HTTP/3: разрушение основ и дивный новый мир
Вот уже больше 20 лет мы смотрим веб-странички по протоколу HTTP. Большинство пользователей вообще не задумывается о том, что это такое и как оно работает. Другие знают, что где-то под HTTP есть TLS, а под ним TCP, под которым IP и так далее. А третьи — еретики считают, что TCP — это прошлый век, им хочется чего-то более быстрого, надёжного и защищённого. Но в своих попытках изобрести новый идеальный протокол они вернулись к технологиям 80-х годов и пытаются построить на них свой дивный новый мир.
Немного истории: HTTP/1.1
В 1997 году протокол обмена текстовой информацией HTTP версии 1.1 обрёл свой RFC. На тот момент протокол использовался браузерами уже несколько лет, а новый стандарт продержался ещё пятнадцать. Протокол работал только по принципу запрос-ответ и предназначался, главным образом, для передачи текстовой информации.
HTTP был спроектирован для работы поверх протокола TCP, гарантирующего надежную доставку пакетов до адресата. Работа TCP основана на установлении и поддержании надежного соединения между конечными точками и разбиении трафика на сегменты. Сегменты имеют свой последовательный номер и контрольную сумму. Если вдруг какой-то из сегментов не придёт или придёт с неверной контрольной суммой, то передача остановится, пока не будет восстановлен потерянный сегмент.
В HTTP/1.0 TCP-соединение закрывалось после каждого запроса. Это было крайне расточительно, т.к. установление TCP-соединения (3-Way-Handshake) это не быстрый процесс. В HTTP/1.1 представили механизм keep-alive, который позволяет переиспользовать одно соединение для нескольких запросов. Однако поскольку оно может легко стать бутылочным горлышком, в разных имплементациях HTTP/1.1 допускается открытие нескольких TCP-соединений к одному хосту. Например, в Chrome и в последних версиях Firefox допускается до 6-ти соединений.
Шифрование предполагалось также отдать на откуп другим протоколам, и для этого поверх TCP стал использоваться протокол TLS, который достаточно надёжно защищал данные, но ещё больше увеличивал время, необходимое на установление соединения. В итоге процесс рукопожатия стал выглядеть так: 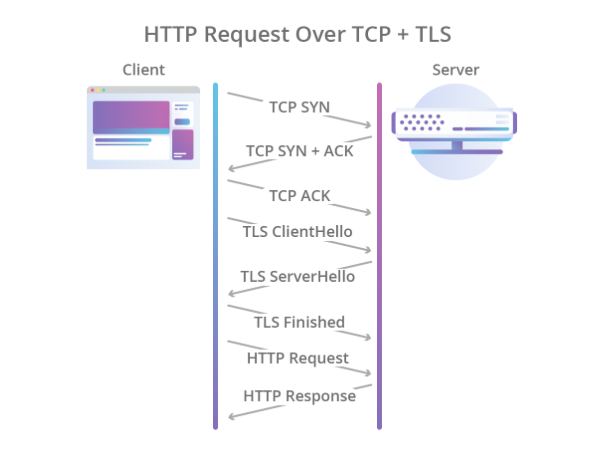
Иллюстрация Cloudflare
Таким образом HTTP/1.1 обладал рядом проблем:
- Медленная установка соединения.
- Данные передаются в текстовом виде, а значит передача картинок, видео и прочей нетекстовой информации неэффективна.
- Одно TCP-соединение используется для одного запроса, а значит остальные запросы должны либо найти себе другое соединение, либо ждать, пока текущий запрос его отпустит.
- Поддерживается только pull-модель. В стандарте нет ничего о server-push.
- Заголовки передаются текстом.
Если server-push худо-бедно реализуется с помощью протокола WebSocket, то с остальными проблемами предстояло разбираться более радикально.
Немного современности: HTTP/2
В 2012-м году в недрах Google началась работа над протоколом SPDY (произносится «спиди»). Протокол был призван решить основные проблемы HTTP/1.1 и при этом должен был сохранить обратную совместимость. В 2015 году рабочая группа IETF представила спецификацию HTTP/2, основанную на протоколе SPDY. Вот какие отличия были в HTTP/2:
- Бинарная сериализация.
- Мультиплексирование нескольких HTTP-запросов в одно TCP-соединение.
- Server-push из коробки (без WebSocket).
Протокол стал большим шагом вперед. Он сильно выигрывает у первой версии по скорости и не требует создания нескольких TCP-соединений: все запросы к одному хосту мультиплексируются в одно. То есть в одном соединении есть несколько так называемых стримов, каждый из которых имеет свой ID. Бонусом идет коробочный server-push.
Однако мультиплексация ведёт к другой краеугольной проблеме. Представьте, что мы асинхронно выполняем 5 запросов к одному серверу. При использовании HTTP/2 все эти запросы будут выполняться в рамках одного TCP-соединения, а значит, если один из сегментов любого запроса потеряется или придёт неверно, передача всех запросов и ответов остановится, пока не будет восстановлен потерявшийся сегмент. Очевидно, что чем хуже качество соединения, тем медленнее работает HTTP/2. По оценке Дениела Стенберга, в условиях, когда потерянные пакеты составляют 2% от всех, HTTP/1.1 в браузере показывает себя лучше, чем HTTP/2 за счёт того, что открывает 6 соединений, а не одно.
Эта проблема называется «head-of-line blocking» и, к сожалению, решить её при использовании TCP не представляется возможным.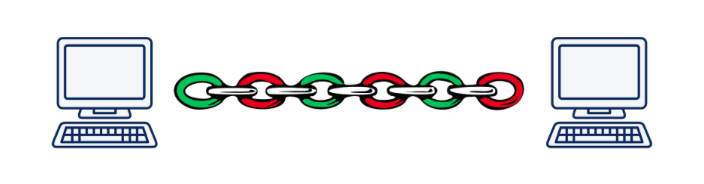
Иллюстрация Daniel Stenberg
Как итог, разработчики стандарта HTTP/2 проделали огромную работу и сделали практически всё, что можно было сделать на прикладном уровне модели OSI. Пришло время спускаться на транспортный уровень и изобретать новый транспортный протокол.
Нам нужен новый протокол: UPD vs TCP
Довольно быстро стало понятно, что внедрить совсем новый протокол транспортного уровня — задача в сегодняшних реалиях нерешаемая. Дело в том, что о транспортном уровне знают железки или middle-boxes (роутеры, файрволы, NAT-серверы…), а научить их чему-то новому крайне непростая задача. Кроме того, поддержка транспортных протоколов зашита в ядро операционных систем, а ядра тоже меняются не то чтобы очень охотно.
И тут можно было бы опустить руки и сказать «Мы, конечно, изобретём новый HTTP/3 с преферансом и куртизанками, но внедряться он будет 10–15 лет (примерно через такое время будет заменено большинство железок)», но есть ещё один не самый очевидный вариант: использовать протокол UDP. Да-да, тот самый протокол, по которому мы кидались файликами по локалке в конце девяностых-начале нулевых. Практически все сегодняшние железки умеют с ним работать.
В чём преимущества UDP по сравнению с TCP? В первую очередь в том, что у нас нет сессии транспортного уровня, о которой знает железо. Это позволяет нам самим определять сессию на конечных точках и там же разруливать возникающие конфликты. То есть мы не ограничены одной или несколькими сессиями (как в TCP), а можем насоздавать их столько, сколько нам нужно. Во-вторых, передача данных по UDP происходит быстрее, чем по TCP. Таким образом, в теории, мы можем пробить сегодняшний потолок скорости, достигнутый в HTTP/2.
Однако UDP не гарантирует надёжность передачи данных. Фактически мы просто посылаем пакеты, надеясь, что на другом конце их получат. Не получили? Ну не повезло… Этого было достаточно для передачи видео для взрослых, но для более серьёзных вещей нужна надёжность, а значит придётся накрутить что-то ещё поверх UDP.
Как и в случае с HTTP/2, работа по созданию нового протокола началась в Google в 2012-м году, то есть примерно в одно время с началом работы над SPDY. В 2013-м Джим Роскинд представил широкой общественности протокол QUIC (Quick UDP Internet Connections), а уже в 2015-м был внесен Internet Draft для стандартизации в IETF. Уже на тот момент протокол, разработанный Роскиндом в Google сильно отличался от вынесенного на стандарт, поэтому гугловскую версию стали называть gQUIC.
Что такое QUIC
Во-первых, как уже было сказано, это обёртка над UDP. Поверх UDP поднимается QUIC-connection, в котором по аналогии с HTTP/2 могут существовать несколько стримов. Эти стримы существуют только на конечных точках и обслуживаются независимо. Если потеря пакета произошла в одном стриме, другие это никак не затронет.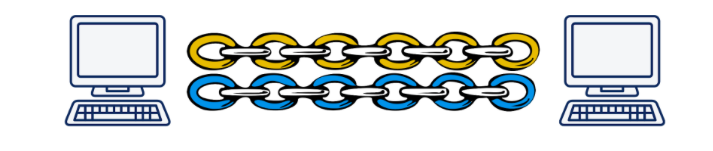
Иллюстрация Daniel Stenberg
Во-вторых, шифрование теперь реализовано не отдельным уровнем, а включено в протокол. Это позволяет устанавливать соединение и обмениваться публичными ключами за одно рукопожатие, а также позволяет использовать хитрый механизм 0-RTT handshake и вообще избежать задержек при рукопожатии. Кроме того, теперь можно шифровать отдельные пакеты данных. Это позволяет не ждать завершения приёма данных из стрима, а расшифровывать полученные пакеты независимо. Такой режим работы был вообще невозможен в TCP, т.к. TLS и TCP работали независимо друг от друга, и TLS не мог знать, на какие куски будет рубить данные TCP. А следовательно, не мог подготовить свои «рекорды» так, чтобы они укладывались в сегменты TCP один к одному и могли быть расшифрованы независимо. Все эти улучшения позволяют QUIC снизить latency по сравнению с TCP.
В-третьих, концепция лёгких стримов позволяет отвязать соединение от IP-адреса клиента. Это важно, например, когда клиент переключается с одной Wi-Fi точки доступа на другую, изменяя свой IP. В этом случае при использовании TCP происходит длительный процесс, в ходе которого существующие TCP-соединения отваливаются по таймауту и создаются новые соединения с нового IP. В случае с QUIC, клиент просто продолжает посылать серверу пакеты с нового IP со старым ID стрима. Т.к. ID стрима теперь уникален и не переиспользуется, сервер понимает, что клиент сменил IP, досылает потерянные пакеты и продолжает коммуникацию по новому адресу.
В-четвертых, QUIC реализуется на уровне приложения, а не операционной системы. Это, с одной стороны, позволяет быстрее вносить изменения в протокол, т.к. чтобы получить обновление достаточно просто обновить библиотеку, а не ждать новую версию ОС. С другой стороны, это ведёт к сильному увеличению потребления процессора.
Ну и напоследок, заголовки. Компрессия заголовков как раз относится к моментам, которые отличаются в QUIC и gQUIC. Не вижу смысла посвящать этому много времени, скажу только, что в версии, поданной на стандартизацию, компрессию заголовков сделали максимально похожей на компрессию в заголовков в HTTP/2. Подробнее можно прочитать здесь.
На сколько оно быстрее?
Это сложный вопрос. Дело в том, что пока у нас нет стандарта, особо нечего измерять. Пожалуй, единственные статистические данные, которыми мы располагаем — статистика Гугла, который использует gQUIC с 2013 года и в 2016 отчитался перед IETF, что около 90% трафика, идущего к их серверам от браузера Chrome, теперь использует QUIC. В этой же презентации они сообщают, что через gQUIC страницы загружаются примерно на 5% быстрее, а в потоковом видео на 30% меньше подвисаний по сравнению с TCP.
В 2017-м году группа исследователей во главе с Arash Molavi Kakhki опубликовала большую работу по изучению производительности gQUIC по сравнению с TCP.
Исследование выявило несколько слабых сторон gQUIC, таких как неустойчивость к перемешиванию сетевы х пакетов, жадность (unfairness) к пропускной способности канала и более медленная передача небольших (до 10 кб) объектов. Последнее, впрочем, удается компенсировать использованием 0-RTT. Во всех остальных исследованных кейсах gQUIC показал рост скорости по сравнению с TCP. О конкретных цифрах тут говорить сложно. Лучше почитать само исследование или короткий пост.
Здесь нужно сказать, что это данные именно о gQUIC, и они неактуальны для разрабатываемого стандарта. Что будет для QUIC: пока тайна за семью печатями, но есть надежда, что слабые стороны, выявленные у gQUIC, будут учтены и исправлены.
Немного будущности:, а что с HTTP/3?
А вот тут всё кристально ясно: API никак не изменится. Всё останется ровно так же, как и было в HTTP/2. Ну, а если API остаётся прежним, переход на HTTP/3 должен будет решаться использованием на бэкенде свежей версии библиотеки, поддерживающей транспорт по QUIC. Правда, довольно долго ещё придётся держать фоллбэк на старые версии HTTP, т.к. интернет сейчас не готов к полному переходу на UDP.
Кто уже поддерживает
Вот список существующих реализаций QUIC. Несмотря на отсутствие стандарта, список неплохой.
Ни один браузер сейчас не поддерживает QUIC в прод-релизе. Недавно была информация, что в Chrome включили поддержку HTTP/3, но пока только в Canary.
Из бэкендов HTTP/3 поддерживает только Caddy и Cloudflare, но пока экспериментально. NGINX в конце весны 2019-го объявили, что начали работу над поддержкой HTTP/3, но пока не закончили.
Какие есть проблемы
Мы с вами живём в реальном мире, где ни одна большая технология не может пройти в массы, не встретив сопротивления, и QUIC тут не исключение.
Самое важное, нужно как-то объяснить браузеру, что «https://» теперь не факт, что ведёт на 443-ий TCP-порт. Там вообще может не быть TCP. Для этого используется заголовок Alt-Svc. Он позволяет сообщить браузеру, что этот веб-сайт также доступен на таком-то протоколе по такому-то адресу. В теории это должно работать как часы, но на практике мы наткнёмся на то, что UDP может быть, например, запрещён на файрволе во избежание DDoS атак.
Но даже если UDP не запрещён, клиент может находиться за NAT-роутером, который настроен на удержание TCP-сессии по IP адресу, а т.к. мы используем UDP, в котором нет аппаратной сессии, NAT не будет удерживать соединение, и QUIC-сессия будет постоянно обрываться.
Все эти проблемы связаны с тем, что UDP раньше не использовался для передачи интернет-контента, и производители железок не могли предвидеть, что такое когда-то случится. Точно так же админы пока не очень понимают, как правильно настроить свои сети для работы QUIC. Эта ситуация будет потихоньку меняться, и, в любом случае, подобные изменения займут меньше времени, чем внедрение нового протокола транспортного уровня.
Кроме того, как уже было описано, QUIC сильно увеличивает использование процессора. Daniel Stenberg оценил рост по процессору до трёх раз.
Когда наступит HTTP/3
Стандарт хотят принять к Маю 2020 года, но, учитывая, что на текущий момент недоделанными остаются документы, запланированные на июль 2019, можно сказать, что дату скорее всего отодвинут.
Ну, а Гугл использует свою имплементацию gQUIC с 2013-го года. Если посмотреть HTTP-запрос, который отправляется гугловому поисковику, можно увидеть вот это: 
Выводы
QUIC сейчас выглядит как довольно сырая, но очень перспективная технология. Учитывая, что последние 20 лет все оптимизации протоколов транспортного уровня касались в основном TCP, QUIC, в большинстве случаев выигрывающий по производительности, выглядит уже сейчас крайне неплохо.
Однако пока ещё остаются нерешённые проблемы, с которыми предстоит справляться в ближайшие несколько лет. Процесс может затянуться из-за того, что вовлечено железо, которое никто не любит обновлять, но тем не менее все проблемы выглядят вполне решаемыми, и рано или поздно у всех нас будет HTTP/3.
Будущее не за горами!
