DBA: Ночной Дозор
Для многих систем характерен паттерн постоянного накопления данных с течением времени. Причем основная их масса больше никогда не изменяется — то есть они пишутся в режиме append-only.
Это не только различного рода логи и метрики оборудования, но и такие, казалось бы, несвязанные вещи, как переписка между пользователями или комментарии к новостям.
Около года назад я уже писал про модель организации секционирования таких данных и вызываемые этим каскадные изменения в структуре БД. А сегодня на примере нашего сервиса анализа логов PostgreSQL-серверов разберем особенности обслуживания организованных так баз, и как грамотный подход (и немного ночной работы) может сократить затраты на инфраструктуру в разы.

Что-то мы сильно грузим диск…
Вся база нашего сервиса «распилена» на суточные секции и реорганизована под максимальную пропускную способность. Подробнее об этом можно прочитать в статьях «Пишем в PostgreSQL на субсветовой: 1 host, 1 day, 1TB» и «Экономим копеечку на больших объемах в PostgreSQL».
При этом мы стараемся писать в базу предельно сбалансированно (см. «Телепортация тонн данных в PostgreSQL»), но все равно наши «хотелки» превышают возможности дисковой подсистемы — занята она регулярно на все 100% и очереди доступа, небольшие, но есть всегда:

«Чукча — не читатель, чукча — писатель!» Или нет?
Как бы это и не удивительно, когда пишешь со скоростью до 200MB/s:

… и читаешь не меньше.
Стоп — читаешь?… Но у нас же нет тонн неэффективных запросов, которые бы столько читали! Но при этом больше половины всех дисковых операций — чтение!

Как же так? Кто этот злодей, который столько читает? И почему это у нас в середине дня до 18 maintenance-процессов? К ним относятся разные VACUUM, ANALYZE, CREATE INDEX и т.п.

Как и что мы мониторим в PostgreSQL, стоит прочитать в статье «Мониторим базу PostgreSQL — кто виноват, и что делать».
«Вот те раз! — подумал Штирлиц»
А ну-ка, воспользуемся функционалом анализа работы autoVACUUM/autoANALYZE:
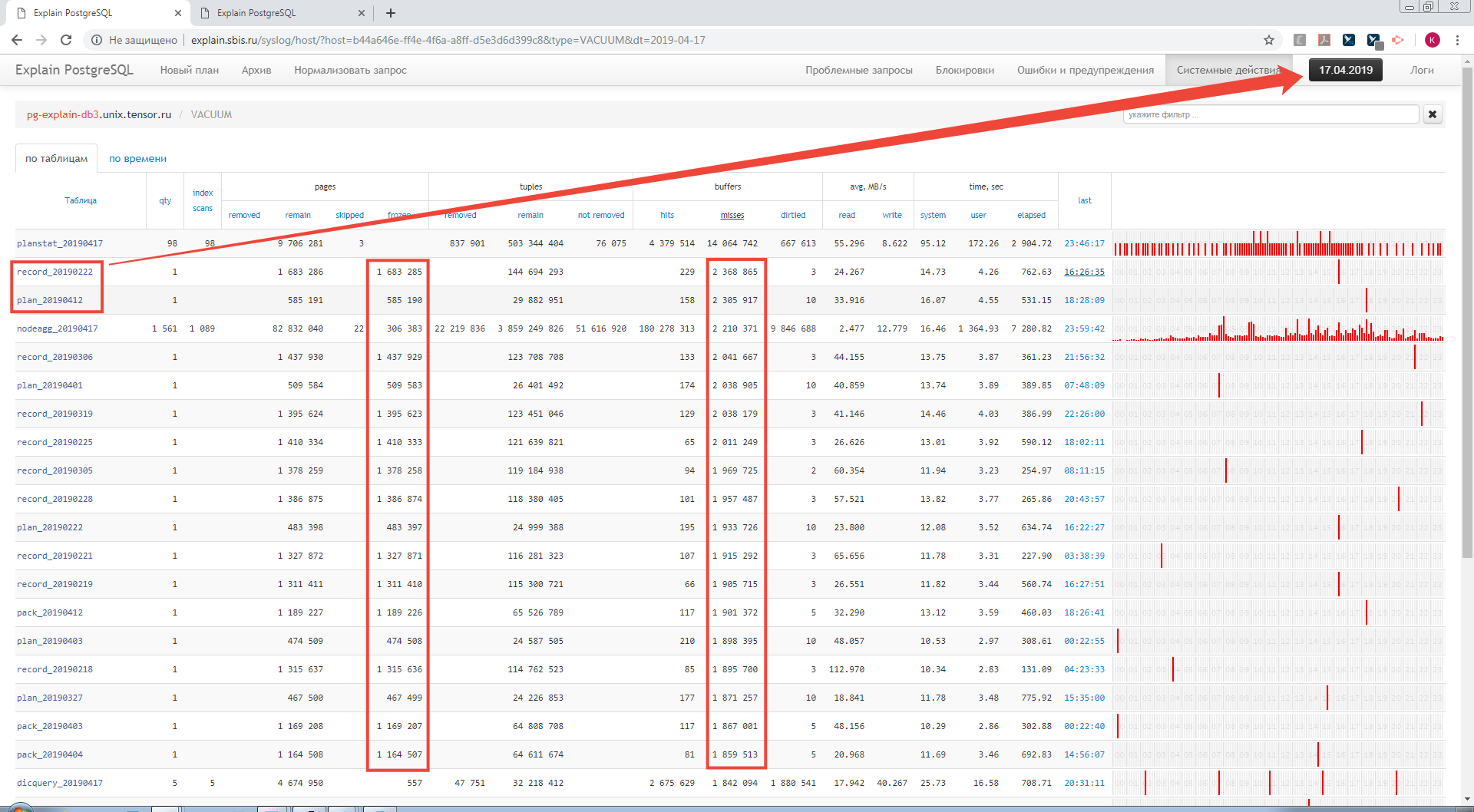
Оказывается, у нас в течение дня бегает множество autovacuum (to prevent wraparound) по секциям каких-то других дней — и все они «промахиваются» мимо кэша данных, и лезут в диск! То есть мы пишем в базу настолько много транзакций, что она регулярно начинает хотеть их «прибрать» по старым секциям, а они у нас до 150GB… Хм.
«Вот те два, — подумал Мюллер, и бросил второй.»
Так, а что у нас делает autoANALYZE?…
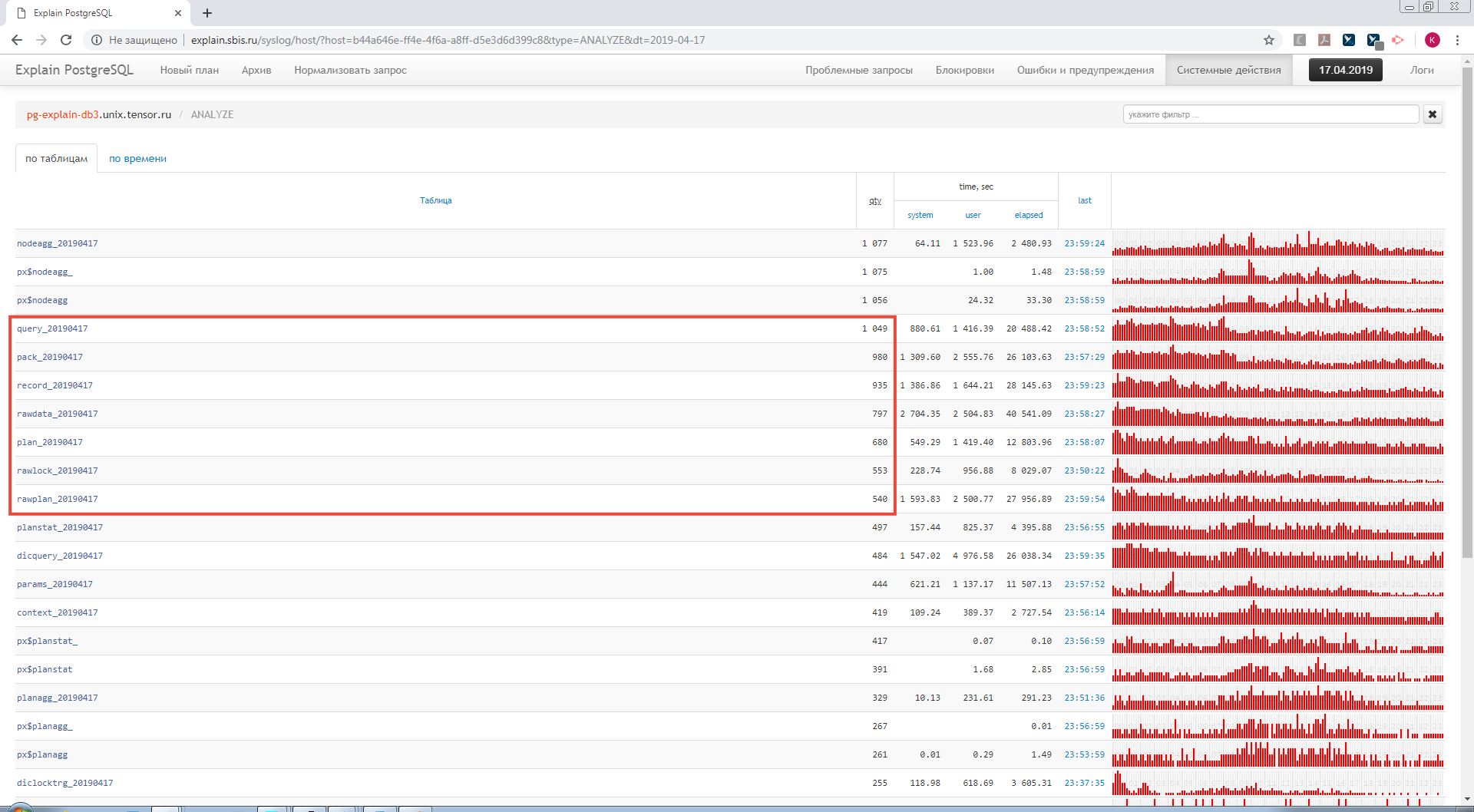
Кучу раз в течение дня делаются ANALYZE-пробежки по append-only табличкам! Большого смысла в этом тоже не сильно много, поскольку заведомо все записи тут уникальны и имеют PK.
Ночной Дозор и не только
Итак, начнем «с хвоста» — избавимся от autoanalyze. Для этого перенастроим соответствующие параметры сервера:
ALTER SYSTEM SET autovacuum_analyze_scale_factor = 1;
-- ждем для следующего сканирования, пока в табличку не запишут еще столько же (x2) записей
ALTER SYSTEM SET autovacuum_analyze_threshold = 100000;
-- ... но не меньше 100KТеперь внимательно посмотрим на «старые» секции. Устаревают они ровно тогда, когда мы перестаем в них писать — около полуночи, как раз когда нагрузка минимальна.
Они у нас есть двух видов:
относительно небольшие с поддержкой INSERT … ON CONFLICT UPDATE со всякими счетчиками
мега-большие append-only «факты»
pg_repack
В силу специфики MVCC, первый вид секций оказывается к концу дня «сильно-дырявым». Это замедляет чтение и приводит к занятости большего объема.
Чтобы «схлопнуть» секцию, не блокируя доступ к ней, мы разработали ежесуточный ночной cron-скрипт, стартующий в 00:15, который последовательно применяет ко всем таким таблицам «предыдущего дня» pg_repack, «схлапывает» их и физически переупорядочивает записи в соответствии с наиболее используемым индексом:
Модуль pgrepack — это расширение Postgres Pro Standard, которое позволяет ликвидировать пустоты в таблицах и индексах и может дополнительно восстанавливать физический порядок кластеризованных индексов. В отличие от CLUSTER и
VACUUM FULL, оно выполняет эти операции «на ходу», обходясь без исключительных блокировок таблиц в ходе их обработки. К тому же pgrepack действует эффективно, демонстрируя производительность, сравнимую с непосредственным использованиемCLUSTER.
VACUUM FREEZE
По всем остальным (append-only) таблицам — выполняем принудительно VACUUM FREEZE, убирая у базы напрочь желание делать это «внезапно» по ходу рабочего дня:
VACUUM FREEZE rawdata_20190419;
VACUUM FREEZE rawplan_20190419;
...Пруфы!
Объем дискового чтения сократился в 20 раз, загрузка диска (disk busy) уменьшилась до ~60%:

