JSON:API 一 это не JSON API

Я занимаюсь разработкой Ruby с 2011 года. В данный момент я team leader в образовательной онлайн-платформе UCHi.RU. Это большая EdTech-компания, которая работает на рынке уже 10 лет. Мы выросли из небольшого отечественного стартапа в группу компаний. UCHi.RU — резидент ИТ-кластера фонда «Сколково», входит в образовательную экосистему VK и создает образовательные продукты и сервисы для школьников и учителей. Сегодня Учи.ру используют 16 миллионов пользователей в стране — каждый второй школьник (10 миллионов), 5,5 миллионов родителей и 450 000 учителей.

Проект Учи.ру стартовал как Ruby-монолит с erb. Сам монолит использовался с 2012 года. Он расширялся, увеличивался в размерах, в него добавлялись различные компоненты, такие как React. Со временем накопилось более 70 React-компонентов монолита, что сказалось на скорости сборки. Монолит стал медленнее собираться, деплой тоже замедлился. Мы приняли решение о распиле монолита, чтобы облегчить работу по развитию продукта и ускорить деплой.
Ритуальный распил монолита
Ритуальный распил монолита, т. е. вынос из него микросервисов, происходил постепенно. В первую очередь мы выносили различные ключевые сервисы, скорость развертывания которых была критична, например, сервис премиумов, олимпиады, сервис аутентификации и т. д. Параллельно мы выносили различные SPA-приложения. Таким образом, мы увеличили скорость сборки и уменьшили время развертывания монолита.
На данный момент мы выделили около 200 сервисов, большая часть из которых бэкенд-сервисы. Мы распределили эти сервисы между командами разработки, тем самым определяя зоны ответственности команд. Кроме того, мы развивали разработку на Roda, Go, Python и других платформах. В настоящий момент параллельно внедряется разработка на Node.js.
По итогам мы задались вопросом: как общаются между собой все эти сервисы?
В далеких 2000-х Рой Филдинг написал диссертацию, в которой очертил путь развития REST, который в нулевых обозначал «не-SOAP/XML-RPC», до определенной концепции:
REST должен был иметь разные ресурсы вместо одного endpoint (Level 1);
REST должен был использовать HTTP verbs вместо имен функций — POST, GET, PUT именно в запросе. Это упрощало документирование по сравнению с XML/SOAP и ситуацию в целом (Level 2);
Предполагалось наличие hypermedia controls, но эта идея не прижилась.
В 2010-х JSON сменил XML-протокол, поэтому необходимость использовать hypermedia controls пропала.
На текущий момент REST представляет собой JSON API или Web API примерно на 90%.
С момента основания монолита в Учи.ру использовался REST Level 1/Level 2, т. е. ресурсы и HTTP verbs. Мы с ними работаем последние 7–8 лет. Но в какой-то момент мы увидели такой соблазнительный формат, как JSON: API.

Данная спецификация для API решала проблему избыточных запросов, т. е. N+1, позволяя увидеть ссылки, указать ресурс и, при необходимости, дочерние ресурсы.
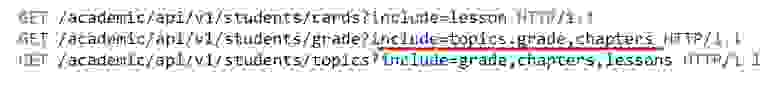
Кроме того, бонусом стала возможность избежать долгих и тяжелых ответов, была решена проблема описания ссылок и межресурсной зависимости в самом контракте.

Протокол также решал вопрос постраничной навигации (пагинации). Ранее постраничную навигацию приходилось создавать, проектировать и конфигурировать самостоятельно (например, на JSON-схемах).

Поэтому мы решили взять данную спецификацию на вооружение.

Однако когда мы попытались подружить бэк и фронт при помощи JSON: API, появились сложности. Пример кода на фронте и бэке:

Несложно догадаться, кто формировал данный контракт, потому что он был написан на Ruby и поддерживался/изменялся рубистами. Контрактом не могли управлять фронтендеры.
У данного контракта был один владелец, что и создавало зависимость фронтендеров от бэкендеров. В идеале у контракта не должно быть владельца, и он должен быть согласован со всеми сторонами.
Кроме того, у JSON: API нет готовой экосистемы на стороне фронтенда (при этом на бэкенде система функционировала отлично).
Мы перебрали на фронте 20 вариантов различных библиотек, выбрав одну, но в итоге все-равно получили большой объем лишнего кода, нам приходилось изобретать велосипед.
Соответственно, использование такого подхода потребовало длительного обучения начинающих разработчиков и коллег по цеху, которые хотели подключиться к проекту использующему JSON: API.
Вследствие долгой реализации и интеграции мы более не осуществляли подобных экспериментов с JSON: API.
Эксперименты
GraphQL
Однако мы на этом не остановились, выбрав GraphQL следующей жертвой. В 2020 году c приходом новых сотрудников мы начали внедрять GraphQL, который на тот момент уже предлагал обширные возможности:
«Из коробки» предлагалось единое описание всего контракта при помощи Apollo.
А также предлагался подход с единым gateway, к которому могли обращаться множество клиентов.
Однако были и проблемы:
Порог вхождения оставался высоким, несмотря на наличие готового пакета для клиента на фронтенде.
Оставались проблемы с отладкой, аналогичные проблемам с XML-RPC, поскольку применяется единый gateway и единый endpoint, но нет разделения на ресурсы. Таким образом, понять, какой ресурс вызывается, можно только из запроса.
Множество проблем с firewall. Например, Cloudflare не покрывает GraphQL gateway. Также возникают проблемы с Sentry, когда в проекте с GraphQL работают несколько команд, зоны ответственности которых необходимо разграничить. Это непросто и требует длительных «плясок с бубном».
Как итог, мы до сих пор используем GraphQL в наших проектах, но пока не расширяем область применения.
gRPC
Мы также используем gRPC для общения между микросервисами, который был интереснее благодаря подходу contract-first «из коробки». В первые месяцы gRPC показал себя достаточно интересно, благодаря намного более низкому порогу вхождения, чем у JSON: API или GraphQL, но при этом у него есть ряд минусов, например:
При изменении контракта, если на контракт завязано много сервисов, приходится делать очень много правок в коде. Поэтому иногда стоимость изменения контракта зашкаливает.
Дебаг очень сложен, поскольку gRPC — бинарный формат, и дебаг gRPC-ответов из STDOUT-логов невозможен.
Преимуществом является то, что gRPC предоставляет генераторы, которые позволяют собирать клиента автоматически. Эти генераторы хорошо поддерживаются и используются и сообществом, и Google.
После всех этих попыток, мы решили не плодить зоопарк, поскольку поддержание n-ного количества технологий в единой экосистеме достаточно проблематично. Мы захотели привести нашу экосистему к единому подходу и выбрали OpenAPI.
OpenAPI
OpenAPI как устоявшаяся спецификация появился в 2016 году. Данный формат документации API показался нам достаточно консистентным и удовлетворяющим всем нашим требованиям.
Мы используем OpenAPI контракты в виде моно-репозитория, состоящего из пакетов. Каждый пакет представляет собой определенный контракт или набор контрактов. Каждое изменение или добавление контракта проходит проверку (Code Review).

После merge PR в main, при релизе на CI собирается пакет контракта и заливается в NPM репозиторий.
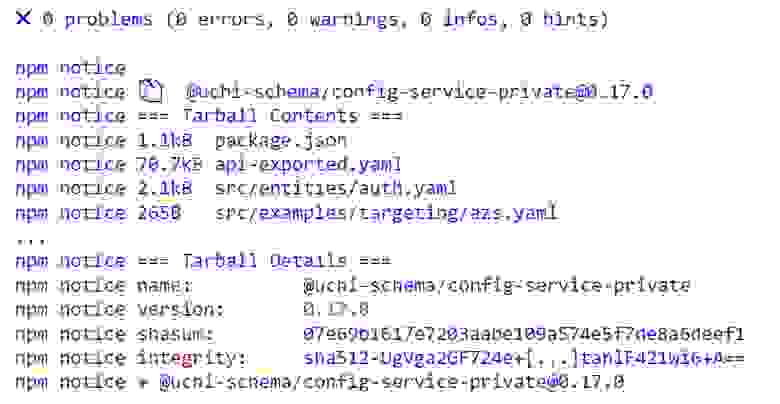
Мы используем авто-генерацию клиента на основе пакета контракта на фронтенде, таким образом устраняя необходимость писать клиента вручную как в случае JSON: API. Это уменьшает стоимость разработки на фронтенде.

Кроме того, у нас был опыт внедрения авто-тестирования на Ruby. Когда необходимо писать тесты, иногда используют Rswag, Rspec OpenAPI или Rspec Api Documentation. Но генерировать контракты на бэкенде необязательно, поскольку можно сделать автотестер на основе юнит-тестов, который будет брать контракты из хранилища и автоматически прогонять тесты именно на основе контрактов при вызове ручек API во время прогона тестов.
Мок-сервер
На основе контрактов мы практикуем сборку мок-серверов. Мок-сервер можно собрать как локально, так и на stage-окружении.
Мок-сервер также используется для тестирования фронтенда, например, когда бэкенд еще не готов, а контракт уже имеется, или необходимо провести тестирование проекта контракта локально или в Docker.

Запуск мок-сервера
Мок-сервер запускается с помощью нашей внутренней разработки, openapi-toolkit.
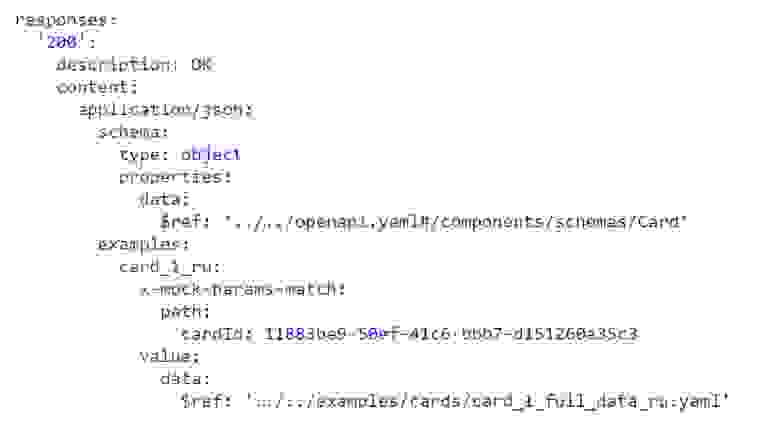
Примеры, которые должен вернуть мок-сервер в ответ на определенный запрос при сборке пакета контракта сохраняются в
api-exported.yaml.
UI контрактов
Мы используем самописный сервис (UI) для хранения контрактов, написанный на Sinatra с использованием ReDoc для просмотра (View). Этот сервис позволяет получать/обновлять контракты при обращении CI/CD к API сервиса и отображать их при помощи ReDoc.

Таким образом, мы пришли к следующим выводам:
Необходимо выработать процессы для работы с API — необходимо, как минимум, изучение и обсуждение до внедрения определенных технологий.
В случае Contract first необходим подход, ориентированный, в первую очередь, на потребителя, а не на бэкенд или фронтенд. Соответственно, контракт планируется исходя из требований потребителя с учетом ограничений исполнителя.
Контракт — это следствие работы нескольких людей/команд/направлений и не должен иметь владельца, поэтому Contract first & OpenAPI надо «продавать» командам.
Технологии OpenAPI, как и любые другие технологии должны быть понятны людям. Кроме того, необходима мотивация для их использования, то есть некий стимул для использования той или иной технологии. Внедрение любой технологии «по фану», может привести к ошибке.
При внедрении любой новой технологии команда должна проходить обучение. В противном случае можно потратить время и деньги впустую, уткнувшись в проблемы при разработке.
Необходимо закладывать время на освоение и поддержку внедряемой технологии, поскольку может потребоваться разработка/внедрение tooling в процесс разработки. Использование технологий, не внедренных в процесс разработки, может оказаться провальным.
Полезные ссылки
Мы решили:
внедрить авто-тестирование контрактов на бэкенде, чтобы исключить необходимость писать тесты;
полностью уйти от генерации контрактов на бэкенде (rswag);
поддерживать развитие инженерного сообщества в компании, чтобы обсуждать актуальные вопросы до их внедрения.
