HaGRID — огромный открытый датасет для распознавания жестов
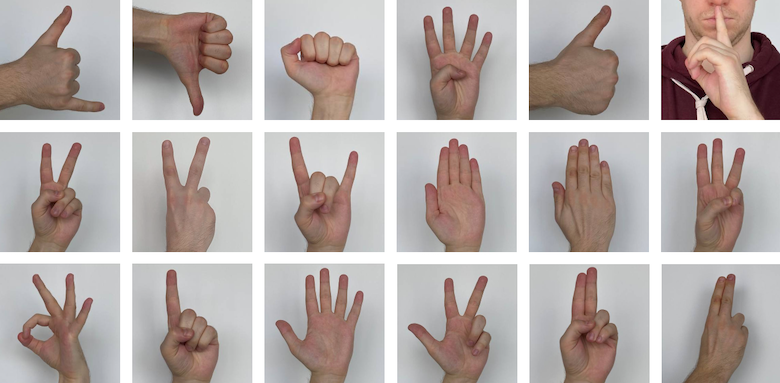 Корзина жестов
Корзина жестов
Хороший набор данных невероятно важен при обучении нейросетей. Наш датасет изображений с жестами HaGRID (Hand Gesture Recognition Image Dataset) — один из таких. С его помощью можно создать систему распознавания жестов, которая будет отлично работать в совершенно разных ситуациях. Например, жестовое управление можно использовать в видеоконференциях, для управления устройствами умного дома или мультимедийными возможностями автомобиля. Ещё одна важная возможность — создание виртуальных помощников для пользователей с дефектами речи или использующих язык жестов. Ниже рассказываем, как всё это работает, и делимся ссылками на датасет и набор предобученных моделей к нему.
Описание
HaGRID (HAnd Gesture Recognition Image Dataset) — на сегодняшний день самый полный датасет для системы распознавания жестов. Он состоит из 552992 изображений, разделённых на 18 классов. То есть в каждом классе примерно по 30 тысяч фото. Изображения — RGB-картинки, преимущественно FullHD (~91% датасета). На них представлены реальные люди, показывающие жесты на камеру. Количество уникальных пользователей в датасете — не менее 34700, при этом набор данных содержит как минимум столько же разнообразных сцен с человеком (различное освещение, расстояние до камеры и положение кистей относительно человека). Датасет в равных пропорциях распределён по полу (число женщин лишь немногим больше мужчин), а возраст исполнителей — от 18 до 60 лет.
Для всего датасета мы разметили обрамляющие прямоугольники (bounding box) с меткой класса жеста, а также метку жеста ведущей руки (leading_hand — правая или левая). Если в кадре присутствуют другие кисти рук, которые не выполняют жест, то разметка содержит несколько боксов. Причём все кисти рук в свободном положении размечаются классом «не жест». Помимо прочего, в разметке есть уникальный анонимизированный id пользователя, который призван помочь разделить датасет на обучающую, валидационную и проверочную выборки с целью избежать попадания субъектов обучающей выборки в остальные. Суммарный объём датасета ~ 716 GB. Для ознакомления с представленным датасетом вы можете скачать мини-версию набора данных, содержащую по 100 изображений на класс и разметку к этому подмножеству.
Все данные и обученные на них модели для задач классификации и детекции жестов абсолютно бесплатны и доступны в открытом доступе для скачивания и распространяются под переработанной версией лицензии Creative Commons Corporation (Attribution-ShareAlike 4.0).
Жесты
Всего в датасете 18 функциональных жестов (call, dislike, fist, four, like, mute, ok, one, palm, peace, peace_inverted, rock, stop, stop_inverted, three, three2, two_up, two_up_inverted) и один класс для руки в свободном положении no_gesture. Каждый из этих жестов может активировать ту или иную функцию при управлении системой распознавания жестов.
Например, жест CALL может активировать вызов, а жестами LIKE и DISLIKE можно оценивать контент (ролик на Youtube, статью на Хабре). Жесты PEACE и PEACE_INVERTED можно использовать в качестве «активационных» и применять для запуска основных приложений, а жестом ROCK можно запускать приложение для воспроизведения музыки. Жесты ONE, PEACE (он же TWO), THREE/THREE2, FOUR и PALM (он же FIVE) можно применить для управления любой шкалой (например, для регулировки громкости), а используя две руки, можно расширить диапазон возможных значений от 1 до 10. Жест MUTE можно применять для выключения звука, а жест STOP использовать для постановки аудио/видео на паузу. Комбинацию жестов PALM и FIST можно использовать в режиме Drag-n-Drop для захвата и перетаскивания чего-либо по экрану (например, в детских играх). Жестами OK и STOP можно активировать тот или иной выбор во время всплывающих подсказок, например »Вы действительно хотите оформить подписку? ».
Вы также могли заметить, что для некоторых жестов мы собирали обратное положение кисти (TWO_UP_INVERTED и STOP_INVERTED). Эти жесты в связке с прямым положением (TWO_UP и STOP) кисти можно использовать для упрощённой реализации динамических жестов, когда мы ограничены в выборе легковесных нейросетевых архитектур. Для этого потребуется простой набор эвристик и простейшая очередь с запоминанием N последних событий, которая отслеживает предсказанный класс.
Так, жест STOP и повёрнутый на 180 градусов STOP_INVERTED образуют динамический жест движения руки вниз, он же «свайп вниз» (SWIPE_DOWN). Повёрнутый на 90 градусов по часовой стрелке STOP и повёрнутый на 90 градусов против часовой стрелки STOP_INVERTED образуют динамический жест «прямой свайп» (SWIPE_FORWARD). По аналогии можно смоделировать поведение для жестов свайп вверх (SWIPE_UP) и обратный свайп (SWIPE_BACKWARD). Для жестов TWO_UP и TWO_UP_INVETED также можно реализовать свайпы. Для лучшей надёжности можно объединить эти пары жестов. Применимость свайпов очевидна — с их помощью можно реализовать поиск и функции переключения (листание по экранам, переключение роликов и т. д.).
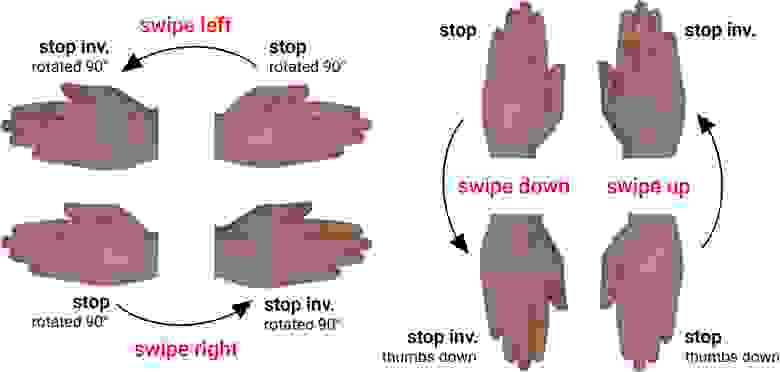 Динамические жесты на базе жеста STOP и его развернутых вариантах
Динамические жесты на базе жеста STOP и его развернутых вариантах
Это лишь некоторые из возможных способов применения «жестовой корзины». Вы можете реализовать собственную систему и расширить представленную функциональность в зависимости от задачи.
Краудсорсинг
Для сбора и разметки данных мы использовали две популярные российские краудсорсинг-платформы: Яндекс.Толоку и ABC Elementary. Эти сервисы идентичны по многим параметрам и немного отличаются в интерфейсе, но финальный вид результирующей разметки не зависит от выбора платформы. Полный цикл создания датасета состоял из нескольких последовательно связанных этапов:
Сбор данных.
Валидация + Фильтрация.
Разметка боксов и ведущей руки.
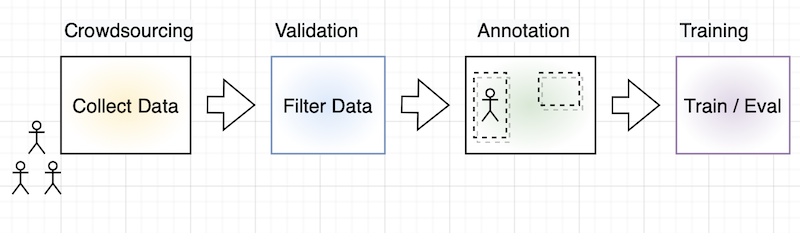 Пайплайн разметки
Пайплайн разметки
Сначала проводился сбор данных, которые затем отправлялись на валидацию. Успешно прошедшие валидацию данные переходили на этап фильтрации, далее — на разметку и в случае острой необходимости — на валидацию разметки. На этапах валидации, фильтрации и разметки использовались различные правила контроля качества: блокировка пользователей за очень быстрые ответы или за неверные контрольные ответы (которые подмешивались в проект к основным заданиям), контроль согласованности ответов и прочие виды эвристик.
Сбор данных
На этапе сбора данных перед исполнителями стояла простая задача — сделать снимок самого себя с указанным в описании жестом. Базовое условие — рука должна быть полностью в кадре. Расстояние до камеры — от 1 до 4 метров. В процессе сбора для разнообразия данных в датасете мы меняли условия и вводили дополнительные правила, связанные с освещённостью: фото на фоне источника яркого света или в темноте. В инструкцию были добавлены примеры правильного выполнения жестов. На этом этапе мы добавили проверку по дубликатам (расчёт хеша изображения и сравнение с остальными), так как недобросовестные исполнители зачастую присылали одни и те же фотографии. А чтобы не решать дополнительно задачу классификации и снизить стоимость на этапе сбора данных, для каждого жеста был создан отдельный пул (подпроект). На стадии сбора данных мы заручились согласием краудсорсеров на сбор данных, в том числе для последующего обучения нейросетей.
Валидация
Следующим шагом мы провели проверку правильности собранных изображений, так как некоторые исполнители пытались «обмануть систему», выполняли задания неправильно или даже присылали сторонние фото. Бывало также, что по ошибке люди загружали перевёрнутое фото или изображение с другим жестом. Такие недочёты тоже приходилось фильтровать на этой стадии.
Если говорить упрощённо, этап валидации — это классификация с двумя вариантами ответа: «правильно»/«неправильно». Каждая фотография отправлялась на проверку с определённым перекрытием (overlap), то есть несколько исполнителей должны были проверить одну и ту же фотографию. Минимальное перекрытие для валидации — 3, а в случае несогласованности ответов исполнителей, это перекрытие динамически увеличивалось сначала до 4, а потом до 5. Финальное решение принималось на основе ответов по принципу мнения большинства.
Для доступа к заданиям на этапе валидации исполнителям необходимо было пройти обучение, состоящее из 10 заданий. В случае неверного ответа появлялись всплывающие подсказки. А в случае успешного прохождения обучения (не менее 7 правильных ответов из 10) исполнители допускались до экзамена, после которого могли выполнять оплачиваемые задания. Экзамен также содержал 10 различных заданий, а порог допуска до боевых пулов с реальными заданиями — 8/10.
Фильтрация
Чтобы сделать предыдущий этап валидации проще и не нагромождать большим перечнем правил, мы разделили валидацию на две стадии. На этапе фильтрации мы повторно проверяли фото после валидации, но накладывали дополнительные ограничения: из датасета удалялись изображения с детьми, людей без одежды и изображения с различными надписями и символикой (национальной, религиозной и т.д.). Здесь мы тоже использовали обучение и экзамен, а перекрытие было жёстко задано и равно 5, поскольку цена ошибки существенно выше.
Разметка
Разметка разбивается на два независимых проекта: 1) определение ведущей руки, выполняющей жест; 2) разметка боксов кистей рук на изображении. Для обоих проектов разметки перед допуском исполнителей к реальным заданиям использовались обучение и экзамен. Для определения ведущей руки overlap = 5. Для отрисовки обрамляющих прямоугольников — перекрытие динамическое от 3 до 5. Причём, для разметки боксов мы использовали обе платформы одновременно (Яндекс.Толоку и ABC Elementary), чтобы повысить точность финальных аннотаций.
Пример интерфейса для разметки боксов (для удобства разметки доступны направляющие по осям и горячие клавиши интерфейса):
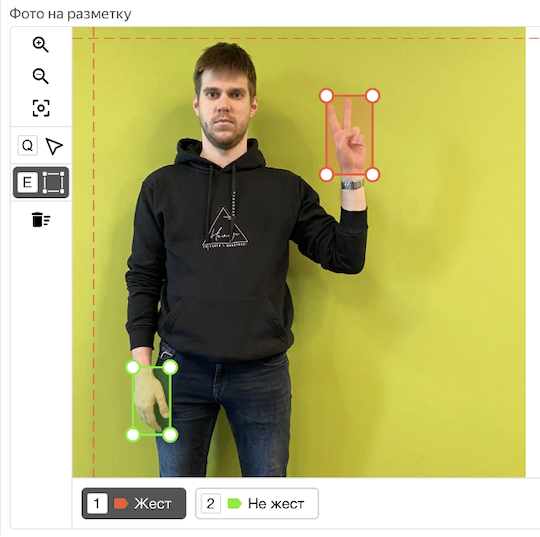 Пример разметки изображения
Пример разметки изображения
Сервисы разметки не позволяют на своей стороне агрегировать сложные результаты, такие как боксы. Для этого мы написали два метода агрегации — hard & soft, которые позволили получить максимально точную и качественную разметку.
Hard-агрегация работает по простому принципу: если какое-то правило из списка не выполняется, то получить финальную разметку нельзя. Алгоритм следующий (для каждого фото с перекрытием overlap N > 2):
Проверяем на равенство боксов в каждой разметке.
Для всех боксов находим центры и ищем все центроиды с помощью MeanShift.
Группируем боксы по найденным центроидам.
Проверяем, что в каждой группе метки класса совпадают.
Для каждой группы по метрике IoU (Intersection over Union) попарно сравниваем боксы с порогом (по умолчанию 0,7).
Усредняем финальный бокс (медианный или средний результат).
 Hard-агрегация
Hard-агрегация
Таким образом, получаем усреднённый бокс для каждого изображения. Если hard-агрегация не сработала, то переходим к soft-схеме.
Soft-агрегация работает по схожему принципу, но не останавливается в случае провала на каком-либо шаге и включает дополнительные эвристики для анализа. Минимальное перекрытие для soft-агрегации равно 4. Пороги для эвристик «мнение большинства» — не менее 70%.
Удаляются все боксы, вырождающиеся в точку (например бокс 2×2 пикселей).
Удаляются все дубликаты (один разметчик мог нарисовать бокс поверх уже существующего).
Проверка меток по «мнению большинства» (например, 4 метки в группе с классом «жест», а 1 метка — «не жест»).
Проверка боксов по «мнению большинства». Например, 4 исполнителей нарисовали бокс вокруг кисти, а пятый — забыл. Или 4 исполнителя бокс не рисовали, а пятый нарисовал в случайном месте (этот бокс требуется удалить).
 Soft-агрегация
Soft-агрегация
Если hard- и soft-алгоритмы не сработали, помечаем изображение особым образом и не используем его в финальном датасете (потенциально можно отправлять такие фото на валидацию разметки, но мы почти сразу отказались от этой схемы). Если в разметку по каким-то причинам попало изображение без жестов, и его никто не размечал, то оно тоже фильтруется из датасета.
Ниже приведена схема работы алгоритмов агрегации:
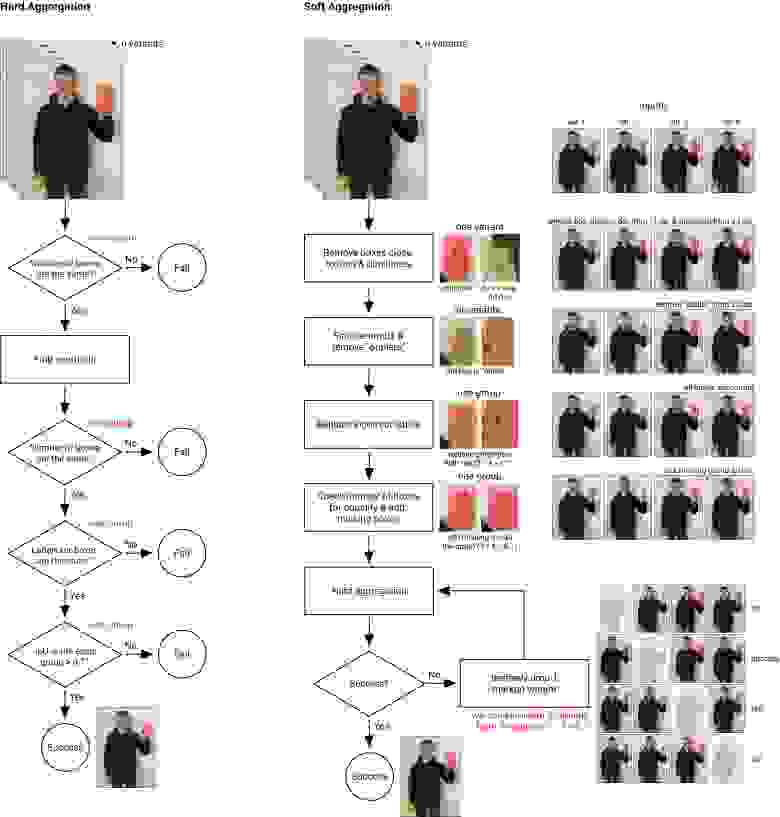 Алгоритм агрегации разметки
Алгоритм агрегации разметки
Финальная разметка представлена в JSON-формате как словарь:
id изображения (название фото);
user_id (уникальный анонимизированный идентификатор);
leading_hand (ведущая рука: left / right);
leading_conf (уверенность ответа для ведущей руки);
bboxes (список боксов в относительных координатах COCO format);
labels (список меток для боксов).
 Пример изображения и разметки
Пример изображения и разметки
Обучение нейросетей
Для проверки качества собранного датасета мы обучили ряд классических популярных моделей для задач классификации (ResNet-18 и ResNet-152, ResNeXt-50 и ResNeXt-101, и MobileNetV3 Small/Large), а также — базовый трансформер ViT-B/32. Для этих классификаторов мы убрали последние слои и сделали две «головы» — для определения класса жеста кисти и для определения ведущей руки.
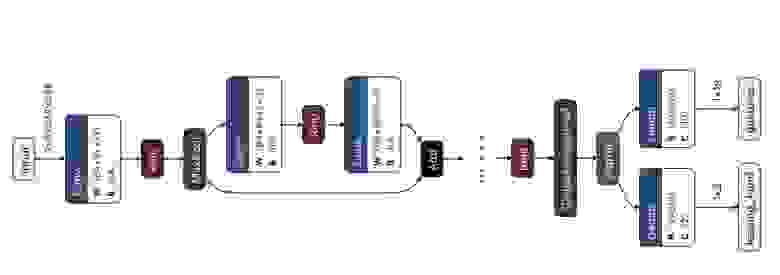 Граф классификатора в Netron
Граф классификатора в Netron
Для демонстрации работы системы распознавания жестов обучен легковесный детектор SSDLite_MobileNetV3. Все вычисления проводились на платформе ML Space и кластере суперкомпьютера Сбера «Christofari» с использованием от 1 до 4 GPU Tesla V100. Вы можете получить тестовый доступ и грант на обучение моделей на платформе ML Space по ссылке.
Классификаторы обучались на вырезанных боксах кистей руки (в качестве гипер-параметра можно задать bbox_scale, который определяет масштабирование бокса вокруг кисти перед обрезкой), в то время как детектор обучается на полном кадре и пытается найти на изображении бокс и предсказать его класс. Модели обучались с нуля (за исключением предобученного ViT-B/32) с базовыми настройками SGD с моментом: batch-size = 32–64, learning rate = 0.005, momentum = 0.9, epochs = 100. Никаких аугментаций и дополнительных техник по улучшению качества нейронных сетей не проводилось — обученные модели выступают как бейзлайны, от которых можно стартовать в своих исследованиях. Финальная матрица ошибок для ResNeXt-101:
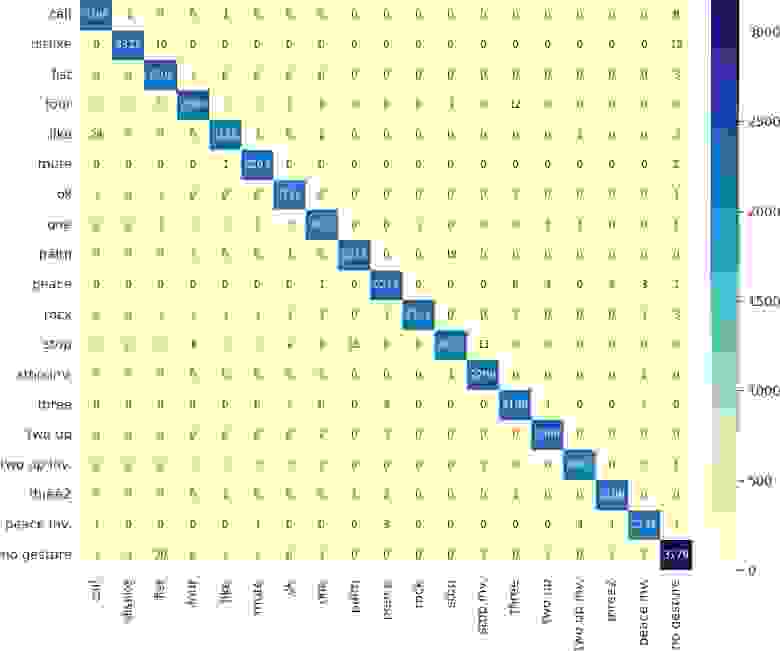 Матрица ошибок для ResNeXt-101
Матрица ошибок для ResNeXt-101
Датасет заранее разбит на тренировочную и тестовую выборки, где ~28–30К изображений на класс попали в обучающий сет, а ~2К изображений — в тестовый. Тренировочная выборка также разбивается на обучающую и валидационную по уникальному идентификатору пользователя user_id, но это разбиение регулируется путём выбора необходимой пропорции как гипер-параметр. В таблице представлено разбиение датасета на выборки по каждому классу.
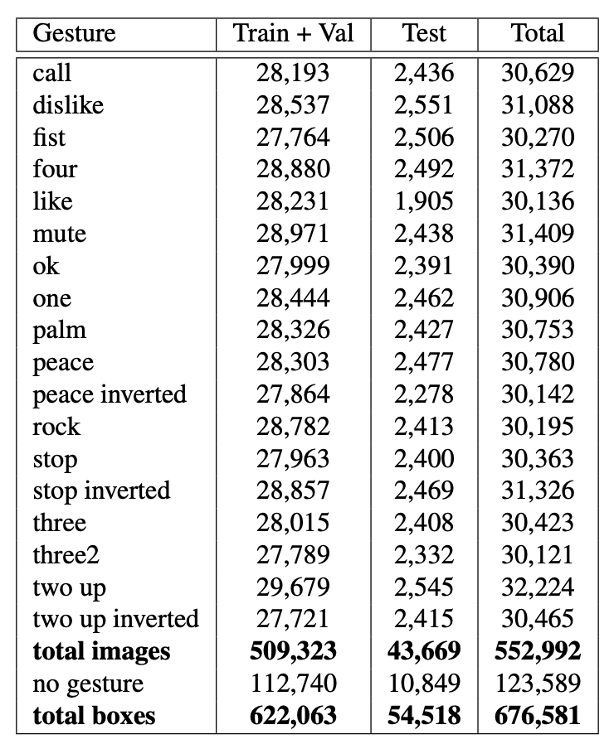 Общее число жестов в train / test выборках
Общее число жестов в train / test выборках
Заключение
В этой статье мы представили большой датасет HaGRID, который можно использовать в системах распознавания жестов. Все изображения и разметка открыты и доступны по ссылкам ниже. В будущих релизах мы планируем расширить жестовую корзину и перейти к датасетам на базе видео. Будем рады получить фидбек, а также мы готовы к совместным проектам!
Коллектив авторов: Александр Капитанов @hukenovs, Карина Кванчиани @karinakvanchiani, Андрей Махлярчук@makhliarchuk. Отдельное спасибо Алёне @alenusch за помощь и советы!
Ссылки
