GPT-4: Чему научилась новая нейросеть, и почему это немного жутковато
В этой статье мы разберем новые удивительные способности последней языковой модели из семейства GPT (от понимания мемов до программирования), немного покопаемся у нее под капотом, а также попробуем понять — насколько близко искусственный интеллект подошел к черте его безопасного применения?

Всем привет, это опять статья от двух авторов! Как и в прошлый раз, за умные мысли и экспертизу в искусственном интеллекте отвечал Игорь Котенков (автор канала Сиолошная про машинное обучение, космос и технологии), а за подачу и кринжовые мемы отдувался Павел Комаровский (автор канала RationalAnswer про рациональный подход к жизни и финансам).
Мы предполагаем, что вы уже читали нашу предыдущую большую статью про эволюцию языковых моделей от T9 до ChatGPT с объяснением того, чем вообще являются нейронки, и как они работают — так что мы не будем заново объяснять самые базовые вещи. Вместо этого мы сразу нырнем в детали свежевышедшей модели GPT-4.
Да, это наконец-то свершилось! OpenAI выбрали день числа Пи (14 марта), чтобы поделиться с общественностью информацией о выпуске своего нового продукта. GPT-4 — это новая флагманская большая языковая модель (Large Language Model, или LLM), которая пришла на смену GPT-3, GPT-3.5 и нашумевшей ChatGPT. Ниже мы обсудим ключевые изменения по сравнению с прошлыми поколениями, разберем ряд наиболее интересных примеров использования новой модели, а также поговорим про новую политику OpenAI относительно открытости и безопасности.
План статьи
Смотрим на мир глазами робота
GPT-4 окончательно вкатилась в программирование
Сравниваем робота с человеком
Мультиязычность и перенос знаний
А где всё это использоваться-то будет в итоге?
Заглядываем внутрь GPT-4
Размер кое-чего у GPT-4 всё же вырос!
Как прикрутитли картинки к текстовой модели?
Безопасность искусственного интеллекта и «Open»-AI
А что такое «безопасность ИИ»?
Смотрим на мир глазами робота
Самое интересное изменение, которое сразу бросается в глаза в GPT-4 — это добавление второго типа данных, которые модель может получать на вход. Теперь помимо текстов ей можно скармливать изображения, причем даже не по одному –, а сразу пачкой! Правда, на выходе она по-прежнему выдает только текст: ни на какую генерацию изображений, звуков или, тем более, видео (о чем ходили слухи и якобы «сливы» информации еще совсем недавно) можете даже не рассчитывать. При этом доступ к модели для широких масс пользователей пока ограничен исключительно текстовыми промптами, а работа с картинками находится в стадии тестирования и обкатки.
Какие возможности открывает это «прозрение» GPT-4? Например, можно засунуть в модель картинку, и задать ей какой-нибудь связанный с нарисованными там объектами вопрос. Нейросеть попробует разобраться сразу и в визуальных данных, и в текстовом промпте — и даст свой ответ.
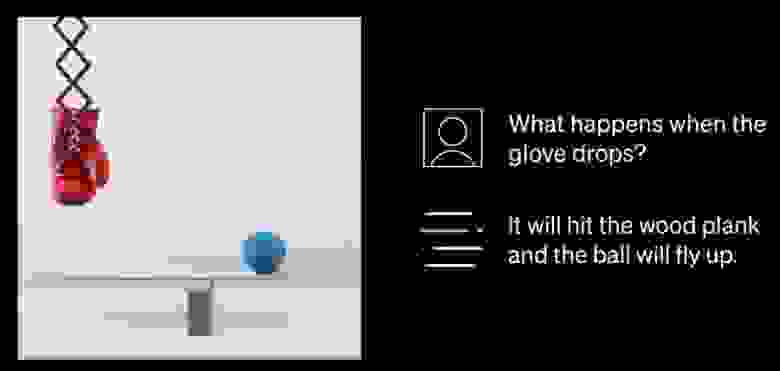
Человеку-то всё сразу «интуитивно» очевидно –, а вот модели для правильного ответа на этот вопрос нужно разобраться, что конкретно изображено на картинке, построить внутри себя некую модель мира, и «просимулировать» дальнейшее развитие событий
Еще можно выдать GPT-4 какой-нибудь график и попросить сделать на базе него анализ. Или заставить ее проходить визуальную головоломку из теста на IQ. Ну и самая огненная вишенка на торте: модель способна объяснить вам мем!

Ну, теперь-то нейросеть уже окончательно сможет заменить типичного офисного работника: смотреть мемы весь день она уже умеет, осталось только научить ее пить кофе!
И ответы на вопросы по изображению, и общий принцип работы с картинками уже существовали и до релиза GPT-4 — такие модели называют «мультимодальными», так как они могут работать сразу с двумя и более модальностями (текст, картинки, а в некоторых случаях — даже звук или 3D-модели). Но при этом новая GPT-4 начисто бьет практически все специализированные и узконаправленные системы ответов на вопросы по изображениям в самых разных задачах (ее результаты лучше в 6 из 8 протестированных наборов данных, причем зачастую более чем на 10%).
А вот ниже еще один скриншот с крышесносной демонстрации на онлайн-трансляции OpenAI, где набросок сайта от руки в блокноте превращается в настоящий сайт буквально в одно мгновение. Вот уж действительно — чудеса мультимодальности! В данном случае модель пишет код сайта, а затем он уже запускается в браузере.

Меня здесь поражает еще и способность нейронки понять каракули чувака из OpenAI — в следующий раз обязательно возьму GPT-4 с собой на прием к врачу!
GPT-4 окончательно вкатилась в программирование (здесь могла быть интеграция ваших курсов)
То, насколько сильно развились навыки программирования у GPT-4 по отношению к ChatGPT, нам еще только предстоит узнать — однако уже за первые двое суток энтузиасты и твиттерские наклепали кучу интересных поделок. Многие пользователи выражают восторг по поводу того, что можно выдать GPT-4 верхнеуровневое описание простенького приложения –, а та выдаст рабочий код, который делает именно то, что требуется.
За какие-то 20 минут можно сделать, например, приложение для ежедневной рекомендации пяти новых фильмов (с указанием работающих ссылок на трейлеры и сервисы для просмотра).

Слева указан текстовый промпт для модели, справа — получившаяся приложуха, которую она накодила. Неплохо, правда?
Вполне вероятно, кстати, что генерируемый моделью код не будет работать с первого раза — и при компиляции вы увидите ошибки. Но это не беда: можно просто скопипастить текст ошибки в диалог с GPT-4 и скомандовать ей «слушай, ну сделай нормально уже, а?» — и та реально извинится и всё пофиксит! Так что до стадии работоспособного приложения с гифки выше можно дойти буквально за 3–4 итерации.
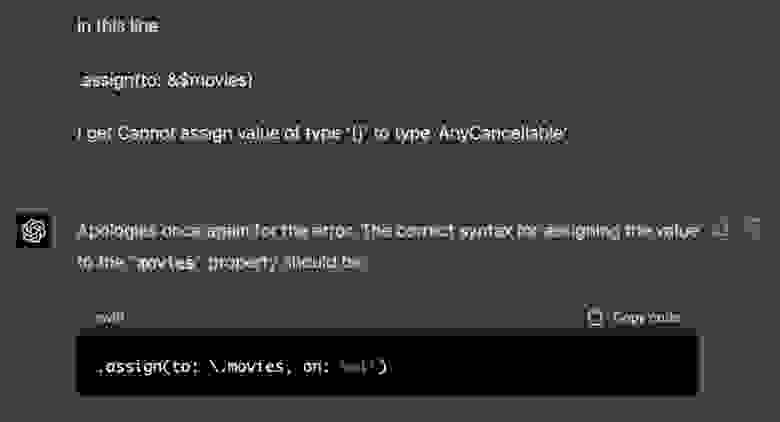
В общем, модель-джун, которую надо тыкать носом в ошибки, у нас уже есть (см. пример на скриншоте). Осталось только создать модель-тимлида, которая на всё будет отвечать фразой «нам нужен часовой Zoom-колл, чтобы обсудить эту проблему!»
Помимо всяких полезных приложений, GPT-4 способна прогать и игры: умельцы уже заставили ее сваять классический Pong, Змейку, Тетрис, го, а также платформер и игру «жизнь». Понятно, что это самые мейнстримные и популярные проекты, которые с одной стороны легко написать, но с другой — они всё-таки являются полноценными демонстрациями. Что-то похожее делала и ChatGPT, но у GPT-4 получается куда меньше ошибок, и даже человек совсем без навыков программирования вполне может сотворить что-то работоспособное за часик-другой.
Ну и отдельного упоминания в номинации «ШТА?» заслуживает разработанная нейросетью игра, в которой можно набигать и грабить корованы. Если это не чистой воды современное искусство — то я уж и не знаю, что им является…

Сравниваем робота с человеком
Раз уж наша модель так насобачилась в простеньком программировании — хотелось бы попробовать как-то более адекватно оценить общий уровень ее умений и знаний. Но сначала давайте попробуем разобраться:, а как вообще подходить к оценке знаний и «сообразительности» модели? Раньше для этого использовали специальные бенчмарки (наборы заданий, вопросов с проставленными ответами, картинок/графиков с задачками, и так далее). Но тут есть одна проблема — развитие технологий всё ускоряется и ускоряется, и бенчмарки уже не очень-то за этим развитием поспевают.
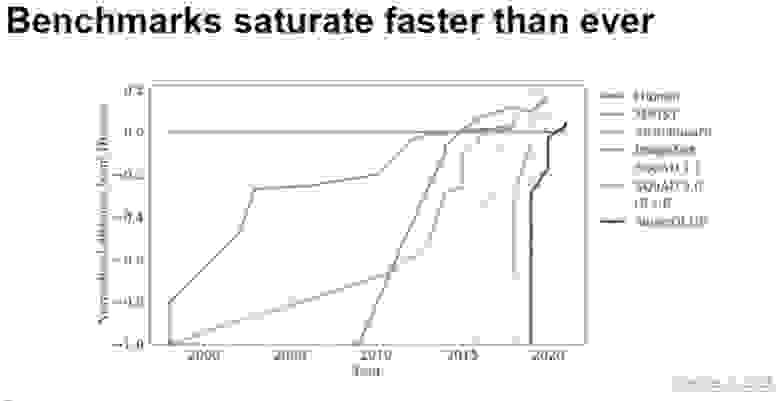
Улучшение результативности моделей в разных бенчмарках с момента их создания в сравнении с уровнем способностей среднего человека (красная линия)
В начале 2000-х и 2010-х годов после создания набора данных требовалось 5+ лет, чтобы «роботы» смогли достичь планки, заданной человеком. К концу прошлого десятилетия некоторые бенчмарки, которые специально создавались с пониманием, что они непосильны нейронкам, закрывались менее чем за год. Обратите внимание на график выше: линии становятся всё вертикальнее и вертикальнее — то есть уменьшается интервал с публикации метода оценки способностей до того момента, когда модели достигают результата на уровне человека.
OpenAI в этом состязании между кожаными мешками и консервными банками пошли дальше, они спросили себя: мол, зачем нам пробовать создавать какие-то специальные тесты для модели, если мы хотим, чтобы она была такой же умной, как человек? Давайте просто возьмем экзамены из реального мира, которые сдают люди в разных областях, и будем оценивать по ним! Результаты для нас с вами (надеемся, эту статью читают в основном люди, а не языковые модели) получились довольно неутешительные, если честно:
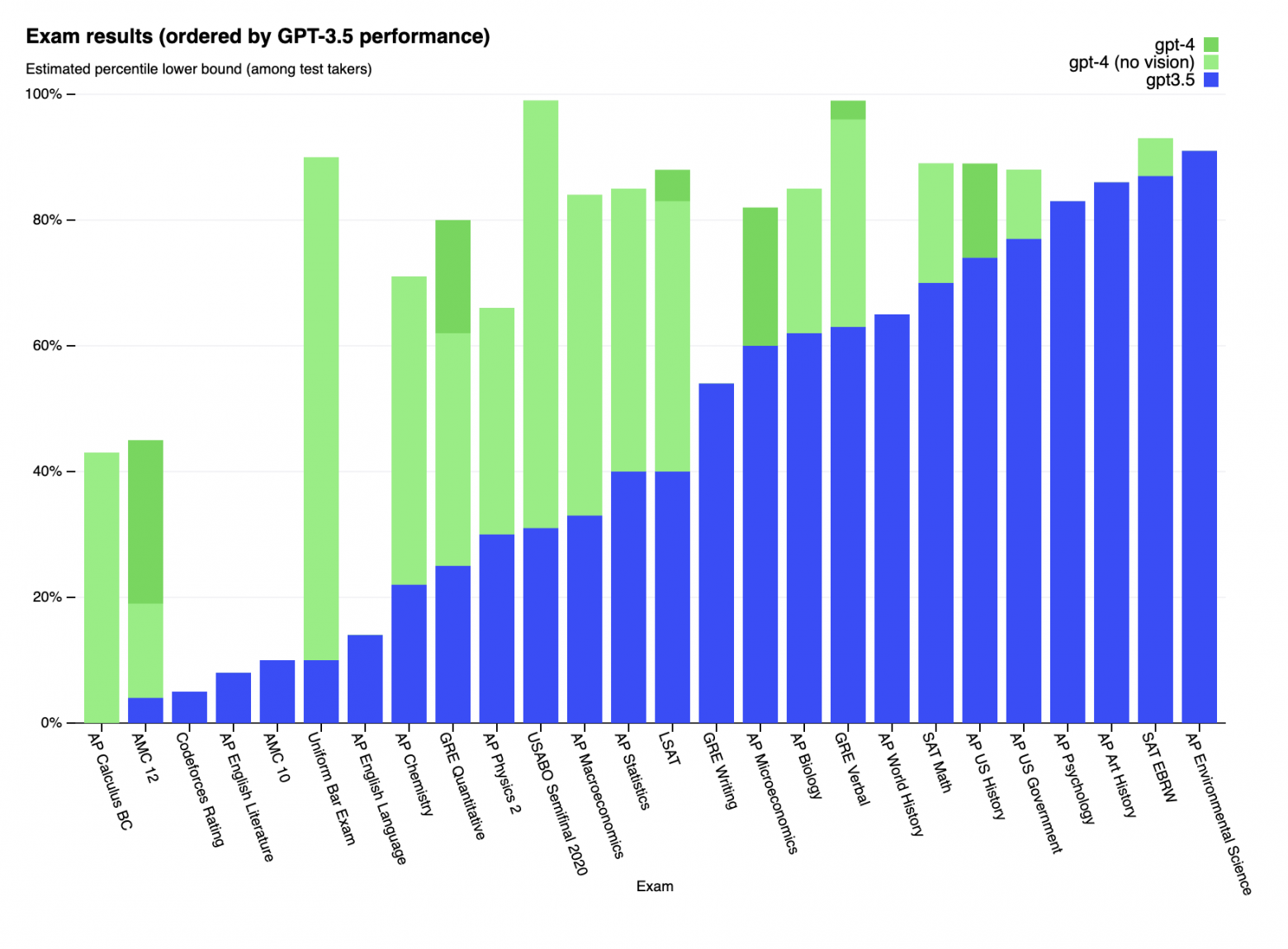
По вертикали — процент людей, сдававших тот или иной экзамен хуже, чем GPT-4 (зелёный) / GPT-3.5 (синий столбик). Чем выше столбик — тем «умнее» модель по сравнению с человеком
На графике выше представлено более 20 реальных экзаменов по разным предметам, от международного права до химии. Причем сравнение здесь идет не с рандомами, а с людьми, которые к этим экзаменам действительно готовились! Да, в небольшой части тестов модель всё еще хуже специалистов, и показывает себя не лучше 30% людей, пришедших на реальное тестирование. Однако уже завтра модель может стать, например, вашим юристом-консультантом — ведь этот экзамен (как и ряд других) она сдала лучше, чем 90% людей, сильно перешагнув за проходной порог. Получается, люди тратят больше пяти лет, усиленно зубрят, не спят ночами, платят огромные деньги за образование –, а модель их всё равно уделывает!
Это заставляет задуматься о двух вещах:
В некоторых отраслях модель уже сейчас может выступать полноценным ассистентом. Пока не автономным работником –, а скорее помощником, который увеличивает эффективность людей, подсказывает, направляет. Если человек может запамятовать о каком-нибудь туманном законе 18-го века, который почти не применяется в судебной практике, то модель напомнит о нем и предложит ознакомиться — если он, конечно, релевантен. Такие ассистенты должны начать появляться уже в этом году.
Уже в 2023 году нам СРОЧНО нужна реформа образования — причем как в методах обучения навыкам и передачи информации от учителей, так и в приемке знаний на экзаменах.

Узнали? Согласны?
На всякий случай для скептиков уточним: модель обучалась на данных до сентября 2021-го (то есть, про то, что Илон Маск целиком купил Твиттер, GPT-4 пока не знает — можете ее этим фактом удивить при случае!). А для проверки OpenAI использовали самые последние общедоступные тесты (в случае олимпиад и вопросов со свободным ответом — распространенные в США Advanced Placement Exams) или приобретали свежие сборники практических заданий к экзаменам 2022–2023 годов. Специальной тренировки модели на данных к этим экзаменам не проводилось.
Для большинства экзаменов доля вопросов, которые модель уже видела во время тренировки, очень мала (меньше 10%) — а, например, для экзамена на адвоката (Bar exam) и вовсе составляет 0% (то есть модель не видела ни одного даже просто похожего вопроса заранее, и тем более не знает ответов). И на графике выше были представлены результаты, достигнутые уже после того, как исследователи выкинули все уже знакомые модели вопросы — так что сравнение было максимально честным.
Мультиязычность и перенос знаний
Уже становится немного страшно, не правда ли? Продолжая тему оценки моделей хочется отметить, что не все бенчмарки уже побиты, и с 2020 года ведется активная разработка новых разносторнних способов оценки. Пример — MMLU (Massive Multi-task Language Understanding), где собраны вопросы из очень широкого круга тем на понимание языка в разных задачах. Всего внутри 57 доменов — математика, биология, право, социальные и гуманитарные науки, и так далее. Для каждого вопроса есть 4 варианта ответа, только один из которых верный. То есть случайное угадывание покажет результат около 25% правильных ответов.

Примеры вопросов по разным темам: от логики и машинного обучения до менеджмента
Разметчик данных (обычный работяга, который однажды повелся на рекламу «вкатись в айти и заработай деньги, просто отвечая на вопросы»), имеет точность в среднем ~35%. Оценить точность экспертов сложно, ведь вопросы очень разные — однако, если для каждой конкретной области найти эксперта, то в среднем по всем категориям они коллективно зарешивают около 90% задач.
До релиза GPT-4 лучший показатель был у модели Google — 69%, nice! Но просто побить этот результат для команды OpenAI — это такое себе достижение (можно сказать, это было бы ожидаемо). И они решили добавить в это «уравнение» еще одну переменную — язык.
Тут вот в чем дело: все задачи по 57 темам, равно как и ответы к ним, написаны на английском языке. Большинство материалов в интернете, на которых обучена модель, тоже написаны на английском — так что не было бы уж столь удивительным, что GPT-4 отвечает правильно. Но что если прогнать вопросы и ответы через переводчик на менее популярные языки, включая уж совсем редкие, где носителей в мире не более 2–3 миллионов, и попробовать оценить модель? Будет ли она хоть сколь-нибудь вменяемо работать?
Да. Не, даже так: ДА! На 24 из 26 протестированных языков GPT-4 работает лучше, чем GPT-3.5 работала на «родном» для нее английском. Даже на валлийском (язык из бриттской группы, на котором говорит всего тысяч 600 человек) модель показывает себя лучше всех прошлых моделей, работавших с английским!
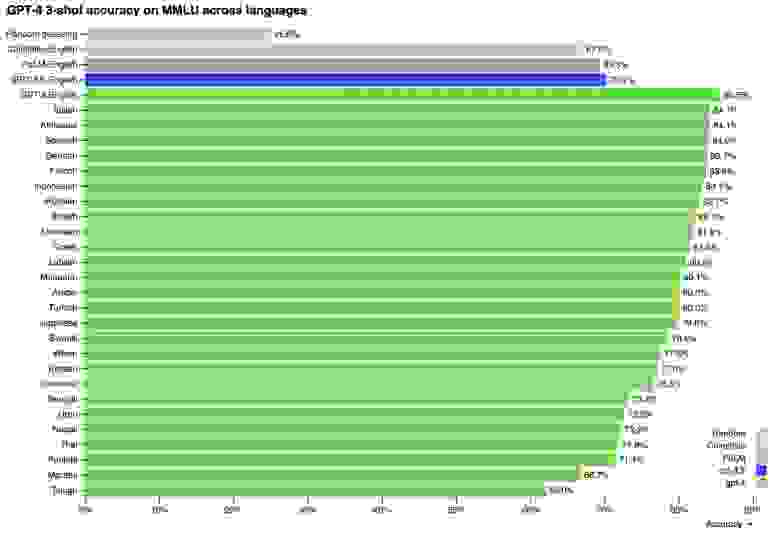
GPT-4 не просто уделывает конкурентов — она изящно делает это сразу на 24 языках, включая русский
Причем, стоит понимать, что качество упирается и в модель-переводчик — ведь она тоже ограничена доступными данными, и качество перевода страдает. Может оказаться, что при переводе теряется смысл вопроса, или правильный ответ теряет важную деталь, делающую его неправильным. И даже при таких вводных GPT-4 всё равно разрывает!
В некотором смысле, мы наблюдаем перенос знаний внутри модели с одного языка на другой (вряд ли на валлийском доступно много материалов про машинное обучение, квантовую физику и прочие сложные темы), когда в тренировочной выборке модель видела упоминание чего-то на немецком или английском, но спокойно применяет знания и отвечает на тайском. Очень грубо можно сказать, что это — proof-of-concept (доказательство концептуальной возможности) того, что называется «трансфер знаний». Это слабый аналог того, как человек, например, может увидеть летящую в небе птицу и придумать концепт самолета — перенеся аналогии из биологии и окружающего мира в инженерию.
Окей, а где всё это использоваться-то будет в итоге?
Так, мы уже поняли — модель вся такая распрекрасная, круто, а какое ей можно найти применение в реальном мире и в бизнесе (а не чтобы просто вот поиграться)? Ну, с Microsoft и их встроенным в Bing поисковиком-помощником всё ясно, а кроме этого?
Еще до релиза GPT-4, на фоне хайпа вокруг ChatGPT, несколько компаний объявили об интеграциях. Это и Snapchat с их дружелюбным чатботом, всегда готовым к общению (самый понятный и простой сценарий), и ассистент по приготовлению блюд в Instacart, который подскажет рецепты с ингридиентами, а также услужливо предложит добавить их в корзину — с доставкой к вечеру.
Куда более важными нам видятся приложения, улучшающие процесс образования. Если подумать, то такой ассистент не устанет отвечать на вопросы по заезженной теме, которую не понимает студент, не устанет повторять правило раз за разом, и так далее. Вот и OpenAI с нами согласны: они приняли в свой стартап-акселератор и инвестировали в компанию Speak, которая разрабатывает продукт, помогающий изучать английский язык.
Не отстает и Duolingo — демоническая зеленая сова на релизе GPT-4 объявила, что в продукте появится две новые функции: ролевая игра (партнер по беседе на разные темы), и умный объяснятель ошибок, который подсказывает и разъясняет правила, с которыми у студента наблюдаются проблемы.

Давайте признаем: мемы про Duolingo уже давно предсказывали, чем вот это всё кончится…
GPT-4 также придет на помощь людям с проблемами зрения, расширив и улучшив функционал приложения Be My Eyes («будь моими глазами»). Раньше в нем добровольцы получали фотографии от слабовидящих людей и комментировали, что на них изображено, а также отвечали на вопросы — вроде «где мой кошелек? не вижу, куда его положила» от бабушки. Так как новая модель умеет работать с изображениями, то теперь уже она будет выступать в качестве помощника, всегда готового прийти на помощь в трудной ситуации. Независимо от того, что пользователь хочет или в чем нуждается, он может задавать уточняющие вопросы, чтобы получить больше полезной информации почти мгновенно.
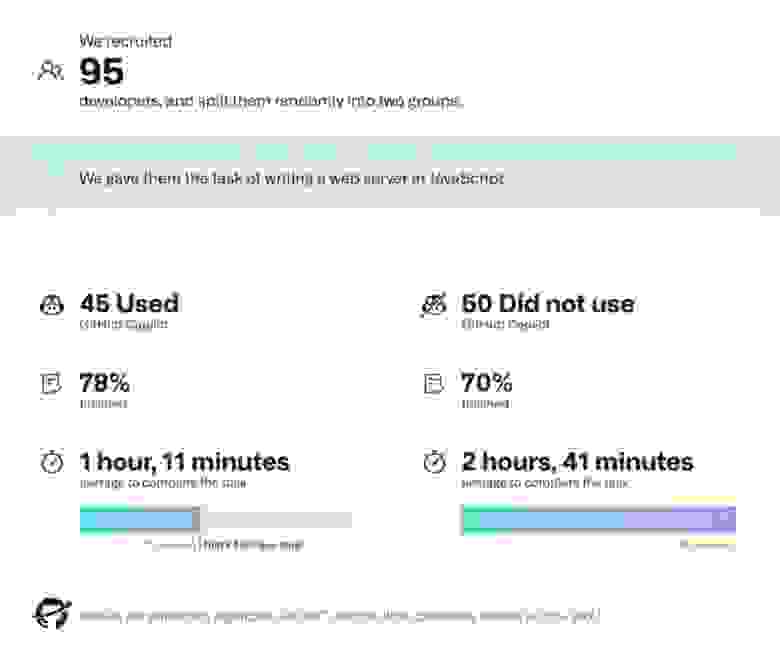
Еще после выхода ChatGPT (и его чуть более раннего аналога для программистов Codex-Copilot) появились исследования, которые показывают существенное увеличение производительности труда специалистов.
Для программистов — это способ быстрее решать рутинные задачи, делая упор именно на сложные вызовы, с которыми машина пока не справляется. Согласно исследованию GitHub, время, затраченное на программирование у пользователей ассистента Copilot, сократилось на 55%, а количество решенных задач выросло.