Как я провёл лето: летняя школа-практикум «Компьютерный континуум-2014»
Добрый день всем! Хочу рассказать о своём опыте участия в летней школе «Компьютерный континуум-2014», где я читал свой курс. Мероприятия школы проходили с 25 по 30 августа. Однако я попал только на три дня, в которые проводились тренинги: с 26 по 28 число. И хотя на непосредственно мероприятиях я пробыл лишь три дня, подготовка заняла значительную часть лета вне отпуска. Задача передо мной стояла непростая.
И хотя на непосредственно мероприятиях я пробыл лишь три дня, подготовка заняла значительную часть лета вне отпуска. Задача передо мной стояла непростая.
Необычная для меня площадка. Я давно не проводил занятий вне стен офиса или своего родного МФТИ. Сжатые сроки проведения. Обычно свой курс я читаю в течение семестра или даже учебного года. Что можно успеть за три дня? Пришлось тщательно ограничивать и балансировать объём теории и практических задач, которые я мог бы выплеснуть на слушателей. Мне был совершенно неизвестен уровень подготовки публики. Работая со студентами одного курса, можно примерно представлять, что они уже проходили; кроме того, обычно мы их собеседуем. Кто будет на этой школе и каков будет уровень их подготовки — для меня было загадкой. И в самом деле, люди пришли очень разные (об этом далее). О школеМероприятие проходило при участии следующих организаций и компаний: Санкт-Петербургский государственный университет, Санкт-Петербургский государственный политехнический университет, Северный арктический федеральный университет им. М.В. Ломоносова (г. Архангельск), Фонд Эйлера (СПб), Нижегородский фонд содействия образованию и исследованиям, Intel, EMC, JetBrains. Участникам школы было предложено на выбор несколько треков занятий. Мой трек имел номер 4 — «Основы программного моделирования». Кроме того, Intel была представлена на треке 5 своим XDK.О чём был трек Intel В первый и второй дни часть времени я уделил теоретическим основам программной симуляции, а именно тому, почему эта технология — важная составляющая разработки аппаратуры и софта, как устроены модели процессоров и чем отличаются от них модели периферийных устройств.Но всё же большую часть времени курса я решил посвятить практической работе по созданию моделей процессора и периферии архитектуры OpenRISC 1000. При подготовке курса я довольно долго решал, какую модель мы будем писать. Почему мной была выбрана именно эта архитектура?
Очень не хотелось в очередной раз делать 100500-й MIPS. Открытая и свободная спецификация. Модульная структура с множеством опциональных частей — в худшем случае, даже если реализовать только ядро и десяток инструкций, то всё равно можно увидеть результат. С другой стороны, если углубиться в поддержку деталей, то работы точно будет больше, чем на три дня. Простота спецификаций с одновременным наличием важных концепций, таких как прерывания и исключения, внешние устройства, таймеры, операции с плавающей запятой, векторные инструкции и т.п., что делает архитектуру совсем неигрушечной. Поддержка сообщества — если кто-то захочет продолжить работать с OpenRISC 1000, то к его услугам готовые инструменты: компиляторы GCC и Clang, библиотеки Libc, ядро Linux и даже дизайны на Verilog. Таким образом, OpenRISC 1000 оставлял мне большое пространство для манёвра — для любой публики найдётся задача по силам.
В качестве симулятора и фреймворка, на котором писались и отлаживались модели, использовался Wind River® Simics. Для академических организаций, желающих проводить обучение или некоммерческие исследования в областях архитектуры или производительности ЭВМ, имеется возможность получить бесплатную лицензию на Simics на 50 мест и набор пакетов с готовыми моделями процессоров Intel® Core™ и Intel® Atom™. По этой программе в России Simics установлен уже в двух вузах — в Московском физико-техническом институте и теперь вот в Петербургском ИИТУ.
Для академических организаций, желающих проводить обучение или некоммерческие исследования в областях архитектуры или производительности ЭВМ, имеется возможность получить бесплатную лицензию на Simics на 50 мест и набор пакетов с готовыми моделями процессоров Intel® Core™ и Intel® Atom™. По этой программе в России Simics установлен уже в двух вузах — в Московском физико-техническом институте и теперь вот в Петербургском ИИТУ.
Почему был выбран Simics?
Я работаю с этим продуктом давно и достаточно интенсивно, и естественным было использовать именно его.
Simics предоставляет богатый и при этом хорошо задокументированный API для написания разнообразных моделей и инструментов для исследования вычислительных систем и разработки системного ПО.
В поставке для академических пользователей идёт большое число примеров реализации устройств с исходными кодами, что позволило начать изучение с уже работающего кода и постепенно модифицировать его под задачи курса. Так, модель ядра or1k была сделана на основе sample-risc, а Tick-таймер — на основе sample-timer-device.
Кто участвовал
 На мои занятия пришли 14 человек. Некоторые были студентами СПбГУ, СПбПУ, ТУСУР, а также из Нижнего Новгорода (ВШЭ НН) и Волгограда (ВолГТУ). Другие участники оказались довольно таки старшими преподавателями вузов, которым тоже было интересно, что тут будут рассказывать. Наконец, «прокрались» несколько коллег из питерского отделения Intel Labs, которыми двигал во многом профессиональный интерес. До третьего дня добрались все, даже коллеги из Intel, хотя они всё время разрывались между очень важными рабочими совещаниями и моим занятием. При этом каждый с интересом занимался программированием своей части создаваемой платформы.
На мои занятия пришли 14 человек. Некоторые были студентами СПбГУ, СПбПУ, ТУСУР, а также из Нижнего Новгорода (ВШЭ НН) и Волгограда (ВолГТУ). Другие участники оказались довольно таки старшими преподавателями вузов, которым тоже было интересно, что тут будут рассказывать. Наконец, «прокрались» несколько коллег из питерского отделения Intel Labs, которыми двигал во многом профессиональный интерес. До третьего дня добрались все, даже коллеги из Intel, хотя они всё время разрывались между очень важными рабочими совещаниями и моим занятием. При этом каждый с интересом занимался программированием своей части создаваемой платформы.
Результаты К концу третьего дня мы имели неплохой набор: одна общая модель ядра or1k, две реализации контроллера прерываний PIC и полтора (один работал, а второй — остался чуть-чуть недописанным) таймера, юнит-тесты для сделанных инструкций ядра и общий скрипт для платформы, которая выглядела примерно так:
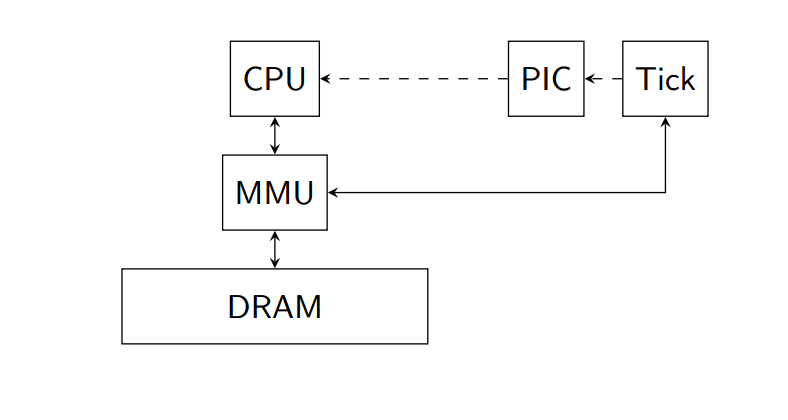
Что же было самым приятным и невероятным — у нас получилось соединить все модели в общую конфигурацию и пронаблюдать, как периодические прерывания то доходят, то не доходят до ядра, которое, в свою очередь, обрабатывает их согласно спецификации, переходя по указанному в ней вектору на код обработчика исключений. Конечно, мы многое не успели: реализовать полный набор инструкций, обеспечить честную трансляцию адресов, написать модель TLB и т.д. Но ведь заработало же!
Что даётся студентам легко Поскольку начался новый учебный год, мне как преподавателю было интересно узнать, какие сложности в восприятии такого типа практической работы могут возникнуть у участников, тем более что я буду проводить аналогичный, но более развёрнутый курс в этом учебном году. Сперва перечислю то, что оказалось относительно легко.
Работа в Linux. Хотя не все участники чувствовали себя уверенно, никто не жаловался на невозможность работы. Меня удивило, что многие использовали Midnight Commander, как и я — раньше я нигде такого не наблюдал. Общая идея интерпретации. Многие из слушателей были знакомы с принципом конвейерной обработки команд в ЦПУ. Считать битовые маски в уме. Удивительно, но некоторым было легче написать константу как 0xc0000000, чем оставить её в виде (1 << 31) | (1 << 30). Поддержка особенности инструкций ветвления — delay slot. Для ряда RISC-процессоров инструкция, стоящая сразу после ветвления, исполняется, даже если должен произойти переход на новый адрес. Некоторые из участников смело бросились моделировать эту (необязательную в общем-то) функциональность и успешно справились с ней. Написание кода на DML. DML — это специализированный язык, используемый для быстрого написания моделей Simics. Он совмещает декларативное описание регистров устройств с императивным описанием процессов, происходящих при их чтении и записи. Вначале я планировал ограничиться чистым Си (т.к. сам почти всегда пишу модели для Simics на нём), однако оказалось, что DML действительно позволяет ускорить процесс написания моделей — два десятка строк на Си заменялись двумя на DML. Выучить же основные его идеи по имевшимся примерам никому не составило труда. Что вызвало затруднения С другой стороны, были и неожиданности в том, что некоторые концепции были неизвестны или давались с некоторым трудом участникам (а иногда и преподавателю).Работа с Git. Только один человек без подсказок смог сам запушить свои правки в общий репозиторий. И тем не менее, данная система контроля версий очень помогла с получением общего кода с финальным результатом. Endianness. Казалось бы, все знают про существование двух порядков байт для представления многобайтовых последовательностей. И всё же мне, как и остальным участникам, очень трудно было быстро рассуждать о том, правильно ли мы положили данные в память, в том ли порядке были извлечены байты для декодирования и т.п. Симуляция с помощью очереди событий. Discrete event simulation (DES) — ключевая техника для эффективного моделирования большого числа агентов с асинхронно возникающими событиями. Модель таймера активно использовала события. Почему-то это оказалось сложнее, чем синхронная модель процессора. Необходимость расширения знака. Многие арифметические инструкции процессора требуют расширения операндов-констант со знаком перед тем, как они будут использованы в операции. Иногда их исходная ширина не была равна 8, 16 или 32 битам, и приходилось придумывать корректный Си-код для правильного учёта позиции знака и его расширения. Какие неожиданности встретились Чисто технические моменты, которые запомнились.GDB в Linux Mint по умолчанию не разрешено подключаться к процессам, не являющимся потомками отладчика (вызов ptrace() возвращает «Permission denied»). Лечится это просто:# echo 0 > /proc/sys/kernel/yama/ptrace_scopeИли же (разрешить отладку и после перезагрузки): записать 0 в файл /etc/sysctl.d/10-ptrace.conf. Иметь у команды опцию -l опасно: она может быть перепутана с -1, что приведёт к длительной отладке с ломанием головы. Заключение Как я уже неоднократно замечал за собой по окончании очередного курса, я не могу сказать, кто в его результате узнал больше — студенты или преподаватель. Так и здесь — погрузившись в немного другую среду, с другой стороны подойдя к ежедневно используемым инструментам, я узнал о них новое. Ну и конечно же, я познакомился с большим числом интересных людей и, надеюсь, смог заинтересовать их.
Спасибо всем участникам школы за интерес к современным технологиям и старание в решении поставленных задач, а её организаторам — за очень хорошую координацию, чёткость расписания и техническое обеспечение события. А читателям этого поста — спасибо за внимание!
