Kaggle: Allstate Claims Severity
Хотелось бы описать решение к недавнему соревнованию по машинному обучению Allstate Claims Severity. (Мой результат 40 из 3055). Так как это это соревнование типа «ансамблевое рубилово», как правило, обсуждение решений вызывает нездоровые священные войны между теми, кто пробовал участвовать и теми кто нет, так что для начала я сделаю небольшое лирическое отступление.
Заранее извиняюсь за обилие английских слов. Какие-то я не знаю как перевести, а какие-то мне переводить не хочется.
Мне нравится думать о машинном обучении как о трех мало связанных между собой направлениях, что я и попытался изобразить на картинке выше, и каждое из этих направлений преследует свои цели.
Например, в академической среде твоя производительность, да и вообще личная крутизна меряется числом и качеством опубликованных статей — и тут важна новизна идей, но насколько эти идеи можно применить на практике прямо сейчас это дело десятое.
В бизнесе сколько денег твои модели приносят компании и тут важна интерпретируемость, масштабируемость, скорость работы и прочее.
В соревновательном машинном обучении задача — всех победить. То есть то, что модель будет немасштабируемой, и тренировать ее надо неделями — это приeмлимо.
В подавляющем большинстве случаев когда какая-то компания предоставляет данные для соревнования, модели с наилучшей точностью в production в силу их сложности не идут. (Классический пример — это соревнование Netflix prize на котором лучшие модели не применимы, но толчок исследованиям знания наработанные участниками в этом соревновании определенно дал.) И, как следствие, среди тех кто не пытался участвовать в соревнованиях по машинному обучению складывается мнение, что модели, которые были получены в рамках соревнований — бесполезные. И они, конечно, правы. Но эта публика тут же делает вывод, что знания, полученные во время участия в соревнованиях тоже бесполезные, и что в соревнованиях участвуют только те, кто не может найти «реальную» работу и у кого есть время на это «никому не нужное занятие». Например, мой коллега на прошлой работе по имени Алекс о котором я рассазывал в этом посте именно так и думал.
Существуют и противоположная крайность: те, кто показывает неплохие результаты на соревнованиях думают что они с легкостью будут извергать из себя модели, которые тут же замечательно заработают в Production, что теоретически может случиться, но на практике мне не попадалось. Все-таки точность модели на train set, test set и в production — это три большие разницы.
Я предпочитаю думать машинном обучении в соревнованиях vs бизнес как о подтягиваниях vs скалолазание. Если вы много раз подтягиваетесь — это не значит, что вы хороший скалолаз, но при этом подтягивания в какой-то степени помогают лазать и хорошие скалолазы часто инвестируют время в то, чтобы подтягиваться лучше, при этом не просто подтягивания, но и подтягивания с отягощениями, подтягивания на кампусборде, с руками на разной высоте и т.д.
Соревнования по машинному обучению работают в похожем режиме в том смысле, что если вы Machine Learning Engineer или Data Scientist и вы не можете предложить что-то достойное на соревнованиях, то, возможно, вам имеет смысл сколько-то времени в это инвестировать. Тем более что соревнований много, они разные и что-то с какого-то соревнования вам может пригодится на работе или по науке. Как минимум ребята с Google, Deepmind, Facebook, Microsoft и прочих серьезных контор периодичеcки участвуют. Да и случаев когда хорошие показания на соревнованиях помогали найти достойную работу более чем достаточно.
Описание задачи
Компания Allstate предоставляет данные для соревнования на Kaggle.com уже не первый раз и, видимо, им нравится. В этот раз приз у соревнования — рекрутер Allstate, возможно, заставит себя потратить 6 секунд на ваше резюме, если вы подадите на позицию Junior Data Scientist. Не смотря на то, что приз ни о чем, соревнование привлекло более трех тысяч участников, что сделало его уникальной кладезью специфических знаний.
Задача была создать модель, которая будет предсказывать величину выплату по страховому случаю. В общем, как обычно, стаховая компания хочет предсказывать кому страховка не нужна — и продавать ее именно им, а кто может попасть под стаховой случай — им не продавать или продавать задорого.
Целевая переменная имеет вот такое асиметричное распределение: 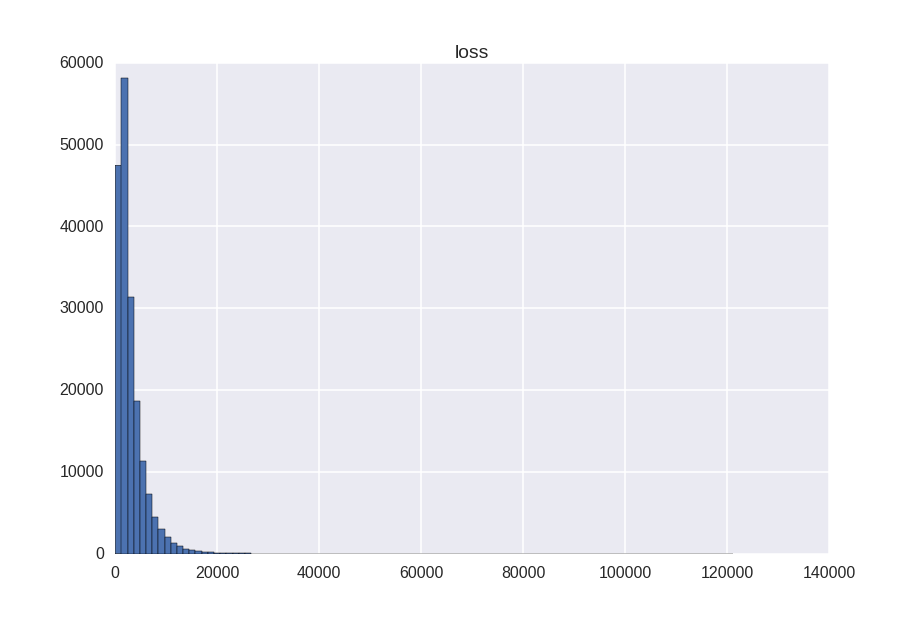
Где:
- min = 0.67
- max = 121012
- mean = 3037
Результаты оценивались по метрике Mean Absolute Error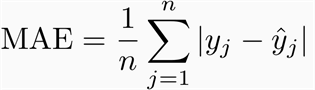
Данные анонимизированные. 16 численных и 116 категориальных признаков.
- Train set — 188318 рядов
- Test test — 125546 рядов
Как обычно, чтобы предотвратить overfitting, test set был разделен на 2 части.:
- 30% test set — Public Leaderboard — точность вашей модели на этой части можно было проверить в течение всего соревнования. (5 попыток в день)
- 70% test set — Private Leaderboard — точность на этой части test set становится известна после окончания соревнования и именно она в конце концов используется для оценки вашей модели.
То есть данных достаточно мало, и неплохой результат можно получить на маломощных машинах без использования облачных вычислений, например на лаптопах, что во многом и обусловило большое число участников.
Уровень моделей / знаний участников можно очень условно разделить на такие категории, где число — это примерная ошибка на Public LeaderBoard.
- 1300+ — те, кто знают основы машинного обучения, могут подготовить данные, натренировать линейную регрессию и сделать предсказание. 16% участников
- 1200–1300 — те, кто знают что-то кроме линейной регрессии. 28% участников.
- 1200–1120 — те, кто знают, что xgboost / LightGBM существует, но плохо умеют его настраивать. 9% участников.
- 1110–1120 — те, кто умеют настраивать xgboost или нейронные сети. 22% участников
- 1104–1110 — те, кто знают, что арифметическое среднее предсказаний xgboost и нейронных сетей точнее чем каждое из предсказаний по отдельности. 11% участников.
- 1102–1104 — те, кто умеют строить более сложные линейные комбинации. 6% участников.
- 1101–1102 — те, кто умеют использовать stacking. 5% участников.
- 1096–1101 — серьезные ребята. 3% участников.
Эта градация весьма условна как минимум в силу большого числа участников и нелепости приза. То есть публика активно делилась идеями и кодом и, например, были ветки на форуме где пошагово обсуждалось что нужно сделать, чтобы получилось 1102. Как следствие, как правильно было замечено одной из участниц, это соревнование было похоже на Red Queen’s race когда надо улучшать свои модели ежедневно только для того, чтобы не сползти вниз на LeaderBoard, ибо 1102+ можно было получить запустив и уседнив результаты предсказаний чужого кода, что в общем достаточно низкий стиль, но уж лучше так, чем никак. Правильно усреднять тоже надо уметь.
Идеи
Идея первая
Целевая переменная сильно асимметричная. При этом алгоритмы машинного обучения лучше работают на симметричных данных. Какие-то любят чтобы целевая переменная имела нормальное распределение, какие-то нет. Но надо было сделать что-то более симметричное. При этом утверждение которое может встретиться в литературе, что чем симметиричнее целевая переменная — тем лучше, в данном случае не верно. Стандартные способы увеличить симметричность — логарифм, возведение в степень.
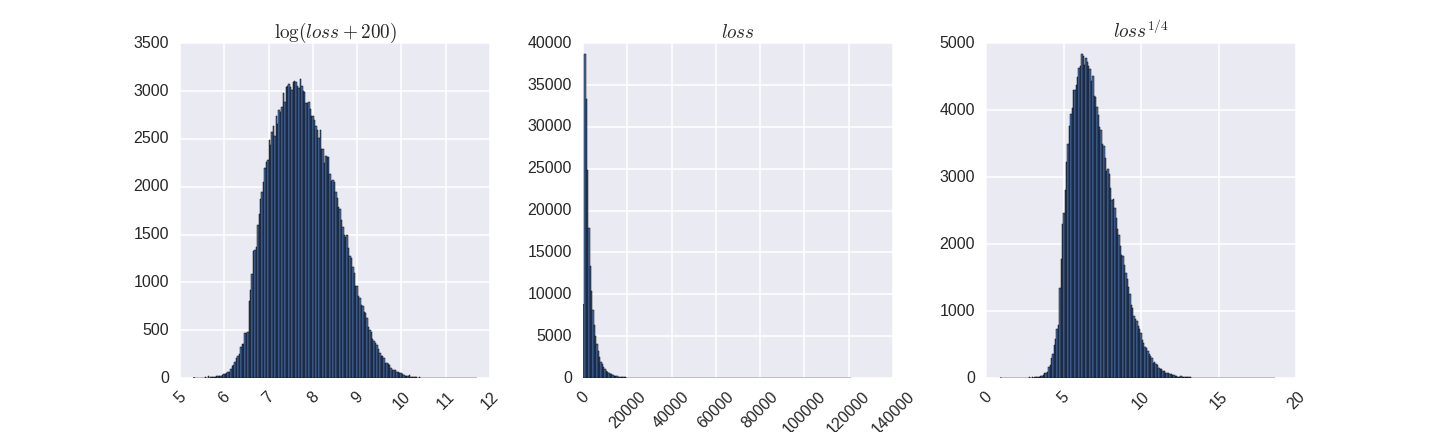
То есть мы хотим что-то более симметричное чем то, что было изначально, но, так как наша целевая метрика MAE от непреобразованной целевой переменной, мы хотим чтобы ошибка при трeнировке на больших значениях вроде 120000 была больше чем на значениях вроде 100, но не в 1200 раз. И правильное преобразование — это то, которое переводит целевую переменную во что-то симметричное, но с толстым правым хвостом. Например корень четвертой степени у меня очень достойно себя показал, лучше чем логарифм.
Идея вторая
Это соревнование:
- на данных смешанного типа которые не обладают локальной структурой
- размер тренировочных данных 10^4 — 10^7
Это тот тип и тот объем на котором в 95% случаев у xgboost конкурентов нет. Что тут и произошло.
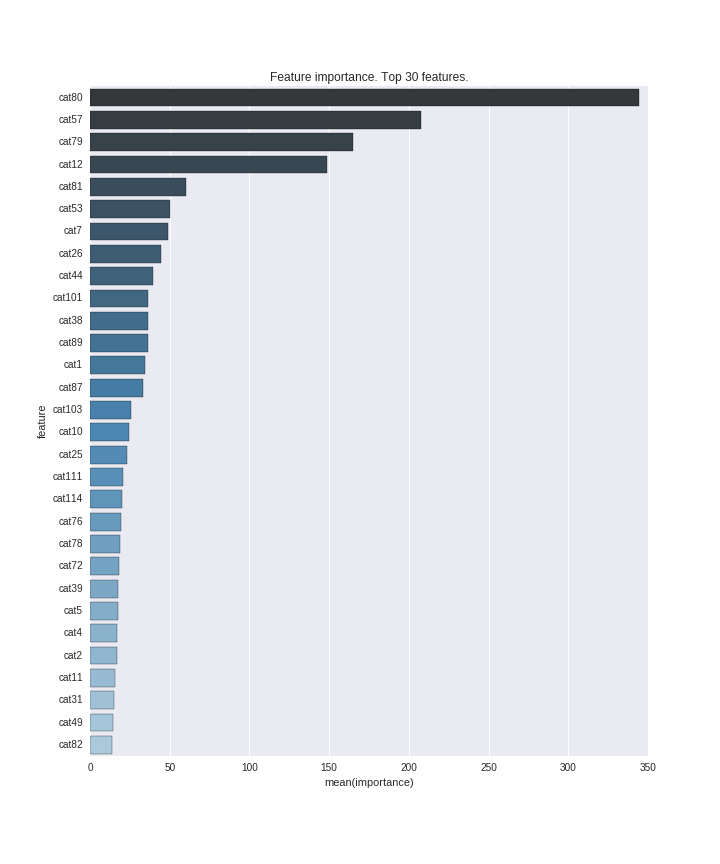
На этом графике топ 30 наиболее важных признаков.
Mathias Müller получил 1109 используя xgboost на исходных данных, что соответствует top 25%. (В итоге он закончил соревнование третьим)
Идея третья
Как находить хорошие гиперпараметры? Существуют несколько методов:
- Вручную.
- GridSearch — выставил сетку и проверяешь все или какоe-то подмножество параметров.
- Более интеллектуальные методы, вроде Hyperopt или BayesianOptimization
На практике хорошо себя показала BayesianOptimization для поиска хороших кандидатов + ручная подкрутка.
Какие диапазоны параметров проверять? Черт его знает. Я верил тому, что пишут в литературе о том что структура алгоритма в основе gradient boosting такова, что использовать деревья с глубиной больше 10 смысла нет. Врут. В большинстве случаев так и есть, но на этих данных этого мало. Наилучшие модели использовали более глубокие деревья, вплоть до max_depth = 25.
Идея четвертая
Так как MAE не дважды дифферeнцируема, то можно аппроксмировать модуль как cosh (ln), что уже дважды дифференцируемо, и теперь можно для функции потерь использовать не среднеквадратичную ошибку —, а что-то более интересное. И была ветка форума на котором это активно обсуждалось.
Идея пятая
Существует мнение, что для алгоритмов которые основаны на decision tree не важно как преобразовывать категориальные признаки в численные. И что во всех остальных алгоритмах кроме one hot encoding ничего использовать нельзя. И то, и другое утверждение с точки зрения бизнеса — правда, с точки зрения соревнований и академической среды — наглая ложь. Разница есть, но она небольшая. Можно пробовать различные encoding и смотреть что лучше работаeт. Например, для некоторых категориальных признаков лексикографический encoding работал чуть лучше, позволяя уменьшить число split в каждом дереве.
Идея шестая
Существует мнение, что алгоритмы на основе деревьев находят взаимодествия между признаками. Это неправда. Они их аппроксимируют. С точки зрения бизнеса — это одно и то же. С точки зрения соревнований — нет. Поэтому если взять топ сколько то наиболее важных признаков с картинки выше и создать новые признаки, которые будут описывать взаимодествия между ними то точность некоторых моделей увеличивается, что и было предложено в одном из скриптов. И это позволило кому-то достигнуть 1103 с xgboost. (Мой лучший результат 1104)
Идея седьмая
А что насчет feature engineering? Правильные признаки в большинстве случаев (но не всегда) дадут больше, чем хитроумные численные методы. При подготовке данных Allstate проделал очень достойную работу, и не смотря на усилия участников ничего толком деанонимизировать не удалось. Вроде поняли что один из признаков — это штат. И что какие-то признаки как-то соотносятся с датами. Но насколько я знаю ничего из этого выудить не получилось. Статистические признаки, насколько я знаю, тоже ни у кого толком использовать не получилось. Я все равно добавил временные зоны, и статистические признаки для наиболлее важных категориальных, но это скорее для успокоения совести.
Вот, например, diff признака cont2 vs cont2.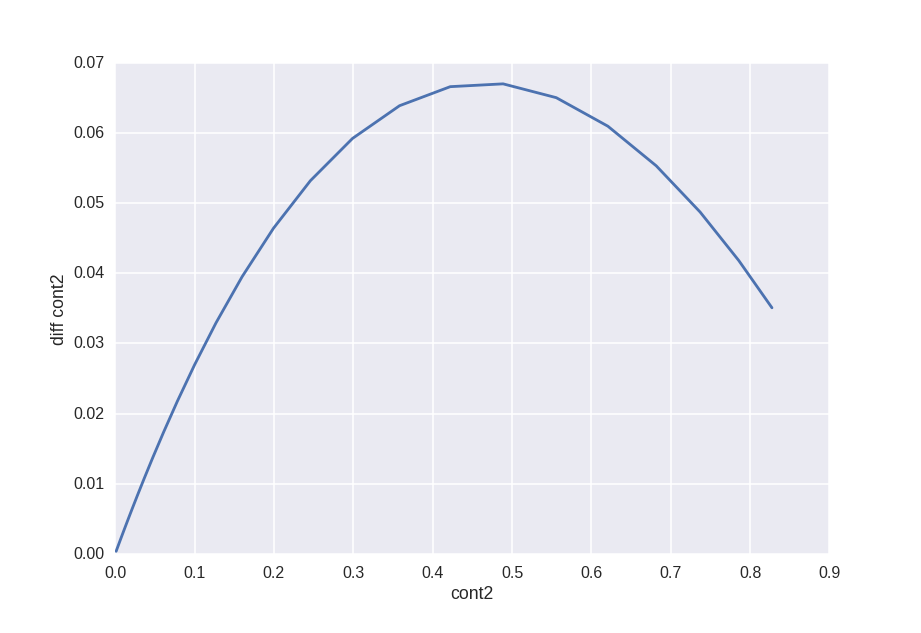
По идее это нам должно сказать какое преобразование Allstate применил к фиче cont2, но как я голову ни ломал не смог придумать как это преобразование найти.
Идея восьмая
Чтобы получить результат лучше 1102 нужен stacking. Это такая хитрая техника, которая используется в каждом втором соревновании, но, насколько я знаю, не используется в production в принципе. Много она не дает. Но использование stacking позволяет очень интеллигентно скрещивать различные модели. Собственно, до участия в этом соревновании я этой техникой не владел, а лишь слышал краем уха, и основная мотивация для участия была как раз именно разобраться и закрыть для себя этот вопрос.
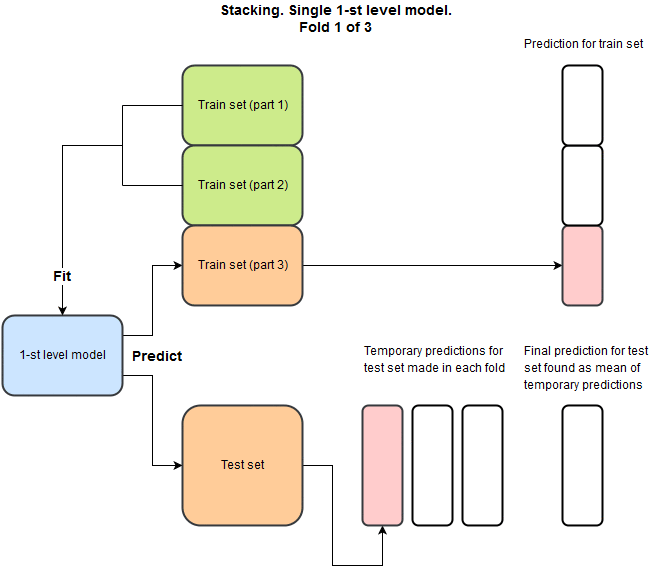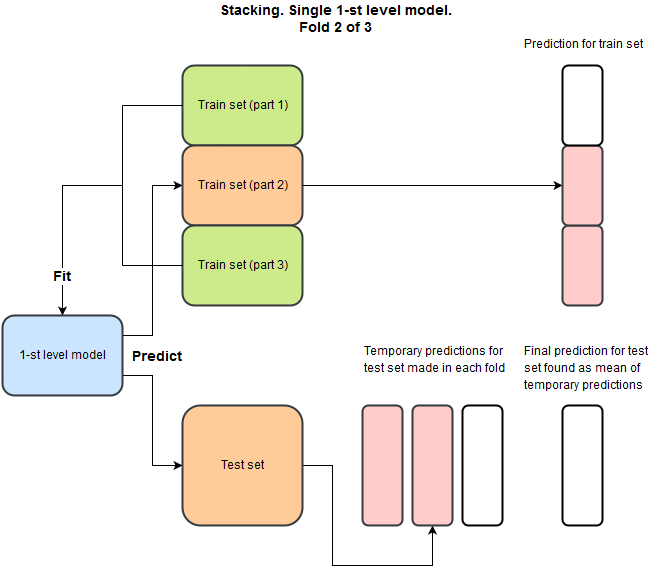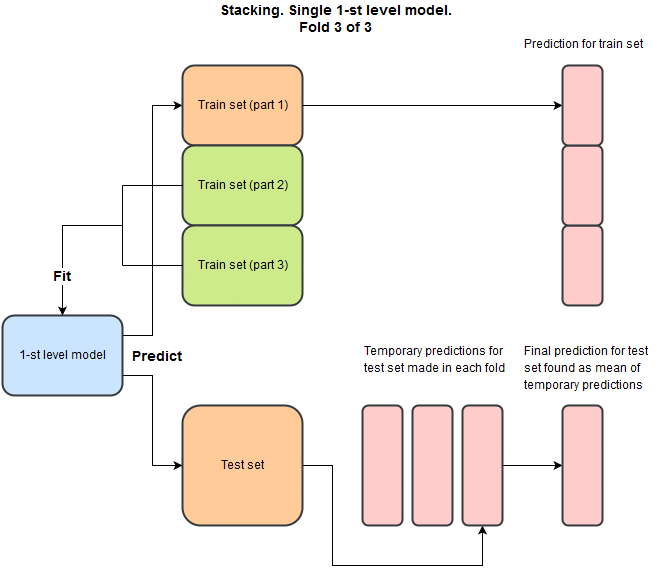
Идея в том, что мы хотим для каждой модели сделать предсказание на train set и на test set, при этом мы не хотим предсказывать на train на тех же данных, что использовалось для тренировки. Вот пример на python как это надо делать.
И как следствие для каждой модели у нас будет предсказание на train, и соответсвующее на test. Зачем это надо? Мы повторяем это для разных моделей и комбинируем предсказания в новый train и test set. С признаками:
- train: {prediction_xgboost, prediction_NN, prediction_SVM, etc}
- test: {prediction_xgboost, prediction_NN, prediction_SVM, etc}
И теперь мы можем забыть про исходные тренировочные и тестовые данные и тренировать второй уровень уже на этих новых данных используя линейные или нелинейные методы.
Причем эту процедуру мы можем повторить несколько раз используя предсказания от предыдущего шага как фичи для следующего. В одном из прошлых соревнований итоговое решение выглядело:

Собственно такие дремучие решения и вызывают отторжение у тех кто думает о машинном обучении только с точки зрения «How can I bring value to the company.», ибо на практике не применимы, хотя есть компании, которые пытаются автоматизировать этот процесс.
Идея девятая
Мы сделали предсказание — используя stacking. Можно ли его улучшить? Можно. Алгоритмы на основе деревьев недооценивают большие значения и переоценивают малые, поэтому итоговое предсказание можно откалибровать. Популярное преобразование, которое использовали некоторые участники — это:
alpha * prediction^beta, а кто-то даже так делал для различных квантилей.
Заключение
Собственно и все. Тренируется много разных моделей (xgboost, Neural Networks, Random Forest, Ridge Regression, Extra Trees, SVR, LightGBM) с различными гиперпараметрами на данных, которые преобразованы различными методами в режиме stacking. А потом на предсказаниях от всех этих моделей тренируется Neural Network с парой скрытых слоев для того, чтобы получить итоговый результат.
Все достаточно просто и прямолинейно, но при этом чтобы дойти до этого требовалось определенное усилие. Причем опытным участникам это давалось проще чем неопытным. Будем надеяться, что в другой проблеме, где могут быть использованы похожие приемы, сакральные знания, полученные тут, как-нибудь да помогут.
Тем, кто не пробовал участвовать в соревнованиях я настойчиво рекомендую.
Eсли вы используете машинное обучение на работе, то вам сам бог велел проверить насколько сильно ваши знания и навыки, полученные на работе применимы в мире Competitive Machine Learning, и не исключено, что что-то вы, возможно, выучите во время соревнований и это сможет пригодится вам на работе чтобы вы могли «bring value to the company». Например, я убедил босса сделать пару сабмишенов на одном из недавних соревнований. Он улетел в нижние 10 процентов LeaderBoard (злой потом ходил и много думал) потому как использовал различный encoding на train и test. После этого его политика на работе изменилась и мы стали чуть больше врeмени уделять тестированию.
Если вы еще студент — сам бог велел участвовать. Если бы пять лет назад я обладал теми же навыками работы с данными, моя научная работа в аспирантуре была более эффективной и я бы опубликовал больше статей. Плюс хорошие результаты с соревнований в которых рабочая лошадка — это нейронные сети практически однозначно можно публиковать. А уж как кусок диплома точно можно вставлять.
Если вы задумываетесь о постепенном переходе в Data Science — вам опять же сам бог велел участвовать. Соревнований самих по себе недостаточно для того, чтобы вас взяли на работу, но в совокупности с образованием и опытом работы в других областях должно помочь. В том году парня в DeepMind пригласили после одного из соревнований, так что случаи бывают разные.
Не все соревнования так ориентированы на численные методы. Недавнeе соревнование по предсказанию продуктов для различных пользователей банка Santander в Испании — чистый feature engineering. Жаль, что я мало времени ему уделил. Или же соревнования которые идут сейчас на тему Computer Vision, нейронных сетей и прочих модных ныне слов:
- Про рыбок — приз $150000
- Про спутниковые карты — приз $100000
Интересно, много знаний, красивые картинки, а кому повезет еще и денег дадут.
И так как это хабр и тут любят код — неструктурированный код, который я использовал.
