Как я сделал синтез своего голоса
Всем привет! Меня зовут Гриша Стерлинг, я занимаюсь синтезом речи в SberDevices. Создать новый голос для синтеза — это долго и дорого. Мы постарались сделать этот процесс проще и доступнее, и в итоге я сам смог записаться на студии, а потом обучить модель разговаривать моим голосом. Получилось неплохо, поэтому я решил написать большую статью с деталями. Она будет интересна датасаентистам, людям из бизнеса и ai-энтузиастам. Приглашаю всех под кат.
Введение
Я озвучил эту статью целиком, чтобы было понятно, как работает наша технология. Чтобы всё было честно, никакие ударения и интонации не исправлял.
Синтез речи — это сложная задача с кучей особенностей. Обычно требуется по тексту предсказать несколько десятков тысяч чисел, которые образуют так называемую вейвформу — дискретное представление звука в компьютере. Чаще всего эту задачу решают в два этапа: акустическая модель предсказывает промежуточное частотно-временное представление звука (мел-спектрограмму), а затем её результат озвучивается вокодером.
Самое интересное тут — это акустическая модель. Она отвечает за просодию, то есть за то, как будет произнесён текст: интонация, тембр, эмоции и всё такое. Это очень важно: иногда от того, на какие слова сделаны акценты, зависит смысл предложения. В результате работы акустической модели текст преобразуется в мел-спектрограмму, в которой закодирован сам текст, а также голос и просодия.
Второй этап синтеза состоит в озвучивании мел-спектрограммы особой моделью — вокодером. Он тоже должен быть качественным, иначе синтез получится металлическим или с артефактами.
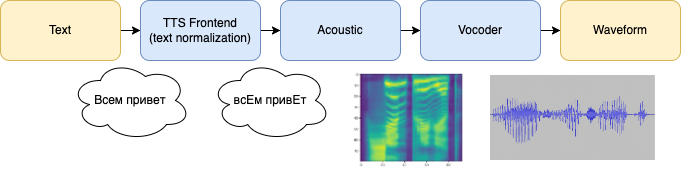 Обычно системы синтеза речи выглядят вот так
Обычно системы синтеза речи выглядят вот так
Отдельно хочу сказать про важность данных, на которых учится модель. Именно от них напрямую зависит, какой у нас получится голос. Для качественного синтеза нужно реально много данных — минимум 10 часов студийных записей, а лучше 20 или 50. Обычно за час работы диктора получается записать 5–15 минут готового материала. Учитывая такой низкий КПД, диктор может месяцами проводить в студии. Это делает процесс создания нового голоса очень затратным по времени и другим ресурсам.
У нас получилось удешевить этот процесс. Мы сделали технологию, которая позволяет обучать высококачественные модели, имея всего 5–30 минут записей. Я протестировал её на своём голосе (по-моему, получилось неплохо), а раньше модели на таком количестве данных вообще бы не заговорили. Ниже делюсь секретами, как нам это удалось.
Обзор технологий
Первый нейросетевой синтез хорошего качества был показан в статье про Tacotron 2. Трансформеры тогда ещё не захватили весь мир: это обычная для 2017 года encoder-decoder-attention генеративная модель на свертках и рекуррентках. Каждый модуль такотрона сам по себе довольно прост. Например, энкодер состоит из нескольких сверточных слоев по буквам и lstm-рекуррентки, которые получают представление каждой буквы или фонемы с учётом контекста.
Декодер является авторегрессионным: он принимает на вход предыдущее предсказание, а также вектор контекста. Вектор должен кодировать букву, которая синтезируется в текущий момент. Откуда он знает, что это за буква? За это отвечает механизм внимания (location sensitive attention), который спроектирован таким образом, чтобы обучиться восстанавливать соответствие между текущим моментом времени и буквой из обучающего примера. Когда спектрограмма сгенерировалась, она уточняется с помощью postnet, а затем озвучивается качественным, но очень медленным вокодером WaveNet.
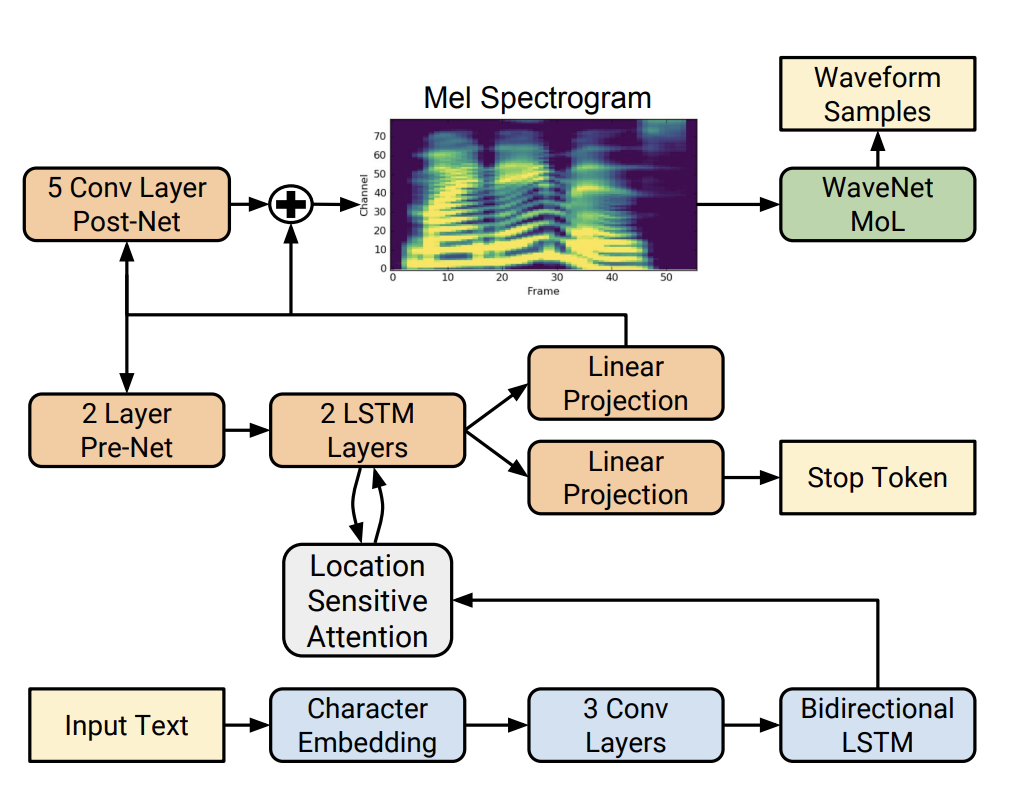 Внутреннее устройство архитектуры Tacotron 2
Внутреннее устройство архитектуры Tacotron 2
Такой сетап позволил синтезировать речь, почти неотличимую от человеческой. Тут есть несколько важных оговорок:
Модель всё равно иногда делает странные интонации
Скорость синтеза будет низкой, даже если заменить вокодер на быстрый
В приложениях хочется иметь инструмент по ручному управлению интонациями
Дальнейшие исследования TTS-сообщества были направлены на улучшение общего качества и ускорение моделей. Например, так родилось семейство не авторегрессионных акустических моделей Fastspeech. Их общая идея такая: особый модуль duration predictor предсказывает длительность звучания каждой фонемы, а затем декодер предсказывает нужное количество фреймов спектрограммы. Модель очень быстро за один проход синтезирует аудио целиком, но проблемы с качеством не решились, скорее наоборот. Мы пробовали такие модели, но в наших экспериментах речь стала менее «живой» на слух, а также проигрывала другим моделям по метрикам.
Про нашу модификацию такотрона — q-taco — мы уже писали. Он работает так: до обучения для каждого слова в предложении считаются фичи — питч, громкость и скорость. Они кодируют то, как было произнесено каждое слово. Затем q-taco учится с такими подсказками восстанавливать более сложные зависимости. На инференсе эти параметры предсказываются по смыслу отдельной нейронкой с помощью языковой модели. Потом q-taco принимает их на вход и синтезирует звук.
Питч
— частота основного тона, он же f0, он же частота колебаний голосовых связок. Это не единственный, но важный орган речевого тракта человека. Они представляют собой натянутые мембраны, которые колеблются при прохождении через них воздушного потока. Частота, с которой они это делают, зависит от их натяжения, и в целом является очень важной характеристикой речи.
Другими словами, мы разбили сложную задачу синтеза на две попроще: «текст» → «параметры речи» и «текст + параметры речи» → «речь». Судя по нашим экспериментам, такое разделение обязанностей позволяет делать синтез более качественным.
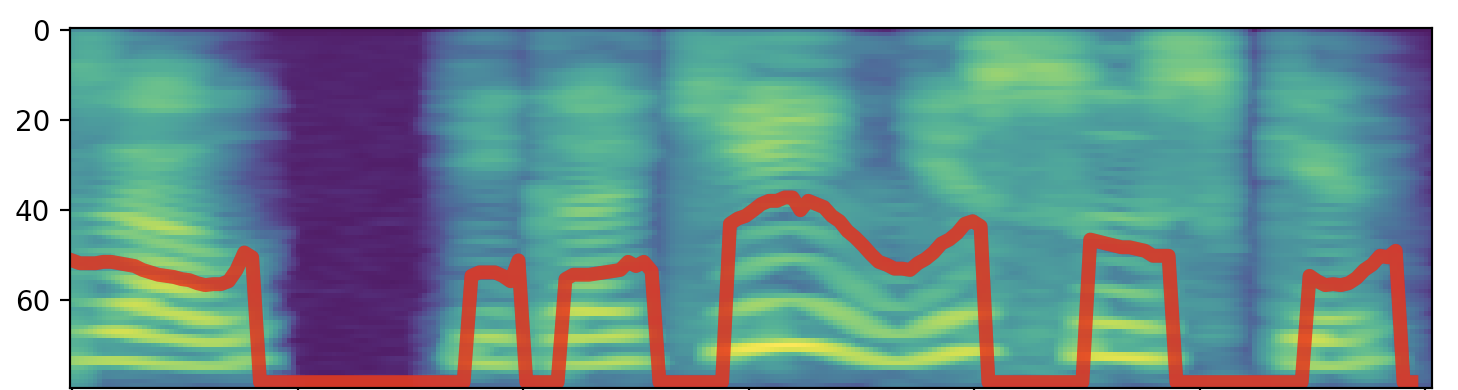 Так выглядит контур частоты основного тона и спектрограмма 3-х секунд речи
Так выглядит контур частоты основного тона и спектрограмма 3-х секунд речи
Больше данных — лучше сетки
Все люди разговаривают примерно одинаково. Я имею в виду, что паттерны питча и остальных фичей у разных людей, прочитавших один и тот же текст, очень похожи. То есть, существуют правила, по которым люди интонируют. Их сложно формализовать, поэтому здесь нам понадобится больше данных, чтобы модель для предсказания просодии была максимально точной.
Моделирование просодии
Просодия — совокупность того, как было что-то произнесено. Это понятие сложно формализовать числами, поэтому как некоторое приближение мы выбрали несколько параметров — питч, громкость и скорость — и дискретизовали их, чтобы потом предсказывать NERC-like моделью. Но в реальности богатство человеческой речи не ограничивается этими фичами. Поэтому нужно провести более глубокий feature engineering — сегодня это одно из основных направлений нашей работы.
Подавляющее большинство TTS-моделей — singlespeaker. Они учатся воспроизводить ровно один голос, из которого состоял датасет. В этом случае одному конкретному диктору нужно провести безумное количество часов в студии. Нас это не устраивало, поэтому мы попробовали обучить multispeaker на тех данных, которые уже собрали. На тот момент это было 9 уникальных голосов, каждый в среднем по 80 часов студийных записей. Удивительно, но выросло не только качество предсказания просодии вспомогательной сеткой (в нашем случае — набора фичей для каждого слова), но и общее качество q-taco.
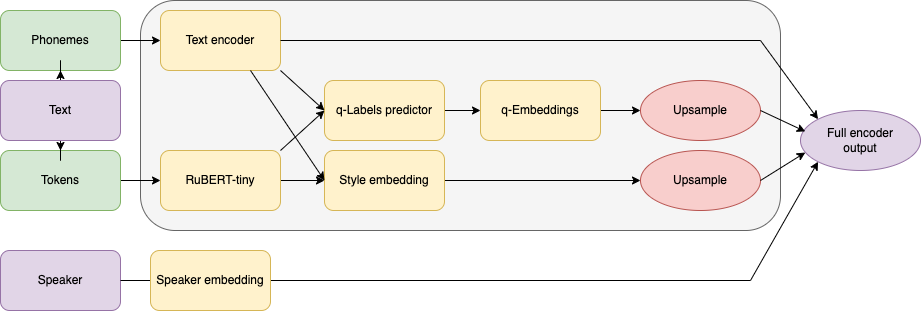 Схема энкодера нашей акустической модели. Кодирующий спикера вектор конкатенируется к выходу singlespeaker энкодера (он обведен серым прямоугольником)
Схема энкодера нашей акустической модели. Кодирующий спикера вектор конкатенируется к выходу singlespeaker энкодера (он обведен серым прямоугольником)
На качество разумно смотреть не в общем, а по каждому голосу отдельно. Мы заметили, что выигрыш тем больше, чем меньше данных для обучения. Другими словами, одна большая модель на много голосов подтягивает по качеству те голоса, у которых мало данных, до уровня тех голосов, у которых много данных. Мы пошли дальше и захотели выяснить, сколько вообще нужно данных, чтобы модель заговорила. Мы рассмотрели несколько важных субъективных характеристик синтеза: тембр, чёткость, богатство и естественность.
Количество данных | Тембр | Четкость | Богатство | Естественность | MOS | PSER |
5 минут | Да | Иногда нет | Нет | Да | 4.12 | 17.8 |
10 минут | Да | Да | Нет | Да | 4.23 | 14.9 |
15 минут | Да | Да | Частично | Да | 4.46 | 12.8 |
30 минут | Да | Да | Да | Да | 4.44 | 12.6 |
Богатством синтеза я назвал воспроизведение индивидуальных особенностей спикера — в первую очередь широту экспрессии, но сюда же можно отнести, например, дефекты речи, эмоции или особенные привычки в интонациях. Другими словами, значение этой метрики «нет» говорит, что синтез получился скучный. Это самая важная метрика, показывающая качество нашего low-resource синтеза. А остальные метрики являются скорее необходимым минимумом: синтез должен повторять голос прародителя, говорить без зажевываний и быть естественным. Табличку выше я заполнял субъективно, опираясь на свой слух, отслушав кучу голосов.
Отдельно расскажу про объективные метрики. Обычно в работе мы используем так называемый SBS — озвучиваем набор текстов двумя системами синтеза и спрашиваем асессоров, что им нравится больше, затем усредняем их ответы. Метрика показывает, что модель A пользователи предпочитают на X процентов чаще модели B. Это хорошая статистически мощная и интерпретируемая метрика, которая позволяет корректно сравнивать две похожие модели. Но для новых голосов она неприменима, потому что есть только один синтез этим голосом, который мы только что обучили. Поэтому мы используем mean opinion score (mos) и pronunciation sentence error rate (pser). Первая из них часто используется в статьях и показывает среднюю оценку от 1 до 5 для разных аудио. Вторая показывает, как часто синтез делает явные ошибки в интонациях, паузах и дикции. Кстати, у записей со студии значения mos и pser зависят от голоса и прыгают около 4.5 и 5–15% соответственно.
По табличке видно, что где-то между 15 и 30 минутами происходит переход от скудного синтеза к богатому. Где именно он произойдет — зависит от голоса, а закономерность тут такая: чем более однообразная речь диктора, тем проще её синтезировать и тем меньше данных нужно. Интересно, а крик — это однообразная речь?
Оказывается да, потому что люди кричат примерно одинаково. Мы записали кричащего диктора и обучили такую же мультиспикер модельку, получилось круто. Ставь лайк, если хочешь, чтобы этот голос отвечал на звонки спамеров.
После такого эксперимента стало ясно, что мы можем обучать удивительные голоса. Мы собрали небольшой пантеон персонажей. Среди них есть упомянутый выше кричащий голос, а также злобный, геройский, рассказывающий сказки на ночь, а также эмоции, шёпот, детские голоса и другие.
Про шёпот хочется рассказать отдельно. Он отличается от обычной речи тем, что когда мы шепчем, у нас не работают голосовые связки — орган речевого тракта человека, отвечающий за тембр и интонации. Звук получается глухим, и на спектрограмме это видно невооружённым глазом.
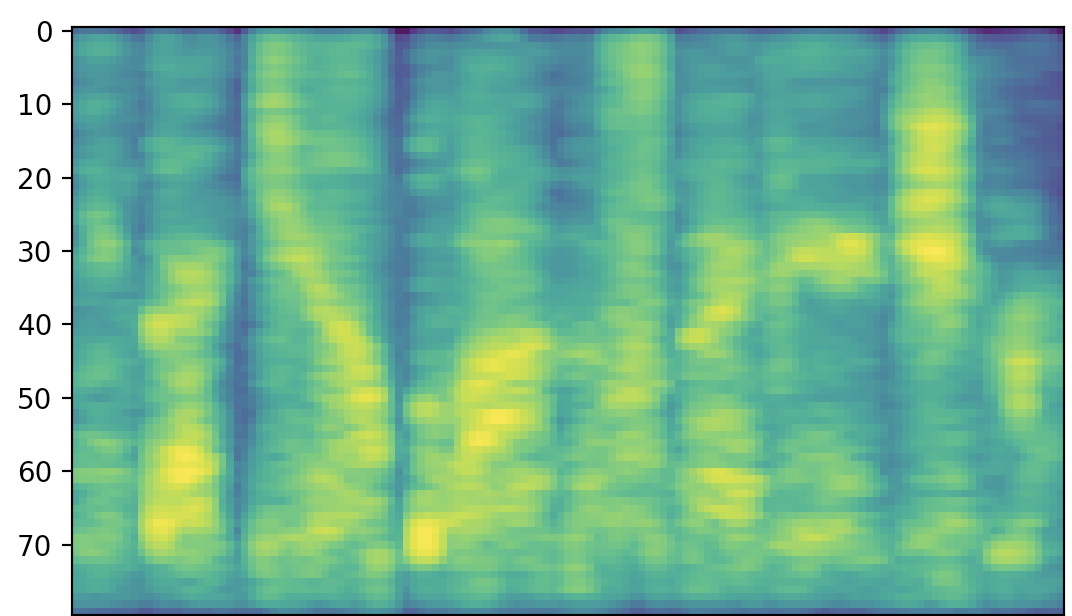 Спектрограмма шепота. На ней пропали характерные для обычной речи «полоски», которые появляются из-за голосовых связок.
Спектрограмма шепота. На ней пропали характерные для обычной речи «полоски», которые появляются из-за голосовых связок.
Со стороны архитектуры модели мы сталкиваемся со сложностью: ванильный q-taco принимает на вход три фичи, связанные с питчем, но для шёпота они не определены. В итоге пришлось чуть-чуть упростить архитектуру модели, а также уменьшить количество голосов в обучении. Чтобы оставить общее качество на таком же уровне, пришлось записать больше данных с шёпотом, а ещё частично пропала возможность управлять интонацией вручную. Но в итоге получился приятный шёпот, который мы зарелизили вместе с нашими новыми умными колонками SberBoom и SberBoom Mini. Послушать его можно в СБОЛе и на наших умных устройствах.
Paint
Выше я затронул тему управляемого синтеза речи. Это очень важная история для приложений. Там синтез является частью какого-либо большого продукта, например, автоматизированного колл-центра. Возможность управления синтезом решает сразу две больших сложных задачи: «красить траву», когда дефолтный синтез косячит, и управлять указанием вопросительного слова, когда без контекста невозможно определить, на какое слово нужно поставить акцент. Более подробно про синтез вопросительных предложений мы рассказали на Salute AI Day. Там мы затронули только базовое качество, но в реальности нередки следующие ситуации. Пример из жизни одного ассистента (нужно синтезом задать пользователю вопрос):
«ПОСТАВИТЬ будильник на восемь?»
«поставить БУДИЛЬНИК на восемь?»
«поставить будильник на ВОСЕМЬ?»В зависимости от того, что именно мы хотим узнать у пользователя, нужно сделать интонационное ударение на разные слова. Если поставить ударение не на то слово, то пользователь ответит не на тот вопрос, а мы получим не тот ответ. В примере выше нет одного объективно правильного слова, на которое нужно сделать ударение. Как нужно знает только человек, который проектирует сценарий общения с пользователем. Отсюда вырастает необходимость иметь под рукой инструмент ручного контроля за интонациями.
Мы назвали его Paint в честь старого графического редактора, который выглядит грубым и угловатым, но при должной сноровке позволяет создавать красоту.
Как он работает: q-taco помимо букв необходим набор меток, которые кодируют то, как нужно прочитать каждое слово в предложении — его скорость, громкость, средний питч, а также две фичи про наклон питча, которые описывают восходящий или нисходящий тон. Каждая фича имеет градацию от 1 до 5 — от самой низкой до самой высокой в обучающем датасете. В обычных условиях эти метки предсказываются с помощью языковой модели по смыслу, но их можно и задать вручную. Именно это делает наш Paint — меняет предсказание нейронки на то, что нужно человеку. Это можно делать как на уровне слов, так и на уровне всего предложения, причём естественным образом, переходы не будут слышны.
Возможность управлять синтезом полностью перекочевала от ванильного q-taco к мультиспикеру, обученному на low-resource голосах. Как это звучит на примере моего голоса:
А выглядит на стандартном для всех tts-движков языке разметки ssml так:
я умею говорить быстро.
я умею говорить медленно.
я умею говорить низко.
я умею говорить высоко.
Но это не единственное приятное наследие. Когда-то давно мы хотели решить проблему с вопросами другим способом и записали большой интонационный корпус — попросили дикторов озвучить предложения типа »*время пить чай», «время *пить чай», «время пить *чай», где слово после звездочки нужно было очень чётко выделить интонацией — лингвисты называют это эмфазой.
Мы обучили мультиспикер и удивились тому, что эмфаза хотя бы вполсилы работает и у тех спикеров, которые не записывали интонационный корпус.
YourVoice
В итоге у нас получилась технология, которая позволяет обучать модели синтеза крутого качества с вишенками на торте типа эмфазы и Paint. Мы сделали из неё готовый продукт YourVoice для внешних заказчиков, позволяющий им всего за пару недель создать собственный уникальный голос или выбрать готовый голос из нашего каталога. Более подробно о решении можно узнать по ссылке, а ниже расскажу, как оно работает.
Создание голоса начинается с данных. Диктор приходит на студию и записывает заранее подобранные тексты. Важно, чтобы они покрывали непопулярные сочетания букв и интонаций. Процесс записи контролирует войс-коуч. Про его работу мы подробно рассказывали здесь. Войс-коуч следит, чтобы всё было естественно, характер персонажа соблюдался, а голос не садился. Всего на студии я провёл ровно 3 часа и озвучил около 800 самых разных предложений. Актёр из меня не очень, и даже игровые реплики я всё равно читал монотонно, будто новости. Это, конечно, повлияло на качество синтеза. Но у вас, уверен, получится ярче:)
После записи данные необходимо обработать: убрать неудачные дубли, уточнить ударения и границы аудио. После такой разметки получается 25–30 минут чистейших данных, на которых можно обучать синтез.
Сейчас приходится учить модель с нуля, а не дообучать уже готовые модели — так по нашим экспериментам получается наилучшее качество. Для этого требуются GPU и куча времени. Вообще сейчас это узкое место, и в будущем мы научимся учить модельки намного быстрее. А пока обучение занимает примерно 4–5 дней.
Кстати, учится не только акустика, но ещё и вокодер. Нам очень нравится LPCNet — это маленькая авторегрессионная нейронка, которая внутри себя очень эффективно использует физику звука. Сложно в паре предложений объяснить, почему этот вокодер такой классный, но под катом ниже я постарался это сделать. А тут скажу, что ему достаточно всего лишь 5 минут звука, чтобы выйти на плато по качеству — это удивительный и приятный результат.
LPCNet
С точки зрения физики звук — это довольно стационарный процесс, спектр которого слабо меняется со временем (соседние фреймы на спектрограмме очень похожи). Есть теорема Хинчина-Колмогорова, которая связывает автокорреляционную функцию со спектром. Отсюда вырастает возможность представить эн плюс первое значение звукового сигнала как линейную комбинацию какого-то числа прошлых значений, а коэффициенты будут довольно просто высчитываться из спектра. Так мы с помощью формул моделируем довольно сложные зависимости в звуке, но реальность оказывается сложнее — всегда есть что-то, что сложно объяснить формулами. Для этого мы учим простейший WaveRNN для предсказания остаточного сигнала. В итоге получается шустрый и качественный вокодер LPCNet, который озвучивает спектрограммы. Его приходится учить для каждого голоса отдельно, но данных для этого нужно совсем мало.
После обучения модель готовится к выкатке в продакшн. Мы разбиваем q-tacotron на отдельные модули, а потом конвертируем их в нужный формат (onnx, trt, а иногда даже пишем кернелы на cuda). Это ускоряет инференс сеток, а также позволяет делать стриминговый синтез. Он нужен, чтобы начать проигрывать синтезированное аудио ещё до того, как оно досчитается до конца. Так задержка между запросом и синтезом становится очень маленькой.
На самом деле, в продакшне крутится не только акустическая модель с вокодером, а ещё так называемый фронтенд синтеза речи. Он решает задачу перевода ненормализованного текста с числами, сокращениями и омографами в правильный для синтеза формат, где все слова написаны прописью с проставленными ударениями. Придумал такой искусственный пример:
«Все хорошо, 20.02.23 сестры рыжей белки попали в камеру, сообщает журнал Science»
->
«всЁ хорошО, двадцаАого февралЯ двАдцать трЕтьего гОда сЁстры рЫжей бЕлки попАли в кАмеру, сообщАет журнАл сАйенс»Здесь добавилось ё в слове всё, дата раскрылась в нужном падеже, транслит перевёлся в русские буквы, а в омографах и остальных словах проставились ударения. Все эти задачи решаются у нас разными алгоритмами с приличной точностью. Когда-нибудь мы расскажем про них отдельно.
Спасибо, что дочитали или дослушали до конца! В конце хочу оставить традиционный call to action: приходите к нам обучать голоса для своего бизнеса или решать интересные задачи в нашей команде. Ещё у нас есть чатик в Telegram, там можно задать вопросы. До скорого!
