Как Алиса узнаёт страны по фотографиям. Исследование Яндекса
Привет! Меня зовут Евгений Кашин, и я работаю в лаборатории машинного интеллекта Яндекса. Недавно мы запустили игру, в которой пользователи соревнуются с Алисой в угадывании стран по фотографиям.
Как действуют люди — понятно: они узнают места, которые видели в путешествиях или в кино, полагаются на эрудицию и здравый смысл. У нейросети ничего этого нет. Нам стало интересно, какие детали на снимках подсказывают ей ответ. Мы провели исследование, результатами которого сегодня поделимся с Хабром.
Этот пост будет интересен как специалистам в области компьютерного зрения, так и всем, кто хотел бы заглянуть внутрь «искусственного интеллекта» и понять логику его работы.

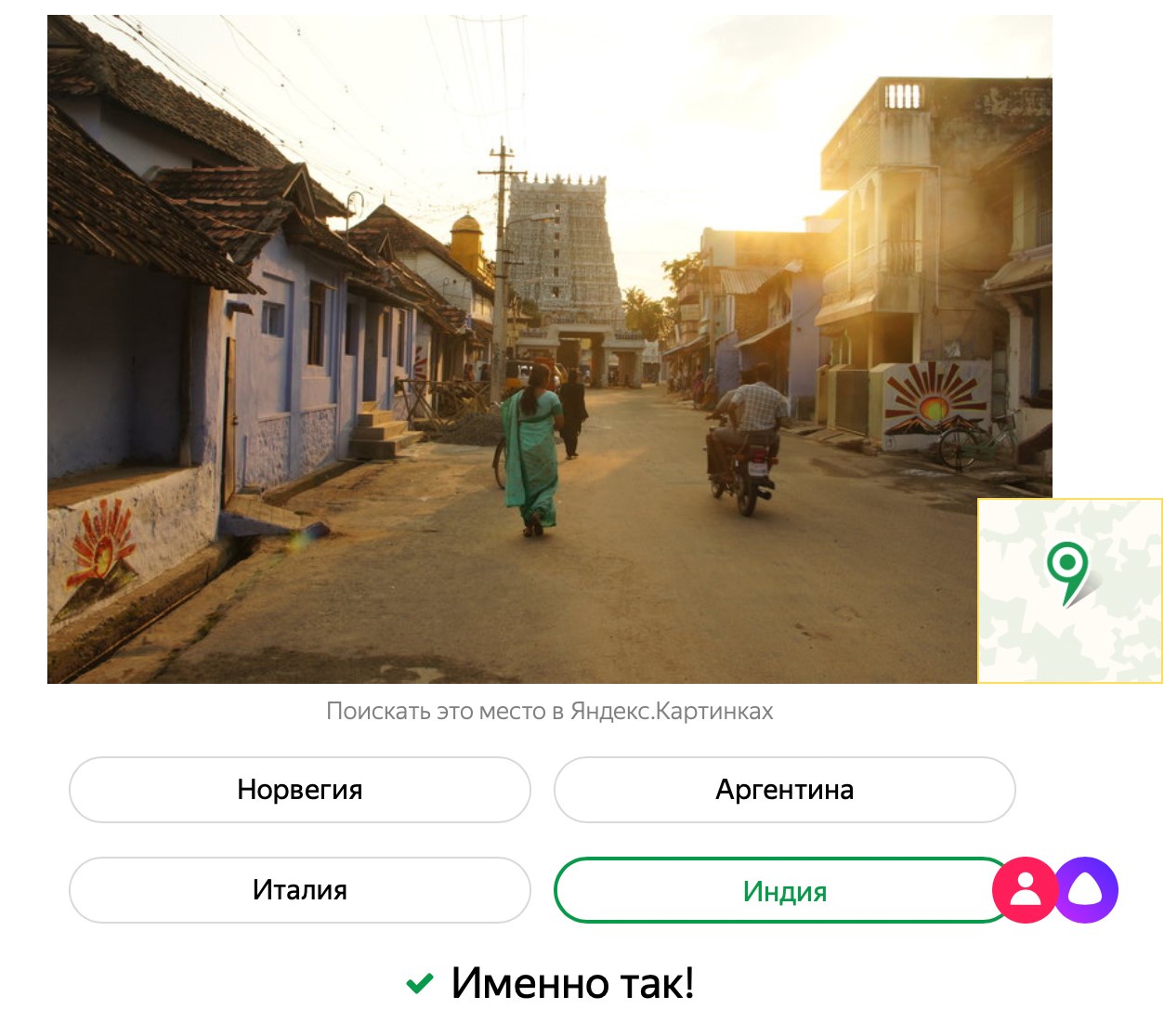
Несколько слов о самой игре «Угадай страну по фото». Если вкратце, мы взяли фотографии с Яндекс.Карт и разделили их на две группы. Первую группу показали нейросети, сообщив, где сделан каждый снимок. Просмотрев тысячи фотографий, нейросеть составила представление о каждой стране — т. е. самостоятельно выделила комбинации признаков, по которым можно её узнать. Вторую группу снимков мы используем в игре, их Алиса не видела и в процессе игры не запоминает. Алиса играет хорошо, но у людей есть преимущество: мы не обучали нейросеть распознавать номера машин, тексты вывесок и указателей, флаги государств.
Для игры мы обучили модель предсказывать страну по одной фотографии. Взяли модель компьютерного зрения SE-ResNeXt-101, предобученную на множестве задач. Признаки, получаемые из изображения с помощью этой свёрточной нейронной сети, достаточно универсальны, поэтому для классификатора стран понадобилось добавить лишь несколько дополнительных слоёв (так называемую голову). Для обучения использовали данные Яндекс.Карт: примерно 2,5 млн фотографий. Многие снимки не подошли для игры по критерию красоты и были отфильтрованы. Под красотой понимается совокупность факторов: качество фотографии, наличие людей, текста, леса, моря. Удалили похожие снимки одного и того же места, чтобы модель не запоминала конкретные достопримечательности. После всех фильтраций осталось около 1 млн фотографий. Обучив модель на этих данных, мы получили довольно точный классификатор, который определяет страну только по фото, не используя дополнительную информацию.
Так как классификация происходит с помощью нейронной сети, мы не можем легко получить интерпретацию предсказаний, в отличие от более простых линейных моделей или деревьев решений. Но нам хотелось выяснить, как нейронная сеть определяет по обычной фотографии улицы или дома, какая это страна. Причём интереснее всего случаи без достопримечательностей в кадре.
Для этого мы обучили нейронную сеть с нуля, подавая ей на вход не целые изображения, а лишь небольшие кусочки — кропы (чтобы модель не запоминала конкретные места или крупные объекты).
Таким образом задача для модели стала заметно сложнее (попробуйте угадать страну по кусочку неба), точность распознавания сильно снизилась. Но зато нейронной сети пришлось уделять больше внимания мелким деталям: необычной кладке, специфическим узорам, типу крыши, растениям. Размер подаваемых в модель кропов менялся, и получались различные модели, которые смотрели на фото на разных уровнях абстракции: чем меньше кроп — тем сложнее задача и тем внимательнее модель к мелочам.

К моделям, которые обучались на кропах разных размеров, можно применить алгоритмы для интерпретации предсказаний. Интерпретировать предсказания хотелось бы на исходных фотографиях. Большинство современных свёрточных сетей перед последним слоем используют Global Average Pooling (GAP) — это даёт возможность обучать сеть на одном размере, а применять на другом. Так получается благодаря тому, что перед последним слоем пространственные признаки, распределённые по ширине и высоте, усредняются в одно число для каждого канала (карты признаков — feature map). Поэтому модели, обученные на кропах (к примеру, 160 × 160 пикселей), можно использовать на исходных, больших изображениях (800 × 800).
На самом деле слой GAP нужен не только для использования модели на разных разрешениях или для регуляризации. Он также помогает нейронной сети сохранять информацию о положении объектов до самого последнего слоя (как раз то, что нам нужно).
Первый метод, который мы попробовали, — Class Activation Mapping (CAM).
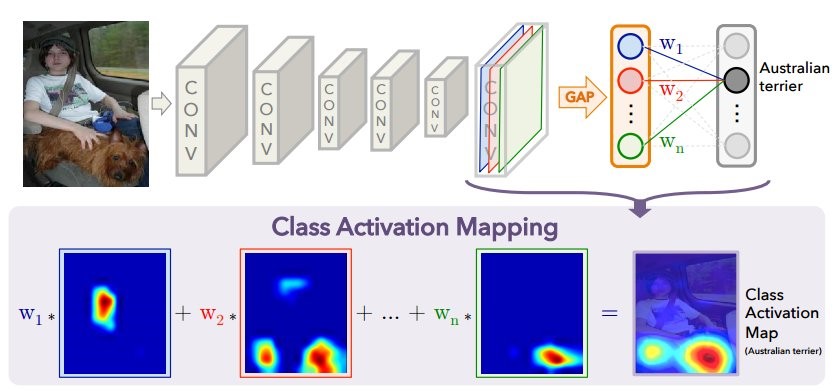
Когда изображение подаётся на вход нейронной сети, то на предпоследнем слое получается уменьшенное «изображение» (на самом деле тензор активаций) с самыми важными для каждого предсказываемого класса признаками. С помощью CAM-метода можно изменить последние слои так, что на выходе получится вероятность каждого класса в каждом регионе. Например, если нужно предсказывать 60 классов (стран), для входного изображения 800 × 800 финальное изображение будет состоять из 60 карт активаций размером 25 × 25. Это хорошо проиллюстрировано в исходной публикации.
На схеме сверху изображена обычная модель с GAP: пространственные признаки сжимаются до одного числа для каждого канала (карты признаков), после этого идёт полносвязный слой, предсказывающий классы, который находит оптимальные веса для каждого канала. Ниже показано, как изменить архитектуру, чтобы получить метод CAM: слой GAP убирается, а веса последнего полносвязного слоя, полученные при обучении с GAP (выше на схеме), используются для каждого канала в каждой точке. Для каждой картинки получается N карт активаций для всех предсказываемых классов. Для каждой страны — чем более яркая область на «карте», тем больший вклад внёс этот участок изображения в решение выбрать некую страну. Что интересно: если после этой операции усреднить каждую карту активации (по сути, применить GAP), то получится как раз изначальное предсказание для каждого класса.

На изображении вы видите карту активации для наиболее вероятного (по мнению модели) класса. Она была получена путём растяжения карты активации 25 × 25 до размера исходного изображения 800 × 800.
Получив такую карту для каждого изображения, мы можем агрегировать самые важные кропы для стран с разных изображений. Это позволяет посмотреть на коллекцию кропов, описывающих страну лучшим образом.
Второй метод, с которым мы решили сравнить первый, — простой перебор. Что, если взять модель, обученную на маленьких кропах (например, 160 × 160 пикселей), и предсказать ею каждый кусочек на большом изображении 800 × 800? Пройдя скользящим окном с наложением по каждой области на изображении, получим другой вариант карты активаций, показывающей, насколько вероятно каждый кусочек изображения относится к классу предсказанной страны.

Изображение нарезано на маленькие кропы с перекрытием размера 160 × 160. Для каждого кропа нейронная сеть делает предсказания, число над кропом — вероятность принадлежности к классу, который в итоге предсказала модель.
Как и в первом методе, мы опять можем выбрать наиболее вероятные для каждой страны кусочки. Но полученные обоими способами изображения для страны могут быть однообразными (например, здание с разных ракурсов или один вариант текстуры). Поэтому лучшие кропы для страны дополнительно кластеризуем — тогда большая часть похожих изображений соберётся в одном кластере. После этого будет достаточно взять одну картинку из каждого кластера с максимальной вероятностью — для каждой страны получится столько изображений, сколько задано кластеров. Мы делали кластеризацию на основе признаков, полученных с последнего слоя классификатора. Агломеративная кластеризация в нашем случае показала себя лучше всего.






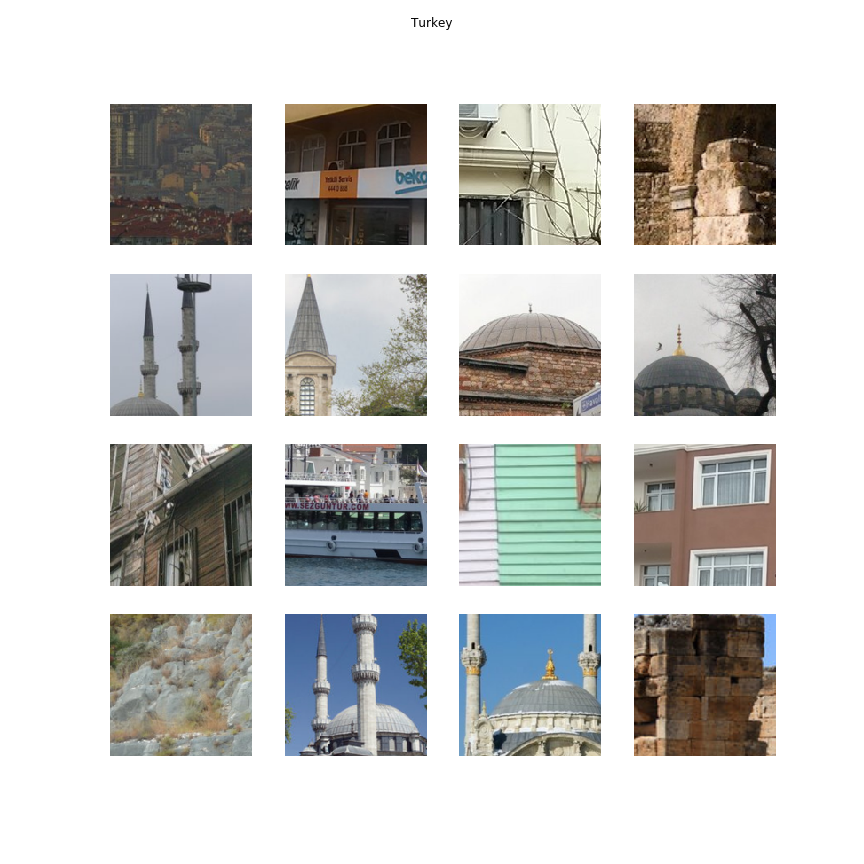

Получив достаточно похожий пайплайн для двух методов, можно перебрать параметры алгоритмов, чтобы найти оптимальную комбинацию. Например, мы подбирали размер кропов и остановились на двух вариантах: 160 и 256 пикселей. Кропы меньше 160 давали слишком мелкие признаки, по которым человеку часто непонятно, что изображено. А кропы больше 256 иногда содержали сразу несколько объектов. Различные параметры нуждаются в подборе на этапе кластеризации: выбор основного алгоритма, а также признаков, по которым проводится кластеризация. Для многих комбинаций параметров было сразу понятно, что они дают недостаточно «интересные» кропы. Но для выбора финального алгоритма мы проводили side-by-side эксперименты на Толоке, чтобы понять, какой вариант, по мнению людей, более «подходяще» описывает конкретную страну.
Неинтуитивным оказалось то, что более простой метод нахождения кропов на картинке (обычный перебор) находит более «интересные» объекты. Это может быть связано с тем, что во втором методе (перебор) нейронная сеть не видит соседнюю часть изображения, а в CAM-методе окружение точки влияет на результат. В итоге мы получили визуализацию характерных черт каждой страны в автоматическом режиме.
Так что теперь мы знаем, какие части кадра имеют определяющее значение для нейросети, и можем посмотреть, что на них попало. Например, Нидерланды нейросеть узнаёт по сочетанию тёмных кирпичных стен и белых контуров окон, ОАЭ — по специфическим небоскребам на фоне пальм, а Иран — по характерным аркам и орнаментам на фасадах.
