Изоморфные React-приложения: производительность и масштабирование

Денис Измайлов (DenisIzmaylov)
Всем привет! Вкратце расскажу о себе. Я — Денис Измайлов. Последние 5 лет сосредоточился на JS-разработке, делал много Single Page Application, highload, React, выступал на MoscowJS несколько раз, каммитил webpack и т.д.
Сегодня хотел бы поговорить вот о чем: почему от Single Page Application в его классическом виде стоит отказаться; как изоморфные приложения отразятся на Вашей зарплате; и что вы будете делать на этих выходных? 
Было бы идеально, если бы у вас уже был какой-то опыт работы с React 14, с webpack, понимали, как работает ES6, что-то делали с express/koa, и хотя бы образно представляете, что такое изоморфные приложения, они же универсальные.
Часть 1.
Web стал очень большим. Сейчас разработка под web стала уже тонкой гранью между наукой и искусством.
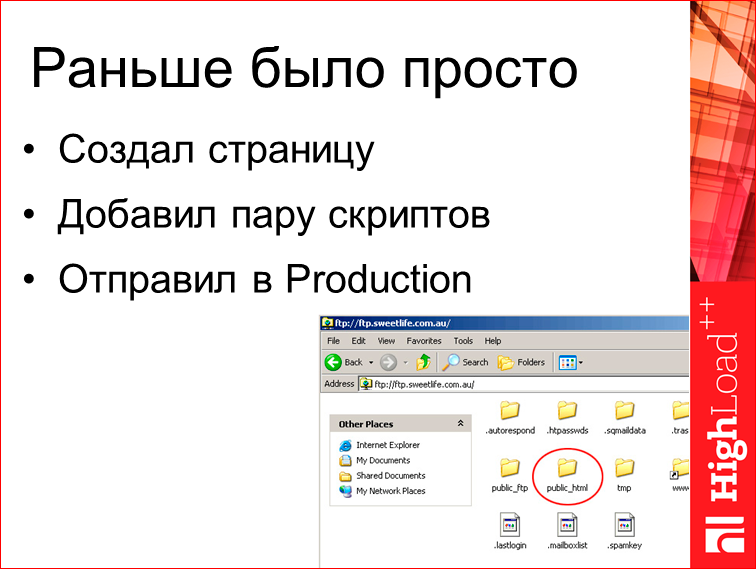
Раньше было достаточно просто: сделал какой-то скрипт на сервере, добавил пару JS и отправил в продакшн, все работало.
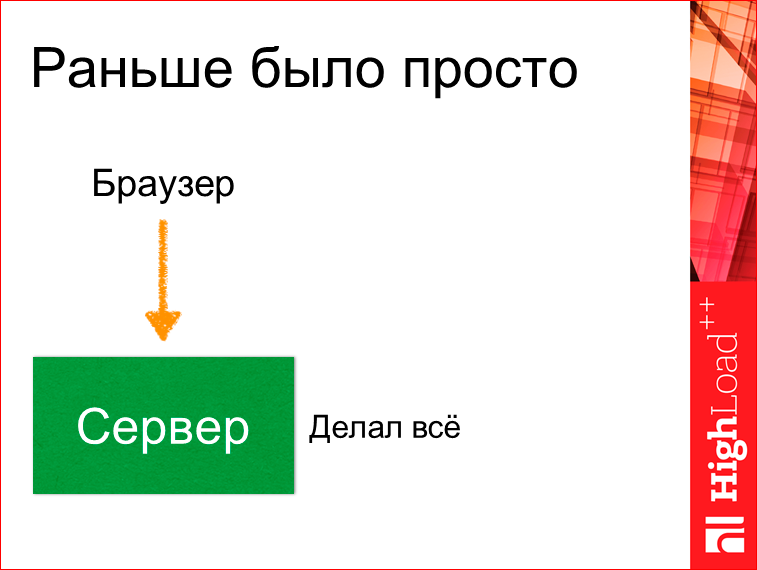
Браузер делал запрос к серверу, а сервер делал абсолютно все, и отдавал какую-то HTML-страницу.
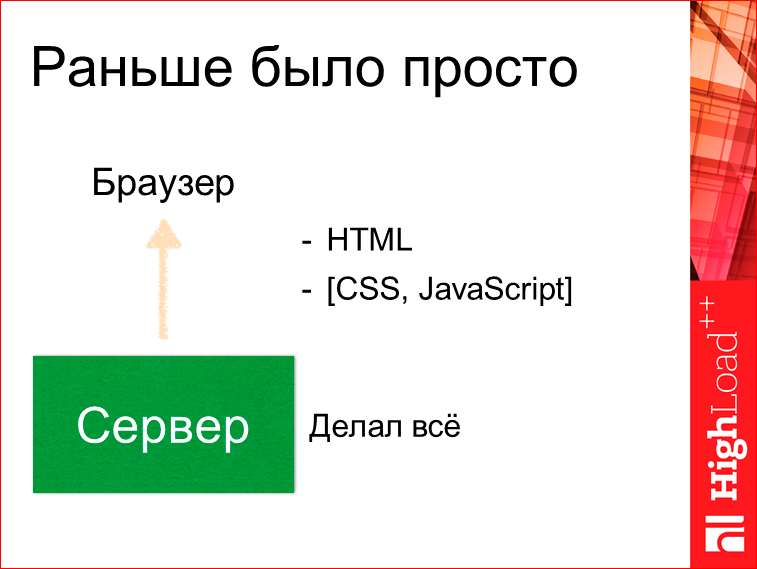
CSS, JS — это было опционально, практически не необходимо. Это работало. Но потом начали выделятся Single Page Application (SPA).
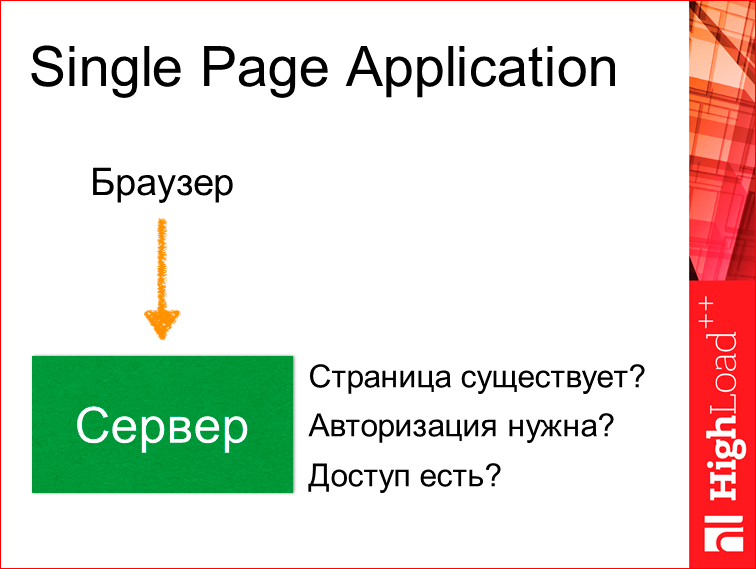
Код на клиентской части стал разрастаться. Сервер уже стал исполнять маленькую роль. Буквально проверялось, существует ли у нас страница, необходима ли авторизация, есть ли у нас доступ к нему?
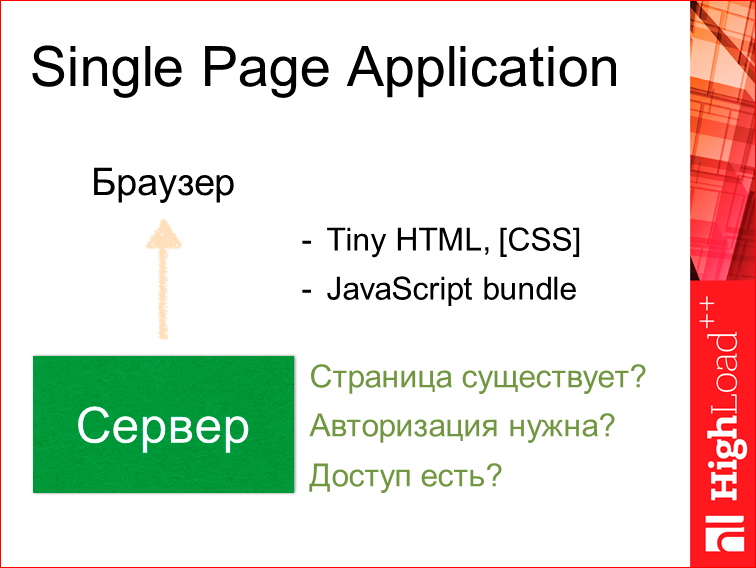
И сервер отдавал уже небольшой HTML, CSS и огромный JS bundle.

Плюсы здесь достаточно большие, т.е. легко начать писать — посмотрел доклад про webpack, настроил, сделал маленький HTML, подключил Redux, React, и оно все заработало.
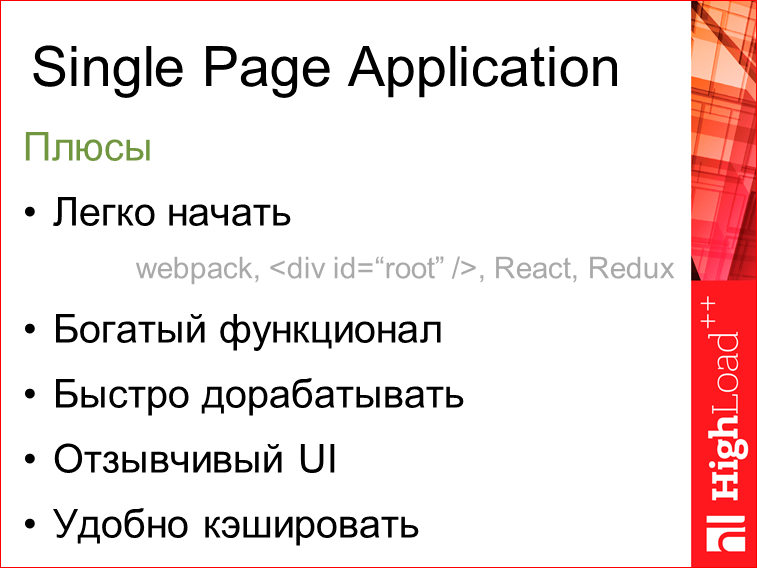
- Богатый функционал. Мы все прогружаем сразу в случае Single Page, и нам не надо заботиться о том, что у нас чего-то нет. Мы можем включать туда абсолютно все, что угодно — картинки, изображения, можем даже видео засунуть внутрь bundle, и это будет работать.
- Быстро дорабатывать, достаточно легко — нам не надо будет заботиться ни о какой оптимизации, у нас все работает, у нас все супер, все классно, мы можем просто добавлять-добавлять-добавлять.
- Отзывчивый UI — соответственно, у нас все загружено, и не надо ничего догружать.
- Это все очень удобно кэшировать. Когда мы загрузили раз какой-то bundle, он у нас уже всегда сохраняется в кэше в браузере и следующий раз у нас быстро загружается.
И не одного минуса? Минусы, есть.

Во-первых, из-за того, что bundle очень большой, порой достигает 3–5 Мб, его очень долго в первый раз загружать. Т.е. часто, когда заходишь в первый раз на сайт, на ресурс какой-то, либо после обновления на прошлый, видим колесико, которое многим не нравится. Т.о. первое обращение к приложению происходит достаточно долго. Исполняется это тоже не быстро. И память это кушает прилично.

Сложность поддержки. Кто поддерживал большие Single Page Application приложения, тот знает, что часто какие-то плагины, которые мы добавляем на некоторые, даже отдельные страницы, могут повлиять на любые другие страницы. Т.е. мы это не можем качественно проконтролировать. И memory leak. Мало кто тестировал, но когда приложение большое и оно у нас работает долго во вкладке, то часто бывает, что память разрастается, и все у нас почему-то начинает виснуть. 3–4 часа прошло и… Но мы это не тестируем, как правило.

Соответственно, долгая загрузка, сложность поддержки, пустая страница, один url (позже объясню, почему это минус) и старые браузеры. Недавно проводили исследования и смотрели, что даже сейчас в наш 2015–2016-ый года, уже, казалось бы, все браузеры должны были обновиться, но нет. 5% — это 12-ая Опера и 7–8-ой IE, и 6-ой даже присутствует. Буквально на прошлой неделе смотрели.
Разве это минусы? Для бизнеса это минусы.
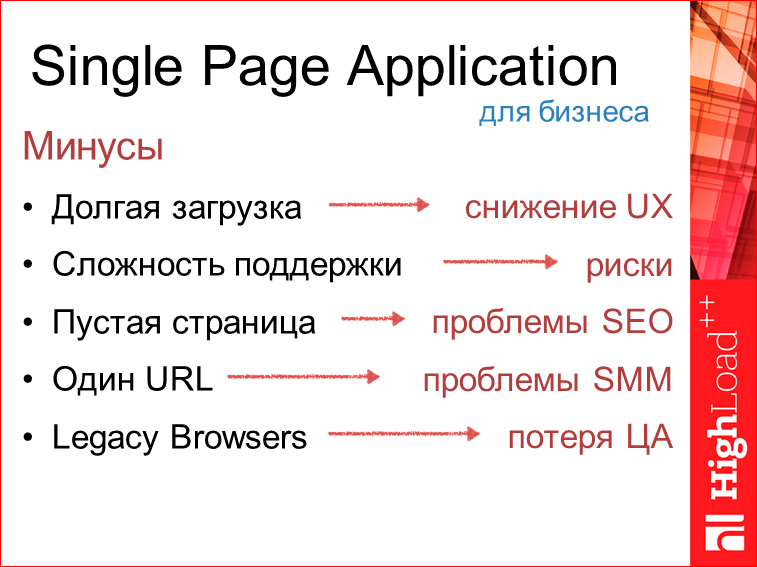
Долгая загрузка — это потери UX, в который вкладываются большие деньги. Сложность поддержки — это риски. Это риски как не уложиться в срок, так и вылезти за бюджет. Пустая страница — это проблемы SEO. Тут у многих может возникнуть такое возражение: есть же пререндеры, наше Angular-приложение может быть легко отрендеренно заранее. Но это, по сути, хак. Там очень мало возможностей в связи с этим. 1 URL — это проблема SMM. SMM — это значит, что пользователь не может расшарить спокойно вашу страницу в социальных сетях, она будет вести на одну страницу. И соответственно, если эта страница не исполнится на старом браузере, то, если у вас нет полифилов, от которых сейчас многие отказываются, то человек на старом браузере в этих 5%, увидит пустую страницу. Все это для бизнеса расходы.
Что делать? Мы можем сейчас взять лучшее из этих двух миров и сделать это в виде изоморфных приложений.

В 2011 году Чарли Роббинс сформулировал это так, что под изоморфным мы подразумеваем тот код, в котором каждая взятая строка может исполнятся как на сервере, так и на клиенте. С небольшими исключениями.
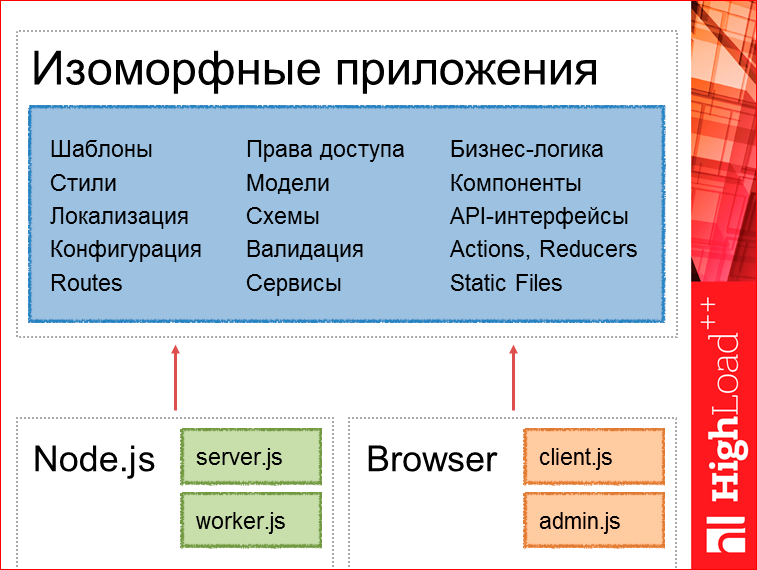
Здесь очень важно сейчас сосредоточиться и понять, потому что возникает вопрос:, а как делить, а как организовать изоморфные приложения? Я попытался сформулировать так, что вот эти части — шаблоны, сервисы, статичные файлы, Actions, Reducers, оно у нас выделяется в универсальное абсолютно, а небольшие стартовые вещи — это может быть клиентский файл, или админка, т.е. то, что инициализирует роутер — это у нас уже может быть для серверной части своя, для клиентской части — своя.
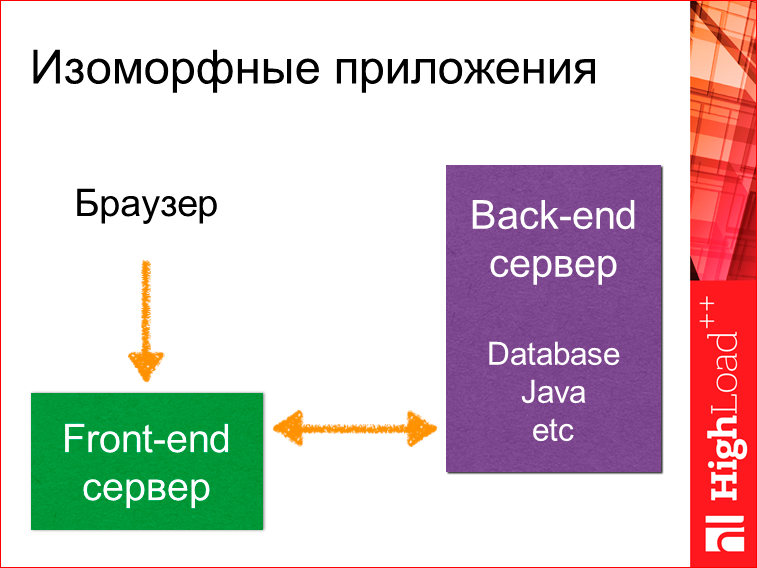
Выглядит это все так, что у нас есть браузер, есть фронтенд-сервер (выделяется отдельно), и есть старый привычный бэкенд-сервер. Это может быть даже база данных без какого-то сервера. Браузер обращается к фронтенд-серверу, тот может обратиться за данными куда-то к старому серверу либо к базе данных, получить данные.
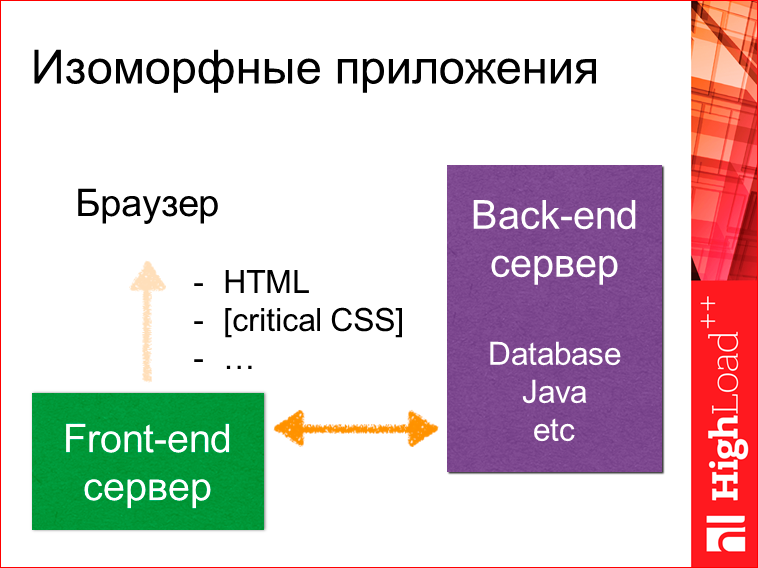
Далее он может сформировать полный HTML, отдать какой-то критичный CSS, который необходим только для рендеринга этой страницы, а не, как в случае с SPA, для рендеринга всего приложения, которое может вполне вам понадобиться.
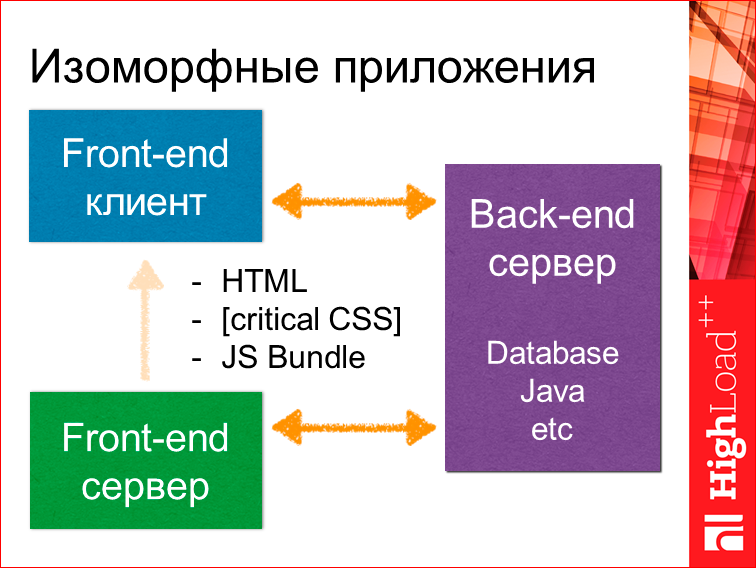
И в конце отдать JS bundle. В этот момент у нас будет собран на клиентской части и поднят фронтенд-клиент, который в свою очередь дальнейшую коммуникацию может осуществлять с бэкенд-сервером предыдущим, допустим, через RESTful API.

Итого, мы имеем единую среду исполнения, общую кодовую базу и полный контроль, потому что, когда у нас бэкенд-сервер, например, на Java, фронтенд-разработчик достаточно проблематично может повлиять или запушить какие-то изменения на сервер. И опять же, имеем экосистему, т.е. node package manager.
Как это реализовать в жизни? Через Sever-Side Rendering.

Суть такая, что у нас сборка при Server-Side Rendering, сборка всего приложения на React«е, например, происходит на фронтенд-сервере, на Node.js. В то же время мы получаем моментально отображение, т.е. у нас отрендерилось приложение, мы сразу его получаем в виде HTML — еще до загрузки JS. И пользователь видит его моментально. Т.е. при первом же обращении. А когда загрузится JS, у нас React просто добавит обработчики события, а это все происходит достаточно быстро.
Код на серверной части выглядит вот так:

Т.е. у нас есть некий рендерер React«овский, это уже 14-ая версия, и есть то самое наше приложение. Т.е. это компилируется в строку и отдается. Понятно, что у нас внутри application уже завернуты все роуты и там, т.к. у нас тот же самый код исполнится, мы уже знаем, что у нас есть какой-то путь, что-то мы должны отобразить для этого пути, у нас будет отображено необходимое нам дерево.

В итоге, что мы имеем? Пользователь мгновенно видит страницу, и у нас не происходит каких-то дополнительных запросов на получение данных, потому что для ее отображения у нас уже все данные собраны и внутри поставлены, где надо. И страница может запускаться даже без JS. Это очень важно, чтобы работать, на том же legasy-браузере из тех 5%. Пусть у них там что-то будет не функционировать так классно, как это сейчас на последнем хроме, но оно будет более-менее работать. И полноценная URL-навигация, и в то же время мета-теги, т.е. это все то, что позволит нам (для продуктовых историй это особенно важно) шарить, делится какими-то ссылками на отдельно взятые страницы гораздо более эффективно, чем как это принято сейчас с хэшом. И в то же время у нас имеется сохранение всех возможностей, актуальных для JS, которые мы имеем.
Часть 2. Производительность и масштабирование. Масштабирование тут не по нагрузочной производительности, а про функциональное масштабирование — как мы будем расти.

В случае Server-Side Rendering все супер, когда у нас все данные уже есть. Все понимают, что Node.js — это однопоточная история, т.к. как обычный JS и, соответственно, все супер, когда у нас данные есть, и мы в одном потоке может все это отрисовать.

Но что, если нам эти данные необходимо получить? Сделать какой-то запрос при этом, мы не имеем право заблочить поток, текущий event loop.

Тут у нас есть три основных способа: необходимые данные изъять вручную и потом отдать как на входящий state; использовать Facebook Relay; и я разрабатывал плагин для Redux-catch-promise.

Вручную для каждой страницы — там все достаточно просто, мы получаем state из базы и потом просто отдаем в renderToString. Ничего у нас такого не меняется, но в этом случае нам для каждой страницы приходится придумывать, а как мы на сервер будем эти данные получать? Мы уже не можем просто взять и добавить страницу, нам придется эти данные как-то извлекать, лезть, дополнительные сущности вводить в проект. Тоже не всегда удобно.

Facebook Relay, который они презентовали несколько месяцев назад — это фреймворк, который позволяет декларативно задавать в компонентах специальные запросы на получение данных. Там достаточно интересная история, т.е. вы декларативно указываете запрос, какие данные вам необходимы, условия, что они завязаны. Relay эти все данные аккумулирует и потом разом кидает на сервер, и вы их получаете разом. Т.е. это происходит батчинг запросов, о котором мы говорили. Единственная проблема, что на сервере это пока не доступно, т.е. server-side, но в первом квартале 2016-го года Facebook обещает уже реализовать это, и будет все работать. Там ссылка на GitHub issues, можете наблюдать.

Redux-catch-promise — это небольшой лайфках, который я сделал, работая для одного проекта. Что такое Redux? Я рассказывал на MoscowJS про него. Это state-контейнер для React. По сути, это замена Flux, гораздо более удачная замена как показывают. Ссылка на выступление есть. Redux-catch-promise — это именно middleware, т.е. плагин для Redux.

Что он делает? Мы вешаем callback для захвата Promise-экшнов в потоке и делаем рендер приложения. При рендере компонента у нас делается запрос, т.е. мы отправляем экшн на получение данных и диспатчим ему в ответ Promise. Этот Promise мы отлавливаем на верхнем уровне, где мы рендерим приложение, и в итоге у нас получается коллекция Promise«ов. Дождавшись ее разрешения, мы рендерим повторно приложение с полученными данными. Тут получается достаточно удобно, некий компромисс между ручным получением и тем, что сейчас реализовано в Relay.

Ссылка на GitHub здесь, там есть пример, может быть, немного устаревший, у нас все очень быстро меняется.
Производительность — вторая часть.

Когда начали смотреть, насколько быстро Server-Side рендерится на обычном MacBook«е…
Чтобы понимание было — страница занимает 56 Кбайт, выглядит она буквально в 4 экрана, небольшой профиль…
Со всеми данными, возьмем ab по тестированию, запрос полноценный. Вышла 61 мс.

Немного непонятно, много это или мало. Допустим, тот же самый, если Hendlebars мы сделаем, то это будет 8 мс.

Думаю, так разница очевиднее, что не супер.
Начинаем искать что-то, смотрим, идем в Google — там ничего конкретного. Пробуем спросить Twitter, тоже все молчат, ретвитят, но никаких ответов мы не находим.
В то же время попробуем поставить NODE_ENV в production.

Запускаем и — бац! — практически в два раза быстрее. Супер, интересно. Вроде лучше, но все еще не торт.

Идем дальше. Посмотрим, в GitHub issues полазим.

Найдем интересное такое «Server rendering is slower with npm react». Там дается решение, что необходимо подключать, а не делать просто импорт react, подключать файл явно react.min.js.

Ок, попробуем. Создадим для теста некий node_modules. Для чистоты сделаем так. Тут мы явно в случае production используем min.js. И в итоге, как это изменило результат? Запускаем.

Получилось даже медленнее.

Слайд, что тест провален.
Как оказалось, тот совет хорошо работал для прошлого React«а, а для 14-го не работает. Общая картинка выглядит примерно вот так:

Т.е. 8 мс занимает Hendlebars, все остальное — это, собственно, если production мы указываем, и фиолетовый — если мы используем js min. Всего лишь на 39% меньше.
Какие-то дальнейшие глобальные изыскания — никакого хака в Server-Side Rendering мы не увидим. На уровне React это все оптимизировать особо некуда, сейчас пока. Есть только достаточно hardcore«ные пути.

Если глобально разделить это, то использовать некие Precompilation и Cache, это разделить Rendering. И использовать недавно вышедший плагин React DOM Stream. Использовать Facebook BigPipe — это очень интересное расширение от Facebook, которое уже давно используется. И HAProxy — это больше к devops, другим секциям доклада.

В чем суть Precompilation? По сути, если мы будем отталкиваться от того, что UI — это результат выполнения некой функции от state — f (state), где f — это React Component, а state — это может быть, допустим, только путь, если это какой-то сайт или дерево страниц, или это может быть у нас завязано на еще что-то. Мы можем достаточно легко по этому ключу кэшировать наш HTML, который мы рендерим.
Простое решение — это просто использовать redis. Если нам нужно, чтобы у нас сразу был быстрый ответ, мы можем использовать redis, плюс очереди, плюс воркеры. Т.е. мы показываем какое-то колесико, загрузку делаем частичную, а в фоне у нас воркеры рендерят при каждом запросе наш компонент. Тут мы получим, где First render, то, что у нас, по сути, в этом случае страница будет отдана моментально, все срендерится у нас в фоне, и при следующем запросе мы уже можем отдать закэшированную часть компонентов.
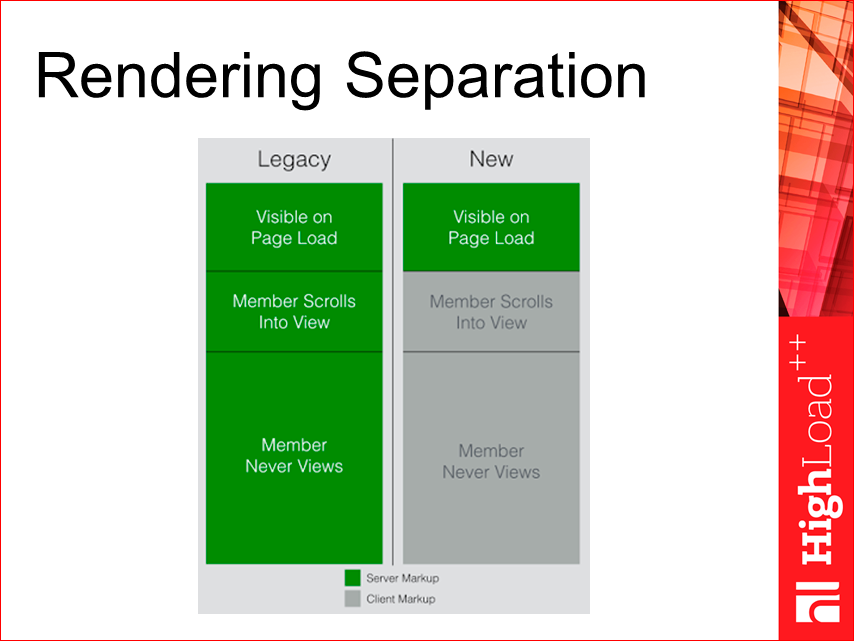
Rendering Separation. Linkedin провел исследования, и они пронаблюдали, что большинство из их страниц (длинных, особенно) не нуждаются в полном серверном рендеринге, достаточно показать только первую часть — видимую. А все остальное мы уже можем догружать отдельно, допустим клиентским JS. И у них в большинстве случаев клиенты видели только первую часть, никто не прокручивал, т.е. таким образом мы можем первую часть на сервере отрендерить и сразу ее отдать, а дальнейшую часть уже программно загрузить через JS. Это дает достаточно большое преимущество в перформансе и в ресурсах.
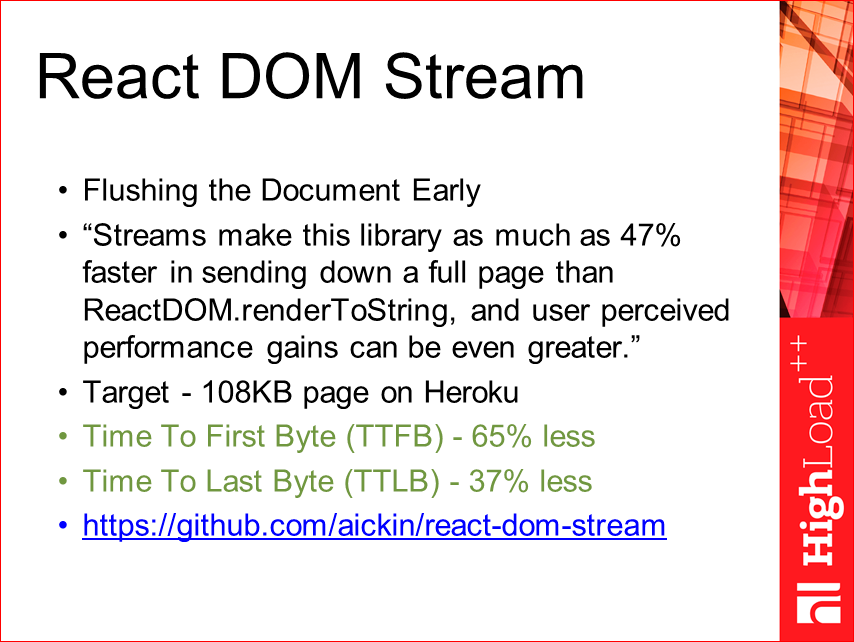
React DOM Stream — это уже следующее расширение — это недавно опубликованный проект. Человек (aickin) форкнул React и реализовал там технологию преждевременного сброса, как http обычного, т.е. вы рендерите-рендерите, а потом разом все отдает. В данном случае он смог реализовать технологию, когда у вас сразу по мере рендеринга компонента, а не в виде html-кода, они сбрасываются в сервер stream. Получается достаточно интересный эффект производительности. Время до первого байта сокращается уже на 65%, т.е. это еще почти в 2 раза, и до последнего байта — на 37%. Если совмещать эти два подхода, получается достаточно хорошо… Единственный минус, что это затронуло сам React, его необходимо было немного доработать, поэтому он там использует форк, и это не тот React, который официальный. Там сейчас идет дискуссия по этому поводу, можете наблюдать, скоро будет готово.
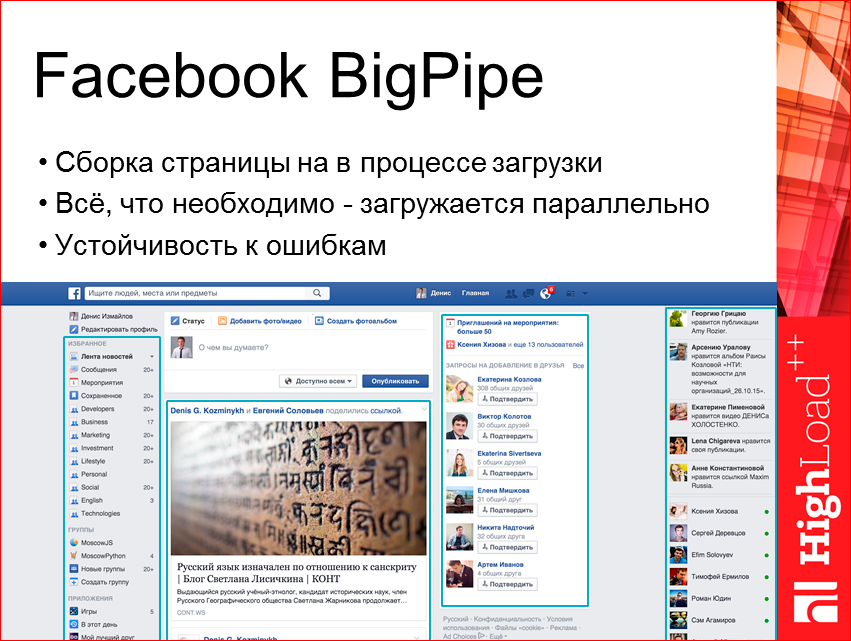
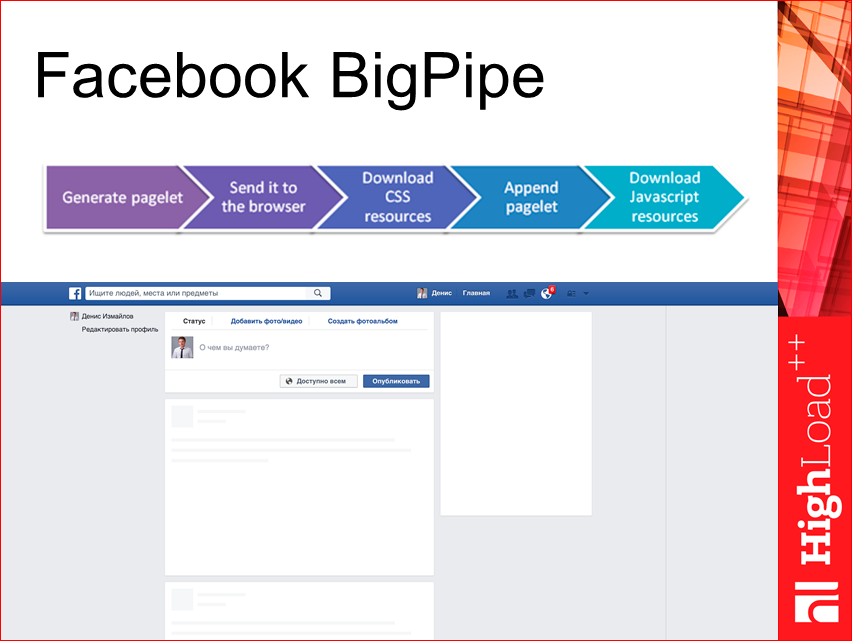
Facebook BigPipe. Очень классное расширение. Они его сделали очень давно, года 2–3 назад. Это когда сборка страницы осуществляется в процессе загрузки. Т.е. у нас все загружается параллельно, от этого у нас получается устойчивость к ошибкам. Суть такая: у нас есть страница, и у нее есть определенные части, которые мы можем выделить и загружать уже в процессе. Т.е. в процессе загрузки страницы мы формируем вызов необходимых для этих блоков JS, CSS, и у нас данные сами загружаются, через какой-то json pipe.
Получается, что мы при первом рендере видим такую, почти полную страницу. Мы можем увидеть даже что-то важное, как Yandex, например, делает. В Yandex, когда вы вводите поисковую фразу, нажали enter, у вас сначала отобразится верхний toolbar с вашим запросом, и только потом догрузятся сами результаты выдачи. Здесь процесс изображен.

HAProxy. Это немного про DevOps, но думаю, у всех сейчас есть доступ к DevOps-специалисту, либо еще что-то сами потом можете настроить. Суть такая, что на продакшне лучше поднимать несколько нод и между ними уже циркулировать.
В заключение хочу привести несколько полезных материалов, тут две страницы:

А в качестве рекомендаций — присоединяйтесь к сообществу MoscowJS и следите за обновлениями.

Там постоянно у нас что-то интересное происходит.
Самое важное — это улучшайте английский, приходите на англоязычные доклады и «не читайте советских газет». Читайте оригиналы и технические блоги. Допустим, те же компании — Linkedin, Facebook, Netflix — они очень актуальные вещи пишут. В Twitter вы всегда можете увидеть все эти анонсы. И Twitter, GitHub сейчас являются, наверное, основными вещами, с помощью которых вы можете держать руку на пульсе и понимать, что происходит в мире фронтенда.
Хочу две цитаты дать, которые мне очень понравились в этой связи:

«Большинство проблем алгоритмов можно решить сменой структуры данных». Это Андрей Ситник сказал в одном из выпусков РадиоJS. И в одном из видео: «Changes is our work», т.е. изменения — это наша работа. Это Jake из Google сказал.
Надеюсь, я сейчас ответил на вопрос, почему от классического Single Page Application необходимо отказаться и куда стоит двигаться. Это на самом деле не так сложно, как кажется, и я призываю дальше двигаться в эту сторону.
Контакты
» DenisIzmaylov
» github
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++ специальной секции «Производительность фронтенда».Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая Frontend Conf. Это профессиональная конференция для разработчиков высоконагруженных систем. А Денис, кстати, входит в её Программный комитет.
Комментарии (1)
 MrCheater
MrCheater
6 января 2017 в 19:16
0↑
↓
Спасибо за обзор.
«как изоморфные приложения отразятся на Вашей зарплате» — хотелось бы послушать и про это.
Про большой размер Bundle-JS: на самом деле можно всё распилить на небольшие чанки (отдельные куски js-кода) и грузить их динамически на клиенте через SystemJS. Webpack 2 нам поможет.
Пока что у React-а весьма плачевная ситуация с роутингом — с 2013 никто так и не осилил сделать всё по уму. Вся надежда на React Router v4. Но пока что там всё очень сыро и недоделано.
А в целом про изоморфные приложения, что хочу добавить: их разработка требует весьма больших компетенций, очень легко где-нибудь облажаться, нужно разбираться в десятках современных инструментов и использовать некоторые подходы к разработке, которые плохо ложатся в головы программистов на JavaScript, например, практически нельзя использовать синглтоны и глобальные переменные в изоморфном коде, а те кто привык писать клиентский код лепят их где попало, ибо привыкли, что всегда один экземпляр клиента.
