Как генерировать стихи с помощью силлабо-тонической трансформенной языковой модели (часть первая)
Всем привет! Меня зовут Илья Козиев, я работаю в Управлении экспериментальных систем машинного обучения SberDevices над вопросами генерации текстового контента. В этой статье я хочу представить эффективный способ решения такой интересной задачи, как генерация стихов, с помощью одной из самых современных нейросетевых архитектур — GPT-3. Я подробно распишу все необходимые шаги на пути к получению стихов примерно вот такого уровня:
Я оставляю брошенные фразы
Иного смеха, слабости и слёз
Я превращаюсь в голубые стразы
Кружась ветвями молодых берёз
Ещё пример:
Люблю грозу в начале мая
Седую стужу в летний зной
И солнцем землю заливая
Весна придёт в мой край родной
Или даже так, с оттенком Агнии Барто:
Опять весна, и вечер наступает
Идет бычок, вздыхает на ходу
И мать кричит, и друга обнимает
Ищу его, покой я не найду
Можно даже сделать продолжение стиха с заданной строчки:
Мчатся тучи, вьются тучи
Опускается рассвет
Мысли пламенные жгучи
И весны тревожный след
Кажется, что все эти эмоции, нечёткие ассоциации и аллюзии, обёрнутые в строгую форму ритма и рифмы, не так-то просто совместить с холодной и бездушной математикой машинного обучения. По сути затронем одну из самых горячих тем в области искусственного интеллекта — машинное творчество. Кроме описания подхода, в конце будет ссылка на докер-образ с кодом и готовыми моделями для ваших экспериментов.
Как насчёт ruGPT-3 и ruT5?
На первый взгляд кажется, что генерация стихов мало чем отличается от генерации текста вообще. А что у нас есть хорошего для генерации текста в текущей точке пространства-времени? Конечно же, большие языковые модели GPT и T5 (а также их многочисленные родственники). Для русского языка существуют ruGPT и ruT5, выложенные в общий доступ, так что было бы странно не проанализировать их применимость для такой задачи.
Кстати, поскольку в рамках описываемого подхода мы будем тренировать свою «поэтическую» GPT с нуля, будет полезно заглянуть в описание тренировки ruGPT. А для погружения в тему текстовой генерации с помощью ruGPT полезным будет заглянуть в статьи «Тестируем ruGPT-3 на новых задачах» и «Всё, что нам нужно — это генерация».
Итак, модели ruGPT обучены на очень большом (десятки Гб) массиве русскоязычных текстов и хорошо знают морфологию, синтаксис и всякие нюансы словоупотребления для русского языка в текстах разных видов, включая художественную литературу, болтовню на форумах, статьи Википедии, новости. Что надо сделать, чтобы GPT начала радовать нас стихами? В нашем распоряжении три подхода.
Во-первых, можно взять большую модель (Large или лучше даже XL) и применить zero-shot или few-shot подходы. Так как при начальном обучении ruGPT видела некоторое количество стихов, оба эти подхода позволят получить какой-то результат без затрат на дообучение моделей.
Во-вторых, можно дообучить ruGPT целенаправленно на корпусе из стихов, чтобы увеличить шансы на получение стихотворной «годноты». Об этом подходе можно почитать в статье «Как ИИ учится литературному творчеству, или Любовные письма от тостера». Корпус стихов можно взять готовый, или наскрапить свой с сайтов поэтического самиздата, о чём я более подробно расскажу во второй части.
Третий подход основан на prompt tuning«е лежит где-то между первыми двумя. С одной стороны, тут будет нужен набор обучающих примеров, так что совсем без подготовки своего корпуса тут не обойтись. Но с другой стороны, количество этих примеров может быть намного меньше, чем для настоящего файнтюна самой языковой модели, так как требуется обучить намного меньшую по размеру вспомогательную нейросетку с более простой архитектурой. Подробности и примеры данного подхода можно найти в статье «Управляем генерацией ruGPT-3: библиотека ruPrompts».
Насколько хорошо работают эти подходы для генерации стихов? Увы и ах, если вы попробуете их (а я крайне рекомендую «пощупать» эти подходы своими руками!), то увидите, что получается не очень. Модели будут стараться выдавать обычную прозу, хотя и не лишенную какого-то налёта верлибра. Причина в том, что привычные нам стихи, а именно силлабо-тоническая поэзия, — это не только и не столько грамматически корректное содержание, но и определённая форма, а именно порядок чередования ударных и безударных слогов, а также фонетическое соответствие заударных окончаний последних слов в строках. Эту информацию языковая модель в ходе обучения на обычных текстах в явном виде не получает, и вывести её как правила синтаксиса из обычных текстов стихов она тоже может лишь с большим трудом и напряжением всех машинных сил. Говоря проще, модели ruGPT и ruT5 не знают ничего про позиции ударений и разбивку слов на слоги. Да, после дообучения такая модель может запомнить некоторое количество пар рифмуемых слов, но этого мало.
Впрочем, иногда такая отфайнтюненная ruGPT выдаёт что-то интересное:
А в небе звёздочка горит,
Сияет так красиво!
И на ветвях берёз шумит
Своей листвой игриво
Но это будут редкие сокровища в терриконах плохо зарифмованных текстов, которые напоминают стихи только «геометрией»:
Я знаю, ты не станешь смеяться
В этот день над моими стихами.
Только белая берёза проснётся
Под моим окном, и заплачет с нами
ОК, раз ruGPT сама не может «в рифму», почему не подсказать ей? Можно взять словарь рифм, какую-то готовую библиотеку, или даже натренировать свою нейромодель рифмовки, чтобы сначала подбирать последнее слово для каждой строки, а стартовые фрагменты строк генерировать с помощью отфайнтюненной на стихах ruT5 и так называемых sentinel tokens. Первые две строки стиха можно генерировать просто в отфайнтюненной rugpt, хотя это ограничит нас схемой рифмовки ABAB:
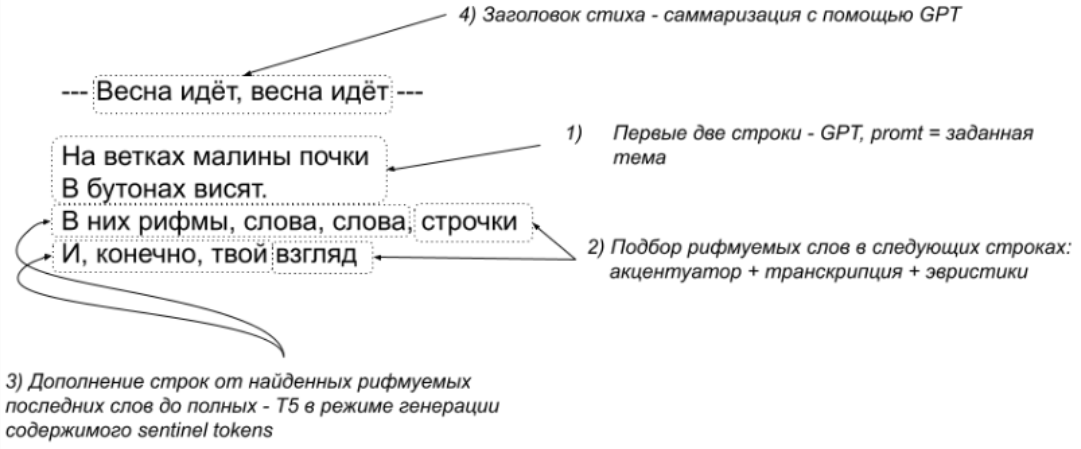
Заодно можно генерировать и заголовок стиха отдельной ruGPT, решая задачу «поэтической суммаризации». Да, такая немного переусложненная архитектура работает чуть лучше просто отфайнтюненной ruGPT, но мы ведь можем сделать намного лучше, да?
Ключевая идея силлабо-тонической модели
Как я уже сказал, стать хорошим поэтом ruGPT мешает полное непонимание фонетики русского языка. Можем ли мы научить модель GPT русской фонетике? Да легко! Всё, что для этого нужно — выбрать правильное представление текста, чтобы в явном виде представить знания об ударных и безударных гласных. А как это сделать? Через правильную токенизацию.
Оригинальная GPT (и ruGPT тоже) представляет текст как последовательность неких токенов. Количество этих токенов выбирается заранее (чуть больше 50 тысяч по сложившейся практике), и словарь формируется автоматически — так, чтобы любое слово языка представлять заранее фиксированным набором токенов. К примеру, в ruGPT самые частотные слова, наподобие »были», состоят из 1 токена, а более редкие бьются на кусочки. В результате, слово »фальшивомонетчицею» представляется цепочкой токенов «фаль | ши | вом | он | ет | чи | це | ю». Почти слоги, кстати. Фонетическая неконсистентность такого разбиения слов — проблема, от которой нам надо избавиться. Поэтому давайте бить слова явно и регулярно на нормальные слоги, чтобы, например,»были» представлялось как «бы | ли». И заодно пометим ударные слоги каким-то маркером, например стандартным юникодным символом справа от гласной:
В ле|су́ ро|ди́|лась ё́|лоч|ка
Таким образом, слоги «су» и «су́» становятся разными токенами (технически — имеют разные числовые индексы), и в ходе обучения модель поймёт, где какой употребляется.
Отлично, а что с рифмами? Может, они как-то сами собой начнут возникать?
Тут стоит вспомнить, как происходит генерация текста в авторегрессионных моделях типа GPT. А происходит она слева направо, так как обучающие тексты она видит именно в таком порядке. В случае стихов это означает, что к моменту, когда надо выбирать последнее слово в строке, модель уже нагенерировала всю начальную цепочку. И зачастую наскрести в языковых сусеках слово с нужной рифмой уже нереально сложно, не поломав метрику. Вот если бы делать наоборот, сначала выбрать последнее слово в строке с нужной рифмой, а потом дописать начало строки…
А что, собственно, мешает нам писать стихотворную строку справа налево? Правильно, ничто, кроме привычки и зашоренности. В других частях нашего обитаемого мира люди пишут и справа налево, и сверху вниз. Вот и давайте отбросим предрассудки, развернём все слова в каждой строке, так сказать «арабизируем» текст.
Было так:
И в нарастающей воде
Призывный стон из глубины
А дале гул звучит везде
То первый вздох и глас весны
А стало так:
де́ во | щей ю ста́ ра на | в | И
ны́ би глу | из | сто́н | вный зы́ При
зде́ ве | чи́т зву | гу́л | ле да́ | А
сны́ ве | гла́с | и | вздо́х | вый пе́р | То
Обратите внимание, что символы в слогах написаны слева направо, а слова и слоги записаны справа налево. Кстати, через некоторое время такие тексты можно научиться читать невооруженным глазом. Хотя делать это приходится только при отладке кода, так что волноваться не надо.
Приглядевшись к новому представлению стиха, можно увидеть, что рифмуемые слова идут уже в начале каждой строки. Генерация текста сначала будет выбирать рифмуемое слово, затем дописывать к нему строку. Хотя может показаться совсем не очевидным, что какая-то там нейросетка сможет писать русский текст справа налево, в то время как его носители вроде бы делают это наоборот. Уверяю — сможет, и неплохо!
Собственно говоря, в этот момент термин «силлабо-тонический» в названии модели должен уже стать полностью раскрытым :)
Разобравшись с представлением стихотворного текста, можно приступать к тренировке языковой модели.
Тренировка силлабо-тонической языковой модели
В этой части я кратко опишу пайплайн тренировки генератора стихов, а важные технические нюансы я подробно опишу в отдельной статье.
Большие языковые модели (далее ЯМ), в чьи ряды должна влиться и наша поэтическая GPT, обычно обучаются в 2 захода. Сначала ЯМ тренируется на очень большом наборе текстов без ручной разметки (претрейн). Корпус для претрейна в нашем случае состоит из автоматически размеченной русскоязычной прозы объёмом примерно 10 миллиардов символов. Этот этап формирует у модели общее понимание грамматики языка, необходимое для генерации связного текста. Плохая новость состоит в том, что претрейн это чрезвычайно ресурсоёмкое и длительное мероприятие. В нашем случае много времени (2—3 недели) занимает расстановка ударений в тексте, и ещё 2—3 дня собственно тренировка трансформенной модели. Хорошая новость заключается в том, что предобученная ЯМ может затем использоваться многократно для экспериментов с файнтюном в качестве базовой. Чтобы сэкономить время тех читателей, которые захотят поэкспериментировать с генерацией стихов и натренировать свою ЯМ, во второй части будет дана ссылка на скачивание готового корпуса.
На втором этапе ЯМ подвергается дообучению под целевую задачу (файнтюн). Используемый для этого корпус состоит из автоматически размеченного набора стихов с небольшой добавкой ручного труда. Основное время тут тратится на сбор стихотворного «сырья», а тренировка модели происходит почти мгновенно — всего несколько часов. Среди важных технических деталей этого этапа я бы назвал разметку стихов с подбором метра, фильтрацию некачественных стихов, и подготовку данных для управления генерацией. Во второй части я также дам ссылку на скачивание готового корпуса для файнтюна и расскажу, как его запускать.
И претрейн, и файнтюн модели делается немного модифицированной версией кода из репозитория ru-gpts. Метаданные и веса моделей получаются в формате, пригодном для запуска инференса с помощью библиотеки transformers, хотя для токенизации придётся использовать свой класс, а не имеющиеся в transformers готовые токенизаторы.
Кстати, тот факт, что у нас модель в целом является вариантом GPT со штатным API инференса, позволяет легко делать самые разные эксперименты, пробуя всякие новинки в теме генерации текстов. О некоторых таких экспериментах я планирую рассказать в одной из будущих статей.
Генератор стихов
Итогом всех наших трудов будут две модели. Первая будет генерировать четверостишье на заданную тему в заданном формате. Вторая модель будет продолжать начатое первой, генерировать следующие четыре строчки, самостоятельно подлаживаясь под метрику и содержание начальных строк. Остаётся завернуть это в какой-то удобный для использования вид, например — телеграм-бот. Я подготовил докер-образ такого бота со всеми необходимыми моделями и кодом для инференса. Вы можете скачать его отсюда и запустить локально. После запуска образа в консоли надо будет ввести токен телеграм-бота, и ваш личный генератор к вашим услугам:

Возвращаясь к теме машинного творчества, упомянутой в самом начале, стоит пару слов сказать про виртуальных ассистентов. Сегодня мы вплотную приблизились к созданию таких чат-ботов, которые будут способны не только отвечать на заранее отобранные вопросы и выполнять простые поручения, играя роль секретаря. Ассистенты нового поколения, возможно, уже скоро будут создавать для нас персональный контент, выполняя роль своего личного композитора, писателя или художника.
Подборка результатов генерации
* * *
Моя любовь, стихи и песни, стоны
И шёпот, шёпот, шёпот тишины
Когда алеют розы, как пионы
Когда искрятся праздники весны
* * *
Мне хочется пройти сквозь тающий песок
И вылиться ручьями этой влаги
Упасть, сорваться, стать на волосок
Швырнуть, на лист промасленной бумаги
* * *
Погода — ядовитая отрава
Осоки, травы, смятые кусты
Обиды и слова — дурная слава
Вникают в строки — смятые листы
* * *
Принёс букеты алых роз
Ей из неведомого края
Восторг, и грусть, и море слёз
Апофеоз любви и рая
* * *
Открыв глаза, увижу сон
И лишь однажды я узнаю
Я боль, когда я вижу сон
Вдыхаю, выдыхаю, таю
