Как эффективно релизить монолит, в который коммитят 150+ разработчиков из разных офисов
Я работаю инженером в Miro в команде, отвечающей за улучшение процесса релизов.
За последний год у нас появился зарубежный офис разработки, инженерная команда выросла вдвое, а полгода назад компания временно перешла на удалёнку. Параллельно с этим происходил постоянный кратный рост количества пользователей нашего продукта.
На фоне этих изменений нам важно было не терять в качестве и скорости, поэтому мы серьёзно обновили процесс серверных релизов. Расскажу про изменения, которые в итоге повысили долю успешных релизов.
Серверные релизы
Наш backend — это монолитное Java-приложение, которое может быть запущено с разными ролями для выполнения разных задач. Для работы backend мы используем AWS инстансы (CPU 4 ядра, RAM 16 ГБ). Большая часть backend-серверов — приложение, которое держит постоянное веб-сокетное подключение с клиентом, чтобы пользователи всегда видели реальное состояние досок в Miro. Для этих серверов мы используем роль Board-сервер (пользователи попадают на них при работе на досках). Для работы с бизнес-логикой и API-запросами используем роль API-сервер.
Релизы мы делаем бесшовными (graceful deploy) и стараемся проводить их во время наименьшей нагрузки на сервис. Во время планового релиза у нас в среднем 60.000 онлайн-пользователей и 50 работающих board-серверов.
Мы считаем релиз успешным, если он вышел в срок и в него попали все задачи, которые были готовы к релизу на момент его запуска. Соответственно, релиз считается неуспешным, если что-то пошло не так, потому что ошибки, которые потребовали остановки или отката релиза, увеличивают время доставки (time to market).
Любые изменения в процессе проведения релизов мы оцениваем исходя из того, насколько они приближают нас к успешному релизу.
Успешный релиз — это релиз, который вышел в срок и в который попали все задачи, готовые к релизу на момент его запуска.
Процесс подготовки релиза:
На каждый пулл-реквест прогоняется релевантный набор e2e тестов. Добавить изменения в мастер можно только при успешном прохождении всех тестов. Внутри автотестов есть маппинг соответствия тестов и кода продукта. Набор e2e-тестов для пулл-реквеста определяется нашим инструментом, который выбирает тесты, основываясь на этом маппинге и анализируя изменённые файлы в пулл-реквесте.
Каждый собранный мастер проходит полную регрессионную проверку. Релиз возможен, если все тесты прошли успешно. Упавшие тесты правят команды, ответственные за функциональность.
Для того чтобы релиз вышел автоматически, мы используем Allure Enterprise Edition, в котором отмечаем false-positive тесты как Resolved.
Процесс релиза:
Ищем сборку со 100% успешных тестов и версией, которая больше текущей версии на продакшене.
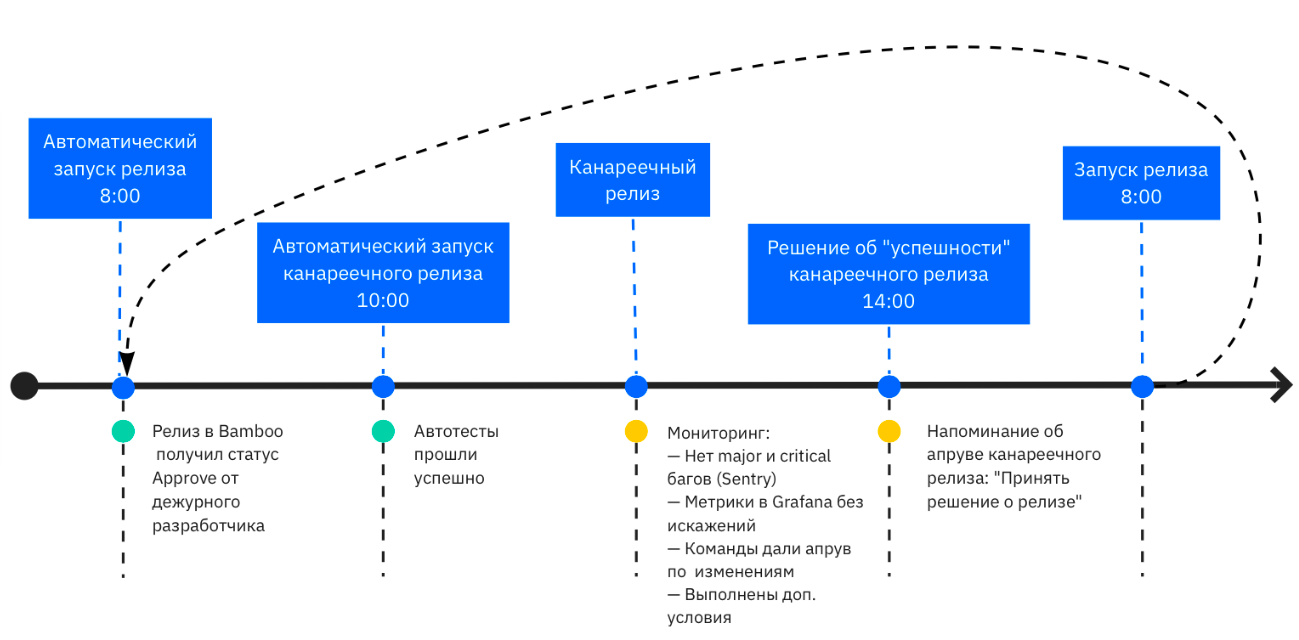
Запускаем канареечный релиз.
Мониторим метрики релиза в течение 4х часов.
Ставим статус Approved или Broken по завершении канареечного релиза. При статусе Approve основной релиз автоматически запускается следующим утром, при Broken запуска не произойдет.
Для релиза на API- и board-серверах создаём инстансы с новой версией. Количество инстансов рассчитываем, исходя из текущей нагрузки и добавляем 20%, чтобы не допустить высокой нагрузки во время или сразу после релиза.
Пользователи постепенно переходят на новые сервера, старые сервера мы выключаем и удаляем.
Релиз от создания инстансов до полного перехода на новую версию занимает полтора часа.
Канареечный релиз
Канареечный релиз нужен для того, чтобы валидировать изменения на небольшой случайной выборке пользователей. В ходе него мы поднимаем несколько серверов с новой версией и наблюдаем за ситуацией. Если на канареечном релизе всё идёт хорошо — релизимся на все сервера.
 Процесс канареечного релиза
Процесс канареечного релиза
Канареечный релиз не способ тестирования на проде, а дополнительный эшелон защиты. Он позволяет уменьшить количество пользователей, которые столкнулись с ошибкой, если кейс сложный или если он повторяется только на инфраструктуре продакшена.
Для быстрой реакции на ошибки в канареечном релизе мы ввели роль дежурного серверного разработчика, которую выполняет каждый разработчик по очереди. Дежурный разработчик в течение четырех часов работы канареечного релиза реагирует на новые ошибки в Sentry и на общие предупреждения из Grafana, может остановить релиз самостоятельно при необходимости. После завершения канареечного релиза он обновляет статус релизной сущности в Bamboo: Approved или Broken.
В случае срочных релизов вне расписания команды могут запустить релиз через деплой в Bamboo самостоятельно, для этого в каждой команде есть инженеры с необходимыми правами.
Пользователи попадают на канареечный релиз случайным образом, с помощью балансировщика. Случайная выборка позволяет валидировать релизы на разных пользователях, но имеет и недостатки: без изменения в коде не позволяет балансировать типами пользователей и аккаунтами, не даёт проверять функциональность на конкретных аккаунтах или досках.
Выкатить канареечный релиз на определённую выборку пользователей мы можем, только если функционал был написан с Feature Toggle, а это уже реализация через код, а не через релизы.
Hot Fix в канареечном релизе
Раньше, находя ошибку в канареечном релизе, мы блокировали мердж в мастер и весь релиз. Это было неудобно, так как блокировало работу других команд и задерживало время выхода релиза.
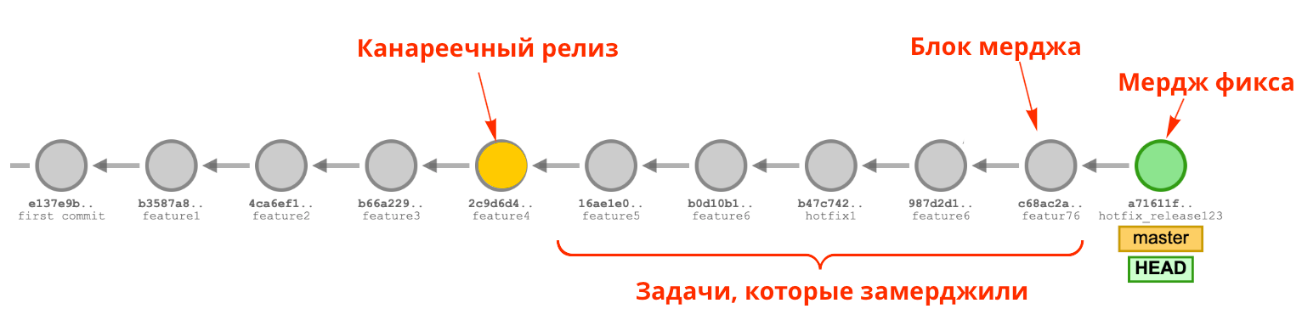
Нам хотелось найти подход, при котором мы могли задерживать выход релиза минимально. Мы изучили существующие подходы (Trunk-Based Development, GitFlow и т.д.) и остановились на GitLab Flow.

Как мы работаем с Hot Fix по GitLab Flow:
Отводим релизные ветки от версии из канареечного релиза.
Мерджим фикс в мастер.
Выполняем git cherry-pick в релизной ветке.
Запускаем канареечный релиз на релизной ветке.
Запускаем следующий плановый канареечный релиз на версии мастера с фиксом или выше.

Подход помог нам вдвое снизить максимальное количество дней без релиза и количество перезапусков канареечных релизов, с четырёх до двух.
Предсказуемость и прозрачность процесса релиза
Для повышения качества релиза мы поддерживаем его прозрачность и предсказуемость. Используем для этого автоматические уведомления и дашборды с ключевыми метриками.
Раньше мы публиковали большой changelog один на все команды: в общем канале со всеми изменениями в релизе. Командам было трудно и больно ориентироваться в нём. Поэтому к общему changelog мы добавили командные changelog, в котором каждая команда видит статусы только по своим задачам и версию релиза, в которой они реализованы.
Дашбордами в Grafana мы пользуемся при работе с внеплановым релизами, чтобы быстрее их завалидировать. Во время плановых релизов нам хватает алертов из Grafana на основе метрик из Prometheus.

Всю статистику по релизам из Jira и Bamboo мы собираем и визуализируем в Looker, чтобы на основе исторических данных принимать решения о качестве процессов и улучшать их.
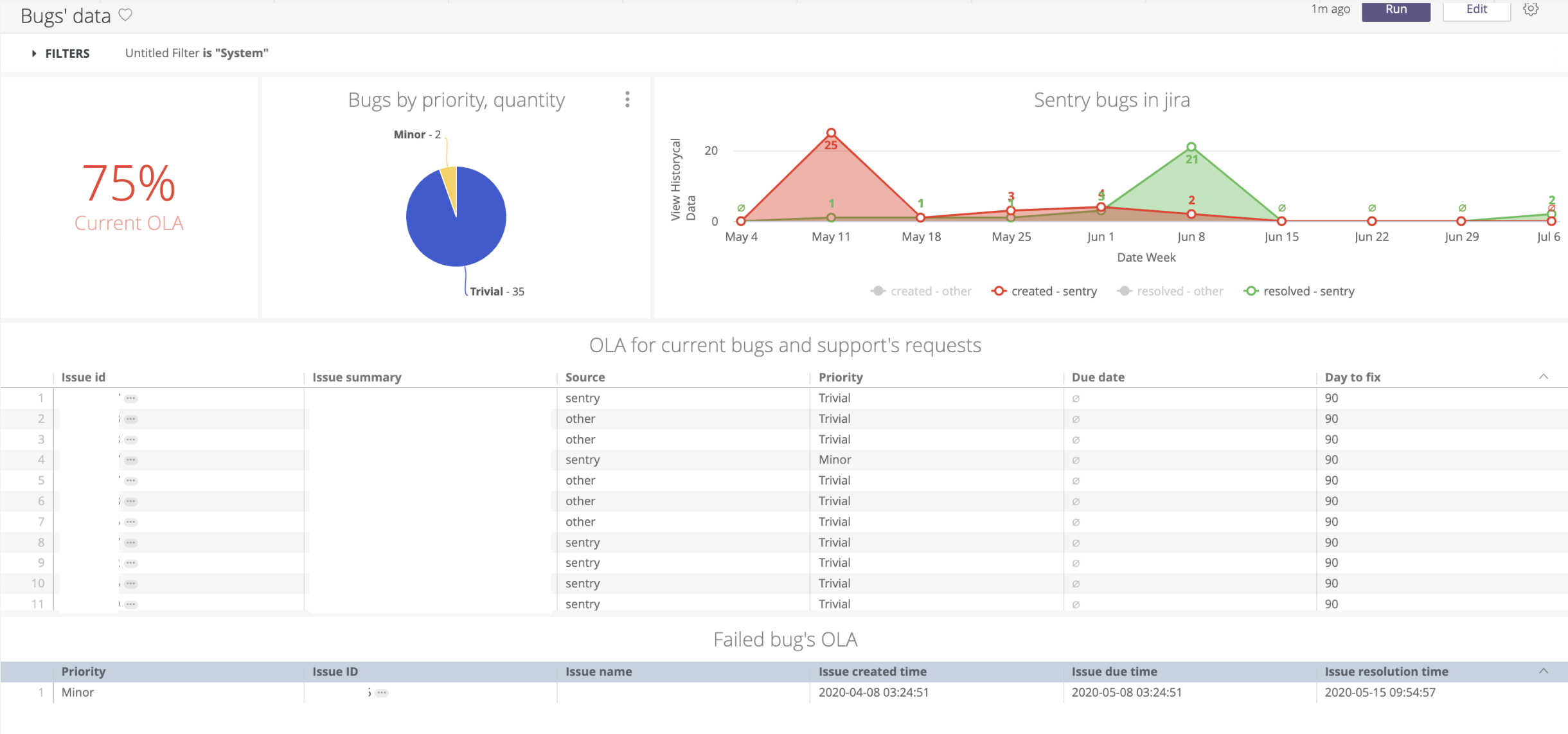 Данные по ошибкам, количество созданных и закрытых задач.
Данные по ошибкам, количество созданных и закрытых задач.
Сейчас мы внедряем фичу, которая позволяет командам блокировать ручные и автоматические релизы, если в мастере есть ошибка. Благодаря ей мы сможем автоматически собирать статистику количества сломанных мастеров, времени фикса и понимать, какие ошибки заблокировали выход релиза.
Изменения, которые увеличили долю успешных релизов
Канареечные релизы помогли сократить количество откатов релизов на 95%.
Отдельные changelog для каждой команды повысили общую прозрачность процесса. Теперь каждая команда вовремя и удобным способом получает уведомления о том, когда выходит их функциональность.
Мониторинг канареечного релиза дежурным серверным разработчиком уменьшил время реакции команды на найденный ошибки.
Подход GitLab Flow для hotfix позволил задерживать выход релиза минимально и исправлять ошибку, не блокируя работу других команд. Автоматические релизы стимулируют команды держать мастер всегда готовым к релизу.
Сбор и анализ всей истории релизов в Looker помогает проверять гипотезы и постоянно улучшать процесс.
Ближайшие планы
Конечная наша цель — выстроить процесс так, чтобы все релизы были успешными и пользователи никогда не сталкивались с ошибками. Для этого мы планируем следующие изменения:
Разбить монолит на микросервисы. Мы начинаем двигаться в эту сторону, но это отдельный большой проект вне темы статьи, поэтому останавливаться здесь на этом не буду.
Увеличить скорость релиза. Сейчас релиз на board-серверах занимает час, релиз на API-серверах — полчаса. Мы хотим быстрее.
Дать командам инструмент для автономного управления релизами. Сейчас есть возможность запустить канареечный релиз для hotfix, но команды не могут воспользоваться GitLab Flow полностью самостоятельно. Например, не могут самостоятельно отвести релизную ветку. У нас по умолчанию включена функция «Branch merging enabled», поэтому ветки при сборке содержит код мастера, а для релизных веток командам нужна помощь со стороны для ручного отключения этой фичи.
Сократить время от момента нахождения ошибки до вывода фикса на канареечный релиз. Сейчас у нас это может занимать до 6 часов рабочего времени в худших случаях из-за сложностей в коммуникациях или процессах.
Управлять нагрузкой на канареечных релизах, чтобы с ростом пользователей мы имели возможность увеличивать скорость прогона релиза, не меняя доли пользователей, участвующих в нём.
Добавить пользовательские метрики в валидацию релиза. Пока используем только технические метрики и метрики с багами.
Буду рада, если в комментариях поделитесь опытом повышения доли успешных релизов, особенно если вы уже реализовали описанные выше задачи.
