Это база: нюансы работы с Redis. Часть 2, репликация
Всем привет, на связи Пётр, инженер компании Nixys. В прошлой статье мы разобрали основные концепции Redis. Теперь рассмотрим способы организации Redis для высокой доступности.
Прежде чем начать, приглашаем вас подписаться на наш блог Хабр, TG-канал DevOps FM, интернет-издание VC и познакомиться с YouTube — мы всегда рады новым друзьям :) Теперь ближе к делу.
Для начала давайте решим, что мы имеем в виду:
Высокая доступность — это концепция, описывающая системы, гарантирующие высокий уровень безотказной работы. Система высокой доступности спроектирована так, чтобы иметь следующие функции:
отказоустойчивость;
непрерывная работа без вмешательства;
отсутствие единой точки отказа (при выходе из строя одного или более элементов отказоустойчивой системы мы хотим, чтобы система продолжала функционировать в целом).
Помимо этого, кластер с высокой доступностью добавляет нам две полезные функции:
Слейвы можно использовать для распределения запросов на чтение/запись между мастером/слейвом. Это особенно полезно, когда нам необходимо выполнять медленные операции на чтение со сложностью O (N).
Слейвы можно использовать как точки сохранения: сбор AOF или RDB дампов не будет влиять на работу мастера, и, как следствие, не повлияет на корректность работы приложения.
Всё вышеперечисленное приносит ощутимую пользу для бизнеса:
Автоматическое и предсказуемое восстановление работы после сбоя.
Возможность обновления элементов системы без прерывания работы.
И как следствие — увеличение времени безотказной работы сервисов.
И для начала, в рамках этой статьи, предлагаю подробно рассмотреть базовый вариант — мастер-слейв репликацию Redis.
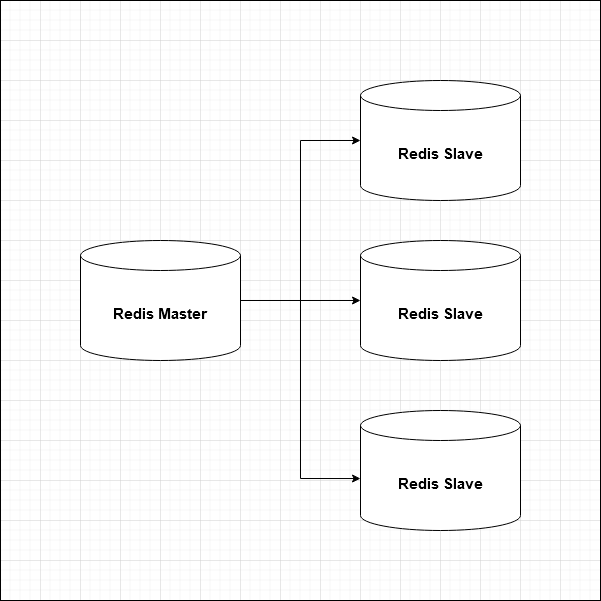
Redis Master-Slave
По умолчанию Redis использует асинхронную репликацию: данные записываются в мастер, а после реплицируются на одну или несколько реплик. При этом мастер не ждёт каждый раз, пока команда будет обработана репликами. После репликации данных клиент может читать данные либо из мастера, либо из любого слейва. Каждый раз, когда происходит обрыв соединения, реплика автоматически переподключается к мастеру и пытается стать его точной копией независимо от того, что происходит с мастером. По большому счёту, с точки зрения слейвов мастера — это немного особые, но всё же клиенты, отправляющие команды (запомним этот тезис, он понадобится нам чуть позже). Для репликации не используется специальный протокол репликации или формат данных.
В основе репликации Redis лежит два основных механизма синхронизации данных:
Частичная синхронизация: штатный способ синхронизации данных между мастером и слейвом. Он работает путём повторного воспроизведения на подчинённых устройствах каждой команды, полученной от мастера Redis, которая фактически произвела изменение в наборе данных.
Полная синхронизация: каждый раз, когда происходит сбой в связи мастера и слейва, а рассинхронизация данных слишком критична, запускается процесс полной синхронизации через запрос от реплики к мастеру. После чего последнему будет необходимо создать снимок всех своих данных, отправить его на реплику, а затем продолжить отправку потока команд по мере изменения набора данных. В момент создания дампа данных мастер разделяется на два отдельных потока: главный поток продолжает отвечать за принятие данных и ответ клиентам, другой несет ответственность за отправку данных в реплику одним из двух способов: дисковый, при котором происходит полный форк данных на диск мастера в виде дампа с последующим переносом данных на слейв, либо бездисковый, при котором дамп данных льется напрямую в слейвы без участия диска мастера. В то же время начинается процесс буферизации всех новых команды записи, полученные от клиентов на мастер. После передачи данных на слейв, мастер отправляет все буферизованные команды реплике. Также полная синхронизация выполняется при первоначальном старте репликации.
Для понимания работы репликации важно понимать два понятия: идентификатор репликации (Replication ID) и смещение репликации (Replication offset). Идентификатор репликации — это псевдослучайная строка, которая отмечает конкретную историю и однозначно идентифицирует поток репликации определенного набора данных. Смещение репликации, с другой стороны, представляет собой 64-битный глобальный счётчик, показывающий, сколько потоков репликации он произвёл. При этом смещение репликации увеличивается, даже если ни одна из реплик не подключена. Метафорически, идентификатор репликации — это номер линии на координатной плоскости, а смещение репликации — это точки на этой линии, помогающие определить текущее местоположение данных относительно друг друга. Концептуально Redis гарантирует, что если два инстанса имеют одинаковые идентификатор репликации и одинаковые смещения репликации, то у них абсолютно одинаковые данные.
Когда экземпляр Redis запускается как мастер, перезапускается или когда реплика Redis повышается до мастера, создается новый идентификатор репликации для этого мастера. При подключении к нему слейва, реплика используют команду PSYNC, чтобы отправить свой идентификатор репликации мастеру и своё текущее смещение, которое он уже обработал. Слейв наследует идентификатор репликации мастера как свой собственный идентификатор, поэтому следующая попытка частичной синхронизации будет предпринята только в том случае, если ID мастера и реплики совпадают, то есть мастер является тем же самым инстансом. Также на мастере происходит сравнение смещения мастера и слейва, при критическом отставании происходит полная синхронизация. Аналогично, если идентификаторы различаются, то также стартует полная синхронизация.
По сравнению с условным MySQL, в котором слейв узнает необходимую мастер-позицию через чтение бинарного лога, лежащего на диске мастер инстанса, Redis хранит необходимые данные в буфере внутри памяти, но выставляет два жестких требования: слейв сможет выполнить частичную синхронизацию только в том случае, если
Он подключается через разумное время, чтобы не было огромного отставания от мастера.
Мастер не был перезапущен.
В противном случае запускается полная синхронизация. Поговорим подробнее про эти буферы, так как это напрямую влияет на настройку Redis.
Буфер бэклога (Backlog buffer) — это буфер, в котором накапливаются данные реплики, когда она отключена от сети на некоторое время. Мастер обладает глобальным для всех слейвов бэклогом настраиваемого размера. Например, если мы выделим для этого буфера 50Mb памяти, то в этом буфере будет содержаться последние 50Mb данных, записанных в мастер. Чем больше бэклог, тем дольше реплика может выдержать отключение и впоследствии сможет выполнить частичную синхронизацию. Если у мастера нет слейвов в течение длительного времени, то бэклог буфер этого мастера уничтожается и не обновляется вообще для экономии ресурсов. Также буфер не начинает автоматически использоваться при запуске нового экземпляра Redis и инициализируется только когда мы подключаем первый слейв инстанс. За размер буфера отвечает параметр repl-backlog-size.
Клиентский буфер репликации (Replication Client Output Buffer). Передача данных по сети по сравнению с чтением данных из ОЗУ — крайне дорогая операция. Так как Redis однопоточен по своей природе, то для скорости работы он стремится как можно быстрее отдать данные клиенту и продолжить выполнять другие операции. Однако возврат ответа на запрос клиента занимает значительно больше времени, чем фактическое получение данных из оперативной памяти процессором Redis. Чтобы обойти этот момент, в Redis есть концепция выходного клиентского буфера. Клиентские буферы составляют пространство памяти, выделенное для обслуживания клиентских запросов, и каждому соединению с Redis выделяется собственное буферное пространство. После обработки запроса Redis копирует данные ответа в буфер клиента и приступает к обработке последующих запросов, в то время как запрашивающий клиент считывает данные обратно через это соединение со своей собственной скоростью, определяемой скоростью его сети.
Помните, что выше писалось о том, что реплика — это своеобразный, но клиент? Так вот реплики получают информацию как обычные клиенты, поэтому данные, которые должны отправляться с мастера, предварительно попадают в этот буфер, пока слейв сервер Redis не завершит полную синхронизацию с мастером. Как только данные отправлены клиенту (в нашем случае реплике), данные из буфера автоматически убираются. Размер буфера для клиента-реплики в Redis регулируется параметром client-output-buffer-limit replica, который настраивается как:
client-output-buffer-limit replica 256mb 64mb 60Где первое число — мягкий лимит, второе — жёсткий, после которого происходит автоматический дисконект реплики, и последнее — время для мягкого лимита. Клиент немедленно отключается, если достигнут жесткий лимит, или если достигнут мягкий лимит и остается таковым в течение указанного количества секунд. Ограничения выходного буфера клиента могут быть использованы для принудительного отключения реплик, которые по каким-то причинам не читают данные с сервера достаточно быстро или вообще не читают. Также в этом буфере хранятся данные, которые будет необходимо залить на слейв после завершения начального этапа полной синхронизации.
При настройке Redis стоит обратить внимание на несколько моментов:
Выделение памяти для буферов репликации берётся не из пространства памяти данных Redis. То есть, при расчёте использования памяти Redis не учитывается размер буфера репликации, и как следствие, он не попадает под параметр maxmemory;
Не имеет смысла устанавливать ограничение клиентского буфера реплики client-output-buffer-limit replica меньше, чем размер конфигурации repl-backlog-size, потому что при ней частичная синхронизация будет успешной, а затем реплика отключится, так как за время синхронизации данных из бэклога буфер репликации переполнится. Такая конфигурация будет проигнорирована и будет автоматически использоваться размер repl-backlog-size.
Размер буфера репликации, очевидно, не бесконечный и может подойти к концу, из-за чего репликация начинается с начала при достижении максимума и уходит в бесконечный цикл. Чтобы этого не произошло, необходимо выполнить настройку ограничения выходного буфера клиента в соответствии с количеством и типами изменений, которые, как ожидается, будут внесены в процессе репликации.
Если мы запросим информацию о репликации через redis-cli, то получим примерно следующий вывод:
$ redis-cli info replication
# Replication
role:master
connected_slaves:1
slave0:127.0.0.1,6380,online,121483
master_repl_offset:121483
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:121482Где:
master_repl_offset — текущее смещение репликации мастер Redis;
second_repl_offset — допустимое смещение репликации, до которого принимаются идентификаторы репликации;
repl_backlog_active — флаг, который указывает, что очередь репликации в буфере бэклога активна;
repl_backlog_size — емкость буфера бэклога в байтах;
repl_backlog_first_byte_offset — смещение мастера в буфера бэклога;
repl_backlog_histlen — общий размер фактических данных в буфере бэклога в байтах;
В этом примере, смещение slave0 совпадает с master_repl_offset, то есть данные в мастере и слейве идентичны. Давайте теперь соберем все полученные данные и попробуем выстроить цепочку действий, которая происходит при репликации:
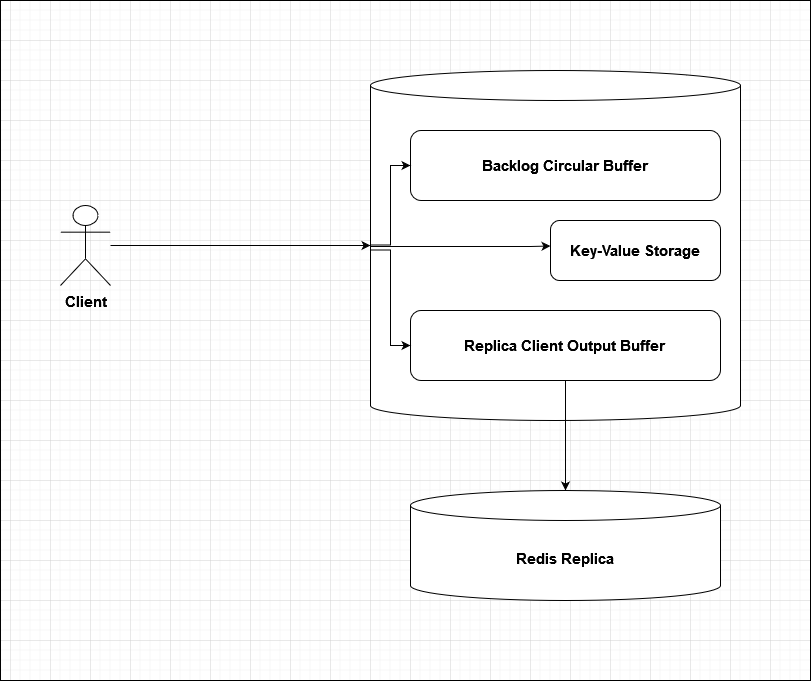
Путь запроса в Redis
Клиент отправляет данные на Redis мастер;
Данные записываются в непосредственно в хранилище ключей Redis, а также в клиентский буфер репликации и буфер бэклога;
При штатной ситуации реплика получает данные клиентского буфера, в зависимости от смещения репликации. Данные удаляются из клиентского буфера, но остаются в буфере бэклога;
Что же происходит после кратковременного отключения слейва?
Слейв отключается; ему необходимо повторно подключиться к мастеру, но структура первого не меняется — он все еще помнит про своего мастера и сохраняет свой идентификатор репликации;
Слейв повторно подключается, организует TCP handshake и использует
REPLCONF get-stream-infoдля получения идентификатора мастера и смещение репликации мастера;Если идентификатора мастера и идентификатора слейва совпадают, то мы можем попробовать провести частичную синхронизацию — вызывается
REPLCONF set-partial-resync-offset, где— это смещение последнего байта, полученного нами по предыдущему каналу репликации, плюс один. Теперь мастер может ответить ошибкой, если отставание слишком критично для запуска частичной синхронизации с указанным смещением, или может ответить ОК, если это возможно; Если все в порядке, инициируется частичная синхронизация, и мастер предоставляет слейву все данные, которые хранятся в буфере бэклога;
После завершения процесса синхронизации слейв доберёт упущенные в процессе частичной синхронизации данные из буфера репликации, обновит сокет, и состояние репликации изменится на CONNECTED;
Если же на шаге №3 возникает ошибка, то стартует процесс полной синхронизации: мастер собирает дамп текущих данных в отдельном потоке, параллельно с этим записывая новую информацию в буфер репликации. Потом идентификатор репликации слейва изменяется на идентификатор репликации мастера, дамп заливается на слейв, и добавляются данные, которые накопились за это время в буфере репликации, после чего статус так же репликации изменится на CONNECTED. В этом случае реплика получила полную копию набора данных мастера с нуля.
Давайте тезисно подчеркнем несколько основных моментов:
Репликация в Redis ассинхронна. При необходимости мастер знает, какая реплика уже обработала ту или иную команду. Это позволяет использовать опциональную синхронную репликацию, однако в продакшене в подавляющем числе случаев используется именно стандартный вариант с асинхронной операцией.
Репликация не блокируется на стороне мастера. Мастер продолжает обрабатывать запросы от клиента, когда одна или несколько реплик выполняют начальную синхронизацию или частичную ресинхронизацию.
Репликация (почти) не блокируется на стороне слейвов. Пока реплика выполняет первоначальный этап полной синхронизации, она может обрабатывать запросы, используя старую версию набора данных, при условии, что вы настроили Redis для этого в redis.conf. В противном случае вы можете настроить реплики Redis так, чтобы они возвращали клиентам ошибку, если поток репликации не работает. Загрузка нового исходного набора данных всё равно будет происходить в основном потоке и блокировать реплику.
У мастера может быть любое количество реплик.
Каждый слейв может выступать мастером для другого инстанса. По умолчанию реплики доступны только для чтения, однако вы можете настроить их так, чтобы в них тоже можно было писать и локальные изменения в слейве будут реплицированы уже на слейвы этого инстанса. Однако стоит помнить, что внесенные на слейв изменения будут затерты при следующей репликации с соответствующего мастера.
Репликация — это прекрасная вещь, однако стоит помнить один критически важный момент:
Ни в коем случае не оставляйте порт Redis открытым наружу без авторизации!
Неважно, будь то стейдж, дев контур или новый сервер, даже если вы решили открыть порт на несколько минут: порт Redis должен быть закрыт всегда либо правилами фаервола, либо сильным паролем. В противном случае вы открываете огромное гостеприимное окно для злоумышленников, и речь идёт даже не о банальном доступе к данным Redis.
В 2020 году команда Alibaba Cloud Security выпустила отчёт, в котором заметила кратное увеличение атак на сервера на базе Linux через червя H2Miner — майнинг-ботнета, который может вторгаться в систему через отсутствие авторизации, в частности через удаленное выполнения команд Redis (RCE). Ботнет загружает вредоносные скрипты для майнинга и горизонтально расширяет ботнет за счёт зараженных серверов. Причина следующая: после версии 4.0, Redis поддерживает функцию загрузки внешних модулей, которая предоставляет пользователям возможность загрузки файлов so, скомпилированных с помощью C в Redis для выполнения определенных команд. Эта функция позволяет злоумышленникам синхронизировать данные со своего Redis на атакуемый инстанс, превратив его в свой слейв через режим fullresync и произведя полную синхронизацию передать на атакуемый сервер вредоносный so файл. После завершения синхронизации злоумышленники подгружают модуль на атакуемый инстанс Redis и выполняют любую команду. Подробный разбор типичной атаки вы можете прочитать в статье от самой команды Alibaba Cloud Security, но ниже мы кратко рассмотрим общий процесс заражения:
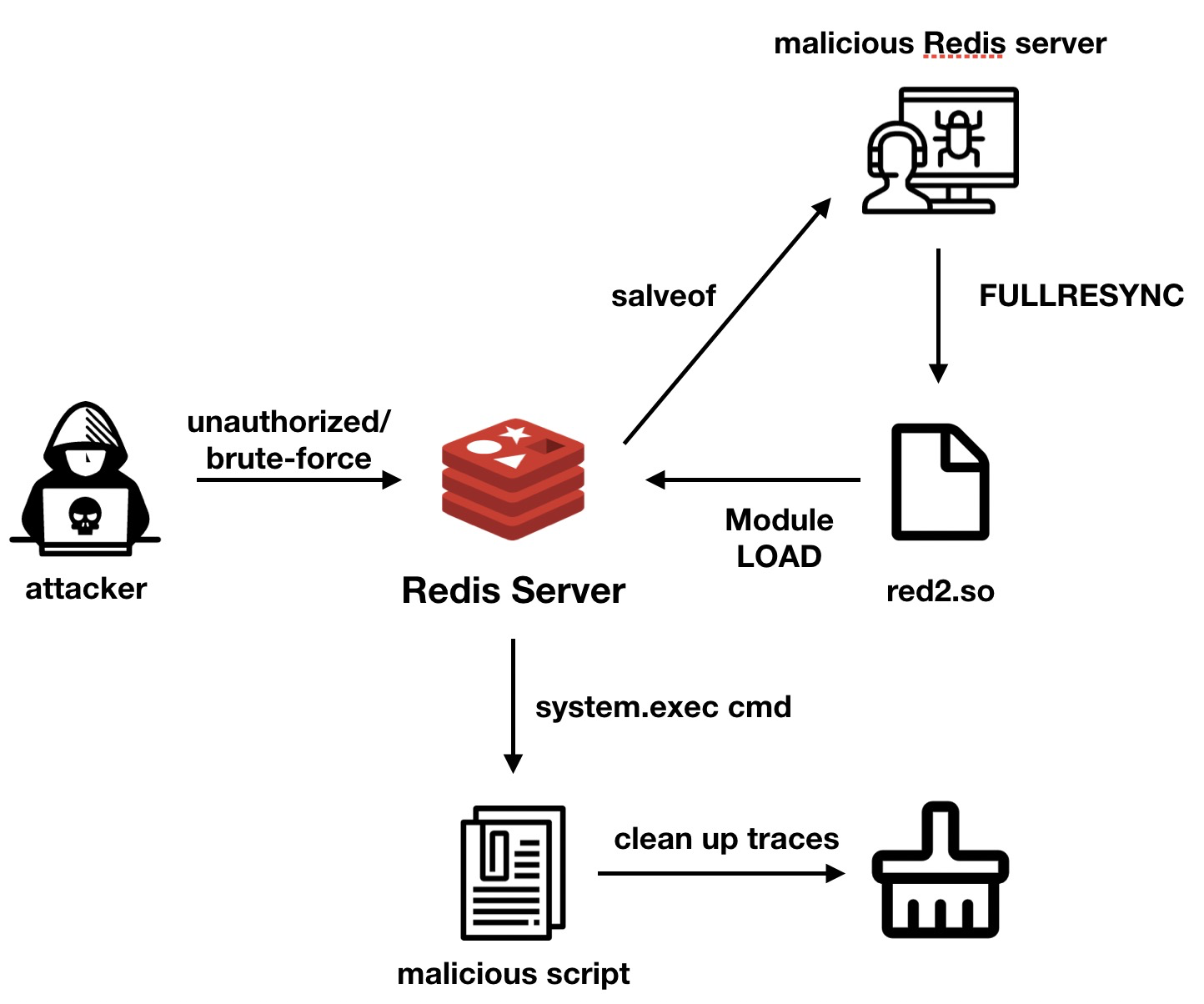
Атака H2Miner
Находится неавторизованный инстанс Redis или Redis со слабым паролем через сканирование открытых портов и последующий Brute-force attack;
На Redis злоумышленника выполнятся команда
config set dbfilename red2.so,чтобы изменить имя файла сохранения;Злоумышленник использует команду
slaveofдля превращения атакуемого Redis в слейв своего инстанса;После установки соединения с вредоносной службой Redis, принадлежащей злоумышленнику, вредоносный Redis отправляет команду
fullresyncдля синхронизации файлов, после чего файл red2.so будет записан на целевой машине, а данные атакуемого Redis будут удалены;Злоумышленник использует
module load ./red2.so, чтобы загрузить этот файл. Этот модуль может выполнять произвольные инструкции или инициировать обратное соединение для получения среды оболочки в соответствии с переданными параметрами;После выполнения вредоносной инструкции, злоумышленник сбросит имя файла резервной копии и использует
module unload, чтобы выгрузить системный модуль для очистки соответствующих следов. Однако, файл red2.so все ещё остается на атакованном хосте.
Вот и всё. В результате, вы, как владелец сервера или системный администратор, получаете следующее:
Полную потерю данных на вашем инстансе Redis;
Потенциально скомпрометированные данные, в зависимости от того, что хранилось в вашем Redis;
Вредоносную утилиту на вашем сервере;
Огромную кучу стресса и проблем.
На этом всё. Сегодня мы рассмотрели работу базовой мастер-слейв репликации Redis. В следующей части этого цикла статей мы подробно изучим отказоустойчивые сетапы Redis для достижения высокой доступности, рассмотрим плюсы и минусы каждого варианта, а также попробуем выбрать оптимальные варианты на все случаи жизни. Увидимся!
