Интеграция dovecot и Apache Solr
Добрый день.
Сегодня, почта до сих пор остаётся одним из ключевых средств обмена сообщениями в корпоративном сегменте. Объём хранимой почты только растёт и со временем занимает сотни гигабайт, а то и вовсе несколько терабайт. В такой момент пользователи в большинстве случаев начинают испытывать проблемы в процессе эксплуатации почты, например с поиском. Если использовать Web клиент, например тот же RoundCube, то при поиске по всем сообщениям во всех папках да и ещё по содержимому самого письма, очень часто результат приходилось ждать десятки секунд, что не очень приятно. Поэтому я и подумал, что пора бы в dovecot настроить FTS плагин.
Для большинства серьёзных и опытных администраторов настроить связку dovecot — solr не является большой проблемой, но если вы впервые с этим сталкиваетесь, то настройка приемлемого результата поиска может занять какое-то время. Попробую упростить настройку для тех кто впервые с этим столкнется.
Итак, изначально имеем следующие исходные данные:
- CentOS 6 — для решения нашей задачи, дистрибутив вообще не важен, но я буду делать на его примере
- Dovecot 2.2.32 — для нас важно что бы версия была 2.2.19 и выше.
- Apache Solr 7 — тут может быть как 6 версия так и 7.
Теперь приступим к настройкам.
Dovecot
Версия данного приложения должна быть выше чем 2.2.19. Это обусловлено тем что в ней исправили ошибку в плагине fts-solr, которая приводила к неправильному формированию запроса, результат всегда был 404. Так же приложение должно быть собрано с поддержкой плагина fts и fts-solr. Как бы странно это не звучало, но при выполнении:
dovecot --build-options
Узнать собран dovecot с поддержкой fts и fts-solr нельзя. Не зависимо от параметров сборки, эти плагины там не появляются. Для того что бы убедится что плагины есть и работают, выполним вот такую команду:
ls /usr/lib64/dovecot/ | grep -E "solr|fts"
Результат у меня выглядит так:
lib20_fts_plugin.so
lib21_fts_solr_plugin.so
lib21_fts_squat_plugin.so
libdovecot-fts.so.0
libdovecot-fts.so.0.0.0
Если у вас результат похож на мой, значит всё нормально, можно приступать к настройке.
Для этого в каталоге /etc/dovecot/conf.d в файле 10-mail.conf в переменную mail_plugins в конец дописываем наши плагины, у меня это выглядит так:
mail_plugins = quota acl expire mail_log notify fts fts_solr
Затем открываем файл 90-fts.conf и приводим его к виду:
plugin {
fts = solr
fts_solr = url=http://127.0.0.1:8983/solr/dovecot/ #слеш в конце обязателен!
fts_autoindex = yes
}
Если у вас файла 90-fts.conf нет, вы его можете создать с содержимым указанным выше. На этом настройка dovecot закончена. Незабываем перезапустить dovecot. Переходим к Solr.
Apache Sorl
Тут всё тоже довольно просто. Поэтому сразу приступаем к делу.
Так как Solr написан на Java надо установить openjdk:
yum install java-1.8.0-openjdk lsof
Сначала скачиваем дистрибутив Apache Solr, на момент написания статьи актуальная версия 7.2.1.
wget http://apache-mirror.rbc.ru/pub/apache/lucene/solr/7.2.1/solr-7.2.1.tgz -O /usr/src/solr-7.2.1.tgz
Распаковываем файл установщик из архива:
tar zxf solr-7.2.1.tgz solr-7.2.1/bin/install_solr_service.sh
И устанавливаем Solr:
./solr-7.2.1/bin/install_solr_service.sh solr-7.2.1.tgz
В результате вывод установки будет наподобие этого:
We recommend installing the 'lsof' command for more stable start/stop of Solr
id: solr: no such user
Creating new user: solr
Extracting solr-7.2.1.tgz to /opt
Installing symlink /opt/solr -> /opt/solr-7.2.1 ...
Installing /etc/init.d/solr script ...
Installing /etc/default/solr.in.sh ...
Service solr installed.
Customize Solr startup configuration in /etc/default/solr.in.sh
NOTE: Please install lsof as this script needs it to determine if Solr is listening on port 8983.
Started Solr server on port 8983 (pid=1647). Happy searching!
Found 1 Solr nodes:
Solr process 1647 running on port 8983
{
"solr_home":"/var/solr/data",
"version":"7.2.1 b2b6438b37073bee1fca40374e85bf91aa457c0b - ubuntu - 2018-01-10 00:54:21",
"startTime":"2018-03-01T11:22:40.462Z",
"uptime":"0 days, 0 hours, 0 minutes, 15 seconds",
"memory":"25.6 MB (%5.2) of 490.7 MB"}
Тут видно, что Solr успешно установился, а так же некоторые данные установки. У solr есть web интерфейс, который будет доступен на порту 8983, там можно понаблюдать статистику, ошибки и некоторые другие вещи. Теперь давайте его настроим.
Первое что желательно сделать, это перенести каталог data, так как он будет очень быстро разрастаться (всё зависит от количества данных которые надо проиндексировать) и желательно что бы места было много. У меня в каталоге /var места не очень, поэтому исправим это.
Создаю каталог для solr:
mkdir -p /srv/solr/data
В нем будут храниться все данные. Теперь открываем файл /etc/default/solr.in.sh и в нём исправляем некоторые настройки:
SOLR_JAVA_MEM="-Xms10240m -Xmx20480m" #тут указываем стартовый и максимальный размер памяти и конечно ориентируемся на размер ОЗУ на сервере на котором стоит Solr
SOLR_HOME="/srv/solr/data" #тут указываем домашний каталог Solr
Касательно оперативки что бы понимали, у меня Solr выглядит так:
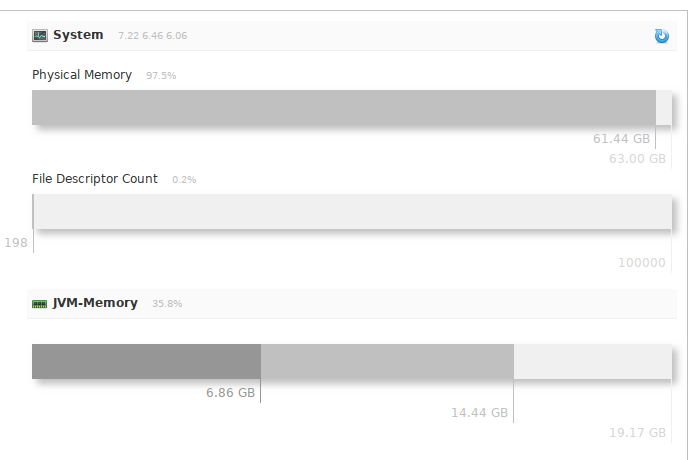
т.е. я не ошибся ноликами в настройках, он очень много кушает, при большом количестве данных.
Так же в этом файле можно поправить и другие настройки, загляните в этот файл, там много интересного. Нам пока достаточно этого.
Скопируем содержимое старого каталога в новый:
cp /var/solr/data/* /srv/solr/data/
И выставим правильные права:
chown -R solr:solr /srv/solr
Теперь можно перезапустить Solr что бы он перечитал конфигурационный файл:
service solr restart
Переходим в каталог установки Solr и авторизуемся под пользователем solr:
cd /opt/solr/bin
su solr
Можно создать схему и настроить сам Solr для работы, что бы он правильно принимал и обрабатывал запросы от dovecot:
Создаем ядро:
./solr create_core -c dovecot -n dovecot
Переходим в каталог вновь созданного ядра:
cd /srv/solr/data/dovecot/conf
Именно тут будут лежать основные настройки для нашего ядра. Нас интересуют два файла:
- schema.xml — основной файл настройки правил индексации и запросов к Solr
- solrconfig.xml — конфигурационный файл самого ядра.
Сначала разберёмся с schema.xml. Схема которая идёт в комплекте с dovecot не приемлема к эксплуатации от слова, совсем. Поэтому я приведу более правильную схему, приведите файл к такому содержимому:
id
Основное что нас интересует это два блока analyzer которые описывают правила индексации и запросов к Solr. Опишу основные моменты:
tokenizer classОписывает как Solr будет разбивать предложение на слова. В этой схеме используется solr.ClassicTokenizerFactory, согласно документации, он предложение:
«Please, email john.doe@foo.com by 03–09, re: m37-xq.»
Разберёт на слова следующим образом:
«Please», «email», «john.doe@foo.com», «by»,»03–09», «re», «m37-xq».
Меня такое более чем устраивает, но не всех это устроит, поэтому вы можете подобрать свой класс который будет более оптимален для вашей системы. Смотрите ссылку что я дал выше.
filter class Описывает обработку слов которые получаются на выходе у tokenizer. Тут могут быть указанны разные параметры, о которых вы можете почитать по ссылке что я привел. Опишу основные:
solr.EdgeNGramFilterFactory — формирует из слова токены согласно своим параметрам minGramSize и maxGramSize. У меня стоит 1 и 40 это значит что из слова «Домены» будут сформированы следующие токены: «д», «до», «дом», «доме», «домен», «домены». Такие токены будут создаваться размером вплоть до 40 символов. Тут есть маленький нюанс, если слово длиннее чем 40 символов, например 50, то если пользователь введёт в поиске запрос размером >40 и < 50 то результат будет нулевым. Поэтому я и ввёл такое большое число, так как я не встречал email длиннее 40 символов, а в русском языке вообще, самое длинное слово 25 символов.
solr.LowerCaseFilterFactory — приводит все слова в нижний регистр, добавил что бы поиск независил от регистра введённых символов.
solr.StopFilterFactory — указывает Solr какие слова вообще не индексировать и просто игнорировать, слова записываем в файл и указываем через параметр words.
solr.EnglishMinimalStemFilterFactory — фильтр для обработки множественного числа английских слов, dogs будет преобразован в dog и т.п.
solr.EnglishPossessiveFilterFactory — так же для обработки английских слов, удаляет притяжательные и не только окончания, Man’s преобразуется в Man.
solr.KeywordMarkerFilterFactory — языковой параметр, тут описан более подробно. Если я правильно понял, своего рода слова исключения которые solr индексирует без предварительных модификаций, так сказать «как есть».
Данные параметры могут быть использованы как в анализаторе индексирования, так и в анализаторе запроса. Естественно что эти анализаторы могут иметь различные параметры и они не влияют друг на друга. На этом со схемой можно закончить.
Переходим к solrconfig.xml. Тут есть момент с 7 версии Solr по-умолчанию используется json формат для общения, но плагин dovecot использует xml. Поэтому нам надо найти в файле несколько параметров и поправить их (к Solr 6 это не относится)
В блоке (~745 строчка):
Блок «defaults» приводим к виду:
explicit
10
xml
В блоке (~810 строчка):
Блок «defaults» приводим к виду:
explicit
xml
true
Теперь необходимо удалить (можно просто закомментировать) блок (Касается 6 и 7 версии Solr)
и добавить блок (в районе 1190 строчки)
перед блоком:
На этом настройка Solr закончена, можно переходить к индексации. Не забываем что после любых изменений конфигурационного файла необходимо перезапустить Solr.
Для того что бы проиндексировать почтовые ящики пользователей у dovecot есть несколько команд.
#сбросит индекс почтового ящика, после этой команды необходима полная индексация почтового ящика
doveadm fts rescan -u s.chistiakov@example.com #индексируем почтовый ящик конкретного пользователя
doveadm -vvvvv index -u s.chistiakov@exmample.com "*"# индексируем все ящики всех пользователей.
doveadm -v index -A "*"
Если у вас doveadm ругается что не может найти пользователей или что-то подобное, проверьте есть ли у вас параметр iterate_query. Без данного параметра могут быть проблемы с поиском пользователей и их ящиков. У меня пользователи лежат в БД и данный параметр у меня выглядит так:
iterate_query = SELECT username as user FROM mailbox
Лежит в файле где описаны запросы к БД пользователей и паролей.
Статистика Solr для ядра dovecot у меня сейчас выглядит так: 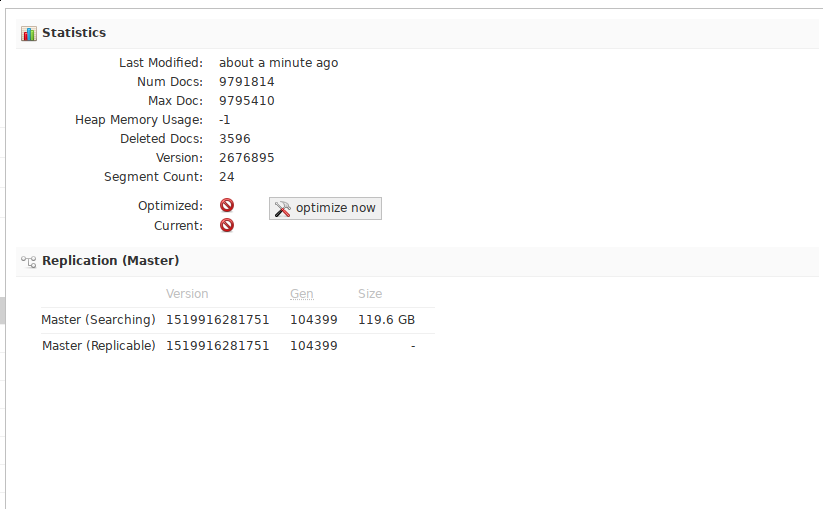
Немного оптимизации, еще в cron у меня добавлены такие параметры:
0 6 * * * /usr/bin/doveadm -v index -A "*"
5 */1 * * * curl "http://127.0.0.1:8983/solr/dovecot/update?commit=true"
еще можно добавить для того что бы проходила оптимизация базы.
0 22 * * * curl "http://127.0.0.1:8983/solr/dovecot/update?optimize=true"
Итого
После полной индексации ящика и скорость обработки поисковых запросов выросла многократно, если раньше сложный запрос занимал десятки секунд, то сейчас менее секунды. Тестов старых у меня к сожалению не осталось, но думаю что можно мне поверить на слово, либо проверить лично используя данную инструкцию.
Не обошлось и без недостатков, если вы меняете параметры индексации, то вам придется индексировать всю почту с нуля. А это занимает очень много времени, на моем объеме и при моих характеристиках железа около 3 дней. Но один раз настроив все будет работать как надо.
Если что-то забыл или попутал, не обессудьте писал по памяти большую часть, так как уже все настроено и работает.
