Готовим PostgreSQL в эпоху DevOps. Опыт 2ГИС. Павел Молявин

Всем привет! Меня зовут Павел! Я работаю в компанию 2ГИС. Наша компания — это городской информационный справочник, навигационный сервис. Это очень хорошая штука, которая помогает жить в городе.

Работаю я в подразделении, которое занимается веб-разработкой. Команда моя называется Infrastructure & Operations, сокращенно IO. Мы занимаемся поддержкой инфраструктурой для веб-разработки. Предоставляем свои сервисы командам как сервис и решаем все проблемы внутри нашей инфраструктуры.

Stack, который мы используем, технологии очень разнообразные. В основном это Kubernetes, мы пишем на Golang, на Python, на Bash. Из баз данных мы используем Elasticsearch, используем Cassandra и, конечно, используем Postgres, потому что мы его очень любим, это один из базовых элементов нашей инфраструктуры.
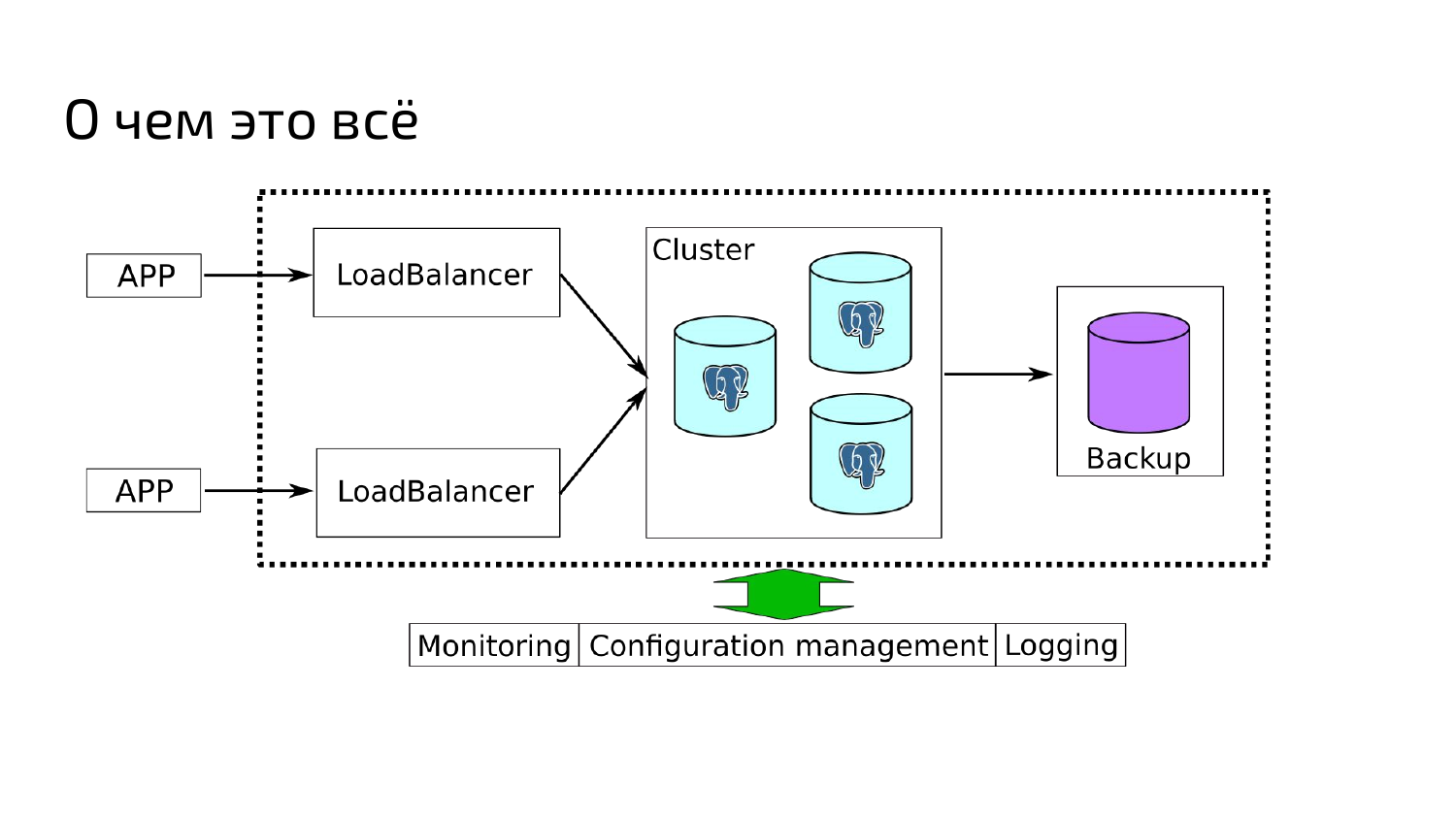
Расскажу я о том, как в один прекрасный момент нам понадобилось создать инструмент для быстрого развертывания отказоустойчивого кластера на основе Postgres. И нужно было обеспечить интеграции со всеми существующими у нас системами, обеспечить управление конфигураций: мониторинг, логирование, обязательно, чтобы были бэкапы, чтобы была серьезная штука для того, чтобы использовать ее в том числе на production.
Мой доклад будет не про внутренности Postgres, не про работу внутри Postgres, а о том, как мы строим инфраструктуру вокруг него. Казалось бы, все просто — берешь и делаешь, но на самом деле нет, все гораздо сложнее. Я расскажу об этом.

Начнем с постановки задачи. У нас продуктовые команды пишут приложения. Количество приложений постоянно растет. Приложения раньше мы писали в основном на PHP, Python и на Java Scala. Потихоньку к нам незаметно вползли модные языки типа Golang, без Node.js тоже сейчас никуда, тем более во FrontEnd.
В качестве хранилищ данных для наших приложений мы выбрали Postgres. Были предложения использовать MySQL, Mongo, но в итоге слон всех победил, и мы используем Postgres.

Поскольку у нас практикуется DevOps, продуктовые команды вовлечены в эксплуатацию, т. е. есть многие сервисы, которые они поддерживают сами для своих приложений. В частности, это было с Postgres. Каждая команда ставила сама себе Postgres, его конфигурировала, настраивала.

Время шло, количество Postgres увеличивалось, были разные версии, разные конфигурации. Постоянно возникали какие-то проблемы, потом у нас началась миграция в Kubernetes, когда Kubernetes перешел в production-стадию. Соответственно, появилось еще больше баз, еще больше Postgres понадобилось, потому что нужно было хранилище данных для миграции, для переходных приложений. В общем, полное безобразие началось.

Команды у нас пытались использовать для установки Postgres и его настройки Ansible. Кто-то, более отважный, использовал Chef, у кого был с ним опыт работы.
Но самый любимый способ — это все поставить ручками, забыть, как сконфигурировали и обратиться в нашу команду IO, и попросить помощи.
Соответственно, нагрузка увеличивалась на команды, которые занимались администрированием Postgres. Нагрузка увеличивалась на нас, потому что они тратили свое время для того, чтобы найти проблему. Потом приходили к нам, мы тратили время. В общем, выяснилось, что всего очень много. У нас даже были особо отличившиеся. Во времена 9.4 Postgres умудрялись ставить Postgres 8-ой версии.

В итоге мы решили, что надо с этим что-то делать, хватит это терпеть. Мы решили создать единое решение. Кинули клич в команды и спросили: «Что вам нужно, чтобы было хорошо?». Сформировали требования и приступили к работе, т. е. к созданию.

Мы решили, что поскольку это все будет production, обязательно нужно сделать кластер, чтобы было несколько реплик и они между собой реплицировались, чтобы был мастер и обеспечивался autofailover на случай, если кластер ночью упадет, но сервисы могли продолжить работать. Также у нас было опциональное требование — обеспечить вынос реплики в другой дата-центр для обеспечения отказоустойчивости и для того, чтобы приложения в другом дата-центре тоже работали хотя бы на чтение.

Обязательно мы решили сделать балансировку, потому что коннекты в Postgres — ресурс достаточно дорогой. Обязательно нужно сделать pooling, устойчивые балансировщики, т. е. обеспечить, чтобы все работало.

Обязательно сделать резервные копии с приемлемой глубиной хранения, чтобы еще можно было осуществлять point in time recovery. И нужно было сделать обязательную архивацию WAL-файлов.

Нужно было обязательно обеспечить интеграцию с существующими системами мониторинга и логирования.
И поскольку мы придерживаемся парадигмы: infrastructure as code, то мы решили, что наше решение будет выглядеть в виде деплоя. Мы решили написать его на общеизвестном в нашем подразделении инструменте. У нас это был Ansible. И еще мы немножко кое-что написали на Python и Bash мы тоже активно используем.
Основная мысль была такая, чтобы это было некое целостное решение, чтобы наш деплой могла взять любая команда. Могла бы поменять какие-то переменные, поменять секреты, ключи, поменять inventory и развернуть себе отказоустойчивый кластер. Т. е. чтобы по большому счету нужно было нажать кнопку «deploy» и через некоторое время уже подключаться к готовому кластеру и с ним работать.

И поскольку мы используем корпоративный Gitlab, хотелось, чтобы все это работало через встроенные возможности Gitlab, через continuous integration, continuous delivery. Т. е. чтобы можно было нажать кнопку «deploy» в репозитории и через некоторое время появлялся бы рабочий кластер.
И теперь мы все эти элементы рассмотрим в отдельности.

Кластер PostgreSQL

- Мы выбрали PostgreSQL 9.4. Это было примерно 3,5 года назад. Тогда как раз был 9.4 в baseline. 9.6, по-моему, только вышел или его еще не было, я точно не помню. Но мы достаточно быстро наше решение проапгрейдили до 9.6, т. е. оно стало его поддерживать.
- Для обеспечения репликации мы не стали ничего выдумывать. Выбрали стандартный метод — потоковую репликацию. Она наиболее надежная, наиболее известная. С ней особых проблем нет.
- Для кластеризации мы выбрали менеджер репликации с псевдо HA. Это repmgr от 2ndQuadrant. В защиту repmgr могу сказать. В предыдущие два дня в него летели активно камни, что он не обеспечивает настоящий HA, у него нет фенсинга, но на самом деле за три года эксплуатации я могу сказать, что у нас не было ни одного инцидента, когда переключения failovers произошли неправильно или закончились ошибкой. Т. е. всегда repmgr переключал кластер по делу. Всегда обеспечивал нам надежность. Не без downtime, конечно. Примерно 2 минуты repmgr соображает, что нужно выполнить failover и после этого его выполняет.
- Для repmgr мы написали кастомный failover_command. Это такая команда, которую repmgr выполняет, когда собирается провести failover, т. е. запромоутить нового мастера. Т. е. запускается специальный скрипт. Он идет на балансировщики, проверяет, что балансировщики работают, что они доступны с нового мастера. И после этого происходит переключение. Т. е. он выполняет failover, переписывает бэкенды на балансировщиках и после этого завершает свою работу. Соответственно, мы получаем нового мастера. И балансировщики подключены к новому мастеру.
- С репликой в другом ДЦ. У нас основное место присутствия — это Новосибирск. Несколько ДЦ в Новосибирске. Но есть площадка в Москве, поэтому нам нужно было обеспечить, чтобы две реплики находились в Москве. Сначала мы их добавили в кластер repmgr.
Но после начала эксплуатации одного из тестовых кластеров, выяснилось, что связь не очень хорошая, постоянные просадки ping«а, лаги. В итоге мы отказали от этой идеи. Постоянно в кластере происходили warning, т. е. мониторинг начинал говорит, что что-то в кластере изменилось, давайте проверим, что происходит. Репликация также периодически прерывалась.
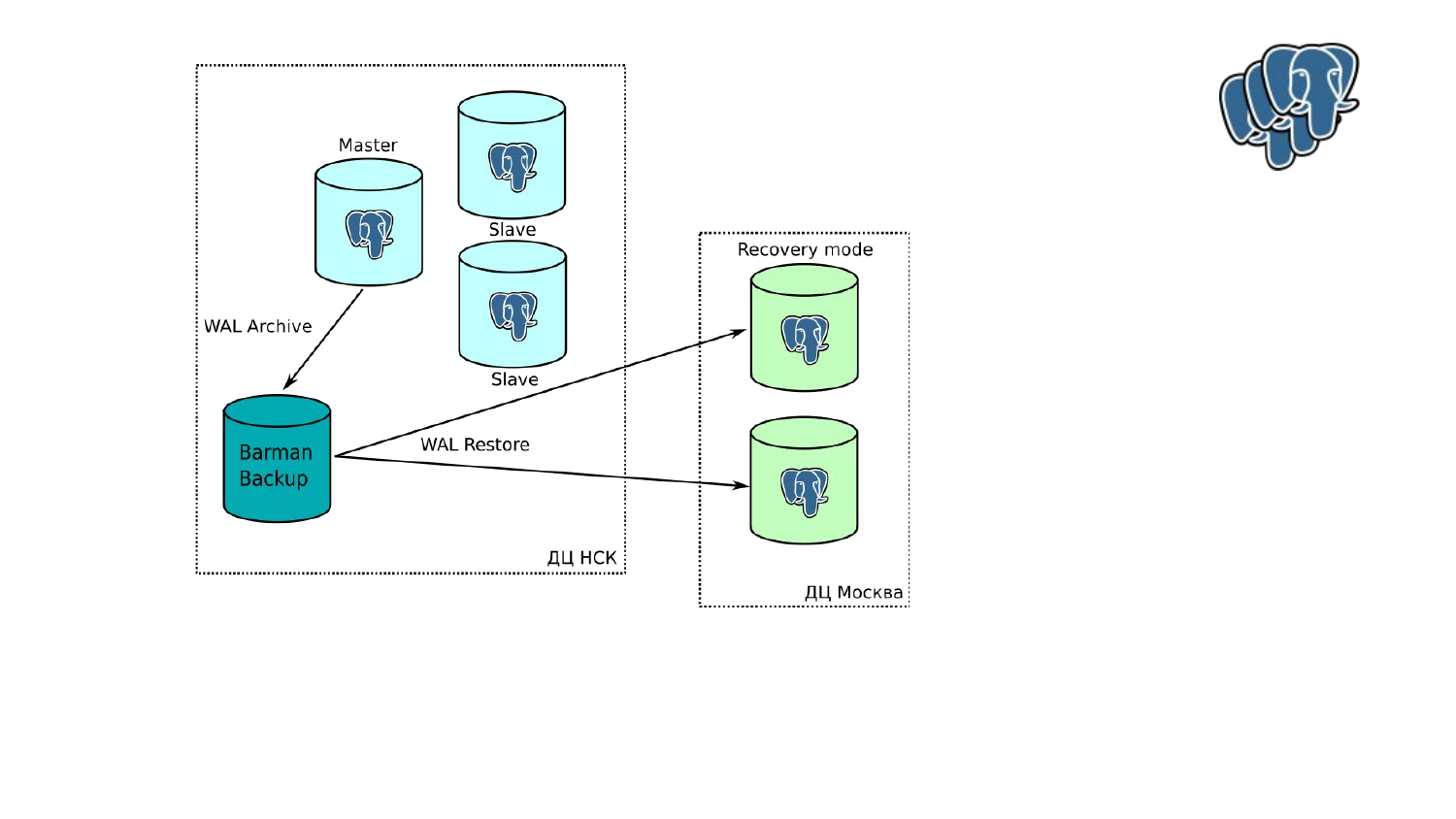
В итоге мы сделали вот такую схему, т. е. мы вытащили из repmgr ноды, которые находятся в Москве. Сделали из них обычный hot standby, не стали ничего выдумывать. Они у нас через restore забирают с бэкап-сервера архивы WALs. Соответственно, проблему лага мы не разрешили. Если у нас на мастере начинается активная работа, то понятно, что реплики в Москве немножко отстают.
Но они отстают так, что сами восстанавливаются, т. е. репликация не прерывается. И приложение, которые используют их используют в Москве в курсе, они знают, они понимают, что такое может быть. И у них всегда в виде fallback есть новосибирские ноды, которые в кластере находятся.

Проблемы. Проблем особых здесь нет. Помимо того, что медленно работает у нас archive_command, потому что сделан через обычный rsync, т. е. журналы с мастера попадают на архив через rsync ssh. Соответственно, если на мастере начинается работа, то это все немножко тормозит. Но с этим мы справимся, потому что, скорее всего, будем переключить архивацию в streaming режим. В общем, не такая это большая проблема.
С балансировкой мы решили, что нам нужно обязательно сделать отказоустойчивые балансировщики.

Мы выделили для этого специальные узлы. У них на входе стоит keepalive. У каждого keepalive есть виртуальный адрес, для которого он является мастером. Соответственно, если один keepalive падает, второй получает его адрес как второй, т. е. у него два адреса.
Эти адреса балансируются в DNS через round robin, т. е. когда приложение подключается к кластеру, они получают либо виртуальный адрес первого балансировщика, либо виртуальный адрес второго балансировщика.
Адреса keepalive у нас получает PgBouncer. Отличный pooler, у нас с ним особых проблем нет. Он работает, не доставляет никаких неприятностей. Но у него есть одна проблема. У него бэкенд может быть только один и он должен смотреть на мастера. Поэтому мы поставили у него на бэкенде Pgpool. Нам он понравился тем, что он знает, где в кластере находится мастер, умеет балансировать запросы на чтение, на slave.

Все было классно, хорошо, мы начали его эксплуатировать, но в определенный момент нам пришлось сделать вот так. Потому что с Pgpool у нас были постоянные проблемы. Он периодически без видимых причин выбрасывал мастера из балансировки. Также его встроенный анализатор, который анализирует запросы, периодически не мог определиться — запрос на запись, запрос на чтение, т. е. он мог запрос на запись отправить на реплику. Соответственно, мы получаем read only кластер и панику на корабле. В общем, все плохо.

Мы избавились от Pgpool. PgBouncer смотреть теперь только на мастер. Деплой проставляет PgBouncer«у бэкенд. И failover_command с будущего мастера переключает адрес бэкенда и делает мягкую перезагрузку PgBouncer. И таким образом PgBouncer всегда смотрит на мастер.
Все было бы хорошо, если бы вся нагрузка не ушла на мастер, потому что при Pgpool были задействованы slave. А тут оказалось, что теперь slave не участвуют.

И совершенно по хорошему стечению обстоятельств наши приложения начали поддерживать real only точки. Т. е. они могут подключаться к балансировщику на запись, они могут подключаться к балансировщику на чтение, чтобы осуществлять чтение с него.
Соответственно, мы сделали такую же пару. Я тут один нарисовал, потому что он уже не влезал. Мы по такому же подобию сделали балансировщики на чтение. Только на бэкенде у PgBouncer поставили HAProxy, который с помощью специально скрипта ходит в кластер и точно знает, где у него находятся slave и отправляет по round robin запросы на них.
Также у нас приложения начали поддерживать pooling на своей стороне, т. е. начали использовать штуки типа Hikari Pool. И, соответственно, экономить коннекты для балансировщика. И после этого стало еще более хорошо жить.

С резервными копиями мы тоже не стали ничего выдумывать, не стали ничего усложнять.

Взяли Barman.
- Barman у нас делает бэкап базы через cron каждые два дня, когда нагрузка минимальная.
- Также у нас через archive_command происходит архивация WAL-файлов к Barman, чтобы можно было PITR осуществлять.
Нам всегда хочется иметь уверенность, что у нас есть бэкап, который можно восстановить. Поэтому у нас есть отдельный выделенный хост, который каждую ночь после прошедшего бэкапа восстанавливает либо последний бэкап, либо предыдущий. И накатывает какое-то количество WAL-файлов, чтобы проверить, что PITR работает. Соответственно, скрипт проходит, база восстанавливается. Он запускает другой скрипт, который заходит в базу, проверяет метки. После этого сигналит нашему мониторингу, что все нормально, бэкап есть и бэкап разворачивается.
Недостатки в этой схеме довольно стандартные:
- Тот же самый archive_command.
- И требуется очень много места, потому что WAL-файлы мы не сжимаем, потому что экономим процессор, экономим время, чтобы при восстановлении можно было максимально быстро восстановиться.

Мониторинг и логи

- У нас используется в качестве мониторинга Prometheus. Он использует pool-модель сбора метрик. Т. е. он сам ходит к сервисам и спрашивает их метрики. Соответственно, нам для каждого компонента системы (а это почти все компоненты, которые не умеют отдавать метрики) пришлось найти соответствующий exporter, который будет собирать метрики и отдавать их Prometheus, либо написать самостоятельно.
- Мы свои exporters пишем на Golang, на Python, на Bash.
- Мы используем в основном стандартные exporters. Это Node exporter — основной системный exporter; Postgres exporter, который позволяет собирать все метрики с Postgres; exporter для PgBouncer мы написали сами на Python. И мы написали еще кастомный Cgroups exporters на Golang. Он нам нужен для того, чтобы четко знать, какое количество ресурсов системных сервер баз данных потратил на обслуживание каждой базы.
- Собираем мы все системные метрики: это память, процессор, загрузка дисков, загрузка сети.
- И метрики всех компонентов. В exporter«е для Postgres вообще ситуация такая, что вы сами exporter«у пишите запросы, которые хотите выполнять в базе. И, соответственно, он вам выполняет их и формирует метрики. Т. е., в принципе, метрики, которые можете добыть из Postgres ограничены только вашей фантазией. Понятно, что нам важно собирать количество транзакций, количество измененных tuples, позицию WAL-файлов для того, чтобы отслеживать постоянно отставание, если оно есть. Обязательно нужно знать, что происходит на балансировщиках. Сколько сессий находятся в каком статусе. Т. е. все-все мы собираем в Prometheus.

Метрики мы смотрим в Grafana. Вот так примерно выглядит график Cgroups с exporter«а. Мы всегда можем посмотреть, какая база у нас, сколько процессора употребила за определенное время, т. е. очень удобно.

Как в любой системе мониторинга у нас есть alerts. Alerts в Prometheus занимается AlertManager.

У нас написано большое количество alerts, касательно кластера. Т. е. мы всегда знаем, что у нас начался failover, что failover закончился, что failover закончился успешно или не успешно. И все эти вопросы мы обязательно мониторим. У нас есть alerts, которые либо сигналят нам в почту, либо сигналят в корпоративный Slack, либо звонят по телефону и говорят: «Просыпайся, у тебя проблема!».
Мониторим мы также успешные бэкапы, успешные восстановления. Проверяем, что у нас база доступна на запись, на чтение через балансировщики, мимо балансировщиков, т. е. полностью мониторим весь путь запроса от балансировщика до базы.
Также обязательно мониторим тестовое восстановление, чтобы знать, что у нас есть бэкап, что он работает, восстанавливается.

С логами у нас не очень богато. У нас в компании используется ELK stack для сбора логов, т. е. мы используем Elasticsearch, Kibana и LogStash. Соответственно, Postgres и все компоненты нашего решения складывают логи на диск в CSV-формате, а с диска их собирает Python Beaver. Есть такой проект. Он их собирает и отдает LogStash. LogStash обогащает какую-то информацию, добавляет информацию к какой команде относится кластер, какой кластер, в общем, вносит какую-то дополнительную информацию.
И после этого в Kibana можно легко логи просматривать и агрегировать, в общем, сортировать и все, что угодно делать.
Также команды нас попросили поставить Pgbadger. Это такая штука, которая позволяет легко и непринужденно анализировать, например, slow логи. Это основное, для чего они хотели эту штуку. Она написана на Perl. Она нам не очень понравилась, потому что под нее нужно было отдельный хост размещать. Мы его в итоге задвинули в Kubernetes. Он у нас работает в Kubernetes. Получает он логи из LogStash. LogStash отдает ему по HTTP логи и в Pgbadger потом можно просматривать, и искать свои медленные запросы. В общем, грустить и выяснять, как это починить.
С деплоем следующая история. Нужно было деплой сделать максимально простым, чтобы инструмент был понятным.
Мы решили написать деплой на Ansible. Хотелось его сделать максимально повторяемым, максимально идемпотентным, чтобы его можно было использовать не только при первоначальном деплое, но и можно было использовать для эксплуатации. Мы хотели автоматизировать все операции, которые могут быть снаружи самого Postgres. В том числе изменение конфигурации в Postgresql.conf, чтобы все-все можно было делать через деплой. Чтобы всегда были версии, чтобы всегда четко можно было по истории репозитория отследить что происходило, и кто вносил изменения.

Как я уже сказал, мы написали деплой на Ansible. Пришлось нам для этого использовать 25 ролей. Все компоненты ставятся с помощью этих ролей, т. е. ничего дополнительно ставить не нужно. Вы запускаете деплой и после этого у вас есть рабочий кластер. Единственное, что вам потом нужно будет сделать, это сделать мерж-реквест в систему мониторинга, потому что она у нас отдельно работает и для нее нужно отдельно указывать, куда ей нужно ходить и собирать метрики.
20 ролей для этого деплоя мы написали сами. 12 из них являются вырожденными, т. е. это роли, которые мы написали исключительно для этого деплоя. И они особо больше нигде не пригодятся, поэтому они лежат прямо в деплое, прямо в специальном каталоге.
И нам пришлось все роли локализовать. Т. е. те, которые раньше мы доставали из интернета, мы их локализовали, потому что Роскомнадзор довольно активизировался. Он постоянно банит хосты GitHub, поэтому мы решили не тащить роли снаружи. И все роли у нас лежат локально в наших репозиториях.
Также мы использовали встроенную возможность Ansible. Это использование для деплоя разные окружения. Т. е. по дефолту в нашем деплое есть testing, production и staging. Под staging мы понимаем такой почти production, но без трафика пользователей. В принципе, используя встроенную возможность Ansible можно добавить какие угодно окружения. Если вам нужно два-три testing, чтобы протестировать какую-то фичу, то вы добавляете в дополнительный environments, добавляете переменные, нажимаете «deploy». И после этого у вас есть рабочий кластер.
Ключи, пароли мы храним в секретах. Шифруем все Ansible Vault. Это встроенная в Ansible возможность.
Поскольку мы используем Ubuntu Linux как базовую систему, то все мы ставим из репозиториев. Все, что не предоставлялось в виде пакетов, мы пакетируем и складываем к себе в локальный apt. Это тоже нужно для того, чтобы не иметь проблем, когда Роскомнадзор снова решит что-то забанить и для того, чтобы максимально деплой ускорить, потому что локально все быстрее происходит.
Мы постарались автоматизировать все рутинные операции. Т. е. любое изменение конфигурации: добавление баз, добавление пользователей, добавление real only пользователей, добавление каких-то дополнительных штук в базу, изменение режима в балансировке, потому что у нас одна часть сервисов использует транзакционную балансировку, другой части нужны prepared statements, а они используют сессионную балансировку.
Также у нас сам bootstrap кластер работает полностью в автономном режиме. Вы при первом запуске выставляете определенную переменную и у вас полностью бутстрапится кластер. Он чист и готов к работе. Там, конечно, есть неудобства, потому что эту переменную нужно выключить. Потому что если вы деплой еще раз запустите с этой переменной, то у вас опять окажется чистый кластер. Т. е. про эти штуки надо помнить. Они отражены в документации.
Деплой у нас лежит в виде Git-репозитории, как я уже говорил, в нашем внутреннем Gitlab.
Вся работа происходит в ветках. Это стандартные workflows. Из веток мы ничего не деплоим. Обязательно создается мерж-реквест. Это мерж из веток в мастер. По нашим внутренним практикам в мерж-реквест призываются ответственные люди, т. е. обычно это либо члены команды, либо члены нашей команды, которые разбираются в вопросе, понимают, о чем идет речь. После того, как мерж одобряется, он сливается в мастер. И из мастера происходит деплой кластера.
Также мы написали кастомную обвязку для развертывания кластера в OpenStack. Это очень удобно. Особенно, если вам нужна куча тестингов. Мы можем использовать нативное Openstack API через модуль Ansible, либо через одну штуку в OpenStack, которая называется heat-api, которая позволяет шаблонами запускать машины по несколько штук. Это очень удобно. Если вам нужно в ветке что-то потестировать, вы подключаете эту обвязку, которая позволяет через heat-api разворачивать машинки. Разворачиваете себе кластер. С ним работаете. После говорите: «Мне это не надо. Удалить». Это все удаляется, т. е. виртуальные машинки в OpenStack удаляются. Все очень просто и удобно.
Также для железных машин мы написали bootstrap, но это обычный пресет образ. Это встроенная возможность Debian, Ubuntu. Он задает несколько вопросов. У него сделана специальное меню. Задает несколько вопросов про диск, про сеть. После того, как вы закончили, вы имеете ноду, которая уже готова для того, чтобы ее можно было использовать в деплое. Т. е. вы прописываете ее в инвентарь и после этого можете запускать деплой, и все будет хорошо.

Также в деплой мы встроили тесты. Тесты написали на Ansible. Тесты инфраструктурные, т. е. мы запускаем их только на тестовом окружении. Тесты у нас сначала запускают кластер. Потом его ломают. Проверяют, что все доступно с балансировщика, что мастер переключился, что происходит бэкап, что база восстанавливается, т. е. полностью все проверяется.
И последний пункт. Мы используем встроенные возможности Gitlab.

Gitlab умеет запускать специальные jobs. Jobs — это отдельные шаги, которые выполняются.
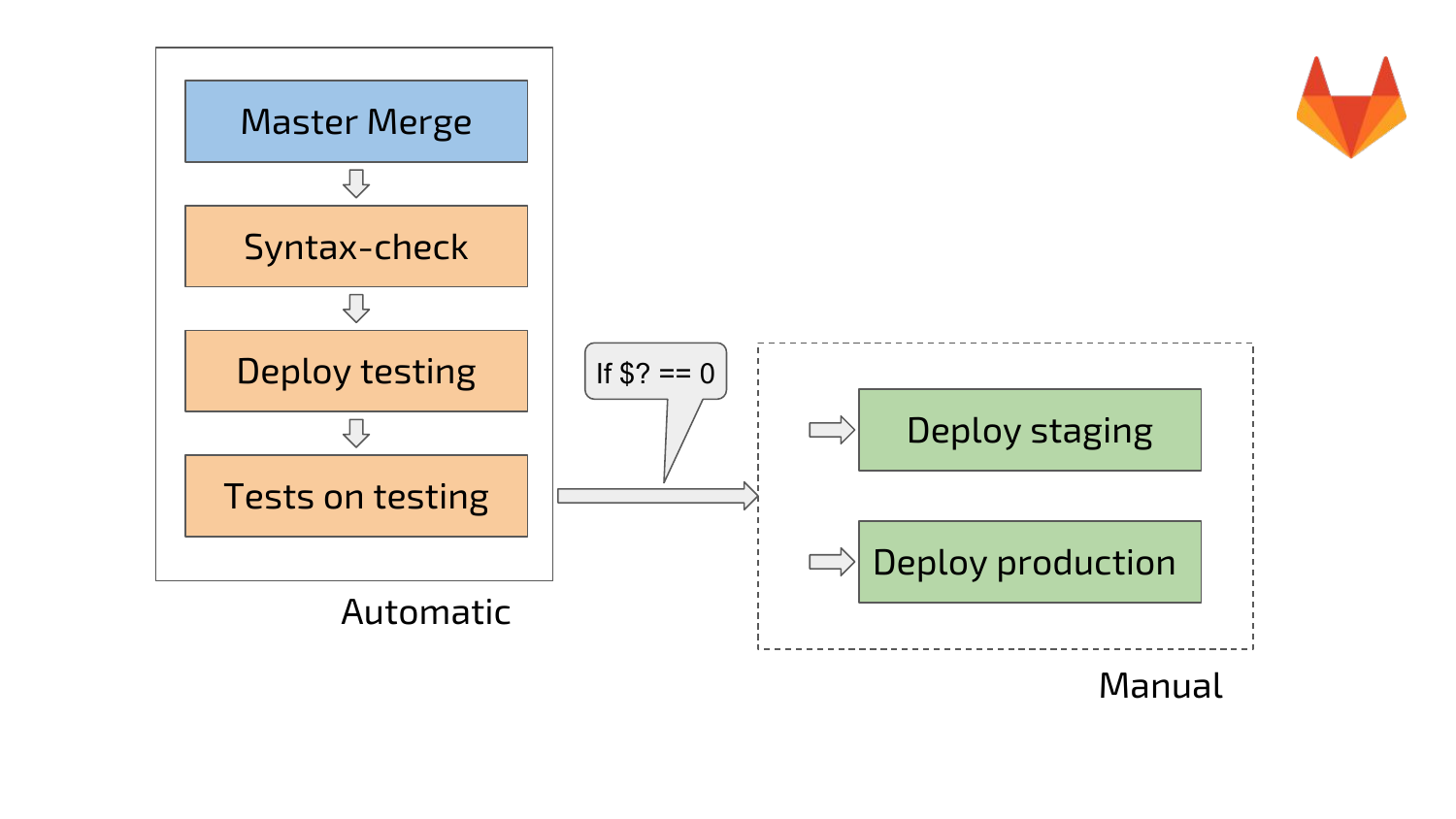
Т. е. у нас отдельными шагами являются syntax check, деплой, тесты. Здесь у нас маленькая схема. После мержа в мастер автоматически запускается pipeline, который производит syntax check, деплоится на тестинг. На тестинге запускаются тесты. После этого, если все Ok, все зеленое, разблокируется ручной запуск деплоя staging и деплоя production.
Ручной запуск у нас сделан, чтобы люди, которые это делают, понимали, что они делают и отдавали отчет, что сейчас будет деплой на testing или на staging или на production.

Подведем итоги. Что же нам удалось? Мы хотели сделать такой инструмент, который будет нам все разворачивать, чтобы получить очень быстро рабочий кластер со всеми интеграциями. В принципе, нам это удалось. Такой деплой мы создали. Нам он очень помогает. Даже при не очень хороших обстоятельствах в течение 15 минут после начала нажатия кнопки «deploy», вы получаете рабочий кластер. Вы можете заходить на endpoint и использовать в работе. Соответственно, команды могут его встраивать прямо в pipeline, т. е. полностью с ним работать.

Наша команда поддерживает несколько кластеров на базе этого решения. Нас все устраивает, мы полностью работаем через деплой. Вручную мы ничего практически не делаем. Я об этом дальше расскажу.
Поддержку командных СУБД мы исключили. Команды перестали у нас заниматься самодеятельностью, перестали ставить Postgres, все это делаем мы. Мы все устанавливаем, все настраиваем. В общем, ребята освободились, они дальше могут писать свои продуктовые фичи, которые им очень нравятся.
Мы получили огромный опыт. Разобрались как работают rep managers, балансировка, репликация, Postgres. Это неоценимый опыт, всем советую.
Failover у нас работает. Failover, я бы не сказал, что происходит часто. За три года порядка десяти раз у нас был failover. Failover практически всегда по делу был.
Мы делаем вручную switchover, т. е. это failover вручную. Switchover мы делаем для всяких интересных штук. Например, когда нам нужно было перевести один из кластеров из одного ДЦ в другой, мы просто забутстрапили с помощью деплоя ноду в другом ДЦ. Сделали на нее switchover, переключили балансировщики. И тогда у нас появился рабочий мастер в новом ДЦ практически без downtime, только на время переключения. А для repmgr (Replication Manager) — это, по-моему, две минуты дефолтные.

Без falls у нас тоже не обошлось:
- Мы хотели сделать решение простым, чтобы команды могли его сами использовать. Но тут ничего не вышло. Все равно надо знать нюансы, как все работает внутри, все равно нужно понимать, как работает репликация, как работает rep managers. Именно поэтому количество форков нашего репозитория равно нулю. Команды не занимаются этим. Может быть, это и неплохо, потому что все проблемы мы бы решали.
- Все равно для каждого кластера приходится что-то допиливать, дописывать. Не удается использовать один и тот же деплой.
- И от ручных операций тоже не удалось избавиться. Все равно апгрейды, перезапуски Postgres, когда нужно внести какие-то изменения в postgresql.conf, приходится делать вручную. Потому что автоматике это можно доверить, но нужно понимать, что происходит. Без оператора не обойтись. Человек должен понимать, что он делает. Без ручных операций все равно не получается.
- Обновление — это отдельная боль. Это нужно все апгрейдить руками. Балансировщики, например, можно проапгрейдить автоматом, но будет downtime. А без автоматики вручную это можно сделать без downtime.
- И мы не очень любим собирать пакеты, потому что на это тратится дополнительное время. Нужно делать инфраструктуру для сборки, инфраструктуру для pushes и репозиторий.

У нас в компании довольно активно развивается Kubernetes, поэтому есть ощущение попробовать что-нибудь новое. Например, попробовать запустить отказоустойчивый Postgres в Kubernetes. Для этого мы хотим посмотреть на Stolon, Patroni. Возможно, это будет первым, чем мы займемся.
И хочется сделать такую же штуку без кластера, т. е. хочется обеспечить модульность, чтобы можно было какие-то шутки отключать в деплое, какие-то включать, и чтобы сильно при этом деплой не переписывать. У нас есть процессинговые базы, которым не нужен кластер, не нужен бэкап, но, например, нужна балансировка и мониторинг с логированием.
И наше решение — мы будем делать апгрейд на PostgreSQL 10–11. Я предвижу, что это будет очень «веселое» развлечение. Вызов принят, у нас вариантов нет, мы используем наше решение и будем апгрейдиться.


Вопросы
Спасибо за доклад! На разработку всех плейбуков в Ansible, сколько потратилось времени?
Путем проб и ошибок, путем нескольких заваленных кластеров где-то порядка два-три месяца заняло. В команде было 2–3 человека.
Какие-то были особенности именно внедрения Ansible в связке с Postgres, с вашим решением? Например, что-то пришлось кардинально перерабатывать?
Модули писать для Ansible?
Да.
Нет, мы использовали встроенные возможности Ansible, т. е. все модули, которые у него идут внутри.
Спасибо за доклад! Почему на Barman остановились? И насчет апгрейда у меня созрел вопрос еще в самом начале, когда про 9.6 рассказывали. Я увидел, что у вас есть планы на 10 и 11 версию, да?
Не знаю, но почему-то решили выбрать Barman. Он нам понравился тем, что конфигурируется нормально. Т. е. у нас была для него уже написанная роль в Ansible. Мы хотим посмотреть на что-нибудь другое, например, на WAL-G. Но проблема в том, насколько я помню, WAL-G не умеет в диск (Уточнение: уже умеет писать на диск). А у нас требование, чтобы все бэкапы и все-все лежали внутри инфраструктуры. А городить для этого отдельный S3, конечно, можно, но зачем?
Апгрейд мы делали вручную. Мы также подеплоили рядом кластер 9.6. В него смигрировали данные и все. И после этого выкинули 9.4 и у нас все стало хорошо.
Спасибо большое за доклад! Вы сказали, что у вас кластеров несколько. Но приложений по ходу гораздо больше, да?
Да.
По какому принципу новые кластера добавляются помимо staging?
Я понял вопрос. Мы все базы консолидировали в трех больших своих кластерах. У нас там есть testing, staging. И когда приложение работает уже на staging, мы можем понять, что что-то…. Допустим, процессинговые базы, про которые я говорил. И такое пускать в кластер не понятно зачем, потому что будет постоянная нагрузка на WALs, будет постоянно большой бэкап. Потому что если бэкап пришел, пока у тебя процессинговая база лежит, ты получаешь …. И, в принципе, по профилю нагрузки мы понимаем, что происходит внутри приложения. И после этого решаем дать отдельный кластер этим ребятам. И деплоим кластер, а что делать? Приложения в production все.
Здравствуйте! Спасибо за доклад! У меня немного двойной вопрос. Вы для половины части используете ванильные сборки Postgres?
Да.
Я сейчас тоже использую ванильные, но присматриваюсь к бесплатной части команды Postgres Professional, т. е. Postgres Pro Standard. И коснулась тема, что выбирать для резервного копирования. И них есть утилита pg_probackup, которая похожа на Barman, но у нее есть встроенная проверка бэкапов уже внутри. Почему вы не обратили внимание на эту утилиту?
Я даже не знаю, как вам правильно ответить. В принципе, мы как-то вообще не рассматривали Postgres Pro«шные штуки. Как-то так получилось. Мы привыкли, что мы сами с усами, строим свои велосипеды. Вроде бы у нас все работает.
Т. е. это выбор каждого: либо городить свой велосипед, либо пойти по проторенному пути.
Да.
Спасибо!
Спасибо большое!
