Бэкенд, машинное обучение и serverless — самое интересное с июльской конференции Хабра
Конференция Хабра — история не дебютная. Раньше мы проводили довольно крупные мероприятия Тостер на 300–400 человек, а сейчас решили, что актуальными будут небольшие тематические встречи, направление которых можете задавать и вы — например, в комментариях. Первая конференция такого формата прошла в июле и была посвящена бэкенд-разработке. Участники слушали доклады об особенностях перехода из бэкенда в ML и об устройстве сервиса «Квадрюпель» на портале «Госуслуги», а также приняли участие в круглом столе, посвященном Serverless. Тем, кто не смог посетить мероприятие лично, в этом посте мы рассказываем самое интересное.

Из бэкенд-разработки в машинное обучение
Чем занимаются дата-инженеры в ML? Чем сходны и чем отличаются задачи бэкенд-разработчика и ML-инженера? Какой путь нужно пройти, чтобы сменить первую профессию на вторую? Об этом рассказал Александр Паринов, который ушел в машинное обучение после 10 лет бэкенда.

Александр Паринов
Сегодня Александр работает архитектором систем компьютерного зрения в X5 Retail Group и контрибьютит в Open Source проекты, связанные с компьютерным зрением и глубоким обучением (github.com/creafz). Его скилы подтверждает участие в топ-100 мирового рейтинга Kaggle Master (kaggle.com/creafz) — самой популярной платформы, проводящей соревнования по машинному обучению.
Зачем переходить на машинное обучение
Полтора года назад Джефф Дин, главы Google Brain — проекта Google по исследованию искусственного интеллекта на основе глубокого обучения — рассказал, как полмиллиона строк кода в Google Translate заменили нейронной сетью на Tensor Flow, состоящей всего из 500 строк. После обучения сети качество данных выросло, а инфраструктура упростилась. Казалось бы, вот наше светлое будущее: больше не придется писать код, достаточно делать нейронки и закидывать их данными. Но на практике все гораздо сложнее.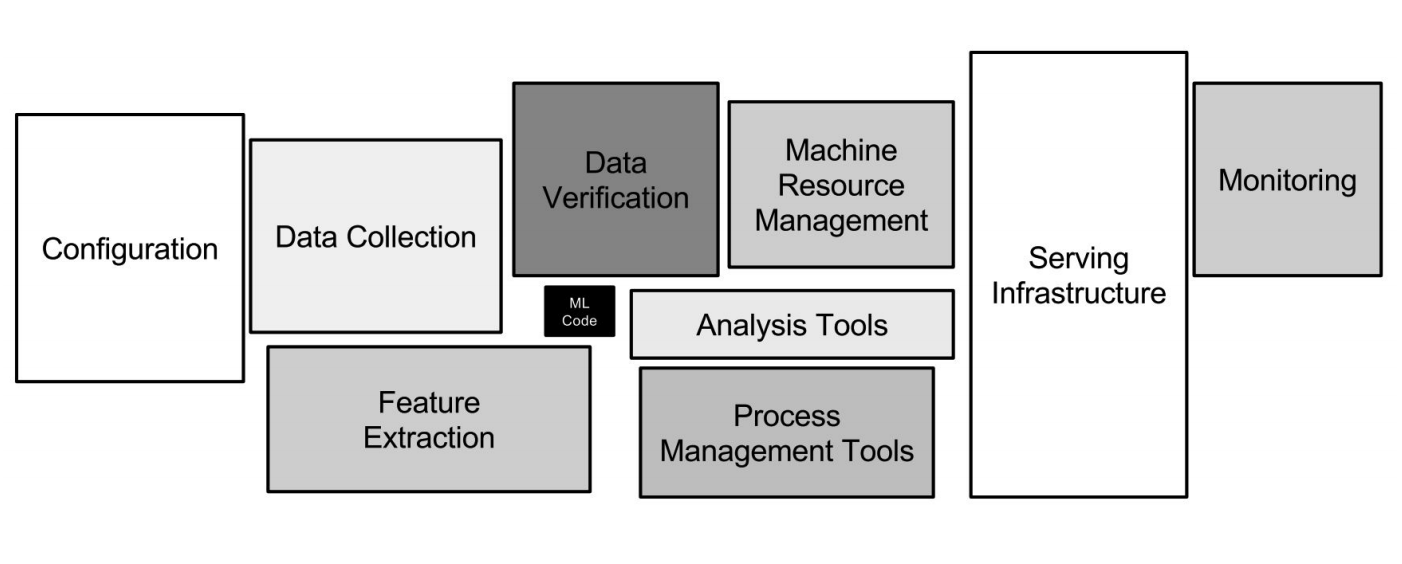 ML-инфраструктура в Google
ML-инфраструктура в Google
Нейронные сети — это лишь небольшая часть инфраструктуры (маленький черный квадратик на картинке выше). Требуется еще много вспомогательных систем, чтобы получать данные, обрабатывать их, хранить, проверять качество и т. д., нужна инфраструктура для обучения, развертывания кода машинного обучения в продакшене, тестирования этого кода. Все эти задачи как раз похожи на то, чем занимаются бэкенд-разработчики.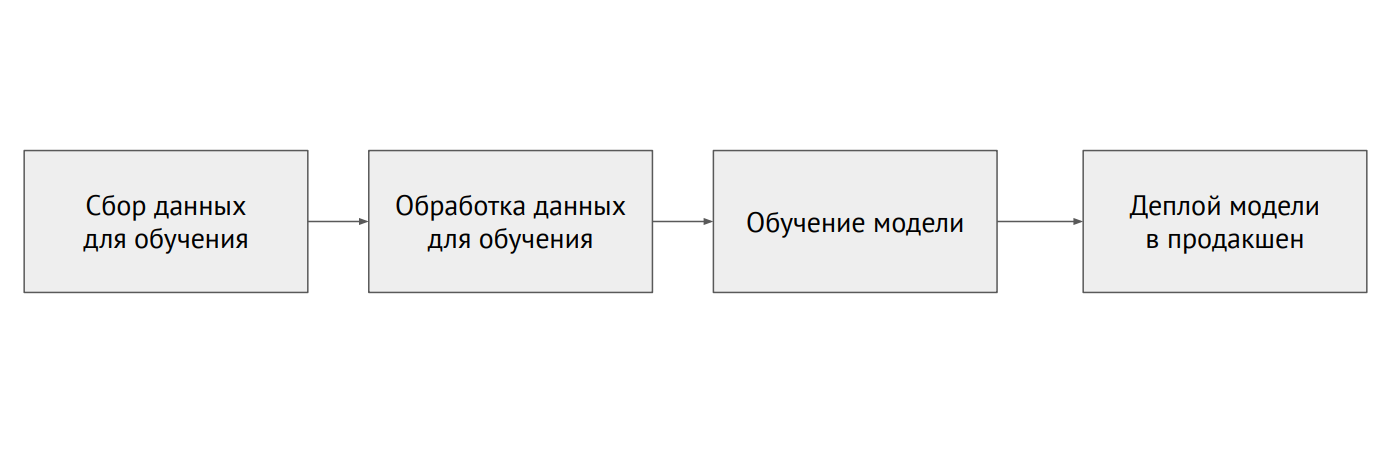 Процесс машинного обучения
Процесс машинного обучения
Чем отличается ML от бэкенда
В классическом программировании мы пишем код, и это диктует поведение программы. В ML у нас есть небольшой код модели и много данных, которыми мы закидываем модель. Данные в ML очень важны: одна и та же модель, обученная разными данными, может показывать совершенно разные результаты. Проблема заключается в том, что почти всегда данные разрозненны и лежат в разных системах (реляционные базы данных, NoSQL-базы, логи, файлы). Версионирование данных
Версионирование данных
ML требует версионирования не только кода, как в классической разработке, но и данных: необходимо четко понимать, на чем обучалась модель. Для этого можно пользоваться популярной библиотекой Data Science Version Control (dvc.org).

Разметка данных
Следующая задача — разметка данных. Например, отметить все предметы на картинке или сказать, к какому классу она принадлежит. Этим занимаются специальные сервисы наподобие «Яндекс.Толоки», работу с которыми сильно упрощает наличие API. Сложности возникают из-за «человеческого фактора»: повысить качество данных и свести ошибки к минимуму можно, поручая одно и то же задание нескольким исполнителям.
 Визуализация в Tensor Board
Визуализация в Tensor Board
Логирование экспериментов необходимо для сравнения результатов, выбора лучшей по каким-то метрикам модели. Для визуализации есть большой набор средств — например, Tensor Board. Но для хранения экспериментов каких-то идеальных способов нет. В маленьких компаниях зачастую обходятся excel-табличкой, в крупных используют специальные платформы для хранения результатов в БД.
 Платформ для машинного обучения множество, но ни одна из них не закрывает и 70% потребностей
Платформ для машинного обучения множество, но ни одна из них не закрывает и 70% потребностей
Первая проблема, с которой приходится сталкиваться при выводе обученной модели в продакшн, связана с любимым инструментом дата-сайентистов — Jupyter Notebook. В нем нет модулярности, то есть на выходе получается такая «портянка» кода, не разбитого на логические куски — модули. Все перемешано: классы, функции, конфигурации и т. д. Этот код трудно версионировать и тестировать.
Как с этим бороться? Можно смириться, как Netflix, и создать свою платформу, позволяющую прямо в продакшене запускать эти ноутбуки, передавать им на вход данные и получать результат. Можно заставить разработчиков, которые катят модель в продакшн, переписать код нормально, разбить на модули. Но при таком подходе легко ошибиться, и модель будет работать не так, как задумывалось. Поэтому идеальный вариант — запретить использовать Jupyter Notebook для кода моделей. Если, разумеется, дата-сайентисты на это согласятся.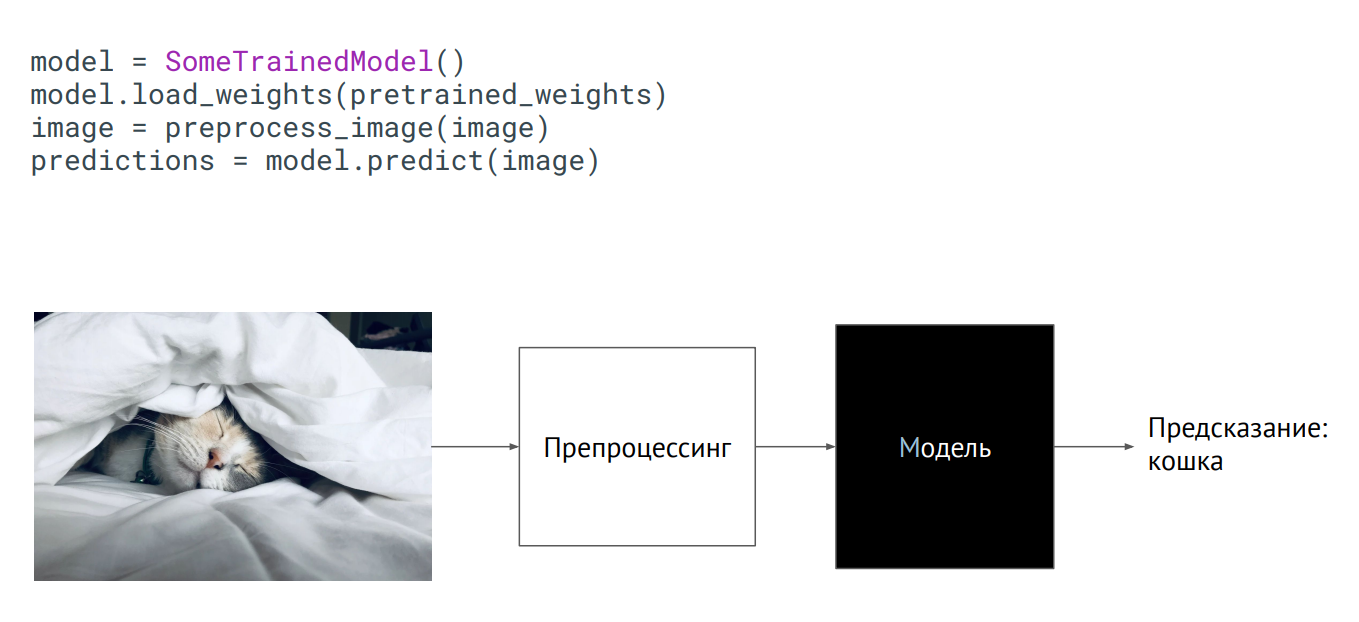 Модель как черный ящик
Модель как черный ящик
Самый простой способ вывести модель в продакшн — использовать ее как черный ящик. У вас есть какой-то класс модели, вам передали веса модели (параметры нейронов обученной сети), и если вы этот класс инициализируете (вызовите метод predict, подадите на него картинку), то на выходе получите некое предсказание. Что происходит внутри — не имеет значения.
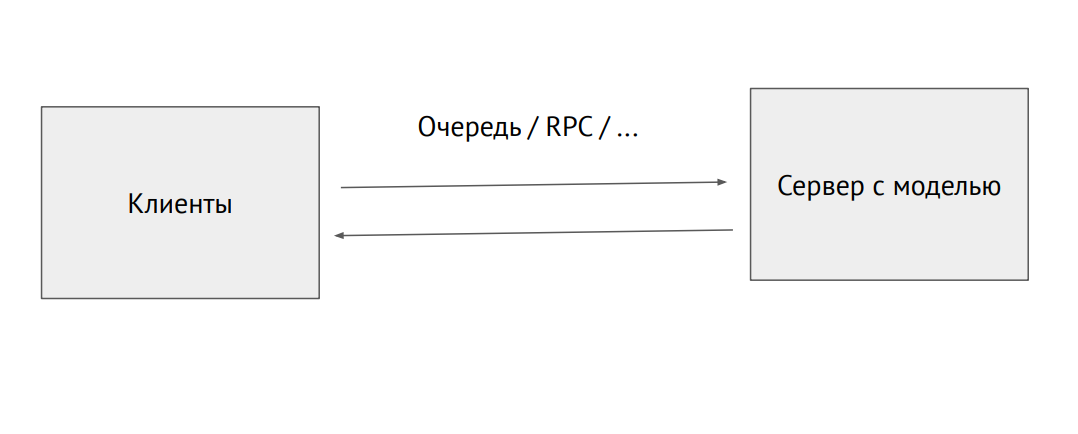
Отдельный процесс-сервер с моделью
Можно также поднять некий отдельный процесс и засылать его через очередь RPC (с картинками или другими исходными данными. На выходе мы будем получать предикты.
Пример использования модели во Flask:
@app.route("/predict", methods=["POST"])
def predict():
image = flask.request.files["image"].read()
image = preprocess_image(image)
predictions = model.predict(image)
return jsonify_prediction(predictions)
Проблема такого подхода — ограничение производительности. Допустим, у нас есть код на Phyton, написанный дата-сайентистами, который тормозит, а мы хотим выжать максимальную производительность. Для этого можно использовать инструменты, которые преобразовывают код в нативный или конвертируют его в другой фреймворк, заточенный под продакшн. Такие инструменты есть для каждого фреймворка, но идеальных не существует, придется допиливать самостоятельно.
Инфраструктура в ML такая же, как в обычном бэкенде. Есть Docker и Kubernetes, только для Docker нужно поставить рантайм от NVIDIA, который позволяет процессам внутри контейнера получить доступ к видеокартам в хосте. Для Kubernetes нужен плагин, чтобы он мог менеджить серверы с видеокартами.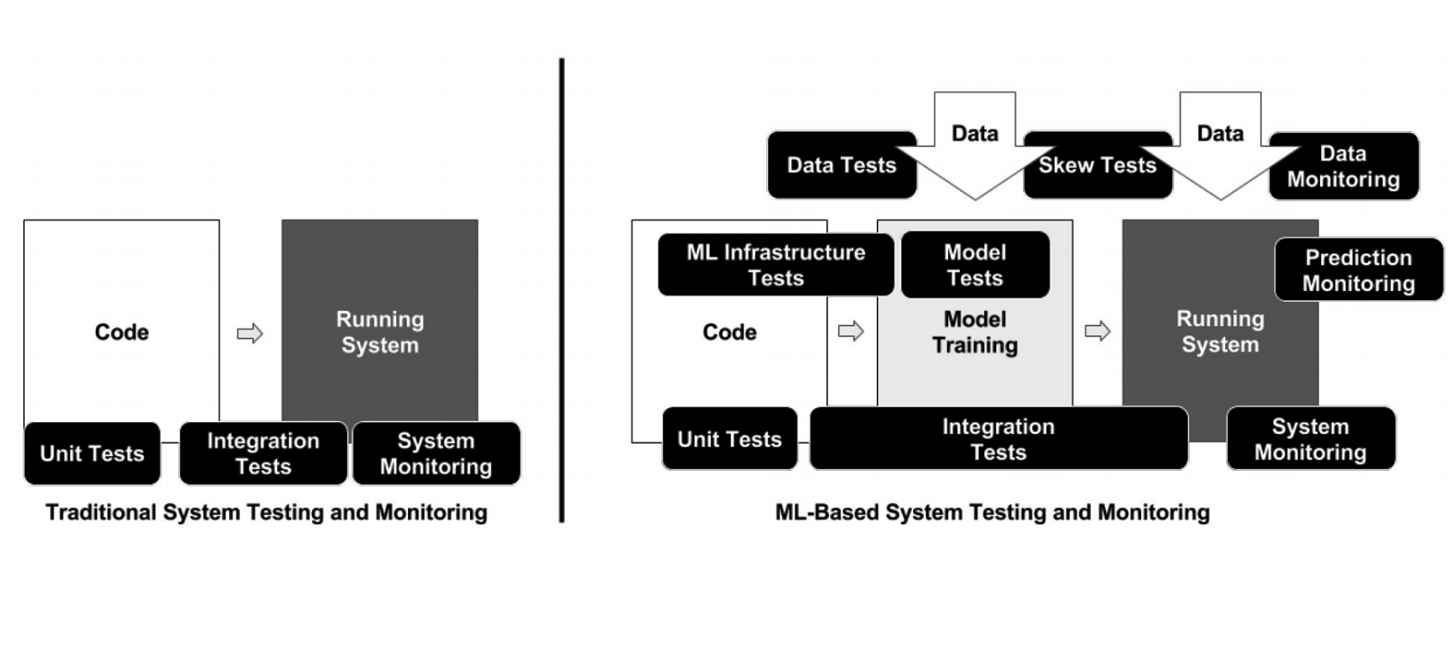
В отличие от классического программирования, в случае с ML в инфраструктуре появляется много разных подвижных элементов, которые нужно проверять и тестировать — например, код обработки данных, пайплайн обучения модели и продакшн (см. схему выше). Важно протестировать код, связывающий разные куски пайплайнов: кусков много, и проблемы очень часто возникают на границах модулей.
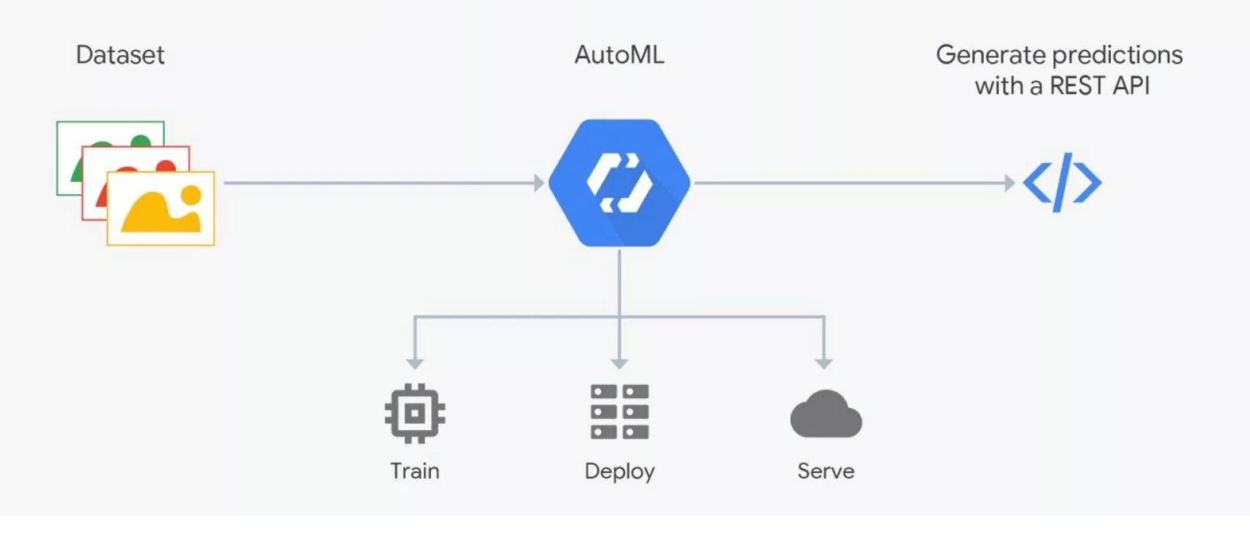
Как работает AutoML
Сервисы AutoML обещают подобрать оптимальную для ваших целей модель и обучить ее. Но нужно понимать: в ML очень важны данные, результат зависит от их подготовки. Разметкой занимаются люди, что чревато ошибками. Без жесткого контроля может получиться мусор, а автоматизировать процесс пока не выходит, нужна проверка со стороны специалистов — дата-сайентистов. Вот на этом месте и «ломается» AutoML. Но он может быть полезен для подбора архитектуры — когда вы уже подготовили данные и хотите провести серию экспериментов для поиска лучшей модели.
Как попасть в машинное обучение
Попасть в ML проще всего, если вы разрабатываете на Python, который используется во всех фреймворках для глубокого обучения (и обычных фреймворках). Этот язык практически обязателен для данной сферы деятельности. С++ применяется для некоторых задач с компьютерным зрением — например, в системах управления беспилотными автомобилями. JavaScript и Shell — для визуализации и таких странных вещей, как запуск нейронки в браузере. Java и Scala используется при работе с Big Data и для машинного обучения. R и Julia любят люди, которые занимаются матстатистикой.
Получать практический опыт для начала удобнее всего на Kaggle, участие в одном из конкурсов платформы дает больше, чем год изучения теории. На этой платформе вы можете взять чей-то выложенный и прокомментированный код и попытаться его улучшить, оптимизировать под свои цели. Бонус — ранг на Kaggle влияет на вашу зарплату.
Другой вариант — пойти бэкенд-разработчиком в ML-команду. Сейчас много стартапов, занимающихся машинным обучением, в которых вы наберетесь опыта, помогая коллегам в решении их задач. Наконец, можно вступить в одно из сообществ дата-сайентистов — Open Data Science (ods.ai) и другие.
Дополнительную информацию по теме докладчик разместил по ссылке https://bit.ly/backend-to-ml
«Квадрюпель» — сервис таргетированных уведомлений портала «Госуслуги»
 Евгений Смирнов
Евгений Смирнов
Следующим выступал начальник отдела разработки инфраструктуры электронного правительства Евгений Смирнов, который рассказал о «Квадрюпеле». Это сервис таргетированных уведомлений портала «Госуслуги» (gosuslugi.ru) — самого посещаемого государственного ресурса Рунета. Дневная аудитория составляет 2,6 млн, всего же на сайте зарегистрировано 90 млн пользователей, из них 60 млн — подтвержденные. Нагрузка на API портала — 30 тыс. RPS.
 Технологии, которые используются в бэкенде «Госуслуг»
Технологии, которые используются в бэкенде «Госуслуг»
«Квадрюпель» — сервис адресного оповещения, с помощью которого пользователь получает предложение об услуге в наиболее подходящий для него момент путем настройки специальных правил информирования. Основными требованиями при разработке сервиса были гибкие настройки и адекватное время на рассылки.
Как работает Квадрюпель

На схеме выше показано одно из правил работы «Квадрюпеля» на примере ситуации с необходимостью замены водительских прав. Сначала сервис ищет пользователей, у которых срок годности кончается через месяц. Им выставляется баннер с предложением получить соответствующую услугу и отправляется сообщение на электронную почту. Для тех пользователей, у которых срок уже истек, баннер и email меняются. После успешного обмена прав пользователь получает другие уведомления — с предложением обновить данные в удостоверении.
С технической точки зрения это groovy-скрипты, в которых написан код. На входе — данные, на выходе — true/false, совпало/не совпало. Всего более 50 правил — от определения дня рождения пользователя (текущая дата равна дате рождения пользователя) до сложных ситуаций. Ежедневно по этим правилам определяется около миллиона совпадений — людей, которых нужно оповестить.
 Каналы уведомлений «Квадрюпеля»
Каналы уведомлений «Квадрюпеля»
Под капотом «Квадрюпеля» находится БД, в которой хранятся данные пользователей, и три приложения:
- Worker предназначен для обновления данных.
- Rest API забирает и отдает на портал и на мобильное приложение сами баннеры.
- Scheduler запускает работы по пересчету баннеров или массовой рассылки.
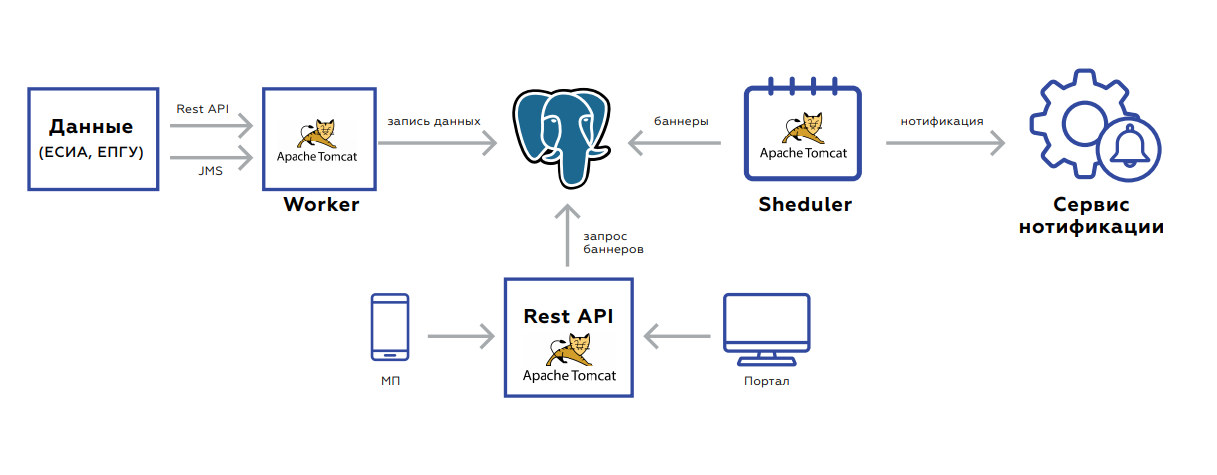
Для обновления данных бэкенд событийно ориентирован. Два интерфейса — рест или JMS. Событий много, перед сохранением и обработкой они агрегируются, чтобы не делать лишних запросов. Сама БД, табличка, в которой хранятся данные, выглядит как key value хранилище — ключ пользователя и само значение: флажки, обозначающие наличие или отсутствие соответствующих документов, их срок действия, агрегированная статистика по заказу услуг этим пользователем и прочее.

После сохранения данных ставится задача в JMS, чтобы немедленно пересчитались баннеры — это нужно сразу отображать на вебе. Система запускается по ночам: в JMS накидываются задачи с интервалами пользователей, по которым надо пересчитать правила. Это подхватывают обработчики, занятые пересчетом. Далее результаты обработки попадают в следующую очередь, которая либо сохраняет баннеры в БД, либо отправляет в сервис задачи на нотификацию пользователя. Процесс занимает 5–7 часов, он легко масштабируется за счет того, что можно всегда либо докинуть обработчиков, либо поднять инстансы с новыми обработчиками.

Сервис работает достаточно хорошо. Но объем данных растет, поскольку пользователей становится больше. Это приводит к увеличению нагрузки на базу — даже с учетом того, что Rest API смотрит в реплику. Второй момент — JMS, который, как выяснилось, не очень подходит из-за большого потребления памяти. Высок риск переполнения очереди с падением JMS и остановкой обработки. Поднять JMS после этого без очистки логов невозможно.
Решать проблемы планируется при помощи шардирования, что позволит балансировать нагрузку на базу. Также в планах сменить схему хранения данных, а JMS поменять на Kafka — более отказоустойчивое решение, которое урегулирует проблемы с памятью.
Backend-as-a-Service Vs. Serverless

Слева направо: Александр Боргарт, Андрей Томиленко, Николай Марков, Ара Исраелян
Бэкенд как сервис или Serverless-решение? В обсуждении этого актуального вопроса на круглом столе участвовали:
- Ара Исраелян, технический директор CTO и основатель Scorocode.
- Николай Марков, Senior Data Engineer в компании Aligned Research Group.
- Андрей Томиленко, руководитель отдела разработки RUVDS.
Модератором беседы стал старший разработчик Александр Боргарт. Мы приводим дебаты, в которых участвовали и слушатели, в сокращенном варианте.
— Что такое Serverless в вашем понимании?
Андрей: Это модель вычислений — Lambda-функция, которая должна обрабатывать данные так, чтобы результат зависел только от данных. Термин пошел то ли от Гугла, то ли от Амазона и его сервиса AWS Lambda. Провайдеру проще обрабатывать такую функцию, выделив под это пул мощностей. Разные пользователи могут независимо считаться на одних и тех же серверах.
Николай: Если просто — мы переносим какую-то часть своей IT-инфраструктуры, бизнес-логики в облако, на аутсорс.
Ара: Со стороны разработчиков — неплохая попытка сэкономить ресурсы, со стороны маркетологов — заработать побольше денег.
— Serverless — то же, что и микросервисы?
Николай: Нет, Serverless — это больше организация архитектуры. Микросервис — атомарная единица некоей логики. Serverless — подход, а не «отдельная сущность».
Ара: Функцию Serverless можно упаковать в микросервис, но от этого она перестанет быть Serverless, перестанет быть Lambda-функцией. В Serverless работа функции начинается только в тот момент, когда ее запрашивают.
Андрей: Они отличаются временем жизни. Lambda-функцию мы запустили и забыли. Она отработала пару секунд, и следующий клиент может обработать свой запрос на другой физической машине.
— Что лучше масштабируется?
Ара: При горизонтальном масштабировании Lambda-функции ведут себя абсолютно так же, как микросервисы.
Николай: Какое задашь количество реплик — столько их и будет, нет никаких проблем с масштабированием у Serverless. В Kubernetes сделал реплика-сет, запустил 20 инстансов «где-нибудь», и тебе вернулось 20 обезличенных ссылок. Вперед!
— Можно ли писать бэкенд на Serverless?
Андрей: Теоретически, но смысла в этом нет. Lambda-функции будут упираться в единое хранилище — нам же нужно обеспечить гарантированность. Например, если пользователь провел некую транзакцию, то при следующем обращении он должен увидеть: транзакция проведена, средства зачислены. Все Lambda-функции будут блокироваться на этом вызове. По факту куча Serverless-функций превратится в единый сервис с одной узкой точкой обращения к базе данных.
— В каких ситуациях есть смысл применения бессерверной архитектуры?
Андрей: Задачи, в которых не требуется общее хранилище — тот же майнинг, блокчейн. Там, где нужно много считать. Если у вас куча вычислительных мощностей, то вы можете определить функцию типа «посчитай хэш чего-то там…» Но вы можете решить проблему с хранением данных, взяв, например, от Амазона и Lambda-функции, и их распределенное хранилище. И получится, что вы пишете обычный сервис. Lambda-функции будут обращаться к хранилищу и выдавать какой-то ответ пользователю.
Николай: Контейнерчики, которые запускаются в Serverless, крайне ограничены по ресурсам. Там мало памяти и всего остального. Но если у вас вся инфраструктура развернута полностью на каком-то облаке — Гугл, Амазон — и у вас с ними постоянный контракт, есть бюджет на все это, тогда для каких-то задач можно использовать Serverless-контейнеры. Необходимо находиться именно внутри этой инфраструктуры, потому что все заточено под использование в конкретном окружении. То есть если вы готовы завязать все на инфраструктуру облака — можете поэкспериментировать. Плюс в том, что не придется менеджить эту инфраструктуру.
Ара: Что Serverless не требует от вас менеджить Kubernetes, Docker, ставить Kafka и так далее — это самообман. Те же Амазон и Гугл это менеджат и ставят. Другое дело, что у вас есть SLA. С тем же успехом можно отдать все на аутсорсинг, а не программировать самостоятельно.
Андрей: Сам Serverless недорогой, но приходится много платить за остальные амазоновские сервисы — например, базу данных. С ними народ уже судился, за то, что они драли бешеные деньги за API gate.
Ара: Если говорить о деньгах, то нужно учитывать такой момент: вам придется развернуть на 180 градусов всю методологию разработки в компании, чтобы перевести весь код на Serverless. На это уйдет много времени и средств.
— Есть ли достойные альтернативы платным Serverless Амазона и Гугла?
Николай: В Kubernetes вы запускаете какой-то job, он отрабатывает и умирает — это вполне себе Serverless с точки зрения архитектуры. Если хочется реально интересную бизнес-логику создать с очередями, с базами, то нужно чуть больше над этим подумать. Это все решается, не выходя из Kubernetes. Тащить дополнительную реализацию я бы не стал.
— Насколько важно мониторить то, что происходит в Serverless?
Ара: Зависит от архитектуры системы и требований бизнеса. По сути, провайдер должен предоставлять отчетность, которая поможет девопсу разобраться в возможных проблемах.
Николай: В Амазоне есть CloudWatch, куда стримятся все логи, в том числе и с Lambda. Интегрируйте пересылку логов и используйте какой-то отдельный инструмент для просмотра, алертинга и так далее. В контейнеры, которые вы стартуете, можно напихать агентов.

— Давайте подведем итог.
Андрей: Думать о Lambda-функциях полезно. Если вы создаете сервис на коленке — не микросервис, а такой, который пишет запрос, обращается к БД и присылает ответ — Lambda-функция решает целый ряд проблем: с многопоточностью, масштабируемостью и прочим. Если у вас логика построена подобным образом, то в будущем вы сможете эти Lambda перенести в микросервисы или воспользоваться сторонними сервисами наподобие Амазона. Технология полезная, идея интересная. Насколько она оправдана для бизнеса — это пока открытый вопрос.
Николай: Serverless лучше применять для operation-задач, чем для расчета некоей бизнес-логики. Я всегда воспринимаю это как event processing. Если у вас в Амазоне он есть, если вы в Kubernetes — да. Иначе вам придется довольно много усилий приложить, чтобы поднять Serverless самостоятельно. Необходимо смотреть конкретный бизнес-кейс. Например, у меня сейчас одна из задач: когда появляются файлы на диске в определенном формате — нужно их заливать в Kafka. Я это могу использовать WatchDog или Lambda. С точки зрения логики подходят оба варианта, но по реализации Serverless сложнее, и я предпочитаю более простой путь, без Lambda.
Ара: Serverless — идея интересная, применимая, очень технически красивая. Рано или поздно технологии дойдут до того, что любая функция будет подниматься меньше, чем за 100 миллисекунд. Тогда в принципе отпадет вопрос о том, критично ли для пользователя время ожидания. При этом применимость Serverless, как уже говорили коллеги, полностью зависит от бизнес-задачи.
Мы благодарим наших спонсоров, которые нам очень помогли:
- Пространство IT- конференций «Весна» за площадку для конференции.
- Календарь IT-мероприятий Runet-ID и издание «Интернет в цифрах» за информационную поддержку и новости.
- «Акронис» за подарки.
- Avito за сотворчество.
- «Ассоциацию электронных коммуникаций» РАЭК за вовлеченность и опыт.
- Главного спонсора RUVDS — за все!

