Исследование быстродействия СУБД MS SQL Server Developer 2016 и PostgreSQL 10.5 для 1С
Цели и требования к тестированию »1С Бухгалтерии»
Основной целью проводимого тестирования является сравнение поведения системы 1С на двух разных СУБД при прочих одинаковых условиях. Т.е. конфигурация баз данных 1С и первоначальная заполненность данными должны быть одинаковыми при проведении каждого тестирования.
Основными параметрами, которые должны быть получены при тестировании:
- Время выполнения каждого теста (снимается отделом Разработки 1С)
- Нагрузка на СУБД и серверное окружение во время выполнения теста снимается- администраторами СУБД, а также по серверному окружению системными администраторами
Тестирование системы 1С должно выполняться с учетом клиент-серверной архитектуры, поэтому необходимо произвести полноценную эмуляцию работы пользователя или нескольких пользователей в системе с отработкой ввода информации в интерфейсе и сохранением этой информации в базе данных. При этом, необходимо, чтобы большой объем периодической информации был разнесен по большому отрезку времени для создания итогов в регистрах накопления.
Для выполнения тестирования разработан алгоритм в виде скрипта сценарного тестирования, для конфигурации 1С Бухгалтерия 3.0, в котором выполняется последовательный ввод тестовых данных в систему 1С. Скрипт позволяет указать различные настройки по выполняемым действиям и количеству тестовых данных. Детальное описание ниже по тексту.
Описание настроек и характеристик тестируемых сред
Мы в компании Fortis решили перепроверить результаты, в том числе с помощью известного теста Гилева.
Также нас подстегнуло к тестированию в том числе и некоторые публикации по результатам изменения производительности при переходе от MS SQL Server к PostgreSQL. Такие как: 1С Батл: PostgreSQL 9,10 vs MS SQL 2016.
Итак, вот инфраструктура для тестирования:
Сервера для MS SQL и PostgreSQL являлись виртуальными и запускались поочередно для нужного теста.
Model: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5–2630 v3 @2.40GHz (2 sockes * 16 CPU HT = 32CPU)
RAM: 212 GB
ОС: VMWare ESXi 6.5
PowerProfile: Performance
Дисковая подсистема гипервизора:
Контроллер: Adaptec 6805, Cache size: 512MB
Volume: RAID 10, 5.7 TB
Stripe-size: 1024 KB
Write-cache: on
Read-cache: off
Диски: 6 шт. HGST HUS726T6TAL,
Sector-Size: 512 Bytes
Write Cache: on
PostgreSQL был настроен следующим образом:
- postgresql.conf:
Базовая настройка делалась по калькулятору — pgconfigurator.cybertec.at, параметры huge_pages, checkpoint_timeout, max_wal_size, min_wal_size, random_page_cost менялись на основе информации, полученной из источников, упомянутых в конце публикации. Значение параметра temp_buffers увеличивалось, исходя из предложения, что 1С активно использует временные таблицы:listen_addresses = '*' max_connections = 1000 #Выделяемый под кэш данных размер ОЗУ. Работа со строками происходит в основном в этом участке памяти. На системах с 32ГБ ОЗУ рекомендуется выделять около 25% от общего объема памяти. shared_buffers = 9GB #Использование больших страницы памяти(Настройка ядра Linux - vm.nr_hugepages). huge_pages = on #Лимит памяти для временных таблиц на сессию. temp_buffers = 512MB #Лимит памяти на одну операцию типа ORDER BY, DISTINCT, merge joins, join, hash-based aggregation, hash-based processing of IN subqueries. #Выставлен из расчета, что 1С делает сложные большие запросы (профиль "Mostly complicated real-time SQL queries" в калькуляторе). Возможно стоит уменьшить до 64MB. work_mem = 128MB #Лимит памяти для служебных операций. VACUUM, создание индексов, etc. maintenance_work_mem = 512MB #Совместно с настройками ядра (vm.dirty_background_bytes, vm.dirty_bytes), данные параметры позволяют устранить всплески нагрузки на IO в процессе CHECKPOINT. checkpoint_timeout = 30min max_wal_size = 3GB min_wal_size = 512MB checkpoint_completion_target = 0.9 seq_page_cost = 1.0 #Настройки для планировщика запросов. Значение по-умолчанию - 4. Для RAID10 рекомендуется уменьшать. random_page_cost = 2.5 #Указание планировщику примерного потенциального размера всей занимаемой postgres памяти, включая страницы в PageCache. effective_cache_size = 22GB - Ядро, параметры ОС:
Настройки заданы в формате файла профиля для демона tuned:[sysctl] #Параметры задающие объем грязных страниц (PageCache), по достижении которого ядро должно начинать фоновую/принудительную запись этих страниц на диск. #По-умолчанию объем задан в процентах(10,30) что на современных системах с большим количеством ОЗУ приводит к всплескам нагрузки на систему ввода/вывода. #Важно для оптимизации производительности CHECKPOINT и устранения всплесков на I/O. #Заданные абсолютные значения применимы для использования с RAID-контроллером имеющим write-back cache объемом 512MB. vm.dirty_background_bytes = 67108864 vm.dirty_background_ratio = 0 vm.dirty_bytes = 536870912 vm.dirty_ratio = 0 #Использовать SWAP по-минимуму. Совсем отключать не стоит, чтобы минимизировать вероятность OOM. vm.swappiness = 1 #Планировщик подразумевает, что заданный период времени процесс использует кеш CPU. #Увеличение этого параметра снижает количество миграций процессов с одного CPU на другой. #Параметр заметно влияет на производительность. kernel.sched_migration_cost_ns = 5000000 #Отключение группировки процессов по CPU на основе сессии. #Для серверов этот параметр нужно выставлять в 0. Заметно влияет на производительность. kernel.sched_autogroup_enabled = 0 #Выделение памяти под большие страницы. Параметр заметно влияет на производительность. #Способ расчетам описан в документации - https://www.postgresql.org/docs/11/kernel-resources.html#LINUX-HUGE-PAGES vm.nr_hugepages = 5000 [vm] #Отключение прозрачных больших страниц. Так как СУБД не использует однородные продолжительные сегменты памяти, этот параметр рекомендуется отключать. Тем более, что включены нормальные большие страницы. transparent_hugepages=never #Параметры энергосбережения CPU. В виртуальной машине едва ли имеют смысл, но на железном сервере просто необходимы. [cpu] force_latency=1 governor=performance energy_perf_bias=performance min_perf_pct=100 - Файловая система:
#Создание ФС: #stride и stripe_width рассчитывались для упомянутого RAID 10 из 6-ти дисков с размером stripe в 1024kb mkfs.ext4 -E stride=256,stripe_width=768 /dev/sdb #Опции монтирования: /dev/sdb /var/lib/pgsql ext4 noatime,nodiratime,data=ordered,barrier=0,errors=remount-ro 0 2 #noatime,nodiratime - отключить запись времени доступа к файлам и каталогам #data=ordered - Журнал включен только для метаданных. Метаданные записываются после данных #barrier=0 - Барьер обеспечивает последовательную запись данных журнала ФС. На RAID-контроллерах с батарейкой барьер можно отключить.
MS SQL был настроен следующим образом: 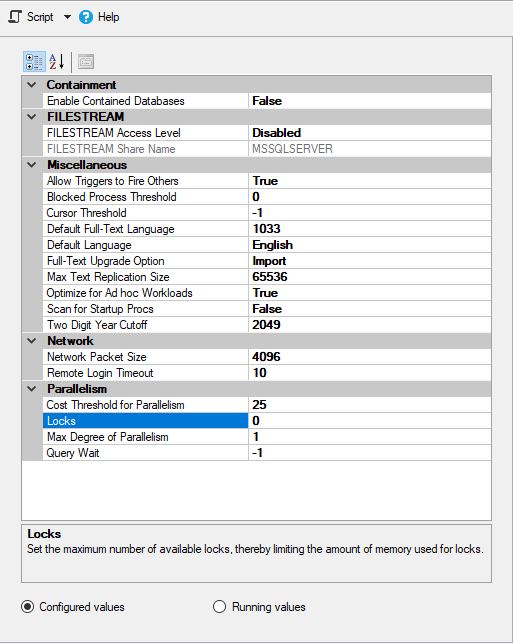
и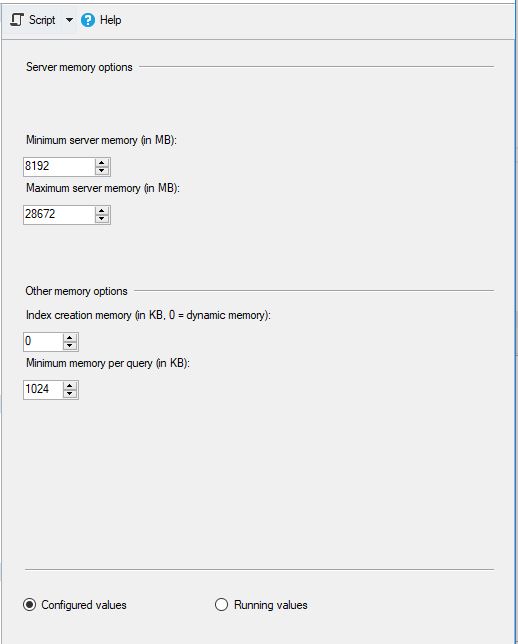
Настройки кластера 1С оставили стандартными: 
и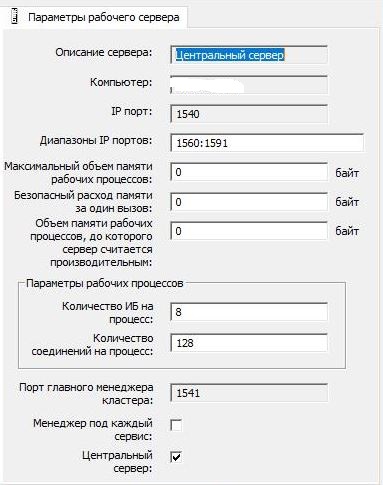
На серверах не стояла антивирусная программа и не было установлено ничего стороннего.
Для MS SQL, БД tempdb была вынесена на отдельный логический диск. Однако, файлы данных и файлы журналов транзакций для баз данных располагались на одном логическом диске (т е не было сделано разнесения файлов данных и журналов транзакций на отдельные логические диски).
Индексирование дисков в Windows, где располагалась MS SQL Server, было отключено на всех логических дисках (как это принято делать в большинстве случаев на продовских средах).
На каждый день выполнения запускаются блоки ввода и вывода информации:
- Блок 1 «СПР_ПТУ» — «Поступление товаров и услуг»
- Открывается справочник «Контрагенты»
- Создается новый элемент справочника «Контрагенты» с видом «Поставщик»
- Создается новый элемент справочника «Договоры» с видом «С поставщиком» для нового контрагента
- Открывается справочник «Номенклатура»
- Создается набор элементов справочника «Номенклатура» с видом «Товар»
- Создается набор элементов справочника «Номенклатура» с видом «Услуга»
- Открывается список документов «Поступления товаров и услуг»
- Создается новый документ «Поступление товаров и услуг» в котором заполняются табличные части «Товары» и «Услуги» созданными наборами данных
- Формируется отчет «Карточка счета 41» за текущий месяц (если указан интервал дополнительного формирования)
- Блок 2 «СПР_РТУ» — «Реализация товаров и услуг»
- Открывается справочник «Контрагенты»
- Создается новый элемент справочника «Контрагенты» с видом «Покупатель»
- Создается новый элемент справочника «Договоры» с видом «С покупателем» для нового контрагента
- Открывается список документов «Реализация товаров и услуг»
- Создается новый документ «Реализация товаров и услуг» в котором заполняются табличные части «Товары» и «Услуги» по указанным параметрам из ранее созданных данных
- Формируется отчет «Карточка счета 41» за текущий месяц (если указан интервал дополнительного формирования)
- Формируется отчет «Карточка счета 41» за текущий месяц
В конце каждого месяца, в котором производилось создание документов выполняются блоки ввода и вывода информации:
- Формируется отчет «Карточка счета 41» с начала года на конец месяца
- Формируется отчет «Оборотно-сальдовая ведомость» с начала года на конец месяца
- Выполняется регламентная процедура «Закрытие месяца»
По итогу выполнения выдается информация о времени проведения теста в часах, минутах, секундах и миллисекундах.
Основные возможности скрипта тестирования:
- Возможность отключения/включения отдельных блоков
- Возможность указания общего количества документов для каждого из блоков
- Возможность указания количества документов для каждого из блоков за день
- Возможность указания количества товаров и услуг внутри документов
- Возможность задания списков количественных и ценовых показателей для записи. Служит для создания различных наборов значений в документах
План основных тестов для каждой из баз:
- «Первый тест». Под одним пользователем создается небольшое количество документов с простыми таблицами, формируются «закрытия месяцев»
- Ожидаемое время выполнения — 20 минут. Заполнение на 1 месяц. Данные: 50 документов «ПТУ», 50 документов «РТУ», 100 элементов «Номенклатура», 50 элементов «Поставщиков» + «Договор», 50 элементов «Покупателей» + «Договор», 2 операции «Закрытие месяца». В документах 1 товар и 1 услуга
- «Второй тест». Под одним пользователем создается существенное количество документов с заполнением таблиц, формируются закрытия месяцев
- Ожидаемое время выполнения — 50–60 минут. Заполнение на 3 месяца. Данные: 90 документов «ПТУ», 90 документов «РТУ», 540 элементов «Номенклатура», 90 элементов «Поставщиков» + «Договор», 90 элементов «Покупателей» + «Договор», 3 операции «Закрытие месяца». В документах 3 товара и 3 услуги
- «Третий тест». Под двумя пользователями запускается одновременное выполнение скрипта. Создается существенное количество документов с заполнением таблиц. Итоговым временем выполнения теста считается максимальное
- Ожидаемое время выполнения — 40–60 минут. Заполнение на 2 месяца. Данные: 50 документов «ПТУ», 50 документов «РТУ», 300 элементов «Номенклатура», 50 элементов «Поставщиков» + «Договор», 50 элементов «Покупателей» + «Договор». В документах 3 товара и 3 услуги
План дополнительных тестов для каждой из баз:
- Изменение структуры базы данных, проверка времени реструктуризации таблиц базы данных:
- Изменение справочника Договора
- Изменение справочника Контрагенты
- Изменение документа «Реализация товаров и услуг»
- Перепроведение документов «Поступление товаров и услуг» и «Реализация товаров и услуг» за указанный период
- Выгрузка базы данных в файл формата 1С »*.dt» и загрузка из него обратно
- Выполнение регламентной процедуры «Закрытие месяца» для одного из старых периодов
Результаты
А теперь самое интересное-результаты на СУБД MS SQL Server:
Тест Гилева:
Как видно из результатов, в общем синтетическом тесте СУБД PostgreSQL проиграла по производительности СУБД MS SQL в среднем на 14,82%. Однако, по последним двум показателям PostgreSQL показал значительно лучше результат, чем MS SQL.
Специализированные тесты для 1С Бухгалтерии:
Как видно из результатов, 1С Бухгалтерия примерно одинаково работает и на MS SQL, и на PostgreSQL при данных выше настройках.
В обоих случаях СУБД работала стабильно.
Конечно возможно нужен более тонкий тюнинг как со стороны СУБД, так и со стороны ОС и файловой системы. Все делалось так, как вещали публикации, которые говорили, что будет значительный прирост в производительности или примерно будет одинаково при переходе с MS SQL на PostgreSQL. Более того, в данном тестировании проводился ряд мероприятий по оптимизации самой ОС и файловой системы для CentOS, которые описаны выше.
Стоит отметить, что тест Гилева запускался многократно для PostgreSQL-приведены самые лучшие результаты. По MS SQL был запущен тест Гилева 3 раза, т к далее оптимизацией по MS SQL не занимались. Все последующие попытки были привести слона к показателям MS SQL.
После достижения оптимальной разности по синтетическому тесту Гилева между MS SQL и PostgreSQL, были проведены специализированные тесты для 1С Бухгалтерии, описанные выше.
Общий вывод заключается в том, что, несмотря на существенную просадку в производительности по синтетическому тесту Гилева СУБД PostgreSQL относительно MS SQL, при должных настройках, данных выше, 1С Бухгалтерию можно установить как на СУБД MS SQL, так и на СУБД PostgreSQL.
Замечания
Сразу необходимо отметить, что данный анализ делался только для сравнения производительности 1С в разных СУБД.
Данный анализ и вывод корректны только для 1С Бухгалтерии при условиях и версиях ПО, описанных выше. На основе полученного анализа невозможно точно сделать вывод, что будет при других настройках и версий ПО, а также при другой конфигурации 1С.
Однако, результат теста Гилева позволяет предположить, что на всех конфигурациях 1С версии 8.3 и новее при должных настройках максимальная просадка в производительности вероятнее всего составит не более 15% для СУБД PostgreSQL относительно СУБД MS SQL. Также стоит учесть, что любое детальное тестирование для точного сравнения занимает значительное время и ресурсы. Исходя из этого, можно сделать более вероятное предположение, что 1С версии 8.3 и новее можно перенести с MS SQL на PostgreSQL с максимальной потерей производительности до 15%. Объективных препятствий для перехода не выявлено, т к эти 15% могут и не проявиться, а в случае их проявления, достаточно просто закупить немного мощнее оборудование при необходимости.
Также важно отметить, что тестируемые БД были небольшими, т е значительно меньше 100 ГБ размером данных, а также максимальное количество одновременно работающих потоков было 4. Это означает, что для больших баз, размер которых существенно больше 100 ГБ (например, около 1 ТБ), а также для баз с интенсивными обращениями (десятки и сотни одновременных активных потоков) данные результаты могут быть некорректными.
Для более объективного анализа, будет полезно в будущем сравнить выпущенную MS SQL Server 2019 Developer и PostgreSQL 12, установленных на одной и той же ОС CentOS, а также когда MS SQL стоит на последней версии ОС Windows Server. Сейчас же PostgreSQL никто не ставит на ОС Windows, т к просадка в производительности у СУБД PostgreSQL при этом будет весьма существенной.
Конечно, тест Гилева говорит в общем о производительности и не только для 1С. Однако, на данный момент говорить, что СУБД MS SQL всегда будет существенно лучше СУБД PostgreSQL рано, т к недостаточно фактов. Для подтверждения или опровержения данного высказывания, необходимо сделать ряд других тестов. Например, для .NET нужно написать как атомарные действия, так и комплексные тесты, запустить их многократно и в разных условиях, зафиксировать время выполнения и взять среднее значение. После этого сравнить эти значения. Это и будет объективный анализ.
На данный момент пока мы не готовы провести такой анализ, но в будущем вполне возможно его проведем. Тогда мы и напишем более подробно при каких операциях PostgreSQL лучше MS SQL и на сколько в процентах, а где MS SQL лучше PostgreSQL и на сколько в процентах.
Также в нашем тесте не были применены методы оптимизации для MS SQL, которые описаны здесь. Возможно в этой статье просто забыли выключить индексирование дисков Windows.
При сравнении двух СУБД надо помнить об еще одном весомом моменте: СУБД PostgreSQL бесплатная и открытая, тогда как СУБД MS SQL платная и имеет закрытый исходный код.
Благодарности
- проводили настройку 1С и запускали тесты Гилева, а также внесли значительный вклад в создании данной публикации:
- Роман Буц — тимлид команды 1С
- Александр Грязнов — 1С программист
- коллеги компании Fortis, которые внесли существенный вклад в настройке оптимизации CentOS, PostgreSQL и т д, но пожелали остаться инкогнито
Также отдельное спасибо uaggster и BP1988 за консультацию в некоторых моментах по MS SQL и Windows.
Послесловие
Также любопытный анализ делался в этой статье.
А какие результаты были у вас и как вы проводили тестирование?
