Hashicorp Vault — собираем непрямую репликацию через ведро
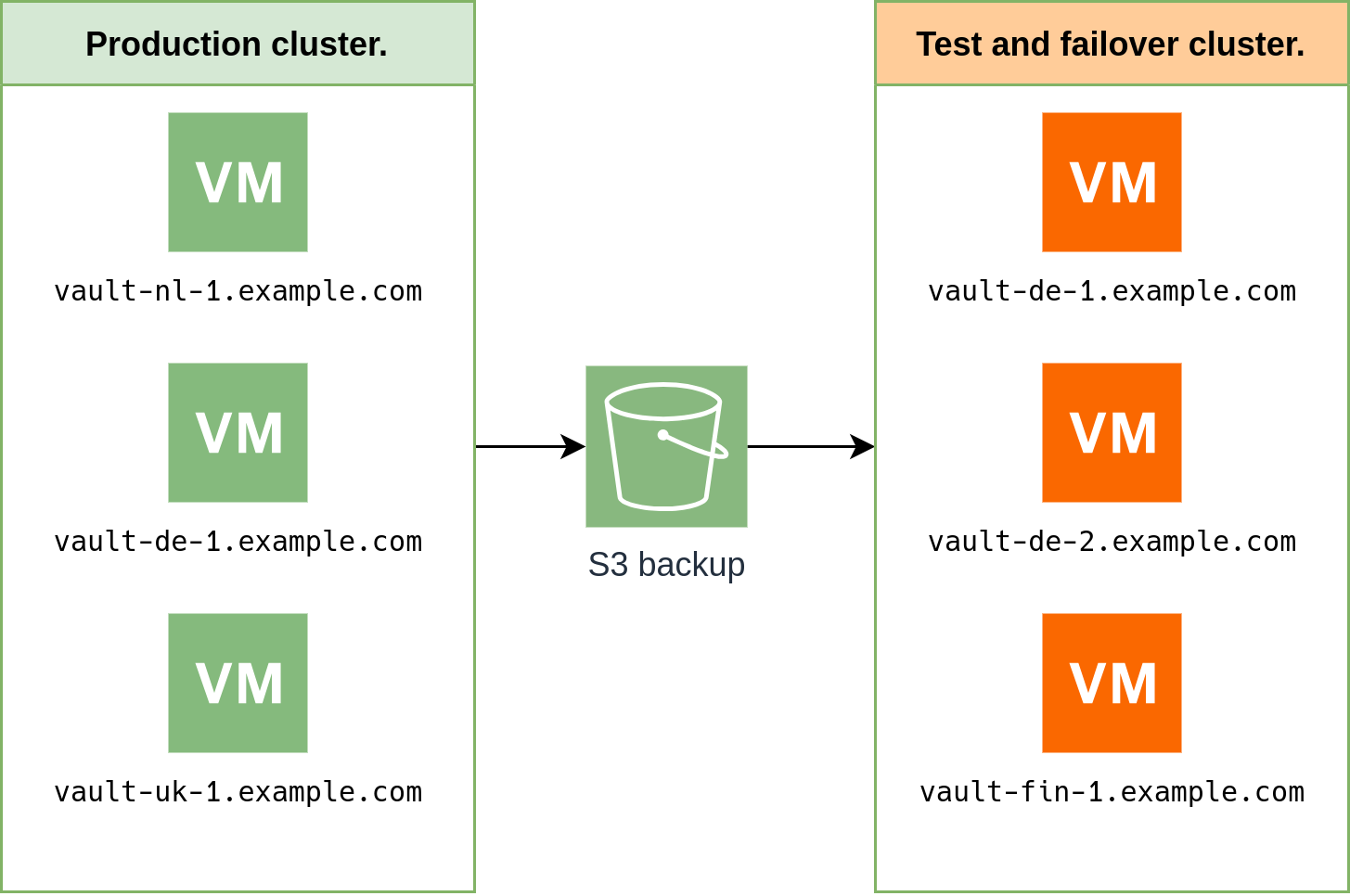
Будем делать непрямую репликацию через ведро
Hashicorp Vault — прекрасный продукт для централизованного хранения всех паролей и других секретов компании. При этом, многие знают, что удобная ключница — это идеальный способ потерять все ключи одновременно. Когда я работал в крупном телекоме, то DRP-протоколы с восстановлением данных учитывали даже запрет на сбор более двух Хранителей Ключей в одном месте. Чисто на случай очень неудачного корпоратива с совместным полетом на воздушном шаре, дегустацией домашних грибов или другими подобными факторами. Короче, если вы внедряете подобную систему, то вам надо очень внимательно подходить не только к вопросам эксплуатации, но и резервного копирования и восстановления.
Сегодня я не буду глубоко касаться темы организации правильного хранения фрагментов ключей Шамира. Вместо этого, я попробую рассказать о том, как развернуть с нуля отказоустойчивый кластер Hashicorp Vault в community edition. Для этого поднимем основной и тестовый кластер Vault в нескольких регионах и датацентрах. Тестовый кластер у нас одновременно будет служить и резервным в рамках процедуры DRP.
Чтобы было совсем интересно, настроим процесс таким образом, чтобы тестовый кластер был односторонней репликой продуктивного с отставанием в несколько суток. Разумеется, все развертывание мы будем проводить в парадигме Infrastructure-as-a-code с Terraform и Ansible в качестве основных инструментов.
Сейчас расскажу, когда это может пригодиться и какими ansible-модулями можно для этого воспользоваться. Сразу предупреждаю — это будет лонгрид, так как я не люблю разбивать на кучу мелких постов единый туториал.
Варианты бэкендов Vault
Для начала давайте определимся с бэкендом для хранения данных. С точки зрения архитектуры, это простое key-value хранилище, на базе которого бинарник Hashicorp Vault реализует основную магию с правильной организацией шифрования, управления жизненным циклом секретов, токенов и тому подобным.
Выбор бэкенда сильно зависит от размера организации и потенциальной нагрузки. Из доступных вариантов у нас есть Consul, ZooKeeper, etcd и некоторые другие. Но, если коротко, то с огромной вероятностью вам нужен наиболее простой в деплое вариант — integrated storage. Это оптимальный вариант, который рекомендует вендор для версий Vault выше 1.4 и умеренных нагрузок. В случае integrated storage, инстанс возьмет на себя не только управление доступами к секретам, но и саму репликацию key-value хранилища по Raft-протоколу.
В норме, CPU-нагрузка на сами узлы Vault минимальна. На прошлой работе в телекоме я устранял аварию, когда в наш кластер прилетело порядка 60 мегабит/с API-запросов. Никаких проблем с CPU не наблюдалось на среднего размера виртуальных машинах, а вот бэкенд, обеспечивающий логирование запросов начал просить пощады уже через несколько десятков минут, вызвав ряд каскадных проблем. При нормальной же работе бутылочным горлышком являются операции ввода-вывода между Vault и key-value хранилищем.
Поэтому, если вы кровавый энтерпрайз или планируете тысячами поднимать и убивать инстансы ПО, использующие Vault, то вам стоит посмотреть в сторону Consul в качестве бэкенда. Вот ключевые различия:
Integrated Storage | Consul | |
Развертывание | Вам понадобится только сам Vault cluster. Все данные он будет реплицировать сам. | Нужно будет поднять отдельно кластер Vault и кластер Consul. При этом Consul должен быть выделен исключительно под задачи Vault. Service discovery, service mesh и другие задачи вешать на него нельзя. |
Где хранятся данные | Данные лежат на диске | Данные хранятся в RAM |
Снапшоты | Регулярность стандартная, так как данные лежат на диске | Вендор рекомендует частое создание резервных копий, так как данные хранятся in-memory |
В нашем туториале мы будем использовать встроенный integrated storage.
Общая архитектура

Для начала давайте опишем общую архитектуру. Детали я изобразил на схеме выше. Вот список наших основных пожеланий к инсталляции:
ИС должна переживать падение любого инстанса Vault так, чтобы никто из клиентов не заметил сбой. Минимально работоспособное число инстансов равно кворуму Raft-протокола — n+1, где n — половина от общего числа узлов в кластере.
ИС должна использовать несколько разных, независимых провайдеров. Я уже писал в прошлом посте, что мы немного параноики и всегда рассматриваем риски, что провайдер может заблокировать аккаунт или внезапно перенести все данные из датацентра в облако из-за незапланированного термического воздействия на оборудование.
Нам нужна тестовая площадка, которая полностью идентична натуральной. Вы же не хотите проводить обновление кластера без предварительных тестов? Тестировать скрипты и ПО, которое имеет право писать в БД на продуктиве тоже не стоит.
Мы должны обеспечить возможность быстрого и удобного извлечения удаленных секретов/политик/прочих данных, к которым применили полный destroy без возможности отката. Доступ к этим данным нужно получить в течение пары минут, а не после часа DRP.
Различные скрипты и ПО будут использовать AppRole авторизацию и будут ходить напрямую к инстансам Vault без промежуточных nginx и других балансировщиков.
Так как мы все-таки поднимаем один из ключевых компонентов информационной безопасности компании, давайте сразу определимся с доступами:
Все привилегированные доступы возможны только из корпоративного VPN или бастион-хоста.
Все узлы Vault максимально закрыты для внешнего доступа.
22 порт доступен только из доверенных сетей.
8201 порт должен быть либо вообще недоступен на публичном интерфейсе, либо разрешен только для членов кластера. Он нужен для репликации данных внутри кластера.
8200 порт, доступен только из доверенных сетей. На нем висит веб-интерфейс и API нашего Vault.
80 порт открыт глобально, на нем будет время от времени подниматься certbot в standalone режиме, чтобы обновить сертификат.
Таким образом, мы будем развертываться на базе Hetzner Cloud и Digital Ocean с односторонней репликацией данных. Вы можете выбрать любых других провайдеров, либо реализовать максимально независимые кластеры на базе внутренней инфраструктуры вашей компании.
Также выберите наиболее удобный для вас вариант хранения бэкапов. Это же самое хранилище бэкапов будет одновременно средством для отложенной репликации тестового/резервного кластера. В моем примере это Amazon S3, но вы можете использовать любой другой, который вам больше подходит. S3-совместимость тоже совершенно не обязательна. SFTP, ssh + rsync, NFS-share или любые другие удобные для вас варианты. Главное, чтобы туда можно было положить и достать бэкап.
Выбор инструмента для отказоустойчивости на уровне DNS также оставлю за вами. Здесь возможны варианты:
DNS указывает на балансировщик, который следит за статусом бэкенда Vault на 8200 порту и направляет запросы только к healthy, unsealed нодам. Но эта схема потребует дополнительных приседаний с хедерами и добавлением вашего балансировщика в белый список доверенных узлов. Без этого не будет работать защита с ограничением авторизации AppRole только с белого списка подсетей.
DNS непосредственно определяет состояние бэкенда и отдает IP только здоровых Vault нод. В нашем случае это AWS Route53.
Поднимаем кластеры
Давайте начнем собирать наши кластеры. Точнее начнем с подготовки кода для развертывания. В этом деплое мы ограничимся обычными виртуальными машинами без Kubernetes, который очень часто будет избыточен. Для нашего варианта достаточно простейшей возможности поднять по одной виртуалке в разных датацентрах и убедиться, что они слышат друг друга на приватном интерфейсе LAN. Также это позволит быстро и без проблем мигрировать к любому другому провайдеру с минимумом телодвижений.
В этой части мануала я предполагаю, что у вас уже есть мастер-образ, на базе которого вы разворачиваете ВМ. Мы для этих целей используем Packer от тех же Hashicorp, чтобы подготовить Oracle Linux с нашими публичными ключами и системными пользователями, от имени которых будет работать Ansible.
Terraform
Начнем мы с описания ресурсов для создания виртуальных машин. В примере ниже я использовал terraform-провайдер для Digital Ocean.
Опишем наши виртуальные машины в main.tf:
# Vault cluster
resource "digitalocean_droplet" "vault-nl-1" {
image = var.ol7_base_image
name = "vault-nl-1.example.com"
region = "ams3"
size = var.size
tags = ["vault"]
monitoring = true
}
resource "digitalocean_droplet" "vault-de-1" {
image = var.ol7_base_image
name = "vault-de-1.example.com"
region = "fra1"
size = var.size
tags = ["vault"]
monitoring = true
}
resource "digitalocean_droplet" "vault-uk-1" {
image = var.ol7_base_image
name = "vault-uk-1.example.com"
region = "lon1"
size = var.size
tags = ["vault"]
monitoring = true
}Также давайте зададим дефолтный регион и ID образа ВМ в variables.tf, чтобы следовать принципу DRY:
variable "size" {
description = "Droplet size"
default = "s-1vcpu-1gb"
}
variable "ol7_base_image" {
description = "Base ol7 DO image made by packer"
default = 312166483
type = number
}В ТЗ выше мы описали необходимость ограничения сетевого доступа. Это можно сделать как на уровне ОС, так и на уровне firewall от самого провайдера. Во втором случае нам нужно будет также описать в main.tf все порты. В этом случае я настоятельно рекомендую использовать классический принцип в разработке, который осуждает негодяев, вставляющих магические значения без описания. Если быть точнее — используйте именованные диапазоны IP адресов вместо простого набрасывания их без обозначения. Через пару лет и десяток итераций редактирования вы не вспомните, что это за адрес и принадлежит ли он вам до сих пор вообще.
resource "digitalocean_firewall" "general-firewall" {
name = "general-firewall"
tags = [ "vault" ]
inbound_rule {
protocol = "icmp"
source_addresses = ["0.0.0.0/0", "::/0"]
}
inbound_rule {
protocol = "tcp"
port_range = "22"
source_addresses = var.bastion_ip_add
}
outbound_rule {
protocol = "udp"
port_range = "all"
destination_addresses = ["0.0.0.0/0", "::/0"]
}
outbound_rule {
protocol = "icmp"
destination_addresses = ["0.0.0.0/0", "::/0"]
}
outbound_rule {
protocol = "tcp"
port_range = "all"
destination_addresses = ["0.0.0.0/0", "::/0"]
}
}Также давайте зададим те самые именованные подсети вроде var.bastion_ip_add в variables.tf:
variable "bastion_ip_add" {
description = "List of bastion IP addresses"
default = ["144.85.22.183/32",
"12.68.22.226/32",
]
}
variable "internal_vpn_ip_add" {
description = "List of internal VPN IP addresses"
default = ["122.85.77.183/32",
"44.68.2.226/32",
]
}
variable "customer_darpa_ip_add" {
description = "List of DARPA IP addresses"
default = ["158.63.250.15/32",
"158.63.250.16/32",
]
}Чтобы добавить использовать несколько именованных диапазонов в main.tf, можно воспользоваться подобной конструкцией:
inbound_rule {
protocol = "tcp"
port_range = "8200"
source_addresses = setunion(var.internal_vpn_ip_add, var.bastion_ip_add, var.customer_darpa_ip_add)
}Теперь подбрасываем в переменные окружения нужные токены и секреты. В нашем случае, это digital ocean token.
terraform init
terraform planЕсли все устраивает, то применяем наши изменения и пьем чай, пока terraform разворачивает виртуальные машины и создает сетевые фильтры.
terraform applyAnsible
Итак, у нас есть две группы виртуальных машин у разных провайдеров. Они стерильны, любят и принимают ваши приватные ключи, ожидая дальнейшего деплоя уже самих приложений. На этом этапе мы будем описывать наш кластер и конфигурацию узлов в ansible.
Мы остановились на удобной роли https://github.com/ansible-community/ansible-vault. Она позволяет просто описать всю архитектуру и достаточно гибкая для наших целей. К сожалению, есть один недостаток, который я поправил в Pull request, но автор пока не принял изменения в апстрим.
Изменение небольшое, но оно включает в себя правку шаблона конфигурации Vault для случая, когда мы хотим TLS-шифрование, но не хотим локальный CA. Это актуально для вариантов деплоя, где мы используем certbot, чтобы получить сертификаты для всех с помощью DNS-challenge.
UPD Автор принял правку, все отлично.
Начнем с получения сертификатов для всех наших узлов. Я не большой фанат «bashansible»-вставок, но в этом случае это необходимо. В нормальном режиме работы подразумевается, что инстанс vault работает от своего, независимого пользователя, который не имеет доступа к приватным ключам в /etc/letsencrypt. Чтобы это обойти, certbot получает сертификаты, а затем с помощью хука копирует полученные сертификаты в доступное для vault место. Для первого выполнения плейбука нам нужно будет однократно проделать это в отдельном таске:
- name: Prepare certificates
hosts: hashicorp_vault
gather_facts: true
become: true
roles:
- role: letsencrypt-ssl
tags: letsencrypt
post_tasks:
- name: Copy the certificates to the vault config dir for the first time
shell: |
rsync -L /etc/letsencrypt/live/{{ inventory_hostname }}/privkey.pem /etc/vault.d/privkey.pem
rsync -L /etc/letsencrypt/live/{{ inventory_hostname }}/fullchain.pem /etc/vault.d/fullchain.pem
chown vault:vault /etc/vault.d/privkey.pem
chown vault:vault /etc/vault.d/fullchain.pem
pkill -SIGHUP vault
args:
creates: /etc/vault.d/fullchain.pem
tags: letsencryptНа следующем этапе мы деплоим непосредственно само приложение:
- name: Deploy hashicorp vault cluster
hosts: hashicorp_vault
gather_facts: true
become: true
roles:
- role: ansible-community.ansible-vault
tags: vault_installПриведу только часть ключевых variables из group_vars, на которые стоит обратить внимание:
vault_version: "1.12.0"
vault_install_hashi_repo: true
vault_harden_file_perms: true
vault_service_restart: false
# listeners configuration
vault_api_addr: "{{ vault_protocol }}://{{ inventory_hostname }}:{{ vault_port }}"
vault_tls_disable: false
vault_tls_certs_path: /etc/vault.d
vault_tls_private_path: /etc/vault.d
vault_tls_cert_file: fullchain.pem
vault_tls_key_file: privkey.pem
vault_tls_min_version: "tls12"
vault_raft_cluster_members:
- peer: hasd-vault-nl-1.itsts.net
api_addr: https://vault-nl-1.example.com:8200
- peer: hasd-vault-de-1.itsts.net
api_addr: https://vault-de-1.example.com:8200
- peer: hasd-vault-uk-1.itsts.net
api_addr: https://vault-uk-1.example.com:8200Здесь мы явно задаем версию ПО и указываем на необходимость добавить репозиторий hashicorp в качестве источника обновлений.
vault_harden_file_perms автоматически закрутит гайки для пользователя vault в соответствии с рекомендациями Production Hardening.
vault_service_restart запретит рестарт демона в случае обновления. Это лучше делать руками, так как по vault при запуске не знает ключа шифрования от своего бэкенда и требует ручного unseal с вводом ключей Шамира. Если просто перезапустить все подряд, то кластер окуклится и станет сервис станет недоступным до unseal. Правильнее будет обновить узлы, а затем перезапустить по очереди по одному узлу, чтобы обеспечить непрерывность сервиса.
Далее идет блок, который описывает ключевые параметры, которые используются в шаблоне для генерации конфигурации инстансов Vault. В частности, vault_raft_cluster_members описывает переменные, которые нужны для сборки кластера в единое целое. Там должны быть перечислены все узлы и их адреса, которые будут подставлены в jinja2-шаблон.
В результате, на узлах должны сформироваться конфигурации /etc/vault.d/vault_main.hcl с приблизительно таким содержимым:
# Ansible managed
cluster_name = "dc1"
max_lease_ttl = "768h"
default_lease_ttl = "768h"
disable_clustering = "False"
cluster_addr = "https://333.222.10.107:8201"
api_addr = "https://vault-nl-1.example.com:8200"
plugin_directory = "/usr/local/lib/vault/plugins"
listener "tcp" {
address = "333.222.10.107:8200"
cluster_address = "333.222.10.107:8201"
tls_cert_file = "/etc/vault.d/fullchain.pem"
tls_key_file = "/etc/vault.d/privkey.pem"
tls_min_version = "tls12"
tls_disable = "false"
}
listener "tcp" {
address = "127.0.0.1:8200"
cluster_address = "333.222.10.107:8201"
tls_cert_file = "/etc/vault.d/fullchain.pem"
tls_key_file = "/etc/vault.d/privkey.pem"
tls_min_version = "tls12"
tls_disable = "false"
}
storage "raft" {
path = "/opt/vault/data"
node_id = "hasd-vault-nl-1"
retry_join {
leader_api_addr = "https://vault-de-1.example.com:8200"
}
retry_join {
leader_api_addr = "https://vault-uk-1.example.com:8200"
}
}
// HashiCorp recommends disabling mlock when using Raft.
disable_mlock = true
ui = trueРазберем несколько ключевых моментов.
api_addr — этот параметр должен совпадать с адресом ноды, который указан в секции listener, если вы не используете промежуточные балансировщики между клиентом и инстансами vault. Инстанс использует его, чтобы сообщить другим членам кластера адрес, на котором он готов обслуживать клиентов. Это нужно для того, чтобы работал механизм внутренних редиректов запросов.
cluster_addr — этот параметр похож на предыдущий, но нужен для того, чтобы сообщить соседям по кластеру адрес и порт, на котором нода готова осуществлять внутрикластерную репликацию.
tls_cert_file, tls_key_file — имена файлов ключа и сертификата, который был получен с помощью certbot. В нашем случае узлы одного кластера расположены в разных датацентрах и проще всего заставить их общаться на публичном интерфейсе, но прикрыв коммуникации TLS-шифрованием. По умолчанию, ноды будут использовать TLS 1.3 для взаимодействия друг с другом.
retry_join — когда нода стартует, она пытается подключиться к соседям. Первичный bootstrap для поиска соседей она получит из этого параметра, чтобы быстро собраться в единый кластер.
На этом этапе, после применения плейбука мы получим работающий кластер, где при первом подключении к работающему узлу произойдет процедура генерации ключей Шамира. Будьте предельно внимательны на этом этапе, он крайне важен! Потерянные ключи Шамира = заблокированное навсегда хранилище после рестарта демона.
В одной из компаний, где мы занимались интеграцией этого продукта в бизнес-процессы с нуля, мы уже сталкивались с проблемами у заказчика. Если коротко, то в этом случае заказчик несколько лет назад поднял минимально работающий инстанс с одним узлом и дефолтными настройками, но забыл сохранить ключи. Все работало на сервере с аптаймом в пару лет, пока его случайно не перезагрузили. После этого стало понятно, что данные необратимо зашифрованы и извлечь их оттуда невозможно. К счастью, к этому моменту мы уже провели аудит и перенесли данные в новый кластер. Ввод в промышленную эксплуатацию получился несколько более внезапным, чем было запланировано.
Важные аспекты HTTPS
Когда вы будете выписывать TLS-сертификаты позаботьтесь о том, чтобы узлы корректно функционировали не только в штатном режиме, но и в ситуации различных аварий:
Вы должны иметь возможность обратиться на общее балансируемое имя vault.example.com. DNS при этом направит вас на ближайший живой узел продуктивного кластера.
Вы должны иметь возможность принудительно обратиться к конкретному узлу своего кластера. Например, vault-nl-1.example.com.
Вы должны иметь возможность экстренно перекинуть нагрузку на тестовый кластер, который на время аварии станет продуктивным. Его узлы должны успешно откликаться как на vault-test.example.com, так и на vault.example.com.
Соответственно требованиям выше планируйте корректное получение сертификатов шифрования:
Ноды продуктивного кластера:
CN = vault.example.com
В SAN перечислены все личные имена узлов кластера вида vault-nl-1.example.com
Ноды тестового кластера:
CN = vault-test.example.com
В SAN vault.example.com для DRP и имена узлов кластера вида vault-test-nl-1.example.com
Не забудьте настроить renew-hook для letsencrypt со скриптом следующего вида:
rsync -L /etc/letsencrypt/live/{{ inventory_hostname }}/privkey.pem /etc/vault.d/privkey.pem
rsync -L /etc/letsencrypt/live/{{ inventory_hostname }}/fullchain.pem /etc/vault.d/fullchain.pem
chown vault:vault /etc/vault.d/privkey.pem
chown vault:vault /etc/vault.d/fullchain.pem
pkill -SIGHUP vaultОбратите внимание, что vault позволяет выполнить reload сертификатов без необходимости рестарта и ручного unseal при каждом обновлении с помощью pkill -SIGHUP vault.
Также рекомендую не забывать добавлять CAA record в DNS, чтобы зафиксировать certificate issuer.
Делаем резервную копию
Зачем нужна косвенная репликация с задержкой
Теперь давайте посмотрим на нашу схему отсроченной репликации. Раз в сутки задача в crontab запускает резервное копирование данных продуктивного кластера и отправляет данные в S3-хранилище. Мы для этого используем duplicity, но вы можете выполнять это любым привычным для вас способом.
Затем, также раз в сутки, на тестовом/резервном кластере происходит обратный процесс с выкачиванием нужного снапшота и восстановлением кластера в это состояние. Вот, чего мы достигаем этим подходом:
Инженер, обслуживающий Vault, может проводить любые эксперименты, которые посчитает нужным. Связь между кластерами строго односторонняя и никакие изменения в тестовом кластере не заденут продуктив.
Раз в сутки тестовая зона полностью очищается и приводится в нетронутое состояние. При необходимости, можно быстро дернуть тот же скрипт вручную. Соответственно, все тесты всегда проходят на почти точной чистой копии продуктивного кластера.
Есть возможность оперативного извлечения данных при их случайном удалении или необратимом повреждении. Не нужно что-то дополнительно настраивать, под рукой всегда есть отстающая на пару дней реплика.
Небольшое отставание по времени позволяет быстро вынуть данные, удаление которых заметили не сразу. Обычно пары дней более чем достаточно, чтобы забрать пароли, которые радикально вчера прибил уставший инженер.
Вы сразу переходите в разряд админов, которые не только делают бэкапы, но и проверяют их извлечение. Только теперь вы это делаете это ежедневно и автоматически. Фактически, схема одновременно реализует близкий к DRP аналог разворачивания из резервной копии.
Пример скрипта
Сам скрипт для бэкапа восстановления может быть любым, который вы сочтете разумным. Ниже пример jinja2-шаблона:
#!/bin/bash
LEADER=$(vault status -format=json | jq -r '.leader_address')
HOSTNAME=$(hostname)
ROLE_ID_VAULT_MAINTENANCE={{ vault_maintenance_role_id }}
# Get the secret ID for the vault_maintenance_snapshot AppRole
SECRET_ID_VAULT_MAINTENANCE=$(cat /root/approle_vault_maintenance_snapshot_secret_id)
# Check if this node is the leader and if the hostname matches
if [[ "$LEADER" == "https://$HOSTNAME:8200" ]]; then
TOKEN=$(vault write auth/approle/login --format=json role_id=$ROLE_ID_VAULT_MAINTENANCE secret_id="$SECRET_ID_VAULT_MAINTENANCE" | jq -r '.auth.client_token')
vault login $TOKEN >/dev/null 2>&1
vault operator raft snapshot save {{ vault_snapshot_location }}
# Send the result to the cloud backup. This will happen on the leader node only
/root/scripts/duplicity-backup.sh -c /root/scripts/{{ duplicity_config_name_s3 }}.conf -b > /dev/null
fiСкрипт подразумевает, что он работает от имени ограниченной AppRole в Vault, которая имеет права только на работу со снапшотами. При этом, ожидается, что ранее вы положили в /root/approle_vault_maintenance_snapshot_secret_id сам secret_id от этой роли. Далее, мы получаем токен, авторизуемся и выполняем snapshot save/restore в зависимости от роли.
Чтобы не допустить одновременного запуска сохранения и восстановления снапшота на всех узлах кластера, вначале мы проверяем, что нода является лидером. Таким образом, мы гарантируем, что в каждый момент времени бэкап будет сохраняться и восстанавливаться только на одном узле кластера.
Вот пример минималистичной policy для AppRole, которая имеет право на снятие снапшотов с последующим восстановлением:
path "sys/storage/raft/snapshot"
{
capabilities = ["read", "update"]
}
path "auth/token/revoke"
{
capabilities = ["update"]
}Краткое резюме
Туториал завершен. Если все было сделано верно, то сейчас у вас есть вот это:
Код ansible и terraform для полностью автоматизированного развертывания кластеров Vault. Все в лучших традициях Infrastructure-as-a-code, как мы любим.
Созданы два независимых отказоусточивых кластера, где каждый узел при старте автоматически подключается к остальными и собирается в кворум.
Настроена отсроченная репликация из продуктивного кластера в тестовый. Можно быстро вынуть данные в случае фатальной ошибки на проде и минимизировать потери.
Вы подготовили платформу для будущего DRP.
Не забудьте прикрутить ко всей этой конструкции мониторинг и у вас получится полный цикл тестирования всех процессов — от healthcheck каждой ноды до ежедневной проверки корректности развертывания бэкапов из резервной копии. Поделиться англоязычными коллегами можно этой версией поста.
В дальнейших постах я попробую рассказать как правильно организовать Disaster Recovery Plan на примере нашего кластера. Все в лучших традициях DevOps-параноиков, как мы любим, чтобы даже падение метеорита учитывалось.
Ну, а если будет нужно, мы можем провести аудит того, как вы храните секреты сейчас, и поможем настроить Vault, чтобы все было безопасно. Вот тут можно с нами связаться. Только скажите, что вы от Хабра — это даст 10% скидку к цене первого месяца обслуживания. Вне зависимости от объемов, да. Я сам терпеть не могу все эти «цены по запросу», но это почти неизбежно для любых комплексных задач. Мы сторонники полной прозрачности, поэтому при обращении подробно все рассчитаем по пунктам и покажем все варианты.
