Как я упрощал процесс работы над опенсорс проектами

В данной статье я расскажу, как я пытался поучаствовать в разработке какого-нибудь крупного опенсорс проекта, возненавидел себя, а потом автоматизировал рутину и научился радоваться жизни. Детали — под катом.
Зачем это вообще нужно?
Обычно разработчики хотят поучаствовать в жизни опенсорс сообщества по нескольким причинам. Вот некоторые (и, вероятно, не все) из них:
- в благодарность за возможность пользоваться этой и другими программами бесплатно
- получение нового опыта
- чтобы прокачать своё резюме
Меня всегда в первую очередь привлекала возможность узнать что-то новое, впитать лучшие практики по разработке ПО, но все остальное не менее приятный довесок в этом процессе.
Хорошо, я в деле, с чего мне начать?
Первое, что надо сделать — найти задачу, над которой поработать. Вы настоящий везунчик, если вам по рабочим нуждам понадобилось доработать какую-то библиотеку — заводите задачу, обсуждайте с владельцами и приступайте к реализации! В ином случае можно обратиться к списку открытых задач на странице проекта и подобрать себе что-нибудь. Найти подходящую — не менее важная часть, чем ее реализация, и здесь не все так просто. Даже если вы опытный инженер, то может быть полезным начать с задач попроще, ознакомиться с кодовой базой, принятыми процессами разработки и лишь потом браться за фичу побольше.
Как находить задачи для начинающих?
Некоторое время тому назад, github начал показывать подходящие задачи для новичков.
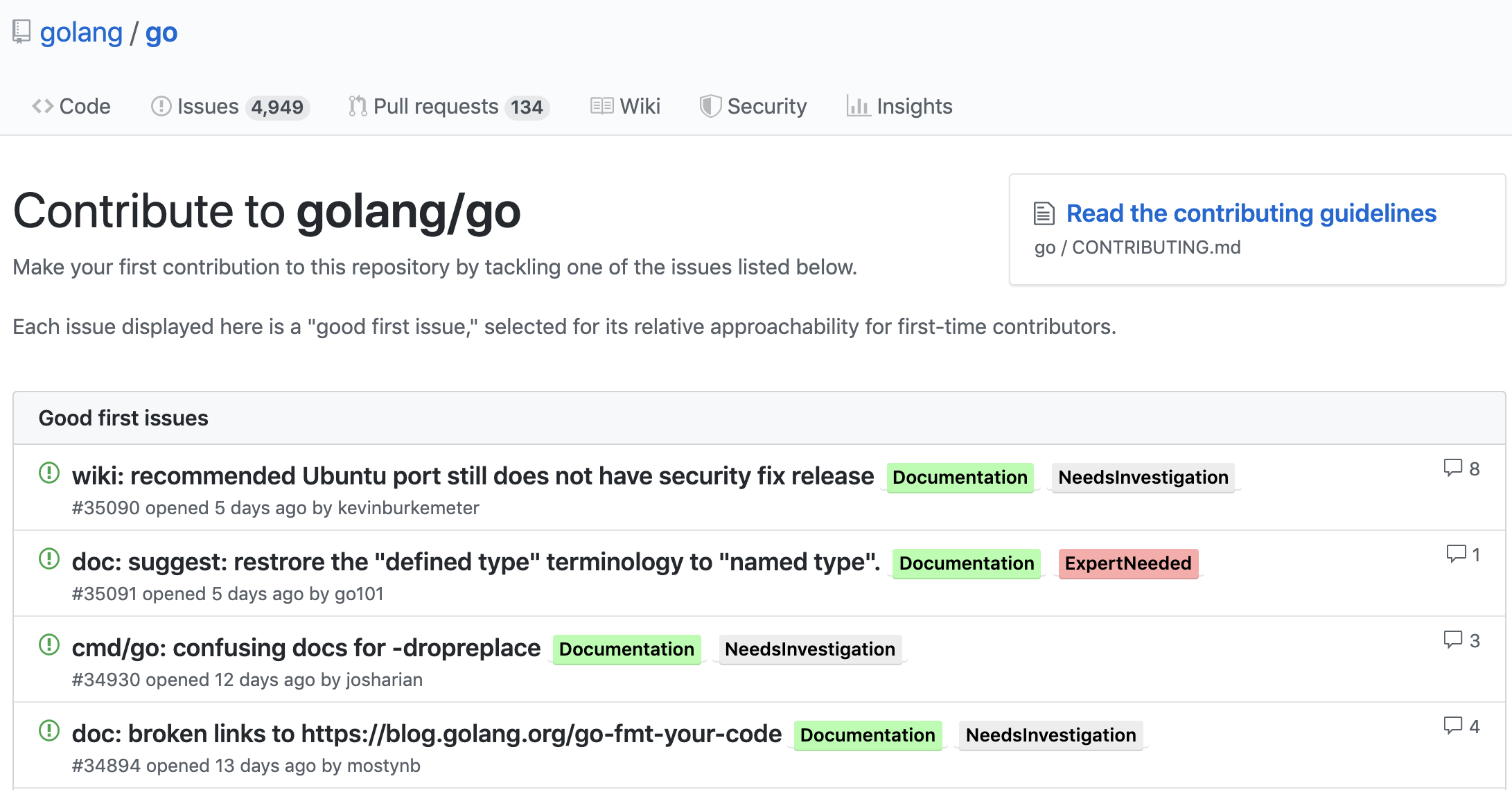
Остановившись на этих «инструментах», мой обычный день стал выглядеть так — я открывал список проектов, над которыми хотел поработать (чтобы держать их под рукой, я пометил их всех зведочками), заходил на вышеуказанную секцию или через поиск перебирал нужные метки, попутно разыскивая те, что используются именно в этом проекте. Стоит ли говорить, что обход 40–60 репозиториев стоил огромной кучи сил и быстро наскучивал мне. В процессе я становился раздражительным, терял терпение и забрасывал это дело. В один из таких дней я понял, что могу автоматизировать процесс перебора и приступил к составлению ТЗ.
Требования
- Задача должна быть открытой
- Задача ни на кого не назначена
- Задача должна быть помечена меткой, обозначающей простоту и открытость для сообщества
- Задача не должна быть слишком старой
После этого я начал анализировать разные репозитории на предмет используемых меток. Оказалось, что есть огромная куча самых разных меток, часть из которых уникальна для конкретных репозиториев/организаций. С учетом регистронезависимости я составил список из ~60 меток
Разработка решения
В качестве инструмента я решил использовать уже знакомый мне Kotlin и реализовал следующий алгоритм: пройтись по всем репозиториям, помеченным звездочкой, достать оттуда все задачи, подходящие под требования, отсортировать по дате изменения, отбросить слишком старые и отобразить. Результирующий список разделен временными метками — за сегодня, за вчера, за прошедшую неделю, за месяц и все остальное — благодаря этому стало сильно удобнее пользоваться программой на регулярной основе. Я решил, что на первом этапе приложение будет консольной утилитой, поэтому вывод идет просто в stdout.
Результат я обернул в docker образ, ожидая, что у человека с большей вероятностью будет установлен docker нежели чем JRE. Утилита не хранит никакого состояния, поэтому каждый запуск будет выполнять весь алгоритм целиком, а отработавший контейнер можно спокойно удалять из системы.
Вот как выглядит процесс работы программы:

Ограничение количества запросов
Обращение к API стороннего сервиса является классическим примером io-intensive задачи, поэтому естественным образом было решено начать грузить данные в несколько потоков. Методом проб и ошибок я познакомился с ограничениями Github API. Во-первых, при большом количестве потоков срабатывала anti-abuse проверка на стороне Github и мне пришлось остановиться на 10 потоках по умолчанию, с возможностью конфигурации через входные аргументы.
Во-вторых, существует ограничение на количество запросов — их можно сделать не больше 5000 в час. С этим ограничением все намного сложнее, так как при передаче нескольких меток в поисковой запрос Github ставит между ними логическое 'И' и, учитывая количество меток в списке, с почти 100% вероятностью ничего не найдет. Столкнувшись с большими тратами обращений к API, я стал делать дополнительный запрос за всеми метками, которые есть в проекте, брать пересечение с моим списком и поштучно запрашивать задачи только по этим меткам. Добавив 1 запрос на каждый репозиторий, я избавился от 50–55 лишних запросов (чем больше меток поддерживает программа, тем больше лишних запросов) за задачами по несуществующим для репозитория меткам.
Тем не менее, для некоторых юзеров и этой оптимизации может быть недостаточно. По поверхностной оценке текущее решение позволяет обойти 1000 репозиториев (в коде также есть жесткое ограничение), ожидая, что в среднем в каждом репозитории встречается 4 простые метки. С таким ограничением пока никто не столкнулся, но идея решения есть в бэклоге. Тут все просто — хранение стейта, кэширование ответов, в особо тяжеловесных случаях медленно обходить в фоне.
Как найти репозитории?
Если вы еще не такой активный пользователь Github или не используете функционал звезд, то вот несколько советов, как найти подходящие репозитории:
- Пройдитесь по технологиям, которые вы используете на своих проектах, возможно часть из них представлена на Github
- Воспользуйтесь разделом популярных трендов
- Воспользуйтесь репозиторием awesome-lists по интересующим вас темам
Запуск
Для запуска потребуется:
С остальными настройками (фильтр по языку, уровень параллелизма, черный список репозиториев) можно ознакомиться на странице проекта. Ссылка на проект — https://github.com/igorperikov/mighty-watcher
Если вам не хватает каких-то меток в проекте — создавайте PR или пишите мне в личку, добавлю.
