[Из песочницы] A Practical Implementation of the Switching Generator Using Verilog HDL
Abstract
Linear feedback shift registers are an excellent tool for implementing a pseudo random bit generator in hardware; they inhibit a simple and efficient electronic structure. Further, they are capable of producing output sequences with large periods and good statistical properties. However, standard LFSRs are not cryptographically secure, since the output sequence can be uniquely predicted given a small number of key stream bits using Berlekamp-Massey algorithm. Several methods have been proposed to destroy the linearity inherent in LFSR design. These methods include nonlinear combination generators, nonlinear filter generators, and clock controlled generators. Nevertheless, they remain vulnerable to many attacks such as side channel attacks and algebraic attacks. In 2015, a new clocked controlled generator, called the switching generator, was proposed. This new generator has been proven to be resistant to algebraic attacks and side channel attacks, while preserving efficiency and security requirements. In this project, we present a design of the switching generator using Verilog HDL.
Introduction and Historical Background
The history of pseudo random number generation in hardware is heavily linked to the development of stream ciphers. Stream ciphers are ciphers that encrypt plain text characters individually (usually bit by bit), in contrast to block ciphers, which encrypt plain text in large block (64 bits or more). Many stream cipher architectures require a key stream generator, which is a pseudo random bit generator whose seed is the encryption key. For each plain text bit, the corresponding cipher text bit is calculated as some revertible function (usually xor gate) of the plain text bit and the corresponding key stream bit. Therefore, designing safe and efficient key stream generators is essential for stream cipher operation.
One useful tool for building key stream generators is linear feedback shift registers. They can be contsructed easily using elementary electronic components, and can be programmed simply on programmable logic devices. Also, due to their simple structure, LFSRs can be modeled and analyzed mathematically, which has lead to a vast body of knowledge and results regarding them. The output sequence of a correctly constructed LFSR has exponential length and good statisitical properties such as large linear complexity.
Despite the good statistical properties of the LFSR, it cannot be used as a key stream generator in its strandard form due to its linear nature. If an attacker managed to know $inline$2L$inline$ consecutive key stream bits, then the output sequence can be uniquely and efficiently predicted using Berlekamp-Massey algorithm, where $inline$L$inline$ is the number of registers. Many different ways to destroy the linearity inherent in LFSR output sequence have been proposed:
- Using multiple LFSRs and a non-linear combining function of their outputs (non-linear combination generators).
- Generating the output sequence as some non-linear function of the LFSR state (non-linear filter generators).
- Irregular clocking of LFSRs (clock-controlled generators).
Still, all of these designs remained vulnerable to attacks such as algebraic and side channel attacks. After the year 2000, this was no longer a critical issue, as block cipher Rijndael was proposed and elected as the Advanced Encryption Standard (AES). AES was capable of operating in stream cipher mode and meet all industrial standards for a stream cipher. Further, with the rise of computational powers, AES could be deployed on various platforms. This has lead to a considerable decrease in stream cipher applications.
Adi Shamir presented an invited lecture in State of the Art in Stream Ciphers 2004 and Asiacrypt 2004 titled «Stream Ciphers: Dead or Alive?». In his presentation, he suggested that stream ciphers can survive in the following applications:
- Software-oriented applications with exceptionally high speeds (e.g. routers).
- Hardware-oriented applications with exceptionally small footprint (e.g. smart cards).
One of the latest proposals for key stream generators is the switching generator. It is claimed to be resistant to algebraic and side channel attacks, all while preserving efficiency and operating speeds.
In this project, we shall present a design of the switching generator in hardware, using Verilog HDL. First, we present the two common forms of LFSRs, Fibonacci LFSRs and Galois LFSRs. Next, we present a mathematical presentation of LFSRs. We will then present the switching generator as introduced by. Finally, we present our Verilog design of the switching generator.
Linear Feedback Shift Registers
Linear feedback shift registers are circuits consisting of a linear list of registers (also called delay elements) and a predefined set of connection among them. A global (single) clock signal controls the data flow inside the LFSR. The two most commonly used types of LFSRs are Fibonacci LFSRs and Galois LFSRs; deferring only in the form of connections. As we shall see later in the mathematical model section, there are many similarities between Fibonacci and Galois architectures, preferring one over the other is application specific.
Through out this article, we assume a hypothetical global time counter starting at $inline$0$inline$ and increasing by $inline$1$inline$ after each positive edge of the global clock cycle.
Registers
A register is a logic element capable of storing one bit of data, called the state. It has two input lines: a one bit data line and a clock signal line. It has a one-bit output that is always equal to the internal state. On every positive edge of the clock input, the data input is assigned to the state, otherwise the state remains unchanged. Let us denote the state of a register $inline$S$inline$ at time $inline$t$inline$ as $inline$\mathop S\nolimits^t$inline$.
Fibonacci LFSRs
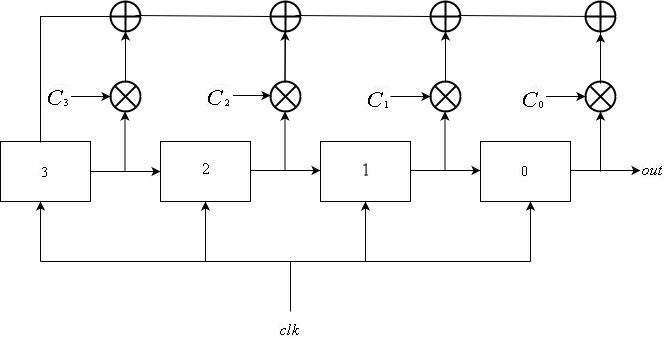
A Fibonacci LFSR consists of $inline$L$inline$ registers enumerated from $inline$0$inline$ to $inline$L-1$inline$, all connected to the same clock signal. The input of register $inline$i$inline$ is the output of register $inline$i+1$inline$ for $inline$0\le i \le L-2$inline$. The feedback input for register $inline$L-1$inline$ is the xor sum of outputs of some subset of registers. The register update can be described mathematically as follows:
$$display$$\mathop S\nolimits_i^t = \left\{ \begin{array}{l} \mathop S\nolimits_{i + 1}^{t-1} {\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \rm{if} \ \ }0 \le i \le L-2\\ \mathop \bigoplus \limits_{j = 1}^k \mathop S\nolimits_j^{t-1} \otimes \mathop C\nolimits_j {\ \ \ \ \rm{if} \ \ }i = L-1 \end{array} \right.$$display$$
where $inline$C_j = 1$inline$ if register $inline$j$inline$ is included in the feedback and $inline$0$inline$ otherwise.
The output sequence is obtained from register $inline$0$inline$. That is, the output sequence is $inline$\mathop {\left\{ {\mathop S\nolimits_0^i } \right\}}\nolimits_{i \ge 0} $inline$.
Galois LFSRs
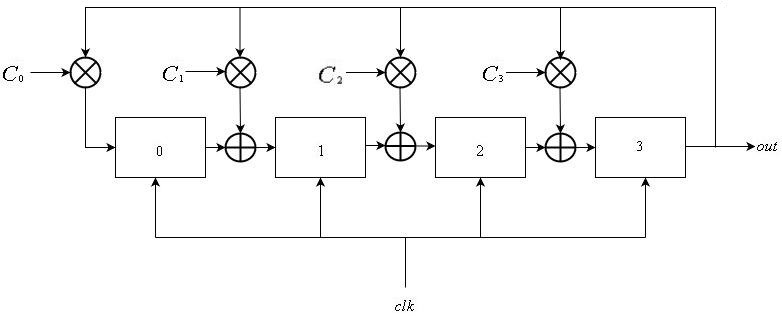
Galois LFSRs also consist of a linear list of $inline$L$inline$ registers enumerated from $inline$0$inline$ to $inline$L-1$inline$, all sharing the global clock signal. The input of register $inline$i$inline$ is the output of register $inline$i-1$inline$ for $inline$1 \le i \le L-1$inline$. For some subset of registers, their input is xored with the output of register $inline$L-1$inline$. This can be expressed as:
$$display$$\mathop S\nolimits_i^t = \left\{ \begin{array}{l} \mathop S\nolimits_{i-1}^{t-1} \oplus \mathop S\nolimits_{L-1}^{t-1} \otimes \mathop C\nolimits_i {\rm{\ \ \ \ if \ \ }} 1 \le i \le L-1\\ \mathop S\nolimits_{L-1}^{t-1} \otimes \mathop C\nolimits_0 {\rm{\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if \ \ }} i = 0 \end{array} \right.$$display$$
where $inline$C_i = 1$inline$ if the input of register $inline$i$inline$ is xored with output of register $inline$L-1$inline$.
In a manner similar to that of Fibonacci LFSRs, the output sequence is defined as $inline$\mathop {\left\{ {\mathop S\nolimits_{L-1}^i } \right\}}\nolimits_{i \ge 0} $inline$.
Comparison Between Fibonacci and Galois Designs
There is a direct correspondence between Fibonacci and Galois LFSRs in the mathematical sense, as we shall see in the next section. However, there are two notable advantages of using Galois' design:
- In software implementation, it does not require an $inline$L$inline$ bit parity check, which adds a logarithmic factor of complexity.
- In hardware implementation, it only requires two-input xor gates, whose propagation delay is considerable less than that of the multi-input xor gates used in Fibonacci’s design.
In our project, we consider the matrix formulation of the LFSR, so both architectures are interchangeable.
Mathematical Model of LFSRs
In the following sections, unless stated otherwise, we assume that all computation in done under Galois field $inline$GF\left (2 \right)$inline$. That is, all operations are computed modulo $inline$2$inline$. Another realization of this convention is that all multiplication is a logical and gate, and all summation is an xor gate.
Consider the states of all $inline$L$inline$ registers of an LFSR at some time $inline$t$inline$; this can represented as a vector from $inline${\left\{ {0,1} \right\}^L}$inline$:
$$display$${S^t} = \left ({\mathop S\nolimits_0^t;\mathop S\nolimits_1^t; \ldots;\mathop S\nolimits_{L-1}^t } \right)$$display$$
We denote this vector as the state of the LFSR. Note that there are at most $inline${2^L}$inline$ possible states for an $inline$L$inline$ register LFSR. Also note that if an LFSR were to reach the all-zero state, it cannot reach any other state. Therefore we say that there are $inline$2^L-1$inline$ non-trivial of an LFSR.
Consider the following linear transformation:
$$display$$F=\left ({\begin{array}{*{20}{c}} 0&1& \cdots &0\\ \vdots & \vdots & \ddots & \vdots \\ 0&0& \cdots &1\\ {\mathop C\nolimits_0 }&{\mathop C\nolimits_1 }& \cdots &{\mathop C\nolimits_{L-1} } \end{array}} \right)$$display$$
Given that $inline$\mathop S\nolimits^t $inline$ is the state of a Fibonacci LFSR, it can be observed that
$$display$$F \cdot \mathop S\nolimits^t = \mathop S\nolimits^{t + 1} $$display$$
If $inline$\mathop S\nolimits^t $inline$ was a state of a Galois LFSR, then consider tranformation $inline$G$inline$:
$$display$$G=\left ({\begin{array}{*{20}{c}} 0& \cdots &0&{\mathop C\nolimits_0 }\\ 1& \cdots &0&{\mathop C\nolimits_1 }\\ \vdots & \ddots & \vdots & \vdots \\ 0& \cdots &1&{\mathop C\nolimits_{L-1} } \end{array}} \right)$$display$$
In this case, we have
$$display$$G \cdot \mathop S\nolimits^t = \mathop S\nolimits^{t + 1} $$display$$
Matrix representations of LFSRs can be flexible when dealing with repeated updates, as they can be interpreted as a simple matrix product. It can be observed that $inline$F = {G^T}$inline$. This fact indicates the many similarities between Fibonacci and Galois designs if they were viewed as linear transformations from $inline${\left\{ {0,1} \right\}^N}$inline$ to $inline${\left\{ {0,1} \right\}^N}$inline$.
Multiplying the state vector of some LFSR by a matrix (of Fiboancci or Galois types) is known as clocking or updating the LFSR.
The Switching Generator
The Switching Generator is a clock-controlled generator proposed in 2015. It is proven to have resistance to algebraic and side channel attacks. In this section, we shall present the design of the switching generator, as specified by the its inventors.
Basic Structure
The switching generator consists of two LFSRs: a control LFSR $inline$A$inline$ of length $inline$N$inline$ and a data LFSR $inline$B$inline$ of length $inline$M$inline$. Control LFSR is updated as described previously. However, data LFSR is updated using one of two possible matrices, $inline$\mathop M\nolimits_1^i $inline$ or $inline$\mathop M\nolimits_2^j $inline$, where $inline${M_1},{M_2}$inline$ are companion matrices of some primitive polynomials. Choosing one matrix over the other is determined by the signal output from the control LFSR. This process can be described as follows:
$$display$$\mathop B\nolimits^t = \left\{ \begin{array}{l} \mathop M\nolimits_1^i \cdot \mathop B\nolimits^{t-1} {\rm{\ \ \ \ if \ \ }}\mathop A\nolimits_{M-1}^t = 0\\ \mathop M\nolimits_2^j \cdot \mathop B\nolimits^{t-1} {\rm{\ \ \ \ if \ \ }}\mathop A\nolimits_{M-1}^t = 1 \end{array} \right.$$display$$
The output of the switching generator is the output of LFSR $inline$B$inline$. Note that we assumed that $inline$A$inline$ is a Galois LFSR. It can just as well be a Fibonacci LFSR.
Integers $inline$i, j$inline$ Are called the switching indices.
The Seed
Recall that an LFSR can iterate through at most $inline${2^L}-1$inline$ non-trivial states before revisiting previous states. Since matrices $inline${M_1},{M_2}$inline$ are transformation matrices of LFSRs, we can deduce that integers $inline$i, j$inline$ can be at most $inline$2^M-1$inline$ before matrices start to repeat.
The seed for the switching generator is $inline$N + 3M$inline$ bits, representing the initial states of the LFSRs $inline$A$inline$ and $inline$B$inline$ and the integer powers $inline$i, j$inline$. Note that matrices $inline${M_1},{M_2}$inline$ are fixed throughout the implementation and are not included in the seed.
Verilog Design
In this section, we shall introduce our design of the switching generator using Verilog HDL. We will present every module design in a bottom up fashion. At the very end, we introduce the switching generator module.
In our design, we tried to keep synchronous components to a minimum. The only clock controlled components are the LFSRs $inline$A, B$inline$.
Matrix and vector operations can be implemented in a number of different methods, varying in consumption of logic units, memory units and procedural complexity. In our design, we eliminate the need for procedural blocks, and use logic elements to a maximum.
All matrices in the following modules are indexed starting at $inline$0$inline$ left to right, and then top to bottom.
Also note that all modules have parameterized sizes; this is for debugging purposes. In an actual implementation, all sizes are fixed.
Multiplexer
This is a module implementing a 2 to 1 $inline$N$inline$-bit multiplexer. The module has two $inline$N$inline$-bit input lines, one 1-bit selector line, and $inline$N$inline$-bit output line. If the selector input is $inline$0$inline$ then the output is set to the first input line, otherwise it is set to the second.
Multiplexer Module
Vector Transformation
This module implements a linear transformation on a vector. It accepts as input an $inline$N \times N$inline$ transformation matrix and an $inline$N$inline$-bit vector. It outputs the matrix-vector product of its input.
Each bit in the output vector is the result of an $inline$N$inline$-bit xor gate, taking as input the result of the $inline$N$inline$-bit bitwise and of the input vector and the corresponding matrix row. That is, each output bit is hardwired to the input, and no procedural blocks are needed.
Exactly $inline$N^2$inline$ two-input and gates are used, along with $inline$N$inline$ $inline$N$inline$-input xor gates.
Vector Transformation Module
Identity
This module accepts no input. Its $inline$N \times N$inline$-bit output is initialized to the $inline$N $inline$ identity matrix. Such a module is declared for the sake of convenience, so that we do not have to initialize a global register vector for each different size.
Identity Matrix Module
Transpose
This module accepts an $inline$N \times N$inline$ matrix and output its transpose. Neither logical nor memory elements are used in this module, its output is merely a permutation of its input
.
Matrix Transpose Module
Matrix Multiplication
This is a module implementing matrix-matrix multiplication. It accepts two $inline$N \times N$inline$ matrices as input, and outputs their matrix-matrix product.
This module contains an instance of the matrix transpose module. This makes it possible to assign consecutive indices to columns in the second input matrix. Each entry in the output matrix is then assigned to the output of an $inline$N$inline$-input xor gate, whose input is the bitwise and of the corresponding row from the first matrix and column from the second.
Exactly $inline$N^3$inline$ two-input and gates and $inline$N^2$inline$ $inline$N$inline$-input xor are used in this implementation.
Matrix Multiplication Module
Matrix Exponentiation
This module raises a matrix to an integer power. It accepts as input an $inline$N \times N$inline$ matrix and a $inline$K$inline$-bit integer. Its output is the matrix raised to the specified integer power.
Matrix Exponentiation Module
Control Unit
This module implements the $inline$N$inline$-bit control LFSR. It is one of the two clock controlled modules in our design.
It includes a static $inline$N \times N$inline$ LFSR transformation matrix and a variable $inline$N$inline$-bit state. Its input includes a clock, an $inline$N$inline$-bit state reset, and a reset signal. Its output is a single bit, which is the last bit of the LFSR.
After each positive edge of the clock signal, the state is updated according to the transformation matrix using a matrix-vector multiplication module. The state reset is assigned to the internal state after each positive edge of the reset signal.
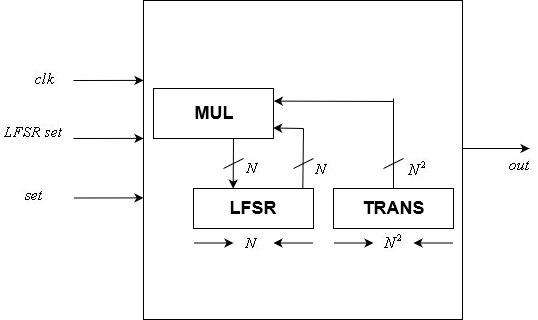
Control Unit Module
Data Unit
The $inline$N$inline$ data LFSR is implemented using this module. Like the control unit module, it is clock controlled
The module includes two $inline$N \times N$inline$ transformation matrices and an $inline$N$inline$-bit LFSR state. It accepts as input a clock signal, a control signal, an $inline$N$inline$-bit LFSR state reset, two $inline$N \times N$inline$ matrix transformation resets, and a reset signal. It has a one bit output, the last bit of the internal LFSR.
Note that since the seed can be changed, then the transformation matrices can also be changed, unlike the control unit whose transformation matrix if fixed.
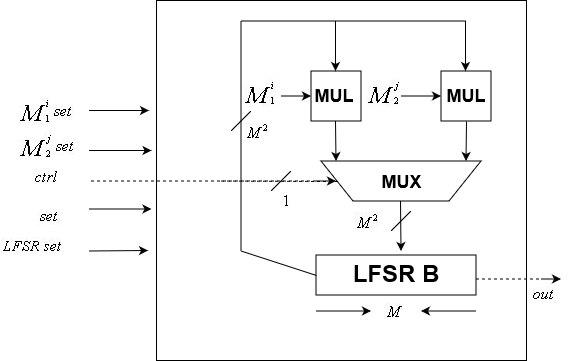
\Data Unit
The Switching Generator
This is the main module of our design. It is parameterized by integers $inline$N, M$inline$, which are the sizes of the control and data units, respectively.
The input to this module is a clock signal, a $inline$N+3M$inline$-bit seed, and a set signal. The seed is simply a concatenation of the control LFSR reset, the data LFSR reset, and integers $inline$i, j$inline$ Its output is one bits, the pseudo random bit generated by the switching generator.
This module includes two $inline$M \times M$inline$ matrices $inline$\mathop M\nolimits_1,\mathop M\nolimits_2 $inline$. These matrices are fixed throughout the implementation.
Two matrix exponentiation modules instances are used to calculate the input matrices for the data unit, where their input are the fixed transformation matrices and integers $inline$i, j$inline$, extracted from the seed.
The Switching Generator Module
Conclusions and Recommendations
In this project, we have presented a design of the switching generator using Verilog HDL. This design is focused entirely on hardware, and eliminates the use of procedural blocks. Such an approach allows for maximum performance at the cost of logic and memory elements. For some applications with logic and memory elements constraints, it might be beneficial to sacrifice performance and increase the use of procedural blocks to reduce electronic elements usage.
One drawback of the project it that it lays the responsibility of choosing good switching indices on the user. One possible advancement is adding a hardware component to check the validity of the used switching index. This requires a hardware implementation of complex algorithms such as finding the characteristics polynomial of a given matrix and checking it for primitivity.
A possible advancement is adding a true random number generator to check random switching indices, and outputting a valid pair once it is found. It can be proven that this process halts after a short time with high probability.
References
- Katz, Jonathan, et al. Handbook of applied cryptography. CRC press, 1996.
- Choi, Jun, et al. «The switching generator: New clock-controlled generator with resistance against the algebraic and side channel attacks.» Entropy 17.6 (2015): 3692–3709.
- Shamir, Adi. «Stream ciphers: dead or alive?.» ASIACRYPT. 2004.
- LFSRs for the Uninitiated
