Глубокое обучение в гараже — Две сети

Это вторая статья из серии про определение смайла по выражению лица.
Глубокое обучение в гараже — Братство данных
Глубокое обучение в гараже — Две сети
Калибрация
Итак, с классификатором, разобрались, но вы наверняка уже заметили, что заоблачные 99% как-то не очень впечатляюще выглядят во время боевого теста на детекцию. Вот и я заметил. Дополнительно видно, что в последних двух примерах очень мелкий шаг движения окон, так в жизни работать не будет. В настоящем, реальном запуске шаг ожидается больше похожим на картинку для первой сети, а там хорошо видно неприятный факт: как бы хорошо сеть не искала лица, окна будут плохо выровнены к лицам. И уменьшение шага — явно не подходящее решение этой проблемы для продакшена.
Ну хорошо, подумал я. Мы нашли окна, но нашли не точные окна, а как бы смещенные. Как бы так их сместить «назад», чтобы лицо оказалось в центре? Естественно, автоматически. Ну, и раз уж я занялся сетями, то и «восстанавливать» окна я решил тоже сетью. Но как?
Первой мыслью пришло предсказывать сетью три числа: на сколько пикселей надо сместить по x и y и в какую константу раз увеличить (уменьшить) окно. Получается, регрессия. Но тут я сразу почувствовал, что что-то не так, аж три регрессии надо сделать! Да еще две из них дискретные. Да еще и ограничены шагом движения окна по оригинальному изображению, ведь нет смысла сдвигать окно далеко: там было другое окно! Последним гвоздем в гробу этой идеи оказались пара независимых статей, которые утверждали, что регрессия сильно хуже классификации решается современными сетевыми методами, и что она гораздо менее стабильна.
Так что, решено было свести задачу регрессии к задаче классификации, что оказалось более чем возможно, учитывая, что окно мне надо подергать совсем немного. Для этих целей, собрал датасет, в котором брал выделенные лица из оригинального датасета, смещал их в девять (включая никакую) разных сторон и увеличивал/уменьшал в пять разных коэффициентов (включая единицу). Итого, получил 45 классов.
Проницательный читатель тут должен ужаснуться: классы-то получились очень сильно связанными друг с другом! Результат такой классификации может вообще мало иметь отношения к реальности.
Для успокоения внутреннего математика я привел три довода:
- По сути, обучение сети — это просто поиск минимума функции потерь. Не обязательно его интерпретировать, как классификацию.
- Мы же ничего и не классифицируем, на самом-то деле, мы эмулируем регрессию! В совокупности с осознанием первого пункта, это позволяет не фокусироваться на формальной корректности.
- Это, черт возьми, работает!
Так как мы не классифицируем, а эмулируем регрессию, то нельзя просто взять лучший класс и считать, что он верный. Поэтому я беру распределение классов, которое выдает сеть для каждого окна, удаляю совсем уж маловероятные ((был бы базис, если бы классы были независимы, а так ну никак не базис же:).
Итого, я ввел в систему вторую сеть, калибрационную. Она выдавала распределение по классам, на основе которого я калибровал окна, надеясь, что лица будут выравниваться по центру окон.
Давайте попробуем обучить вот такую сеть:
def build_net12_cal(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 12, 12), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
network = conv(network, num_filters=16, filter_size=(3, 3), nolin=relu)
network = max_pool(network)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=128, nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=45, nolin=linear)
return network
И вот такой алгоритм расчета смещения:
def get_calibration():
classes = np.array([(dx1, dy1, ds1), (dx2, d2, ds2), ...], dtype=theano.config.floatX) # ds -- это изменение scale
min_cal_prob = 1.0 / len(classes)
cals = calibration_net(*frames) > min_cal_prob # вернет вероятности калибрационных классов для каждого окна, обрезанные по нижнему порогу
(dx, dy, ds) = (classes * cals.T).sum(axis=0) / cals.sum(axis=1) # первая сумма -- по всем окнам, вторая сумма -- по классам для каждого окна. Она была бы всегда равна единице, если бы не было отсечения строкой выше
return dx, dy, ds
И это работает!

Слева исходные окна от детекционной сети (маленькой), справа они же, но откалиброванные. Видно, что окна начинают группироваться в явные кластера. Дополнительно, это помогает более эффективно фильтровать дубликаты, так как окна, относящиеся к одному лицу, пересекаются большей площадью и становится легче понять, что одно из них надо отфильтровать. Так же это позволяет уменьшить число окон в продакшене за счет увеличения шага скольжения окна по изображению.
Заодно вот и результаты обучения маленькой калибрации: 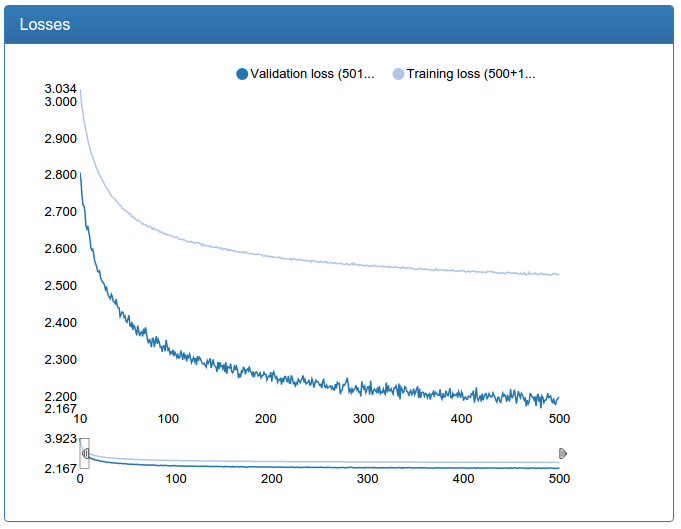

и большой калибрации: 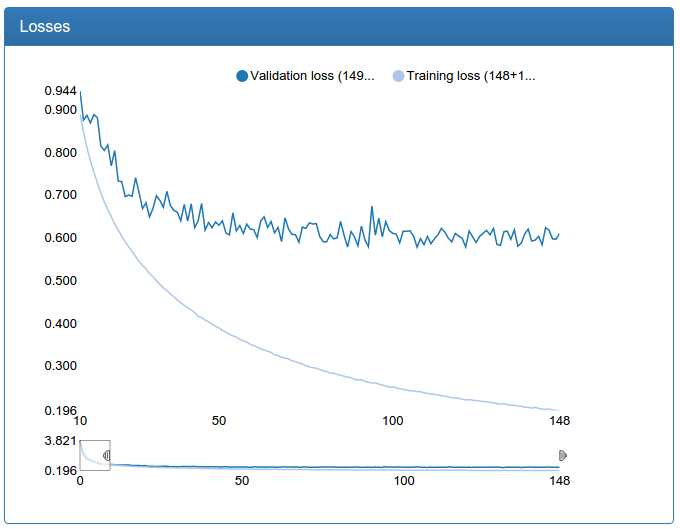
а вот и сама большая калибрационная сеть:
def build_net48_cal(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 48, 48), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu)
network = max_pool(network)
network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.3), num_units=256, nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.3), num_units=45, nolin=linear)
return network
К этим графикам стоит относиться скептически, ведь нам нужна не классификация, а регрессия. Но эмпирическое тестирование взглядом показывает, что калибрация, обученная таким образом, хорошо выполняет свою цель.
Еще замечу, что для калибрации исходный набор данных в 45 раз больше, чем для классификации (по 45 классов для каждого лица), но с другой стороны, его нельзя было дополнить вышеописанным образом просто по постановке задачи. Так что, колбасит, особенно большую сеть, изрядно.
Оптимизация II
Вернемся к детекции. Эксперименты показали, что маленькая сеть не дает нужного качества, так что нужно обязательно учить большую. Но проблема большой в том, что даже на мощной GPU очень долго классифицировать тысячи окон, которые получаются из одной фотографии. Такую систему было бы просто невозможно воплотить в жизнь. В текущем варианте есть большой потенциал для оптимизаций хитрыми трюками, но я решил, что они не достаточно масштабируемы и проблему надо решать качественно, а не хитро оптимизируя флопсы. И решение же вот оно, перед глазами! Маленькая сеть со входом 12×12, одной конволюцией, одним пулингом и классификатором сверху! Она работает очень быстро, особенно учитывая, что запустить классификацию на GPU можно параллельно для всех окон — получается почти мгновенно.
Ансамбль
One Ensemble to bring them all and in the darkness bind them.
Итак, было решено использовать не одну классификацию и одну калибрацию, а целый ансамбль сетей. Сначала будет идти слабая классификация, потом слабая же калибрация, потом фильтрация откалиброванных окон, которые предположительно указывают на одно лицо, а потом уже только на этих оставшихся окнах прогонять сильную классификацию и затем сильную калибрацию.
Позже, практика показала, что это все еще довольно медленно, так что я сделал ансамбль аж из трех уровней: в середине между этими двумя была вставлена «средняя» классификация, за которой шла «средняя» калибрация и потом фильтрация. В такой комбинации система работает достаточно быстро, что есть реальная возможность использовать ее в продакшене, если приложить некоторые инженерные усилия и реализовать некоторые трюки, просто, чтобы уменьшить флопсы и увеличить параллельность.
Итого получаем алгоритм:
- Находим все окна.
- Проверяем первой детекционной сетью.
- Те, что загорелись, калибруем первой калибровочной сетью.
- Фильтруем пересекающиеся окна.
- Проверяем второй детекционной сетью.
- Те, что загорелись, калибруем второй калибровочной сетью.
- Фильтруем пересекающиеся окна.
- Проверяем третьей детекционной сетью.
- Те, что загорелись, калибруем третьей калибровочной сетью.
- Фильтруем пересекающиеся окна.
Батчи окон
Если шаги со второго по седьмой делать для каждого окна отдельно, получается довольно долго: постоянные переключения с CPU на GPU, неполноценная утилизация параллелизма на видеокарте и кто знает что еще. Поэтому было решено сделать конвейеризованную логику, которая бы могла работать не только с отдельными окнами, а с батчами произвольного размера. Для этого было решено каждую стадию превратить в генератор, и между каждой стадией поставить код, который тоже работает как генератор, но не окон, а батчей и буферизирует результаты предыдущей стадии и при накоплении заранее заданного числа результатов (или конце) отдает собранный батч дальше.
Эта система неплохо (процентов на 30) ускорила обработку во время детекции.
Moar data!
Как выше я уже заметил в предыдущей статье, большая детекционная сеть учится со скрипом: постоянные резкие прыжки, да и болтает ее. И дело не в скорости обучения, как бы в первую очередь подумал любой, знакомый с обучением сетей! Дело в том, что все-таки мало данных. Проблема обозначена — можно искать решение! И оно тут же нашлось: датасет Labeled Faces in the Wild.
Объединенный датасет из FDDB, LFW и моих личных доливок стал почти втрое больше исходного. Что из этого получилось? Меньше слов, больше картинок!
Маленькая сеть заметно стабильней, быстрее сходится и результат лучше: 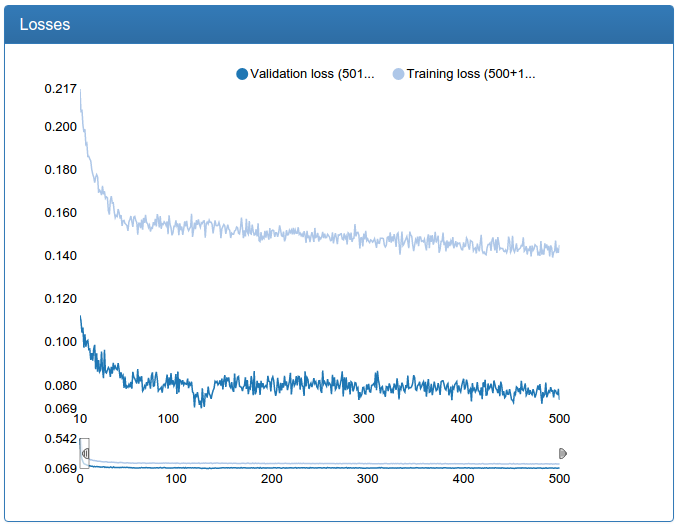
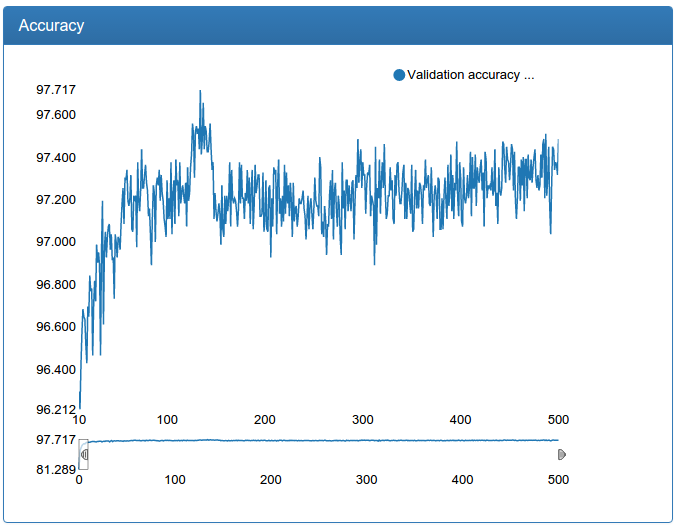

Большая сеть тоже заметно стабильней, пропали всплески, сходится быстрее, результат, внезапно, чуток хуже, но 0.17% кажутся мне допустимой погрешностью: 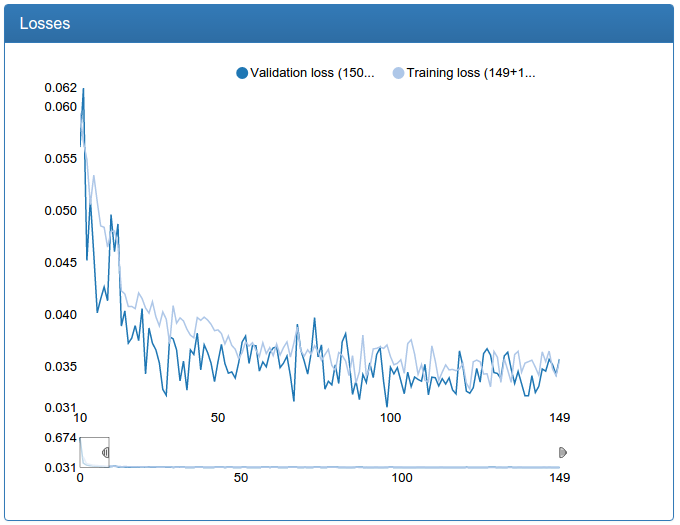
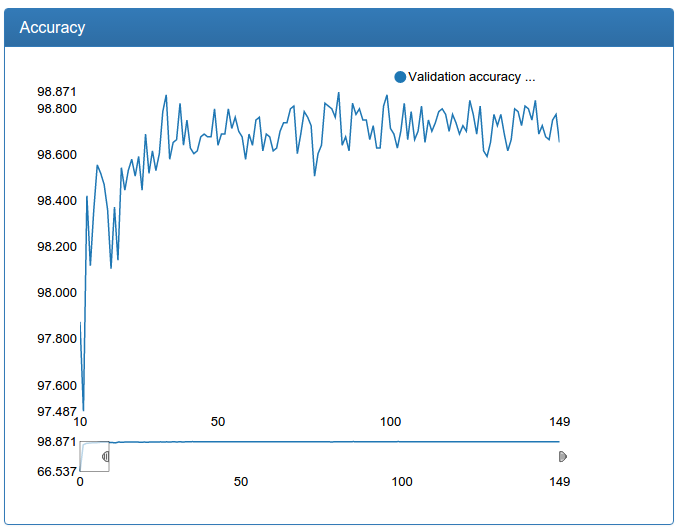

Дополнительно, такое увеличение объема данных позволило еще увеличить большую модель для детекции: 
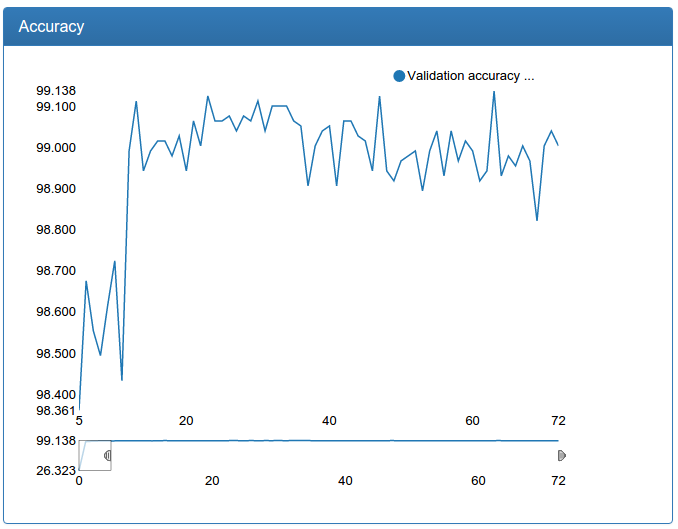

Видим, что модель еще быстрее сходится, к еще лучшему результату и очень стабильно.
Заодно я заново обучил и калибрационные сети на большем объеме данных.
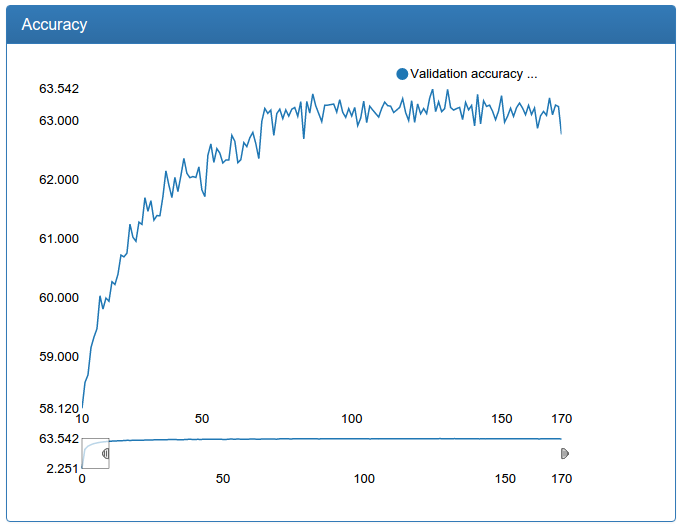
Маленькая калибрация: 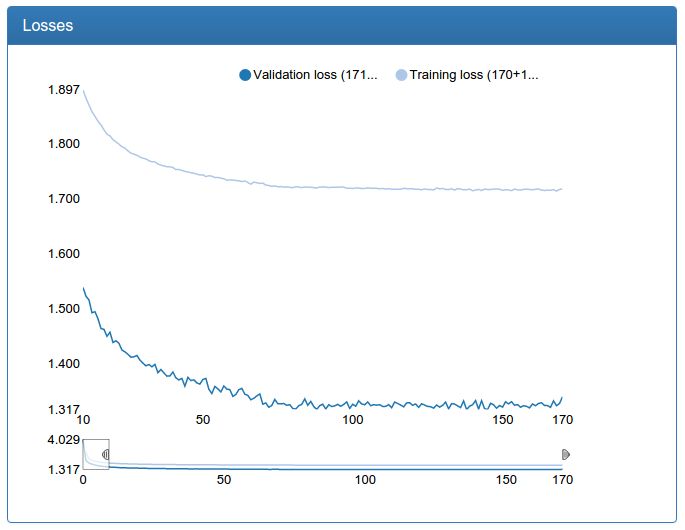
и большая калибрация: 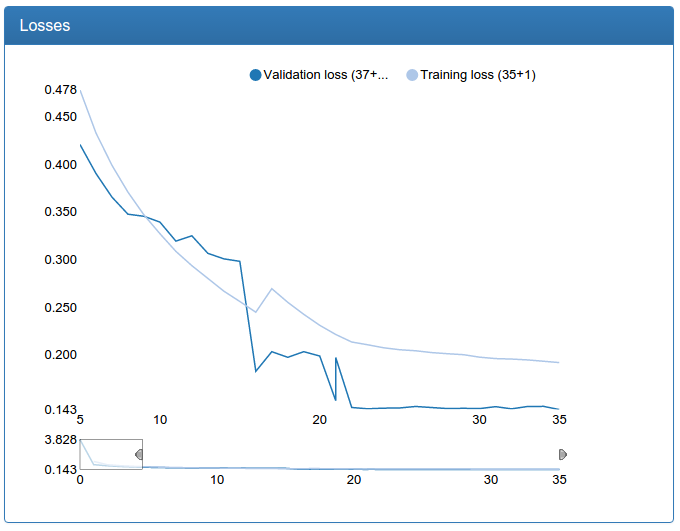
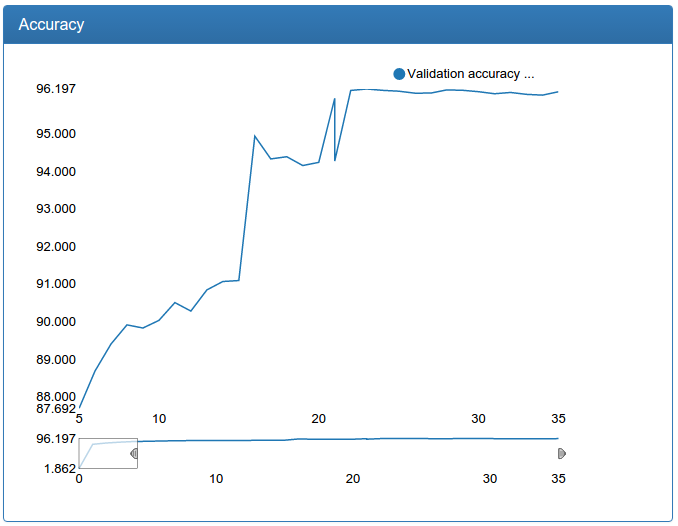
В отличии от детекционной сети тут видно прямо-таки драматическое улучшение. Это происходит потому, что исходная обучающая выборка не аугментируется и исходная сеть сильно страдает от недостатка данных, как страдала сеть для детекции до аугментации.
Детектирование готово
Картинка, иллюстрирующая весь пайплайн (классификация-1, калибрация-1, фильтрация, классификация-2, калибрация-2, фильтрация, классификация-3, калибрация-3, фильтрация, глобальная фильтрация, белым отмечены лица из тренировочного множества):

Успех!
Мультиразрешение
К этому моменту те из вас, кто следит за трендами, наверняка уже подумали, мол что за динозавр, использует техники из глубокой древности (4 года назад :), где же свежие крутые приемы? А вот они!
На просторах arxiv.org была подчерпнута интересная идея:, а давайте карты фичей в конволюционных слоях считать на разных разрешениях: банально сделать сети несколько входов: NxN, (N/2)x (N/2), (N/4)x (N/4), сколько угодно! И подавать один и тот же квадрат, только по-разному уменьшенный.
Потом же для финального классификатора все карты конкатенируются и он как бы может смотреть на разные разрешения.
Слева было, справа стало (померяно на той самой средней сети): 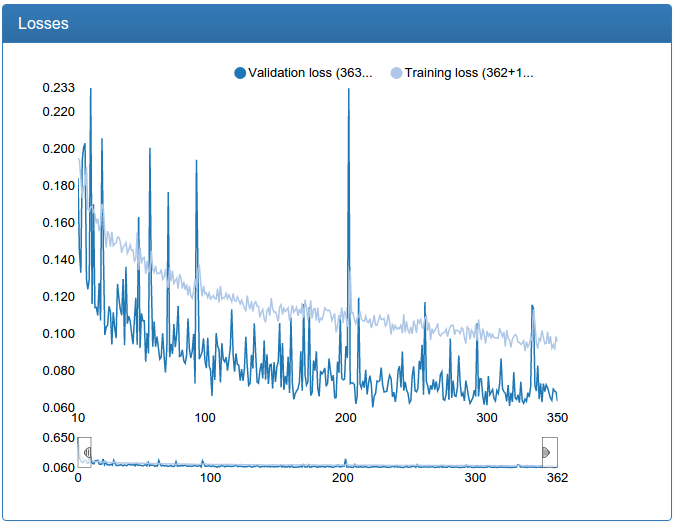
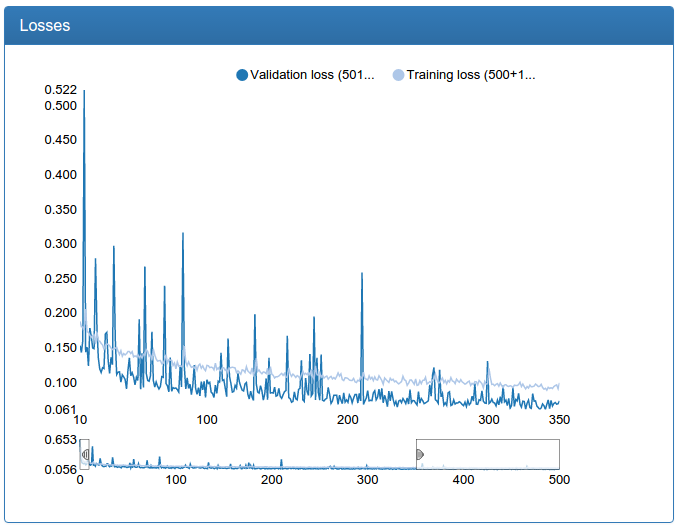
Видно, что в моем случае сеть с несколькими разрешениями сходится быстрее и чуть менее болтается. Тем не менее, идею я отбросил, как не работающую, так как маленькая и средняя сети не должны быть суперточными, а большую вместо мультиразрешений я просто потом увеличил с еще большим успехом.
Batch normalization
Batch normalization — это техника регуляризации сети. Идея в том, что каждый слой на вход принимает результат предыдущего слоя, в котором может быть практически любой тензор, координаты которого предположительно как-то распределены. А слою было бы очень удобно, если бы на вход ему подавали тензоры с координатами из фиксированного распределения, одного для всех слоев, тогда ему не нужно было бы учить преобразование инвариантное к параметрам распределения входных данных. Ну и окей, давайте между всеми слоями вставим некое вычисление, которое оптимальным образом нормализует выходы предыдущего слоя, что снижает давление на следующий слой и дает ему возможность делать свою работу лучше.
Мне эта техника неплохо помогла: она позволила снизить вероятность дропаута при сохранении того же качества модели. Снижение вероятности дропаута в свою очередь приводит к ускорению сходимости сети (и большему переобучению, если делать это без нормализации батчей). Собственно, буквально на всех графиках вы видите результат: сети достаточно быстро сходятся к 90% финального качества. До нормализации батчей падение ошибки было существенно более пологим (к сожалению результаты не сохранились, так как тогда еще не было DeepEvent).
Inceptron
Разумеется, я не смог устоять перед тем, чтобы поковыряться с современными архитектурами и попробовал натренировать на классификацию лиц Inceptron (не GoogLeNet, а гораздо меньшую сеть). К сожалению, в Theano эту модель правильно сделать нельзя: библиотека не поддерживает zero-padding произвольного размера, так что мне пришлось оторвать одну из веток Inception-модуля, а именно правую на этой картинке:
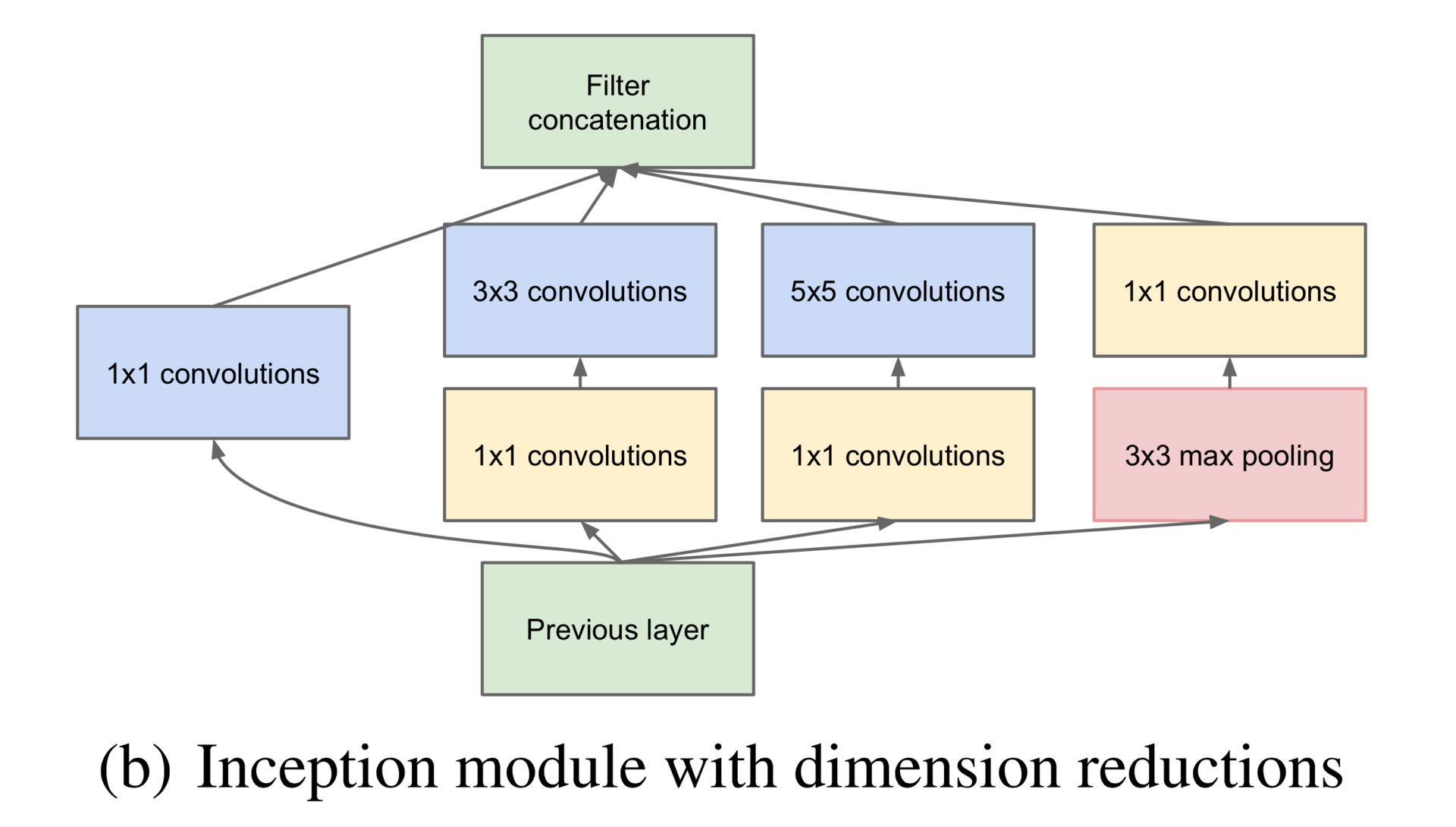
Дополнительно, у меня было лишь три inception-модуля друг на друге, а не семь, как в GoogLeNet, не было предварительных выходов, и не было обычных конволюционно-пулинговых слоев в начале.\
def build_net64_inceptron(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 64, 64), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
b1 = conv(network, num_filters=32, filter_size=(1, 1), nolin=relu)
b2 = conv(network, num_filters=48, filter_size=(1, 1), nolin=relu)
b2 = conv(b2, num_filters=64, filter_size=(3, 3), nolin=relu)
b3 = conv(network, num_filters=8, filter_size=(1, 1), nolin=relu)
b3 = conv(b3, num_filters=16, filter_size=(5, 5), nolin=relu)
network = lasagne.layers.ConcatLayer([b1, b2, b3], axis=1)
network = max_pool(network, pad=(1, 1))
b1 = conv(network, num_filters=64, filter_size=(1, 1), nolin=relu)
b2 = conv(network, num_filters=64, filter_size=(1, 1), nolin=relu)
b2 = conv(b2, num_filters=96, filter_size=(3, 3), nolin=relu)
b3 = conv(network, num_filters=16, filter_size=(1, 1), nolin=relu)
b3 = conv(b3, num_filters=48, filter_size=(5, 5), nolin=relu)
network = lasagne.layers.ConcatLayer([b1, b2, b3], axis=1)
network = max_pool(network, pad=(1, 1))
b1 = conv(network, num_filters=96, filter_size=(1, 1), nolin=relu)
b2 = conv(network, num_filters=48, filter_size=(1, 1), nolin=relu)
b2 = conv(b2, num_filters=104, filter_size=(3, 3), nolin=relu)
b3 = conv(network, num_filters=8, filter_size=(1, 1), nolin=relu)
b3 = conv(b3, num_filters=24, filter_size=(5, 5), nolin=relu)
network = lasagne.layers.ConcatLayer([b1, b2, b3], axis=1)
network = max_pool(network, pad=(1, 1))
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=256, nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=2, nolin=linear)
return network
И у меня даже получилось! 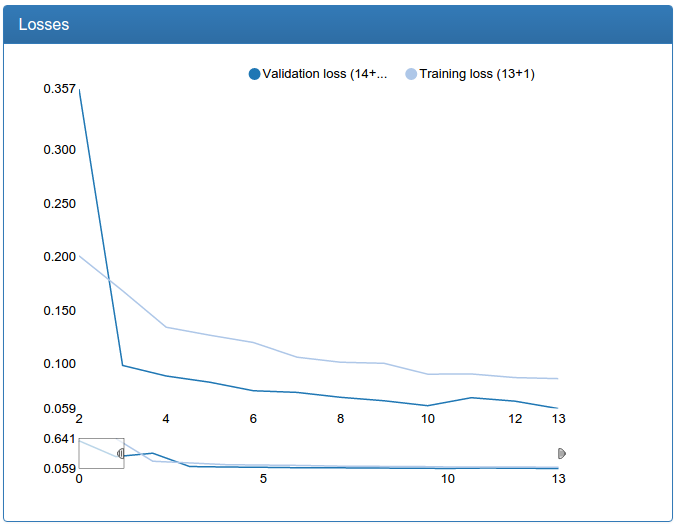

Результат на процент хуже обычной конволюционной сети, обученной мной ранее, но тоже достойный! Однако, когда я попробовал обучить такую же сеть, но из четырех inception-модулей, она стабильно разлеталась. У меня осталось ощущение, что эта архитектура (как минимум, с моими модификациями) очень капризная. К тому же, batch normalization, почему-то, стабильно превращала эту сеть в полный расколбас. Тут я подозреваю полукустарную реализацию batch normalization для Lasagne, но в общем все это заставило меня отложить Инцептрон до светлого будущего с Tensorflow.
Кстати, Tensorflow!
Конечно, я попробовал и его! Эту модную технологию я опробовал в тот же день, когда он вышел с большими надеждами и восхищением Гуглом, спасителем нашим! Но нет, надежд он не оправдал. Заявленного автоматического использования нескольких GPU нет и в помине: на разные карточки нужно руками помещать операции; работал он только с последней кудой, которую мне тогда было нельзя ставить на сервер, имел захардкоженную версию libc и не пускался на другом сервере, да еще и собирался вручную с помощью blaze, который не работает в докер-контейнерах. Короче, одни разочарования, хотя сама модель работы с ним очень даже неплоха!
Tensorboard тоже оказался разочарованием. Не хочу вдаваться в детали, но мне все не нравилось и я занялся разработкой своего мониторинга под названием DeepEvent, скриншоты с которого вы видели в статье.
В следующей серии:
Смайлы, готовая система, результаты и, наконец-то уже, симпатичные девушки!
