Использование JSONB-полей вместо EAV в PostgreSQL
На одной из конференций PGConf мы обнаружили, что комьюнити с большой опаской относится к использованию JSONB-полей в своих системах. Интернет при этом не столь радикален. Наша же команда в это время вовсю использует JSONB у себя в проекте. Мы решили поделиться нашим вполне успешным кейсом в реальной нагруженной системе с сотнями миллионов строк в таблицах, где эти поля используются.

Проект — CRM-система для взаимодействия с клиентами энергосбытовых компаний. Она используется для множества каналов коммуникации с клиентами, от звонков на горячую линию и переписки в мессенджерах до визитов в офисы и почтовых рассылок. Архитектурно система спроектирована так, что способна сопровождать оказание практически любых видов услуг, но исторически сосредоточена на электроэнергетике.
У многих бизнес-объектов системы есть разновидности со специфичными только для них атрибутами. Приведем в пример клиентов. Они бывают физическими (ФЛ) или юридическими лицами (ЮЛ), а могут быть и более экзотическими, такими как «лид» или «контактное лицо». У каждого подвида разный набор атрибутов. Скажем, у ФЛ — ФИО и паспорт, у ЮЛ — название юрлица и ИНН. При этом часть атрибутов может совпадать, например, адрес и email. Как же их подружить? Рассмотрим, как это сделали мы, и сравним с классическим подходом EAV.
Мы исходим из того, что нам важно сохранить основные объекты в одной таблице, поэтому не рассматриваем случаи, когда мы еще и создаем отдельно таблицы «Клиент ФЛ» и «Клиент ЮЛ». Тогда в классической схеме EAV наш MVP будет выглядеть примерно так:

Пока у нас минимум контроля над данными. Мы можем только проверить, что к клиенту не добавили несвойственный ему атрибут, и соответствие типу данных. Тут есть нюансы:
Тип клиента (ФЛ, ЮЛ) будет находиться в «Сущности».
Создаем таблицу «Атрибут сущности», потому что некоторые атрибуты могут принадлежать к нескольким типам клиента. Это также позволит контролировать принадлежность атрибута к «Сущности» при сохранении значения.
Поле «Значение атрибута» вынуждено быть текстовым (или json, но мы же вроде не хотим иметь дела с json:)). Это само по себе несколько осложняет производительную работу запросов, а ведь основной аргумент против jsonb — проблемы поиска на больших масштабах. Здесь есть и другое решение:
! Можно под каждый тип данных сделать отдельное поле и заполнять в шахматном порядке. Только у самого атрибута надо указывать, к какому типу данных он относится. Но это порождает довольно большие сложности с построением запросов.
Теперь рассмотрим нашу схему с использованием jsonb.
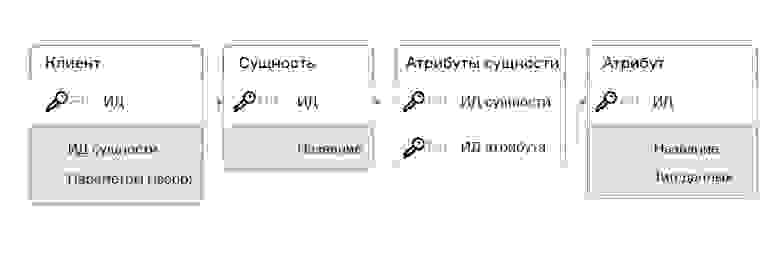
Отличия пока минимальные.
Значение поля «Параметры» — это всегда JSON-объект, который строится по принципу: {«Название атрибута»: <Значение атрибута>, …}. Например, {» Фамилия»: «Иванов», «Возраст»: 28}. Понятно, что для именования атрибутов мы используем латинские символы, для этого у нас в «Атрибуте» есть отдельная колонка, но тут для простоты мы будем использовать просто колонку с «Названием».
Давайте теперь сразу накидаем некоторые пункты по развитию этой простой структуры, которые не касаются хранения в JSONB и поэтому будут одинаково выглядеть для обоих решений, чтобы потом уже сосредоточиться на различиях. Итак:
1. Сделаем поля с ограниченным выбором из списка. Любой комбобокс, например, пол.
2. Сделаем больше ограничений/проверок содержимого поля. В качестве примера возьмем поле email. Проверим, что в нем хранится именно электронная почта, а не произвольный текст.
3. Сделаем древовидную систему сущностей, чтобы наследовать общие атрибуты. Так, сущность «Клиент» делится на подвиды «ФЛ» и «ЮЛ». У «Клиента» при этом могут быть свои атрибуты, например, «Номер договора», который в итоге будет использован и для ФЛ, и для ЮЛ.
4. Добавим возможность настраивать обязательность атрибутов и дефолтное значение.
Решение.
1. Для комбобоксов создаем таблицы для хранения справочных данных типа «ключ-значение» и добавляем в таблицу «Атрибут» ссылку на этот справочник.
Если надо ссылаться на внешние справочники, это делается примерно так же, просто настройка становится более громоздкой. Мы не будем тут усложнять.
«Тип данных» можно поменять на справочник, а можно и оставить целочисленным, если у справочника целочисленный ИД.
В конечном счете, хранить на «Клиенте» мы будем именно ИД значения, и для интерфейса находить по нему само значение и показывать.
2. Для дополнительных ограничений делаем отдельную таблицу «Домен». На нее опять же ссылаемся из «Атрибута».
В «Домене» храним всякие настройки: размерность, маску ввода, регулярное выражение для проверки и т.п. Можно даже «Тип данных» туда перенести при желании, но это может быть контрпродуктивно.
Тут сразу сделаем следующий шаг и поместим в эту таблицу указание на функцию кастомизированной проверки/преобразования. Так мы расширим наши возможности до безграничных. Если нам вдруг понадобится какая-то проверка, не укладывающаяся ни в какие стандартные рамки, мы просто напишем типовую функцию и сошлемся на нее. Более того, мы еще и скорректировать можем что-то, например, зашифровать содержимое поля.
3. Добавляем в «Сущность» поле «ИД родителя». Делаем представление, которое будет по ИД сущности возвращать все атрибуты, включая родительские. Делаем проверку, что по всей цепочке атрибуты не повторяются.
4. В таблицу «Атрибут сущности» добавляем поля «Признак обязательности» и «Значение по умолчанию».
Выглядеть это будет так для обоих решений:
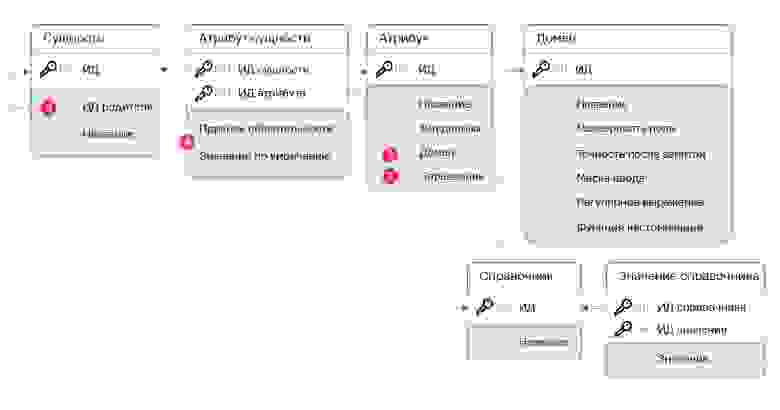
А вот со следующими пунктами у EAV-модели начинаются сложности. Рассмотрим фичи, влияющие на выбранный способ хранения.
1. Привязка сущностей к другим объектам системы.
2. Поля массивов. Чекбоксы с выбором нескольких значений, например, категории рассылок, на которые клиент дал согласие. Или просто массивы, не обязательно списочные.
3. Составные поля. Например, адрес.
Решение!
1. В целом по этому пункту уже все готово и различий с EAV тоже особых нет:
Просто добавляем поле «Параметры» другому объекту системы и пользуемся. Однако, если мы хотим не допустить путаницы и не дать записывать в объекты сущности, не относящиеся к ним, добавим в таблицу «Сущность» указание на таблицу, для которой она создана.
В случае EAV мы добавляем не поле, а целую таблицу со значениями и всеми ключами, это в целом плюс-минус то же самое. Разница только в том, что при структурных доработках поле JSONB мы, вероятно, даже трогать не будем, а таблицы со значениями придется каскадно править по всем задействованным объектам, кратно увеличивая стоимость их обслуживания. Почему бы не создать одну таблицу под все объекты? Потому что она уже хранит бизнес-данные из разных модулей, которые могут быть разнесены по базам и вообще неправильно хранить бизнес-данные вне области влияния модуля, ответственного за бизнес-объект.
2. Чтобы сделать массив в таблицу «Атрибут сущности», добавим поле «Признак массива». Именно сюда, потому что одни и те же атрибуты могут быть массивами в одних сущностях и не быть ими в других.
Теперь такое поле в «Параметрах» будет выглядеть так: {«Атрибут 1»: [<Значение 1>, …, <Значение N>], …}
Для EAV нам, помимо признака, нужно будет расширять первичный ключ у значения. Добавим поле «Порядковый номер». Если оно заполнено, это массив. Тут у EAV даже есть небольшое преимущество, потому что любой массив будет с идентификатором значений, а, значит, можно править их по отдельности. JSON этого не позволяет, там редактирование будет состоять из удаления старого значения и вставки нового, но все можно обмазать синтаксическим сахаром.
3. Чтобы сделать вложенные объекты, заведем новый «Тип данных» — «Сущность». И для этого типа данных мы в «Атрибуте» прописываем ИД сущности, на которую он будет ссылаться. Теперь, если продолжать пример с «Адресом», у нас в «Сущностях» помимо «ФЛ» и «ЮЛ«появится еще и «Адрес», который содержит собственный набор атрибутов внутри.
Клиент с таким атрибутом в JSON будет заполнен так: {«Адрес»: {«Полный адрес»: «г. Москва, ул. Ленина д. 1», «Населенный пункт»: «Москва», …}, …}
Для EAV мы вновь вынуждены расширять первичный ключ таблицы значений. Добавим поле «ИД родителя», если оно заполнено, это составной атрибут.
Как вы уже догадались, можно объединить эти свойства и хранить по клиенту вложенный массив из составных объектов. Более того, у нас уже есть функционал кастомных проверок в «Домене», и он вполне пригодится, чтобы обрабатывать и такие атрибуты, как массив составных объектов. Так как это просто атрибут, мы сначала отправим на проверку его содержимое целиком, а затем еще и рекурсивно пробежимся по вложенным атрибутам по отдельности.
Помимо того, что EAV-модель уже показывает большую сложность по сравнению с хранением в JSONB, мы еще не обращали внимание на событие сохранения данных в БД.
В случае с JSON-ом нет ничего проще для интерфейса, чем собрать всю заполненную анкету с данными в один большой JSON и так его и пульнуть в сервис сохранения. Нам остается только его проверить на соответствие метамодели данных. При этом сколько там будет уровней вложенности атрибутов друг в друга, значения не имеет. Вся проверка будет рекурсивной.
Для EAV, если с фронта прилетит JSON, его нужно будет распарсить, точно так же проверить и сохранить атомарно. Если же анкету будут присылать частями или отдельными элементами, сложно представить, как заставить это работать. У EAV тут только одно преимущество — «Порядковый номер». Он позволяет работать точечно с элементами массива.
Посмотрим, как будет выглядеть итоговая схема обоих решений:
JSON

EAV

По итогу мы имеем метамодель данных, которая способна организовать совершенно произвольный набор данных на любой вкус, практически без дальнейшего участия разработки в построении бизнес-модели. Она настолько хорошо работает, что в системе даже есть интерфейс для управления ею, чтобы заказчик мог самостоятельно заводить какие ему угодно атрибуты и сущности.
Что еще мы не сделали, но могли бы для полноты функциональности:
Можно перенести связь таблицы значений с «Атрибута» на «Атрибут сущности», чтобы появилась возможность один атрибут привязывать под разными именами к одной сущности. Например, адрес прописки и проживания. И тут мы бы снова увидели, что для EAV сделать это на порядок сложнее, так как пришлось бы переделать все таблицы значений. А JSONB-поле даже трогать бы не пришлось, просто существующим связям прописать те же имена, что и в атрибуте.
Можно сделать возможность идентификации составного атрибута. Если у нас составной массив, это по сути вложенная таблица. Хотелось бы понимать, какой набор атрибутов в ней уникален. Для этого в «Атрибуте сущности» необходимо добавить «Признак ключа». Тут наоборот, у EAV преимущество, потому что ее поля «ИД атрибута» + «ИД родителя» + «Порядковый номер» уже создают в рамках клиента уникальную строку. Поэтому данному решению уже вообще ничего не надо для идентификации нужного элемента массива.
В завершение — немного о производительности. Мы никогда не делали вариант с EAV, но реализация с JSONB работает у нас на нагруженной системе. JSON-поля хранят бизнес-данные всех основных таблиц, таких как «Клиенты», «Услуги», «Заказы».
В системе более 13 миллионов клиентов
И более 300 миллионов оказанных услуг
Поиск произвольного набора клиентов по строчным данным, например, по фамилии или по адресу проживания укладывается в 40 секунд. При этом он успевает поискать и у нас в базе, и по API в интегрированных системах.
Все это работает благодаря gin индексу на json-полях.
Однако для контекстного поиска по адресам, которые не всегда точно и в правильной последовательности передаются с фронта, разработан особый gin-индекс. Он формируется непосредственно по адресным атрибутам из JSON-а, которые преобразовываются в tsvector с весами.
Для построения описанной системы мы, конечно, приложили массу усилий. Но если в подобной гибкости системы нет необходимости, или вы не готовы много в это инвестировать, возможно, вам и не нужен EAV? Некоторые разработчики начинают строить EAV-модели как, наоборот, простое решение, при котором не нужно долго думать над дизайном данных. Однако это путь, который точно не ведет к упрощению. Если же вы решили делать гибкий дизайн, возможно, наша статья показала, что JSONB-поля работают для него не хуже, а поддерживаются существенно легче классического EAV.
