[Из песочницы] Версионирование базы данных на лету
Здравствуйте, меня зовут Евгений, и я веб разработчик. Несколько лет назад мне перепала функция DBA (Database Administrator), я получил по этому поводу несколько сертификатов и решал соответствующие задачи. Я давно хотел описать задачу версионирования базы данных, но мне казалось, что для этого должны быть какие-то беспроигрышные варианты, которые хорошо знают умелые дяди, а я просто чего-то недопонимаю. Вчерашнее собеседование и последующий поиск по тематическим ресурсам показал, что это не так, и задача действительно сложна, актуальна и не решается однозначно. Разберём её по пунктам.
Мы используем контроль версий только для DDL (Data Definition Language) запросов. Сами данные нас не интересуют. Почему? Рассмотрим два крайних случая.
- Данных мало (скажем, менее 50 мегабайт). В этом случае, мы можем просто периодически делать полный дамп базы и смело складывать его в репозиторий.
- Данных много (больше гигабайта). В этом случае версионирование нам мало поможет, всё равно разобраться в этом будет довольно проблематично. Целесообразно в данном случае использовать стандартную схему с бекапами и архив логом, которая позволяет нам получить целостную версию базы на любой момент во времени.
Если вы работаете со сложной базой данных, то таблицы, как ни странно, в ней наименее интересны (хотя тоже должны быть под контролем версий). Гораздо сложнее приходится с бизнес логикой, которая содержится в триггерах, представлениях, пакетах и процедурах, и тому подобных объектах. К примеру, в одной из баз, с которыми я работал, были пакеты размером до полутора мегабайт. В эти пакеты постоянно вносятся правки, и жизненно необходимо знать, кто внёс правки, когда, желательно знать, зачем, и как бы нам это откатить до любого нужного состояния.
Представим себе идеальный мир, в котором у нас есть чёткое ТЗ, которое не меняется до завершения проекта. Релиз, после которого мы забываем о том, что делали, и получаем регулярную зарплату за красивые глаза. Идеальный код, который мы писали сразу с учётом всех нюансов, который работает без ошибок и не требует сопровождения. Отсутствие доработок, срочных багфиксов, механизмов интеграции, возможность работать на тестовой базе и тестовых выборках, наличие повсеместных юнит тестов, которые говорят, что всё безупречно.
В этом случае, нам более чем достаточно использовать систему контроля версий в качестве первичного источника информации о состоянии БД, и выкатывать из неё изменения на базу. Есть единый репозиторий, есть совместная работа над кодом базы — всё красиво и прозрачно. Есть несколько продуктов, которые вроде как неплохо реализуют данный функционал.

Теперь открываем глаза и смотрим вокруг. В большинстве случаев, проект реализуется по схеме, которую я бы назвал СВВ (сделал, выкатил, выкинул). Огромный процент завершённых проектов не может продаться и закрывается без всяких перспектив на будущее. Оставшиеся счастливчики переживают сотни итераций, после которых от изначального ТЗ остаётся в лучшем случае название. В этой реальности нас в первую очередь волнует не скорость работы продукта, его требования и качество. Нас волнует скорость разработки, поскольку, кроме очевидных причин, от неё зависит самая большая часть бюджета проекта — стоимость работы в часах разработки.
Да, это неправильно. Мир жесток, несправедлив, динамичен, и требует мгновенной реакции, даже если при этом страдает качество. Все разработчики стремятся в душе к идеальному коду, но большинство принимает условия сделки с дьяволом, и ищет допустимый компромисс качества и скорости. Мы стараемся делать, как лучше, но учимся не краснеть, если вместо срока в полгода и идеального продукта мы за две недели сделали нестабильное и местами некрасивое решение. Более того, в какой-то момент приходит понимание, что «последний баг» никогда не будет найден, и всё, что мы можем — просто в какой-то момент прекратить его искать и сделать релиз. Доводить решение до идеала — удел простейших приложений и консольных скриптов — да и то часто не удаётся учесть какие-то нетривиальные моменты. Когда же мы говорим о крупных проектах, то пример Oracle, Microsoft и Apple нам показывает, что идеального кода не бывает. Как пример — классический ответ DBA на вопрос о том, что в новом релизе Oracle Database — «убрали 30% старых багов, добавили 40% новых».
Во что же это выливается, если мы говорим о БД? Обычно это так:
- Доступ к базе есть у большого количества разработчиков
- Часто есть необходимость откатить тот или иной объект
- Никто и никогда не признается, что это именно он сломал объект
- Модификации часто носят непонятный характер
Далее, если к DBA приходит разработчик и просит вернуть предыдущую версию его объекта, то DBA может это сделать в трёх случаях (на примере Oracle):
- Если предыдущая версия всё ещё сохранилась в UNDO
- Если объект был просто удалён и сохранился в мусорной корзине (RECYCLEBIN)
- Если он может развернуть полный бекап базы на требуемую дату
Самый реальный вариант — третий. Но он осложняется тем, что зачастую неизвестно, на какую дату нужно выполнить восстановление, и восстановление базы размером, скажем, в 10 террабайт — это довольно долгая и ресурсоёмкая операция. Так что обычно DBA просто разводит руками, разработчик хмуро выпивает кофе и идёт писать своё объект с нуля.
Что мы можем сделать, чтобы упростить жизнь разработчикам? Я вижу единственный вариант — версионировать базу по факту уже совершённых изменений. Естественно, это не даёт никакой возможности предупредить возможные ошибки — зато даст способ в большом проценте случаев вернуть к жизни нужный объект и всю систему.
Первое простое решение «в лоб» — это просто периодически выгружать всю базу. Но выгрузка базы занимает длительное время, и тогда мы не будем знать, кто, когда и что менял. Так что явно требуется что-то сложнее. А именно — нам нужно выгружать только изменённые DDL объекты. Для этого можно использовать два подхода — использовать Audit, или создать системный триггер. Я воспользовался вторым способом. Тогда последовательность получается такая:
- Создаём таблицу, в которой будут хранятся данные о DDL запросах
- Создаём системный триггер, который будет писать в эту таблицу
При этом для каждого действия мы можем получить довольно подробную информацию, включая полный текст запроса, схему, имя и тип объекта, IP адрес пользователя, сетевое имя его машины, имя пользователя, тип и дату изменений. Как правило, этого хватает, чтобы потом найти разработчика и выдать медаль.
Далее нам хочется иметь репозиторий, в котором в интуитивном виде будет представлена структура базы, чтобы иметь возможность сравнивать различные версии объекта. Для этого, при каждом изменении базы требуется выгрузить изменённые объекты и закоммитить в базу. Ничего сложного! Создаём Git репозиторий, сначала делаем туда полную выгрузку, затем создаём сервис, который мониторит нашу таблицу изменений, и в случае появления новых записей выгружает изменившиеся объекты.
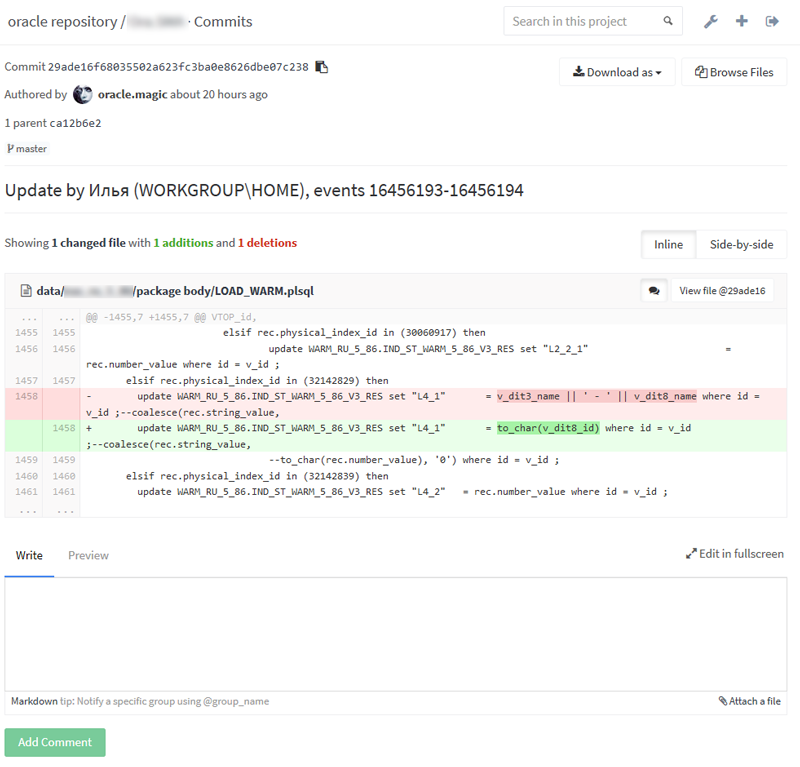
Side by side сравнение
Список объектов в схеме
История изменений конкретного объекта
То же самое на github
То есть, у нас есть рабочий инструмент, при помощи которого можно найти источник любых изменений в базе и при необходимости их откатить. В моём случае, наиболее крупный Git репозиторий в Gitlab (свой инстанс на отдельной машине) занимает несколько сотен мегабайт, в нём около сотни тысяч коммитов, и при этом он достаточно шустро работает. До переезда на Gitlab этот же репозиторий отлично жил на github, а потом на bitbucket.
Данные о каких объектах мы после этого имеем:
- Таблицы
- представления
- материализованные представления
- триггеры
- последовательности
- пользователи (с хешами паролей, которые можно использовать для восстановления старого пароля)
- пакеты, функции, процедуры
- database links (тоже с хешами паролей)
- гранты
- констрейны с их состоянием
- синонимы
Так же можно модифицировать программу под задачу обновления устаревшей базы данных — выгружаем старую версию, поверх неё выгружаем новую, исправляем разницу в полуавтоматическом режиме.
- Некоторые изменения могут произойти слишком быстро, и сервис не успеет выгрузить промежуточные результаты —, но вряд ли они нам актуальны, да и можно их найти в таблице изменений.
- Некоторые изменения могут затрагивать сразу несколько объектов — например, удаление схемы или DROP CASCADE —, но это тоже можно корректно отработать при желании, вопрос только в реализации.
- Из-за того, что в репозитории хранятся хеши паролей, его нельзя выдавать напрямую разработчикам.
В качестве рекомендации так же добавлю, что лучше периодически выгружать текущую версию поверх того, что есть в репозитории — на случай каких-то изменений, которые не смогла покрыть логика алгоритма выгрузки.
Ссылка на мой алгоритм для PHP и руководство по установке есть в конце статьи, но я искренне рекомендую вам пользоваться им только для справки — он был написан давно и очень криво левой рукой во время выполнения других задач. Единственный плюс — в том, что, как ни странно, он работает.
Искренне желаю вам, чтобы вам не пришлось работать с таким workflow. И надеюсь, что эта публикация вам поможет, если ваш мир всё же далёк от идеального.
А вы версионируете свою базу данных? Правильным образом, или по факту? Может быть, есть реализации под другие СУБД — MySQL, Postgres? Или есть какой-то фундаментально другой хороший подход, который я проглядел?
- Большое обсуждение того, как версионировать базу на stackoverflow
- Реализация правильного подхода от Liquibase
- Аналогичная моей старая реализация на Java + SVN
- Веб сайт моего инструмента с инструкциями по установке
- Репозиторий кода моего инструмента на github
- Взять меня на работу можно тут
