Greenplum, NiFi и Airflow на страже импортозамещения: но есть нюансы
В статье описывается практическое применение популярных Open-Source технологий в области интеграции, хранения и обработки больших данных: Apache NIFI, Apache Airflow и Greenplum для проекта по аналитике учета вывоза отходов строительства.
Статья полезна специалистам и руководителям, которые работают с данными решениями и делают ставку на них в части импортозамещения аналогичных западных технологий. Статья дает обзор основных сложностей внедрения на примере реального кейса, описывает архитектуру и особенности при совместном использовании решений.
Актуальность
В эпоху импортозамещения решений по КХД и Озерам данных данные решения являются стандартом в области аналитики. Если в части Apache NiFi еще есть определенные вопросы у компаний по его использованию, то для Greenplum и Airflow вопрос будет звучать как:, а есть ли те, кто не использует Greenplum и Airflow для хранения и обработки данных? Возможно, такие компании и найдутся, но это будет уже исключение. Конечно, речь о компаниях с большими объемами данных (скажем, более 5 ТБ), которые достигли определенного уровня зрелости в части управления данными.
Поэтому в крупном проекте по анализу рейсов мы выбрали привычный и популярный стек, в котором накоплена экспертиза, реализовано множество проектов, а также доступна подробная документация.
Заказчик — орган исполнительной власти крупного мегаполиса. В рамках системы учета по вывозу отходов строительства ведется фиксация каждого вывезенного килограмма отхода, за который государство делает платежи. Поэтому важно, чтобы система объективного контроля и аналитики рейсов могла быстро, надежно, корректно и эффективно делать расчеты каждого рейса и определять его статус: был ли рейс корректным исходя из набора проверенных критериев. Когда рейс признан некорректным, алгоритм должен показывать, какой конкретно критерий не сработал.
Задача осложняется большим количеством источников данных, где один из источников — это потоковые данные движения грузовых автомобилей, которые используются для расчета расстояния между машиной и полигоном.
Прежнее решение по аналитике базировалось на самописном Java-приложении, которое работало слишком долго и нестабильно, а аналитика рейсов делалась с помощью Qlik Sense. Так, была задача как заместить Qlik Sense в части визуализации данных на Open-Source решение Apache Superset (не цель данной статьи), так и заместить текущее Java-приложение на более современные масштабируемые и надежные решения новой аналитической платформы данных.
Роль Open-Source в импортозамещении аналитических систем
Немного про то, почему Open-Source так важен в вопросе импортозамещения решений по аналитике данных в РФ и не только. Open-Source не только не теряет свою долю рынка, а по прогнозам будет даже ее набирать.
Так,»через два года две трети программного обеспечения в корпоративном сегменте будет основано на открытом исходном коде, в то время как только треть будет полностью проприетарным ПО. Доли коммерческого ПО на основе открытого исходного кода и его бесплатных аналогов будут равными, составляя по 32% на каждый сегмент». Это данные исследования, опубликованного 18 марта 2024 года Институтом изучения мировых рынков.
В части решений по хранилищам Open-Source также набирает обороты, постепенно захватывая долю рынка. При этом проприетарные решения на базе Open-Source также увеличивают популярность.
NIFI как low-code инструмент транспорта данных: особенности использования
Мы не первый раз используем в проектах NiFi — low-code ETL-инструмент для интеграции данных из различных гетерогенных источников.
Исходя из ряда схожих проектов NiFi неплохо показывает себя в качестве «транспорта» данных из различных гетерогенных источников. Благодаря большому количеству встроенных коннекторов и визуальному интерфейсу можно относительно быстро построить процесс извлечения данных из внешней системы, обогащение и загрузку в КХД или озеро данных. Ключевые концепции NiFi можно посмотреть в официальной документации.
Почему мы выбрали NiFi для этого проекта:
Мощный визуальный интерфейс. Пользователи могут создавать и настраивать потоки данных, перетаскивая и соединяя готовые компоненты (low-code)
NiFi предлагает набор готовых процессоров, которые покрывают различные сценарии обработки данных.
Способность обрабатывать данные как в режиме реального времени, так и батчами.
Функции контроля доступа к данным: механизмы аутентификации, авторизации и шифрования данных на различных уровнях.
Возможность масштабирования горизонтального и вертикального: можно добавлять новые узлы и ресурсы для увеличения пропускной способности и обработки больших объемов данных.
Возможность нативной интеграции с Schema Registry для хранения схем потоков данных и удобного версионирования.
Apache Airflow: де-факто стандарт в области оркестрации процессов управления данными — и немного больше
Airflow — это Open-Source инструмент управления и планирования задач, основанный на концепции Directed Acyclic Graph (DAG). Он поддерживает множество популярных систем, таких как Apache Spark, Hadoop, BigQuery, AWS S3, MySQL, PostgreSQL.
Airflow — самый распространенный инструмент для оркестрации информационных потоков и рабочих процессов. Обычно он используется как оркестратор, но в некоторых проектах было также его использование в качестве ETL-инструмента.
Что нам нравится в Airflow:
Отличная масштабируемость, использовали кластеры с десятками воркеров
Есть веб-интерфейс, который позволяет визуализировать DAG, отслеживать статус выполнения задач и анализировать логи ошибок, запуска
Поддерживает планирование задач, управление зависимостями и автоматическую повторную попытку выполнения неудачных задач.
Поддерживает стандартные функции Python
Много встроенных коннекторов к большому количеству СУБД
Написан на python, что отлично вписывается универсальность языка для различных задач управления данными, процессов ETL, управления качеством данных и др.
Развитое сообщество и большое количество документации и примеров использования в различных кейсах
Greenplum: основная технология построения MPP-хранилищ в эпоху импортозамещения
Greenplum — Open-Source продукт, массивно-параллельная реляционная СУБД для хранилищ данных с гибкой горизонтальной масштабируемостью и полиморфным хранением данных.
Почему мы выбрали Greenplum для данного проекта:
Массивно-параллельная обработка данных позволяет эффективно обрабатывать большие объемы данных и выполнять сложные аналитические запросы по расчетам критериев рейсов за короткое время.
Возможность хранения данных как построчно, так и поколоночно для разных типов нагрузки
Поддержка SQL и расширяемость: полностью совместим с языком SQL, что облегчает разработку и выполнение аналитических запросов.
Высокая доступность и отказоустойчивость: механизмы резервного копирования, репликации и автоматического восстановления.
Однако, при плохой эксплуатации решения и недостаточности опыта разработки Greenplum может создать достаточно много головной боли. Об этом — ниже
Case Study: нюансы и боль использования NIFI, Airflow и Greenplum на примере внедрения крупной платформы данных в госсекторе
Проект состоял в проверке набора критериев по каждому рейсу вывоза отходов. Требовалось интегрировать набор источников и выстроить регламентные процессы обновления данных и проверки корректности этих критериев.
Если по результатам проверки находились критерии, которые не прошли проверку, то рейс признавался некорректным с указанием конкретных непройденных шагов.
Общая архитектура решения
Архитектура решения представлена ниже — как связаны компоненты системы и слои данных в Greenplum для нашего кейса расчета рейсов:
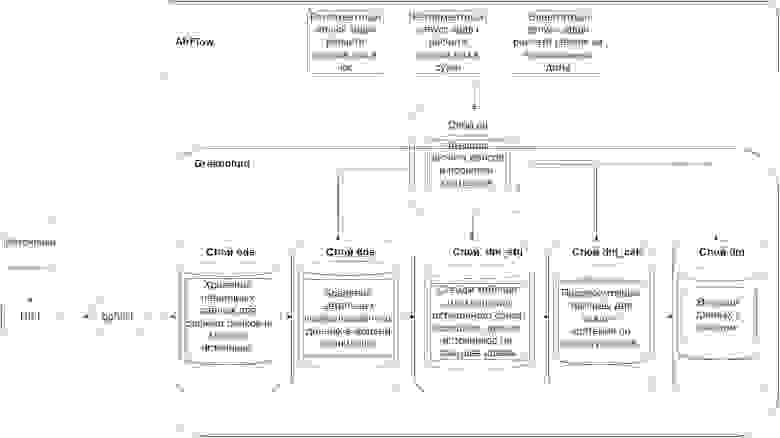
Рис. 1. Общая архитектура решения
Разделение слоев в Greenplum — слой ods для первичных данных с источников, dds для детальных данных в реляционной структуре, dm — слой витрин данных. Все функции перекладки и проверки критериев сделаны на процедурах Greenplum и находятся в отдельном слое — etl. Оркестрация вызова функций сделана из Airflow.
Из интересного — на схеме также указан gpfdist — его мы использовали для более эффективной вставки данных в Greenplum. Он позволяет делать вставку данных напрямую в сегменты, минуя мастер, который становится узким местом при загрузке координат в однопоточном режиме по JDBC (например, используя стандартный процессор в NIFI).
Загрузка данных из источников
Мы использовали NiFi для загрузки данных из источников в слой ODS в Greenplum.
Источники данных и их обновление было следующим:
Мобильное приложение — частота обновления раз в 5 минут
Географические координаты — частота обновления раз в 5 минут
Интеграция со сторонней системой для загрузки общих справочников — частота обновления раз в 4 часа
Система расчета рейсов на основе старого алгоритма — частота обновления раз в 4 часа.
Общее количество таблиц — 18. Вся загрузка таблиц осуществляется инкрементально.
Пайплайн обработки данных выглядел следующим образом:
Забор данных с источника
Сохранение в CSV-файл
Создание external таблицы
Добавление новых записей в целевую БД
Обновление данных уже имеющихся записей за последние 27 часов.
В процессе реализации столкнулись с набором проблем, в частности:
Нехватка ресурсов железа (оперативной памяти, ядер) — постоянная ошибка out of memory. Решение — добавить оперативной памяти (самое простое). Для «тяжелых» сущностей с большим количеством данных — геокоординат грузовых машин, которые грузятся крупными батчами раз в 5 минут, количества памяти не хватало довольно часто, так как пакет данных с источника полностью помещается в оперативную память при извлечении.
Out of memory мы победили — с помощью NiFi нарезались CSV файлы на более мелкие. Так, надо учитывать объем оперативной памяти, чтобы подбирать возможные батчи данных, извлекаемых с источников.
Нестабильная работа gpfdist. Решение — более точная настройка gpfdist под конкретные задачи: например, max-line-length увеличили с 16 до 64, так как попадались некоторые записи при загрузке истории данных, когда длина файла не пролазила и gpfdist падал с ошибкой.
Связка Airflow и NiFi была асинхронная, то есть Airflow DAGs запускались без привязки к процессам загрузок в NIFI. Ее можно сделать синхронной с переходом на событийную загрузку (пришли данные из NIFI в ods — запускаем Airflow DAG), использовать для этого сенсоры в Airflow или API Airflow с вызовом из соответствующих процессных групп NIFI. Решений может быть несколько.
Нарушение типов данных с источника. Частая проблема при интеграциях, когда источник начинает отдавать данные другого, отличного от согласованного типа. Такие случаи рекомендуется решать на стороне источника данных с помощью валидации полей на стороне транзакционной системы.
Обработка критериев
Системой обрабатываются 22 критерия.
Часть критериев довольно просты: проверить, зарегистрированы ли в системе отходопроизводитель и объект вывоза груза, наличие нужного оборудования и ПО на объекте, отметить соответствие времени продолжительности рейса согласованным нормативам и номерам разрешений.
Следующие критерии требовали более сложных расчетов, связанных с координатами объектов и массой перевозимого груза. Например, необходимо было, имея на руках координаты транспортного средства (ТС) и объекта составить периметр объекта и рассчитать местоположение транспортного средства относительно объекта в момент формирования рейса.
По схожей схеме требовалось рассчитать расстояние между ТС и ответственным лицом выполняющим загрузку груза. В промежутке за 2 минуты до и 2 минуты после старта рейса ТС не успело выехать за пределы согласованного расстояния от объекта.
Еще пример критерия: в течение 300 секунд до и после измерения массы ТС при въезде на объект приема требуется наличие хотя бы одной географической координаты ТС.
Для обработки критериев, связанных с координатами, мы использовали библиотеку PostGIS — это Open-Source ПО, добавляющее поддержку географических объектов в PostgreSQL.
Проблемы и выученные уроки разработки на Greenplum
Также извлекли ряд выводов из реализованных задач:
Нельзя создавать большие таблицы без партиционирования, это приводит к потере производительности. Для нас была отсечка — несколько десятков ГБ.
Недостаток оперативной памяти приводит к невозможности использования CTE, при большом объеме данных в CTE запросы перестают работать и падают с ошибкой: Canceling query because of high VMEM usage.
Не стоит выполнять взаимо-блокирующие операции на одну и ту же сущность внутри одной транзакции. К примеру truncate и insert на одну и ту же таблицу.
Нельзя упускать из расчетов недостатки/ баги используемой версии. В конкретном случае при использовании Greenplum на основе Postgresql 9.4 столкнулись с системным багом, сессии переходили в статус idle и из за этого блокировки таблиц не отваливались до тех пор, пока в той же сессии не производился commit или rollback. Как решили: перед каждой итерацией пайплайна настроили проверку таблицы pg_locks на присутствие блокировок сущностей из пайплайна. И отключали эти сессии, чтобы исключить следующие итерации.
Для достижения оптимальной производительности в кластере Greenplum необходимо выбирать серверы однородных характеристик и равномерно распределять данные по ним. Greenplum работает на основе скорости самого медленного сегмента, а равномерное распределение данных сильно влияет на скорость операций Join.
Проблемы эксплуатации Greenplum
С какими трудностями можно столкнуться в процессе эксплуатации?
Несогласованные действия эксплуатации на кластере Greenplum, изменение параметров конфигурации СУБД — например, уменьшение выделенной памяти привело к падениям некоторых функций алгоритма расчета, так как они использовали большее количество памяти. Важно: никакие действия с параметрами конфигурации не должны проводиться без согласования со всеми командами эксплуатации кластера и проектами. Чтобы избежать падений по памяти после изменений настроек памяти Greenplum, мы перешли на создание временных таблиц.
Отсутствие контура Test и контура Preprod. Разработка делалась на контуре stage, при этом релизилось все сразу на контур Prod. На stage нет столько дисков, чтобы иметь возможность проводить нагрузочные тесты. Рекомендация: всегда иметь минимум 3 контура, при этом должен быть минимум 1 контур, полностью повторяющий контур Prod.
Невозможность пользоваться Prod-данными при разработке отчетов — это проблема, так как проводить сверку рейсов на кусочных данных или синтетических не представлялось возможным. Приходилось вручную перетаскивать с Prod-контура данные порциями, однако настроить стабильный поток с Prod-контура на stage физической возможности не было.
Отсутствие регламентных работ на кластере — сбора статистики и вакуумизации таблиц. В частности, отсутствие данных процессов на кластере приводило к тому, что была деградация производительности расчета рейсов — за неделю без вакуумизации и сбора статистики по таблицам время расчета увеличивалось с 50 мин. до 1ч30 мин. Сбор статистики и вакуумизация — крайне важны.
Отсутствие бекапов — в силу отсутствия у заказчика места под бекапы, решили, что они не нужны (все ведь можно перезагрузить с источников). Однако было несколько раз, когда надо было перегружать данные с источников, а они были недоступны по внутренним причинам. Всегда полагаться на источники — не следует.
Airflow: когда зацикливание DAGs между собой может быть неплохо или как уйти от сенсоров
Зацикливание имеет смысл, когда нужно получать данные на лету, то есть добиться максимальной частоты обновления данных в витрине. Применяем это в исключительных случаях при повышенных требованиях бизнеса к частоте обновлений. Так как пайплайн DAGs имеет непрерывный цикл, недостающие данные попадут в витрину в следующей итерации.
Из интересных решений — перестали использовать расписание для построения витрин, а вместо этого использовали триггеры. Сделали это потому, что из-за роста объема данных перестало прогнозироваться время выполнения DAG. Мы ушли от сборки витрин по расписанию, как это было изначально, в сторону событийной загрузки, так как витрины не успевали дожидаться прихода данных в слой DDS.
Еще возникала проблема с нагрузкой на Greenplum, его производительность падала, время отработки ДАГа увеличивалось. Триггеры решили обе эти проблемы.
Результаты
Проект разработки длился около пяти месяцев. Новая система сейчас работает параллельно со старой версией, проходит эксплуатационный период.
Сделали процессы загрузок данных из гетерогенных источников до слоя ODS на базе NiFi для 4 источников и 18 сущностей.
Сделали формирование детального слоя DDS из ODS для 18 сущностей на базе вызова функций Greenplum и DAGs Airflow.
Сделали ежедневный штатный DAG, считающий корректность рейсов ежедневно с вызовом 51 функции за 25 минут, проверяющий 22 критерия успешности рейсов.
Сделали внештатный DAG с запуском расчетов рейсов за произвольные даты.
Что улучшили в процессах заказчика по результатам проекта:
Добились бесперебойной работы NiFi.
Оптимизировали работы gpfdist для работы на конкретных данных и в связке с NIFI — Greenplum
Построили полноценный пайплайн заполнения витрины от DDS до DM с инкрементальным обновлением.
Увеличили частоту обновления данных в витрине
Настроили стабильные процессы эксплуатации Greenplum, которые не приводят к деградации производительности расчета рейсов на Greenplum
