GraphQL — API по-новому
Что такое язык запросов GraphQL? Какие преимущества дает эта технология и с какими проблемами столкнутся разработчики при ее использовании? Как эффективно использовать GraphQL? Обо всем этом под катом.

В основе статьи — доклад вводного уровня Владимира Цукура (volodymyrtsukur) с конференции Joker 2017.
Меня зовут Владимир, я руковожу разработкой одного из департаментов в компании WIX. Более сотни миллионов пользователей WIX создают сайты самой разной направленности — от сайтов-визиток и магазинов до сложных веб-приложений, на которых можно писать код и произвольную логику. В качестве живого примера проекта на WIX я бы хотел показать вам успешный сайт-магазин unicornadoptions.com, который предлагает возможность приобрести набор для приручения единорога — прекрасный подарок для ребенка.

Посетитель этого сайта может выбрать понравившийся набор для приручения единорога, скажем, розовый, затем посмотреть, что именно входит в этот набор: игрушка, сертификат, значок. Далее у покупателя есть возможность добавить товар в корзину, просмотреть ее содержимое и оформить заказ. Это простой пример сайта-магазина, и таких сайтов у нас много, сотни тысяч. Все они построены на одной и той же платформе, с одним бэкендом, с набором клиентов, которые мы поддерживаем, используя для этого API. Именно об API и пойдет речь дальше.
Простой API и его проблемы
Давайте представим себе, какой API общего назначения (то есть один API для всех магазинов поверх платформы) мы бы могли создать, чтобы обеспечить функциональность магазинов. Сконцентрируемся пока сугубо на получении данных.
Для страницы продукта на таком сайте должно возвращаться название продукта, его цена, картинки, описание, дополнительная информация и многое другое. В полноценном решении для магазинов на WIX таких полей данных — более чем два десятка. Стандартное решение для такой задачи поверх HTTP API — это описать ресурс /products/:id, который на GET-запрос возвращает данные продукта. Ниже указан пример данных ответа:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!",
"sku":"010",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
]
}

Давайте теперь посмотрим на страницу каталога продуктов. Для этой страницы понадобится ресурс-коллекция /products. Вот только в отображении коллекции продуктов на странице каталога нужны не все данные продуктов, а лишь цена, название и основное изображение. Например, описание, дополнительная информация, второстепенные изображения и прочее нас не интересуют.

Допустим, для простоты, мы решаем использовать одинаковую модель данных продукта для ресурсов /products и /products/:id. В случае коллекции таких продуктов потенциально будет несколько. Схему ответа можно представить следующим образом:
GET /products
[
{
title
price
images
description
info
...
}
]
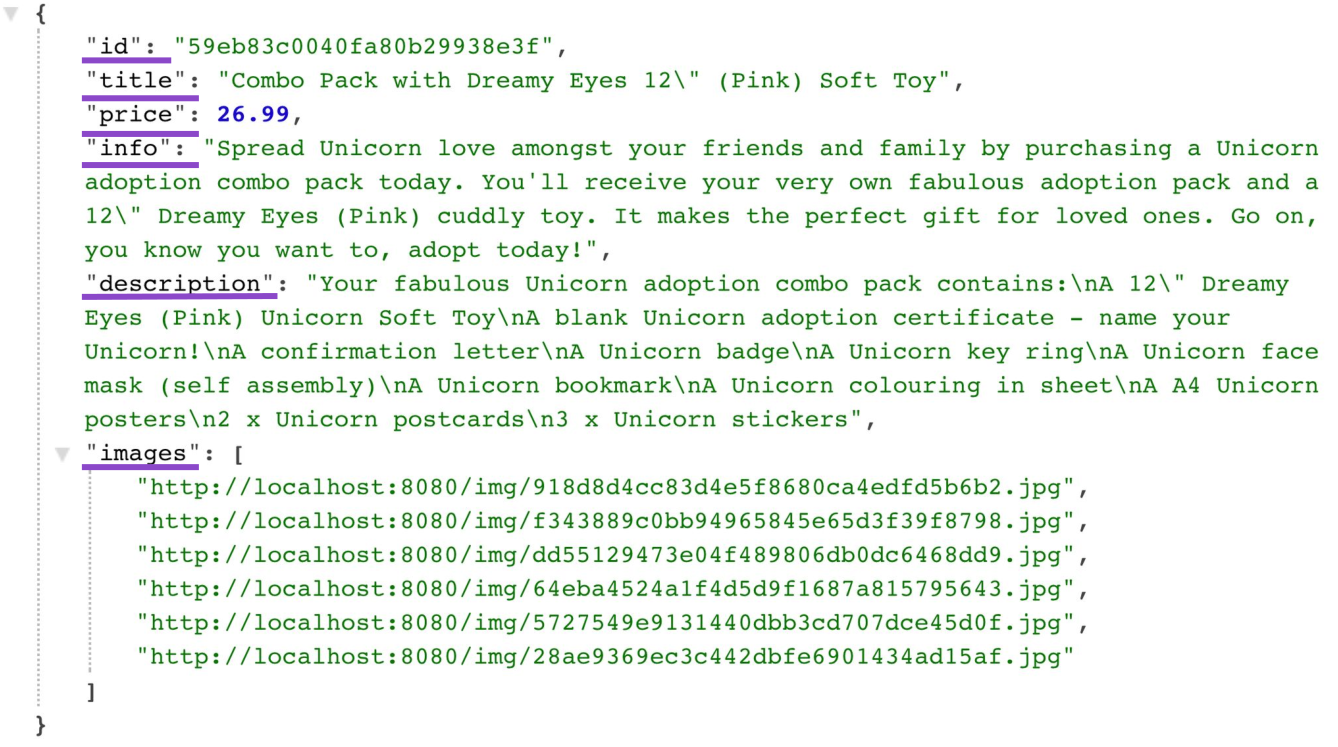
А теперь давайте посмотрим на «полезную нагрузку» ответа от сервера для коллекции продуктов. Вот что в действительности используется клиентом среди более чем двух десятков полей:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
"description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}
Очевидно, что если я хочу держать модель продукта простой, возвращая одинаковые данные, то в итоге сталкиваюсь с over-fetching проблемой, получая в некоторых случаях больше данных, чем мне необходимо. В данном случае это проявилось на странице каталога продуктов, но вообще, любые экраны UI, которые так или иначе связаны с продуктом, потребуют от него потенциально только части (а не всех) данных.
Давайте теперь рассмотрим страницу корзины. В корзине, кроме самих продуктов, есть еще их количество (в этой корзине), цена, а также суммарная стоимость всего заказа:

Если продолжать подход простого моделирования HTTP API, то корзина может быть представлена через ресурс /carts/: id, представление которого ссылается на ресурсы продуктов, добавленных в эту корзину:
{
"id": 1,
"items": [
{
"product": "/products/59eb83c0040fa80b29938e3f",
"quantity": 1,
"total": 26.99
},
{
"product": "/products/59eb83c0040fa80b29938e40",
"quantity": 2,
"total": 25.98
},
{
"product": "/products/59eb88bd040fa8125aa9c400",
"quantity": 1,
"total": 26.99
}
],
"subTotal": 79.96
}
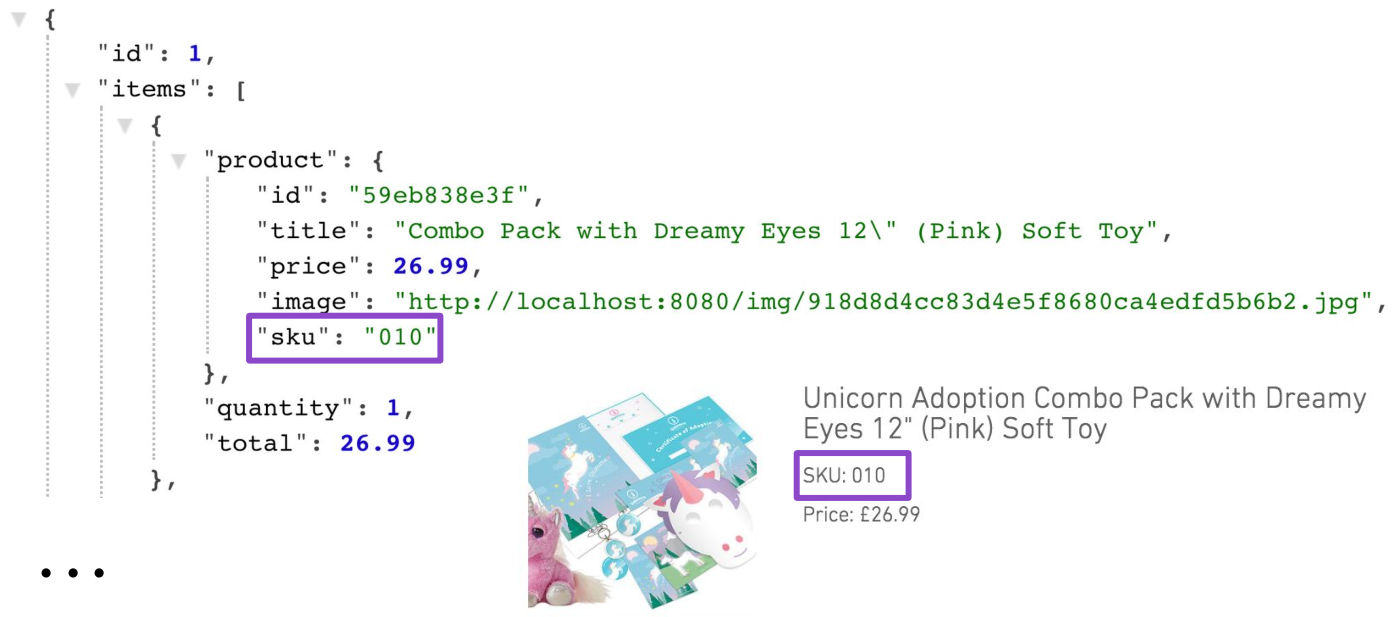
Теперь, например, для того чтобы отрисовать корзину с тремя продуктами на фронтенде, необходимо сделать четыре запроса: один для того, чтобы загрузить саму корзину, и три запроса, чтобы загрузить данные по продуктам (название, цену и артикул SKU).
Вторая проблема, которая у нас возникла — under-fetching. Разграничение ответственности между ресурсами корзины и продукта привело к необходимости делать дополнительные запросы. Тут очевидно есть ряд недостатков: из-за большего количества запросов батарею мобильного телефона мы сажаем быстрее и полный ответ получаем медленнее. И к масштабируемости нашего решения тоже возникают вопросы.
Конечно же, такое решение не подходит для продакшена. Один из способов избавиться от проблемы — это добавить поддержку проекций для корзины. Одна из таких проекций могла бы кроме данных самой корзины возвращать и данные по продуктам. Причем эта проекция будет очень специфическая, потому что именно на странице корзины нужен инвентарный номер (SKU) продукта. Нигде в других местах SKU пока что не был нужен.
GET /carts/1?projection=with-products
Такая «подгонка» ресурсов под конкретный UI обычно не заканчивается, и мы начинаем генерировать другие проекции: краткую информацию по корзине, проекцию корзины для мобильного web, а после этого — и вовсе проекцию для единорогов.

(А вообще, в конструкторе WIX вы как пользователь можете сконфигурировать, какие данные продукта вы хотите отображать на странице продукта и какие данные показывать в корзине)
И тут нас подстерегают трудности: мы городим огород и ищем сложные решения. Стандартных решений с точки зрения API для такой задачи немного, и они обычно сильно зависят от фреймворка или библиотеки описания HTTP-ресурсов.
Что еще важно, теперь становится тяжелее работать, потому что, когда меняются требования на клиентской стороне, бэкенд должен их постоянно «догонять» и удовлетворять.
В качестве «вишенки на торте» давайте рассмотрим еще одну важную проблему. В случае простого HTTP API серверный разработчик понятия не имеет, какие именно данные используются клиентом. Используется ли цена? Описание? Одно или все изображения?
Соответственно, возникает несколько вопросов. Как работать с deprecated / устаревшими данными? Как узнавать, какие данные действительно больше не используются? Как относительно безопасно убрать данные с ответа, не поломав большинство клиентов? Ответа на эти вопросы с привычным HTTP API нет. Вопреки тому, что мы оптимистичны и вроде бы API у нас простой, ситуация выглядит не ахти. Такой спектр проблем с API возник не только у WIX. С ними пришлось иметь дело большому количеству компаний. А теперь интересно посмотреть на потенциальное решение.
GraphQL. Начало
В 2012 году в процессе разработки мобильного приложения с подобной проблемой столкнулась компания Facebook. Инженерам хотелось достичь минимального количества обращений мобильного приложения к серверу, при этом на каждом шаге получая только нужные данные и ничего, кроме них. Результатом их усилий стал GraphQL, представленный в 2015 году на конференции React Conf. GraphQL — это язык описания запросов, а также среда исполнения этих запросов.

Рассмотрим типичный подход к работе с GraphQL-серверов.
Описываем схему
Схема данных в GraphQL определяет типы и связи между ними и делает это в строго-типизированной манере. Например, представим себе простую модель социальной сети. Пользователь User знает про своих друзей friends. Пользователи живут в городе City, и город знает про своих жителей через поле citizens. Вот что является графом такой модели в GraphQL:
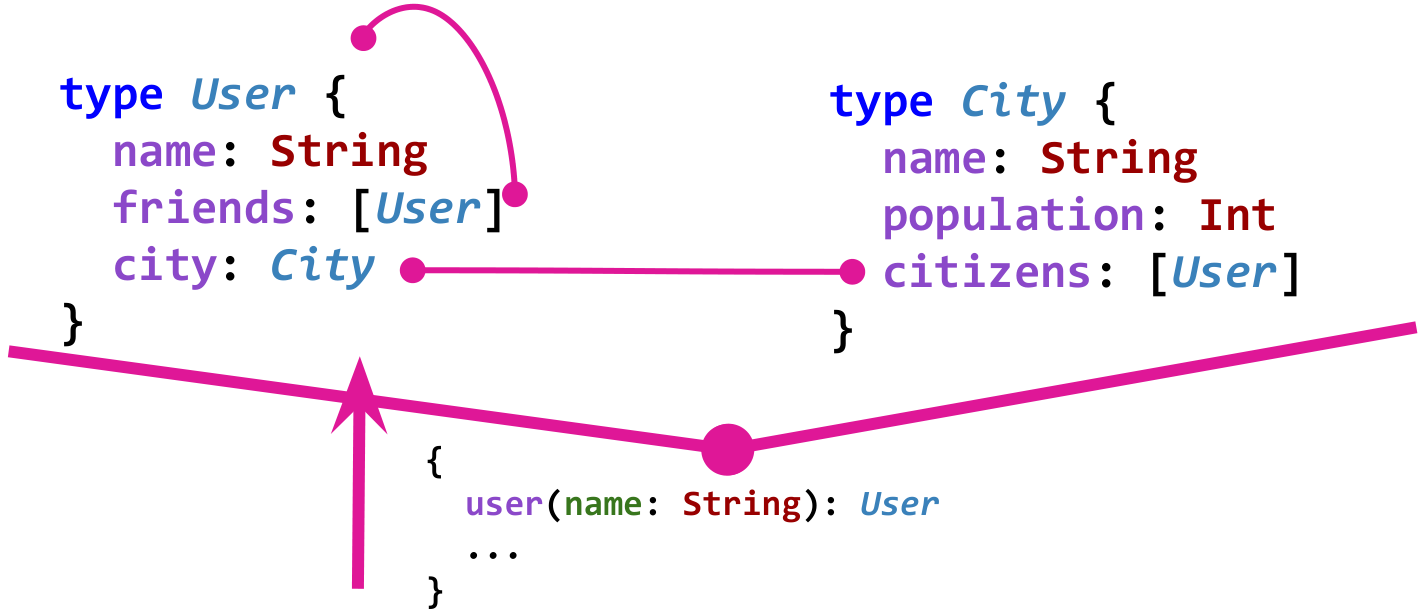
Конечно же, для того чтобы граф был полезным, нужны еще так называемые «точки входа». Например, такой точкой входа может быть получение пользователя по имени.
Запрашиваем данные
Давайте посмотрим, в чем суть языка запросов GraphQL. Переведем на этот язык такой вопрос: «Для пользователя с именем Vanya Unicorn, хочу узнать имена его друзей, а также название и население города, в котором Ваня проживает»:
{
user(name: "Vanya Unicorn") {
friends {
name
}
city {
name
population
}
}
}
И вот приходит ответ от GraphQL-сервера:
{
"data": {
"user": {
"friends": [
{ "name": "Lena" },
{ "name": "Stas" }
]
"city": {
"name": "Kyiv",
"population": 2928087
}
}
}
}
Обратите внимание, как форма запроса «созвучна» с формой ответа. Возникает ощущение, что этот язык запросов создавался для JSON. Со строгой типизацией. И все это делается за один запрос HTTP POST — не нужно делать несколько обращений к серверу.
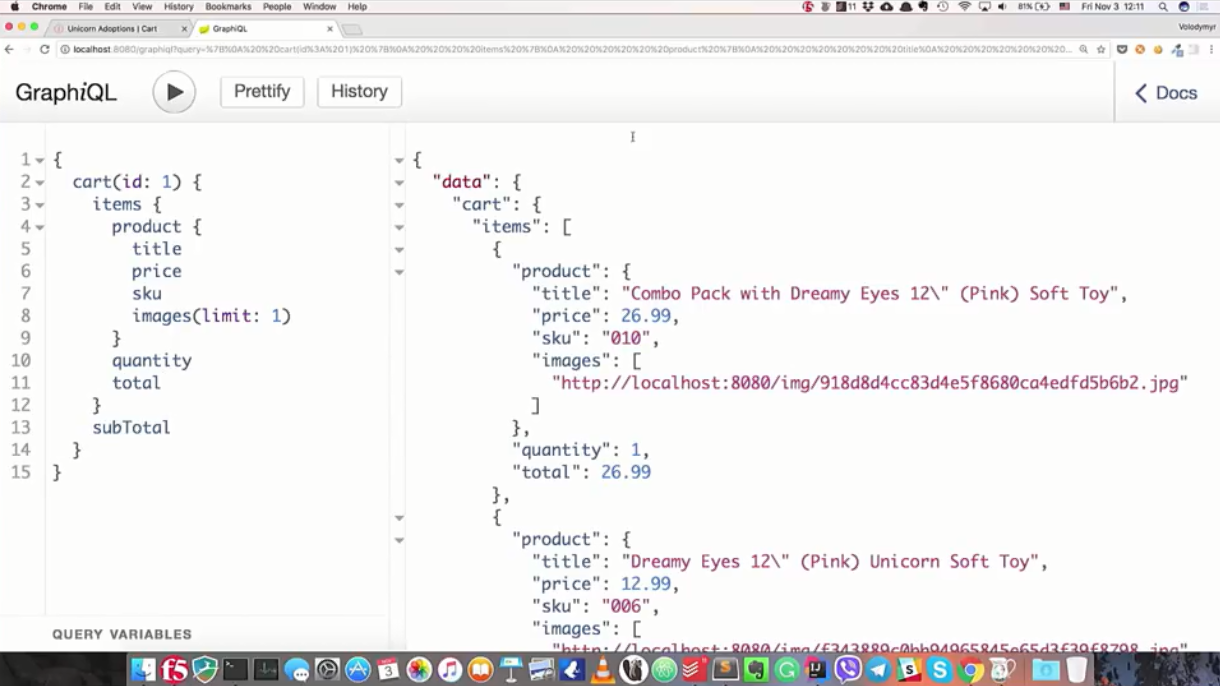
Давайте посмотрим, как это выглядит на практике. Откроем стандартную консоль для GraphQL-сервера, которая называется GraphiQL («графикл»). Для запроса на корзину я выполню следующий запрос: «Хочу получить корзину по идентификатору 1, интересуют все позиции этой корзины и информация по продуктам. Из информации важны название, цена, инвентарный номер и изображения (причем только первое). Также меня интересует количество этих продуктов, какова их цена и общая стоимость в рамках корзины».
{
cart(id: 1) {
items {
product {
title
price
sku
images(limit: 1)
}
quantity
total
}
subTotal
}
}
После успешного выполнения запроса получем ровно то, что попросили:
Главные преимущества
- Гибкая выборка. Клиент может составить запрос под свои конкретные требования.
- Эффективная выборка. В ответе возвращаются только запрошенные данные.
- Более быстрая разработка. Много изменений на клиенте могут происходить без необходимости менять что-либо на серверной стороне. Например, исходя из нашего примера, запросто можно показать другое представление корзины для мобильного web.
- Полезная аналитика. Так как клиент обязан в запросе указывать поля явно, сервер точно знает, какие поля действительно нужны. А это важная информация для deprecation-политики.
- Работает поверх любого источника данных и транспорта. Важно, что GraphQL позволяет работать поверх любого источника данных и любого транспорта. В данном случае HTTP — это не панацея, GraphQL может также работать через WebSocket, и мы чуть позже затронем этот момент.
Сегодня GraphQL-сервер можно сделать практически на любом языке. Наиболее полная версия GraphQL-сервера — GraphQL.js для Node-платформы. В Java-комьюнити эталонной реализацией является GraphQL Java.
Создаем GraphQL API
Давайте посмотрим, как создать GraphQL-сервер на конкретном жизненном примере.
Рассмотрим упрощенную версию интернет-магазина на основе микросервисной архитектуры с двумя компонентами:
- Cart-сервис, обеспечивающий работу с пользовательской корзиной. Хранит данные в реляционной БД и использует SQL для доступа к данным. Очень простой сервис, без лишней магии :)
- Product-сервис, обеспечивающий доступ к продуктовому каталогу, из которого, собственно, и наполняется корзина. Предоставляет HTTP API для доступа к продуктовым данным.
Оба сервиса реализованы поверх классического Spring Boot и уже содержат всю базовую логику.
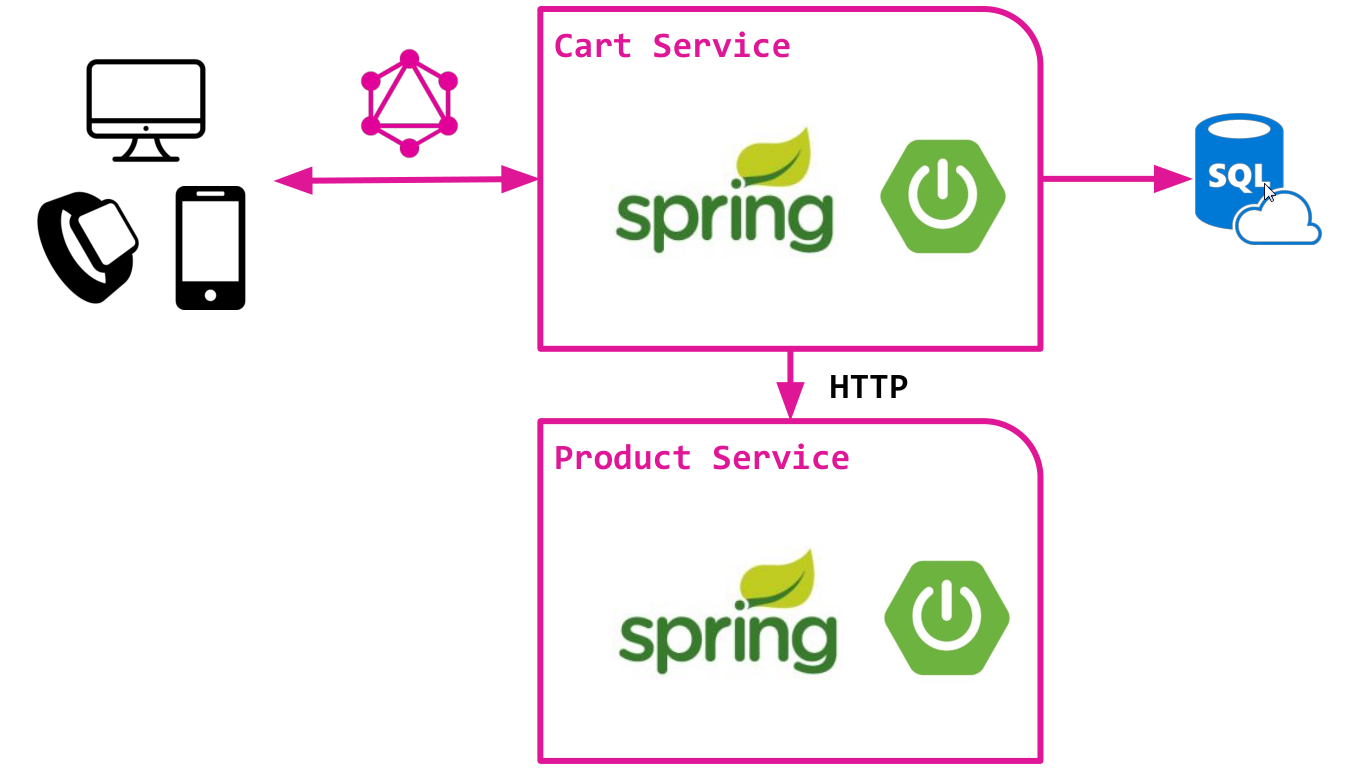
Мы же намерены создать GraphQL API поверх Cart-сервиса. Этот API призван обеспечить доступ к данным корзины и добавленным в нее продуктам.
Первая версия
Нам поможет эталонная реализация GraphQL для экосистемы Java, о которой мы упоминали ранее — GraphQL Java.
Добавим несколько зависимостей в pom.xml:
com.graphql-java
graphql-java
9.3
com.graphql-java
graphql-java-tools
5.2.4
com.graphql-java
graphql-spring-boot-starter
5.0.2
com.graphql-java
graphiql-spring-boot-starter
5.0.2
В дополнение к ранее упомянутой graphql-java нам понадобится библиотека инструментов graphql-java-tools,, а также Spring Boot «стартеры» для GraphQL, которые значительно упростят первые шаги по созданию GraphQL-сервера:
- graphql-spring-boot-starter предоставляет механизм быстрой связки GraphQL Java с Spring Boot;
- graphiql-spring-boot-starter добавляет интерактивную веб-консоль GraphiQL для выполнения GraphQL-запросов.
Следующий важный шаг — это определить схему GraphQL-сервиса, наш граф. Узлы этого графа описываются с помощью типов, а ребра с помощью полей. Пустое определение графа выглядит так:
schema {
}
В этой самой схеме, как вы помните, есть «точки входа» или запросы верхнего уровня. Они определяются через поле query в схеме. Назовем наш тип для точек входа EntryPoints:
schema {
query: EntryPoints
}
Определим в нем поиск корзины по идентификатору как первую точку входа:
type EntryPoints {
cart(id: Long!): Cart
}
Cart — это и есть не что иное как поле в терминах GraphQL. id — параметр этого поля со скалярным типом Long. Восклицательный знак ! после указания типа означает, что параметр обязательный.
Самое время определить и тип Cart:
type Cart {
id: Long!
items: [CartItem!]!
subTotal: BigDecimal!
}
Кроме стандартного идентификатора id в корзину входят ее элементы items и сумма за все товары subTotal. Обратите внимание, что items определены как список, о чем свидетельствуют квадратные скобки []. Элементы этого списка являются типами CartItem. Наличие восклицательного знака после названия типа поля ! указывает, что поле обязательное. Это значит, что сервер обязуется вернуть непустое значение для этого поля, если оно было запрошено.
Осталось посмотреть на определение типа CartItem, в который входит ссылка на продукт (productId), сколько раз он добавлен в корзину (quantity) и сумма продукта, пересчитанная на количество (total):
type CartItem {
productId: String!
quantity: Int!
total: BigDecimal!
}
Здесь всё просто — все поля скалярных типов и являются обязательными.
Такая схема выбрана не случайно. В Cart-сервисе уже определена корзина Cart и ее элементы CartItem с точно такими же названиями и типами полей, как и в схеме GraphQL. Модель корзины использует библиотеку Lombok для автогенерации геттеров/сеттеров, конструкторов и других методов. JPA используется для персистенции в БД.
Класс Cart:
import lombok.Data;
import javax.persistence.*;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
@Entity
@Data
public class Cart {
@Id
@GeneratedValue
private Long id;
@ElementCollection(fetch = FetchType.EAGER)
private List items = new ArrayList<>();
public BigDecimal getSubTotal() {
return getItems().stream()
.map(Item::getTotal)
.reduce(BigDecimal.ZERO, BigDecimal::add);
}
}
Класс CartItem:
import lombok.AllArgsConstructor;
import lombok.Data;
import javax.persistence.Column;
import javax.persistence.Embeddable;
import java.math.BigDecimal;
@Embeddable
@Data
@AllArgsConstructor
public class CartItem {
@Column(nullable = false)
private String productId;
@Column(nullable = false)
private int quantity;
@Column(nullable = false)
private BigDecimal total;
}
Итак, корзина (Cart) и элементы корзины (CartItem) описаны и в GraphQL-схеме, и в коде, и «совместимы» между собой по набору полей и их типам. Но этого еще недостаточно для того, чтобы наш сервис заработал.
Нам необходимо уточнить, как именно будет работать точка входа »cart(id: Long!): Cart». Для этого создадим крайне простую Java-конфигурацию для Spring с bean-ом типа GraphQLQueryResolver. GraphQLQueryResolver как раз и описывает «точки входа» в схеме. Определим метод с именем, идентичным полю в точке входа (cart), сделаем его совместимым по типу параметров и воспользуемся cartService для того, чтобы найти ту самую корзину по идентификатору:
@Bean
public GraphQLQueryResolver queryResolver() {
return new GraphQLQueryResolver () {
public Cart cart(Long id) {
return cartService.findCart(id);
}
}
}
Этих изменений нам достаточно для получения работающего приложения. После перезапуска Cart-сервиса в консоли GraphiQL начнет успешно исполняться следующий запрос:
{
cart(id: 1) {
items {
productId
quantity
total
}
subTotal
}
}
На заметку
- В качестве уникальных идентификаторов корзины и продукта мы используем скалярные типы
LongиString. В GraphQL есть специальный тип для таких целей —ID. Семантически это более правильный выбор для настоящего API. Значения типаIDмогут использоваться как ключ для кэширования. - На данном этапе разработки нашего приложения внутренняя и внешняя модель предметной области полностью идентичны. Речь идет о классах
CartиCartItemи их непосредственном использовании в GraphQL-резолверах. В боевых приложениях эти модели рекомендуется разделять. Для GraphQL-резолверов должна существовать отдельная от внутренней предметной области модель.
Делаем API полезным
Вот мы и получили первый результат, и это замечательно. Но сейчас наш API слишком примитивен. Например, пока что нет возможности запросить полезные данные по продукту, такие как его название, цена, артикул, картинки и так далее. Вместо этого есть всего лишь productId. Давайте сделаем API действительно полезным и добавим полноценную поддержку понятия продукта. Вот как выглядит его определение в схеме:
type Product {
id: String!
title: String!
price: BigDecimal!
description: String
sku: String!
images: [String!]!
}
Добавим нужное поле в CartItem, а поле productId пометим как устаревшее:
type Item {
quantity: Int!
product: Product!
productId: String! @deprecated(reason: "don't use it!")
total: BigDecimal!
}
Со схемой разобрались. А теперь самое время описать, как именно будет работать выборка для поля product. Ранее мы полагались на наличие геттеров в классах Cart и CartItem, что позволяло GraphQL Java автоматически связывать значения. Но тут следует напомнить, что как раз свойства product в классе CartItem нет:
@Embeddable
@Data
@AllArgsConstructor
public class CartItem {
@Column(nullable = false)
private String productId;
@Column(nullable = false)
private int quantity;
@Column(nullable = false)
private BigDecimal total;
}
Перед нами стоит выбор:
- добавить свойство product в CartItem и «научить» его получать данные по продуктам;
- определить, как получать product, не изменяя класс CartItem.
Второй путь более предпочтителен, потому что модель описания внутренней предметной области (класс CartItem) в этом случае не будет обрастать деталями реализации GraphiQL API.
В достижении этой цели поможет маркер-интерфейс GraphQLResolver. Реализуя его, можно определить (или переопределить), как именно получать значения полей для типа T. Вот как выглядит соответствующий bean в Spring-конфигурации:
@Bean
public GraphQLResolver cartItemResolver() {
return new GraphQLResolver() {
public Product product(CartItem item) {
return http.getForObject("http://localhost:9090/products/{id}",
Product.class,
item.getProductId());
}
};
}
Название метода product выбрано не случайно. GraphQL Java ищет методы-загрузчики данных по имени поля, а нам как раз нужно было определить загрузчик для поля product! Объект типа CartItem, переданный как параметр, определяет контекст, в котором выбирается продукт. Дальше — дело техники. С помощью клиента http типа RestTemplate мы выполняем GET-запрос к Product-сервису и преобразуем результат в Product, который выглядит так:
@Data
public class Product {
private String id;
private String title;
private BigDecimal price;
private String description;
private String sku;
private List images;
}
Этих изменений должно быть достаточно для того, чтобы реализовать более интересную выборку, которая включает настоящую связь между корзиной и продуктами, которые в нее добавлены.
После перезапуска приложения можно попробовать новый запрос в консоли GraphiQL.
{
cart(id: 1) {
items {
product {
title
price
sku
images
}
quantity
total
}
subTotal
}
}
А вот как выглядит результат исполнения запроса:

Несмотря на то, что productId был помечен как @deprecated, запросы с указанием этого поля будут продолжать работать. Но консоль GraphiQL не будет предлагать автозаполнение для таких полей и специальным образом подсветит их использования:

Самое время показать и Document Explorer, часть GraphiQL-консоли, которая строится на основе GraphQL-схемы и показывает информацию по всем определенным типам. Вот как выглядит Document Explorer для типа CartItem:

Но вернемся обратно к примеру. Для того чтобы достичь той же функциональности, что и в самом первом демо, еще не хватает наложения лимита на количество возвращаемых изображений. Ведь для корзины, например, нужно только одно изображение для каждого продукта:
images(limit: 1)
Для этого поменяем схему и добавим новый параметр для поля images в тип Product:
type Product {
id: ID!
title: String!
price: BigDecimal!
description: String
sku: String!
images(limit: Int = 0): [String!]!
}
А в коде приложения опять воспользуемся GraphQLResolver, только на этот раз по типу Product:
@Bean
public GraphQLResolver productResolver() {
return new GraphQLResolver() {
public List images(Product product, int limit) {
List images = product.getImages();
int normalizedLimit = limit > 0 ? limit : images.size();
return images.subList(0, Math.min(normalizedLimit, images.size()));
}
};
}
Опять обращаю внимание, что название метода не случайно: он совпадает с названием поля images. Контекстный объект Product дает доступ к изображениям, а limit является параметром самого поля.
Если клиент ничего не указал в качестве значения для limit, то наш сервис вернет все изображения продукта. Если же клиент указал конкретное значение, то сервис вернет ровно столько (но не больше, чем их есть вообще в продукте).
Компилируем проект и ждем, пока сервер перезапустится. Перезапуская в консоли схему и исполняя запрос, видим, что действительно работает полноценный запрос.
{
cart(id: 1) {
items {
product {
title
price
sku
images(limit: 1)
}
quantity
total
}
subTotal
}
}
Согласитесь, все это очень здорово. За короткое время мы не только узнали, что такое GraphQL, но и перевели простую микросервисную систему на поддержку такого API. И нам было неважно, откуда приходили данные: как SQL, так и HTTP API хорошо уложились под одной крышей.
Подход Code-First и GraphQL SPQR
Вы могли обратить внимание, что в процессе разработки было некоторое неудобство, а именно необходимость постоянно держать GraphQL-схему и код в синхронизации. Изменения типов всегда нужно было делать в двух местах. Во многих случаях удобнее использовать подход code-first. Суть его состоит в том, что схема для GraphQL автоматически генерируется на основе кода. В этом случае не нужно поддерживать схему отдельно. Сейчас я покажу, как это выглядит.
Только базовых возможностей GraphQL Java нам уже недостаточно, понадобится еще библиотека GraphQL SPQR. Хорошие новости в том, что GraphQL SPQR — это надстройка над GraphQL Java, а не альтернативная реализация GraphQL-сервера на Java.
Добавим нужную зависимость в pom.xml:
io.leangen.graphql
spqr
0.9.8
Вот как выглядит код, реализующий ту же самую функциональность на основе GraphQL SPQR для корзины:
@Component
public class CartGraph {
private final CartService cartService;
@Autowired
public CartGraph(CartService cartService) {
this.cartService = cartService;
}
@GraphQLQuery(name = "cart")
public Cart cart(@GraphQLArgument(name = "id") Long id) {
return cartService.findCart(id);
}
}
И для продукта:
@Component
public class ProductGraph {
private final RestTemplate http;
@Autowired
public ProductGraph(RestTemplate http) {
this.http = http;
}
@GraphQLQuery(name = "product")
public Product product(@GraphQLContext CartItem cartItem) {
return http.getForObject(
"http://localhost:9090/products/{id}",
Product.class,
cartItem.getProductId()
);
}
@GraphQLQuery(name = "images")
public List images(@GraphQLContext Product product,
@GraphQLArgument(name = "limit", defaultValue = "0") int limit) {
List images = product.getImages();
int normalizedLimit = limit > 0 ? limit : images.size();
return images.subList(0, Math.min(normalizedLimit, images.size()));
}
}
Аннотация @GraphQLQuery используется для того, чтобы помечать методы-загрузчики полей. Аннотация @GraphQLContext задает, в рамках какого типа происходит выборка для поля. А аннотация @GraphQLArgument помечает явно параметры-аргументы. Все это частички одного механизма, который помогает GraphQL SPQR генерировать схему автоматически. Теперь если удалить старую Java-конфигурацию и схему, перезапустить Cart-сервис с использованием новых фишек от GraphQL SPQR, то можно убедиться, что функционально все работает точно так же, как и раньше.
Решаем проблему N+1
Настало время посмотреть в больших деталях, как работает выполнение всего запроса «под капотом». Мы быстро создали GraphQL API, но работает ли он эффективно?
Рассмотрим следующий пример:

Получение корзины cart происходит в один SQL-запрос к базе данных. Данные по items и subtotal возвращаются там же, ведь элементы корзины подгружаются вместе со всей коллекцией, исходя из JPA-стратегии eager fetch:
@Data
public class Cart {
@ElementCollection(fetch = FetchType.EAGER)
private List- items = new ArrayList<>();
...
}

Когда же дело доходит до загрузки данных по продуктам, то запросов на Product-сервис будет выполнено ровно столько, сколько в данной корзине продуктов. Если в корзине три разных продукта, то мы получим три запроса к HTTP API сервиса продуктов, а если же их десять — то тому же сервису придется отвечать на десять таких запросов.

Вот как выглядит коммуникация между Cart-сервисом и Product-сервисом в Charles Proxy:

Соответственно, мы возвращаемся к классической проблеме N+1. Ровно той, от которой так старались уйти в самом начале доклада. Несомненно, у нас есть прогресс, ведь между конечным клиентом и нашей системой выполняется ровно один запрос. Но внутри серверной экосистемы производительность явно требует улучшений.
Я хочу решить эту проблему, получив все нужные продукты за один запрос. Благо, Product-сервис уже поддерживает такую возможность через параметр ids в ресурсе коллекции:
GET /products?ids=:id1,:id2,...,:idn
Посмотрим, как можно модифицировать код метода выборки для поля product. Предыдущую версию:
@GraphQLQuery(name = "product")
public Product product(@GraphQLContext CartItem cartItem) {
return http.getForObject(
"http://localhost:9090/products/{id}",
Product.class,
cartItem.getProductId()
);
}
Заменим на более эффективную:
@GraphQLQuery(name = "product")
@Batched
public List products(@GraphQLContext List- items) {
String productIds = items.stream()
.map(Item::getProductId)
.collect(Collectors.joining(","));
return http.getForObject(
"http://localhost:9090/products?ids={ids}",
Products.class,
productIds
).getProducts();
}
Мы сделали ровно три вещи:
- пометили метод-загрузчик аннотацией @Batched, дав понять GraphQL SPQR, что загрузка должна происходить батчем;
- изменили возвращаемый тип и контекстный параметр на список, ведь работа с батчем предполагает, что принимается и возвращается несколько объектов;
- поменяли тело метода, реализовав выборку всех нужных продуктов за один раз.
Этих изменений достаточно для того, чтобы решить нашу проблему N+1. В окне приложения Charles Proxy видно теперь один запрос к Product-сервису, который возвращает три продукта сразу:

Эффективные выборки по полям
Мы решили основную проблему, но можно сделать выборку еще быстрее! Сейчас Product-сервис возвращает все данные, независимо от того, что нужно конечному клиенту. Мы могли бы улучшить запрос и возвращать только запрошенные поля. Например, если конечный клиент не просил изображения, зачем нам вообще их передавать на Cart-сервис?
Отлично, что HTTP API Product-сервиса уже поддерживает эту возможность через параметр include для того же самого ресурса коллекции:
GET /products?ids=...?include=:field1,:field2,...,:fieldN
Для метода загрузчика добавим параметр типа Set с аннотацией @GraphQLEnvironment. GraphQL SPQR понимает, что код в этом случае «просит» список имен полей, которые запрошены для продукта, и автоматически заполняет их:
@GraphQLQuery(name = "product")
@Batched
public List products(@GraphQLContext List- items,
@GraphQLEnvironment Set
fields) {
String productIds = items.stream()
.map(Item::getProductId)
.collect(Collectors.joining(","));
return http.getForObject(
"http://localhost:9090/products?ids={ids}&include={fields}",
Products.class,
productIds,
String.join(",", fields)
).getProducts();
}
Теперь наша выборка действительная эффективная, лишена проблемы N+1 и задействует только нужные данные:

«Тяжелые» запросы
Представим себе работу с графом пользователей в рамках классической социальной сети, такой как Facebook. Если такая система предоставляет GraphQL API, то клиенту ничего не мешает послать запрос следующего характера:
{
user(name: "Vova Unicorn") {
friends {
name
friends {
name
friends {
name
friends {
name
...
}
}
}
}
}
}
На 5–6 уровне вложенности полноценное выполнение такого запроса приведет к выборке всех в мире пользователей. Сервер уж точно не справится с такой задачей за один присест и скорее всего просто напросто «упадет».
Есть ряд мер, которые следует обязательно предпринять для того, чтобы обезопаситься от подобных ситуаций:
- Ограничить глубину запроса. Иными словами, нельзя позволять клиентам просить данные произвольной вложенности.
- Ограничить сложность запроса. Назначив вес на каждое поле и подсчитав сумму весов всех полей в запросе, можно принимать или отклонять такие запросы на сервере.
Для примера рассмотрим следующий запрос:
{
cart(id: 1) {
items {
product {
title
}
quantity
}
subTotal
}
}
Очевидно, что глубина такого запроса — 4, ведь самый длинный путь внутри него cart -> items -> product -> title.
Если принять, что вес каждого поля 1, то с учетом 7 полей в запросе, его сложность составляет также 7.
В GraphQL Java наложение проверок достигается указанием дополнительного инструментирования при создании объекта GraphQL:
GraphQL.newGraphQL(schema)
.instrumentation(new ChainedInstrumentation(Arrays.asList(
new MaxQueryComplexityInstrumentation(20),
new MaxQueryDepthInstrumentation(3)
)))
.build();
Инструментирование MaxQueryDepthInstrumentation проверяет глубину запроса и не позволяет запускаться слишком «глубоким» запросам (в данном случае — с глубиной больше 3).
Инструментирование MaxQueryComplexityInstrumentation перед исполнением запроса подсчитывает и проверяет его сложность. Если это число превышает указанное значение (20), то такой запрос отвергается. Можно переопределить вес для каждого поля, ведь некоторые из них явно достаются «тяжелее», чем другие. Например, полю продукта можем быть назначена сложность 10 через аннотацию @GraphQLComplexity, поддерживаемую в GraphQL SPQR:
@GraphQLQuery(name = "product")
@GraphQLComplexity("10")
public List products(...)
Вот пример проверки на глубину, когда она явно превышает указанное значение:

Между прочим, механизм инструментирования не ограничивается наложением ограничений. Его можно использовать и для других целей, таких как логирование или трейсинг.
Мы рассмотрели меры «защиты», специфические для GraphQL. Однако существует еще ряд приемов, на которые стоит обратить внимание независимо от типа API:
- throttling / rate-limiting — ограничение количества запросов за единицу времени
- timeouts — ограничение времени на операции с другими сервисами, БД и т.д.;
- pagination — поддержка постраничного просмотра.
Изменение данных через мутации
До сих пор мы рассматривали сугубо выборку данных. Но GraphQL позволяет органично организовать не только получение данных, но и их изменение. Для этого существует механизм мутаций.
