Ищем боттлнеки за 30 минут с помощью Jaeger трейсов
Всем привет! Меня зовут Артем, я бэкенд-разработчик в команде клиентского бэкенда. Одна из важных частей моей работы — это снижение латенси нашего бэкенда. История, о которой я расскажу в статье, как раз и началась с одной из таких задач. Звучала она следующим образом:
В одном из эндпоинтов чекаута 99 перцентиль латенси пробивает SLO. Нужно это исправить.
Соответственно, возникает вопрос: как максимально быстро и точно найти причину тормозов очень низкочастотного запроса на 99 перцентиле и что делать, чтобы ее устранить? Ответом на него стала библиотека для полуавтоматического поиска узких мест в распределененных системах. Ссылка на гитхаб будет в конце статьи.
На эту тему я уже делал доклад на митапе Joom. Если больше любите смотреть видео, добро пожаловать.
Какие есть стандартные инструменты для поиска узких мест по производительности?
В открытом доступе уже есть несколько таких инструментов.
- Профилирование, например, с помощью pprof.
- Построение дашбордов с перфоманс-метриками. С этим нам могут помочь, например, Prometheus + Grafana.
- Изучение трейсов исполнения интересующих нас запросов, полученных, например, с помощью Jaeger.
Давайте детальнее рассмотрим эти три пути и разберемся с их достоинствами и недостатками.
Профилирование не поможет в распределенной системе
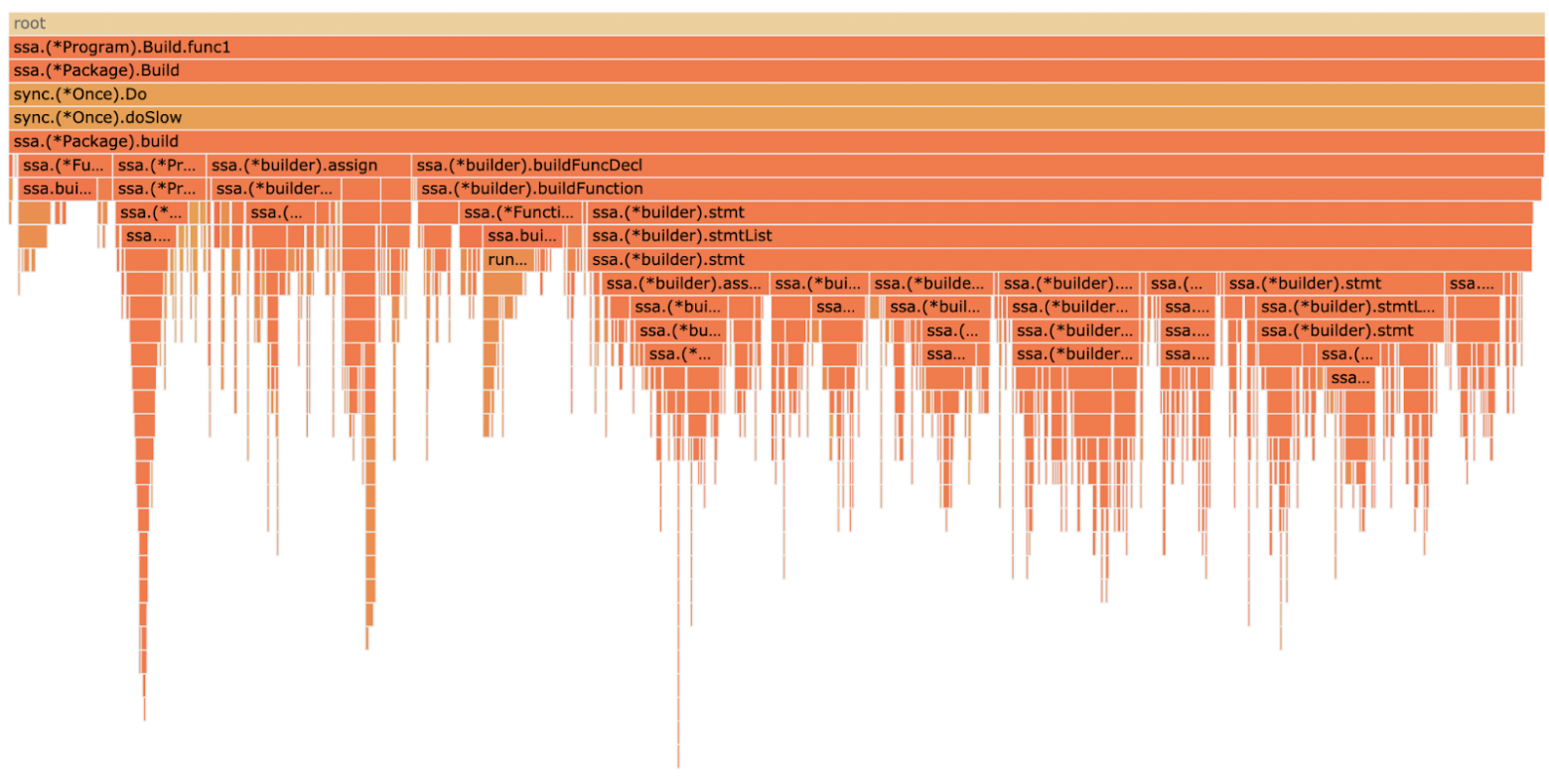
Профилирование помогает найти узкие места по времени исполнения, ЦПУ и памяти. В случае экосистемы Go профилировщик вообще идет из коробки, так что если у нас в коде есть доминатор, который заодно с походами в базу майнит крипту для соседней команды, то найти его этим способом не составит труда.
Но профилировщик не поможет, если речь идет о распределенной системе с несколькими десятками (а то и сотнями) сервисов, написанных к тому же на разных языках. В таких системах далеко не всегда можно однозначно идентифицировать проблемный сервис, который необходимо профилировать. Поэтому хочется иметь инструмент, который анализировал бы производительность всей системы в целом и указывал на проблемы во всех сервисах сразу.
Такой инструмент оказывается суперполезным, если ускорять бэкенд нужно вам, но затык лежит где-то в области ответственности соседней команды. В этом сценарии работа идет гораздо бодрее, если задача сформулирована как «Петь, там ваш сервис тормозит на запросе X к базе Y; попробуй его ускорить, пожалуйста», а не «Петь, там, кажется, ваш сервис где-то тормозит; сделайте его побыстрее».
В нашем случае при ускорении одного из запросов выяснилось, что соседний сервис тупит из-за того, что данные лежали в перегруженной базе. Миграция в соседнюю базу должна была помочь. И, поскольку мы абсолютно точно знали, что надо делать, ресурсы на миграцию в соседней команде почти сразу нашлись. Как следствие, задача по оптимизации была выполнена довольно быстро.
Еще одна проблема профилировщиков — это то, что мы получаем лишь информацию о том, как сервис живет в целом. То есть если у нас есть какой-то критически важный, но низкочастотный запрос, который не вносит серьезного вклада в общее потребление ресурсов, с помощью профилировщика нам не удастся понять, как его можно ускорить.
Например, в нашем бэкенде одни из самых частотных запросов — это запросы карточки товара и главной страницы. Узкие места в этих запросах на профилях прямо огнем горят! С другой стороны, корзина, оформление заказа, профиль пользователя запрашиваются в тысячи раз реже. Соответственно, даже если на этих запросах есть очень серьезные проблемы с производительностью, на профилях они будут почти незаметны. Особенно если эти проблемы проявляются лишь на старших перцентилях (например, p95, p99). В этом случае добиться от профилировщика ответа на вопрос «Что тормозит в определенном запросе на определенном перцентиле?» вообще не представляется возможным.
Резюме: профилирование может помочь найти глобальные боттлнеки в определенном сервисе, но этот инструмент не приспособлен к выявлению проблем в специфических пользовательских сценариях в распределенных системах.
Дашборды с перфоманс-метриками — на всех не напасешься
Если у вас уже есть дашборд, на котором показывается латенси проблемного места — это прекрасно! Но дело в том, что для построения такого дашборда проблемное место надо сначала найти. А ещё построение каждого дашборда требует определенных усилий, и построить их заранее на все случаи жизни вообще нереально.
Возвращаясь к примеру из предыдущего раздела — вряд ли кому-то придет в голову строить дашборд времени ответа базы на очень специальный запрос к одной из сотен коллекций в десятке разных БД. Но даже если такой дашборд внезапно появился, как догадаться, что нужно смотреть именно на него?
Поэтому вместо кучи разрозненных дашбордов хотелось бы иметь инструмент, который бы в пассивном режиме собирал для нас плюс-минус всю необходимую для анализа производительности информацию, а потом позволял бы делать к собранным данным запросы произвольной сложности и сам подсвечивал вероятные проблемы.
Ручной просмотр Jaeger трейсов — отлично, но чего-то не хватает
Jaeger трейсы — это древовидные структуры, в каждом узле которых находится время выполнения соответствующего метода в процессе обработки запроса (на Хабре уже есть хорошая статья про Jaeger).
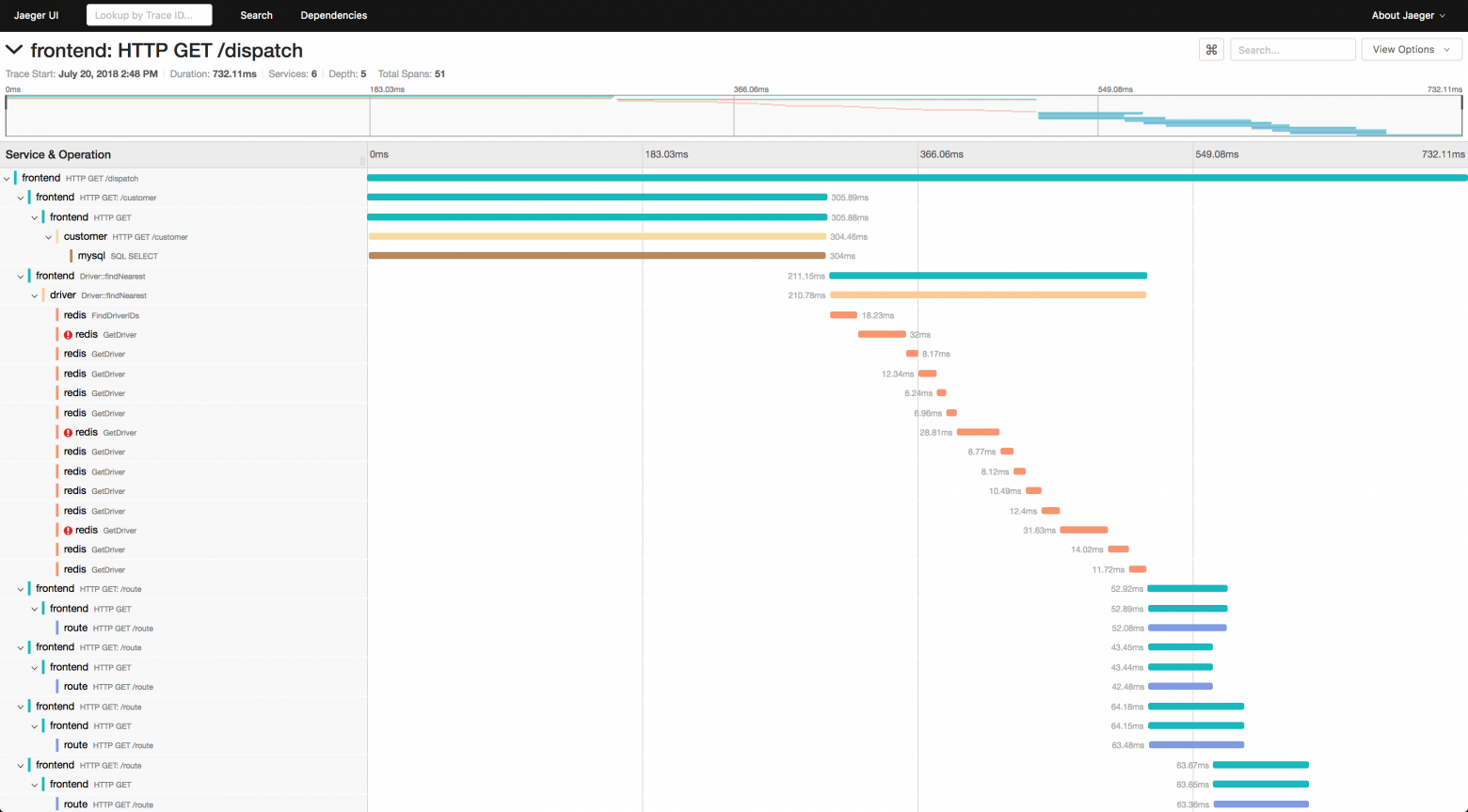
Сбор таких трейсов позволяет устранить все перечисленные выше недостатки профилировщиков и дашбордов.
- У трейса есть такие параметры, как эндпоинт и время исполнения. То есть мы можем смотреть только на те запросы, которые нам действительно интересны.
- Трейс может содержать информацию о всех сервисах, задействованных в обработке запроса. То есть мы можем одним взглядом охватить распределенную систему с произвольным количеством компонент.
- Трейсы собираются пассивно — то есть если мы решили посмотреть, почему у нас тормозит корзина, не нужно начинать обвешивать ее метриками и строить новый дашборд. Достаточно просто запросить у джагера соответствующие трейсы.
Но, к сожалению, и у этого инструмента есть проблемы.
- Трейсы длинные (до нескольких тысяч спанов) — на глаз проблемы могут быть видны плохо.
- На старших перцентилях (p95, p99) разброд и шатание — из единичных трейсов сложно понять, что же тормозит сильнее всего (в одном может затупить база, в другом — кэш, в третьем — поиск и т.д., а на чем в итоге надо сосредоточить усилия — непонятно).
- Jaeger UI не позволяет удобно смотреть на латенси отдельных подсистем. Приходится открывать весь трейс, а внутри него уже искать нужные вызовы.
- Нет способа оценки, насколько предполагаемые оптимизации улучшат работу всей системы в целом.
Возвращаясь к примеру из раздела про профилирование — хотя тормоза в той коллекции и были основной проблемой, долгие запросы встречались далеко не на каждом трейсе. И однозначно решить, что стоит сосредоточить усилия именно на миграции коллекции, а, например, не на оптимизации походов в Redis, было сложно.
Наше решение — Jaeger + Spark
Из всех способов поиска узких мест наиболее многообещающим нам показался анализ Jaeger трейсов. Но чтобы не надо было заниматься просмотром единичных трейсов вручную, мы в Joom решили выгрузить их и проанализировать сторонними средствами.
Когда встал вопрос о том, с помощью чего можно построить какую-нибудь агрегированную статистку поверх трейсов, первым, что пришло в голову, был Spark (спойлер: на нем мы и остановились).
В Joom мы используем Spark для множества различных задач, таких как:
- построение дашбордов по событиям клиентской аналитики,
- процессинг исторических логов,
- построение пайплайнов для наших ML-команд.
Итак, для того, чтобы анализировать трейсы в спарке, надо сначала их в него загрузить. Для этого мы использовали способность jaeger-collector (сервис, отвечающий за пересылку трейсов в долговременные хранилища) использовать Kafka в качестве второго хранилища. Далее периодическая джоба вычитывает трейсы из кафки и складирует их в S3, откуда мы можем вычитать их в наших spark-джобах.
Теперь трейсы в нашем распоряжении, осталось решить, что с ними делать.
Поиск в сети готовых решений для группового анализа трейсов исполнения привел нас только к вот такой статье Microsoft. Но несмотря на свою эффективность, предложенный в статье алгоритм достаточно сложен в реализации, а также нуждается в адаптации под наши нужды.
В связи с этим мы поставили для себя задачу написать инструмент, который по отгруженным трейсам был бы способен ответить на следующие вопросы.
- У меня есть множество запросов определенного энпоинта с определенной длительностью. Какие вызовы в этом срезе занимают наибольшее время?
- Если мне удастся ускорить некоторые вызовы (на процент или на фиксированную величину), то какими станут интересующие меня перцентили латенси соответствующих срезов?
Для решения первого вопроса мы решили пойти по самому простому пути — выбираем нужный срез трейсов и внутри трейса суммируем длительности всех спанов по имени операции. В качестве имени операции может фигурировать произвольная строка. Например, полное имя метода. После этого мы можем отсортировать по убыванию время исполнения всех спанов и понять, какой из них, вероятно, самый тяжелый.
Со вторым вопросом все оказалось несколько сложнее, так как вызовы могут выполняться как последовательно, так и параллельно. Допустим, что поход в сторонний сервис занимает 100 мс. Его ускорение на 95% может в лучшем случае ускорить выполнение всего запроса в целом на 95 мс.

А в худшем — не ускорит вовсе, если поход в этот сервис делался параллельно с еще более тяжелым запросом.

В тривиальном случае мы можем просто посмотреть в кодовую базу и выяснить, как именно делается запрос по отношению ко всем остальным запросам в трейсе. Но если наша кодовая база достаточно развесистая, легко пропустить запуск новой горутины шестью фреймами выше по стеку и потратить время на оптимизацию того, что в итоге в целом ничего не ускорит.
Поэтому при написании нашей библиотеки мы пошли по более надежному пути — с помощью кода на Scala мы к каждому трейсу из среза применяем гипотетическую оптимизацию. Гипотетические оптимизации могут иметь следующий вид:
- операция X ускорена на Y%;
- операция X ускорена на Y мс;
- все операции X после первой ускорены на 100% (такая формулировка полезна в случае кэширования повторных вызовов в рамках одного трейса);
- …
После этого по полученным синтетическим трейсам строится распределение латенси по интересущим перцентилям для каждой из синтетических оптимизаций. По результатам такой симуляции мы имеем довольно надежную оценку того, к чему может нас привести оптимизация работы того или иного компонента системы. Теперь можно приступать собственно к перелопачиванию кода!
Приступим к делу!
Давайте на реальном примере посмотрим, как описанный выше подход помог нам найти проблему в одном из запросов флоу оформления заказа.
Поиск оптимизаций
Первым делом смотрим на детализацию того, чем сервис занимается во время исполнения запроса.

На этом графике по горизонтальной оси отложены операции, а по вертикальной — отношение их суммарного времени исполнения к суммарному времени исполнения всех трейсов в срезе. То есть в среднем на вызов метода checkoutdata.GetBundle уходит 15% от всего времени запроса. Иногда уже этой информации достаточно для того, чтобы появились мысли о том, где искать узкие места. Если же с ходу мыслей не появилось, можно запросить такую же диаграмму для любой из дочерних операций. Например, давайте посмотрим, что происходит внутри вызова checkoutdata.GetBundle.
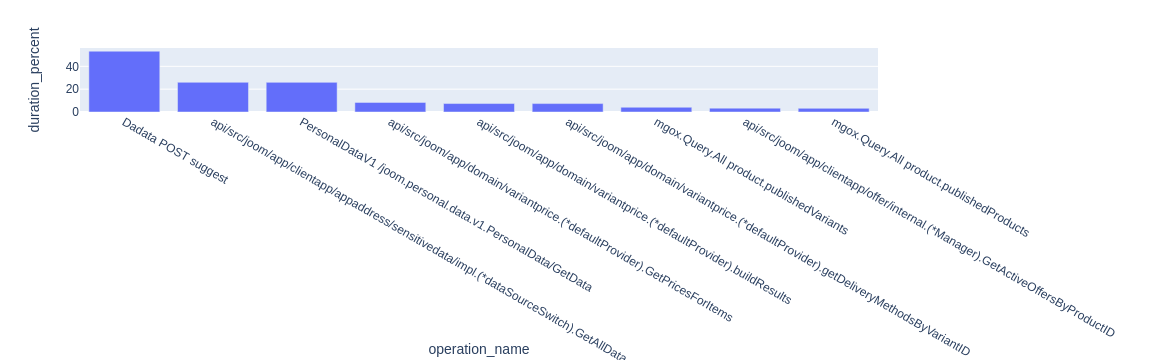
Итак, мы видим, что в запросе GetBundle существенную часть времени занимает поход в сервис саджеста адресов DaData.
Присмотревшись внимательно к коду, мы заметили, что в этом запросе нас слабо интересует весь адрес в целом — достаточно лишь региона. То есть этот запрос можно эффективно кэшировать. Но прежде, чем бросаться в бой и вкручивать кэши, давайте выясним, насколько такое кэширование действительно ускорит запрос.
Симуляция оптимизаций
Допустим, мы сможем закэшировать поход в сервис саджестов адресов, и хитрейт у кэша будет в районе 95%. Нужно оценить, насколько такой кэш в целом ускорит анализируемый запрос. Для простоты будем считать, что мы во всех трейсах ускоряем поход в дадату на 95% (если мы хотим сымитировать поведение кэша более реалистично, надо с вероятностью 95% ускорять поход в дадату на 100%, а с вероятностью 5% — не ускорять совсем). Применяем эту синтетическую оптимизацию ко всем интересующим нас трейсам и получаем следующий график.

По горизонтальной оси здесь отложены перцентили латенси запроса, а по вертикали — на сколько процентов ускорится соответствующий перцентиль при применении гипотетической оптимизации.
Мы видим, что наибольшее влияние такой оптимизации сосредоточено в зоне младших перцентилей (p75, p85). При этом p99 реагирует относительно слабо — только на 5%. Тем не менее ускорение p50 на 10% выглядит крайне многообещающе. Следовательно, стоит попробовать добавить кэширование этого запроса. В реальности после того, как мы такое кэширование добавили, латенси этого запроса на p50 действительно немного упала (примерно на 6–7%).
Другие примеры
Описанный выше пример — далеко не единственный из тех, в которых нам помогла библиотека анализа Jaeger трейсов.
Среди успешных оптимизаций можно отметить следующие.
- Нашли и обезвредили лишний поход в сторонний сервис в модуле расчета цен. Результат — минус 6% латенси на p50 главного экрана.
- Обнаружили лишний поход в систему ранжирования на экране акций. Результат — минус 40% латенси p99 этого экрана.
- Нашли на чекауте поход в перегруженную базу (тот самый, о котором мы говорили при сравнении разных методов поиска боттлнеков). Результат — минус 12% латенси p99 этого запроса.
Резюме
В итоге путем применения всей мощи спарка к выгруженным из джагера трейсам удалось сделать удобный инструмент, позволяющий не только искать потенциальные проблемы в больших распределенных системах, но и давать подробную оценку потенциала оптимизаций до их реализации. Если вы тоже используете в своей работе спарк и джагер, возможно, вам он также будет полезен. Код лежит в открытом репозитории по ссылке. Буду ждать вашей обратной связи и комментариев.
