Интересные алгоритмы кластеризации, часть первая: Affinity propagation
Не то чтобы k-means так уж плох, но его результат почти всегда дёшев и сердит. Есть более совершенные способы кластеризации, но не все знают, какой когда следует применять, и очень немногие понимают, как они работают. Я бы хотел приоткрыть завесу тайны над некоторыми алгоритмами. Начнём с Affinity propagation.
Предполагается, что вы знакомы с классификацией методов кластеризации, а также уже применяли k-means и знаете его плюсы и минусы. Я постараюсь не очень глубоко вдаваться в теорию, а попытаться донести идею алгоритма простым языком.
Affinity propagation
Affinity propagation (AP, он же метод распространения близости) получает на вход матрицу схожести между элементами датасета
 и возвращает набор меток, присвоенных этим элементам. Без лишних слов сразу выложу алгоритм на стол:
и возвращает набор меток, присвоенных этим элементам. Без лишних слов сразу выложу алгоритм на стол: 
Ха, было бы что выкладывать. Всего три строчки, если рассматривать основной цикл; (4) — явно правило присвоения меток. Но не всё так просто. Большинству программистов совсем не очевидно, что же эти три строчки делают с матрицами  ,
,  и
и  . Околоофициальная статья поясняет, что и — матрицы «ответственности» и «доступности» соответственно, и что в цикле происходит «обмен сообщениями» между потенциальными лидерами кластеров и остальными точками. Честно сказать, это весьма поверхностное объяснение, и толком непонятно ни назначение этих матриц ни как и почему изменяются их значения. Попытка разобраться скорее всего приведёт вас куда-нибудь сюда. Хорошая статья, но неподготовленному человеку сложно выдержать целый экран монитора, забитый формулами.
. Околоофициальная статья поясняет, что и — матрицы «ответственности» и «доступности» соответственно, и что в цикле происходит «обмен сообщениями» между потенциальными лидерами кластеров и остальными точками. Честно сказать, это весьма поверхностное объяснение, и толком непонятно ни назначение этих матриц ни как и почему изменяются их значения. Попытка разобраться скорее всего приведёт вас куда-нибудь сюда. Хорошая статья, но неподготовленному человеку сложно выдержать целый экран монитора, забитый формулами.
Так что я начну с другого конца.
Интуитивное объяснение
В некотором пространстве, в некотором государстве живут точки. У точек богатый внутренний мир, но существует некоторое правило
 , по которому они могут сказать, насколько похож на них сосед. Более того, у них уже есть таблица , где записаны все , и она почти никогда не меняется.
, по которому они могут сказать, насколько похож на них сосед. Более того, у них уже есть таблица , где записаны все , и она почти никогда не меняется.Одним жить на свете скучно, поэтому точки хотят собраться в кружки по интересам. Кружки формируются вокруг лидера (exemplar), который представляет интересы всех членов товарищества. Каждая точка хотела бы видеть лидером кого-то, кто максимально на неё похож, но готова мириться с другими кандидатами, если те нравятся многим другим. Следует добавить, что точки довольно-таки скромные: все думают, что лидером должен быть кто-нибудь другой. Можно переформулировать их низкую самооценку так: каждая точка считает, что когда дело доходит до объединения в группы, то она сама на себя не похожа ( ). Убедить точку стать лидером, могут либо коллективные ободрения со стороны похожих на неё товарищей, либо, наоборот, если в обществе не будет совсем никого похожего на неё.
). Убедить точку стать лидером, могут либо коллективные ободрения со стороны похожих на неё товарищей, либо, наоборот, если в обществе не будет совсем никого похожего на неё.
Точки заранее не знают ни что это будут за коллективы, ни общее их количество. Объединение идёт сверху вниз: сначала точки цепляются за президентов групп, затем только размышляют, кто ещё поддерживает того же кандидата. На выбор точки в качестве лидера влияют три параметра: сходство (про него уже сказано), отвественность и доступность. Ответственность (responsibility, таблица c элементами  ) отвечает за то, насколько
) отвечает за то, насколько  хочет видеть
хочет видеть  своим предводителем. Ответственность возлагается каждой точкой на кандидата в лидеры группы. Доступность (availability, таблица , c элементами
своим предводителем. Ответственность возлагается каждой точкой на кандидата в лидеры группы. Доступность (availability, таблица , c элементами  ) — есть ответ от потенциального предводителя , насколько хорошо готова представлять интересы . Ответственность и доступность точки вычисляют в том числе и сами для себя. Только когда велика самоответственность (да, я хочу представлять свои интересы) и самодоступность (да, я могу представлять свои интересы), т.е.
) — есть ответ от потенциального предводителя , насколько хорошо готова представлять интересы . Ответственность и доступность точки вычисляют в том числе и сами для себя. Только когда велика самоответственность (да, я хочу представлять свои интересы) и самодоступность (да, я могу представлять свои интересы), т.е.  . Обычно в самом начале,
. Обычно в самом начале,  и
и  .
.
Возьмём простой пример: точки X, Y, Z, U, V, W, весь внутренний мир которых — любовь к котикам,  . У X аллергия на кошек, для него будем считать
. У X аллергия на кошек, для него будем считать  , Y относится к ним прохладно,
, Y относится к ним прохладно,  , а Z просто не до них,
, а Z просто не до них,  . У U дома четыре кошки (
. У U дома четыре кошки ( ), у V — пять (
), у V — пять ( ), а у W целых сорок (
), а у W целых сорок ( ). Определим непохожесть как абсолютную величину разности . X непохож на Y на один условный балл, а на U — на целых шесть. Тогда сходство, — это просто минус непохожесть. Получается, что точки с нулевым сходством как раз таки одинаковы; чем более отрицательно , тем сильнее отличаются точки. Немного контринтуитивно, ну да ладно. Размер «самонепохожести» в примере оценим в 2 балла (
). Определим непохожесть как абсолютную величину разности . X непохож на Y на один условный балл, а на U — на целых шесть. Тогда сходство, — это просто минус непохожесть. Получается, что точки с нулевым сходством как раз таки одинаковы; чем более отрицательно , тем сильнее отличаются точки. Немного контринтуитивно, ну да ладно. Размер «самонепохожести» в примере оценим в 2 балла ( ).
).
Итак, на первом шаге каждая точка возлагает ответственность на всех (в том числе и на себя) пропорционально сходству между и и обратно пропорционально сходству между и самым похожим на него вектором кроме ((1) c  ). Таким образом
). Таким образом
- Ближайшая (самая похожая) точка задаёт распределение ответственности для всех остальных точек. Расположение точек дальше первых двух пока что влияет только на отведённую им и только им.
- Ответственность, возлагаемая на ближайшую точку также зависит от расположения второй ближайшей.
- Если в радиусе досягаемости есть несколько более-менее похожих на него кандидатов, на тех будет возложена примерно одинаковая ответственность
 выступает своего рода ограничителем — если какая-то точка слишком сильно непохожа на все остальные, ей ничего не остаётся, кроме как надеяться только на себя
выступает своего рода ограничителем — если какая-то точка слишком сильно непохожа на все остальные, ей ничего не остаётся, кроме как надеяться только на себя
Если
 хотела бы, чтобы был её представителем.
хотела бы, чтобы был её представителем.  хочет быть основателем коллектива,
хочет быть основателем коллектива,  — что хочет принадлежать другому коллективу.
— что хочет принадлежать другому коллективу. Возвращаясь к примеру: X возлагает на Y отвественность в размере $inline$-1-(-2)=1$inline$ балл, на Z — $inline$-2-(-1)=-1$inline$ балл, на U — $inline$-6-(-1)=-5$inline$, а на себя $inline$-2-(-1)=-1$inline$. X в общем-то не против, чтобы лидером группы котоненавистников был Z, если Y не захочет быть им, но вряд ли будет общаться с U и V, даже если они соберут большую команду. W настолько непохожа на все остальные точки, что ей ничего не остаётся, как возлагать отвественность в размере $inline$-2-(-35)=33$inline$ балла только на себя.
Затем точки начинают думать, насколько они сами готовы быть лидером (доступны, available, для лидерства). Доступность для самого себя (3) складывается из всей положительной ответственности, «голосов», отданных точке. Для неважно, сколько точек думают, что она будет плохо их представлять. Для неё главное, что хоть кто-то думает, что она будет их представлять хорошо. Доступность для зависит от того, насколько сильно готов представлять сам себя и от количества положительных отзывов о нём (2) (кто-то другой тоже считает, что он будет отличным представителем коллектива). Эта величина ограничивается сверху нулём, чтобы снизить влияние точек, про которых слишком многие думают хорошо, чтобы они не объединили в одну группу ещё больше точек и цикл не вышел из под контроля. Чем меньше  , тем больше голосов нужно собрать , чтобы было равно 0 (т.е. эта точка была не против взять под своё крыло ещё и ).
, тем больше голосов нужно собрать , чтобы было равно 0 (т.е. эта точка была не против взять под своё крыло ещё и ).
Начинается новый этап выборов, но теперь уже  . Вспомним, что
. Вспомним, что  , а
, а  . Это по-разному влияет на
. Это по-разному влияет на
 . Тогда не играет роли, и в (1) все $inline$-max (\dots)$inline$ в правой части будут не меньше, чем были на первом шаге.
. Тогда не играет роли, и в (1) все $inline$-max (\dots)$inline$ в правой части будут не меньше, чем были на первом шаге.  по сути отдаляет точку от
по сути отдаляет точку от  . Самоответственность точки повышается от того, что у самого лучшего кандидата с её точки зрения, плохие отзывы.
. Самоответственность точки повышается от того, что у самого лучшего кандидата с её точки зрения, плохие отзывы. . Тут выступают оба эффекта. Этот случай расщепляется на два:
. Тут выступают оба эффекта. Этот случай расщепляется на два:  — max. То же самое что и в случае 1, но повышается отвественность возлагаемая на точку
— max. То же самое что и в случае 1, но повышается отвественность возлагаемая на точку  — max. Тогда $inline$-max (\dots)$inline$ будет не больше, чем на первом шаге, уменьшается. Если продолжать аналогию, то это как если бы точка, которая и так уже задумывалась, не стать ли её лидером, получила дополнительное одобрение.
— max. Тогда $inline$-max (\dots)$inline$ будет не больше, чем на первом шаге, уменьшается. Если продолжать аналогию, то это как если бы точка, которая и так уже задумывалась, не стать ли её лидером, получила дополнительное одобрение.
Доступность оставляет в соревновании точки которые или готовы сами постоять за себя (W,
 , но это никак не влияет на (1), т.к. даже с учётом поправки W находится очень далеко от остальных точек) или те, за которых готовы постоять другие (Y, в (3) у неё по слагаемому от X и от Z). X и Z, которые не строго лучше всего похожи на кого-то, но при этом на кого-то таки похожи, выбывают из соревнования. Это влияет на распределение отвественности, что влияет на распределение доступности и так далее. В конце концов, алгоритм останавливается — перестают меняться. X, Y и Z объединяются в компанию вокруг Y; дружат U и V c U в качестве лидера; W хорошо и с 40 кошками.
, но это никак не влияет на (1), т.к. даже с учётом поправки W находится очень далеко от остальных точек) или те, за которых готовы постоять другие (Y, в (3) у неё по слагаемому от X и от Z). X и Z, которые не строго лучше всего похожи на кого-то, но при этом на кого-то таки похожи, выбывают из соревнования. Это влияет на распределение отвественности, что влияет на распределение доступности и так далее. В конце концов, алгоритм останавливается — перестают меняться. X, Y и Z объединяются в компанию вокруг Y; дружат U и V c U в качестве лидера; W хорошо и с 40 кошками.Перепишем решающее правило, чтобы получить ещё один взгляд на решающее правило алгоритма. Воспользуемся (1) и (3). Обозначим  — сходство с поправкой на то, что говорит о своих командирских способностях ;
— сходство с поправкой на то, что говорит о своих командирских способностях ;  — непохожесть - с поправкой.
— непохожесть - с поправкой.
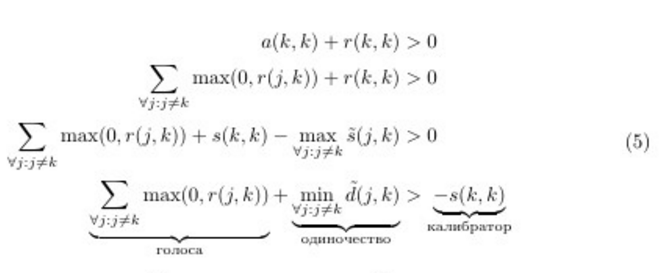
Примерно то, что я сформулировал вначале. Отсюда видно, что чем менее уверены в себе точки, тем больше «голосов» необходимо собрать или тем более непохожим на остальные нужно быть, чтобы стать лидером. Т.е. чем меньше , тем крупнее получаются группы.
Что ж, я надеюсь, вы приобрели некоторое интуитивное представление того, как работает метод. Теперь чуть серьёзнее. Давайте поговорим про нюансы применения алгоритма.
Очень-очень краткий экскурс в теорию
Кластеризацию можно представить в виде задачи дискретной максимизации с ограничениями. Пусть на множестве элементов задана функция сходства
 . Наша задача найти такой вектор меток
. Наша задача найти такой вектор меток  , который максимизирует функцию
, который максимизирует функцию
где
 — член ограничитель, равный $inline$-\infty$inline$, если существует точка , которая выбрала точку своим лидером (
— член ограничитель, равный $inline$-\infty$inline$, если существует точка , которая выбрала точку своим лидером ( ), но сама лидером себя не считает (
), но сама лидером себя не считает ( ). Плохая новость: нахождение идеального
). Плохая новость: нахождение идеального  — это NP-сложная задача, известная как задача о размещении объектов. Тем не менее, для её решения существует несколько приближённых алгоритмов. В интересующих нас методах
— это NP-сложная задача, известная как задача о размещении объектов. Тем не менее, для её решения существует несколько приближённых алгоритмов. В интересующих нас методах  ,
,  и
и  представляются вершинами двудольного графа, после чего между ними происходит обмен информации, позволяющий с вероятностной точки зрения оценить, какая метка лучше подойдёт для каждого элемента. См. вывод здесь. Про распространение сообщений в двудольных графах см. здесь. Вообще распространение близости — это частный случай (скорее, сужение) циклического распространения убеждений (loopy belief propagation, LBP, см. здесь), но вместо суммы вероятностей (подтип Sum-Product) в некоторых местах мы берём только максимальную (подтип Max-Product) из них. Во-первых, LBP-Sum-Product на порядок сложнее, во-вторых, там легче столкнуться с вычислительными проблемами, в-третьих теоретики утверждают, что для задачи кластеризации это имеет больший смысл.
представляются вершинами двудольного графа, после чего между ними происходит обмен информации, позволяющий с вероятностной точки зрения оценить, какая метка лучше подойдёт для каждого элемента. См. вывод здесь. Про распространение сообщений в двудольных графах см. здесь. Вообще распространение близости — это частный случай (скорее, сужение) циклического распространения убеждений (loopy belief propagation, LBP, см. здесь), но вместо суммы вероятностей (подтип Sum-Product) в некоторых местах мы берём только максимальную (подтип Max-Product) из них. Во-первых, LBP-Sum-Product на порядок сложнее, во-вторых, там легче столкнуться с вычислительными проблемами, в-третьих теоретики утверждают, что для задачи кластеризации это имеет больший смысл.Авторы AP при много говорят про «сообщения» от одного элемента графа к другому. Такая аналогия происходит из вывода формул через распространение информации в графе. На мой взгляд она немного путает, ведь в реализациях алгоритма никаких сообщений «точка-точка» нет, зато есть три матрицы , и . Я бы предложил следующую трактовку:
- При вычислении идёт пересылка сообщений от точек данных к потенциальным лидерам — мы просматриваем матрицы и вдоль строк
- При вычислении идёт пересылка сообщений от потенциальных лидеров ко всем остальным точкам — мы просматриваем матрицы и вдоль столбцов
Affinity propagation детерминирован. Он имеет сложность
 , где
, где  — размер набора данных, а
— размер набора данных, а  — количество итераций, и занимает
— количество итераций, и занимает  памяти. Существуют модификации алгоритма для разреженных данных, но всё равно AP сильно грустнеет с увеличением размера датасета. Это довольно серьёзный недостаток. Зато распространение близости не зависит от размерности элементов данных. Пока что не существует распараллеленного варианта AP. Тривиальное же распараллеливание в виде множества запусков алгоритма не подходит в силу детерминированности. В официальном FAQ, написано, что вариантов с добавлением данных в реальном времени тоже нет, но я нашёл вот такую статью.
памяти. Существуют модификации алгоритма для разреженных данных, но всё равно AP сильно грустнеет с увеличением размера датасета. Это довольно серьёзный недостаток. Зато распространение близости не зависит от размерности элементов данных. Пока что не существует распараллеленного варианта AP. Тривиальное же распараллеливание в виде множества запусков алгоритма не подходит в силу детерминированности. В официальном FAQ, написано, что вариантов с добавлением данных в реальном времени тоже нет, но я нашёл вот такую статью. Существует ускоренный вариант AP. Предложенный в статье метод основывается на идее, что необязательно вычислять вообще все обновления матриц доступности и ответственности, ведь все точки в гуще других точек относятся к далёким от них экземплярам примерно одинаково.
Если вам хочется экспериментов (так держать!), я бы предложил поколдовать над формулами (1–5). Части  в них выглядят подозрительно похоже на нейронно-сеточные ReLu. Интересно, что получится если использовать ELu. Кроме того, раз вы теперь понимаете суть происходящего в цикле, вы можете добавить в формулы дополнительные члены, ответственные за необходимое вам поведение. Таким образом можно «подтолкнуть» алгоритм в сторону кластеров определённого размера или формы. Также можно наложить дополнительные ограничения, если известно, что какие-то элементы с большей вероятностью принадлежат одному множеству. Впрочем, это уже спекуляции.
в них выглядят подозрительно похоже на нейронно-сеточные ReLu. Интересно, что получится если использовать ELu. Кроме того, раз вы теперь понимаете суть происходящего в цикле, вы можете добавить в формулы дополнительные члены, ответственные за необходимое вам поведение. Таким образом можно «подтолкнуть» алгоритм в сторону кластеров определённого размера или формы. Также можно наложить дополнительные ограничения, если известно, что какие-то элементы с большей вероятностью принадлежат одному множеству. Впрочем, это уже спекуляции.
Обязательные оптимизации и параметры
Affinity propagation, как многие других алгоритмов, можно прервать досрочно, если
и перестают обновляться. Для этого почти во всех реализациях используется два значения: максимальное количество итераций и период, с которым проверяется величина обновлений.Affinity propagation подвержен вычислительным осцилляциям в случаях, когда есть несколько хороших разбиений на кластеры. Чтобы избежать проблем, во-первых, в самом начале к матрице сходства добавляется немного шума (очень-очень немного, чтобы не повлиять на детерменированность, в sklearn-имплементации порядка  ), а во-вторых, при обновлении и используется не простое присваивание, а присваивание с экпоненциальным сглаживанием. Вторая оптимизация притом в целом хорошо влияет на качество результата, но из-за неё увеличивается количество необходимых итераций . Авторы советуют использовать параметр сглаживания
), а во-вторых, при обновлении и используется не простое присваивание, а присваивание с экпоненциальным сглаживанием. Вторая оптимизация притом в целом хорошо влияет на качество результата, но из-за неё увеличивается количество необходимых итераций . Авторы советуют использовать параметр сглаживания  со значением по умолчанию в
со значением по умолчанию в  . Если алгоритм не сходится или сходится частично, следует увеличить
. Если алгоритм не сходится или сходится частично, следует увеличить  до
до  или до
или до  с соответствующим увеличением количества итераций.
с соответствующим увеличением количества итераций.
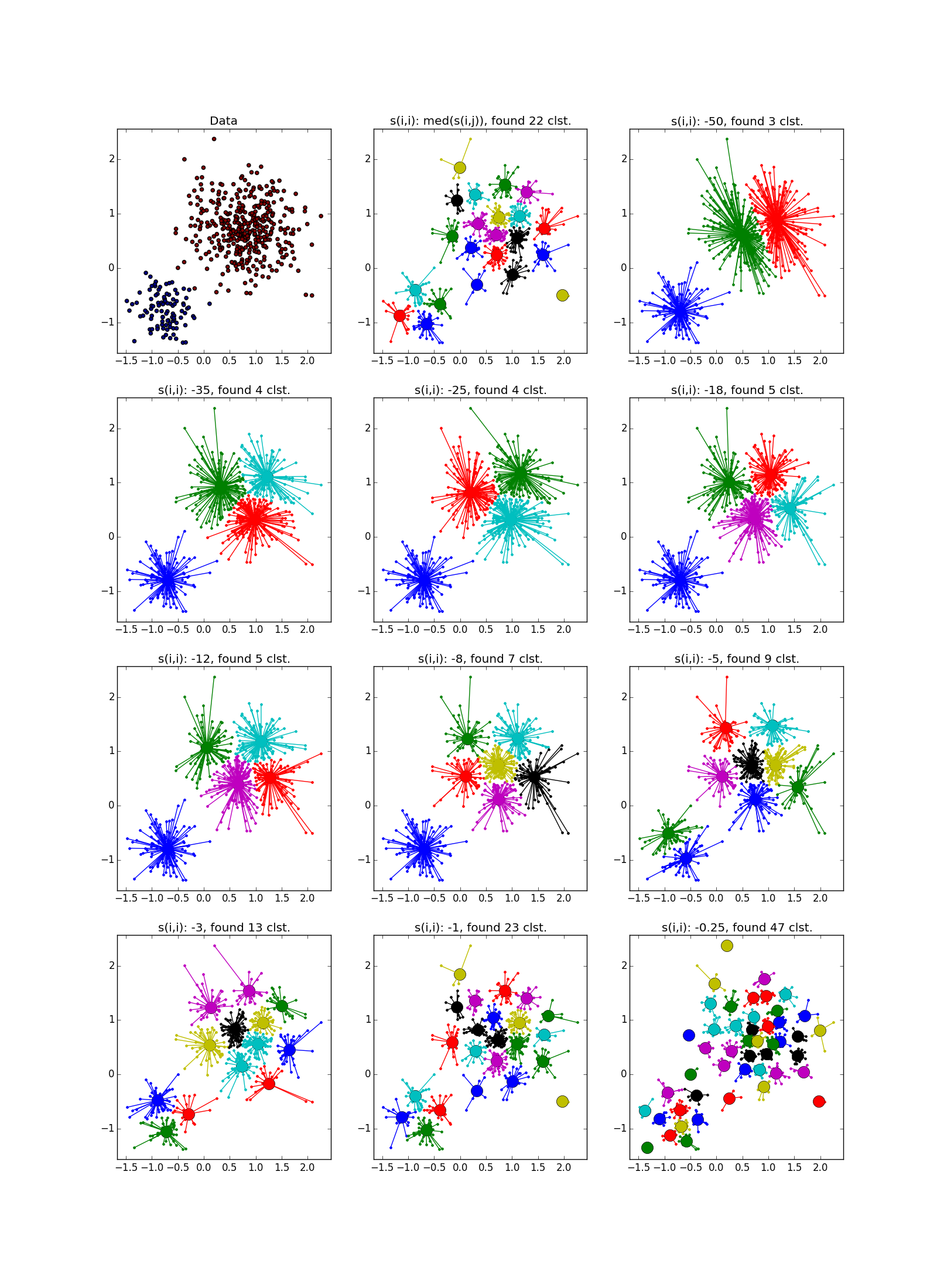
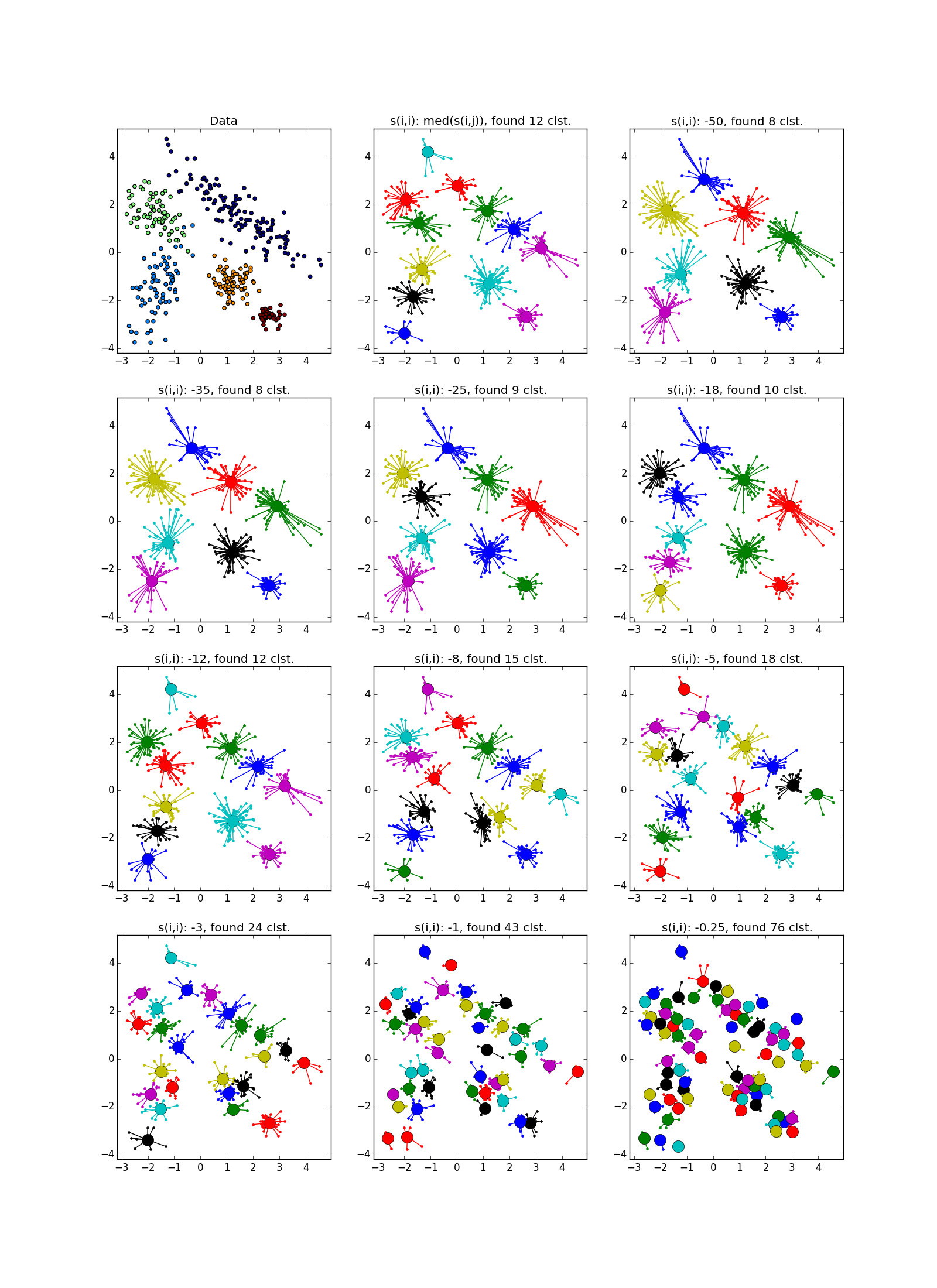
Вот так выглядит отказ — куча мелких кластеров, окружённая кольцом кластеров среднего размера: 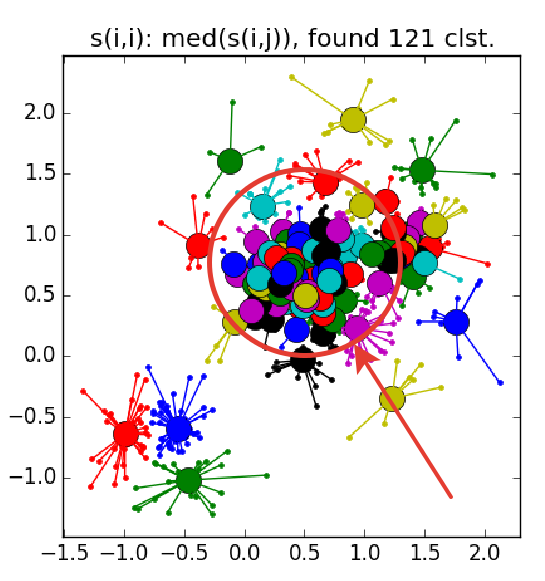
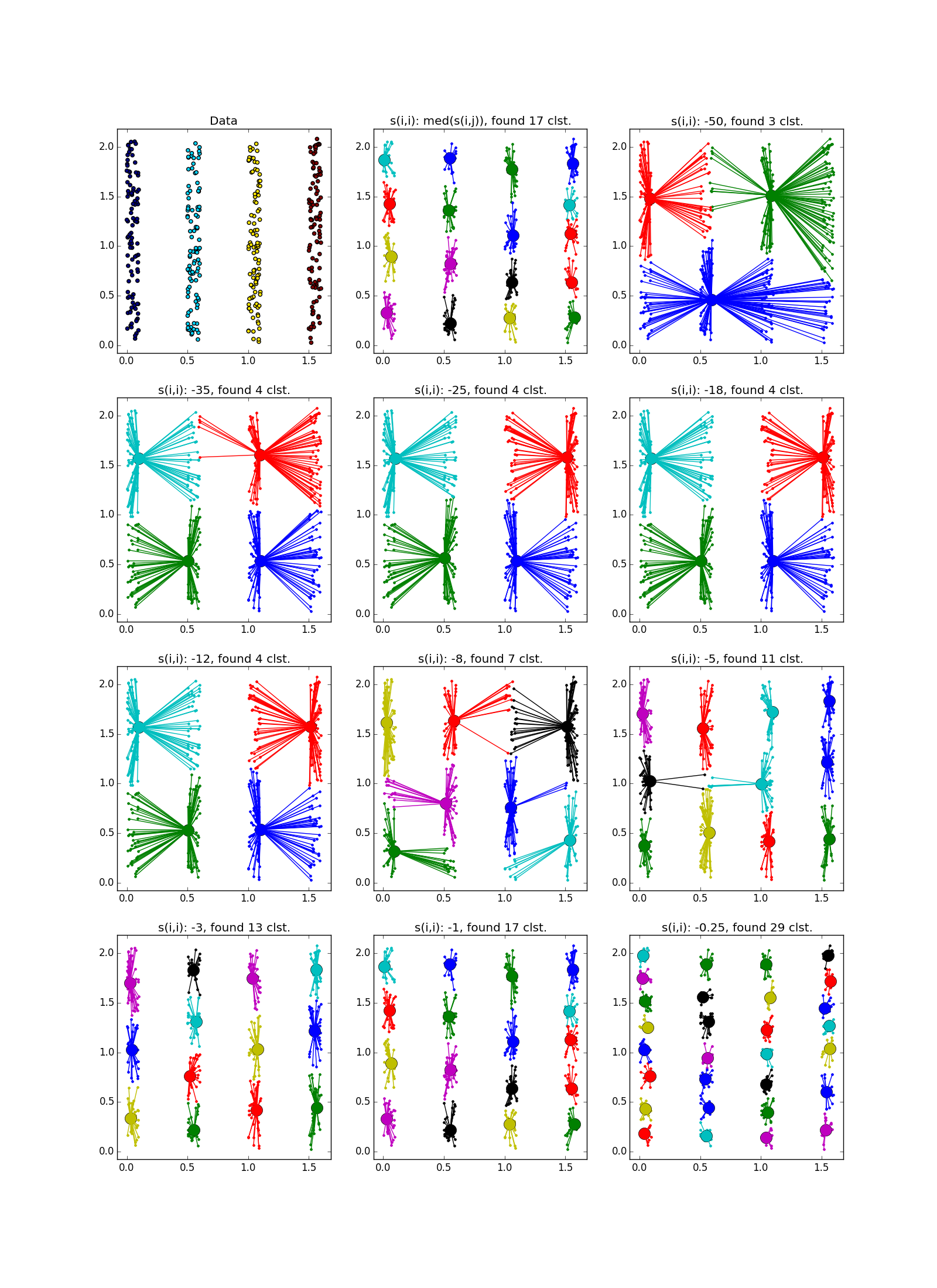
Как уже было сказано, вместо наперёд заданного количества кластеров используется параметр «самоподобия» ; чем меньше , тем крупнее кластеры. Существуют эвристики для автоматической подстройки значения этого параметра: используйте медиану по всем для большего числа кластеров; 25 перцентиль или даже минимум по — для меньшего (всё равно придётся подгонять, ха-ха). При слишком маленьком или слишком большом значении «самоподобия» алгоритм и вовсе не выдаст каких-то полезных результатов.
В качестве само собой напрашивается использовать отрицательное евклидово расстояние между и , но вас никто не ограничивает в выборе. Даже в случае датасета из векторов действительных чисел можно перепробовать много интересного. Вообще же, авторы утверждают, что на функцию сходства не наложено каких-либо особых ограничений; даже не обязательно, чтобы выполнялось правило симметрии или правило треугольника. Но стоит заметить, что чем более хитроумная у вас , тем меньше вероятность, что алгоритм сойдётся к чему-то интересному.
Размеры кластеров, полученных в ходе распространения близости, варьируются в довольно небольших пределах, и если в датасете есть сильно различные по размеру скопления, AP может либо пропустить маленькие, либо посчитать большие за несколько. Обычно вторая ситуация менее неприятна — она исправима. Поэтому часто AP нуждается в постобработке — дополнительной кластеризации лидеров групп. Подходит любой другой метод, тут может помочь дополнительная информация о задаче. Следует помнить, что честным одиноко стоящим точкам выделяется свои кластеры; такие выбросы нужно отфильтровывать перед постобработкой.
Эксперименты
Фух, закончилась стена текста, началась стена картинок. Проверим Affinity propagation на разного вида кластерах.
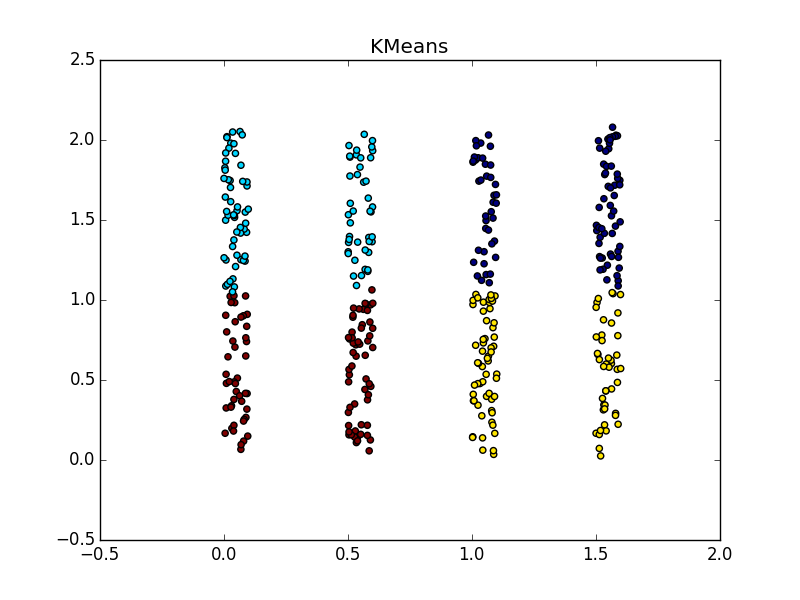
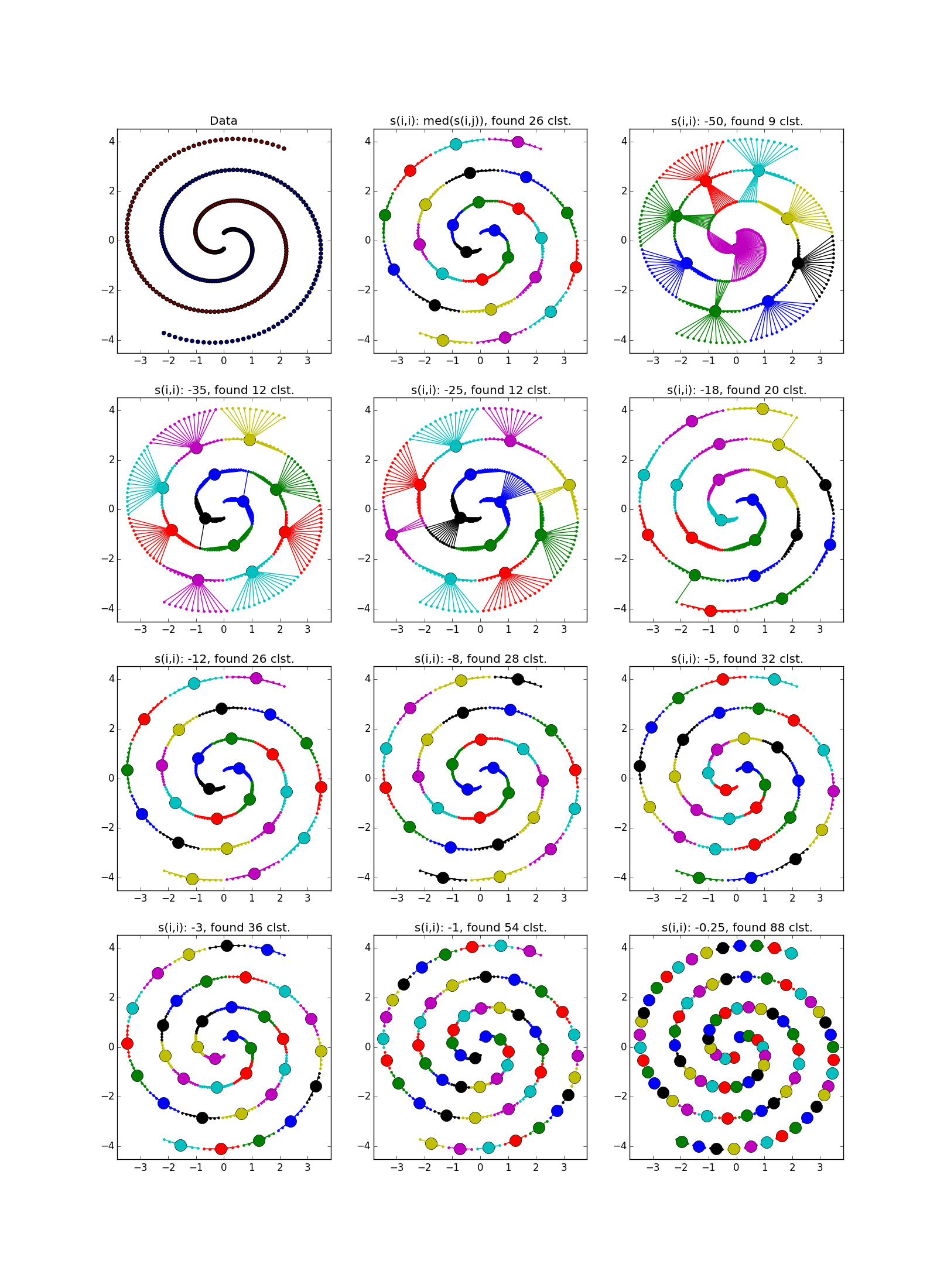
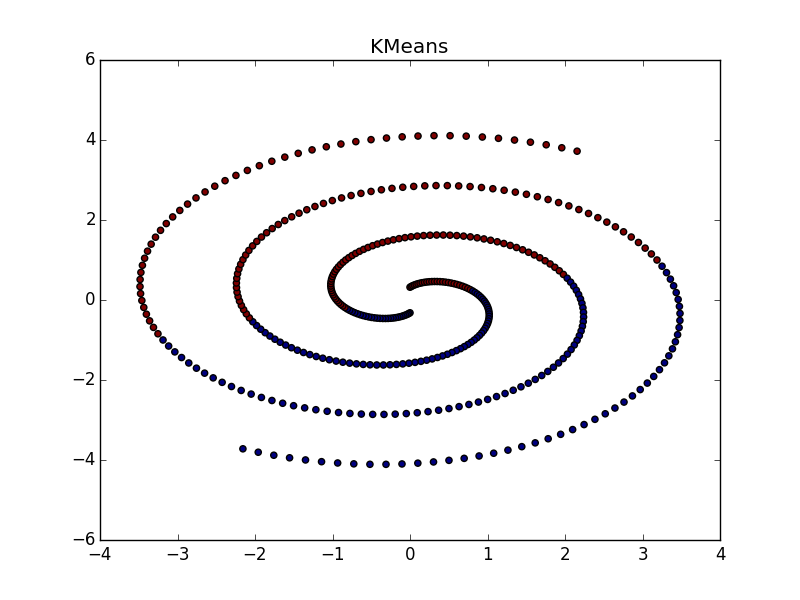
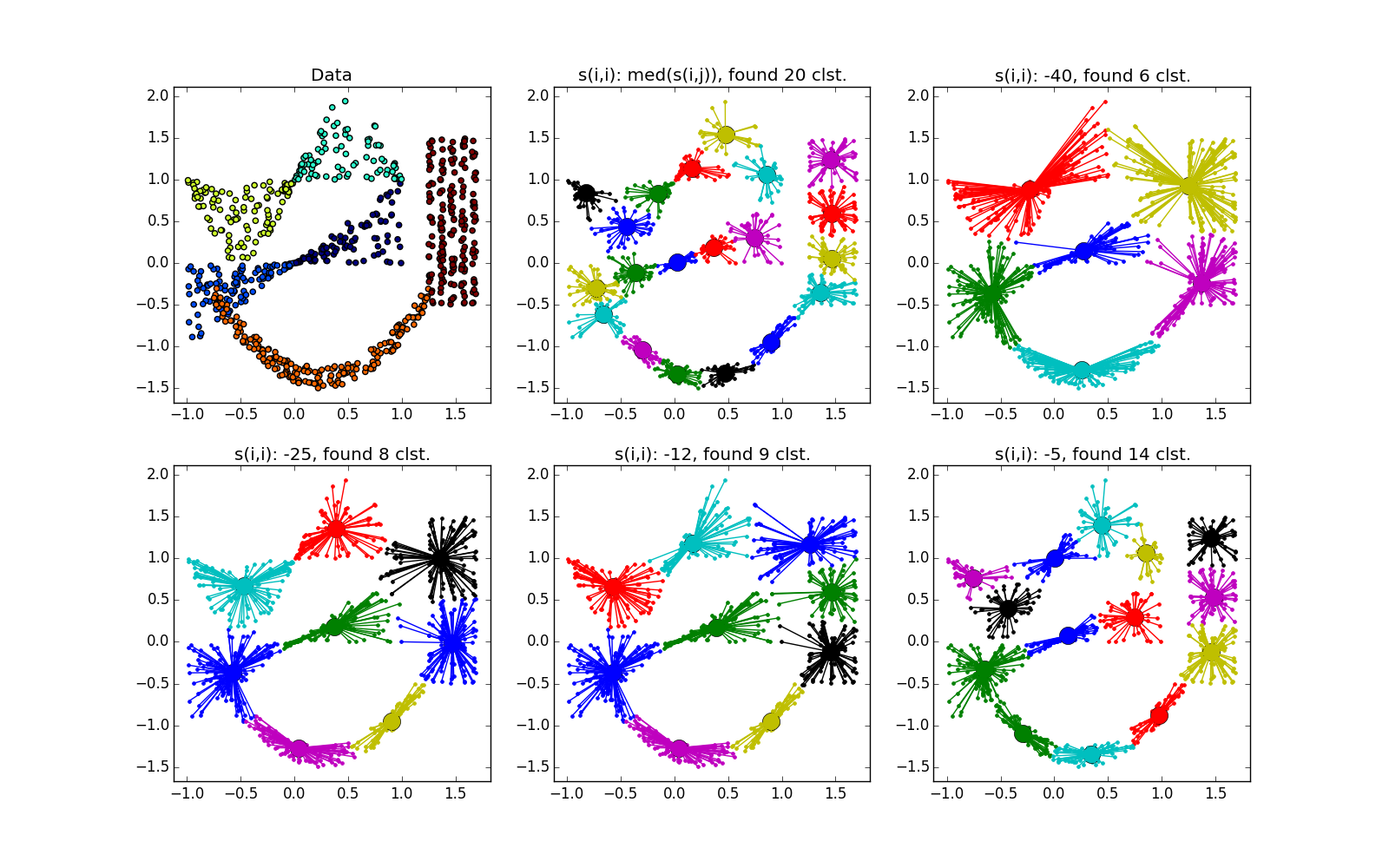
Если складка пересекает другой сгусток, дело обстоит хуже, но даже так AP помогает понять, что в этом месте творится что-то интересное.
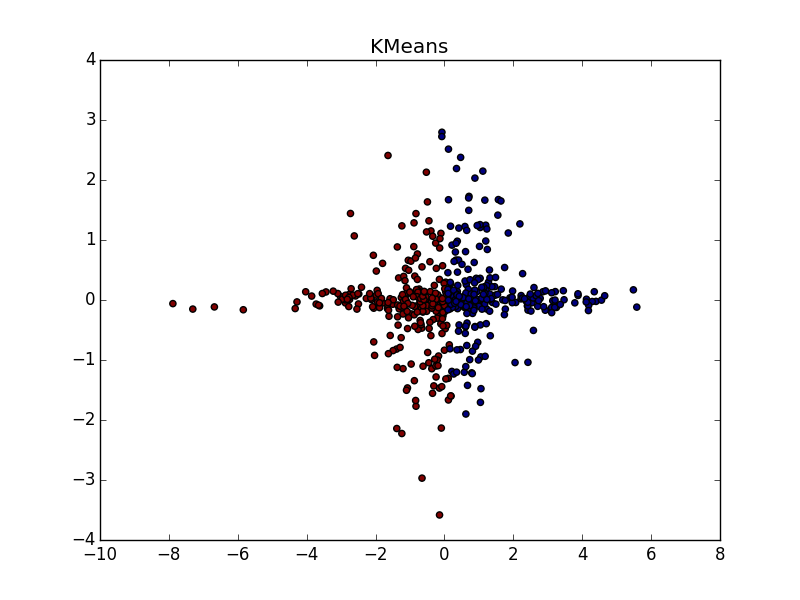
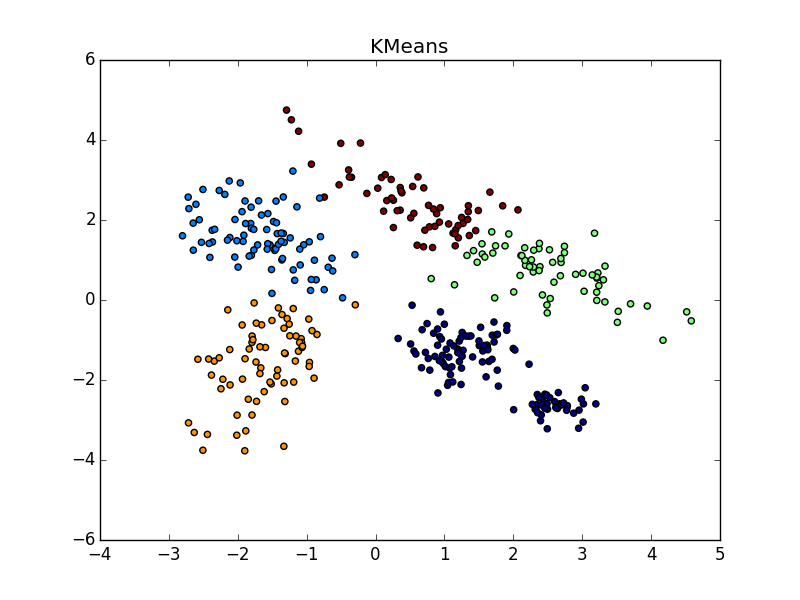
При хорошем подборе параметра и кластеризатора-постобработчика AP выигрывает и в случае кластеров разного размера. Обратите внимание на картинку с  — почти идеальное разбиение, если объединить кластеры сверху-справа.
— почти идеальное разбиение, если объединить кластеры сверху-справа.
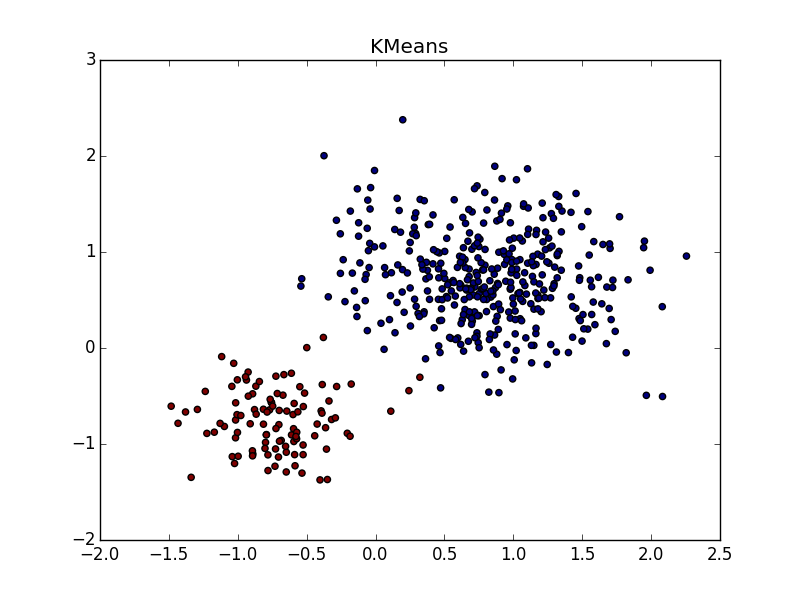
С кластерами одинаковой формы, но разной плотности у AP и k-means плюс-минус паритет. В одном случае нужно хорошо угадать  , а в другом — .
, а в другом — .


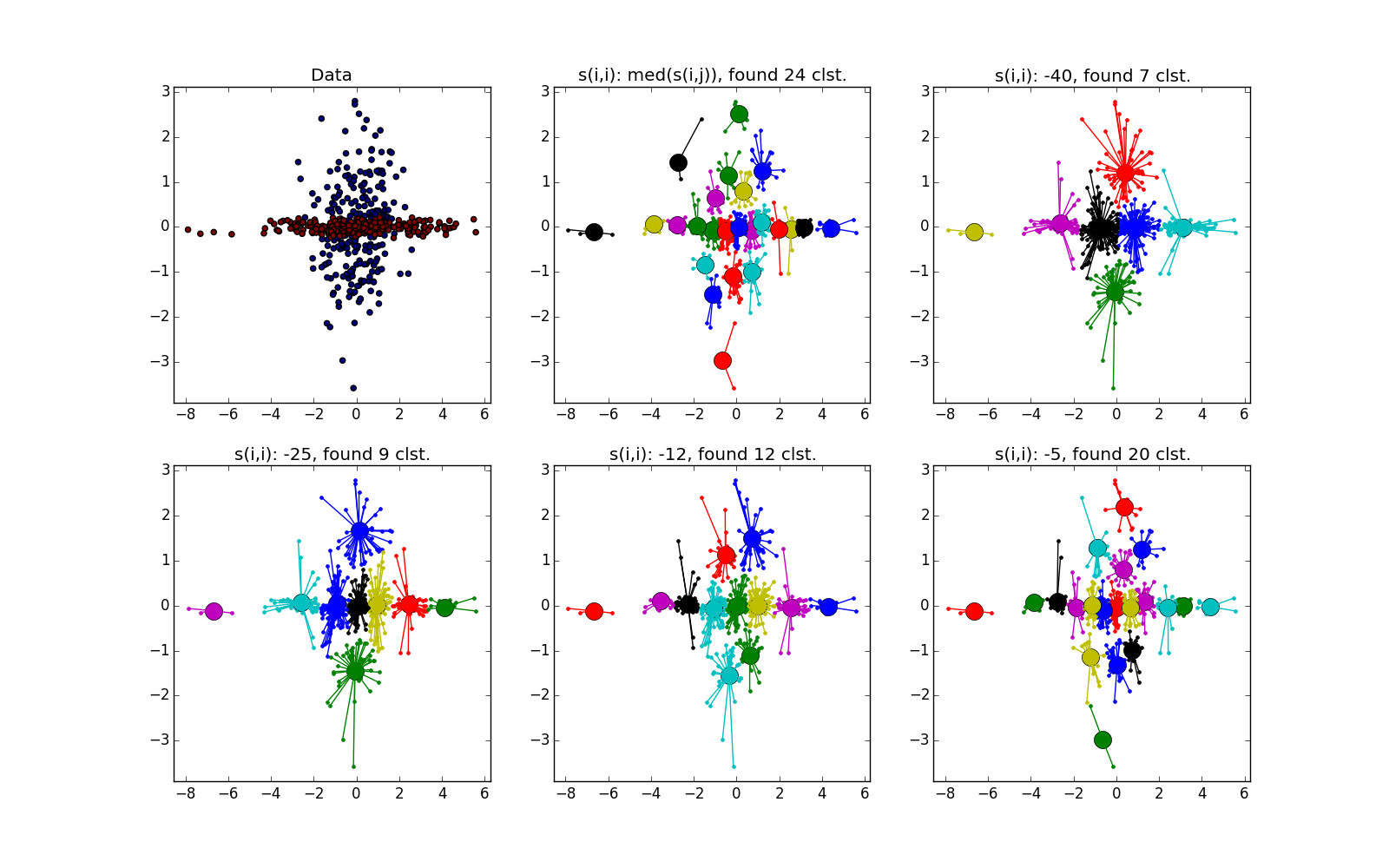
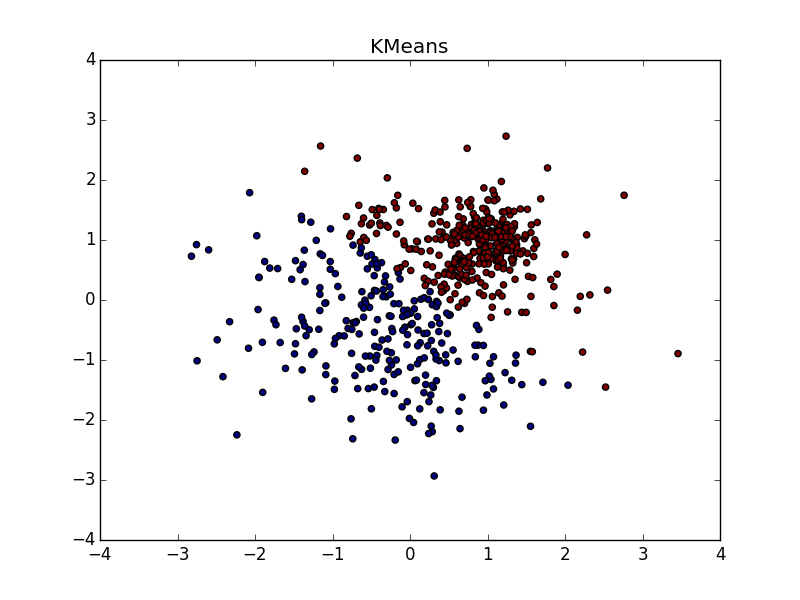
Со сгустком большей плотности в другом сгустке, на мой взгляд, чуть-чуть выигрывает k-means. Он, конечно, «отъедает» значительный кусок в пользу кластера большей плотности, но по визуальному результату работы AP вообще не слишком видно неоднородность.
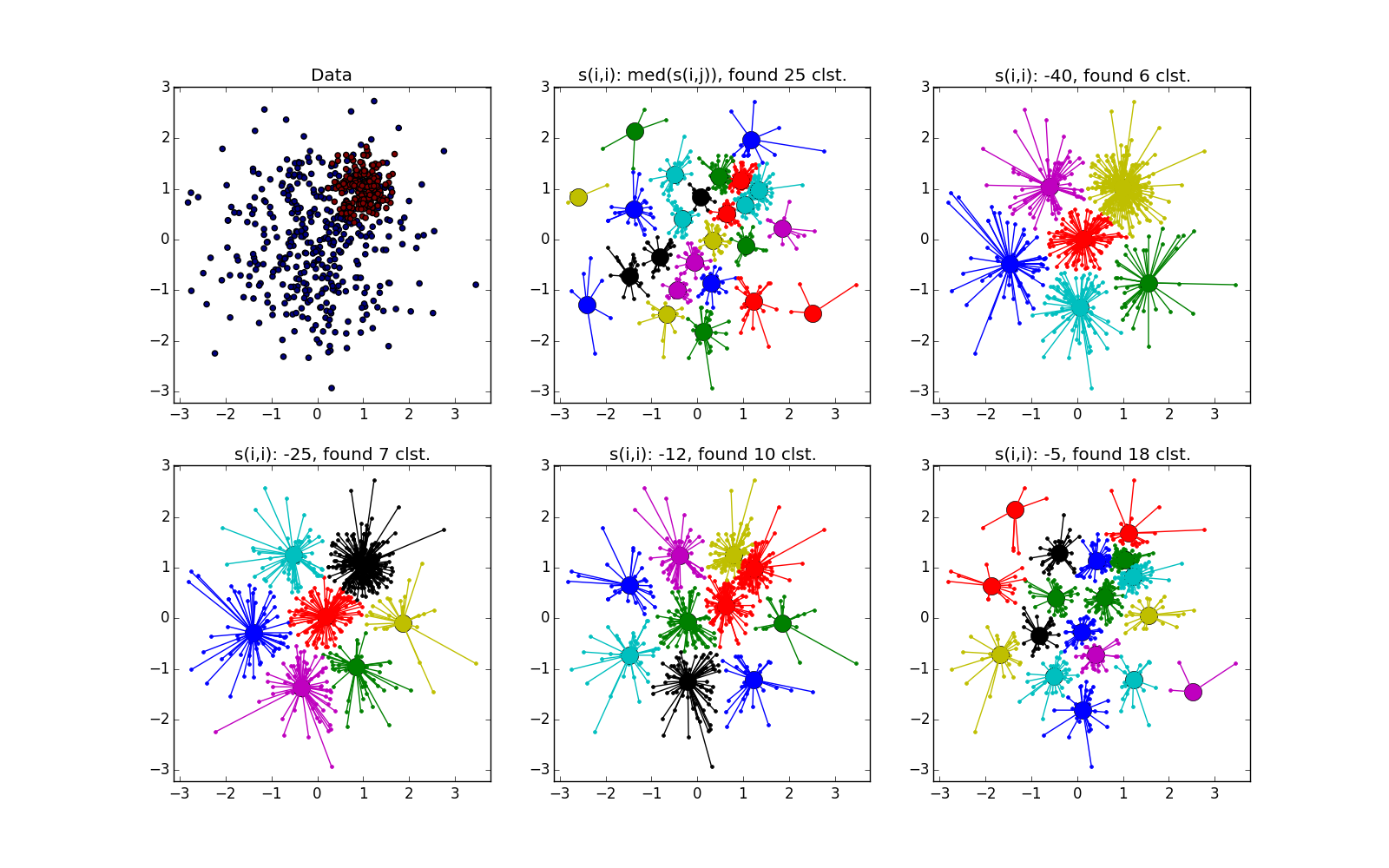
Ещё немного картинок:
Итог
Используйте Affinity propagation, когда
- У вас не очень большой (
 ) или в меру большой, но разреженный (
) или в меру большой, но разреженный ( ) датасет
) датасет - Заранее известна функция близости
- Вы ожидаете увидеть множество кластеров различной формы и немного варьирующимся количеством элементов
- Вы готовы повозиться с постобработкой
- Сложность элементов датасета значения не имеет
- Свойства функции близости значения не имеют
- Количество кластеров значения не имеет
Утверждается, что разные учёные успешно применяли Affinity propagation для
- Сегментирования изображений
- Выделения групп в геноме
- Разбиения городов на группы по доступности
- Кластеризации образцов гранита
- Группирования фильмов на Netflix
Во всех этих случаях был получен результат лучше, чем при помощи k-means. Не то чтобы это какой-то суперский результат само по себе. Мне неизвестно, проводилось ли во всех этих случаях сравнение с другими алгоритмами. Я планирую сделать это в грядущих статьях. По всей видимости, на датасетах из реальной жизни больше всего помогает умения распространения близости обходиться с кластерами разной геометрической формы.
Что же, вроде бы и всё. В следующий раз рассмотрим ещё какой-нибудь алгоритм и сравним его с методом распространения близости. Удачи, Хабр!
Комментарии (2)
 MikeLP
MikeLP
6 февраля 2017 в 09:57
0↑
↓
Было бы неплохо увидить реальный пример функции на С или Python. Или если есть ссылка на какой нибудь репозиторий с рабочими примерами, тоже было бы хорошо. Спасибо за статью.6 февраля 2017 в 10:20
0↑
↓
Вот, например, питонья sklearn-имплементация с примером использования, которую я препарировал. Здесь можно найти matlab версию, а здесь — Java (распараллеленная, кстати!), но я их не смотрел.
