JEP-400 или UTF-8 РєРѕРґРёСЂРѕРІРєР° РїРѕ умолчанию
Не прошло и пяти лет, как в Java 18 докатилось небольшое, но очень ожидаемое и обсуждаемое изменение: теперь во всех стандартных API используется UTF-8 кодировка по умолчанию. Это изменение, которое сделает выражение «Write once, run anywhere» действительно правдой, так как теперь поведение приложения будет еще меньше зависеть от системы, где оно запущено.
На конференции Joker я рассказал, как развивались события в работе над JEP-400 и как сделать так, чтобы ничего не поломалось после перехода на новые версии JDK. А теперь делюсь с Хабром и видеозаписью доклада, и текстовой версией. Как говорится, помимо двух самых сложных задач в программировании — нейминга и инвалидация кэша, есть ещё две: таймзоны и кодировки. Вот о кодировках и поговорим. Как читается название — разберёмся в конце.
Мир переходит на Unicode
Стандарты давно фиксируют использование юникода: HTML5 и XML, в JSON-е сразу несколько. Языки программирования меняют кодировку, используемую по умолчанию: Python 3 с появления декларирует Unicode, .NET с выходом Core 2.0. Появляются языки вроде Go и Rust, которые с самого зарождения используют юникод. В PHP 6 тоже хотели завезти нативную поддержку Unicode, но не смогли, но это уже совсем другая история. И вот, настал тот день в 2022-м, когда Java тоже по умолчанию используется UTF-8.

В чём проблема?

Возьмём Windows с Java ниже 18 версии. Запишем «Привет, мир!» в файл методом, который без указания кодировки по умолчанию берёт значение из Charset.defaultCharset(). Перекинем этот файл на Mac или Linux, считаем и получим крякозябры.
Проблемы бывают даже на одном и том же компьютере. Скажем, мы в Windows записали файл с помощьюFiles.write(path, str.getBytes()), а потом считали с Files.readString(path) и снова закрякозябрились.
Но Java же очень надёжный язык, он не может просто так поломаться? Разработчики языка тоже так подумали и решили, что надо с этим что-то сделать. И пришли к герою сегодняшнего дня: JEP-400.

Жизнь до JEP-400
Сначала посмотрим, как было раньше.
Разработчики не всегда указывают конкретную кодировку при вызове методов. Либо ленятся, либо указание ломает красивые конструкции
(::)в стримах.Property-файлы, начиная с JDK 9, лежат в UTF-8.
Методы класса
java.nio.file.Filesпо умолчанию считываются в UTF-8, в них это прямо захардкожено.Некоторые классы (
URLEncoder/Decoder) задепрекейтили методы без указания кодировки.Остальные получают кодировку из метода
Charset.defaultCharset(), который смотрит на ключик-Dfile.enconding, который, в свою очередь, смотрит на системную локаль.В Windows используются кодировки а-ля Windows-1251, зависящие от региона, а на Linux и Mac используется Unicode.
Из-за этого и возникают проблемы.
Более того, многие используют ключ -Dfile.encodıng, чтобы сказать JVM:»Используй Юникод и не смотри на систему». Хотя на самом деле, этого делать было нельзя, потому что по словам создателей, это внутренняя деталь языка и не следует никак ни читать, ни изменять это значение. И единственный способ поменять кодировку в приложении по словам авторов — это поменять её в системе до старта приложения. Поэтому, например, если поменять на лету значение параметра -Dfile.encodıng с помощью метода setProperty, то ничего не выйдет, так как он кешируется на старте. Это справедливо для большинства JVM, но каждый производитель виртуальной машины вправе сделать это иначе, так как спецификация никак не описывает поведение этого ключа.

Так выглядел ответ авторов JVM по поводу этого ключика, сейчас уже страничка удалена.
Как решить эти проблемы, если ты разработчик языка?
Представим себя на месте инженеров, создающих Java. С одной стороны, можно оставить всё так, как есть. Может, это и выход, но проблема реальная, и надо её решать.
Можно задепрекейтить методы без конкретного указания кодировки и сказать:»Слушайте, разработчики, теперь вы должны обязательно указывать кодировку». Помимо очевидного удлинения кода (а Java не всегда радует своей лаконичностью), все производители библиотек пойдут хардкодить своё значение кодировки.
Можно забить на развитие Java и выпустить новый язык:) Конечно, это шутка, но у Kotlin и других новых языков всё уже в порядке. Для нас это не выход: очень много систем, которые работают на Java, и сам язык живее всех живых.
Можем просто захардкодить UTF-8 или любое другое значение везде, но тогда мы поломаем обратную совместимость. А Java очень славится стремлением к сохранению контрактов.
И вот мы пришли к пути JEP-400 — это trade-off, выбор между разными вариантами.
Что поделать | Последствия |
Ничего не делать | Не решит проблему |
Задепрекейтить методы без указания кодировки | Удлинит код, риск получить непараметризуемый зоопарк |
Выпустить новый язык:) | Не выход |
Захардкодить UTF-8 везде | Ломаем обратную совместимость |
Путь JEP-400 | Так и победим |
В далёком 2017-ом…
Откроем багтрекер OpenJDK и посмотрим, какие решения тогда были приняты. Там прямо написано «что мы хотим сделать»:
Cделать поведение программ более предсказуемым и портируемым в методах, где используется кодировка по умолчанию.
Определить, где Java API использует кодировку по умолчанию.
Стандартизировать UTF-8 во всех Java API, кроме консоли.
Но почему UTF-8? Почему не любая другая кодировка?
 Usage of character encodings broken down by ranking, https://w3techs.com/technologies/cross/character_encoding/ranking
Usage of character encodings broken down by ranking, https://w3techs.com/technologies/cross/character_encoding/ranking
Во-первых, соседние языки, особенно более свежие, уже давно решили избрать ее стандартом.
Во-вторых, популярные способа обмена JSON и XML давно уже используют UTF-8. Это прописано в спецификации.
В-третьих, это уже де-факто стандарт для веба. По статистике подавляющее количество страниц используют UTF-8 кодировку.
Ещё есть методы класса java.nio.file.Files, захардкодившие эту кодировку. И, согласно JEP-226, property тоже в UTF-8.
Но прежде чем мы пойдем дальше, небольшой экскурс UTF-8 и кодировки вообще.
Короткий экскурс в кодировки
Итак, что такое кодировка. Если упрощать — это маппинг между тем, что вы видите на экране и тем, что компьютер на самом деле хранит у себя. Если еще грубее сказать — это некоторый ключ, с помощью которого расшифровывается последовательность нулей и единиц, превращаясь в читаемые символы.
Исторически так сложилось, что компьютеры в разных странах развивались своим темпом, и сейчас существует большое количество кодировок — Java поддерживает 173.
В России были популярны Windows-1251, CP866 и KOI8-R. В Китае вообще интересно — на выбор кодировки влияет в том числе политическая обстановка. Некоторым локациям повезло ещё меньше — вот ситуация в Японии:
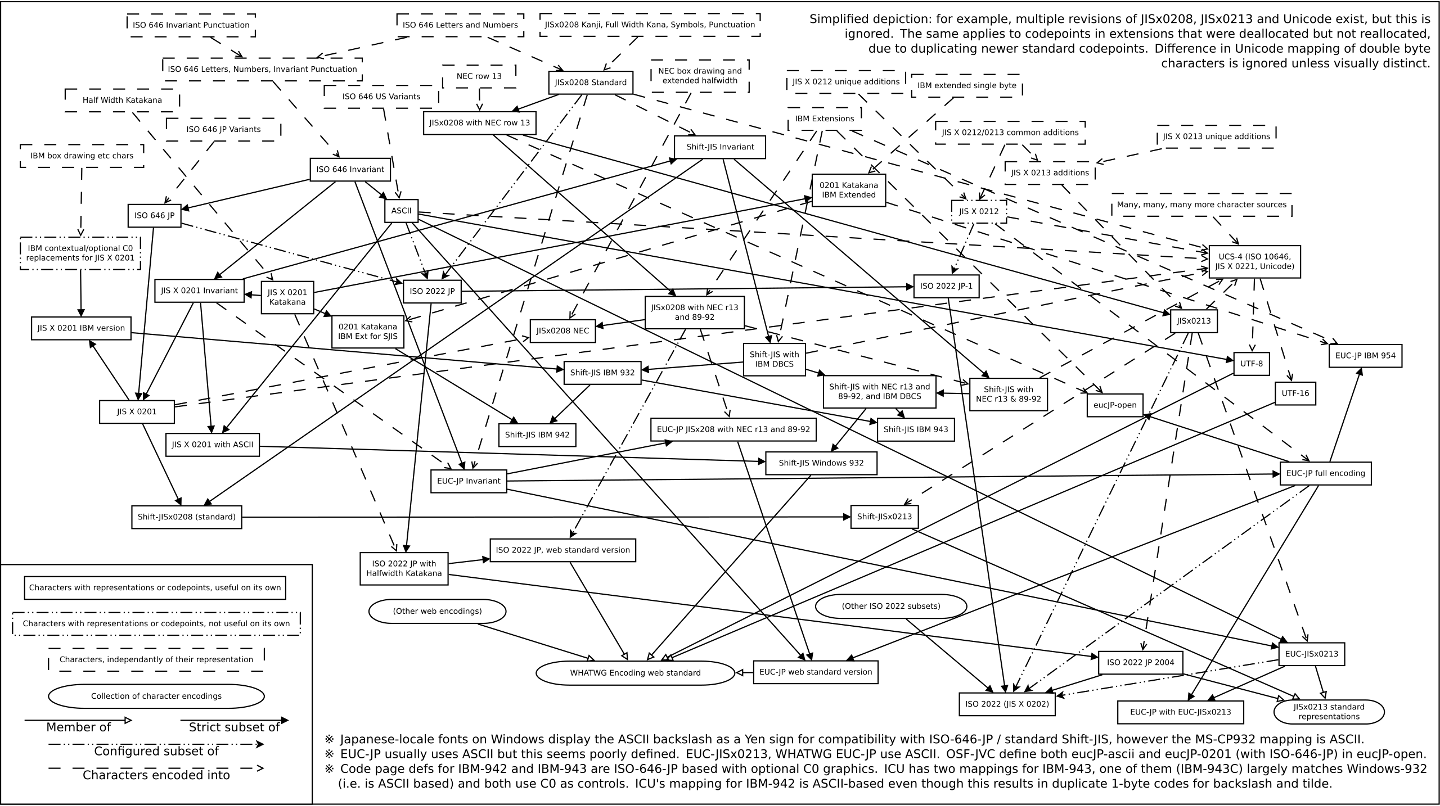 By HarJIT, CC BY 4.0, https://commons.wikimedia.org/w/index.php? curid=62685538
By HarJIT, CC BY 4.0, https://commons.wikimedia.org/w/index.php? curid=62685538
В конце концов, нашлись такие ребята, которые в свое время сказали: «Хватит это терпеть!», и сделали как в меме «Что делать, когда у нас и так много конкурирующих стандартов?» — еще один. Назвали Unicode, определили миссию: «Соберем в себе все возможные начертания и символы, которые вообще человечество когда-либо создавало». С переменным успехом это получается.
Но мало собрать все символы — нужно их хранить и передавать. И для этого придумали несколько Unicode Transformation Format — UTF.
UTF-8 использует переменное количество байт на один символ — от 1 до 6. UTF-16 кодирует количеством байтов кратным 2. UTF-32 фиксированной длины — всегда 4 байта.
Простой символ латинского алфавита J живёт в однобайтовом диапазоне. Буква Д уже в двухбайтовом промежутке. А эмодзи ленивца
