GPT для чайников: от токенизации до файнтюнинга
К моему удивлению, в открытом доступе оказалось не так уж много подробных и понятных объяснений того как работает модель GPT от OpenAI. Поэтому я решил всё взять в свои руки и написать этот туториал, в котором разобраны следующие темы:
Откуда взялась GPT и какую задачу она решает
Токенизация текста
Внутреннее устройство GPT
Методы генерации текста
Файнтюнинг GPT
У этой статьи есть google colab версия, где можно сразу в интерактивном режиме запустить все примеры.
 Картинка с сайта OpenAI.
Картинка с сайта OpenAI.
Небольшая историческая справка
Сначала миром NLP правили рекуррентные сети (RNN, LSTM), потом появился механизм внимания — attention, который, применительно к рекуррентным сетям, давал огромный буст на всех тестах. Далее ребята из гугла предположили, что attention настолько крутой, что справится и без RNN — так появился первый трансформер в статье Attention Is All You Need. Тот трансформер состоял из энкодера и декодера и умел только переводить текст, но делал это очень круто.
Потом произошёл великий раскол: в OpenAI решили, что от трансформера надо оставить только декодер, а Google решил сконцентрироваться на энкодере. Так появились первые GPT и BERT, породив целый зоопарк себе подобных моделей.
Так что же такое GPT?
Короткий ответ — это нейронная сеть для генерации (продолжения) текста. Если чуть подробнее и сложнее, то это — языковая модель, основанная на архитектуре трансформер и обученная в self-supervised режиме на куче текстовых данных.
Оригинальные статьи про три поколения GPT:
Архитектура оригинального трансформера
Hugging Face — лучшая библиотека для работы с трансформерами
Для работы с GPT нам нужно будет скачать предобученную модель. Лучший выбор для работы с трансформерами — это библиотеки от Hugging Face: transformers, tokenizers, datasets — самые любимые библиотеки любого нлпшника. Все они разработаны стартапом Hugging Face, который стремится стандартизировать архитектурные решения для работы с transformer-based моделями. Также они выполняют функцию своеобразного хаба предобученных весов огромного количества трансформеров.
В данном туториале мы будем работать только с библиотекой transformers и, для наглядности, с русскоязычной моделью ruGPT3 от Сбера.
# Сначала установим библиотеку transformers
!pip install transformers
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Для наглядности будем работать с русскоязычной GPT от Сбера.
# Ниже команды для загрузки и инициализации модели и токенизатора.
model_name_or_path = "sberbank-ai/rugpt3large_based_on_gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name_or_path)
model = GPT2LMHeadModel.from_pretrained(model_name_or_path).to(DEVICE)Языковое моделирование
Чтобы разобраться, как работает GPT, нужно понять, какую задачу пытается решать эта модель. Языковое моделирование — это предсказание следующего слова (или куска слова) с учётом предыдущего контекста. На картинке пример того, как с задачей языкового моделирования справляется поиск Яндекса.
 Языковое моделирование в поисковой строке
Языковое моделирование в поисковой строке
Для того чтобы «всего лишь» дописывать текст, модель должна очень хорошо понимать его смысл и даже иметь какие-то свои знания о реальном мире. Внутренние знания модели можно попытаться вытащить наружу, модифицируя «левый контекст» текста. Это позволяет решать множество задач: отвечать на вопросы, суммаризировать текст и даже создавать диалоговые системы!
Например, если мы хотим при помощи языковой модели ответить на вопрос «Сколько будет 2+2?», то можно подать на вход модели следующий текст «Вопрос: Сколько будет 2+2? Ответ: … » и самым естественным продолжением такого текста будет именно ответ на вопрос, поэтому хорошая языковая модель допишет «4».
Подбор модификаций текста называется «Prompt Engineering». Такая простая идея позволяет решать практически неограниченное количество задач. Именно поэтому многие считают GPT-3 подобием сильного искусственного интеллекта.
# prompt engineering for QA
text = "Вопрос: 'Сколько будет 2+2?'\nОтвет:"
input_ids = tokenizer.encode(text, return_tensors="pt").to(DEVICE)
out = model.generate(input_ids, do_sample=False)
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> Вопрос: 'Сколько будет 2+2?'
#>>> Ответ: '2+2=4'Похожим способом можно кратко пересказывать тексты, если в конце дописывать «TL;DR», потому что модель во время обучения запомнила, что после этих символов идёт краткое содержание. А ещё можно сделать переводчик с русского на английский:
# prompt engineering for Translation
text = "По-русски: 'кот', по-английски:"
input_ids = tokenizer.encode(text, return_tensors="pt").to(DEVICE)
out = model.generate(input_ids, do_sample=False)
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> По-русски: 'кот', по-английски: 'cat'Токенизация
Машинное обучение лучше справляется с числами, чем с текстом, поэтому нам необходима процедура токенизации — преобразование текста в последовательность чисел.
Самый простой способ сделать это — назначить каждому уникальному слову своё число — токен, а затем заменить все слова в тексте на эти числа. Но есть проблема: слов и их форм очень много (миллионы) и поэтому словарь таких слов — чисел получится чересчур большим, а это будет затруднять обучение модели. Можно разбивать текст не на слова, а на отдельные буквы (char-level tokenization), тогда в словаре будет всего несколько десятков токенов, НО в таком случае уже сам текст после токенизации будет слишком длинным, а это тоже затрудняет обучение.
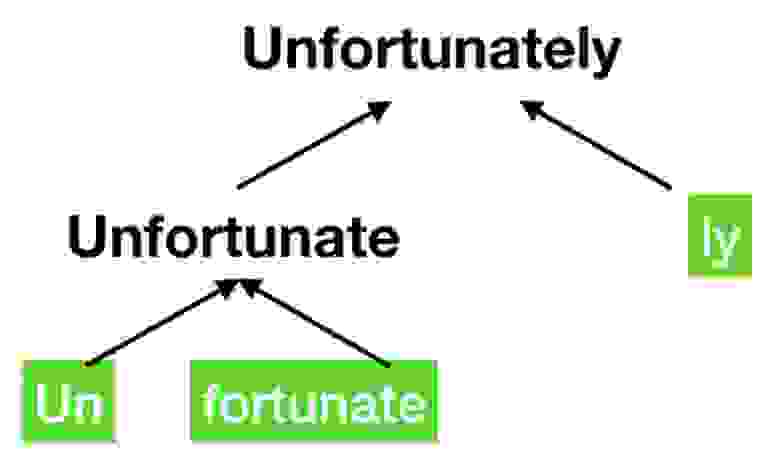 Пример BPE токенизации
Пример BPE токенизации
Обычно предпочтительнее выбрать что-то среднее, например, можно разбивать слова на наиболее общие части и представлять их полные версии как комбинации этих кусков (см. картинку). Такой способ токенизации называется BPE (Byte Pair Encoding). Но даже это иногда не самый оптимальный выбор. Чтобы сжать словарь ещё сильнее для обучения GPT OpenAI использовали byte-level BPE токенизацию. Эта модификация BPE работает не с текстом, а напрямую с его байтовым представлением. Использование такого трюка позволило сжать словарь до всего-лишь ~50k токенов при том, что с его помощью всё ещё можно выразить любое слово на любом языке мира (и даже эмодзи).
# Изначальные текст
text = "Токенизируй меня"
# Процесс токенизации с помощьюю токенайзера ruGPT-3
tokens = tokenizer.encode(text, add_special_tokens=False)
# Обратная поэлементая токенизация
decoded_tokens = [tokenizer.decode([token]) for token in tokens]
print("text:", text)
print("tokens: ", tokens)
print("decoded tokens: ", decoded_tokens)
#>>> text: Токенизируй меня
#>>> tokens: [789, 368, 337, 848, 28306, 703]
#>>> decoded tokens: ['Т', 'ок', 'ени', 'зи', 'руй', ' меня']Так как GPT использует byte-level токенизатор, то не для любого токена найдется существующий символ или слово. Некоторые токены существуют только в комбинациях. Такое случается редко, но я нашёл для вас пример таких токенов:
# Эти три токена по отдельности не декодируются
print(tokenizer.decode([167]))
#>>> �
print(tokenizer.decode([245]))
#>>> �
print(tokenizer.decode([256]))
#>>> �
# Но вместе они образуют иероглиф
print(tokenizer.decode([167, 245, 256]))
#>>> 撝Архитектура GPT
Если коротко, то при генерации продолжения текста с помощью GPT происходит следующее:
Входной текст токенизируется в последовательность чисел (токенов).
Список токенов проходит через Embedding Layer (линейный слой) и превращается в список эмбеддингов (очень похоже на word2vec).
К каждому эмбеддингу прибавляется positional embedding, о котором я расскажу в сл. секции.
Далее список эмбеддингов начинает своё путешествие через несколько одинаковых блоков (Transformer Decoder Block), о которых я тоже расскажу потом.
После того как список эмбеддингов пройдёт через последний блок, эмбеддинг, соответствующий последнему токену матрично умножается на всё тот же входной, но уже транспонированный Embedding Layer и после применения SoftMax получается распределение вероятностей следующего токена.
Из этого распределения выбираем следующий токен (например с помощью функции argmax).
Добавляем этот токен к входному тексту и повторяем шаги 1–6.
Схема работы GPT (продолжение текста)
Positional encoding
Так уж получилось, что в отличие от рекурентных сетей архитектура трансформера не чувствительна к порядку входных токенов, то есть даже если перемешать слова местами, то аутпут будет получаться всё равно одинаковым (permutation invarience).
Но ведь в языке порядок слов критически важен! Чтобы его учитывать пришлось придумать костыль — positional encoding. Этот механизм позволяет трансформерам «видеть» порядок входных токенов. Грубо говоря, positional encoding — это любой способ кодирования позиции слова внутри эмбеддинга. Самый простой способ это сделать — просто конкатенировать к эмбеддингу номер позиции слова, но это работает очень плохо. Поэтому в GPT используется кодирование позиции в виде вектора, который прибавляется к эмбеддингу токена. Эти позиционные эмбеддинги можно зафиксировать заранее как в оригинальном трансформере (они на картинке), либо обучать, как в случае GPT.
Позиционные эмбеддинги оригинального трансформера.
Transformer Decoder Block
Вот так выглядит главная структурная часть GPT: self-attention, нормализация, feed-forward и residual connections. Не будем останавливаться подробно, но если вам очень интересны технические детали, то рекомендую посмотреть эту статью на хабре (тык).
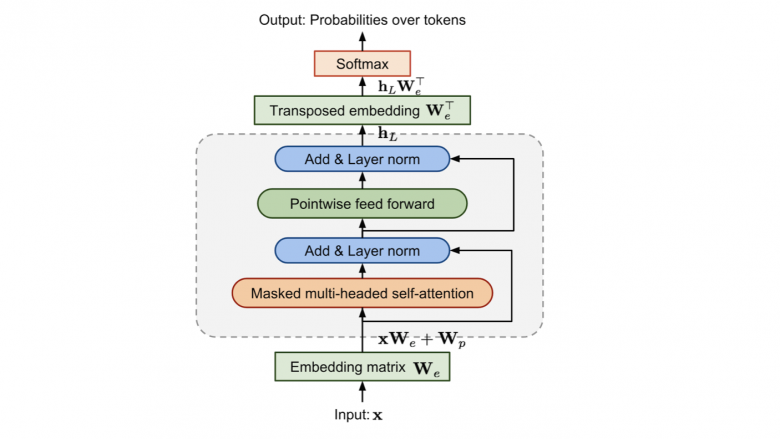 Схема Decoder блока трансформера.
Схема Decoder блока трансформера.
Методы генерации текста
Как я говорил выше, языковая модель выдаёт распределение вероятностей следующего токена, а эту информацию можно по-разному использовать для генерации текста.
Для наглядности применим все основные методы для продолжения следующего текста: 'Определение: "Нейронная сеть" - это'
# Заранее токенизируем текст
text = 'Определение: "Нейронная сеть" - это'
input_ids = tokenizer.encode(text, return_tensors="pt").to(DEVICE)Greedy Search
Самый простой способ — это аргмаксная генерация (greedy search), когда мы каждый раз выбираем токен, у которого максимальная вероятность. Это не самый лучший метод, так как в таком случае генерация застревает в локальных минимумах и часто выдаёт повторяющиеся фрагменты, например the the the the ...
# Пример аргмаксного сэмплирования
out = model.generate(input_ids,
do_sample=False,
max_length=30)
# Декодирование токенов
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> Определение: "Нейронная сеть" - это компьютерная программа, которая
#>>> позволяет создавать и анализировать нейронные сети.Beam search
Чуть более сложный и качественный способ сэмплирования — это beam search. В этом случае на каждом шаге мы выбираем не только один самый вероятный токен, а сразу несколько (beam-size), и дальше продолжаем поиск для каждого из выбранных токенов. Таким образом мы разветвляем пути генерации, получая несколько вариантов сгенерированного текста. В итоге можно выбрать тот вариант, у которого лучшая перплексити (уверенность модели в реалистичности текста). Такая генерация обладает хорошей когерентностью (связностью), но обычно у них не хватает «человечности», они кажутся сухими и скучными. Также это не полностью решает проблему повторяющихся фрагментов генерации.
Пример дерева beam-search. Числа — это вероятности токенов.
# Пример генерации с помощью beam-search
out = model.generate(input_ids,
do_sample=False,
num_beams=5,
max_length=30)
# Декодирование токенов
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> Определение: "Нейронная сеть" - это сеть, состоящая из множества
#>>> нейронов, соединенных друг с другом.Сэмплирование с температурой
Чтобы добавить тексту непредсказуемости и человечности можно использовать вероятностное сэмплирование с температурой. При такой генерации мы берём не самый вероятный токен, а выбираем его «случайно» с учётом распределения вероятностей. Параметр температуры позволяет контролировать степень рандомности. При нулевой температуре этот метод совпадает с аргмаксным сэмплированием, а при очень большой температуре токены будут выбираться совсем наугад. Обычно хорошо работает температура в диапазоне 0.8 - 2.0. Формула модификации распределения вероятностей очень похожа на формулу распределения Больцмана. Чем выше температура системы тем больше «размазывается» распределение вероятностей её возможных состояний, отсюда слово «температура».
p'=softmax(log(p)/t)
Но у этого метода есть и минусы, ведь случайная природа генерации будет иногда приводить к совсем уж некорректным результатам, хоть и редко.
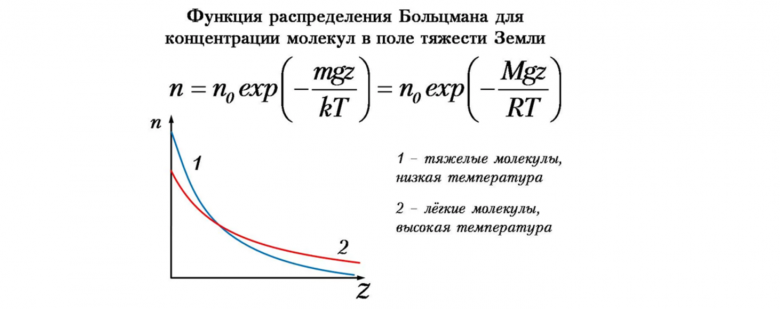 Распределение Больцмана позволяет контролировать «рандомность» сэмплирования.
Распределение Больцмана позволяет контролировать «рандомность» сэмплирования.
# Пример вероятностного сэмплирования
out = model.generate(input_ids,
do_sample=True,
temperature=1.3,
max_length=30)
# Декодирование токенов
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> Определение: "Нейронная сеть" - это модель, при которой каждый
#>>> элемент сети имеет "исполнительный элемент" - "всплеск.Сэмплирование с ограничением маловероятных токенов (Nucleus Sampling)
Для запрета сэмплирования совсем уж некорректных токенов вводят top-k или top-p ограничения. В этом случае генерация тоже происходит случайным образом, но мы заранее отсекаем все маловероятные токены. В случае top-k мы просто зануляем все вероятности кроме k самых больших. А в случае top-p мы оставляем такой минимальный сет токенов, чтобы сумма их вероятностей была не больше p. Ограничение top-p иногда называют nucleus sampling.
# Пример вероятностного сэмплирвоания с ограничением
out = model.generate(input_ids,
do_sample=True,
temperature=1.3,
top_k=20,
top_p=0.8,
max_length=30,
)
# Декодирование токенов
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> Определение: "Нейронная сеть" - это совокупность объектов и программ,
#>>> объединенных единой целью и имеющих функциональный характер.Сравнение поколений GPT
GPT-1
GPT — Generative Pretraining of Transformers. Первая версия этой модели состояла из 12 слоёв и была обучена на 7000 книг. Как языковая модель она работала не очень хорошо (длинные тексты генерировались плохо), но при файнтюнинге на отдельных задачах эта модель выбила несколько SOTA результатов. Собственно, статья была про то, что usupervised language modeling pretraining улучшает качество дальнейшего файнтюнинга. Максимальный размер контекста у GPT-1 — 512 токенов.
GPT-2
SOTA результаты первой GPT держались недолго, так как появился BERT. В OpenAI психанули и решили значительно прокачать свою модель. Во-первых, они её сделали в 10 раз больше: 48 слоёв ~ 1.5B параметров. А во вторых, обучили на невероятно большом объёме данных — к книгам добавили 8 миллионов сайтов (с хорошим рейтингом на реддите). Суммарно получилось 40 гб текста. Архитектурно модель изменилась не сильно — только немного переместили слои нормализации. В итоге оказалось, что GPT-2 настолько стала лучше, что научилась писать длинные связные тексты и даже решать при помощи prompt engineering множество новых задач! Максимальный размер контекста у GPT-2 — 1024 токенов.
GPT-3
Опять же модель сделали в 10 раз больше (175B параметров) и обучили на ещё большем количестве данных (570GB текста). Из архитектурных изменений — только немного оптимизировали attention. После такого апгрейда модель стала настолько крутой, что научилась писать рабочий программный код (так появился CODEX) и решать ещё больше почти сверхъестественных задач (воскрешать мёртвых). Максимальный размер контекста у GPT-3 — 2048 токенов.
Файнтюнинг
Процесс бучения GPT
Обучающий текст нарезается на случайные куски, которые составляются в последовательности из 1024 (2048 у GPT-3) токенов, разделяясь специальным <|endoftext|> символом. Во время обучения, модель учится предсказывать (классифицировать) каждый токен в последовательности один за другим при помощи CrossEntropy Loss.
Так как входная последовательность всегда заполнена до конца, padding не используется. Но во время инференса, длина входного текста может быть произвольной, поэтому надо явно указывать чем паддить оставшиеся позиции. По дефолту используется тот же <|endoftext|>.
В кастомных версиях GPT вышесказанное может модифицироваться. Например, в ruGPT3 гораздо больше специальных токенов: <\s>,
Обучающие данные
Будем учить GPT генерировать стихи Пушкина. В качестве обучающих данных возьмём всего лишь один всем известный стих.
# Для краткости приведу здесь только первую строчку
text = "Мороз и солнце; день чудесный... В библиотеке transformers есть готовые инструменты для подготовки датасета и даталодера. На вход нужен всего лишь один .txtфайл с обучающим текстом.
from transformers import TextDataset, DataCollatorForLanguageModeling
# Сохраним обучающие данные в .txt файл
train_path = 'train_dataset.txt'
with open(train_path, "w") as f:
f.write(text)
# Создание датасета
train_dataset = TextDataset(tokenizer=tokenizer,file_path=train_path,block_size=64)
# Создание даталодера (нарезает текст на оптимальные по длине куски)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,
mlm=False)Training
Для файнтюнинга нам понадобится объект класса Trainer, который сделает всё грязную работу за нас (посылаем лучи добра Hugging Face). Далее нужно будет всего-навсего запустить trainer.train()
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./finetuned", # The output directory
overwrite_output_dir=True, # Overwrite the content of the output dir
num_train_epochs=200, # number of training epochs
per_device_train_batch_size=32, # batch size for training
per_device_eval_batch_size=32, # batch size for evaluation
warmup_steps=10, # number of warmup steps for learning rate scheduler
gradient_accumulation_steps=16, # to make "virtual" batch size larger
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
optimizers = (torch.optim.AdamW(model.parameters(),lr=1e-5), None)
)trainer.train()Результат дообучения
Готово! Теперь давайте посмотрим что же сочинит GPT в стиле Пушкина если на вход подать такую строчку: 'Как же сложно учить матанализ!'
text = "Как же сложно учить матанализ!\n"
input_ids = tokenizer.encode(text, return_tensors="pt").to(DEVICE)
model.eval()
with torch.no_grad():
out = model.generate(input_ids,
do_sample=True,
num_beams=2,
temperature=1.5,
top_p=0.9,
max_length=100,
)
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> Как же сложно учить матанализ!
#>>> Чтобы в математике успеха добиться,
#>>> Попробуйте по буквам составить
#>>> Решение задачи по алгебре.
#>>> Умножь два на два и реши задачу по геометрии.
#>>> Умножь на три и реши задачу по алгебре.Заключение
Несмотря на то, что в обучающей выборке было всего лишь одно стихотворение, модель смогла уловить стиль Пушкина, хотя и остаются небольшие проблемы с рифмой.
Надеюсь, что после прочтения этой статьи вам стало понятнее, как работает знаменитая модель GPT и как с её помощью можно генерировать текст. Если вам понравилось, то загляните в мой телеграм канал, там я стараюсь оперативно разбирать свежие научные публикации по NLP и Computer Vision.
Полезные ссылки
GPT в картинках — очень подробный разбор внутренней архитектуры GPT-2 с акцентом на иллюстрации.
Трансформер в картинках — очень подробный разбор архитектуры Transformer с акцентом на иллюстрации.
Tokenizers tutorial — краткий разбор всех типов токенизаторов от Huggingface с примерами.
Как генерировать текст — обзор способов сэмплирования текста с помощью языковых моделей (бимсёрч и тд).
Attention is All You Need — оригинальная статья про первый трансформер.
GPT-1 — статья в блоге OpenAI про GPT-1.
GPT-2 — статья в блоге OpenAI про GPT-2.
GPT-3 — статья в блоге OpenAI про GPT-3.
WebGPT — статья в блоге OpenAI про GPT-3, обученную гуглить.
Codex — статья в блоге OpenAI про GPT-3, обученную писать код.
