Использование сверточных сетей для поиска, выделения и классификации
Недавно ZlodeiBaal опубликовал статью «Нейрореволюция в головах и сёлах», в которой привел обзор возможностей современных нейронных сетей. Самым интересным, на мой взгляд, является подход с использованием сверточных сетей для сегментации изображений, про этот подход и пойдет речь в статье.
Уже давно появилось желание изучить сверточные сети и узнать что-то новое, к тому же под рукой есть несколько последних Tesla K40 с 12Гб памяти, Tesla c2050, обычные видеокарты, Jetson TK1 и ноутбук с мобильной GT525M, интереснее всего конечно попробовать на TK1, так как его можно использовать практически везде, хоть на столб фонарный повесить. Самое первое с чего начал, это распознавание цифр, тут конечно удивить нечем, цифры уже давно неплохо распознаются сетями, но при этом постоянно возникает потребность в новых приложениях, которые должны что-то распознавать: номера домов, номера автомобилей, номера вагонов и т.д. Все бы хорошо, но задача распознавания цифр является лишь частью более общих задач.
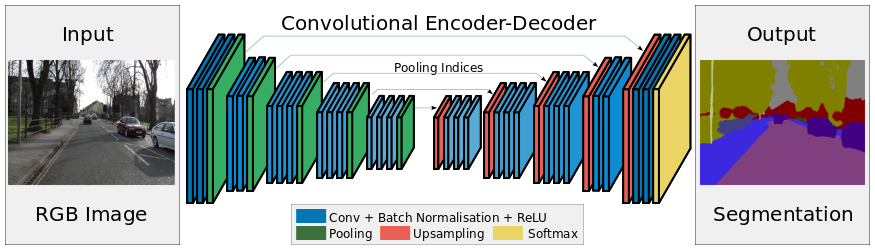
Свёрточные сети бывают разные. Какие-то умеют только распознавать объекты на изображении. Какие-то умеют выделить прямоугольник с объектом (RCNN, например). А какие-то могут профильтровать изображение и превратить его в некоторую логическую картинку. Мне больше всего понравились последние: они самые быстрые и красивее всего работают. Для тестирования была выбрана одна из самых последних сетей на этом фронте — SegNet, подробнее можно прочитать в статье. Основная идея этого метода заключается в том, что вместо lable подается не число, а изображение, добавляется новый слой «Upsample» для увеличения размерности слоя.
layer {
name: "data"
type: "DenseImageData"
top: "data"
top: "label"
dense_image_data_param {
source: "/path/train.txt" // файл обучения: image1.png label1.png
batch_size: 4
shuffle: true
}
}
В конце развернутое изображение и маска из lable подается в слой loss, где каждому классу назначается его вес в функции потерь.
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "conv_1D"
bottom: "label"
top: "loss"
softmax_param {engine: CAFFE}
loss_param: {
weight_by_label_freqs: true
class_weighting: 1
class_weighting: 80
}
}
Правильно распознать цифры это лишь часть задачи распознавания номеров и далеко не самая сложная, надо для начала этот номер найти, затем найти где примерно располагаются цифры, а затем уже их распознавать. Довольно часто на первых этапа появляются большие ошибки, и в итоге получить высокую достоверность распознавания номеров довольно сложно. Грязные и затертые номера плохо детектируются и с большими погрешностями, шаблон номера плохо накладывается, в результате возникает много неточностей и сложностей. Номер может быть вообще нестандартным с произвольными интервалами и т.д.
Например, номера вагонов имеют множество вариаций написания. Если правильно выделить границы номера, то можно получить хоть 99.9% на каждой цифре. А если цифры переплетены? Если сегментация будет давать разные цифры в разных частях вагона?

Или, например, задача обнаружения автомобильного номера. Конечно, её можно решить и через Haar и через Hog. Но почему бы не попробовать другой метод и сравнить? Тем более когда есть готовая для обучения и разметки база?
На вход сверточной сети подается изображение с автомобильным номером и маска, на которой единицей залит прямоугольник с номером, а все остальное нулем. После обучения проверяем работу на тестовой выборке, где на каждое входное изображение сеть выдает такого же размера маску, на которой закрашивает те пиксели, где по ее мнению есть номер. Результат на рисунках ниже.





Просмотрев тестовую выборку можно понять, что этот метод работает достаточно хорошо и почти не дает сбоев, все зависит от качества обучения и настроек. Так как у Vasyutka и ZlodeiBaal была размеченная база номеров, то обучились именно на ней и проверили насколько хорошо всё работает. Результат был не хуже каскада Хаара, а во многих ситуациях даже лучше. Можно отметить некоторые минусы:
- не детектирует наклонные номера (их не было в обучающей выборке)
- не детектирует номера, отснятые в упор (их тоже не было в выборке)
- иногда не детектирует белые номера на чистых белых машинах (скорее всего тоже из-за неполноты обучающей выборки, но, что интересно — этот же глюк был и у каскада Хаара)
В целом проявление этих недостатков закономерно, сеть плохо находит то, чего не было в обучающей выборке. Если тщательно подойти к процессу подготовки базы, то и результат будет высокого качества.
Полученное решение можно применить для большого класса задач поиска объектов, не только автомобильных номеров. Хорошо, номер найден, теперь надо найти там цифры и распознать их. Это тоже не простая задача, как кажется на первый взгляд, нужно проверить множество гипотез их расположения, а что если номер не стандартный, не подходит под маску, то дело труба. Если автомобильные номера изготавливаются по госту и имеют определенный формат, то есть номера, которые могут быть написаны как угодно, от руки, с разным интервалом. Например, номера вагонов, пишутся с пробелами, единички занимают гораздо меньше места, чем другие цифры.
К нам на помощь снова спешат сверточные сети. А что если использовать туже самую сеть для поиска и распознавания. Будем искать и распознавать номера вагонов. На вход сети подается изображение, на котором есть номер и маска, где квадратики с цифрами заполняются значениями от 1 до 10, а фон заполняется нулем.

После не очень долгого обучения на Tesla K40 получен результат. Чтобы результат был более читабельным, разные цифры раскрашены в разные цвета. Определить номер по цветам большого труда уже не составит.


На самом деле получился очень хороший результат, даже самые плохие номера, которые до этого плохо распознавались, удалось найти, разделить на цифры и распознать весь номер. Получился универсальный метод, который позволяет не только распознать цифры, но и в целом найти объект на изображении, выделить и классифицировать его, если таких объектов может быть несколько.


А что если попробовать что-то более необычное, интересное и сложное, например выделение и сегментацию на медицинских изображениях. Для теста снимки флюорографии были взяты с открытой базы КТ и X-RAY снимков, по ним было проведено обучение сегментации легких и в результате удалось достаточно точно выделить интересующую область. На вход сети также подавалось исходное изображение и маска с нулем и единицей. Справа результат, который выдает сверточная сеть, а слева выделена та же область на изображении.
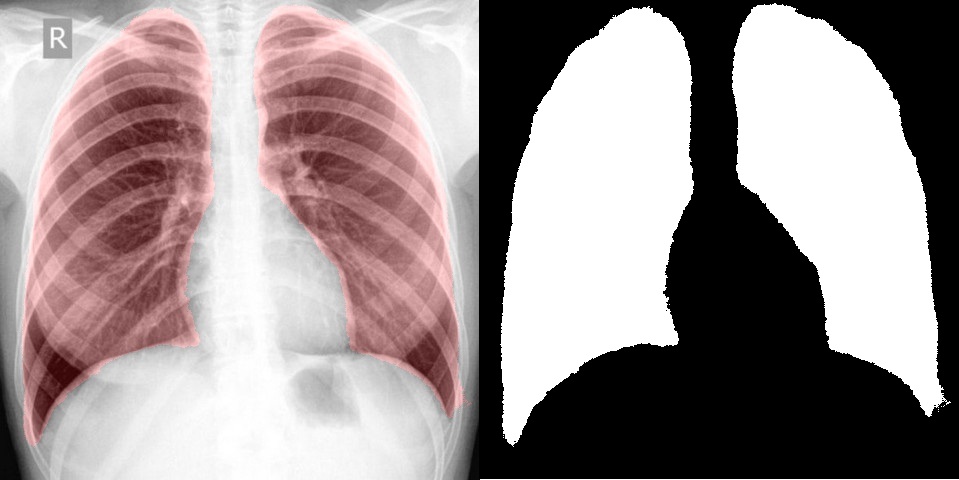
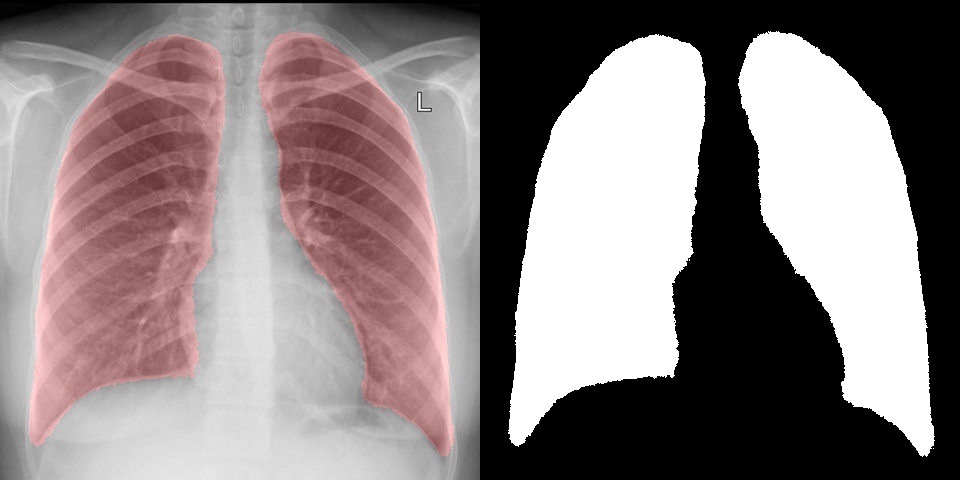
Например, в статье используется модель легких для сегментации. Полученный с помощью сверточных сетей результат нисколько не уступает, а в некоторых случаях даже лучше. При этом, обучить сеть занимает куда быстрее, чем создавать и отлаживать алгоритм.
В целом данный подход показал высокую работоспособность и гибкость в большом спектре задач, с помощью него можно решить всевозможные задачи поиска объектов, сегментации и распознавания, а не только классификации.
- выделение автомобильных номеров;
- распознавание автомобильных номеров;
- распознавание номеров на вагонах, платформах, контейнерах и т.д;
- сегментация и выделение объектов: легкие, котики, пешеходы и т.д.
Работает данный метод достаточно быстро, на видеокарте Tesla обработка одного снимка происходит за 10–15 мс, а на Jetson TK1 за 1.4 секунды. Про то, как запустить Caffe на Jetson TK1 и какой скорости обработки можно на нем достичь в этих задачах, наверно лучше посвятить отдельную статью.
1. SegNet
2. A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation (pdf)
3. Haar
4. Hog
5. Сегментация легких на изображениях (pdf)
