Хранение метрик: как мы перешли с Graphite+Whisper на Graphite+ClickHouse
Всем привет! В своей прошлой статье я писал об организации модульной системы мониторинга для микросервисной архитектуры. Ничего не стоит на месте, наш проект постоянно растёт, и количество хранимых метрик — тоже. Как мы организовали этот переход в условиях высоких нагрузок, об ожиданиях от него и результатах миграции читайте под катом.

Прежде чем я расскажу, как мы организовали переход от хранения метрик в Graphite+Whisper на Graphite+ClickHouse, хотелось бы дать информацию о причинах принятия подобного решения и о тех минусах Whisper, с которыми мы жили в течение продолжительного времени.
Проблемы Graphite+Whisper
1. Высокая нагрузка на дисковую подсистему.
На момент перехода к нам прилетало примерно 1.5 млн метрик в минуту. С таким потоком дисковая утилизация на серверах была равна ~30%. В целом это было вполне приемлемо — все работало стабильно, быстро писалось, быстро читалось… До того момента, пока одна из команд разработки не выкатила новую фичу и не стала отправлять нам 10 млн метрик в минуту. Вот тогда-то дисковая подсистема поднапряглась, и мы увидели 100% утилизации. Проблему удалось быстро решить, но осадочек остался.
2. Отсутствие репликации и консистентности.
Скорее всего как и все, кто использует/использовал Graphite+Whisper, мы лили одинаковый поток метрик сразу на несколько серверов Graphite с целью создания отказоустойчивости. И с этим особых проблем не было — до момента, когда один из серверов по какой-либо причине не падал. Иногда мы успевали поднять упавший сервер достаточно быстро, и carbon-c-relay успевал заливать в него метрики из своего кэша, а иногда нет. И тогда в метриках была дыра, которую мы затягивали rsync`ом. Процедура была достаточно долгой. Спасало только то, что происходило подобное очень редко. Также мы периодически брали рандомный набор метрик и сравнивали их другими такими же на соседних нодах кластера. Примерно в 5% случаев несколько значений различались, что нас не очень радовало.
3. Большой объем занимаемого места.
Так как мы пишем в Graphite не только инфраструктурные, но и бизнес-метрики (а теперь ещё и метрики из Kubernetes), то довольно часто получаем ситуацию, при которой в метрике присутствуют только несколько значений, а .wsp-файл создается с учетом всего retention периода, и занимает предвыделенный объем места, который у нас был равен ~2Мб. Проблема усугубляется ещё и тем, что подобных файлов со временем появляется очень много, и при построении отчетов по ним на чтение пустых точек уходит много времени и ресурсов.
Сразу хотелось бы отметить что с проблемами, описанными выше, можно бороться различными методами и с разной степенью эффективности, но чем больше к вам начинает поступать данных, тем сильнее они обостряются.
Имея все вышеперечисленное (с учетом предыдущей статьи), а также постоянный рост количества получаемых метрик, желание перевести все метрики к интервалу хранения в 30 сек. (при необходимости — до 10 сек.), мы решили попробовать Graphite+ClickHouse в качестве перспективной альтернативы Whisper.
Graphite+ClickHouse. Ожидания
Посетив несколько митапов ребят из Яндекса, прочитав пару статей на хабре, прошерстив документацию и найдя вменяемые компоненты для обвязки ClickHouse под Graphite, мы решили действовать!
Хотелось получить следующее:
- снизить утилизацию дисковой подсистемы с 30% до 5%;
- снизить объем занимаемого места с 1Тб до 100Гб;
- иметь возможность принимать по 100 млн метрик в минуту в сервер;
- репликацию данных и отказоустойчивость из коробки;
- не сидеть над этим проектом год и сделать переход за какой-то вменяемый срок;
- переключиться без даунтайма.
Достаточно амбициозно, правда?
Graphite+ClickHouse. Компоненты
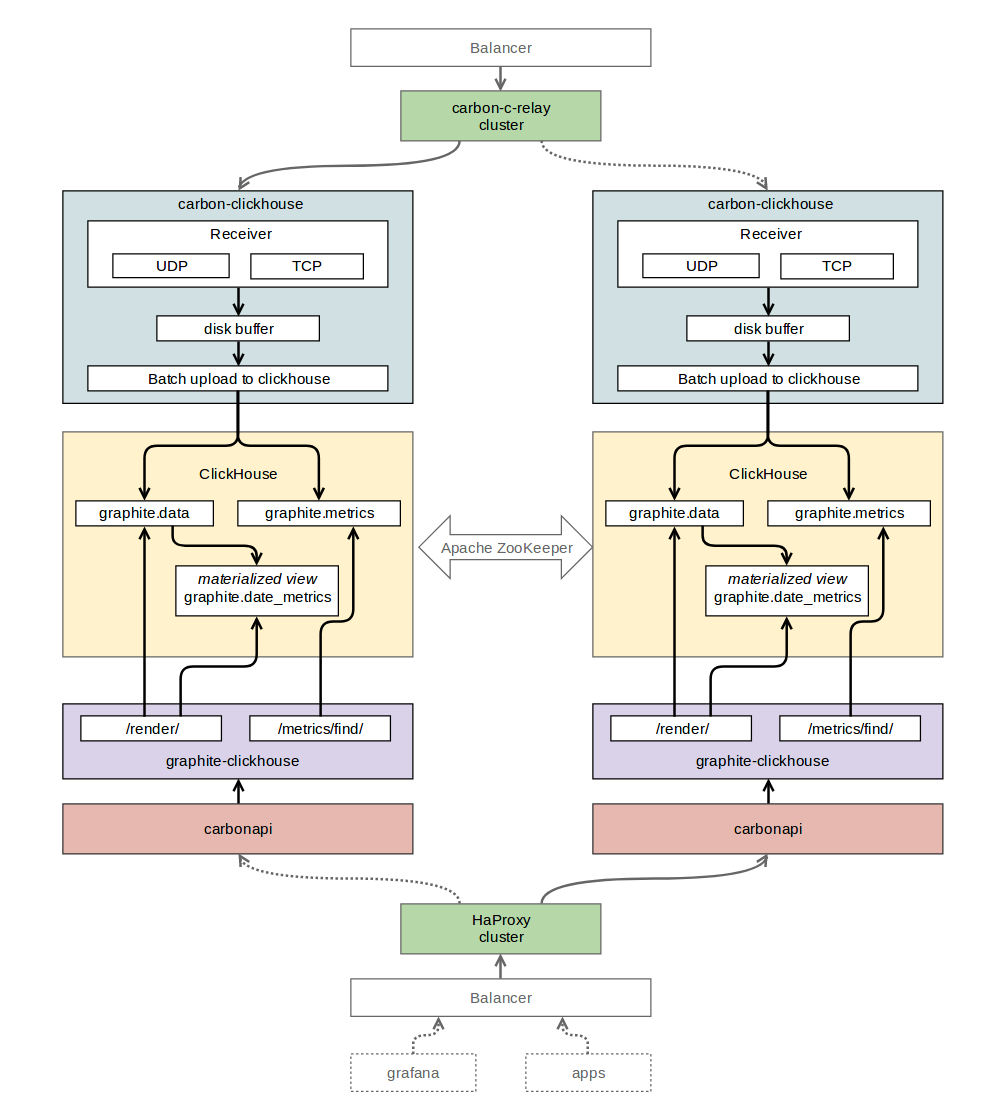
Для получения данных по протоколу Graphite и последующей записи их в ClickHouse, был выбран carbon-clickhouse (golang).
В качестве базы данных для хранения временных рядов был выбран последний на тот момент релиз ClickHouse стабильной версии 1.1.54253. При работе с ним были проблемы: в логи сыпало гору ошибок, и было не совсем понятно что с ними делать. В обсуждении с Романом Ломоносовым (автор carbon-clickhouse, graphite-clickhouse и еще много-много чего) был выбран более старый релиз 1.1.54236. Ошибки пропали — все стало работать на ура.
Для чтения данных из ClickHouse был выбран graphite-сlickhouse (golang). В качестве API-интерфейса для Graphite — carbonapi (golang). Для организации репликации между таблицами ClickHouse был использован zookeeper. Для маршрутизации метрик мы оставили нами горячо любимый carbon-c-relay © (см. прошлую статью).
Graphite+ClickHouse. Структура таблиц
«graphite» — база данных, созданная нами для таблиц мониторинга.
«graphite.metrics» — таблица с движком ReplicatedReplacingMergeTree (реплицируемый ReplacingMergeTree). В данной таблице хранятся имена метрик и пути до них.
CREATE TABLE graphite.metrics ( Date Date, Level UInt32, Path String, Deleted UInt8, Version UInt32 ) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicator/graphite.metrics', ‘r1’, Date, (Level, Path), 8192, Version);«graphite.data» — таблица с движком ReplicatedGraphiteMergeTree (реплицируемый GraphiteMergeTree). В данной таблице хранятся значения метрик.
CREATE TABLE graphite.data ( Path String, Value Float64, Time UInt32, Date Date, Timestamp UInt32 ) ENGINE = ReplicatedGraphiteMergeTree('/clickhouse/tables/replicator/graphite.data', 'r1', Date, (Path, Time), 8192, 'graphite_rollup')«graphite.date_metrics» — таблица, заполняемая по условию, с движком ReplicatedReplacingMergeTree. В эту таблицу записываются имена всех метрики, которые встретились за сутки. Причины создания описаны в разделе «Проблемы» в конце этой статьи.
CREATE MATERIALIZED VIEW graphite.date_metrics ( Path String, Level UInt32, Date Date) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicator/graphite.date_metrics', 'r1', Date, (Level, Path, Date), 8192) AS SELECT toUInt32(length(splitByChar('.', Path))) AS Level, Date, Path FROM graphite.data«graphite.data_stat» — таблица, заполняемая по условию, с движком ReplicatedAggregatingMergeTree (реплицируемый AggregatingMergeTree). В эту таблицу записывается количество входящих метрик, с разбивкой до 4 уровня вложенности.
CREATE MATERIALIZED VIEW graphite.data_stat ( Date Date, Prefix String, Timestamp UInt32, Count AggregateFunction(count)) ENGINE = ReplicatedAggregatingMergeTree('/clickhouse/tables/replicator/graphite.data_stat', 'r1', Date, (Timestamp, Prefix), 8192) AS SELECT toStartOfMonth(now()) AS Date, replaceRegexpOne(Path, '^([^.]+\\.[^.]+\\.[^.]+).*$', '\\1') AS Prefix, toUInt32(toStartOfMinute(toDateTime(Timestamp))) AS Timestamp, countState() AS Count FROM graphite.data GROUP BY Timestamp, Prefix
Graphite+ClickHouse. Схема взаимодействия компонентов
Graphite+ClickHouse. Миграция данных
Как мы помним из ожиданий от данного проекта, переход на ClickHouse должен быть без даунтаймов, соответственно, мы должны были каким-то образом переключить всю нашу систему мониторинга на новое хранилище максимально прозрачно для наших пользователей.
Сделали мы это так.
В carbon-c-relay добавили правило отправлять дополнительный поток метрик в carbon-clickhouse одного из серверов, участвующих в репликации ClickHouse таблиц.
Написали небольшой скрипт на python, который с помощью библиотеки whisper-dump вычитывал все .wsp-файлы из нашего хранилища и отправлял эти данные в вышеописанный carbon-clickhouse в 24 потока. Количество принимаемых значений метрик в carbon-clickhouse, достигало в 125 млн/мин., и ClickHouse даже не вспотел.
Создали отдельный DataSource в Grafana с целью отладки функций, использующихся в существующих дашбордах. Выявили список функций, которые мы использовали, но они не были реализованы в carbonapi. Дописали эти функции, и отправили PR`ы авторам carbonapi (отдельное им спасибо).
- Для переключения читающей нагрузки в настройках балансировщиков изменили эндпоинты с graphite-api (API интерфейс для Graphite+Whisper) на carbonapi.
Graphite+ClickHouse. Результаты
снизили утилизацию дисковой подсистемы с 30% до 1%;
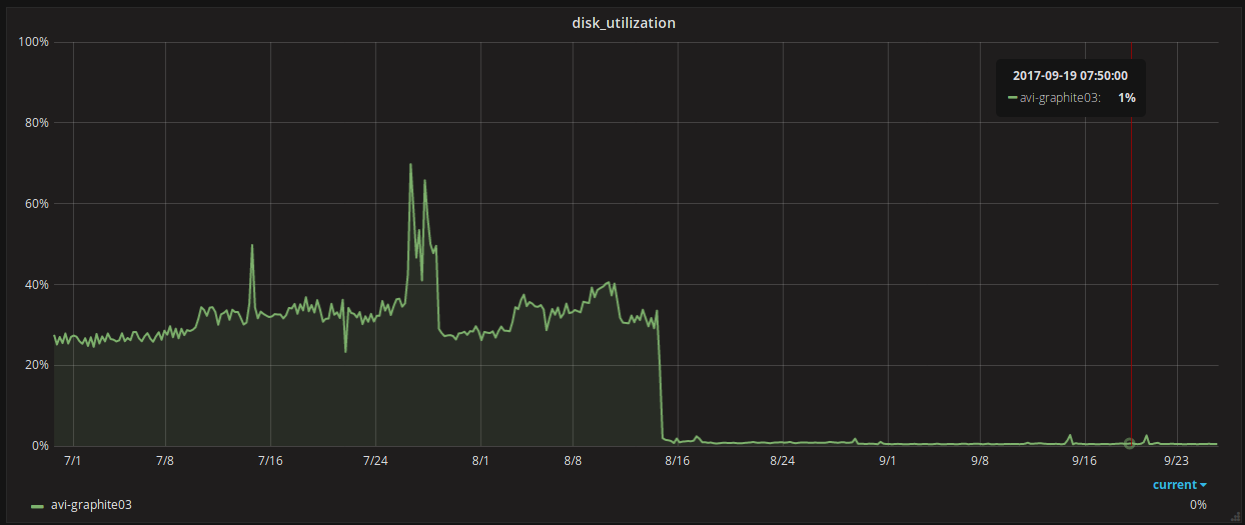
- снизили объем занимаемого места с 1 Тб до 300 Гб;
- имеем возможность принимать по 125 млн метрик в минуту в сервер (пики в момент миграции);
- перевели все метрики на тридцатисекундный интервал хранения;
- получили репликацию данных и отказоустойчивость;
- переключились без даунтайма;
- на все потратили примерно 7 недель.
Graphite+ClickHouse. Проблемы
В нашем случае не обошлось и без подводных камней. Вот с чем мы столкнулись после перехода.
- ClickHouse не всегда перечитывает конфиги на лету, иногда его надо перезагружать. К примеру, в случае с описанием кластера zookeeper в конфиге ClickHouse — он не применялся до перезагрузки clickhouse-server.
- Не проходили большие запросы ClickHouse, поэтому у нас в graphite-clickhouse строка подключения к ClickHouse выглядит вот так:
url = "http://localhost:8123/?max_query_size=268435456&max_ast_elements=1000000" - В ClickHouse довольно часто выходят новые версии стабильных релизов, в них могут встретиться сюрпризы: будьте внимательны.
- Динамически создаваемые контейнеры в kubernetes отправляют большое количество метрик с коротким и случайным периодом жизни. Точек по таким метрикам не много, и проблем с местом нет. Но вот при построении запросов ClickHouse поднимает огромное количество этих самых метрик из таблицы «metrics». В 90% случаев данные по ним за окно (24 часа) отсутствуют. А вот время на поиск этих данных в таблице «data» затрачивается, и в конечном счете упирается в таймаут. Для того, чтобы решить эту проблему, мы стали вести отдельную вьюшку с информацией по метрикам, которые встретились за сутки. Таким образом, при построении отчетов (графиков) по динамически создаваемым контейнерам, мы опрашиваем только те метрики, которые встречались в пределах заданного окна, а не за всё время, что в разы ускорило построение отчетов по ним.
Для вышеописанного решения был собран graphite-clickhouse (fork), включающий реализацию работы с таблицей date_metrics.
Graphite+ClickHouse. Теги
С версии 1.1.0 Graphite стал официально поддерживать теги. И мы активно думаем над тем, что и как надо сделать чтобы поддержать эту инициативу в стеке graphite+clickhouse.
Graphite+ClickHouse. Детектор аномалий
На базе описанной выше инфраструктуры, мы реализовали прототип детектора аномалий, и он работает! Но о нем — в следующей статье.
Подписывайтесь, жмите стрелку вверх и будьте счастливы!
