Хаки при работе с большим числом мелких файлов
Идея статьи родилась спонтанно из дискуссии в комментариях к статье «Кое-что об inode».
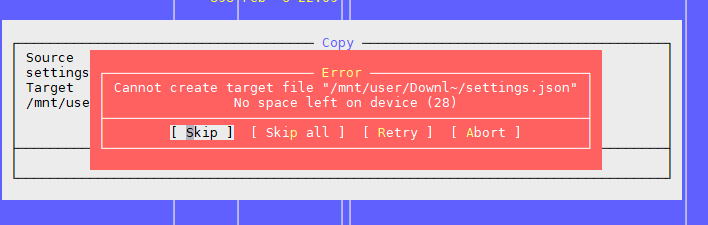
Дело в том, что внутренней спецификой работы наших сервисов является хранение огромадного числа мелких файлов. На данный момент у нас порядка сотен терабайт таких данных. И мы натолкнулись на некоторые очевидные и не очень грабельки и успешно по ним прошлись.
Поэтому делюсь нашим опытом, может кому и пригодится.
Проблема первая: «No space left on device»
Как упоминалось в вышеупомянутой статье, проблема в том, что свободные блоки на файловой системе есть, а вот inode закончились.
Проверить число использованных и свободный inodes можно командой df -ih:
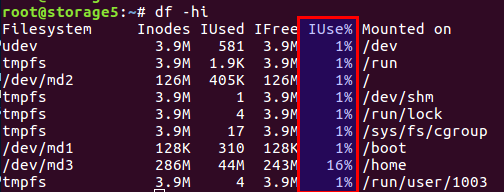
Не буду пересказывать статью, если кратко, то на диске есть как блоки непосредственно для данных, так и блоки для мета-информации, они же inodes (index node). Их количество задается при инициализации файловой системы (речь идет об ext2 и ее наследниках) и далее не меняется. Баланс блоков данных и inodes вычисляется из среднестатистических данных, в нашем же случае, когда много мелких файлов, баланс должен сдвигаться в сторону числа inodes — их должно быть больше.
В Linux уже предусмотрели варианты с разным балансом, и все эти предрасчитанные конфигурации находятся в файле /etc/mke2fs.conf.
Поэтому при первичной инициализации файловой системы через mke2fs можно указать нужный профиль.
Вот несколько примеров из файла:
small = {
blocksize = 1024
inode_size = 128
inode_ratio = 4096
}
big = {
inode_ratio = 32768
}
largefile = {
inode_ratio = 1048576
blocksize = -1
}
Выбрать нужный вариант использования можно опцией »-T» при вызове mke2fs. Также можно вручную задать нужные параметры, если нет готового решения.
Больше подробностей описано в мануалах для mke2fs.conf и mke2fs.
Не затронутая в вышеупомянутой особенность — можно задать размер блока данных. Очевидно, что для больших файлов есть смысл в бОльшем размере блока, для маленьких — в меньшем.
Однако стоит учитывать такую интересную особенность, как архитектура процессора.
Я как-то в свое время задумался, что мне для больших файлов фоток нужен размер блока побольше. Дело было в домашних условиях, на домашней файлсторадже имени WD на архитектуре ARM. Я, не долго думая, задал размер блока то ли 8к, то ли 16к вместо стандартного 4к, предварительно измерив экономию. И все было замечательно ровно до того момента, как сам сторадж не вышел из строя, при этом диск был жив. Поставив диск в обычный комп с обычным интеловским процессором, получил сюрприз: неподдерживаемый размер блока. Приплыли. Данные есть, все хорошо, но прочитать невозможно. Процессоры i386 и подобные не умеют размеры блока, не соответствующие размеру страницы памяти, а она ровно 4к. В общем, дело закончилось использованием утилит из user space, все было медленно и печально, но данные спасли. Кому интересно — гуглите по названию утилиты fuseext2. Мораль: или продумывать все кейсы наперед, или не строить из себя супергероя и пользоваться стандартными настройками для домохозяек.
UPD. По замечанию пользователя berez уточняю, что для i386 размер блока не должен превышать 4к, но не обязательно должен быть ровно 4к, т.е. допустимы 1к и 2к.
Итак, как решали проблемы мы.
Во-первых, с проблемой мы столкнулись, когда многотерабайтный диск был забит данными, и переделать конфигурацию файловой системы мы не могли.
Во-вторых, решение нужно было срочное.
В итоге мы пришли к выводу, что нужно изменить баланс, уменьшив число файлов.
Чтобы уменьшить число файлов, было решено складывать файлы в один общий архив. Учитывая нашу специфику, мы складывали в один архив все файлы за некоторый промежуток времени, и проводили архивацию cron-таской ежедневно по ночам.
Выбрали zip-архив. В комметариях к предыдущей статье предлагался tar, но с ним есть одна сложность: он не имеет оглавления, и файлы в нем лежат поточно (не просто так «tar» — это сокращение от «Tape Archive», наследие ленточных накопителей), т.е. если нужно почитать файл в конце архива — нужно прочитать весь архив, поскольку в нем нет смещений для каждого файла относительно начала архива. А поэтому это долгая операция. В zip все намного лучше: он имеет то самое оглавление и смещения файлов внутри архива, и время доступа к каждому файлу не зависит от его расположения. Ну и в нашем случае можно было задать опцию сжатия »0», ибо все файлы уже заранее были пожаты в gzip.
Клиенты забирают файлы через nginx, и согласно старому API, указывается просто имя файла, например так:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
Чтобы на лету распаковывать файлы, нашли и подключили модуль nginx-unzip-module (https://github.com/youzee/nginx-unzip-module) и настроили два апстрима.
В результате получилась такая конфигурация:

Два хоста в настройках выглядели так:
server {
listen *:8081;
location / {
root /home/filestorage;
}
}server {
listen *:8082;
location ~ ^/hydra/(\d+)/(\d+)/(.*)$ {
root /home/filestorage;
file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip";
file_in_unzip_extract "$2/$3";
file_in_unzip;
}
}
И конфигурация апстримов на вышестоящем nginx:
upstream storage {
server server.com:8081;
server server.com:8082;
}
Как работает:
- Клиент идет на font nginx
- Front nginx пытается отдать файл с первого апстрима, т.е. напрямую с файловой системы
- Если файла нет — пытается отдать со второго апстрима, который пытается найти файл внутри архива
Проблема вторая: опять «No space left on device»
Это вторая проблема, с которой мы столкнулись, когда в каталоге много файлов.
Мы пытаемся создать файл, система ругается, что места нет. Изменяем имя файла и снова пытаемся его создать.
Получается.
Выглядит примерно так:

Проверка inodes ничего не дала — их много свободных.
Проверка места — то же самое.
Подумали, что может слишком много файлов в каталоге, а на это есть ограничение, но опять нет: Maximum number of files per directory: ~1.3 × 10^20
Да и файл-то создать можно, если поменять имя.
Вывод — проблема в имени файла.
Дальнейшие поиски показали, что проблема в алгоритме хеширования при построении индекса каталога, при большом числе файлов наблюдаются коллизии со всеми вытекающими последствиями. Более подробно можно почитать тут: https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_Directories
Можно отключить эту опцию, но… поиск файла по имени может стать непредсказуемо долгим при переборе всех файлов.
tune2fs -O "^dir_index" /dev/sdb3
В общем, как временное решение может сработать.
Мораль: много файлов в каталоге — это обычно плохо. Так делать не надо.
Обычно в таких случаях создают вложенные каталоги, по первым буквам имени файла или по каким-либо другим параметрам, например, по датам, в большинстве случаев это спасает.
Но общее число маленьких файлов — это все равно плохо, даже если их разбить по каталогам — тогда см. первую проблему.
Проблема третья: как посмотреть список файлов, если их много
В нашей ситуации, когда у нас много файлов, так или иначе мы сталкивались с проблемой, как посмотреть содержимое каталога.
Стандартное решение — команда ls.
Ок, посмотрим, что получается на 4772098 файлах:
$ time ls /home/app/express.repository/offercache/ >/dev/null
real 0m30.203s
user 0m28.327s
sys 0m1.876s
30 секунд… многовато будет. Причем основное время уходит на обработку файлов в user space, а вовсе не на работу ядра.
Но решение есть:
$ time find /home/app/express.repository/offercache/ >/dev/null
real 0m3.714s
user 0m1.998s
sys 0m1.717s
3 секунды. В 10 раз быстрее.
Ура!
Проблема четвертая: большой LA при работе с файлами
Периодически возникает ситуация, когда нужно скопировать кучу файлов с одной машины на другую. При этом часто нереально сильно вырастает LA, поскольку все упирается в производительность самих дисков.
Самое разумное, что хочется — использовать SSD. Реально круто. Вопрос только в стоимости многотерабайтных SSD.
Но если диски обычные, копировать файлы надо, а это ко всему еще и продакшн-система, где перегрузка ведет к недовольным возгласам клиентов? Есть как минимум два полезных инструмента: nice и ionice.
nice — уменьшает приоритет процесса, соответственно шедулер раздает больше квантов времени другим, более приоритетным процессам.
В нашей практике помогало выставлять nice максимальным (19 — это минимальный приоритет, -20 (минус 20) — максимальный).
ionice — соответственно корректирует приоритет ввода/вывода (I/O scheduling)
Если у вас используется RAID и ему понадобилось внезапно синхронизироваться (после неудачного ребута или нужно восстановление RAID-массива после замены диска), то в отдельных ситуациях есть смысл уменьшить скорость синхронизации, чтобы остальные процессы могли более-менее адекватно работать. Доя этого поможет такая команда:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
Проблема пятая: Как синхронизировать файлы в real-time
Имеем все те же огроменные количества файлов, которые нужно бэкапить на второй сервер во избежание… Файлы постоянно пишутся, поэтому, чтобы иметь минимум потерь, нужно их максимально быстро копировать.
Стандартное решение: Rsync over SSH.
Это хороший вариант, если только не нужно это делать раз в несколько секунд. А файлов много. Даже если их не копировать — то надо как-то все равно понимать, что изменилось, а сравнить несколько миллионов файлов — это время и нагрузка на диски.
Т.е. нам надо сразу знать, что надо копировать, без запуска сравнения каждый раз.
Спасение — lsyncd. Lsyncd — Live Syncing (Mirror) Daemon. Он тоже работает через rsync, но дополнительно мониторит файловую систему на предмет изменений с использованием inotify и fsevents и запускает копирование только для тех файлов, которые появились или изменились.
Проблема шестая: как понять, кто грузит диски
Это наверное знают все, но тем не менее для полноты картины: для мониторинга дисковой подсистемы есть команда iotop — наподобие top, но показывает процессы, наиболее активно использующие диски.

Кстати, старый добрый top тоже позволяет понять, что проблемв с дисками или нет. Для этого есть два наиболее подходящих параметра: Load Average и IOwait.
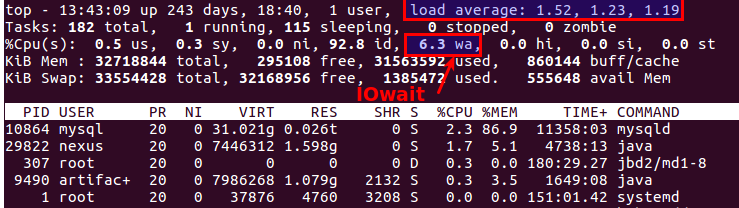
Первый показывает, сколько процессов стоят в очереди на обслуживание, обычно больше 2х — уже что-то идет не так. При активном копировании на бэкап-сервера мы допускаем до 6–8, после этого ситуация считается нештатной.
Второй — насколько процессор занят дисковыми операциями. IOwait >10% — причина для беспокойства, хотя у нас на серверах со специфическим профилем нагрузки бывает стабильно 40–50%, и это реально норма.
На этом закончу, хотя наверняка есть много моментов, с которым нам не приходилось сталкиваться, с удовольствием буду ждать комментариев и описаний интересных реальных случаев.
