccio. Verdaccio поддерживает отправку ответа 302, если сделать внутри плагина как-то так:
const readTarballStream = new ReadTarball({});
readTarballStream.emit("move", url);
return readTarballStream;
Мы этим, конечно же, воспользовались и на все запросы тарболов отвечали 302 со ссылкой на S3.
Интересно, что в Verdaccio асинхронные middlewares не работают по умолчанию. Это связано с тем, что в реализации логгера есть такие строки:
let bytesin = 0;
req.on('data', function(chunk): void {
bytesin += chunk.length;
});
На первый взгляд ничего страшного, но вызов этого метода у стрима активирует чтение, и плагин body-parser получает стрим, который уже завершился. Вы скажете, что можно поставить стрим на паузу, но нет, это не сработает. В текущем цикле чтение чанка будет произведено в любом случае и, если там больше нет данных, стрим закроется.
Мы сделали форк, из которого удалили строки, создававшие проблему. Знаниями о размере принимаемых пакетов пришлось пожертвовать, но для нас это было приемлемо. К сожалению, добавить эту правку во внешний репозиторий у нас не получилось. Команда Verdaccio занималась разработкой 5-й версии и нам сообщили, что в ней вся система плагинов будет переработана.
Итого, к концу августа у нас было:
- плагин метрик,
- собственный логгер с async-hook и пробросом контекста запроса,
- плагин авторизации через внутренние сервисы,
- тот самый плагин для хранения пакетов.
Мы были готовы к переключению 100% GET-запросов на Verdaccio.
Первая попытка

Через минуту после переключения количество запросов выросло, и мы получили вот такой рисунок на графиках балансеров:
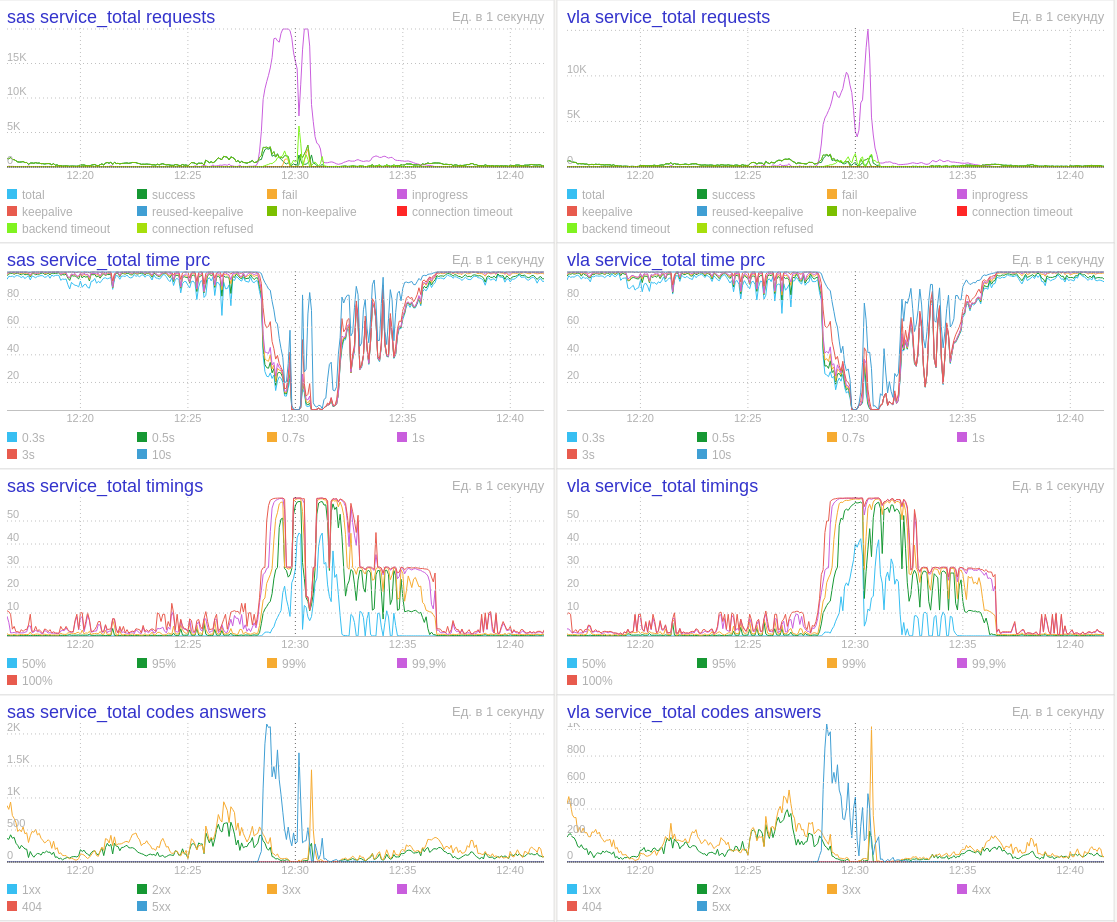
В этот же момент графики CPU на инстансах упёрлись в потолок. То, что работало при 1000 RPS, отказывало при 5000 RPS. Пришлось откатываться назад и открывать профайлер на локальной машине.
Потратив какое-то время на профайл, обнаружили критическую проблему: Verdaccio постоянно парсит json и преобразует его обратно в строку. Каждое обращение за пакетом — это парсинг json, каждая запись пакета, его отправка пользователю — преобразование в строку. Всё логично, ведь Verdaccio нужно как-то получать информацию о пакете и отправлять его, только вот некоторые файлы с метаданными пакетов во внешнем npm весили по несколько мегабайт. То есть неоправданно высокое потребление ресурсов, на которое мы ругались вначале, имело вполне конкретную причину.
Что делать? Увеличивать ресурсы бесконечно нельзя. К тому же получится, что новое решение, на адаптацию которого было потрачено почти 2 месяца, работает хуже старого. На помощь пришёл механизм, который уже был реализован в предыдущем плагине S3 и успешно перекочевал в новый — отдача кода 302 для тарболов. Если мы отдаём 302 для тарболов, то можем сделать то же самое и для метаданных, предварительно проверив их наличие в базе, где хранится информация о пакетах. А если в базе пакета нет, можно отправить его дальше в Verdaccio.
Изучив, как express обрабатывает запросы и какие существуют эндпоинты в Verdaccio, мы придумали вот что:
return async function(req: Request, res: Response, next: NextFunction): Promise {
// Проверяем соответствие роутеру
const packageRouteUrl = "/:package/:version?";
const packageRoute = pathToRegexp(packageRouteUrl);
const metaParams = packageRoute.exec(req.url);
if (!metaParams || !metaParams[1] || metaParams[2]) {
return next();
}
// Получаем имя пакета
const packageName: string = decodeURIComponent(metaParams[1]);
// Ищем в кеше
const cachedPackageRecord = getPackageFromCache(packageName);
let packageRecord: PackageRecord | undefined = cachedPackageRecord;
// Если в кеше нет, то ищем в базе
if (!packageRecord || packageRecord.isOutdated()) {
packageRecord = await getPackageFromDB(packageName);
// Если и в базе нет, то отдаём запрос Verdaccio
if (!packageRecord) {
return next();
}
}
// Для внутренних пакетов сразу отдаём 302 код с ссылкой
if (packageRecord.isInternal()) {
addPackageToCache(packageRecord);
sendMetaUrl(packageName, req, res);
} else {
// Для внешних пакетов проверяем, не нужно ли обновлять пакет по результату проверки etag
if (!etagUpdater.packageIsActual(packageRecord)) {
return next();
}
// Если у пакета истёк срок хранения, то в фоне создадим задачу на проверку etag
// Если etag истёк, то пометим пакет как требующий обновления
if (packageRecord.isOutdated()) {
etagUpdater.checkEtag(packageRecord);
} else if (!cachedPackageRecord) {
// Добавляем в кеш пакет, у которого всё в порядке с временем хранения и который не требует обновления
addPackageToCache(packageRecord);
}
sendMetaUrl(packageName, req, res);
}
};
Код для статьи чуть переписан, чтобы акцентировать внимание на самом главном. Если коротко, то мы:
- Перехватываем запросы на получение пакета.
- Ищем пакет в LRU-кеше или в базе.
- Если не нашли пакет, отправляем запрос в Verdaccio.
- Если пакет внутренний, отдаём ссылку на мету, потому что она всегда будет актуальна.
- Для внешнего пакета проверяем, не был ли он помечен во время проверки etag как устаревший, если не был, идём дальше, если был — отправляем запрос в Verdaccio.
- Если у пакета истёк срок хранения, ставим фоновую задачу на проверку его etag.
- Отдаём ответ 302 со ссылкой на метадату.
То есть, фактически, мы реализовали свой прокси перед Verdaccio, а чуть позже сделали то же самое и для тарболов.
Вторая попытка

Вторая попытка переключения оказалась чуть более удачной. Нам удалось без проблем выдержать весь RPS, и мы уже собирались отпраздновать переключение, как опять загорелись балансеры и подскочил график CPU. На ровном месте. При нагрузке меньше 1000 RPS.
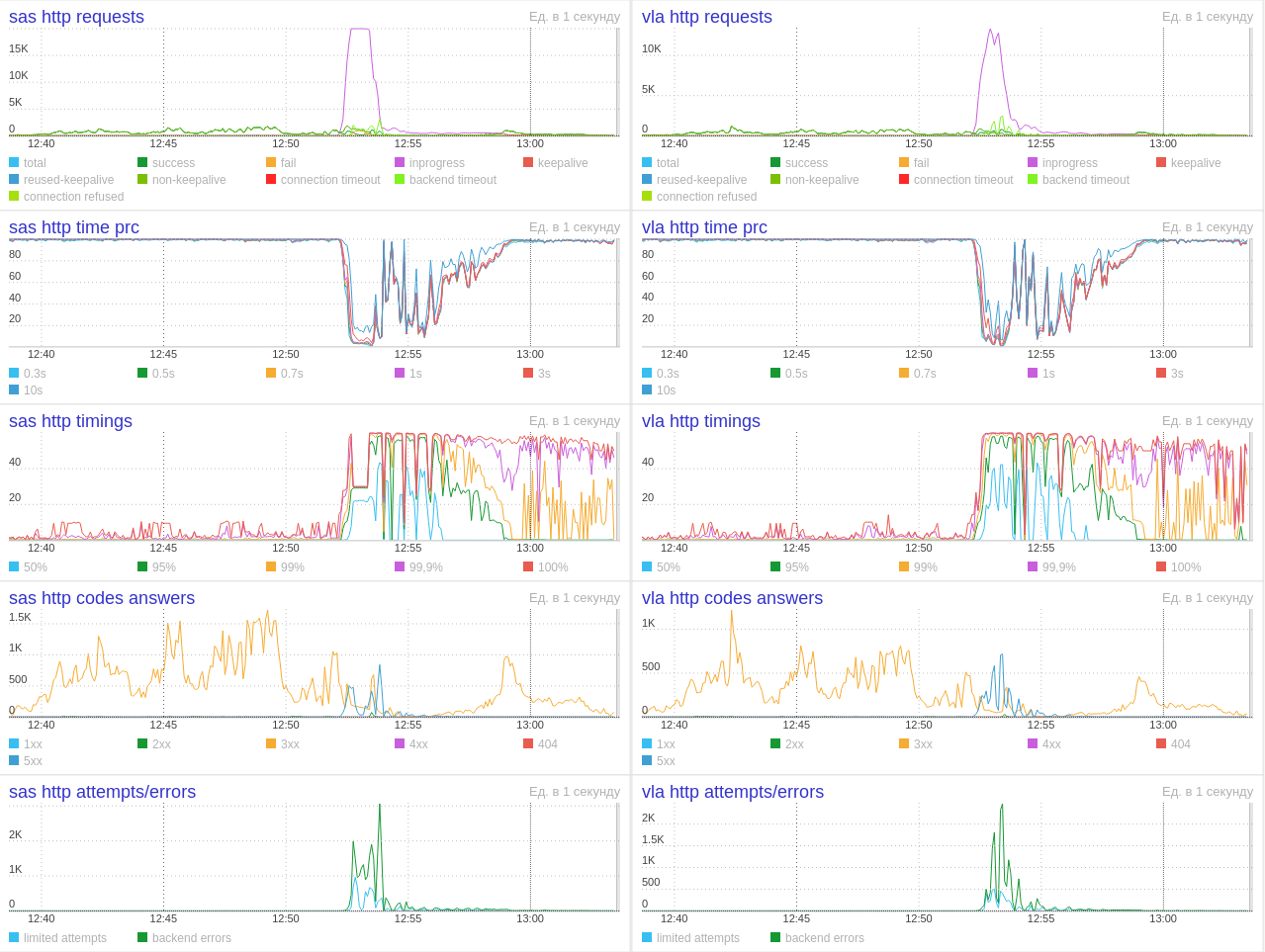
Ещё к нам пришли ребята из команды S3 недоумевая, зачем мы упорно запрашиваем один и тот же файл, получая неизменный ответ 404.
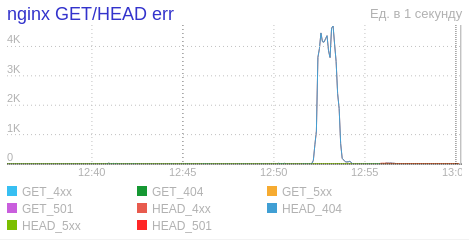
Всё выглядело, мягко говоря, странно. Было ощущение, что Verdaccio умножает запросы к самому себе и таким образом создаёт эту лавину. Проверили аплинки в конфиге — всё было в порядке, плюс, мы помнили, что в Verdaccio была защита от подобного поведения. На этом и пошли локально дебажить.
Во время дебага нашли в коде одно интересное место. Как думаете, что делать, если в пакете указан аплинк и файл не найден локально? Кажется, нужно взять имя файла и сходить по этому аплинку. Но Verdaccio делает не совсем так:
for (const uplinkId in self.uplinks) {
if (self.uplinks[uplinkId].isUplinkValid(file.url)) {
uplink = self.uplinks[uplinkId];
}
}
if (uplink == null) {
uplink = new ProxyStorage(
{
url: file.url,
cache: true,
_autogenerated: true,
},
self.config
);
}
Он проверяет, принадлежит ли исходный url файла этому аплинку и, если не принадлежит, просто идёт на указанный url. А исходный url — это url балансера, потому что пакет внутренний. Окей, учли это, и при отдаче меты из S3 подменяем URL для Verdaccio.
Но что же на счёт защиты от запросов к самому себе? Она есть и работает в точности как нужно — защищает текущий инстанс от запроса к самому себе:
headers['Via'] += '1.1 ' + this.server_id + ' (Verdaccio)';Пришлось написать свою реализацию antiLoop, которая просто проверяет наличие строки »(Verdaccio)» в заголовке «via».
Финал

После всех описанных манипуляций нам удалось переключить GET-запросы, а с переключением POST-запросов проблем, к счастью, не возникло:

Как дела обстоят сейчас?
- Сервис в 3 локациях по 32 инстанса в каждой.
- Выдерживаем отключение 1 датацентра без деградации сервиса и минус 2 датацентра с небольшой деградацией времён ответов, никаких ручных действий при отключении не требуется.
- Нагрузка до 5000 RPS в пиках.
- Максимальная нагрузка, которую можем держать при 3 датацентрах онлайн: 16000 RPS
Оказалось, что Verdaccio при нагрузке в 10 RPS и 6000 RPS — совсем разные вещи. Но если доработать решение под свои требования, применение ему найдётся и в больших компаниях. Предыдущий репозиторий выдерживал 4000 RPS, новый — до 16000 и имеет неограниченный потенциал масштабирования. В результате разработчики внутри Яндекса стали счастливее: запросы в поддержку исчезли, ошибок на балансерах больше нет. Система работает стабильно и не требует вмешательства со стороны команды инфраструктуры.
