Как добавить системности в мониторинг продакшна: параметры и тулинг для инцидент-менеджмента

Привет, меня зовут Иван, я инцидент-менеджер в Сравни. Давайте обсудим, как добавить системности в мониторинг проблем на продакшене — поговорим об инцидент-менеджменте.
На проде что-то сломалось — такова суровая реальность, случается с лучшими из нас, увы. Что обычно происходит в подобных случаях? Ловим алерты, бежим смотреть графики и логи, вызваниваем из отпуска разработчика, который занимался этой функциональностью, выкатываем фикс, рвем на себе бороду, проводим пост-мортем. Это реакция на уровне здравого смысла, классика.
Но когда речь заходит о недозаработанных из-за инцидента деньгах, расстроенных пользователях — любое улучшение, даже небольшое, на доли процента — может принести ощутимый результат.
Давайте поговорим, как подойти к вопросу мониторинга методологически — задействовать инструментарий инцидент-менеджмента. Обсудим, как оценивать критичность сервисов и какие системы могут быть полезны для отслеживания проблем.
Статья ориентирована в первую очередь на тех, кто прямо сейчас занимается мониторингом на уровне общей инженерной грамотности, но пока не использует в явном виде инцидент-менеджмент как подход.
Что-то сломалось — о чём именно речь?
«На проде проблемы» — такую фразу можно услышать от коллег о совершенно разных вещах.
Тут в статье для терминов «инцидент» и «инцидент-менеджмент» мы используем определения, принятые в ITIL и ITSM (вот неплохая вводная статья от Atlassian).
В рамках такого подхода выделяют следующие категории инцидентов:
деградация производительности;
частичная недоступность;
полная недоступность;
нарушение безопасности хранения данных.
На пальцах всё более-менее понятно, но как только идёшь договариваться о процессах, кто-то кому-то начинает быть что-то должен, могут возникнуть вопросы из серии «А точно ли оно нужно?».
Чтобы договориться между собой в команде разработки и предоставить аргументы бизнесу, вот список типичных проблем, которые мы хотим чинить с помощью инцидент-менеджмента:
Негативный настрой клиентов — с правильными алертами будем раньше узнавать о проблемах, расстраивающих пользователей, больше понимать об их природе.
Незаработанные деньги — если сервис недоступен, люди склонны переставать нам за него платить; хотим этого избежать.
Нагрузка на поддержку — если коллеги из саппорта тонут в обращениях пользователей, могут возвращаться к клиентам слишком поздно или пропустить важные обращения; это в свою очередь может приводить к предыдущим двум проблемам.
Неоптимальное распределение времени команды разработки — если инженерам из раза в раз приходится «тушить пожары», это дорого стоит в человеко-часах и может приводить к демотивации и эмоциональному выгоранию, а это — к снижению продуктивности и уходу из компании, может увеличить сложность найма.
Перерасход ресурсов — тут речь о конфигурации и стоимости инфраструктуры, числе людей в команде; «забросать проблему деньгами» — не всегда самый удачный подход.
Ок, представим, что все со всеми договорились, и у нас есть «зелёный свет» на инцидент-менеджмент — давайте поговорим о первых шагах.
Инцидент-менеджмент: с чего начать
В нашем случае первые шаги выглядели следующим образом:
найти крайнего ответственного;
рассказать всем, что именно будет происходить;
обойти все команды.
Если нет явной договоренности, кто именно должен реагировать на инциденты, может произойти ситуация, когда каждый думает, что заняться проблемой должен кто-то другой (такое бывает даже в случаях, когда договоренность есть — обсуждали такое у нас в статье о проблемах с дежурствами).
В идеале должен быть выделенный человек для инцидент-менеджмента, чтобы иметь достаточно фокуса и контекста. Если отдельного человека нет — это не блокер. Тут логика такая же, как для пилотирования любых новых активностей — попробуем, пусть сначала этим займётся человек, который будет совмещать новые задачи с другими обязанностями, а если увидим пользу и будем иметь возможность, то заведем отдельную роль. В нашем случае пилотированием инцидент-менеджмента занимался лид второй линии поддержки.
Рассказать всем, что именно будет происходить — формат и количество коммуникаций зависит от вашей организационной структуры и сложившихся каналов для распространения информации. Важно донести концепцию до руководства (чтобы не было принципиальных возражений с их стороны) и следом рассказать на всю команду вообще (а тут уже ранее проинформированное руководство сможет поддержать «инициативу на местах»).
Ключевая часть анонса: договориться о параметрах мониторинга.
Мы выбрали следующие:
критичность сервиса для бизнеса;
есть ли дежурные;
как зависит от внутренних сервисов;
какие есть зависимости от внешних сервисов.
Для критичности мы выделили три уровня:
Сервис не влияет на клиентский путь — проблемы чинятся с учетом нагрузки команды, попадают в общую очередь задач на разработку соответствующей команды.
Сервис затрудняет прохождение клиентского пути, но клиенты в целом могут пользоваться продуктом — соответствующие задачи отправляются в бэклог, исправление происходит в штатном режиме, в рабочие часы команды. Типичные задачи: исправление сервиса, добавление дополнительного логирования, перенастройка алертов.
Клиенты не могут пользоваться сервисом — исправление должно быть незамедлительным, даже если требуется это сделать ночью или в выходные.
Дежурства — полезная практика, но потребность в ней есть не всегда. Если дежурных в команде пока нет, а необходимость есть, то договариваемся с разработчиками в команде или эскалируем расширение штата (найм), или пересматриваем критичность сервиса.
Зависимость от внутренних сервисов — прописываем, чтобы в случае инцидента можно было быстро проверить, всё ли в порядке в соседних командах, ускорить поиск причин.
Зависимость от внешних сервисов — прописываем и перепроверяем, что у нас обязательно есть контакты с той стороны, с явным SLA для времени реакции на наши запросы.
Ещё одна важная сущность в контексте инцидент-менеджмента, о которой стоит рассказать всем и договориться о правилах — бюджет ошибок. Это максимальное время, в течение которого система может деградировать или быть недоступной без оговоренных в соглашении последствий.
У нас в Сравни есть правило: в среднем по компании время uptime для сервиса должно быть 95%. Но в разных командах есть свои нюансы, мы попросили всех лишний раз обсудить с бизнесом, чтобы всех всё устраивало.
Инструменты инцидент-менеджмента
Договоренности с коллегами и внешними контрагентами — сложная часть дела, но не единственная сторона вопроса, где что-то может пойти не так. Для инцидент-менеджмента важно аккуратно настроить соответствующий тулинг, и тут, как водится, есть свои нюансы.
Наши основные инструменты для мониторинга: Apdex, Sloth, Grafana OnCall. Давайте расскажу о них чуть подробнее.
Apdex
Application Performance Index (Apdex) — это стандартизированный показатель, который дает простую и понятную оценку эффективности работы приложения с точки зрения пользователей.
Для нас это инструмент, который показывает работу наших сервисов по шкале от 0 до 1, где 0 — «сервису совсем плохо», 0.5–0.75 — «сервису в целом ок, но может быть и лучше», 1 — «сервис чувствует себя замечательно». Детектируются ошибки, а также скорость ответа на запросы, время отклика сервисов.

Из нюансов: прикрутить Apdex получится только к ручкам, у которых >1 RPS. Для <1 RPS, вместо Apdex мы смотрим на их Error Rate (отношение количества нормальных ответов к количеству ошибок).
Sloth
Service Level Objectives (SLO) — цель по уровню обслуживания, которая определяет ожидаемое качество и производительность сервиса. Sloth — инструмент на базе Prometheus, который упрощает и стандартизирует создание SLO, делая этот процесс более быстрым, простым и надежным.
С его помощью мы можем посмотреть, как сервис чувствует себя в ретроспективе. Кроме этого, инструмент включает в себя поддержку создания дашбордов для Grafana, что делает мониторинг и анализ SLO удобнее и доступнее.
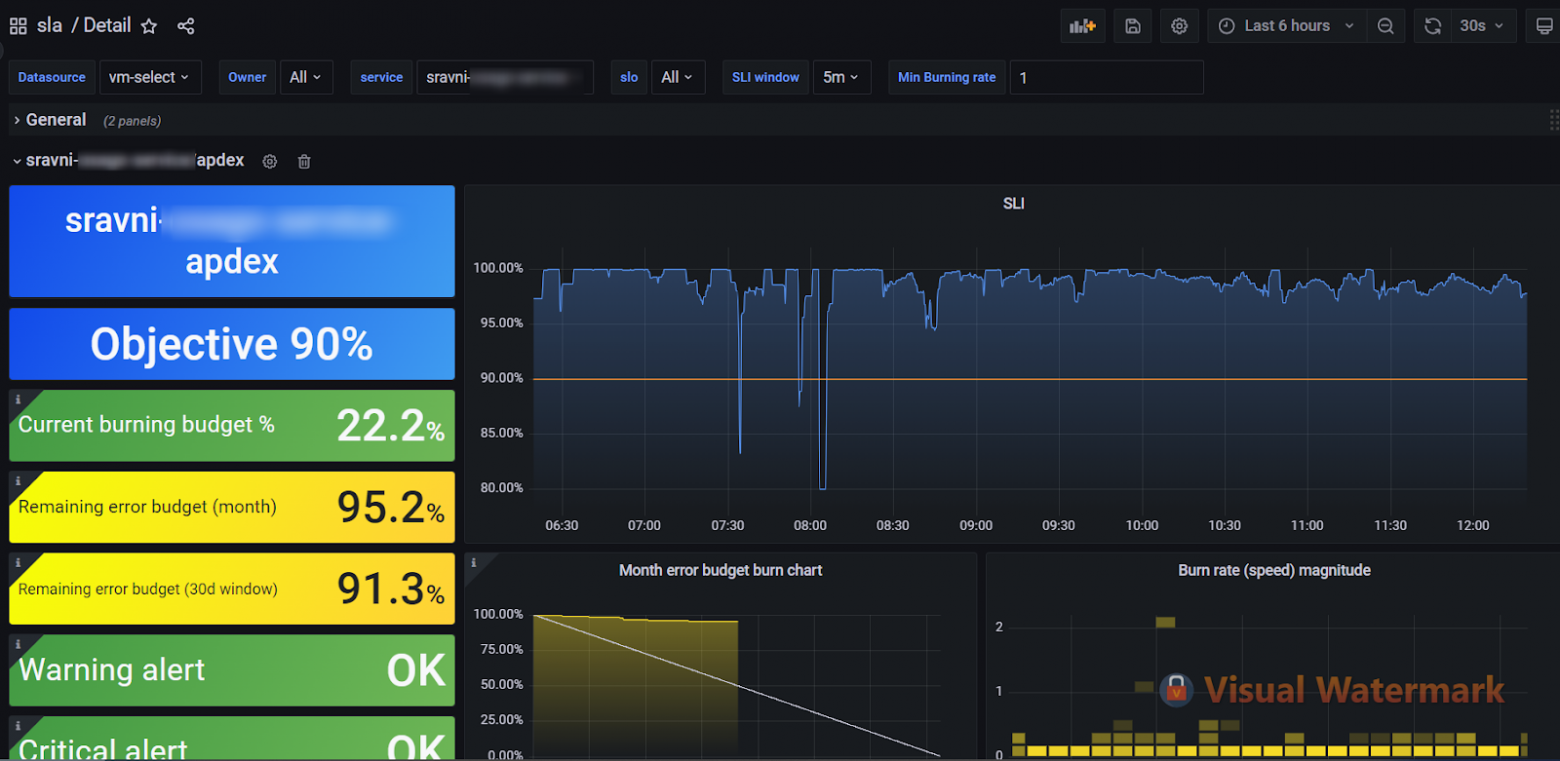
Жёлтая линия обозначает порог, ниже которого начинает «выгорать» бюджет ошибок
Тут тоже не обошлось без нюансов. Если вы уже подключили Apdex, то вам не составит труда подключить Sloth. Если работа с Apdex не настроена, то придется писать кастомные запросы на специальном языке для Grafana.
Ещё аспект — ложные алерты. «Тревога» может сработать не из-за того, что сервис стал плохо себя чувствовать, но, например, из-за проблем с метриками. Здесь нужно быть морально готовыми, что придётся поэкспериментировать с настройками, сделать несколько итераций тюнинга параметров по мотивам наблюдений за реальным уровнем деградации сервисов. Вряд ли удастся всё включить «из коробки» так, чтобы каждое оповещение об инциденте всегда сигнализировало о реальной проблеме — ложные алерты по началу скорее всего будут.
Grafana OnCall
Здесь чеклист по настройке:
Завести команду людей по работе с инцидентами.
Добавить членов команды — всех, кого хотим привлекать к взаимодействию с инцидентами.
Создать расписание дежурств.
Задать правила эскалации — в каких случаях достаточно прислать дежурному оповещение в условный Telegram, а когда нужно звонить СТО на телефон.
Включить интеграции — в нашем случае все алерты прилетают в общий канал в рабочем мессенджере.
Связать алерты с правилами эскалации.
Прилетающие в рабочий мессенджер алерты у нас выглядят вот так:

Интеграция Grafana OnCall с Jira
Интеграция с таск-трекером настраивается в интерфейсе Grafana OnCall с помощью вебхука (вот инструкция).
Будьте аккуратны с переходом от тестирования интеграции к её полноценному использованию — в своё время я на старте использования этой опции случайно создал 1000+ алертов, в Jira одномоментно завелось такое же количество тикетов — разработчики были, кхм, удивлены.
Лайфхак для поиска ответов на вопросы по интеграции: помимо проверки документации и гугления, можно вступить в открытый канал Grafana в Slack, там разработчики довольно оперативно и доброжелательно могут дать наводку на интересующую вас информацию.
Инцидент-менеджмент: необходимое и достаточное условия
Но ведь есть же компании, которые живут без инцидент-менеджмента и ничего, как-то справляются?
Это правда. Вопросы «а точно ли нам нужно?» и «если да, то когда начинать?» — во многом лежат в плоскости верхнеуровневых принципов ИТ-команды.
У нас за работоспособность продуктов отвечают команды, которые их разрабатывают — это идеологический и организационный момент. Число команд растет, появляются новые зависимости от внешних партнеров и между продуктами. При таком раскладе жить без понятного для всех стандарта и при этом выполнять для клиентов обещание по доступности сервисов — практически невозможно.
Так что для нас инцидент-менеджмент был не результатом любопытства или веянием моды, а необходимостью.
Как оно будет в вашем случае — перепроверьте в культуре ИТ-команды. Каким бы ни было отношение к инцидент-менеджменту, про сами инциденты хочется пожелать всем, чтобы случались пореже!
Расскажите в комментариях — как у вас устроен процесс работы с инцидентами — есть выделенные люди на такие задачи, какими инструментами пользуетесь, как оцениваете критичность сервисов?
