Google представила ToTTo — датасет для генерации текста по таблицам

Google опубликовала датасет для создания текста на основе таблиц. ToTTo (сокращение от «Table-To-Text») позволяет резюмировать текст с высокой точностью, утверждают в компании.
За последние несколько лет исследования в области генерации естественного языка, которая используется для таких задач, как резюмирование текста, достигли больших успехов. Однако нейросети до сих пор бывают склонны к «галлюцинациям» (созданию текста, который не соответствует источнику). Например, нейросеть, резюмирующая информацию о бельгийском футболисте Константе Вандене Стоке, может ошибочно назвать его американским фигуристом. Эта проблема мешает использованию нейросетей в приложениях, требующих высокой точности.
Определить точность резюмирования проще, если исходный контент структурирован — например, представлен в форме таблицы. Структурированные данные могут также проверить способность модели к рассуждениям и выводам. Однако, отмечают в Google, существующие крупные структурированные наборы данных часто зашумлены и плохо поддаются резюмированию, из-за чего для измерения «галлюцинаций» при разработке модели они бесполезны.
ToTTo представляет собой датасет для преобразования таблицы в текст, созданный с использованием нового процесса аннотации. ToTTo (сокращение от «Table-To-Text») состоит из более чем 120 тыс. обучающих примеров. Датасет и код опубликованы на GitHub.
Разработка процесса аннотации для получения естественных, но при этом точных предложений из табличных данных — серьезная проблема, указывают в Goole. Многие датасеты, такие как Wikibio и RotoWire, эвристически сочетают естественный текст с таблицами, что затрудняет понимание того, вызвана ли «галлюцинация» шумом данных или недостатками модели.
ToTTo создан с использованием новой стратегии. Для начала модель собирает данные из Википедии. Итоговое предложение конструируется с помощью контекста страницы в соответствии с общими для таблицы и контекста словами и гиперссылками, ссылающимися на табличные данные.
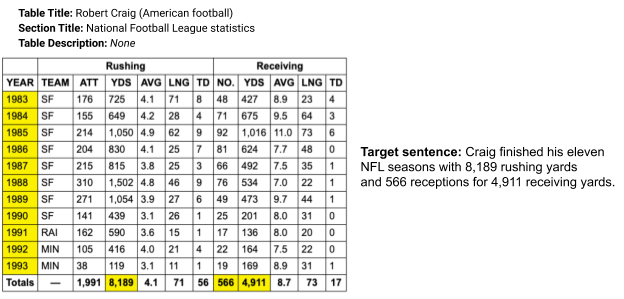
Итоговое предложение может содержать информацию, не поддерживаемую таблицей, однако модель выделяет ячейки в таблице, которые соответствуют предложение, и удаляет фразы, которых там нет. Модель также деконтекстуализирует предложение, чтобы оно было автономным (например, с правильным местоимением) и исправляет грамматику, где это необходимо.
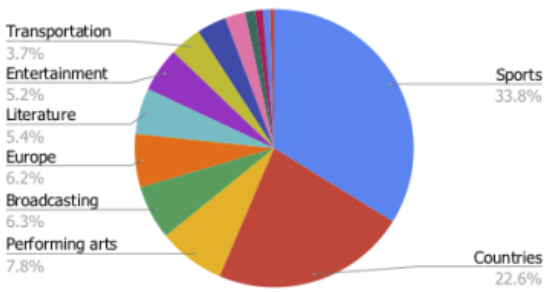
Тематический анализ ToTTo показал, что темы «Спорт» и «Страны» вместе составляют 56,4% датасета. На остальные 44% приходится более широкий набор тем, включая исполнительское искусство, транспорт и развлечения.