И к гадалке не ходи. Как и зачем мы предсказываем офлайн-продажи товаров

Онлайн-ритейлеры и всевозможные маркетплейсы постоянно пересчитывают цены, придумывают хитрые акции и ставят эксперименты на пользователях. Но кто сказал, что в магазине у дома нельзя делать то же самое? Да, это сложнее, но зато интереснее и может принести больше пользы.
Мы разрабатываем системы управления ценообразованием для больших розничных сетей. В рамках этой задачи экспериментируем с предсказанием продаж в розничных офлайн-магазинах. Предлагаем вам узнать больше о подходах, которые используются в решении таких задач.
Проблемы условной «Пятерочки»
Офлайн-ритейл — по большей части гиперлокальный бизнес. Чтобы успешно торговать продуктами в этом формате, нужно удерживать лучшие цены в рамках конкретного ареала потребителя (например, отдельно взятого квартала). А для этого нужно знать и учитывать цены в магазинах конкурентов, расположенных поблизости.
Если речь про один магазин, в этом нет особой проблемы. Его владельцы часто живут в том же районе, в курсе цен и чуть ли не знают каждого клиента в лицо. Однако на уровне торговой сети из сотен или тысяч небольших торговых точек крайне сложно управлять такой маленькой гранулярностью. Нужно как-то централизованно рассчитывать цены для каждого товара в каждом магазине, причем с учетом индивидуальных особенностей:
географического расположения;
конкурентной ситуации;
себестоимости;
наличия товарных остатков;
и еще массы разнообразных факторов — чем больше, тем лучше (по крайней мере в теории).
Чтобы решить такую комплексную задачу, нужно опутать автоматизацией всю компанию сверху донизу. Нужно разработать комплексную систему контроля и управления ценообразованием. Это интересная, но очень большая и сложная задача. Мы решили ее для одного крупного российского ритейлера.
Только слона мы будем есть по частям, так что в этой статье рассмотрим только один маленький компонент этой головоломки, а именно — как рассчитать оптимальную цену для отдельно взятого товара. Точнее, как предсказать спрос.
Причем здесь спрос? Сейчас объясню.
Микроэкономика на примере пива и воблы
Понятие «оптимальная цена» в нашем контексте требует пояснений.
Ритейл опирается на три ключевые метрики:
Маржинальная прибыль. Это тот объем прибыли, который компания получает с проданных товаров, разница между выручкой и себестоимостью. Рост маржинальной прибыли приносит больше денег акционерам и собственникам компании.
Общий объем выручки в рублях. Рост выручки означает увеличение доли на рынке.
Общий объем продаж в штуках. Рост продаж повышает количество чеков, число покупателей.
С точки зрения логики алгоритма мы должны учитывать все три эти бизнес-цели. Сложность в том, что все они находятся в нелинейной взаимосвязи и даже отчасти противоречат друг другу. Например, увеличения продаж можно добиться при помощи скидок, но это снизит маржинальную прибыль. И наоборот, можно добиться повышения выручки в рублях за счет повышения цен и снижения общего объема продаж. Однако такие меры могут как повысить, так и сократить маржинальную прибыль в зависимости от ситуации.
Сложно? Мы только начали.
В идеальном мире из учебника микроэкономики все действуют рационально и обладают полной информацией о предложениях всех продавцов в округе. Более того, он готов переключаться. Если, например, пиво дешевле в одном магазине, а вобла продается по скидке в другом — он сходит за пивом в первый магазин, а за закуской — во второй.
Это идеальный концепт с точки зрения эластичности спроса (чувствительности потребителя к изменению цены). В такой ситуации мы можем описать поведение потребителя в зависимости от цены на товар определенной линейной или нелинейной зависимостью. То есть мы хорошо понимаем влияние цены на изменение спроса.
В реальном мире (пускай он тоже сферический и в вакууме) этот концепт обрастает массой деталей, предсказание спроса сильно осложняется. Например, цены на часть товаров ограничены со стороны государства: табачные изделия, алкоголь, товары первичной потребительской корзины. К тому же в расчеты попадает масса шумов — независимых и непредвиденных факторов. Например, если сотрудники забыли приклеить ценники на новый товар или отчитались, что выложили товар на полку, но на самом деле не сделали этого. Это тоже нужно выявлять и учитывать, а значит, мониторить не только наличие товара в остатках магазина, но и динамику продаж за день.
И таких факторов великое множество. Банально, есть годовая инфляция, которая нелинейна и даже некатегориальна — она происходит на уровне конкретных SKU (артикулов). Поэтому мы не можем напрямую сравнивать товары внутри года, то есть использовать цену как один из параметров зависимости спроса. Думаю, не нужно объяснять, почему цена в 70 рублей сегодня — не то же самое, что 70 рублей год назад. Более того, эти 70 рублей «ведут себя» по-разному в зависимости от того, какие предложения есть сейчас у конкурентов.
На практике на спрос влияет масса таких относительных вещей. Поэтому в основу расчетов нужно брать не твердую цену товара в рублях, а скорее некий »вес», ценность предложения.
Итого, задачу максимизации маржинальной прибыли можно формализовать так:

где  — себестоимость товара,
— себестоимость товара,  — функция спроса, ожидаемые продажи в штуках с определенной ценой.
— функция спроса, ожидаемые продажи в штуках с определенной ценой.
Поэтому мы предложили заказчику перевернутьзадачу поиска оптимальной цены товара в задачу высокоточного прогнозирования спроса. Суть та же, но для спроса можно провести больше экспериментов, и вывести больше метрик, которые помогут валидировать расчеты. Например:

Учитывает пропорциональные изменения спроса и лучше, чем MAPE подходит для случаев, когда продажи неустойчивы.

Учитывает несимметричную природу задачи — чаще предпочтительными являются ситуации избытка товара.

Учитывает пропорциональные изменения спроса.
Прогноз спроса в офлайн-ритейле многофакторный, он учитывает различные параметры, которые есть в бизнесе, в том числе и ценовые. Меняя эти параметры можно понять, насколько вырастет или упадет спрос. А определение оптимума по спросу и цене — сравнительно несложный арифметический подход к задаче предсказания, к которой даже не нужно привлекать экстрасенсов.
По классике. Методы прогнозирования спроса
Самый простой метод — расчет по константной модели: берут продажи последней недели (месяца, года) и пытаются аппроксимировать их на будущее. Но в таком подходе нет как такового прогнозирования. Мы опираемся на исторические продажи и предполагаем, что существует некая инерция спроса: если мы в прошлом месяце продали 60 штук, то, вероятно, в этом месяце тоже продадим 60.
Модель с функцией скользящего среднего чуть умнее, чем константная, потому что лучше обрабатывает колебания спроса. Константная функция сильно реагирует на всплески спроса и может допустить большую ошибку (например, если на 35-й неделе был огромный спрос, то тот же самый спрос будет предполагаться и на 36-й неделе), а модель скользящего среднего сглаживает такие пики, и поэтому в среднем точнее.
Поверх этих классических методов прогнозирования спроса строится логика, которая позволяет учитывать в расчетах различные коэффициенты.
Вместо средних показателей в разрезе недель возьмем средние в разных разрезах — допустим, средние продажи в прошлом году или средние продажи по месяцам. Далее можно задавать разные модели средних величин с разными весами, получая в результате комбинированную модель из средних, которая уже может давать неплохую точность. Но все же этого мало. Если сравнивать этот подход с нашим, то он скорее похож на технический инвестиционный анализ с попыткой найти зависимости там, где их может не быть.
Если спрос окружен большим количеством шумов и отклонений, то искать в нем зависимости по средней модели может быть просто… глупой затеей. Судите сами: скажем, санаторий закупил в магазине партию яблочного сока. По статистике в этот день в данном магазине будет всплеск продаж. Если опираться на вышеописанный метод, то через семь дней в тот же день недели мы привезем туда большую партию товара, но ничего не продастся. Или, например, график упал вниз, и средняя модель скажет: «О, у нас ужасные продажи!». А на самом деле в магазине просто не было остатков, что никак не определяет спрос. Такой технический анализ, когда мы пытаемся из простого графика со всплесками или падениями вытащить максимум информации, может быть обманчивым. Чем менее гранулярными будут данные, тем больше будем обманываться.
А как на практике?
Наш заказчик рассчитывал дополнительные поставки для промоакций и прогнозировал товародвижения, устанавливая при этом единые цены в масштабах населенного пункта и целых категорий товаров.
Чтобы понимать, как изменится спрос, менеджеры использовали довольно прямолинейные методы, как правило, константные. Для прогнозирования товародвижения они брали продажи за предыдущие семь дней, а затем применяли ЛВК (лимитирующе-выталкивающий коэффициент) — по сути, это костыль, который дает менеджеру возможность управлять прогнозом вручную. Предполагается, что с помощью ЛВК менеджер учтет факторы которые не попадают в прогнозную модель. Для расчета промоакций сотрудники заказчика опирались на продажи, которые происходили год назад в те же даты. Получалась низкая детализация и примерно такой график.
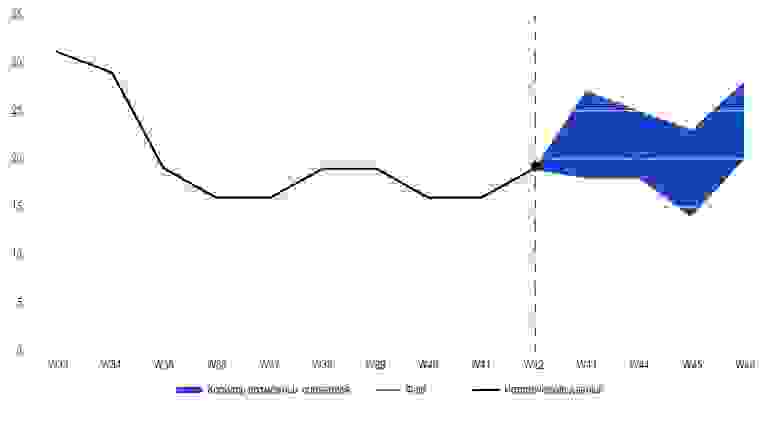
Коридор возможных сценариев для предсказания прогнозного объема продаж для отдельно взятого товара
Точность такого прогноза сильно зависит от опыта и даже чутья конкретного менеджера и оставляет желать лучшего на хоть сколько нибудь большой дистанции. Плюс, когда оставляешь место для человеческого фактора, сразу ограничиваешь объем и скорость обработки данных.
Менеджер физически не может акцептовать все решения о цене. В нашем кейсе речь шла примерно о 15 млн уникальных комбинаций цен на товары в рамках торговой сети. На таких масштабах алгоритмы имеют значительное преимущество, только нужно скормить им много правильных данных.
Как в прачечной. Очищаем и отбираем данные
В начале проекта в наши руки попала вся матрица продаж ритейлера, из которой мы взяли «почековые» данные, то есть те, которые генерируют магазинные кассы. Мы также получили доступ к истории продаж за два года, данным по остаткам во всех магазинах и ценам конкурентов.
Пару слов о масштабах: в двух регионах (Москве и Нижнем Новгороде) за неделю мониторинга цен конкурентов накапливается 4 млн строк. Умножаем на 50 недель в году, получаем 200 млн строк за год. Перед тем как перейти к построению модели и выбору метрик ее оценки, необходимо было произвести разделение датасета на:
1) Категории по географическому положению:

где — все множество строк набора данных.
— все множество строк набора данных.
2) Категории по типу товара  :
:

При расчетах также стоит учитывать, что из спроса в некоторую последовательность дат можно составить ряд , так что это еще и задача прогнозирования временного ряда.
, так что это еще и задача прогнозирования временного ряда.
Спрос на некоторый товар зависит не только от его цены, но и от таких параметров, как, например, сезонность, цены конкурентов, погодные условия и т. д. Поэтому функцию спроса можно представить так:

где  — некоторый набор учитываемых характеристик помимо цены. Большинство из них под NDA, но очевидно что во многом продажи зависят от характеристик товара. То же пиво и мороженное зависят от погоды: в жару продажи растут двух-, а то и и трехкратно. Поэтому в прогнозировании спроса на этот товар погода оказалась важным фактором в уточнении модели. Также играют роль праздничные дни, суммарный и средний спрос и даже расстояние до ближайших магазинов — всего мы учитывали порядка 30 факторов.
— некоторый набор учитываемых характеристик помимо цены. Большинство из них под NDA, но очевидно что во многом продажи зависят от характеристик товара. То же пиво и мороженное зависят от погоды: в жару продажи растут двух-, а то и и трехкратно. Поэтому в прогнозировании спроса на этот товар погода оказалась важным фактором в уточнении модели. Также играют роль праздничные дни, суммарный и средний спрос и даже расстояние до ближайших магазинов — всего мы учитывали порядка 30 факторов.
Каннибализация и другие неучтенные факторы
Самым сложным было начать. Трудно отталкиваться от того, что написано в научных статьях, когда работаешь с реальным миром.
Например, мы столкнулись с тем, что в нашем датасете с ростом цены увеличивается спрос. Долго думали, как такое может быть… Оказалось, что в том регионе открылось много новых магазинов — поэтому и спрос вырос. И таких вот инсайтов было бесконечное множество.
Каждый раз кажется, что вот сейчас ты все учел и теперь все должно работать отлично. Но смотришь на графики, и все равно получается какая-то фигня… И так десятки раз. Сначала ты не учел, что открываются новые магазины; потом не учел, что у тебя остатки в магазине могут обнуляться;, а еще сотрудники меняют ценники не в тот же день, в который поменялись цены на бумаге, а через два-три дня… И каждый раз всплывает что-то новое. И ты такой: «Блин, да как мы это пропустили?» И кажется, что это рушит всю модель и надо начинать чуть ли не с чистого листа.
А еще есть инерция спроса (инертность поведения потребителя). Это когда покупатель еще некоторое время по привычке продолжает брать товар по завышенной цене, прежде чем пойти в другой магазин. Играет роль и так называемая каннибализация (территориальная и категориальная) — из-за изменения цены потребители переключаются не только между магазинами, но и с одного товара на другой.
Цены конкурентов также оказались очень важны. Причем, нельзя просто взять и внести стоимость товаров. Чтобы модель лучше обрабатывала эти данные, их тоже нужно подготовить, правильно агрегировать.
Например, мы можем взять минимальную цену среди конкурентов в определенном радиусе, можем задать разницу между нашей ценой и ценой конкурентов, можем использовать категорийные ценовые агрегаты и сравнивать наши и конкурентные цены в районе конкретного магазина. Фактор конкурентной цены в разрезе использования этих различных агрегатов по сложности, пожалуй, сопоставим со всеми остальными факторами вместе взятыми.
Так как же предсказать спрос?
Для начала можно проводить расчеты с учетом одного параметра. Для этого примем каждый товар в ассортименте за отдельную категорию, а информацию о продажах по магазинам усредним в рамках одной недели с сохранением разбиения по ценам.То есть, мы усредняем продажи в рамках одной недели и наносим эти точки на плоскость, где на оси X — цена товара, на оси Y — средние продажи этого товара, а затем стараемся провести по этим точкам регрессию.

где  — некоторая дифференцируемая функция с набором обучаемых параметров
— некоторая дифференцируемая функция с набором обучаемых параметров  .
.
Получается так называемая кривая спроса, отражающая влияние цены на продажи товара. Самый простой способ визуализировать эту зависимость — убывающая линейная регрессия, но существует много альтернатив. В качестве целевой функции » » можно использовать:
» можно использовать:
 — квадратичную зависимость;
— квадратичную зависимость;  — степенной закон;
— степенной закон;  ;
; линейную комбинацию 2–4 сигмоид вида
 .
.
Так, например, комбинация сигмоид выглядит как убывающая гладкая функция и стремится моделировать существующие в реальной жизни пороги цен: «психологические», связанные с ценами других магазинов или являющиеся комбинацией нескольких факторов. На их примере сигмоид хорошо видно, что изменение цены в некоторых пределах может практически не влиять на продажи, а затем они резко упадут или увеличатся. Изменение кривых можно предсказывать при помощи машинного обучения. Это тема, достойная отдельной статьи, и на Хабре уже есть одна такая публикация, так что задерживаться на ней не будем.
Конечно, расчеты на базе кривых спроса работали неплохо, это давно известный метод, однако им не хватало предсказательной точности для использования на практике. Чем дальше мы заглядывали в будущее, тем сильнее была погрешность. Неучтенные факторы, скажем инфляция, влияют на продажи, и их влияние накапливается со временем, в то время, как эта модель их вообще не учитывает. Чтобы добавить к прогнозу, например, данные о ценах конкурентов, придется усложнить итоговую функцию до вида:

При этом в качестве цены конкурентов на определенный товар возьмем 2-квантиль от всех цен конкурентов в соответствующий момент времени. Получится уже не плоский график, а функция в пространстве — облако точек, на основе которого строится поверхность второго порядка. Добавление нового параметра в регрессию дает некоторый прирост точности предсказаний, но использовать в продакшене такой подход все еще не стоит.
Опытным путем мы выяснили, что можно добиться заметного повышения точности прогнозов, если пойти по пути предсказания процентных изменений в продажах относительно прошлых периодов. Это несколько облегчает представление данных. Если раньше мы имели дело с конкретными объемами товаров, то теперь задача предстает в ином виде. Есть 100% товара, проданного за прошлый период и нужно предсказать, на сколько процентов больше или меньше продадут в следующем периоде.
Мы решили поэкспериментировать с моделью, где в качестве таргета для каждого дня было использовано отношение изменения спроса продаж на следующей неделе (семи следующих дней, включая рассматриваемый) к продажам на прошлой неделе (семи ближайших прошедших дней, не включая рассматриваемый). Этот целевой параметр показывает процентное изменение продаж и позволяет предсказывать динамику, не заостряя внимание на абсолютных значениях.
Для решения этой задачи можно использовать обыкновенный Catboost. Вся »соль» в том, какие фичи и в какой форме подавать на вход. Чтобы включить в расчеты все 30 с лишним факторов, влияющих на спрос и, соответственно, на продажи, можно использовать в качестве модели классическую линейную регрессию. Однако перед обучением модели все числовые параметры-признаки необходимо нормировать: привести СКО к единице, а среднее — к нулю.
В рамках наших экспериментов было исследовано 2 варианта: обучение одной модели под все товары с маркером класса товара и обучение отдельной модели под каждый товар. Метрики обоих подходов приведены ниже:
MAPE

MAE

RMSE

Quantile

Мы экспериментировали с Quantile Loss на уровне 
А как точно предсказать спрос?
Пропорциональные предсказания в сочетании с кропотливым фича-инжинирингом дают значительный прирост точности предсказания спроса в 5–9% пунктов по сравнению с нашими старыми подходами.
Используя ценовые и неценовые факторы, мы вычисляем, как изменится спрос за следующие N дней относительно прошлого периода такой же длины. Строим кривую спроса с учетом этих факторов, а также с учетом поведения временного ряда. Мы научились предсказывать спрос на товар в конкретном магазине со средней точностью +/- 18% и с точностью +/- 13% по городу на горизонте 7 дней.

Коридор возможных сценариев для предсказания прогнозного объема продаж для отдельно взятого товара. Точность предсказаний меняется от товара к товару, но в среднем наша модель позволяет получить на горизонте в неделю погрешность в 18% на уровне региона, 13% в пределах города. В то время, как константная модель дает разброс 27%, а среднее — 36%. Расчеты проводились на выборке в 100 самых продаваемых товаров.
Точность константного и среднего подхода по городу +/- 27% и +/- 36% соответственно. Конечно, это все еще экспериментальный подход, но для статической модели — неплохо. Нам удалось построить многофакторную прогнозную модель спроса, которая в 9 из 10 случаев оказывалась точнее, чем классические методы прогнозирования продаж.
Это несмотря на ограниченность с точки зрения экспериментов, которая вытекает из особенности офлайн-ритейла. Мы не можем прийти и сказать: «Давайте завтра на месяц снизим цену на этот товар на три рубля и посмотрим, что получится». Это сильно отличается от онлайна, где можно в пару кликов отрезать часть трафика, раскатить на пользователей A/B-тест и быстро проверить гипотезу.
Модель с этими показателями в принципе уже можно применять на практике. А сам метод расчетов можно довольно быстро адаптировать под другую задачу. Например, если заказчика интересует товародвижение, то результатом будет прогноз продаж в разрезе, например, товаров ежедневного потребления в определенных населенных пунктах.
Это плюс, но для для управления ценами в рамках большой торговой сети одной такой модели недостаточно. Общая картина еще сложнее. Переходя к экспериментам по определению оптимальной цены, мы столкнулись с двумя ключевыми препятствиями:
Недостаточная точность модели для определения значимости цены в спросе, а значит и построения эластичности (мы объясняли около 50% зависимости спроса, остальные 50% приходились на шум).
Даже если предположить, что мы бы с высокой точностью определили оптимальную цену на товаромагазин (спрос на один товар в одном магазине), практически невозможно доказать статистическую значимость полученных результатов эксперимента. Проводить А/Б-тесты в офлайне проблематично. В наших условиях выборка составляла около 500 магазинов в течение 4 месяцев на 1 товар для оценки прироста маржинальной прибыли в рамках 2%.
Поэтому мы продолжили исследования: переложили предсказания на нейросети и изменили сам подход к ценообразованию от качественного прогнозирования к качественному тестированию и анализу результатов, где цены в рамках эксперимента задаются псевдослучайным образом в определенном коридоре (+/- 3%). Затем производится аналитика на предмет поиска оптимума с учетом запросов бизнеса, но это уже другая история.
Как говорится, данные — это новая нефть, и понимание рыночных процессов дает больший контроль над бизнес-процессами, обостряет конкуренцию и делает торговлю выгоднее, как для продавцов, так и для покупателей. В конечном счете эти изыскания позволят решить ряд проблем, связанных с оптимизацией торговли. Тут много перспективных возможностей, например:
Разработка системы реагирования на аномалии продаж. При прогнозировании спроса на товаромагазин внутри дня можно сопоставлять реальные продажи вплоть до конкретных часов с прогнозом спроса, а также привязывать продажи к тем или иным товарам в проценте от поступающего трафика. Таким образом можно замечать аномалии продаж и отправлять сотрудникам торговой точки уведомления на терминал сбора данных о том, что с товаром что-то пошло не так, например:
товар отсутствует на полке, в то время, как в системе он заведен;
у товара некорректный или отсутствующий ценник;
у товара истек срок годности, или он испортился, рассыпался, разбился и т. д.
Оперативное устранение подобных проблем по нашим оценкам может дать прирост к товарообороту торговой точки порядка +1–2%.
Прогнозирование продаж внутри дня позволит планировать маршрутизацию заказов в торговые точки на те периоды, когда сотрудники наименее загружены (в часы минимальных продаж), поскольку приемкой и разгрузкой занимаются непосредственно сотрудники точек.
Прогнозирование скидок и промо. На основе данных чувствительности покупателей к изменению цен можно определять оптимальный размер скидки в период промо-акции, а также размер партии, который необходимо закупить у поставщика и развести по торговым точкам.
