Hadoop и автоматизация: Часть 2
Привет, Хабрапосетители!  Продолжаю свою «развеселую» серию статей, посвященных знакомству с Hadoop и автоматизации развертывания кластера.
Продолжаю свою «развеселую» серию статей, посвященных знакомству с Hadoop и автоматизации развертывания кластера.
В первой части я вкратце описал, что нужно было достичь, какую архитектуру кластера построить и что представляет собой Hadoop-кластер с точки зрения архитектуры. Также, я рассмотрел, наверное, самую простую часть кластера — Clients, которая отвечает за постановку задач, предоставление данных для вычислений и получение результатов.Теперь настало время поговорить о части архитектуры кластера, которая представляет собой Masters —, а именно о HDFS и YARN.Приведу еще раз пример архитектуры, которую предстояло развернуть в приватное облако. Предназначалась она исключительно для тестовых нужд, реальная нагрузка данными не предусматривалась.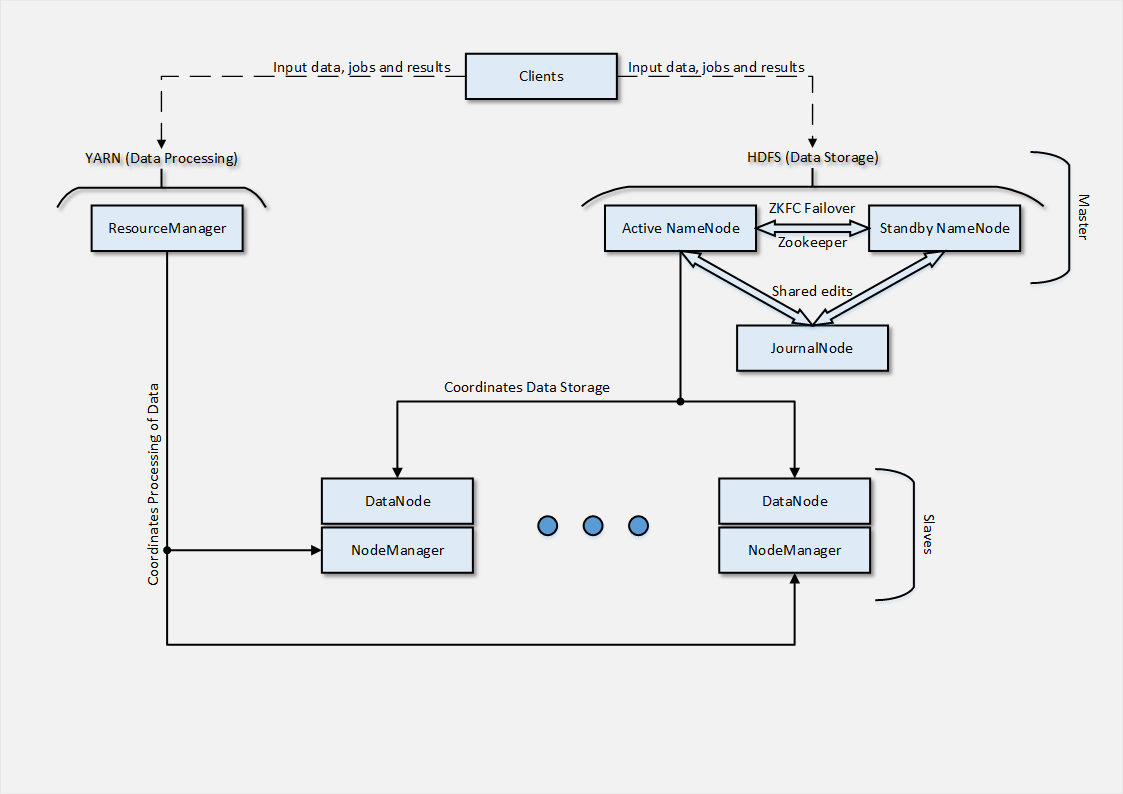 Итого, предполагалось, что у нас будет 2 узла, отвечающие за NameNode-роль, между которыми настроен HA+Failover на базе Zookeeper. NameNode в свою очередь отвечают за координацию данных, находящихся в нашей распределенной файловой системе HDFS. Именно NameNode владеют деревом директорий и следят за файлами, распределенными по нашему кластеру. Сами по себе, NameNode-узлы не хранят данные, т.к. для этой роли у нас есть Slaves.JournalNode, в свою очередь, необходима нам в случае, если мы реализуем High Availability на базе QJM (Quorum Journal Manager), суть которого состоит в том, что для синхронизации между Active и Stanbdy NameNode используется выделенные виртуальные машины (JournalNode), содержащие списки изменений в HDFS. Логи этих изменений доступны обоим NameNode, соответственно в любом из случаев failover-а мы достигаем синхронизации наших NameNode-узлов.Другой вариант High Availability — с использованием NFS/NAS. Суть примерна та же — существует «монтируемое» по сети хранилище, в которое пишутся все т.н. shared edits, упомянутые логи изменений в HDFS.За YARN в нашем случае отвечает 1 узел — ResourceManager, который управляет задачами, вычислениями, распределяет вычислительные ресурсы между заданиями, а также отвечает за принятие и постановку заданий на выполнение.
Итого, предполагалось, что у нас будет 2 узла, отвечающие за NameNode-роль, между которыми настроен HA+Failover на базе Zookeeper. NameNode в свою очередь отвечают за координацию данных, находящихся в нашей распределенной файловой системе HDFS. Именно NameNode владеют деревом директорий и следят за файлами, распределенными по нашему кластеру. Сами по себе, NameNode-узлы не хранят данные, т.к. для этой роли у нас есть Slaves.JournalNode, в свою очередь, необходима нам в случае, если мы реализуем High Availability на базе QJM (Quorum Journal Manager), суть которого состоит в том, что для синхронизации между Active и Stanbdy NameNode используется выделенные виртуальные машины (JournalNode), содержащие списки изменений в HDFS. Логи этих изменений доступны обоим NameNode, соответственно в любом из случаев failover-а мы достигаем синхронизации наших NameNode-узлов.Другой вариант High Availability — с использованием NFS/NAS. Суть примерна та же — существует «монтируемое» по сети хранилище, в которое пишутся все т.н. shared edits, упомянутые логи изменений в HDFS.За YARN в нашем случае отвечает 1 узел — ResourceManager, который управляет задачами, вычислениями, распределяет вычислительные ресурсы между заданиями, а также отвечает за принятие и постановку заданий на выполнение.
Развертывание HDFS <Лирическое отступление>Стоит отметить, что изначально идея автоматизации процессов развертывания кластера Hadoop выглядела достаточно экзотической, в виду достаточно «нежного» характера оного (хотя может быть это лично мой опыт…). Что я имею ввиду? При автоматизации выяснилось, что малейшие отклонения от документации приводили к большому количеству вопросов либо выявлению проблем, ранее задокументированных в JIRA разработчиков Hadoop дистрибутивов.Одним словом, cookbook получился не самым приближенным к «best practices» в моем понимании, т.к. он содержит приличное количество Bash кода, ресурсов execute и только иногда (где возможно) использует Ruby DSL и ресурсы Chef.Также не давало покоя идея о том, что существует Apache Ambari — нативная система управления Hadoop кластером. Но опять же — это не наш метод, да и я хотел разобраться в процессе без помощи стороннего ПО.Пришло время немного углубиться в процесс развертывания и код cookbook-а, который будет отвечать за автоматизацию процесса развертывания кластера.Я упоминал в первой статье, что cookbook, который я писал, был основан на Community наработках, вокруг которых я создавал wrapper. На самом деле, не все выходило гладко, т.к. в версии community cookbook-а, доступной на момент начала моей работы — было несколько проблем, порой очень досадных — опечатка, неправильная команда и прочие мелочи (надо отдать должное разработчику, который очень быстро реагировал на мои скромные contribution и постоянные вопросы).На самом деле, наработки сообщества были отличным фундаментом для того, чтобы начинать работу, добавляя при возможности какие-то свои решения.Что ж, начал я с развертывания NameNode и механизма HA+Failover. Данный процесс для узлов с ОС Linux можно описать следующим образом:
Установка пререквизитов в виде Java; Добавление репозиториев с пакетами Hadoop дистрибутива; Создание костяка директорий, необходимых для установки NameNode; Генерация файлов конфигурации на основе шаблона и атрибутов cookbook-а Установка пакетов дистрибутива (hdfs-namenode, zookeeper-server, etc) Обмен ssh-ключами между NameNode (необходимо для контролируемого Failover); В зависимости от роли узла (Active/Standby) — запуск процессов для работы кластера (далее — подробнее); Регистрация статуса процесса развертывания. Запуск процессов, необходимых для того, чтобы NameNode функционировала, состоял из следующих шагов: chown директорий, относящихся к Hadoop-компонентам (например, директории инсталяции HDFS NameNode) — очень важный шаг, т.к. в большинстве случаев приводит к проблемам; hdfs namenode -format, который форматирует и инициализирует директорию, указанную как dfs.namenode.name.dir; service zookeeper-server start — запуск Zookeeper сервера, используемого при failover hdfs zkfc -formatZK — создает znode (Zookeeper Data Node, иными словами — участник failover процесса); $HADOOP_PREFIX/sbin/hadoop-daemon.sh --config /etc/hadoop/conf.chef/ --script hdfs start namenode» — для запуска Active NameNode процессаилиhdfs namenode -bootstrapStandby — для запуска Standby NameNode процесса на узле; $HADOOP_PREFIX/sbin/hadoop-daemon.sh --config /etc/hadoop/conf.chef/ start zkfc — для запуска ZooKeeper Failover Controller процесса; node.set['hadoop_services']['already_namenode'] = true — установка статуса процесса, Ruby-код, который устанавливает атрибут значение атрибута узла. После того, как Chef успешно отработал на 2 узлах, выполняя данные шаги — можно приступать к процессу верификации установки. Есть несколько вариантов проверки, которые лучше всего использовать: Открытие веб-страницы NameNode DFS Health, доступной, по умолчанию, по такому адресу — FQDN:50070 — в которой предоставляется данные о роли узла (Active или Standby), о доступных Slaves, а также различная системная информация и логи; Использование утилиты jps (предоставляемой в дистрибутиве Hadoop и являющейся аналогом ps), в выводе которой должны присутствовать процессы NameNode, DFSZKFailoverController и QuorumPeerMain; Запуском локальных утилит hdfs haadmin -healthCheck и hdfs haadmin -getServiceState, результат которых, по стуи, приведен на веб-странице в более детальном формате; Для верификации процесса Failover можно вызвать контролируемый failover-механизм следующим образом: hdfs haadmin -failover, в результате которого узлы NameNode должны поменяться ролями Active/Standby. Успешным результатом является связка 2 узлов, один из которых принимает роль Active NameNode, другой — Standby NameNode; между узлами (znode) установлен контроль Zookeeper-а, который в состоянии провести failover-процесс; доступ к Slave-узлам и файловой системе (об развертывании Slave будет идти речь в следующей статье).Как уже упоминалось — High Availability нашего кластера может быть достигнуто 2 вариантами — с использованием NFS/NAS либо выделенного JournalNode-узла.В случае с NFS/NAS — все, что нам нужно, это иметь возможность «примонтировать» хранилище по сети к нашим NameNode. Хранилище должно быть доступно 24/7 (крайне желательно), доступно с низкими задержками, а также быстро реагировать на операции read/write по сети.В случае с использование JournalNode — необходимо выделить узел, на который инсталируется пакет JournalNode из дистрибутива Hadoop. За конфигурацию в базовом варианте отвечает 2 параметра: dfs.journalnode.http-address — параметр, который указывает FQDN и порт, на котором запущен сервис JournalNode); dfs.journalnode.edits.dir — директория, в которую складываются логи событий, происходящих в HDFS.
Развертывание YARN YARN-часть кластера представлена в нашей архитектуре ResourceManager-узлом, который работает с задачами и ресурсами для их выполнения. Процесс развертывания данного узла выглядит проще, чем у NameNode: Установка пререквизитов в виде Java; Добавление репозиториев с пакетами Hadoop дистрибутива; Создание костяка директорий, необходимых для установки NameNode; Генерация файлов конфигурации на основе шаблона и атрибутов cookbook-а Установка пакетов дистрибутива (hadoop-yarn-resourcemanager) Запуск процесса ResourceManager путем service hadoop-yarn-resourcemanager start; Регистрация статуса процесса развертывания. Для верификации успешного развертывания можно сделать следующее: Открытие веб-страницы ResourceManager, доступной, по умолчанию, по такому адресу — FQDN:8088 — в которой предоставляется данные о доступных Slaves, а также различная информация о задачах и ресурсах, выделенных на их выполнение; Использование утилиты jps (предоставляемой в дистрибутиве Hadoop и являющейся аналогом ps), в выводе которой должны присутствовать процесс ResourceManager; На этом по поводу Masters части у меня все. В конце следующей статьи я планирую выделить раздел, в котором опишу минимальные настройки кластера, которые являются НЕОБХОДИМЫМИ для запуска. Также, в следующей статье, я опубликую ссылки на свой скромный проект и полезную документацию, которой я пользовался в процессе создания оного.Всем спасибо за внимание! Коментарии и особенно поправки — очень приветствуются!
