Как бекапить облака? Варианты от Veeam

Информация, загруженная в облако, уже никуда и никогда оттуда не пропадет! Именно так можно сформулировать одну из популярнейших IT легенд, восхваляющую незыблемость облаков и суляющую наступление всеобщего счастья от миграции с банальных on-premise серверов.
Однако на деле всё совершенно не так, и к угрозе потери данных в облаках надо относиться не менее серьёзно, чем к хранящимся на грешной земле. Вот об этом мы сегодня и поговорим: почему облака теряют данные, рассмотрим на примере Azure, какие варианты бекапов нам предлагают облачные вендоры, а на примере Veeam — как эти процессы можно улучшить.
Случайно или осознанно, но многие, видя пять девяток доступности, обещаемые каждым первым облаком, воспринимают это заявление как тождественное клятве на крови о сохранности всего, что вы туда поместите. Однако провайдер облака обещает вам только то, что будет функционировать именно облако. Он не будет никак заморачиваться, чтобы ваш сервис, который вы у него развернули, не взломали и не пошифровали файлы. Или на случай, когда ваш сотрудник стёр у себя все письма, или когда девопсы перепутали стейджинг с продом и теперь у вас нет боевой базы. Таких “или” много, но результат всегда будет один — облако работает, а вот ваши данные в нём или утеряны, или превращены в бесполезный мусор.
Поэтому, повторяем как “отче наш” — облачный провайдер гарантирует доступность облака, а не данных внутри него! Защита данных клиента от утери или повреждения — это задача клиента, а не облака.
Поскольку большая часть окружающей нас реальности подчинена законам капитализма, было бы странно, если бы облачные провайдеры не предложили за нас решить и эту проблему, параллельно заработав свою трудовую копеечку.
Тут надо задать себе важный вопрос: целостность чего именно нам надо сохранить? Предположим, что мы используем возможности облака по полной и работаем по модели IaaS. Тогда нас мучают два вопроса: как обеспечить бекап на уровне всей инфраструктуры и как мы будем обеспечивать бекап отдельных виртуальный машин?
В случае с Azure, на первый взгляд, встроенный Azure Backup позволяет нам успешно закрыть оба вопроса, но давайте посмотрим внимательнее.
Azure Backup действительно мощный и отличный инструмент. Это встроенный сервис, который может работать в двух вариантах: Azure Backup для бекапа инфраструктуры на уровне IaaS, и MARS — агентский бекап на уровне отдельных машин. Оба интегрированы в стандартный портал и по большей части одинаковы, кроме разницы в RPO: у Azure Backup он 24 часа (то есть бекап только раз в сутки), а у MARS 8 часов. Так себе варианты, если бизнес ставит вам задачу RPO не более часа. И другая проблема: доступ к бекапам будет у всех, кто имеет доступ к порталу Azure, что прямо противоречит пословице, ставящей в зависимость сохранность яиц от количества корзин. Отчасти это нивелируется функцией Soft Delete, которая гарантирует возможность доступа к удалённым данным в течение 14 дней после нажатия кнопки “Удалить”. Но и тут есть проблема — эту функцию можно отключить и никому не сказать.
И, возможно, значимый нюанс — данные в Azure хранятся в обычном сторадж блобе, где к ним будет применена компрессия, но не дедупликация. В условиях оплаты per instance + GB это может стать неприятной финансовой проблемой.
А что если вместо нативного Mars агента нам использовать Veeam Agent for Windows? Технических ограничений этому нет, поэтому можно смело внедрять такой вариант. Можно даже использовать расширенный вариант: подключить Azure Blob как часть Scale-out репозитория, в роли Capacity Tier. Помимо удобства, это позволит решить проблему случайно (и не очень) удалённых файлов бекапа.
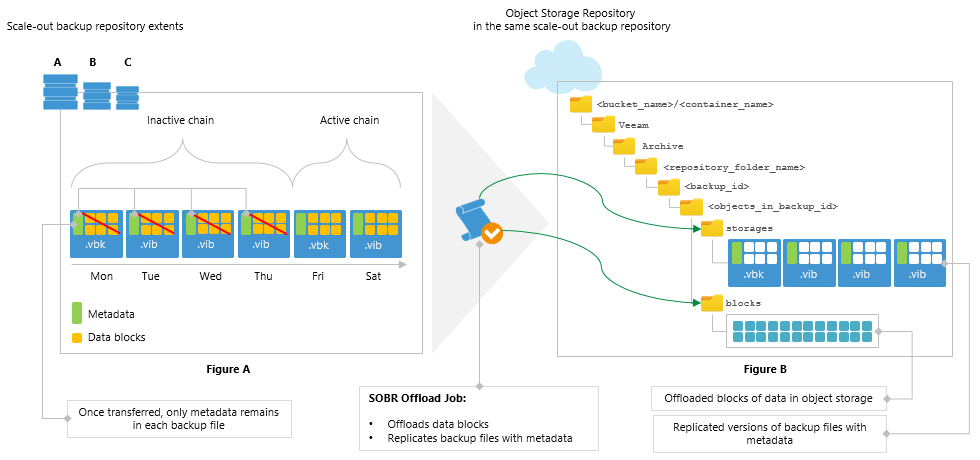
Вся цепочка будет выглядеть таким образом: создаём задание в имеющейся инсталляции Veeam B&R, агенты устанавливаются на целевые машины, делают бекапы. Согласно настройкам, бекапы сохраняются в репозитории и в завершение файлы бекапов загружаются в Azure Blob. Напрямую делать бекапы в блоб пока возможности нет, так как данные перед отправкой в любое объектное хранилище надо структурировать специальным образом. Подробнее об этом можете почитать в недавней статье про NAS Backup, где это было реализовано. В принципе, можно даже не опускать бекапы не землю, если развернуть сервер Veeam B&R прямо в Azure.
Да, этот вариант даст нам возможность выстроить более гибкий процесс резервного копирования со значительно меньшим RPO, однако в деньгах мы тут проиграем. Да и сама архитектура такого решения, скажем честно, выглядит громоздко. Поэтому двигаемся дальше.
В конце апреля мы выпустили уже полноценный продукт для бекапов ваших мощностей в Azure. Идеологически он схож с Veeam для AWS, но кроме того, что оба они позволяют не беспокоиться за данные в публичных облаках, функциональное сходство и заканчивается. В конце концов, Azure — это Hyper-V, а AWS базируется на KVM.
Но пора переходить от слов к делу, и давайте более внимательно рассмотрим наш новый продукт.
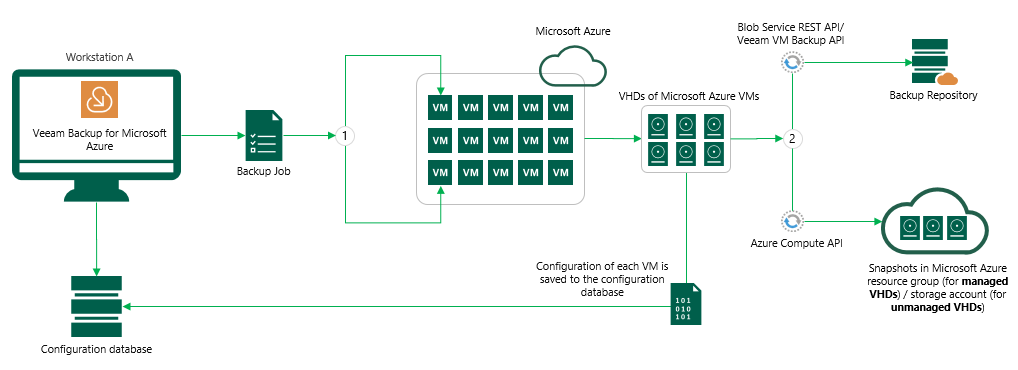
Итак, Veeam Backup for Microsoft Azure — это сервис, работающий внутри Azure и позволяющий бекапить машины и диски сразу в Azure блоб. На местах это выглядит как управляющая машина Veeam с Ubuntu 18.04 LTS на борту и дополнительно включаемые на время создания резервных копий машины воркеры. Управляющая машина занимается оркестрацией воркеров, ведением расписания, отслеживанием retention policy и запуском процессов создания бекапов, снапшотов и даже восстановления виртуальных машин. Словом, типичный мозговой центр.
У воркеров тоже есть свои особенности. Основная их задача не просто переложить данные из снапшота в блоб на хранение, а сделать это таким образом, чтобы количество транзакций (а значит, и итоговый чек клиента) было минимальным. Их количество масштабируется по принципу одна виртуальная машина в бекапной политике (аналог backup job из Veeam B&R), один работающий с ней воркер. Пока не будет создан бекап этой машины, воркер не переключится на следующую. Поэтому, чтобы не получить лавину новых машин при каждом запуске бекапа, максимальное и минимальное их количество задаётся явным образом в настройках. Если используется автоматический режим деплоя, то там система такая: указываете диапазон, например min — 3, max — 10. Значит в политике будет задействовано 10 воркеров. После завершения работы политики, спустя какое-то время, управляющая машина 7 удалит, а оставшиеся 3 выключит. Также воркеры можно размещать и вручную. Но в любом варианте воркеры будут размещены в той же ресурсной группе, что и машины в бекапе.
И да, бекап сохраняется только в Azure blob. Приземлить его сразу на землю не получится.
Для полноценного функционирования Veeam необходимо предоставить аккаунт с уровнем Azure Service Account. Он же Azure AD Application. Он будет использоваться для получения информации о всех необходимых ресурсах, таких как конфигурация машин, подписка, ресурсные группы, storage accounts, снапшоты, Azure Lighthouse и т.д. Из-за технических ограничений может быть использован только один сервисный аккаунт, который будет иметь доступ только к тому тенанту, где разворачивается управляющий сервер.
Когда наступает час Х, Veeam запрашивает конфиги машин и все VHD каждой машины. После этого создаются снепшоты дисков (а куда без них в наше беспокойное время), а конфиги машин сохраняются в базе на машине с Veeam (база PostgreSQL, вдруг кому интересно). Если вы используете managed диски (простите, но термин “управляемые диски” вызывает у меня смех), их снапшоты сохраняются в ресурсной группе машины. А при наличии unmanaged дисков их снапшоты остаются в оригинальном storage account. Затем данные сжимаются, шифруются и уезжают на хранение в Azure Blob Storage.
Теперь рассмотрим варианты создания бекапов. Их три:
- Сделать дерево Azure-native снапшотов
Всё ровно так, как и в любом гипервизоре: создаём снепшот, затем ещё один, и ещё один и так пока не подойдёт время удалить самый старый, согласно заданным настройкам. Снапшоты можно создавать как автоматически, так и оставить это действие на совести пользователя. Причем, если выбран автоматический режим, в случае неудачи будет предпринята попытка создать снапшот ещё раз. В ручном режиме такой роскоши нет. - Делать Azure-native снапшот, считывать с него данные и отправлять на хранение в блоб. Фактически, это полный аналог работы обычного Veeam B&R. Создаём снапшот, читаем данные, делаем цепочку файлов в бекапном репозитории. Просто здесь репозиторий будет находиться в блобе, и файловая структура будет нечеловекочитаемой.
- Просто сделать отдельный снапшот
В этом варианте никакой автоматизации, всё только вручную. Отличие от предыдущих двух вариантов в том, что данное действие может быть выполнено для любых ресурсов без добавления в политику. Правда, если сделать снапшот для участника любой из политик РК, он будет учтён в его ретеншн. Например, если у нас есть политика с настройками хранить 3 снапшота и мы создаём вручную четвёртый, то при следующем запуске политики создастся уже пятый. Поэтому, чтобы соблюсти ретеншн, будут удалены сразу два самых старых снапшота.
Кстати, о вариантах ретеншн. Их также три:
- Вышеупомянутое количество снапшотов. Если сказано хранить семь снапшотов, значит, после отрабатывания политики останется семь самых свежих снапшотов.
- Вариант, основанный на датах. Позволяет хранить бекапы не старше стольких-то дней/месяцев. Тут всё просто: говорим, что нам нужны бекапы за последние пять дней, значит, точка, созданная шесть дней назад, будет удалена.
- Глобальный ретеншн. Используется только для снапшотов для которых не задан ретеншн. Это контроль для созданных через “Take Snapshot Now” снапшотов, дабы не хранились вечно. На бекапы он не действует, так как для этого нет необходимости — ретеншен на них задан всегда, и всегда в днях. Так что даже если политика будет задизейблена или удалена, бекапы уйдут в означенный час.
Теперь самое время обсудить, как это всё лицензируется. Здесь есть изменения по сравнению с классическим Free/Paid.
Сначала зафиксируем, что именно лицензируется. Один объект лицензирования — это один Azure VM, для которого был создан хотя бы один бекап за последние 31 день. Но чтобы не городить огород технических терминов, мы в Veeam ввели понятие инстансов. Один инстанс, одна виртуалка, и не важно, где и какая. Хоть в облаке, хоть в on-premise гипервизоре.
Итак, как только вы устанавливаете приложение, сразу активируется бесплатная лицензия на 10 инстансов. Бери да пользуйся. Никаких ограничений по функциональности или времени использования. Но если попробовать забекапить одиннадцатую машину, Veeam выдаст ошибку и продолжит обслуживать только десять.
Второй вариант называется BYOL от Bring Your Own License. Конечно, совсем любая не подойдёт, но купленная у нас будет работать точно. Лицензия покупается на определённый срок.
Но мы не звери какие-то и прекрасно понимаем, что иногда люди забывают вовремя продлить лицензию или шестерёнки в процессах покупки у больших компаний могут просто не успеть провернуться, поэтому даже когда срок лицензии сойдёт на нет, Veeam продолжит полноценного работать ещё 30 дней.
А спустя и эти бонусные 30 дней, уж извините, все ваши настроенные политики превратятся в тыкву и прекратят работать. Кроме 10 бесплатных инстансов, конечно-же. Для всего остального останется возможность восстанавливать ранее забекапленное да вручную делать снапшоты.
Выхода из ситуации два: или покупать новую лицензию, или переключаться на Free license mode.
Как происходит распределение лицензий: они автоматически присваиваются на машины, участвующие в политиках бекапа, и отзываются, если машина не бекапилась 31 день. И, конечно же, есть механизм ручного переназначения лицензий.
Кстати, из мелких, но крайне удобных фич надо отметить наличие механизма оценки стоимости создаваемой политики бекапов. При любви облаков брать деньги за каждый чих этот пункт может а) помочь спланировать бюджет в) не оказаться должным миллионы.
И в завершении, блок полезных ссылок:
