Григорий Кошелев – А вы Кафку пробовали
Apache Kafka — распределённый программный брокер сообщений, применяемый в обработке в реальном времени данных большого объёма. К отличительным особенностям Apache Kafka можно отнести: надёжность, масштабируемость и высокую производительность. В докладе разберём основные архитектурные особенности и сценарии использования Apache Kafka. Рассмотрим неочевидные моменты и грабли, которые мы собрали на пути Востока.

Всем привет! Меня зовут Григорий! И сегодня мы поговорим про Kafka.
План у нас будет такой:
- Вначале я расскажу для чего нужна нам Kafka, что мы с ней делаем.
- Потом потихоньку начнем разбираться, как она устроена, т. е. введение в Kafka.
- Далее по архитектуре отдельных компонентов пробежимся.
- И самая интересная часть доклада — это какие-то неочевидности. По-хорошему здесь надо было писать «грабли, боль и страдания», но оставим немного интриги.
- А в конце подведем итоги. Сделаем выводы и поймем: надо ли с этим что-то делать и как вообще жить.
Содержание:
[TOC]
Зачем нам Kafka?
В какой-то момент у нас в компании появился проект Vostok.
Это тот инструмент, который позволяет масштабировать и разрабатывать микросервисную архитектуру с минимальными затратами. Т. е. он конкретно под проект Hercules заточен. Он нацелен на то, чтобы со всех приложений, со всех тысяч микросервисов уметь собирать логи, метрики, распределенные трассировки сетевого взаимодействия между сервисами.
И также мы хотим универсальное какое-то решение получить, чтобы наши пользователи, наши проекты могли передавать бизнес-события через такую трубу.
А также в нашей компании Kafka используется для поисковых и рекомендательных систем.

Т. е. у нас есть много источников различных интересных данных, по которым можно строить интересные штуки, рекомендательные системы. Kafka где-то это все агрегирует. На другом конце находится Spark, туда заливаются данные, вычисления происходят. А также поисковые движки могут стоят на другом конце.
Для первого проекта у нас используется Kafka версии 2 и выше, т. е. самую последнюю версию используем.
Почему мы это можем делать? Потому что у нас там Java stack.
Для рекомендательных систем используется Kafka версии 0.11, потому что нет клиента ни для Python, ни для DotNet для Kafka версии 1 и выше. У нас в компании основной stack — это DotNet, поэтому ребятам очень тяжело. И поэтому они старую Kafka использует.
В каждой версии Kafka есть свои баги, свои проблемы. И они либо перетекают из версии в версию, либо все-таки фиксятся. Может даже что-то меняться в архитектурном плане. И к этому надо быть готовым при апдейте своей версии.

Давайте разберемся, что такое Apache Kafka
Введение в Apache Kafka
Для тех, кто не поднимал сейчас руку, поясню, что у Kafka много компонентов. Первый из них — это producer. Producer — это тот, кто создает кучу сообщений и отправляет их куда-то.

На другом конце находится consumer. Они употребляют эти данные, что-то с ними делают.
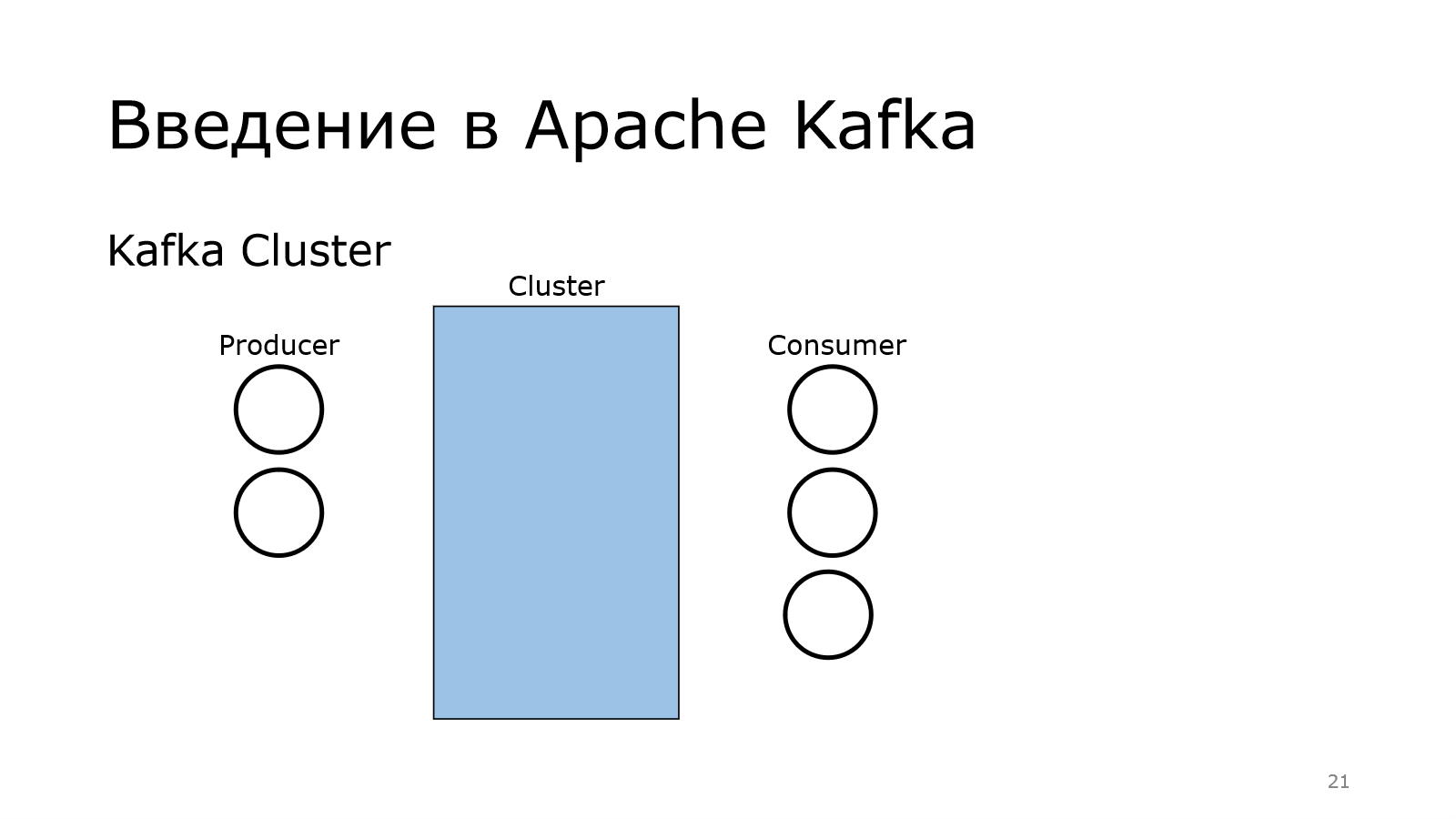
Передача осуществляется через кластер. Там у меня было написано, что Apache Kafka — это распределенный брокер сообщений. Получается, что у нас есть в кластере куча брокеров.
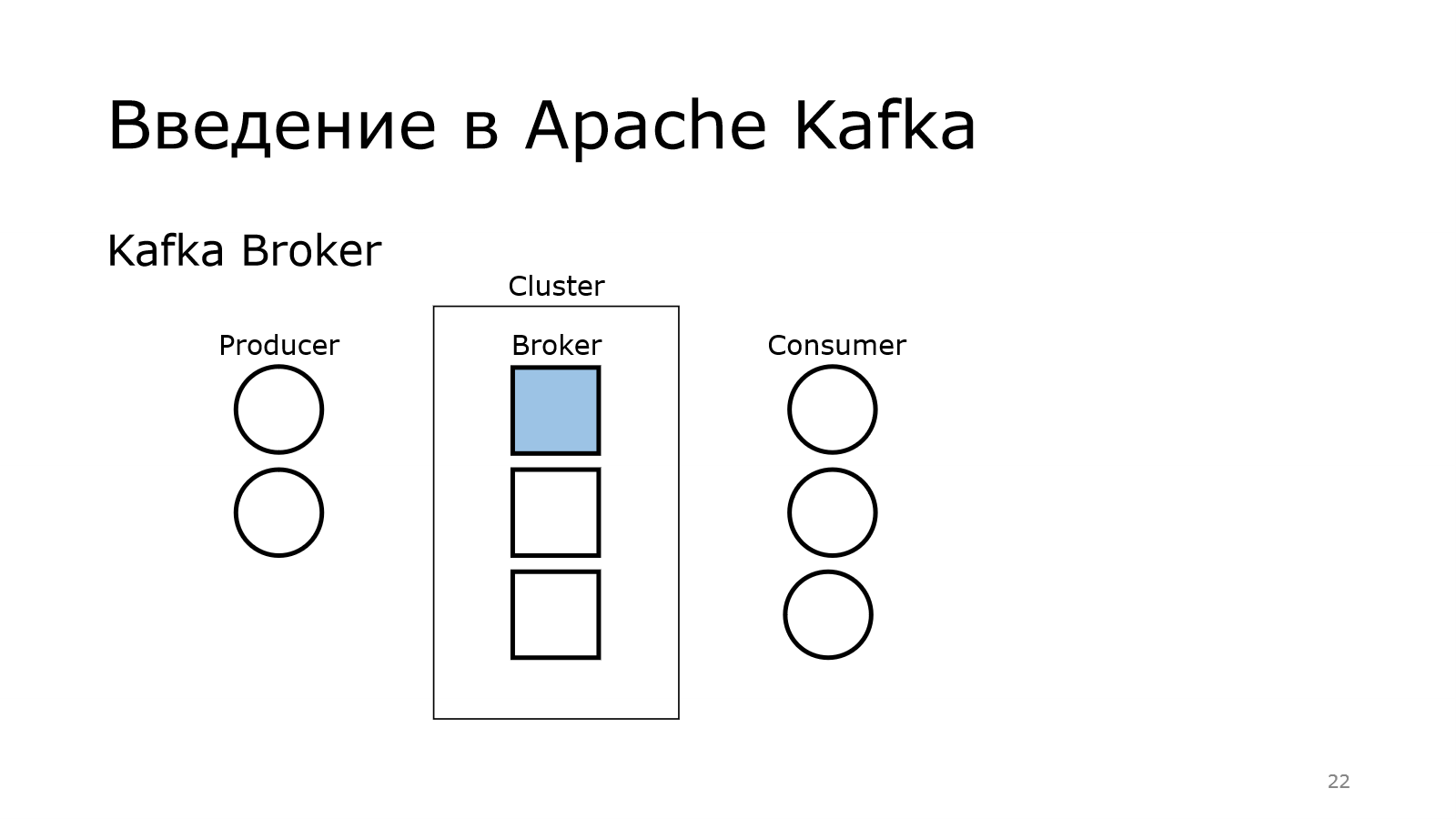
У нас в кластере есть куча брокеров.
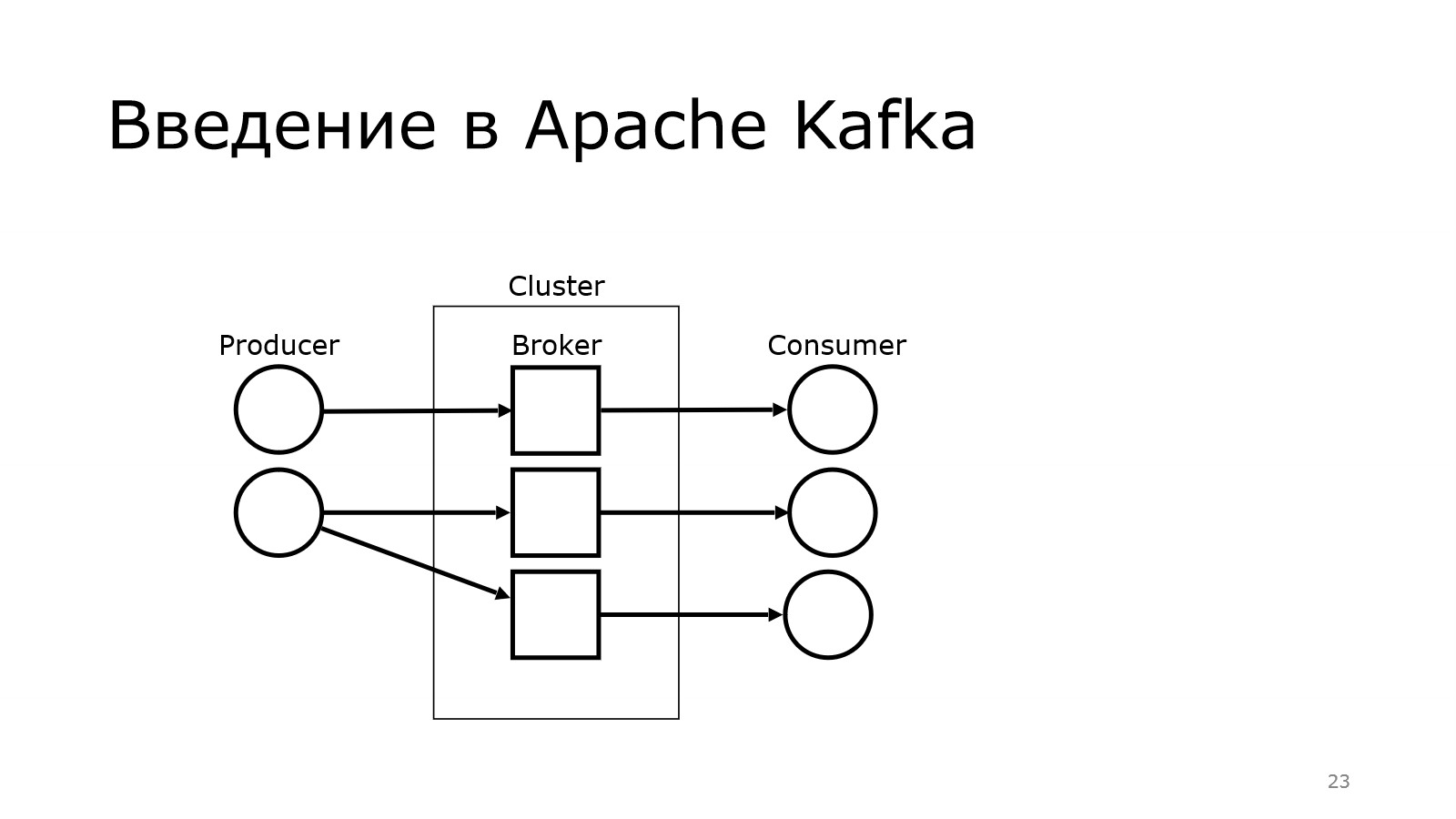
Передача сообщений осуществляется через них.
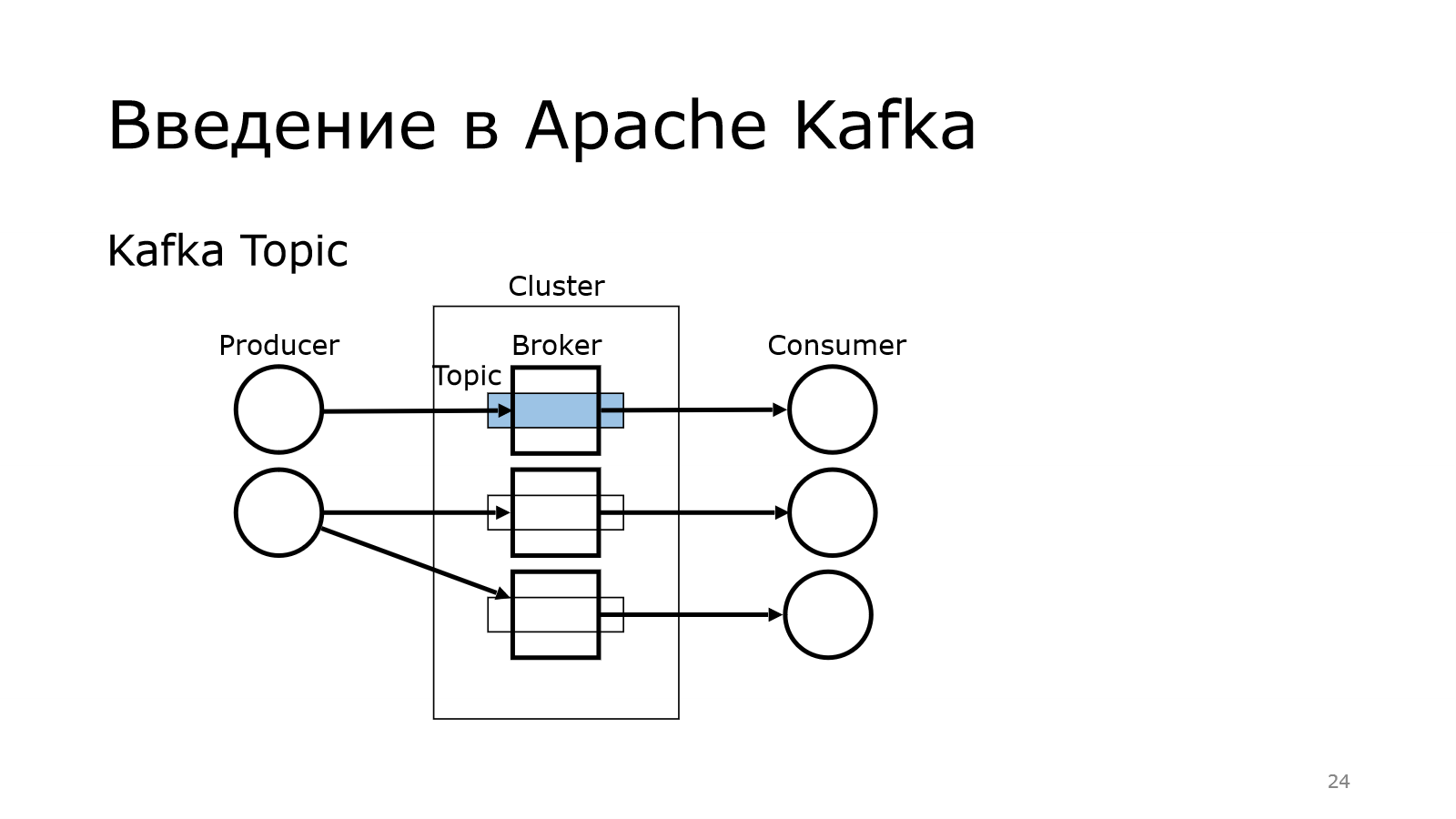
И там брокер выступает таким звеном, который позволяет от producer к consumer не напрямую данные передавать, а через такой топик. Опытный слушатель может сказать, что это обычный Message Queue. Обычный, но не совсем.

Там используется Publish-Subscribe, т. е. у нас просто продюсер пихает сообщение в топик, а consumers могут подписываться на них. И одни и те же сообщения могут читаться разными consumers.
И важно, что для чтения используется poll-механика, т. е. брокер не должен говорить: «Вот, consumer, тебе новое сообщение. Забери его». Каждый consumer должен прийти к Kafka и сказать: «Есть что-то новое?». И она отдает данные.
Такой подход лучше масштабируется, чем, когда сам брокер начинает вливать данные в consumers.
Архитектура Apache Kafka
- Topic
- Broker
- Producer
- Consumer
Мы увидели 4 важные вещи. Это топик, брокер, producer и consumer. Давайте по ним и пойдем в таком порядке.
Архитектура Kafka Topic

Топик — это логическая единица, которая связывает между собой producers, consumers. И есть какое-то физическое хранение. Каждый такой топик — это множество партиций.
В данном случае у нас топик с тремя партициями. В них записано сообщение. Что при этом важно?

- Сообщения всегда пишутся в конец партиции.

- Писать можно параллельно в несколько партиций одновременно. Они между собой никак не связаны, физически это разные вещи.

При этом у каждого сообщения есть свой номер, свой offset. Каждая партиция начинается с номера 0.
 И там они увеличиваются на единичку. Offset = 0
И там они увеличиваются на единичку. Offset = 0

Все вроде бы просто.

Но партиция может стать очень большой. Она может начать весить десятки, сотни гигабайт. А видео одного такого файла не похоронить, поэтому каждая партиция делится на сегменты.
Вот у нас такая длинная-длинная партиция.

Она делится на кусочки.

Они примерно одинакового размера, т. е. 1 сегмент, 2 сегмент и т. д.

И есть последний сегмент.

Последний сегмент еще по-другому называется активным сегментом. Это тот сегмент, в который можно писать данные. Благодаря этому сохраняется правило, что пишем всегда в конец партиции. Это логично.

У нас каждый такой сегмент начинал с некоторого сообщения.
Вот такой базовый offset, с которого начинается каждый из сегментов.

Он состоит из четырех вещей. Про базовый offset уже понятно.

Он используется для того, чтобы называть файлики, которые лежат в файловой системе. И также data, index, timeindex — это три файла.
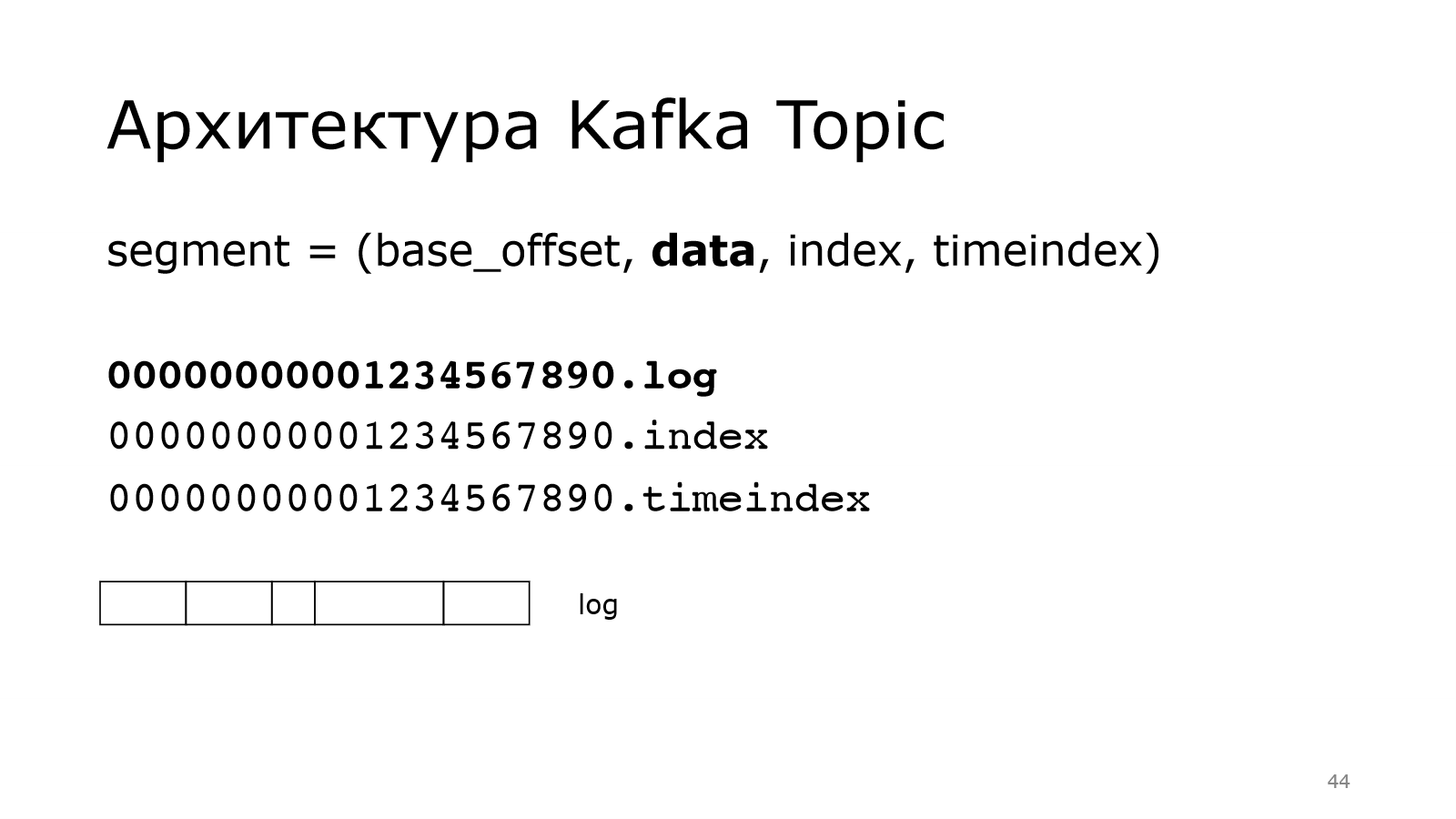
Data — это наши данные, т. е. есть какой-то здоровый файл. И в нем лежат сообщения. Сообщения могут быть разного размера. Kafka все равно, складывайте, что хотите в нее.
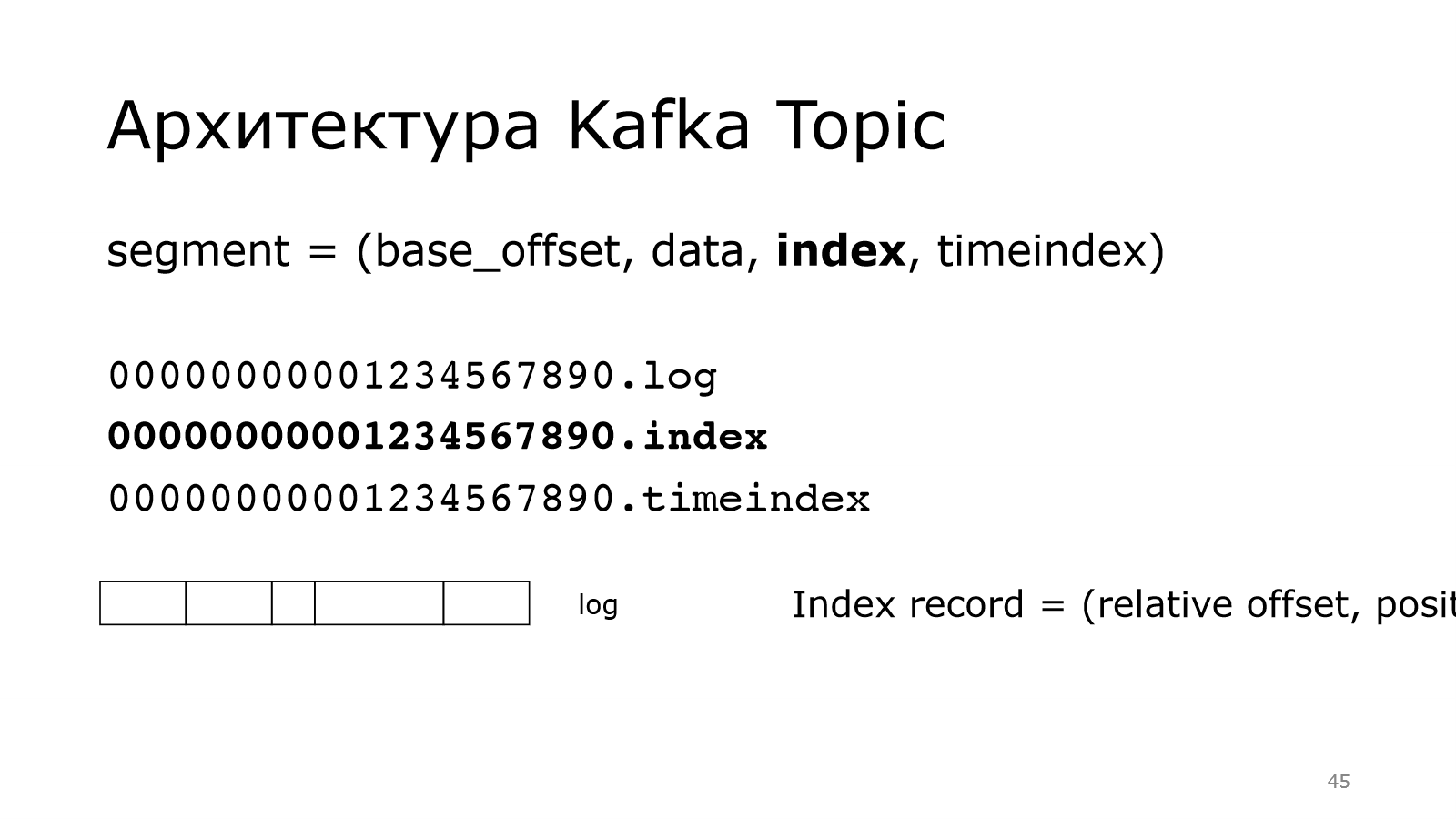
Что такое index? Если мы хотим найти какое-то сообщение по смещению, то надо уметь это делать быстро. Как раз index позволяет это делать.

Он выглядит следующим образом. Каждая запись в index занимает в общей сложности 8 байт. Там два int: relative offset, positon.
Relative offset — это смещение от начала сегмента.
Берем offset сообщения, вычитаем базовый offset, получаем вот это число.
Сообщений в партиции могут быть миллиарды, соответственно базовый offset будет большой и не влезет в int. Но у нас сегмент небольшой, поэтому относительный offset влезет в int.
Тоже самое с position. Position — это просто физическое смещение данного сообщения в этом лог-файле.

Получается, что у нас растет relative offset на единичку, позиция смещается относительно размера предыдущих сообщений.

Он потихоньку растет-растет.

И так можно будет потом искать по этому индексу. Мы знаем номер сообщения, который мы хотим найти. Быстро через базовый offset находим relative offset и в индексе смотрим его позицию, и можно забирать.
Понятно, что там не все сообщения хранятся, а только какие-то выборочные. Там есть шаг, с котором их можно сохранять в индекс. Это все настраивается в Kafka.

Похожим образом устроен timeindex. Для чего он нужен? Каждое сообщение в Kafka имеет какую-то метку времени. И неплохо бы уметь искать по этой ветке времени. Timeindex решает эту задачу.
Архитектура Kafka Broker
Вернемся к кластеру, к брокерам. Кластер — это множество брокеров.
Один из них отвечает за контроллер.

Он координирует работу кластера. О его назначении мы поговорим чуть попозже.

У нас есть топик, который состоит из нескольких партиций. В данном случае мы создали топик на кластере из трех брокеров. И партиции распределились по кластеру.
При этом Kafka надежная, у нее есть replication factor для каждого топика. И мы можем сказать, что он равен трем.

Это означает, что каждая партиция должна иметь три копии. У нас три копии, поэтому на каждом брокере будет по копии.
Вот у нас 4 партиции на одном, на втором и на третьем.
При этом Kafka позволяет добавлять новые партиции к топику.

Поэтому, если у нас данных станет много, можно увеличить единицу параллелизации.
Партиция — это единица параллелизации, поэтому можно добавить еще одну. И там producers стало больше, которые могут писать с той же эффективностью.
Теперь поговорим о роли контроллера. Дело в том, что контроллер должен назначить лидера. Каждая партиция должна иметь своего лидера.
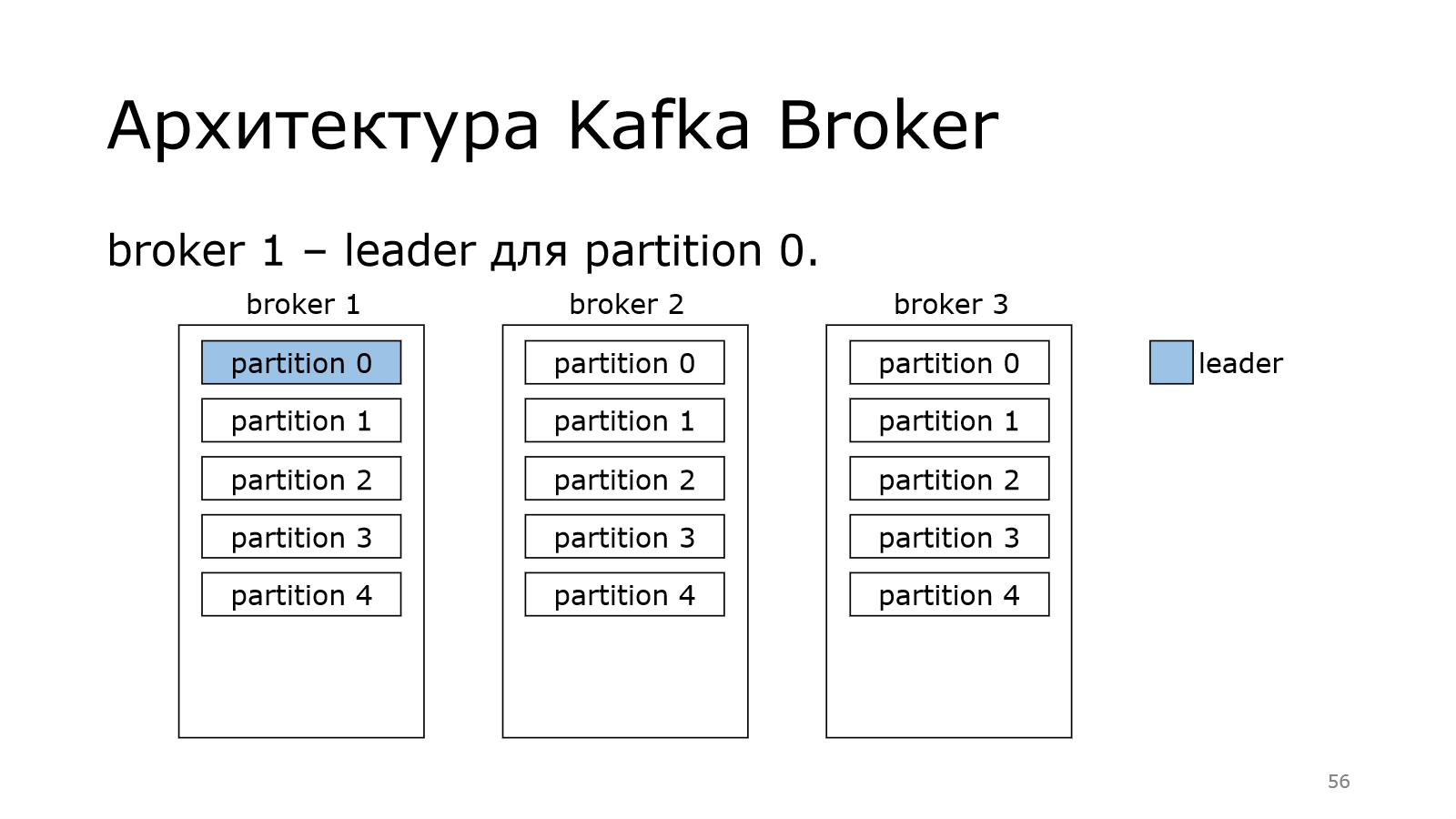
Лидер — это тот брокер, который отвечает за запись в конкретную партицию. Не может быть у одной партиции несколько лидеров. Иначе каждый из них что-то написал бы свое, а потом это никак нельзя было бы соединить в какую-то одну последовательную партицию.

И каждый брокер может стать лидером у некоторых партиций.
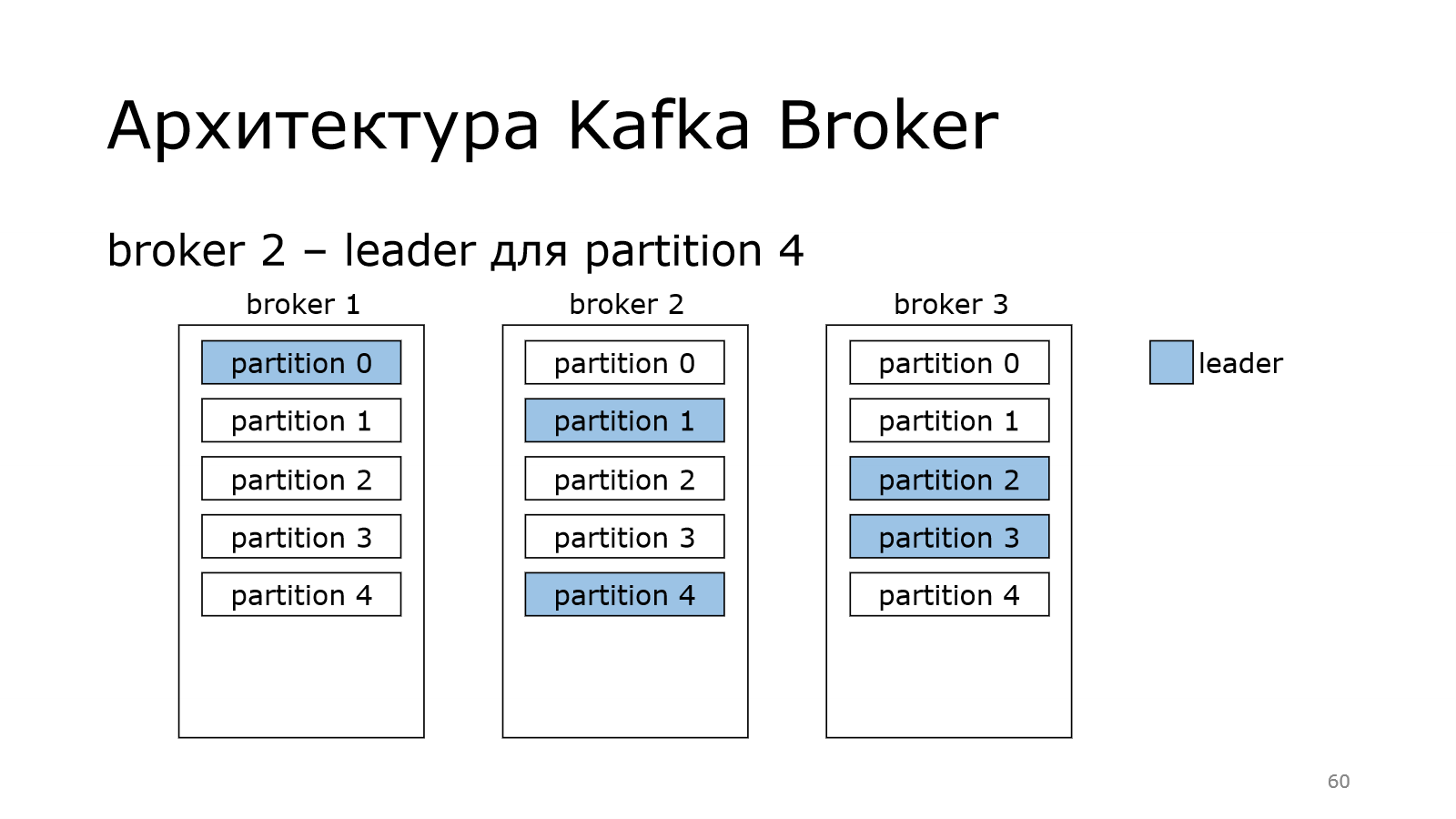
В данном случае получилось так, что у нас на одном брокере лидерство двух партиций. На одном всего одна.
Kafka старается это равномерно распределять по кластеру и балансировать, чтобы не получилось так, что один брокер пыхтит и в себя все пишет-пишет, а остальные отдыхают. Чтобы такого не было, она равномерно пытается распределить.
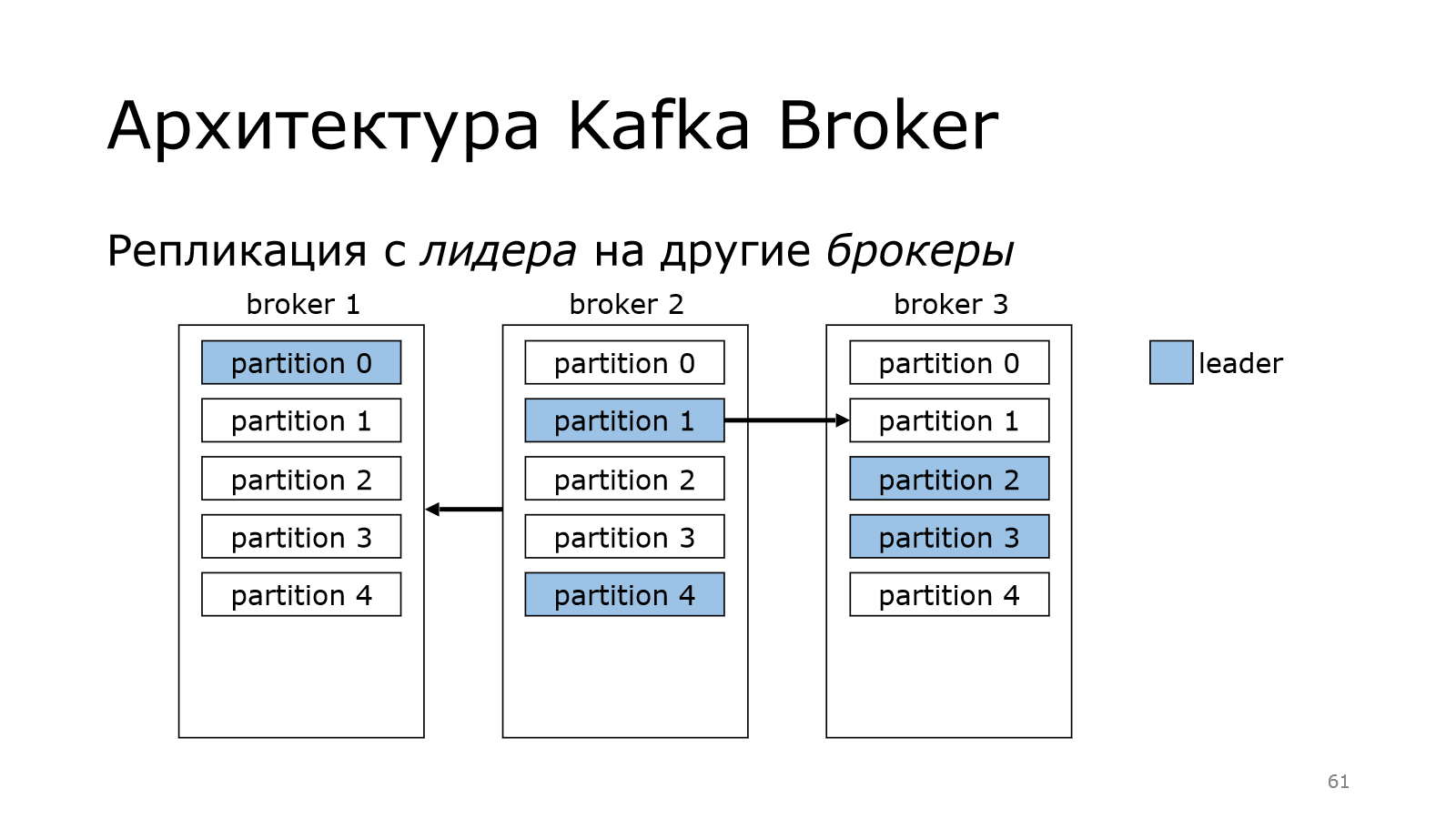
Что происходит дальше? Данные, которые пишутся в лидера, должны быть распределены по репликам. Те, кто в себя тащат данные из лидера, называются follower. Они следуют за ним и потихоньку подкачивают к себе данные.
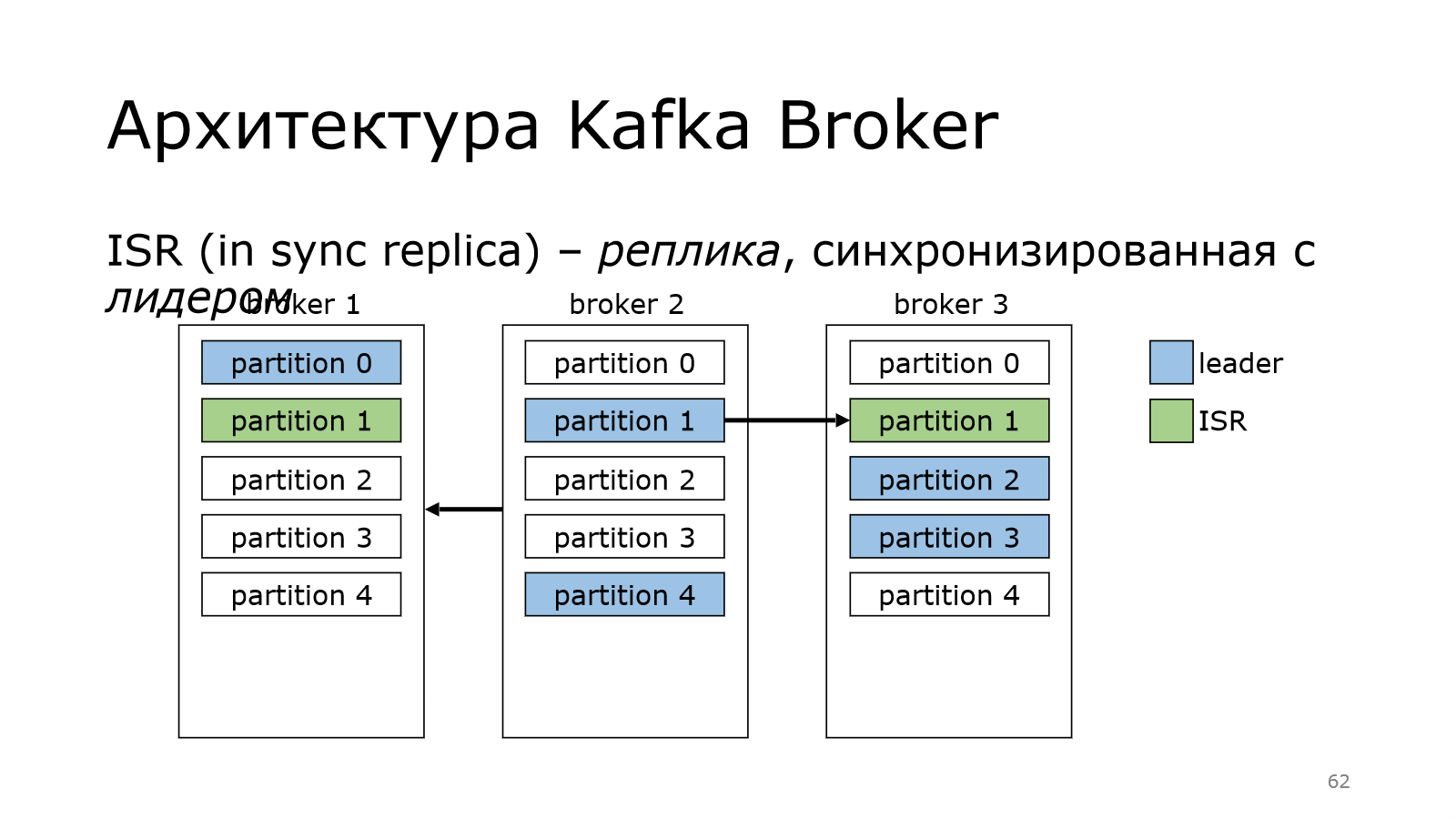
После того, как они сохранили в себе все данные, они становятся крутыми, они становятся in sync replica. Это реплика, которая синхронизирована с лидером.

И в идеале у нас весь кластер должен быть синхронизирован, т. е. все реплики должны быть в списке in sync replica.
Понятно, что какая-то из реплик может выпасть. Если это follower, то ничего страшного? Почему? Потому что follower ходит в лидер за данными. И подумаешь, если один из них перестанет ходить.

А что произойдет, если сам лидер пропадает?
У нас был лидер в брокер 3 на партиции 2, а потом пропал. В этот момент мы данные писать не можем, потому что лидера нет.

Kafka не теряется, она выбирает нового лидера. И за это отвечает контроллер. Все, отлично.
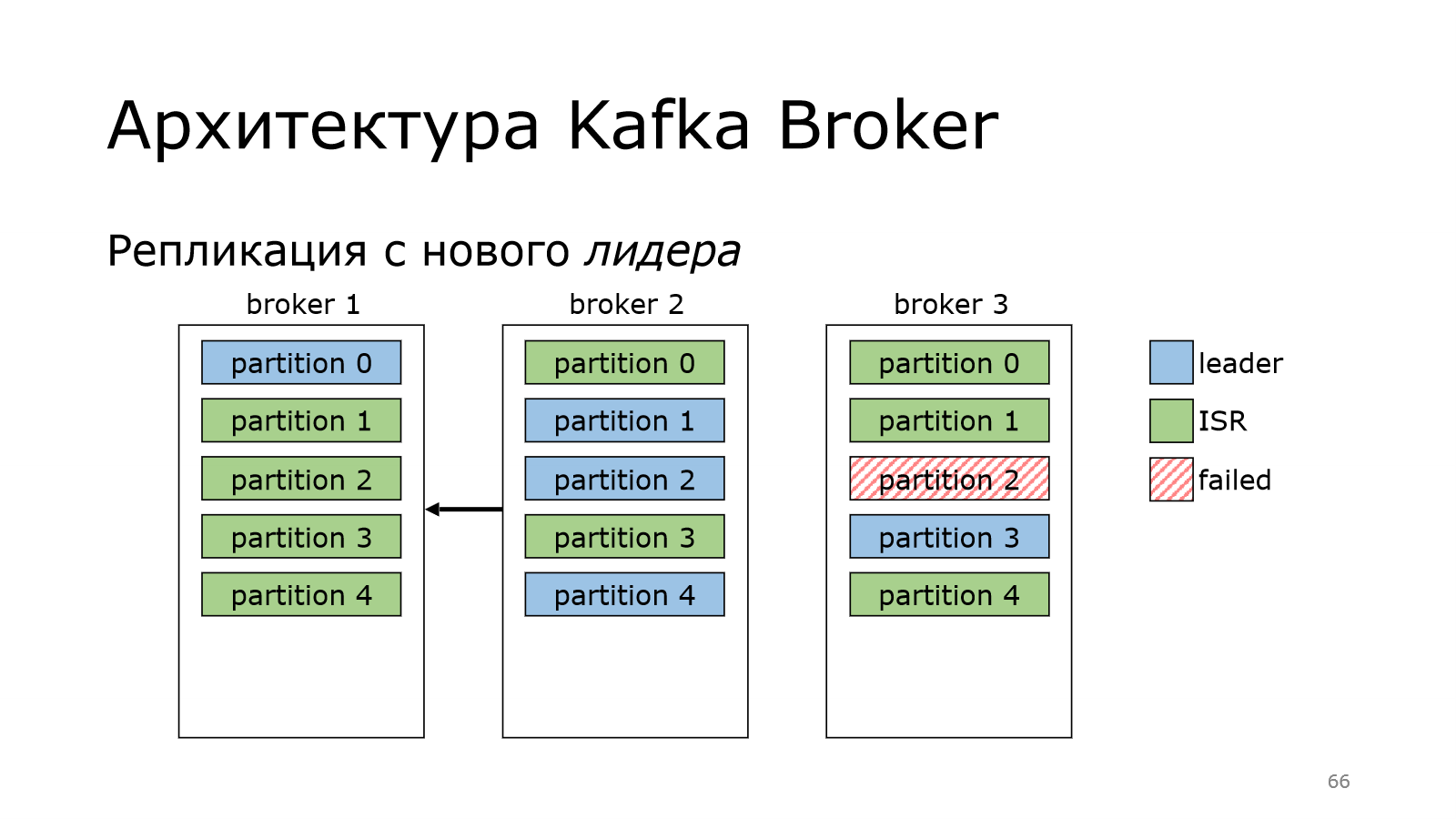
Теперь с него можно реплицировать данные по другим брокерам. Но в партиции старый лидер может ожить.

Ожил, у него все хорошо, но он успел отстать по данным, потому что лидерство сменилось, появились новые данные.
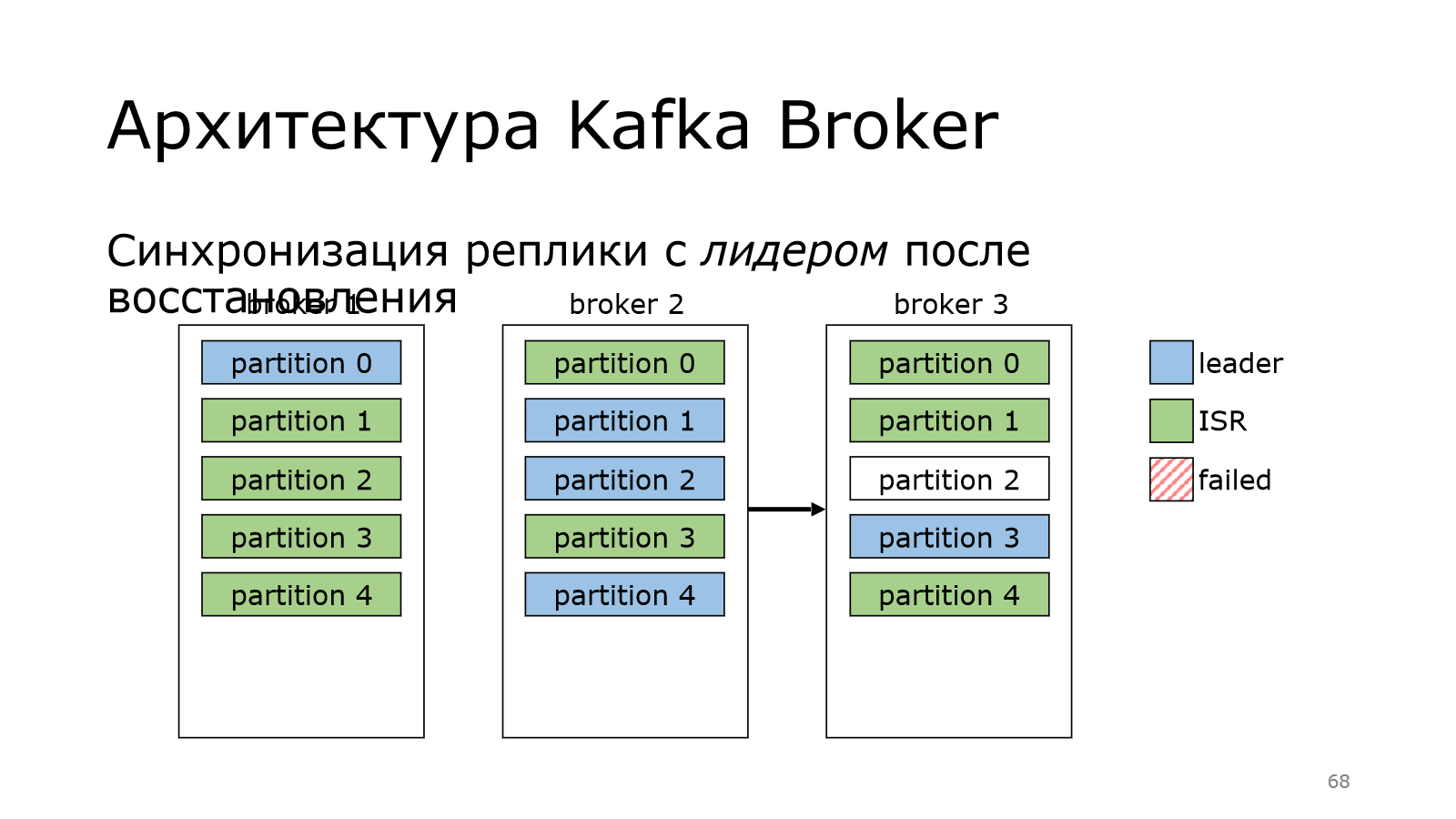
И поэтому он вынужден уже реплицироваться с нового лидера. Он это сделал. Кластер восстановился. И все хорошо.
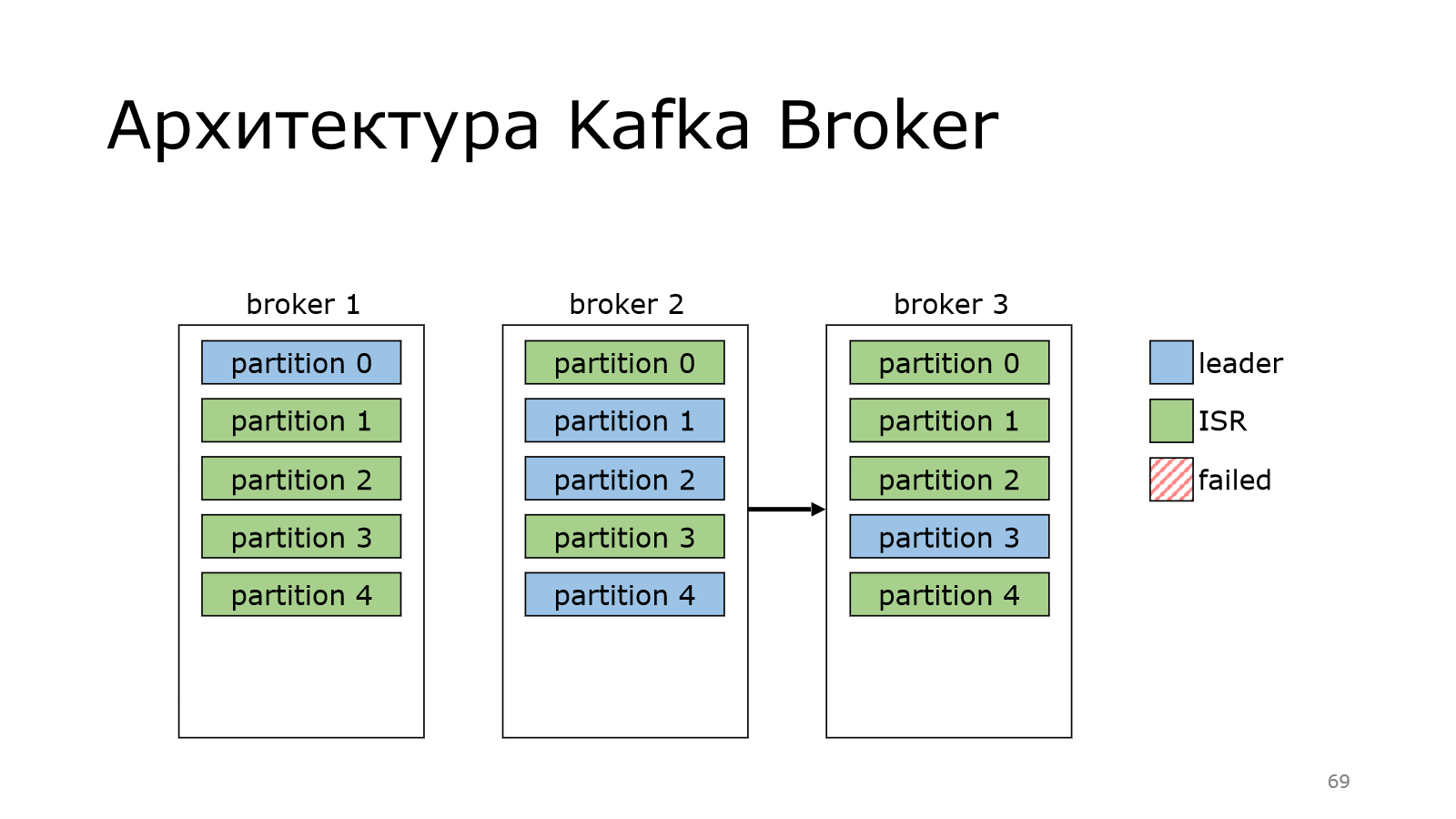
И потом в Kafka случается магия, которая — раз и возвращает лидера обратно.

Для чего это сделано? Если мы последовательно будем перезапускать ноды, мы можем взять и согнать лидерство на одного брокера. Это не очень хорошо. Он будет отвечать за всю запись, а остальные брокеры будут отдыхать. И чтобы этого не было Kafka периодически умеет это дело перебалансировать. И у нее есть куча настроек, которые это дело регламентируют.
Архитектура Kafka Producer

Теперь пойдем к продюсеру, т. е. поговорим о том, как данные пишутся.
Начнем с сообщения. Сообщение можно представлять, что это пара ключ, значение.
При этом для Kafka и ключ, и значение — это просто массив байтов, в который можно писать все, что угодно. Продюсер должен знать, что он туда сериализует. И consumer должен знать, что он туда десериализует.

Зачем нужен ключ? Ключ используется для определения номера партиции, куда положить данные. Используется MurmurHash в том случае, если ключ есть.

Если ключа нет, то используется round robin, когда продюсер перебирает партиции по кругу, т. е. дошел до конца, начинает с нулевой и т.д.
И при этом важный point: куда положить данные решает продюсер. Т. е. не брокер как-то там сам определяет и сохраняет, а именно продюсер. Продюсер должен всегда писать в лидера. Соответственно, он пишет в конкретного брокера, в конкретную партицию. Это важно.
Про ключ я уже сказал, что Kafka это интерпретирует как массив байтов и так же сохраняет в лог, как и другую метаинформацию. Другая метаинформация — это offset, timestamp и т. д.

У нас есть одна партиция. И у нее три реплики. Они синхронизированы.
Одна из них является лидером. В каждой по 9 записей.
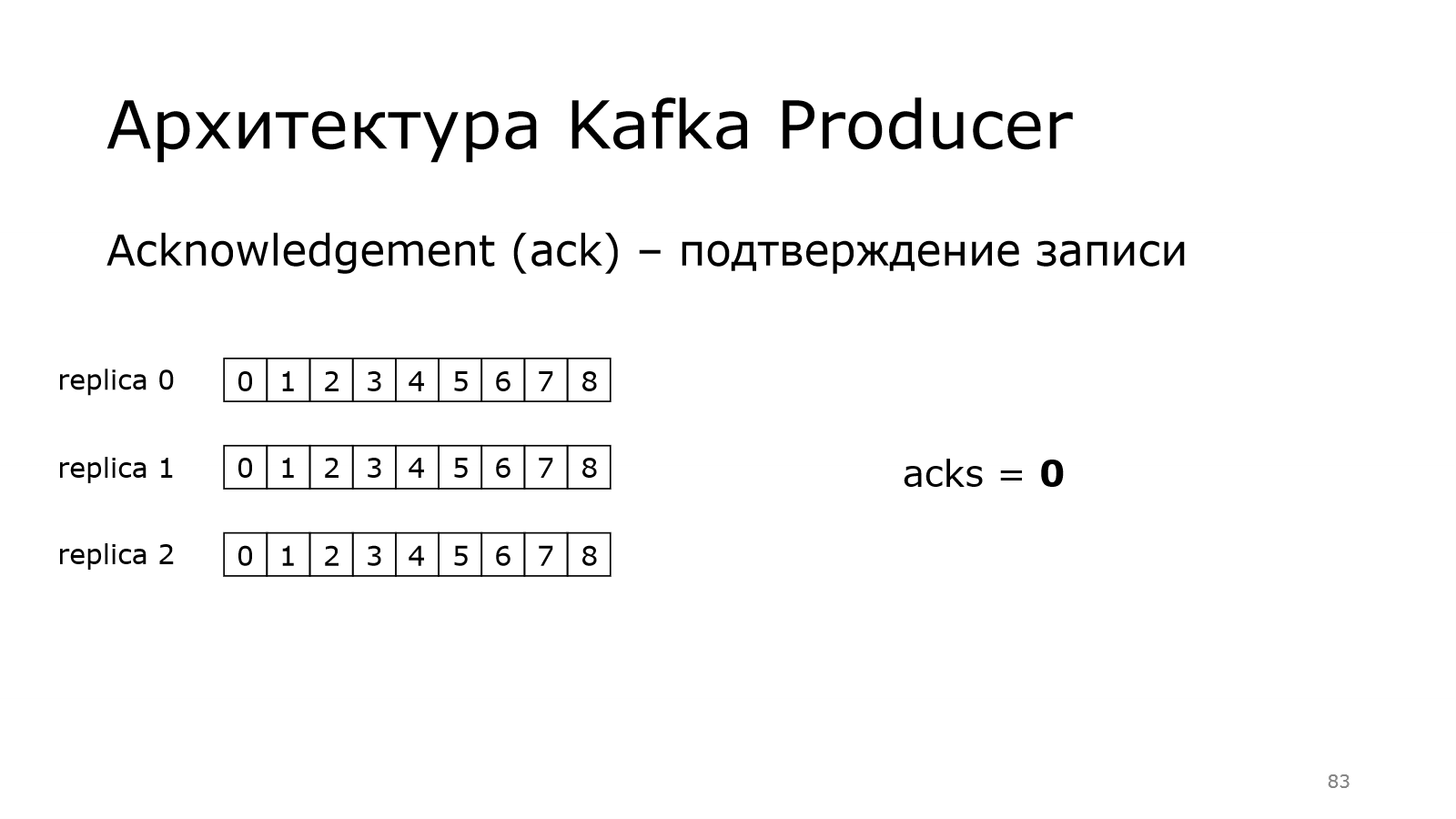
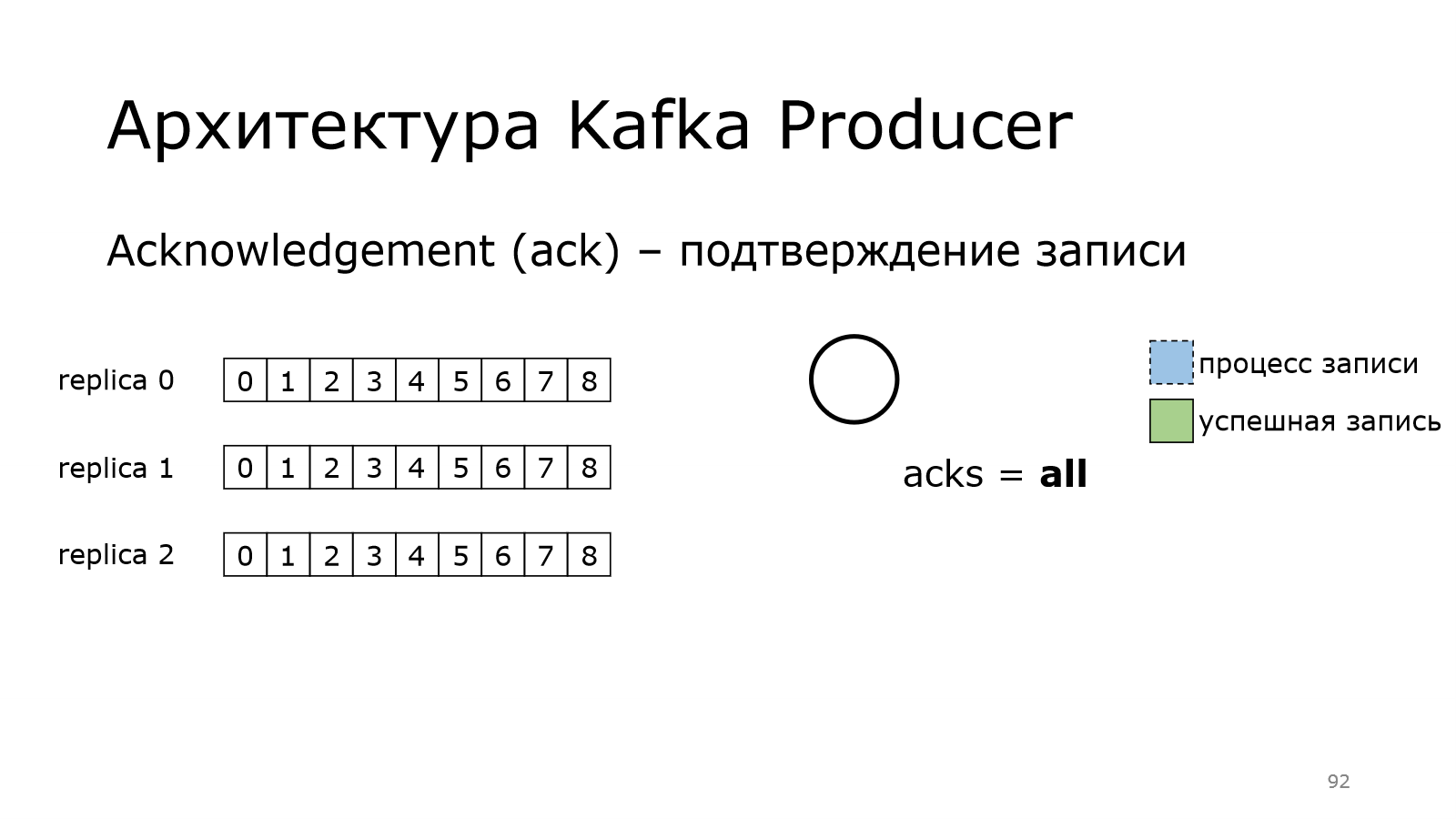
Теперь посмотрим, как работает продюсер. Есть такая штука в Kafka, как acknowledgement, т. е. подтверждение записи. Продюсер должен убедиться, что данные записались

Нулевой уровень предоставляет нулевые гарантии. Как это работает?
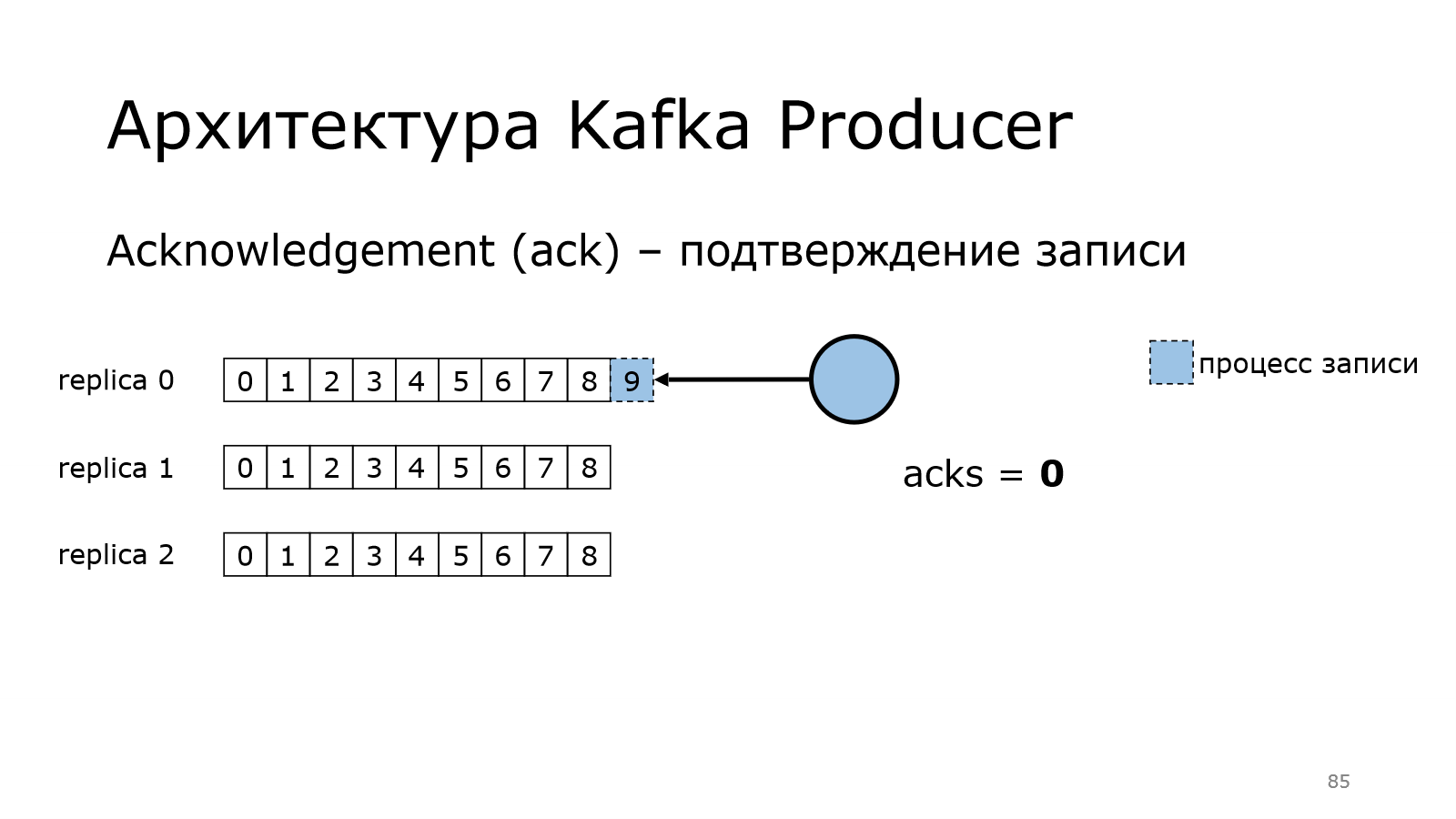
Продюсер начинает писать сообщение в одной из партиции. Он передал все данные и говорит, что у него все хорошо.

Ему не надо никакого подтверждения.
При этом данные могли записаться в Kafka, а могли не записаться. Там могла быть какая-то проблема. И лидер в реплике 0 мог не сохранить данные. И тут уже может быть потеря данных. Это нужно понимать.

Поднимаем уровень. Уровень гарантии стал 1.
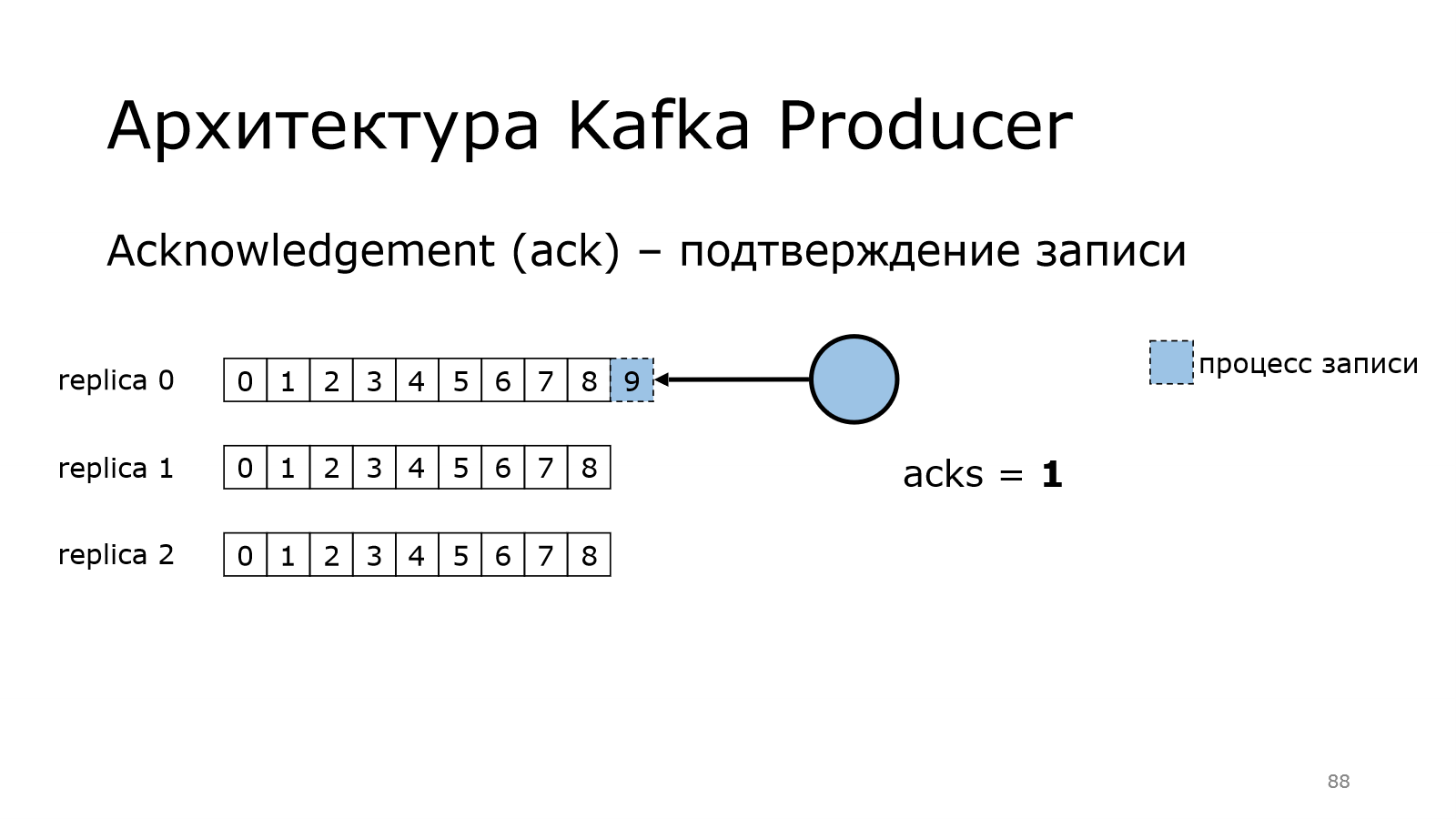
Что изменилось? Теперь продюсер пишет данные. Он передал все данные в Kafka. Kafka пишет. Он ждет.
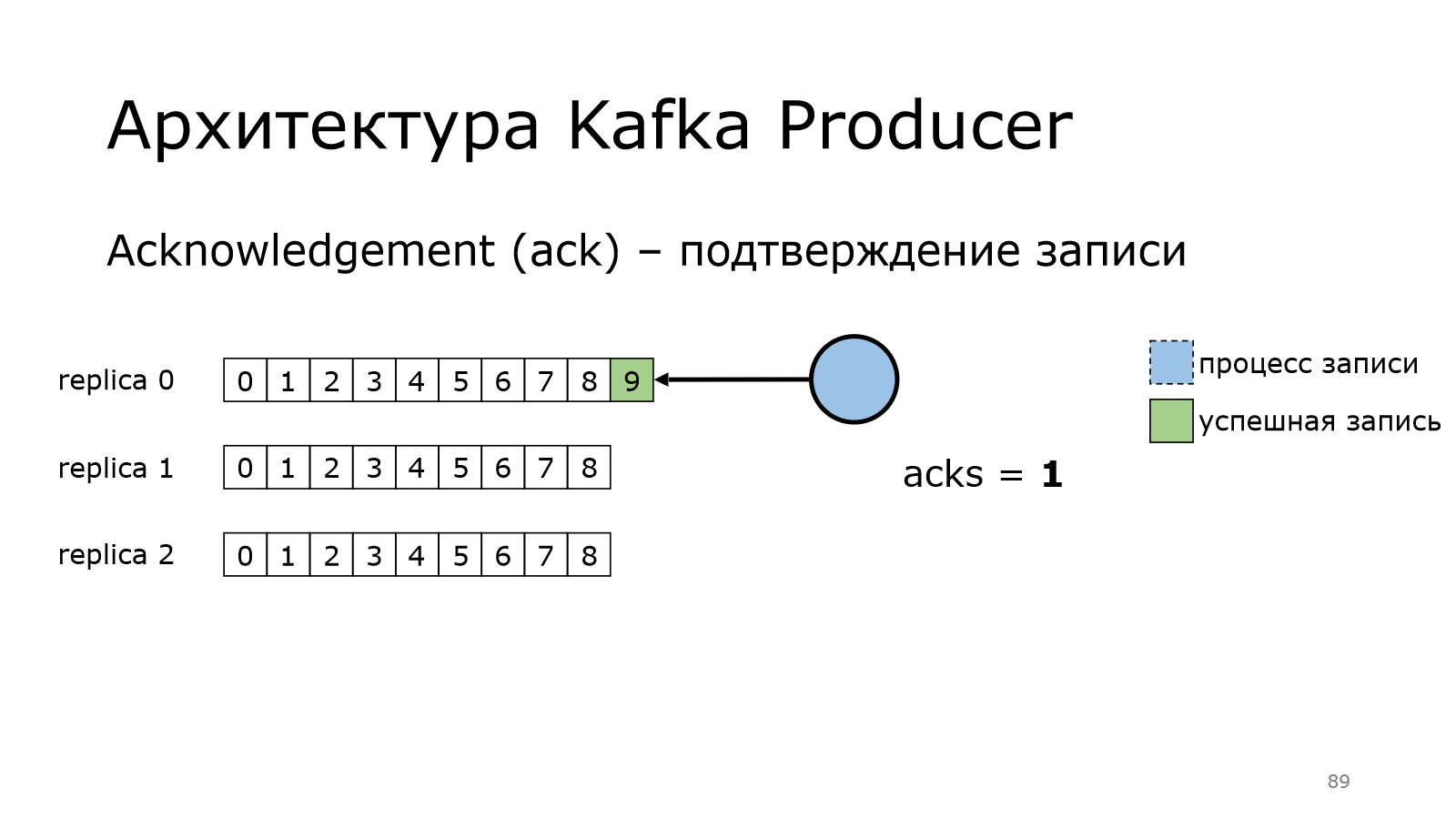
Запись произошла успешно на брокера. Брокер вернул подтверждение, что сохранил.
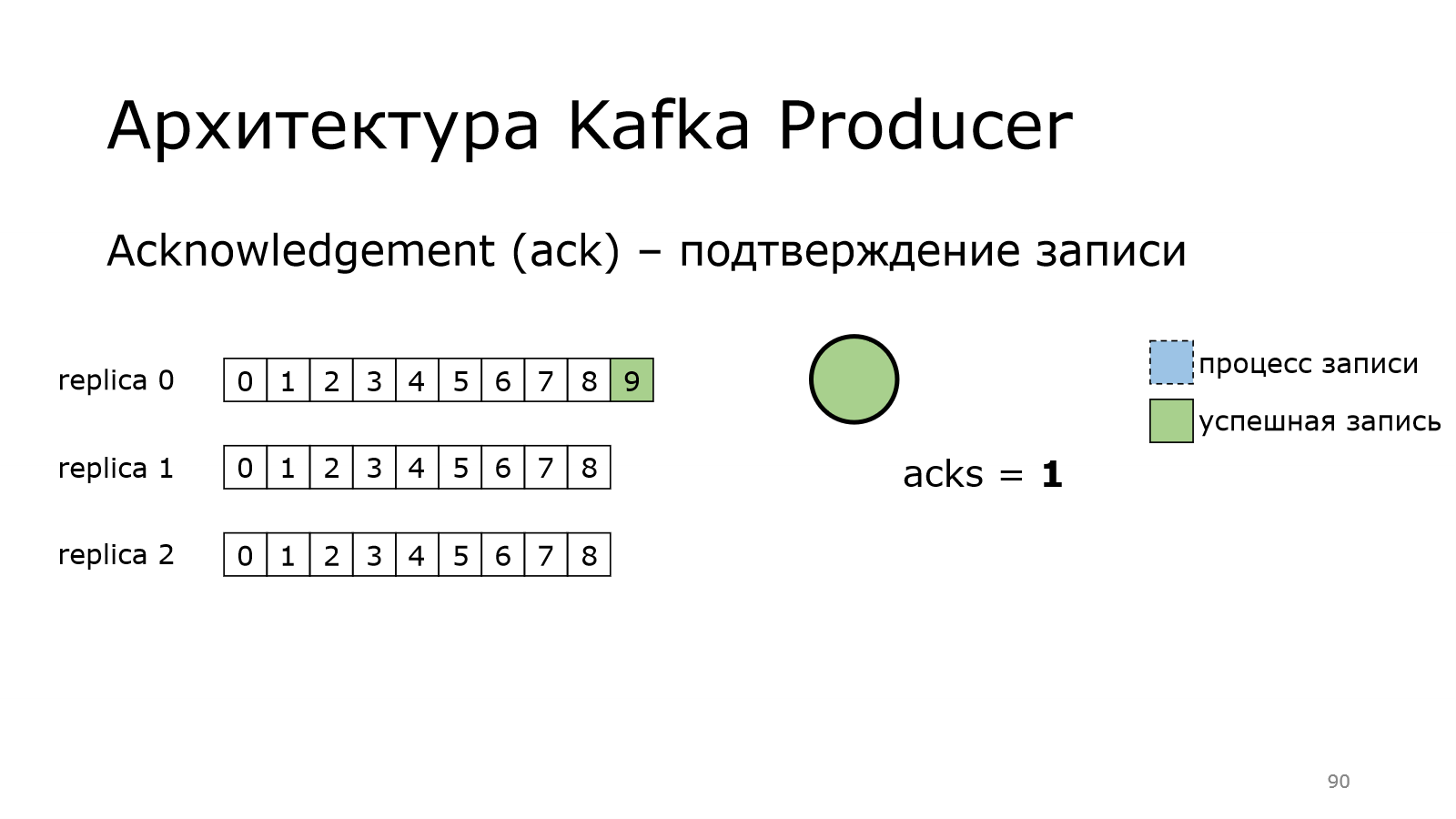
После этого продюсер считает, что все хорошо.
Какой следующий шаг?
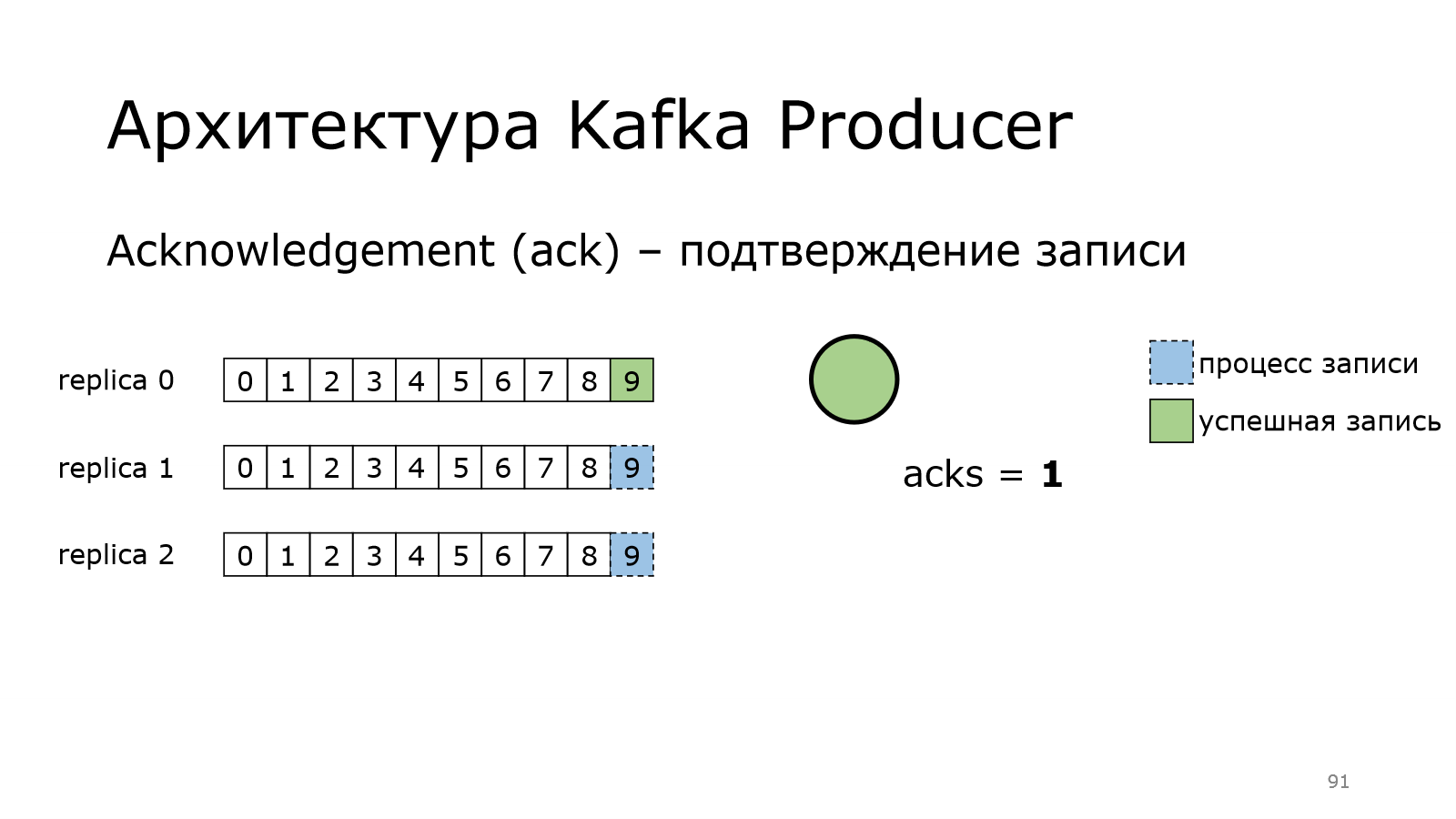
Followers приходят к лидеру и говорят: «У тебя есть новые данные?». Он говорит: «Да». И они это забирают. А могли и не забрать. Это важно. Об этом мы, может быть, позже подробней поговорим.
И, наконец, максимальный уровень. Уровень all, когда идем на все.

Как это работает? У нас продюсер пишет данные в лидера.
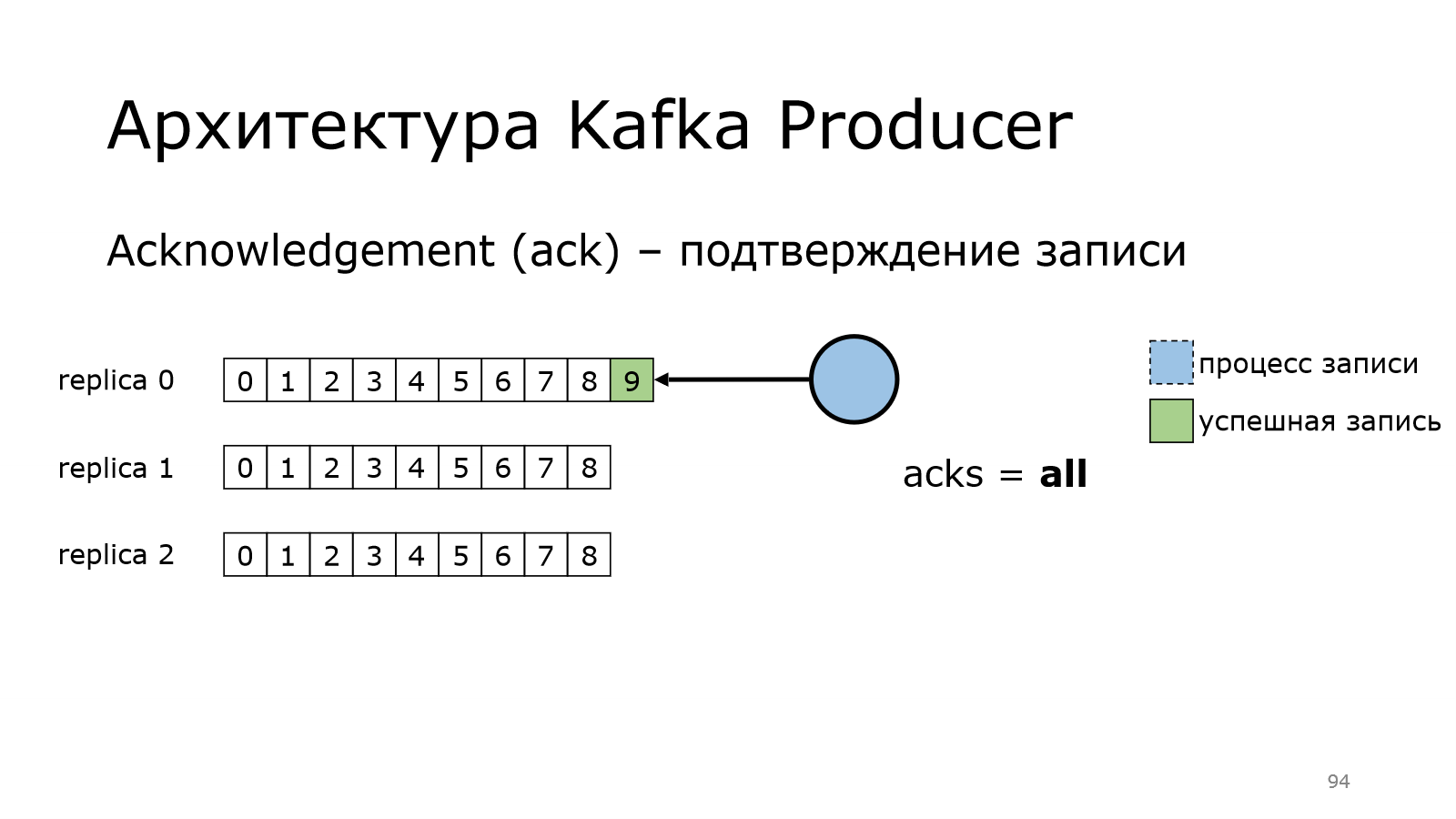
Лидер сохранил, но ничего пока не говорит продюсеру.
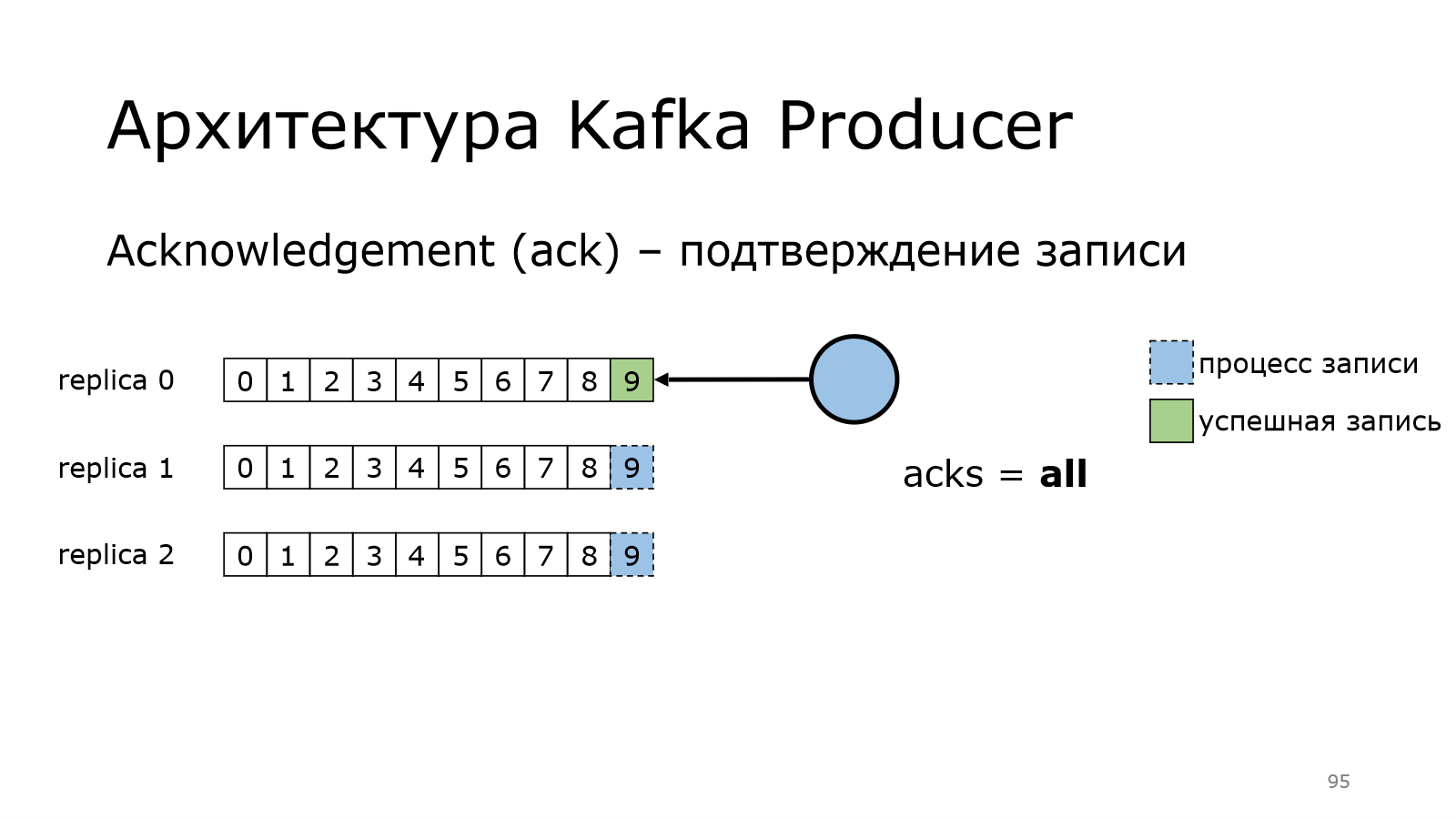
Дальше followers фоном приходят за данными.

И начинают их фетчить с лидера, пишут к себе. Записал первый, записал второй.

Брокер, который лидер, понимает, что данные записаны на всех и говорит продюсеру, что данные записались.

После этого продюсер считает, что все хорошо.
И тут появляется важная настройка появляется. Это min.insync.replicas.

Сейчас это равно 3, поэтому лидер уведомляет продюсера, что данные записались не меньше, чем в эти 3 реплики, т. е. в себе + еще 2.
Эту настройку можно понизить, тогда можно дожидаться не всех, а, допустим, все-1.
Архитектура Kafka Consumer

Теперь посмотрим, как работает consumer. У нас есть несколько партиций. Пока consumer будет читать из одной партиции. Он еще ни разу не читал, он читает с самого начала. Вот он прочитал какое-то количество сообщений.
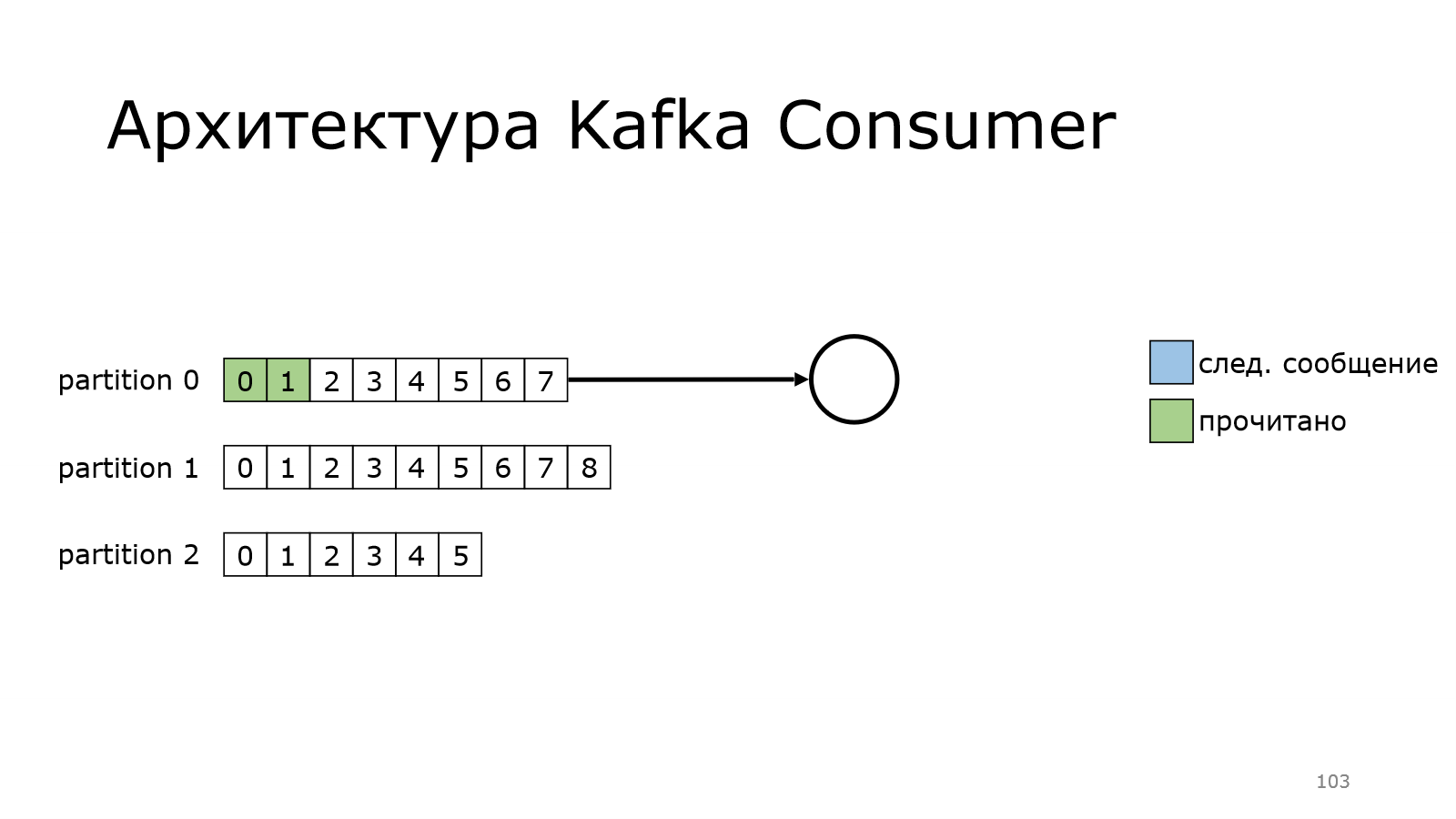
Потом перешел к следующему моменту, и так постепенно дочитывает.


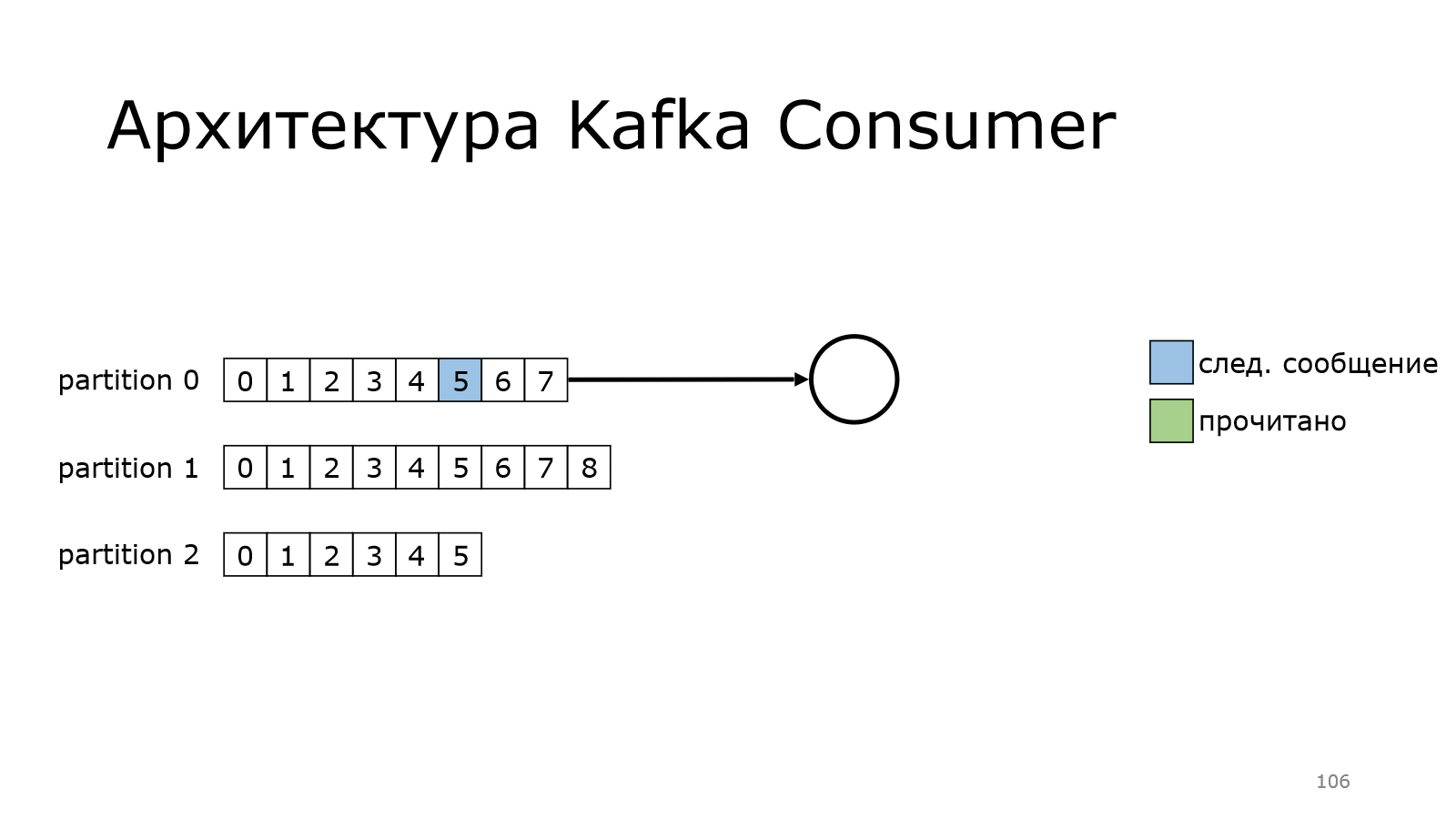
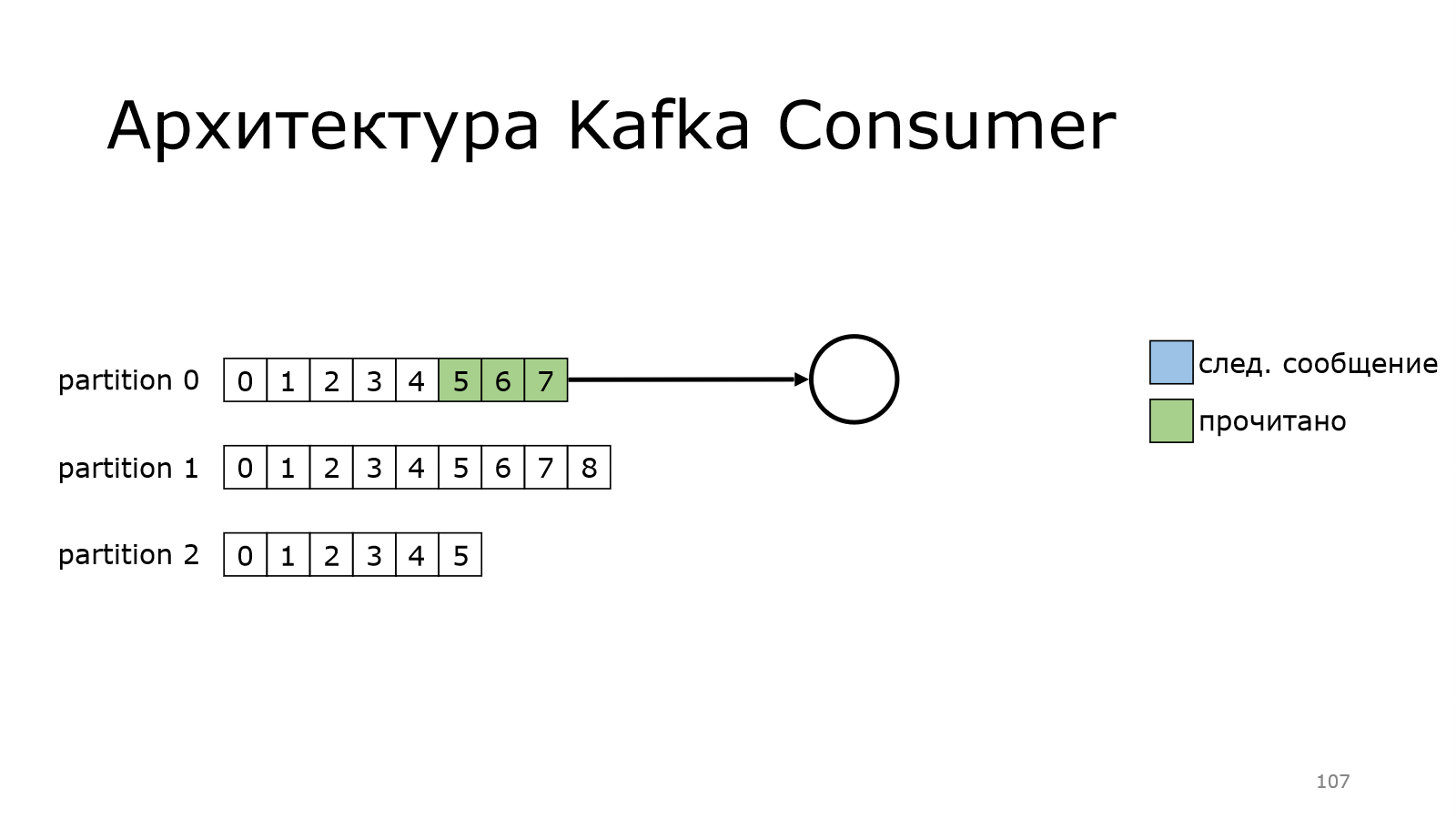
Также он может читать из нескольких партиций одновременно.

Как это выглядит?

Он на каком-то месте остановился и начинает забирать данные.
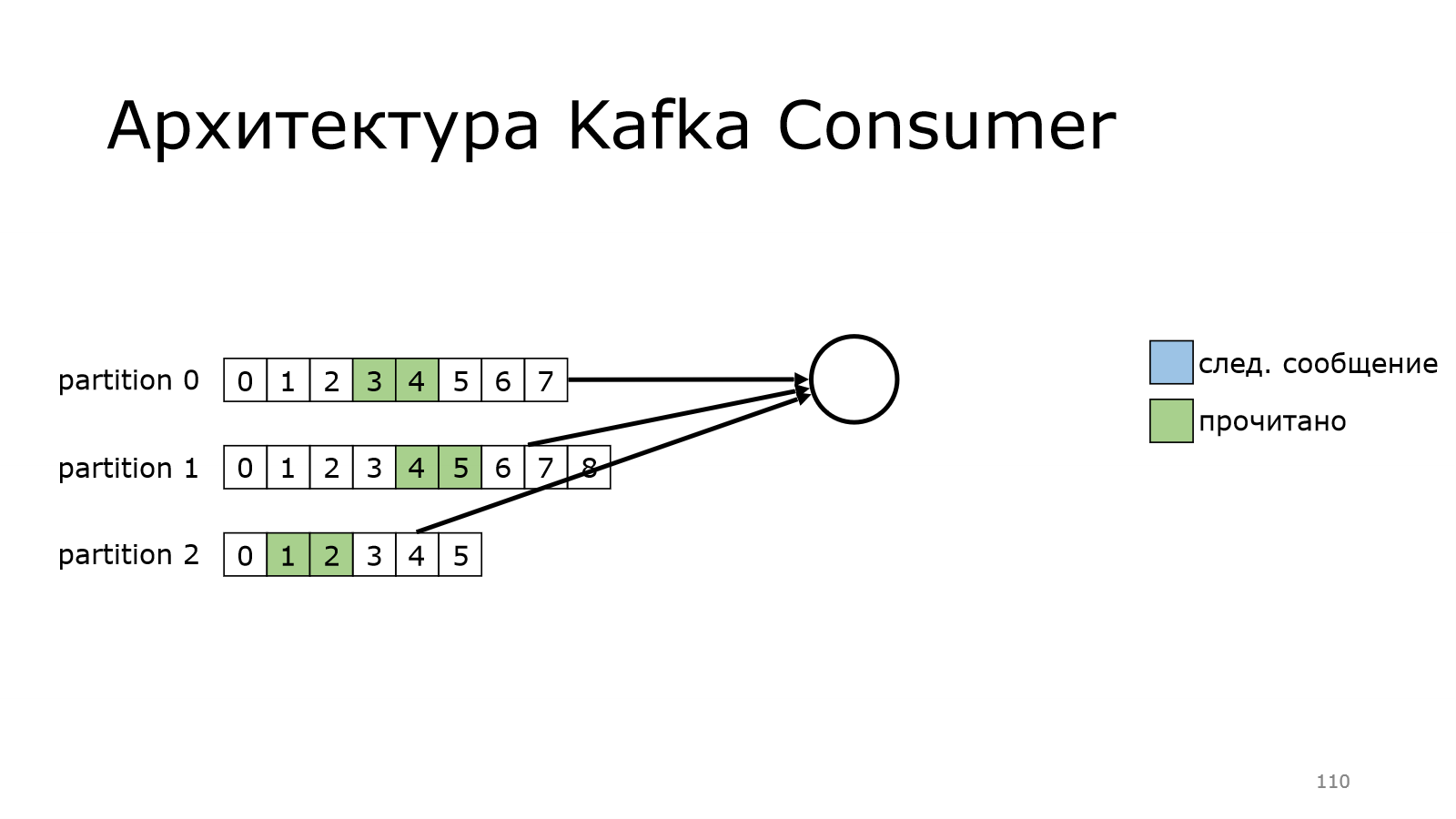
Он забрал данные.
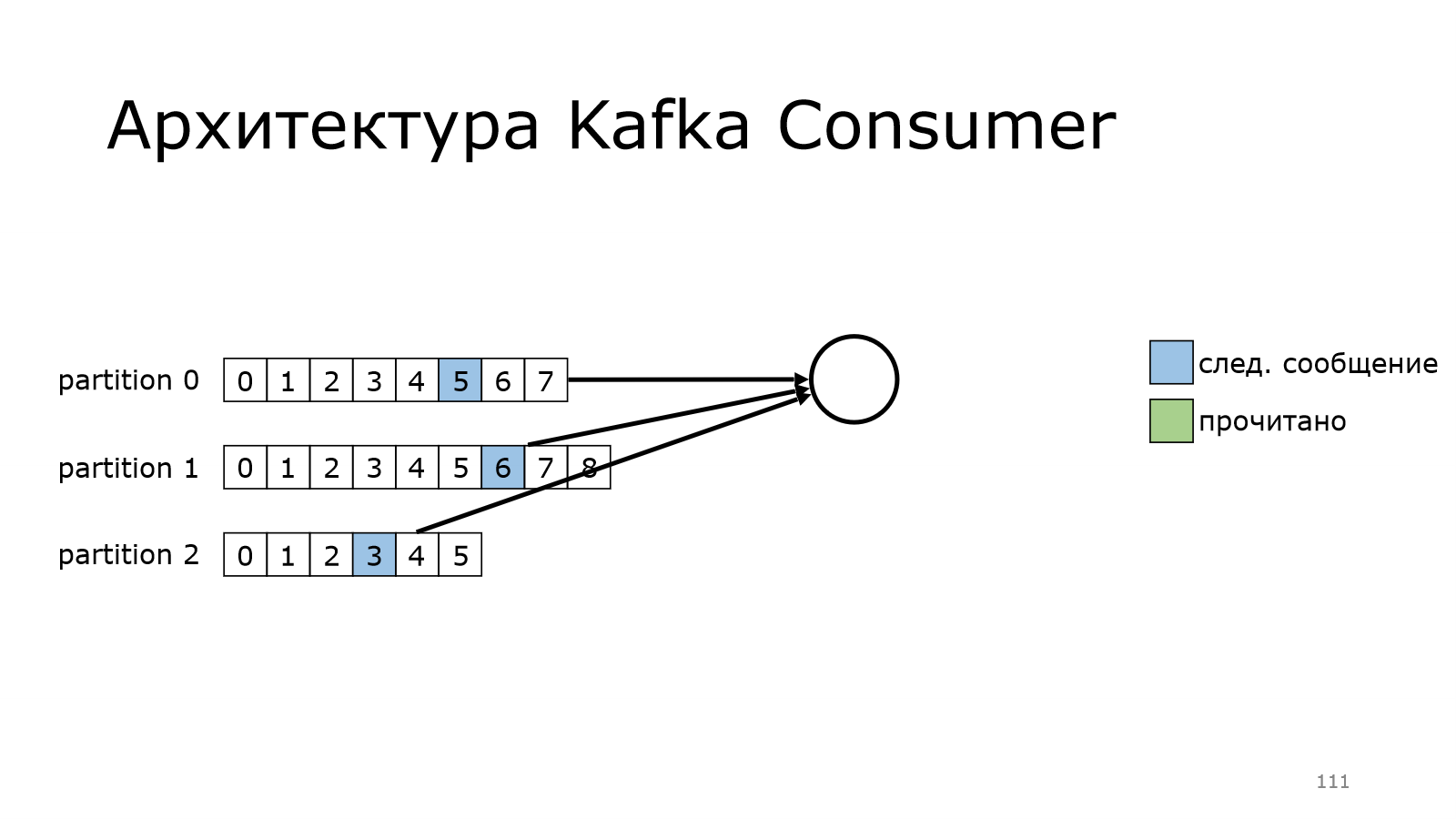
Пошел дальше-дальше и дошел до конца.
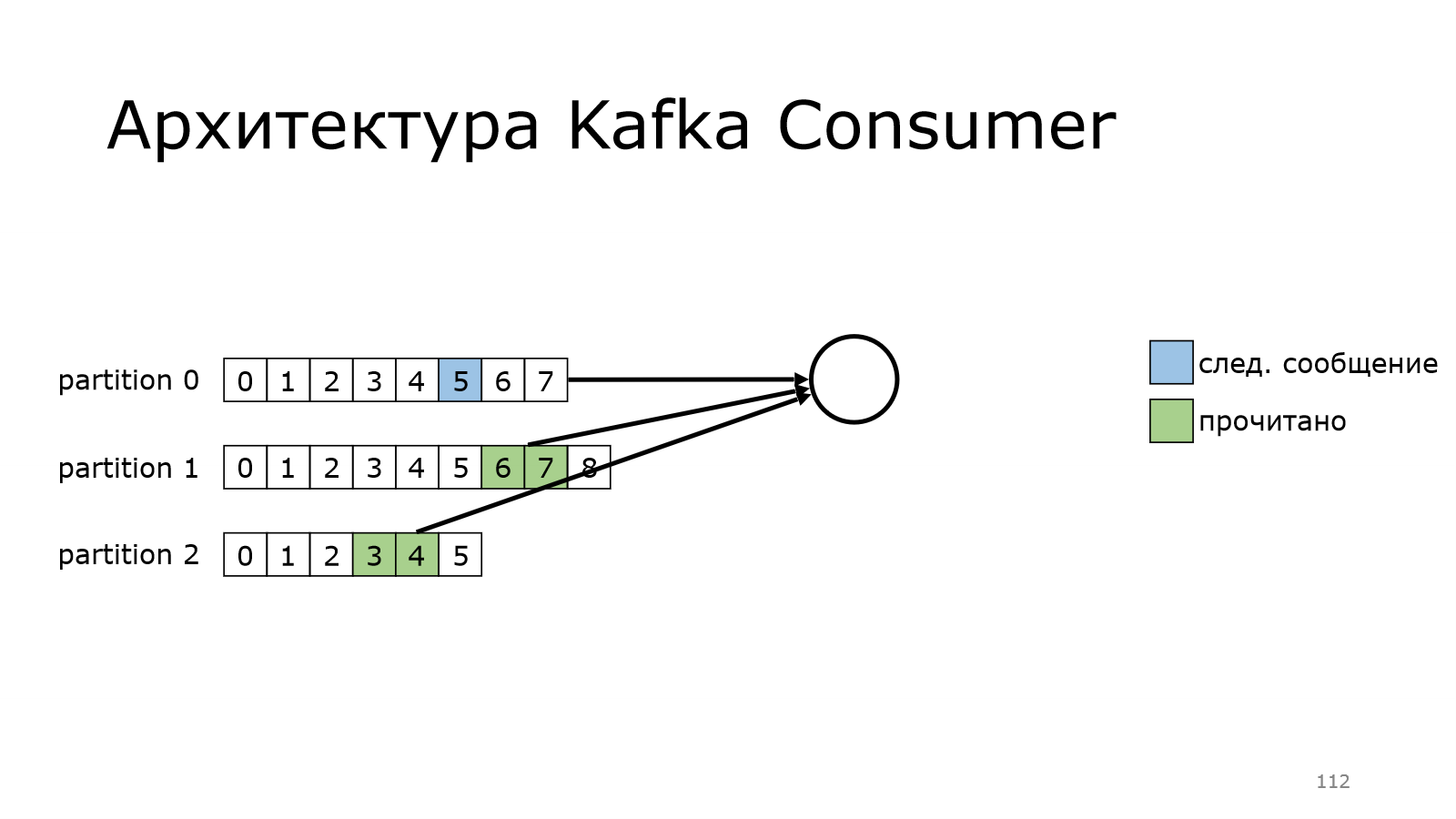
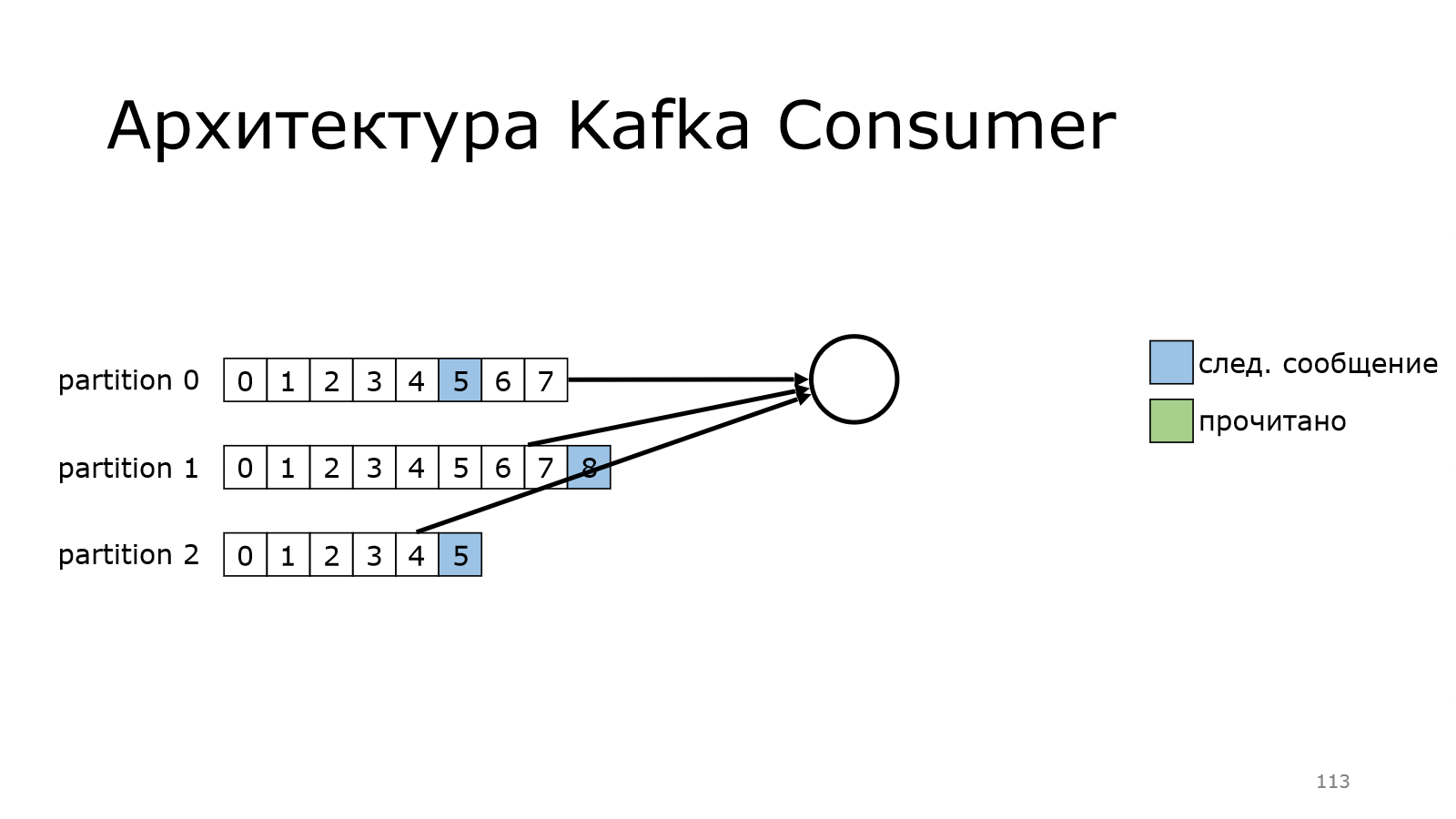
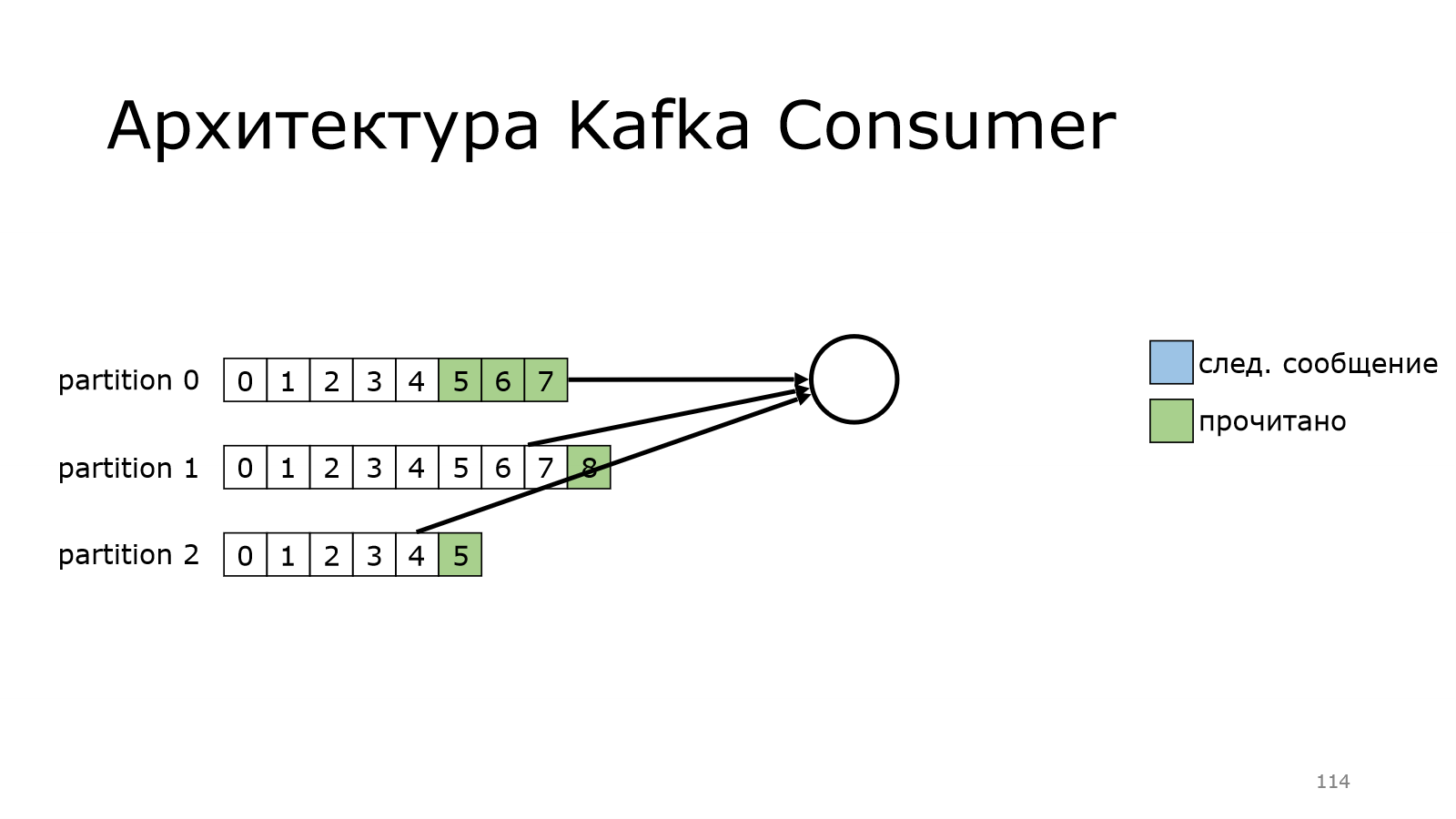

А в version polled сообщений в Kafka еще нет. И он будет продолжать делать это до тех пор, пока данные новые не появятся, и он их не получит.
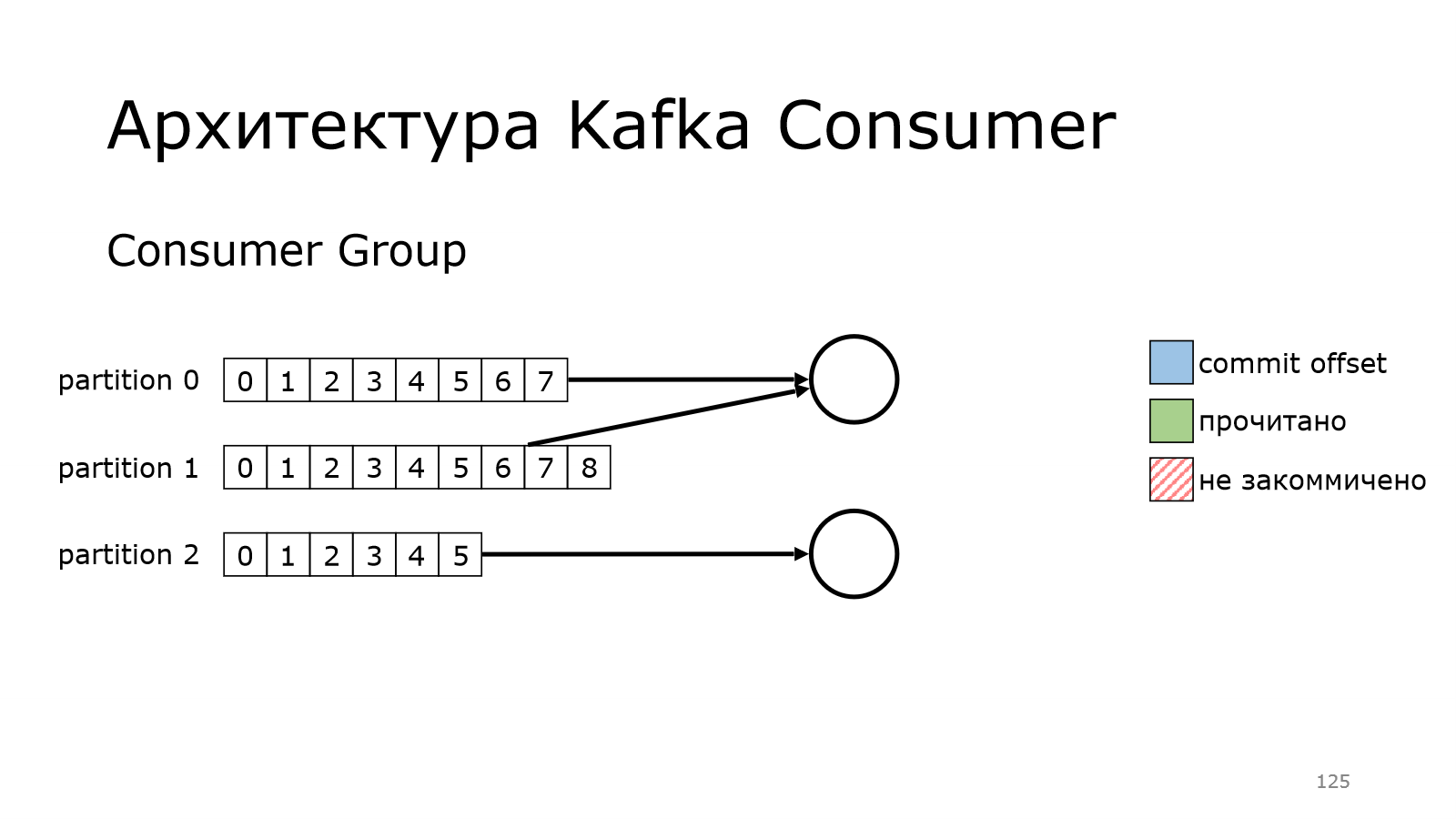
Но есть маленькая тонкость. Когда вот это он делал, он запоминал место, с которого надо читать дальше. Он мог и перезапуститься, мы могли прибить процесс. И эта информация потеряется. Это понимали и те, кто делали Kafka. И поэтому добавили такую фичу, как commit offset.

Что это значит?

У нас есть consumer, он прочитал несколько сообщений.

И то значение, с которого надо начинать дальше, он коммитит. Он говорит Kafka: «Я дочитал до вот этого и с этого места я хочу потом продолжить». Соответственно, он потом продолжает и читает.

Потом у него могло произойти что-то и он отвалился.

И при этом он не успел закоммитить данные. Т. е. вот эти все сообщения считаются не закоммитченными.

И когда consumer вернется в работу, он начнет ровно с того момента, на который в последний раз закоммитил.

И с него благополучно начнет читать.

Кажется, что все логично.
Мы в какой-то момент начинаем писать много данных и нам надо уметь масштабироваться.

У нас есть consumer, который начинает уже не справляться с чтением всех данных.
Тогда мы поднимаем еще один. И как бы мы могли это сделать? Мы могли бы сделать так, что один consumer читает из первых двух партиций, второй consumer читает из другой партиции. Но этим очень трудно управлять ручками, поэтому в Kafka предусмотрена вот такая штука.
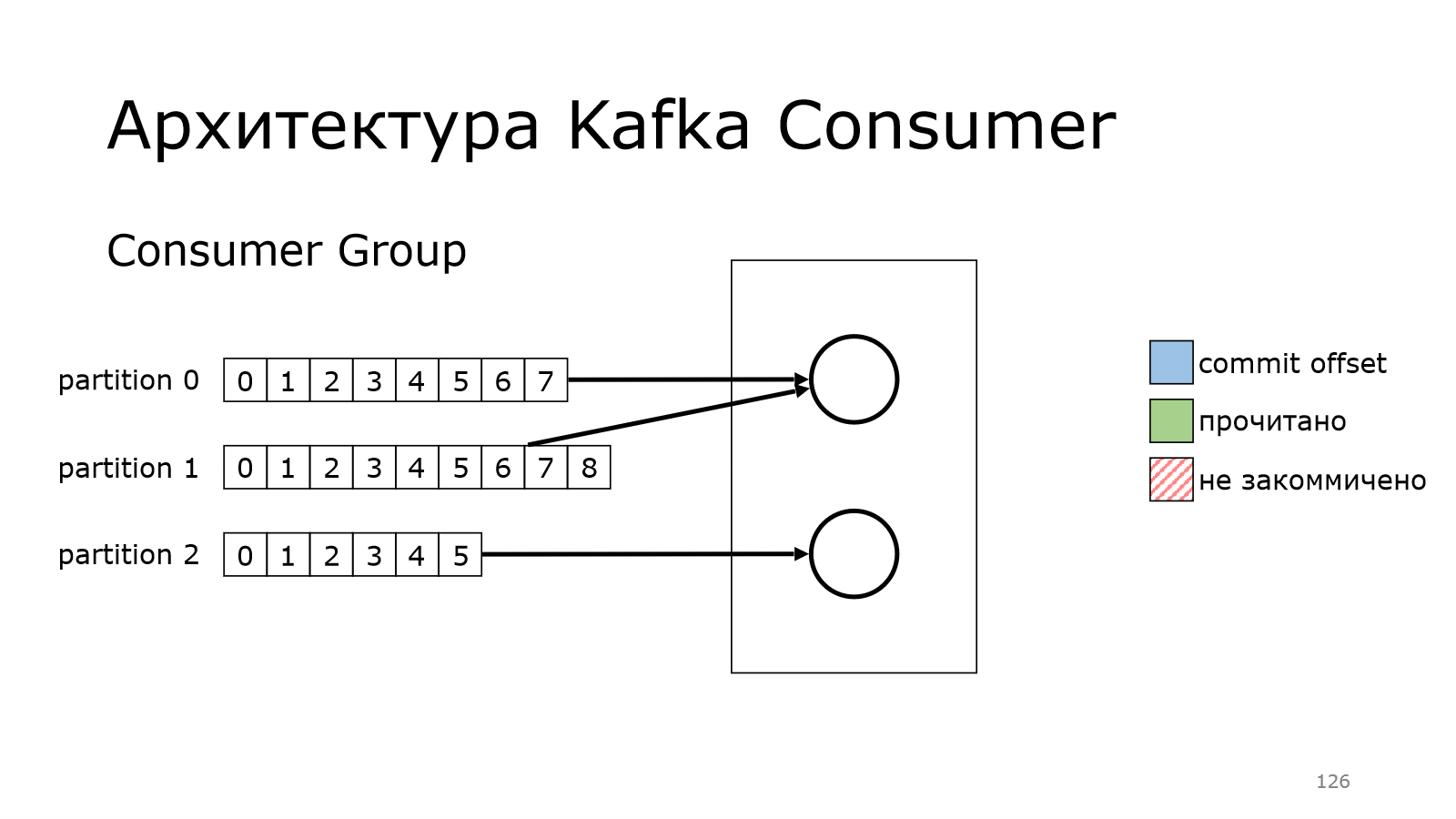
Можно взять и объединить набор consumers в группу. И у них там появляется общий идентификатор.

И когда они работают, они между ними автоматически расбалансируют все партиции и начнут читать.

У них там был какой-то offset, с которого они должны начать.

Первый почитал, второй начал читать.

И второй — бах и упал, и не докоммитил что-то.

Что произойдет? Во-первых, надо начать снова с первого сообщения.

Произойдет перебалансировка в этой группе.
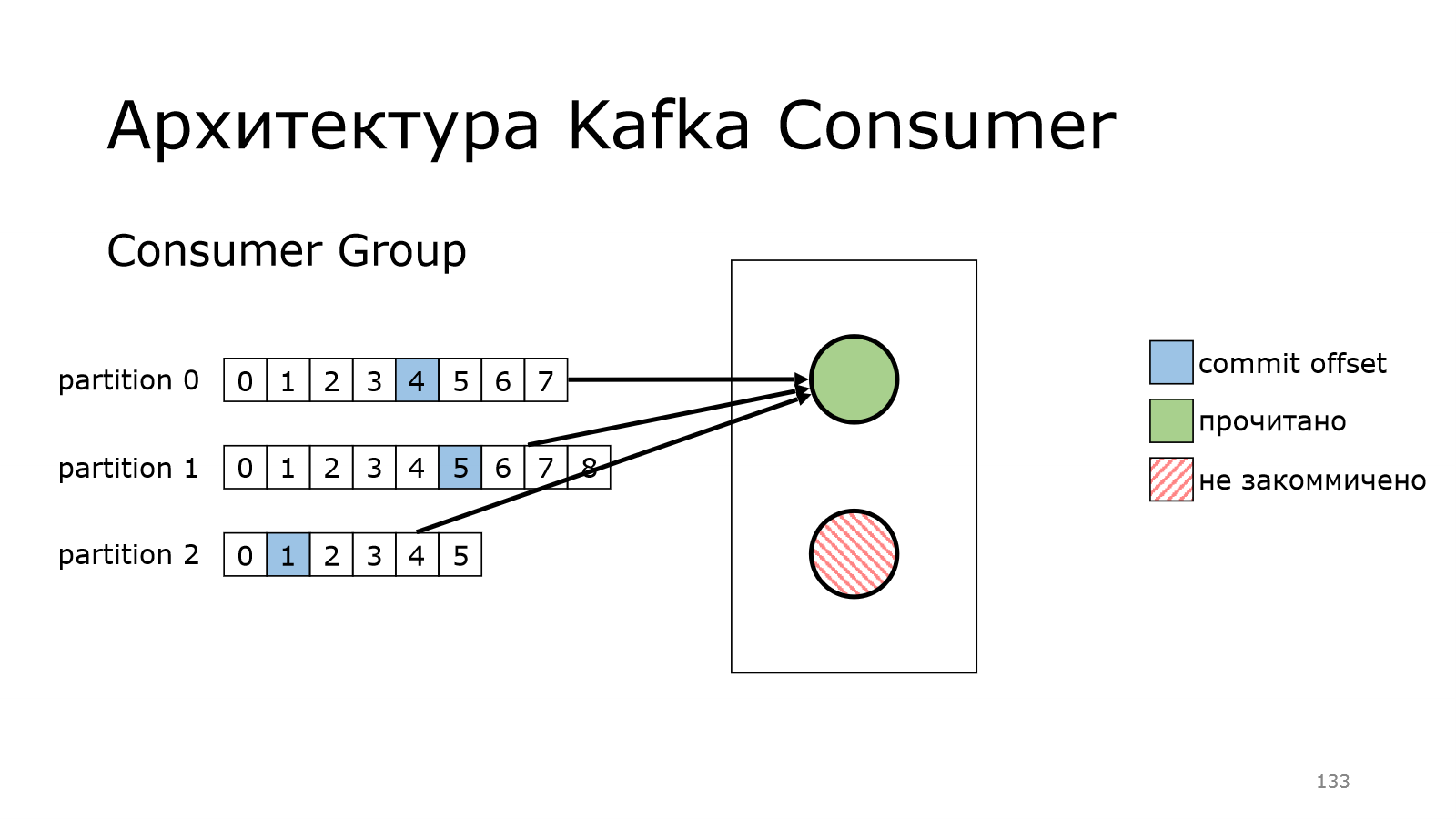
Единственный живой consumer в данном случае подхватит эту партицию.

И уже сам начнет читать данные.

И так же коммитить.

А потом consumer ожил, все у него хорошо. Он снова присоединяется к группе.

И получает какую-то партицию, с которой он может читать данные.
Кажется, что все очень просто, все хорошо работает. Там очень клевая архитектура, все очень быстро.
Неочевидности Kafka
Но потом мы начинаем все эксплуатировать и сталкиваемся с реальностью.
И поговорим о том, что мы пережили за год эксплуатации.
Но честно скажу, что это очень-очень краткое изложение.
Я постарался выбрать показательные примеры того, с чем приходится сталкиваться разработчикам и не только при работе с Kafka.
Настройки — Как разломать кластер
Давайте начнем с настроек. Как разломать кластер? Его можно разломать разными способами. Я предложу один.
Есть настройка в Kafka. Называется log.dirs. Как можно догадаться из названия, это папки, где лежат данные.

У нас есть два брокера. У каждого из них по реплике, по какой-то партиции.
 Один — не очень, он не успевает за лидером. Лидер в этот момент был нами, например, остановлен, перезагружен.
Один — не очень, он не успевает за лидером. Лидер в этот момент был нами, например, остановлен, перезагружен.

Что произойдет?

А реплика 1 ожила, у нее все хорошо. GC прошел долгий.
И вот какая ситуация. У лидера данных было больше, чем у последователя. И в Kafka может произойти такая штука, как грязные перевыборы. Вроде бы ему нельзя быть лидером, потому что данные потеряются.

И есть вот такая настройка — unclean.leader.election.enable=false. Она по умолчанию такая с 0.11 версии.
KIP-106 — Change Default unclean.leader.election.enabled from True to False (0.11)

Теперь всё. Теперь партиция не доступна на запись. Надо ждать. Чего мы ждем? Мы ждем, когда вернется старый лидер.
А мы же эту настройку поменяли. И сказали, что теперь у тебя данные лежат в другом месте. Это что означает? Когда брокер поднимается, у него партиция пустая. И теперь кластер видит вот такую ситуацию. У реплики 1 какие-то данные есть, у реплики 0 их нет.
Но как мы помним, мы ждали возвращение реплики 0.

И поэтому реплика 1 говорит, что я так не могу больше. И брокер упал.
А теперь представьте, что таких партиций было много на самом первом, который был перезагружен с новым каталогом. И получается, что все остальные брокеры упали, один остался.

https://issues.apache.org/jira/browse/KAFKA-3410
В Kafka заведен не один баг по этой теме. И кажется, что он исправлен в версии 1.1.
По крайней мере в этой ситуации вроде бы брокеры уже не падают. Но это не точно.
Настройки — Настройки по умолчанию

Поехали дальше. Теперь мы поговорим про настройки по умолчанию. У нас по умолчанию default.replication.factor = 1.
И понятно, почему. Потому что, когда мы только установили Kafka и начинаем ее пробовать, мы поднимаем на своей dev-тачке всего одну ноду, поэтому, если бы default.replication.factor был каким-то другим, то мы не смогли бы ничего себе создать. Это логично.
Хорошо, всегда при создании топика будем указывать replication.factor, который мы хотим.

Но есть второй подводный камень — это опция auto.create.topics.enable = true.
Это по умолчанию такая настройка. Что она означает? Если мы создаем топик со своими настройками, то все отлично, но если кто-то пытается писать к нам в несуществующий топик сообщение, то Kafka думает: «О, что-то новенькое». И создает нам топик. И создает топик с настройками по умолчанию, т. е. с replication.factor =1. И мы увидели у себя в production, что часть топиков с нормальным настройками replication.factor, а у некоторых топиков почему-то replication.factor = 1. И оказалось, что кто-то просто не дожидался создания и уже начинал писать данных. И из-за этого оно вот так ломалось.
Поэтому первым делом, когда вы развернули кластер, меняйте вот эти две настройки.

Еще две истории с настройками. Я думаю, все согласны, что настройки у брокера, у consumer должны быть. Но они должны не просто быть, а еще должны быть согласованы.
Давайте посмотрим, что нам разработчики Kafka подложили в качестве дефолтных настроек.

Есть такая настройка, как message.max.bytes. На брокере она равна 1 000 012 байт.
Что она означает? Грубо говоря, мы с продюсера начинаем писать данные. И это максимальный размер сообщения с данными, который можно запихнуть в Kafka.

Хорошо, на стороне брокера есть похожая настройка, только она равна мегабайту в другой системе. Мегабайт равен настоящему мегабайту, которому мы с вами привыкли. Для сравнения у consumer она точно такая же, как у продюсера. Дело в том, что consumer и продюсер, видимо, одни люди писали. А брокер кто-то другой делал. Клиент Kafka на Java написан, а брокер написан на Scala.
К чему это может привести? Если у нас на стороне продюсера есть большое-большое сообщение, то, естественно, мы это сообщение получили только в production. Оно чуть больше, чем один миллион байт, но меньше одного мегабайта. Т. е. с нашей стороны пуля вылетела, а брокер сообщение не сохраняет.
С этими настройками была еще одна забавная история.
Настройки — Умножение

Т. е. тут было большое сообщение, но мы в коде ограничение понизили. На стороне нашего кода мы не передаем большие сообщения. Соответственно, когда в Kafka упаковывается вроде бы должно быть все нормально.
Но в Kafka есть еще одна такая настройка, как batch.size. Она измеряется не в штуках, она измеряется в байтах. 16 килобайт — это пачка, которую Kafka-клиент может собрать перед тем, как отправить в брокер. Т. е. там не сразу первое же сообщение пуляет в Kafka, он набирает потихоньку, чтобы меньше сетевых запросов было. Кажется, логично. Все здорово.
Мы протестировали на своих данных. И оказалось, что вот это сообщение надо умножить на 10. Т. е. для нас 160 килобайт выдает нормальный performance.
Хорошо, все протестировали, все замечательно.
А потом мы выкатили это на production. И помнили, что это значение надо умножить на 10. И оказалось, что у нас уже 160 килобайт было, а мы еще на 10 умножить. И в production уехала эта настройка в чуть больше 1,5 мегабайт.
Что мы получили? Если вы думаете, что все развалилось, то нет. Все было следующим образом. Мы выкатываем, все хорошо работает. Никаких ошибок нет. У нас нагрузка потихоньку растет-растет и растет. И потом мы пересекаем какой-то невидимый порог и все разваливается. Производительность падает практически в ноль.
Что происходит?

Дело в том, что в Kafka есть KIP-126 — Allow KafkaProducer to split and resend
oversized batches (0.11)
KIP (Kafka Improvement Proposals) — это такие предложения по тому, как улучшить Kafka, т. е. сделать ее прикольней.
И такой KIP в версии 0.11 выпущен. Kafka producer, если получает от брокера информацию о том, что какой-то большой пакет, он его разбивает и снова перенаправляет Kafka.
И когда нагрузка маленькая, то не успевают копиться пачки. Мы их отправляем, и они пролетают быстро. А когда нагрузка возрастает, пачки начинают расти. И мы отправляем пачку, которая чуть меньше одного мегабайта, потому что у продюсера такая настройка, но это больше миллиона байта, который может принять брокер.
Соответственно, брокер присылает ошибку. В логах ничего нет. Сам клиент решает переразбить. Он переразбивает данные и переотправляет.
И мы раз большую пачку отправили. Брокер отвечает: «Не пойдет». Мы разбили и еще отправили. Получается, что у нас сетевая активность очень сильно выросла. И мы по этой части тухли неожиданно.
API — Блокирующий send

Давайте перейдем к API, перейдем к блокирующему send. Почему я об этом говорю? Дело в том, что в Kafka есть крутой асинхронный API, т. е. все, что бы мы не делали с Kafka, она возвращает нам future. И код дальше продолжает выполняться. Но, как выяснилось, не всегда. Если метаданные не доступы, то продюсер send блокируется, т. е. он нам даже future не вернет, а просто остановится. Метаданные — это информация о том, какой брокер на каких топиках является лидером и у какой партиции. Это информация, которая нужна продюсеру, чтобы понять в какой брокер записать данные, т. е. в какую конкретно партицию. И как раз вот эта метаданная периодически обновляется. В кластере лидерство меняется, поэтому его надо периодически обновлять. Заблокироваться он может вплоть до 60 секунд.
Такое значение по умолчанию. Если каким-то с кластером были проблемы, то мы даже фьючу не сможем получить. И свой код, который написан с той точки зрения, что у нас от Kafka все асинхронно, просто встает на достаточно большой промежуток времени.

KIP-286: producer.send () should not block on metadata update (discuss)
Кто считает, что так недолжно быть? Все верно, есть люди, которые считают, что это не нормально. И есть люди, которые сказали: «Давайте сделаем нормально». И этот KIP в статусе discuss. Это означает, что там какие-то обсуждения идут. И неизвестно, когда эта штука появится в Kafka и когда не появится. Но живем дальше, жизнь на этом не заканчивается.
API — бесконечная десериализация

Давайте посмотрим, как на другой стороне. У нас был продюсер, а сейчас посмотрим, как на стороне consumer. Я говорил, что у нас poll-механика, т. е. consumer приходит и просит у Kafka данные. Это означает, что типичный consumer выглядит примерно таким образом:
Есть такой бесконечный цикл, в котором мы берем и долбит Kafka. Получаем какие-то данные и дальше с ними что-то делаем. Все неинтересное,
