Гибкое управление Data Science-продуктами
Асхат Уразбаев был программистом, руководил IT-командами, но заинтересовался Agile и основал компанию ScrumTrek, которая помогает компаниям внедрять гибкие подходы.
Однажды в ScrumTrek за помощью обратилась компания с data science-продуктами. Казалось бы, работа понятна и схема отработана: рассказать, что такое Agile, собрать бэклог, запустить спринт — 3 дня работы. 3, не 3, но через 3 месяца точно что-то начнет получаться, а через 3 года вообще все будет отлично.
Оказалось, не так все просто.

87% data science-проектов никогда не попадают в прод. То есть не просто не укладываются в бюджеты и сроки, а вообще не доходят до использования в продакшене. Почему так происходит и как все-таки можно внедрить гибкие методологии в data science, Асхат Уразбаев рассказал на TeamLead Conf, а мы сделали из этого статью.
Существует примерно два подхода к построению процессов в data science-проектах.
CRISP-DMсоздан в 90-х годах и вообще не удобен для внедрения. Это просто Work Breakdown Structure (WBS) — список работ, которые примерно нужно сделать. Он слишком общий, поэтому на самом деле не подходит ни одному проекту.
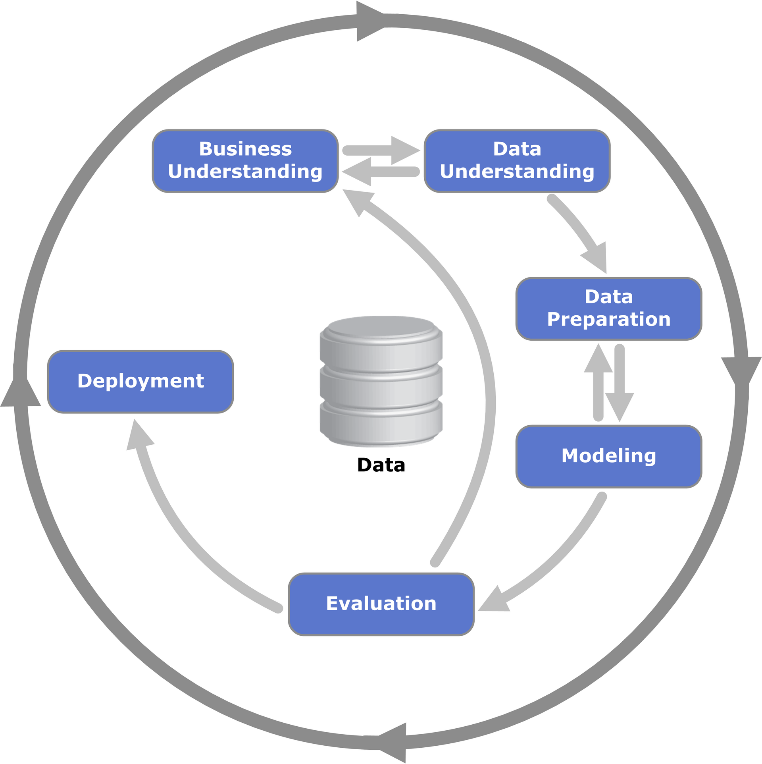
MS TDSP — Microsoft Team Data Science Process — вроде бы коллаборативный подход, построенный вокруг Scrum, но реальные проблемы проектов он, к сожалению, тоже не решает.
Рассмотрим типовые проблемы в data science и поймем, что с ними делать.
Бизнес и DS не понимают друг друга
Разберем проблему непонимания на примере разработки чат-ботов для ритейла. В магазинах торговой сети иногда случаются проблемы, например, продавщица подралась с посетителем, или охранник поругался с продавщицей. В таких ситуациях сразу начинают звонить в юридический отдел. Но юристы отвечают в рабочее время по Москве, а магазины по всей России.
Логичная идея: сделать чат-бот, которому люди будут писать, и умный чат-бот будет отвечать. Команда data science говорит, что надо бы обучить модель, а юристы отвечают, что они уже все подготовили: «Мы написали инструкции в Word, пусть чат-бот их прочитает, выучит и сможет отвечать пользователям». Но data science так не работает, нужны диалоги для обучения модели — заказчик разочарован. А договор уже подписан, деньги на проект выделены и надо что-то делать. Что-то и делают, в итоге результат всех не устраивает.

Почему так получается?
Для заказчиков исполнители выглядят так:
- непрозрачно;
- непонятно;
- закапываются;
- штурмовщина;
- индивидуализм.
В какой-то момент обсуждения проекта data scientist переключается на другой язык, и его вообще перестают понимать. Это может произойти прямо в середине встречи: идет обычная бизнес-встреча, а потом раз и пошли модельки, глаза заказчиков стекленеют. Но они даже не говорят об этом, потому что боятся показаться неумными.
В свою очередь исполнители думают, что у заказчиков:
- завышенные ожидания;
- работа строго по ТЗ;
- нет ориентации на цели;
- нет компетенций в data science.
Специалисты по data science говорят на своем языке и думают о заказчиках: «Какие странные люди, мы тут занимаемся высокими технологиями, а они внизу какой-то ерундой».
Как лечить?
Первое, что можно попробовать сделать — перестать передавать проекты data science-команде до горизонта.
Приведу еще один пример. У нас была задача в одной нефтяной компании: грузовики, в том числе бензовозы ездят по России, водители иногда курят в машине, подвозят посторонних людей и другим образом нарушают правила. Это кейсы, с которыми нужно уметь работать. В грузовиках есть камеры, но кто их отсматривает? Представляете, сколько это часов записи. Это прекрасная проблема для искусственного интеллекта, он же может проанализировать записи с камер.
Технически к задаче подошли следующим образом: поставили задачу людям, которые в этом не очень хорошо разбираются. Команда ушла в себя на 9 месяцев, создала proof of concept, который умеет закрывать почти все подобные кейсы. Но для внедрения такое решение оказалось тяжелым, потому что не влезает в кабину грузовика и потребляет слишком много энергии.
Нужна была совместная с представителями бизнеса работа, чтобы найти реализуемое решение. То есть единая команда, у которой:
- общие цели;
- единый план;
- совместные мероприятия;
- один владелец продукта;
- совместное принятие решений.
Постановка бизнес-задачи
К сожалению, задачи по data science часто ставят люди, которые не разбираются в искусственном интеллекте и машинном обучении. Получается как-то так.

Представьте, что человек, который никогда не видел реальных продуктов, никогда не пользовался компьютером и знает о разработке ПО из журналов, писал бы требования для инженера. И это только часть проблемы.
Вторая часть проблемы: «Всем норм». Почему-то data scientist’ы, в отличие от разработчиков ПО, не спорят с такими постановками. Они всегда могут сделать крутую модель.
Заказчик говорит, что читал в журнале про TensorFlow и хочет его внедрить. Он не знает, зачем и почему, но это прикольно. Data scientist с удовольствием берется запускать TensorFlow для чего-нибудь, потому что ему тоже прикольно. В результате все это не внедряется, не запускается, пользы не приносит.
Чтобы не применять data science просто «чтобы было» нужна профессиональная роль — product owner или product manager.
AI Product Owner
Data science должен перестать быть сервисом для людей, которые не понимают, как поставить задачу data science. Должен быть человек, который является мостом между бизнесом и data science, у которого есть понимание возможностей и ограничений data science. Product owner сможет построить ценный продукт на стыке возможностей и потребностей. Но для этого у него должны быть полномочия в принятии решений.
Без product owner могут получиться классные пилоты, для промышленного внедрения которых нужно решить миллион вопросов: кто будет поддерживать и развивать, куда денутся люди, которые раньше следили за камерами, как, возможно, нужно менять регламенты, кто будет отвечать за инциденты и т.д.
Часто, чтобы внедрить data science-решение, нужно поменять структуру самой организации — создать новые отделы, а некоторые старые убрать. Product owner — это тот человек, который должен уметь решать такие задачи и у него должны быть соответствующие полномочия.
Говорят, что иногда data scientist должен прямо сказать, что данные плохие и хорошо обучить на них модель нельзя. Это правильно, но этого недостаточно. За этим должен идти следующий шаг — что-то придумать, сделать, чтобы в следующий раз были подходящие данные. Задача единой команды и product owner или product manager собрать или научиться собирать нужные данные. Это требует определенной работы, и data science-специалист может дать рекомендации, что для этого нужно. Но все равно это пока рекомендации, которые нужно довести до результата.
У product owner должно быть достаточно мотивации и понимания, что он действительно отвечает за результат. Когда у него есть ответственность за результат с точки зрения бизнеса и потребителя, а не за сервис, тогда появляются реальные, полезные результаты.
Product Brief
Чтобы перейти к практике, нужно правильную поставить задачу. Мы для себя придумали Product Brief:
- Бизнес-проблема. Описание ценности для бизнеса.
- Контекст. Описание контекста, в котором находится бизнес-проблема. Может быть в формате пользовательских сценариев, карты потока ценности, описания бизнес-процесса и т.д.
- Критерии успеха. Метрики и критерии, по которым можно судить об успешном достижении результата.
- Стейкхолдеры. Список заинтересованных лиц, которые будут участвовать в постановке задачи и принимать результаты.
- Входные данные. Описание известных или доступных данных на момент создания заявки.
- Ожидаемые результаты и их формат.
- Внедрение результата. В какой форме результат будет доводиться до промышленной эксплуатации.
- Сроки. Ожидания по срокам реализации.
- Риски. Почему мы можем не успеть к срокам, что может помешать.
Это примерный набор вопросов, которые мы задаем заказчику на старте проекта.
Самым трудоемким в этом Product Brief является формулирование критериев успеха. На старте не всегда понятно, чего же хотят добиться заказчики, и ответ на этот вопрос может занять до нескольких недель. Поэтому после первого брифа мы поняли, что для того, чтобы сформулировать критерии успеха, нужно сразу смотреть данные. Product manager или product owner должен подключить специалистов по data science уже на этом этапе.
Теперь мы тратим максимум две встречи и неделю-полторы на то, чтобы составить Product Brief. Мы формулируем в бэклог задачи в примерно таком виде: «Исследовать данные для того, чтобы понять то-то и то-то», и они уже помещаются на доску задач. Мы не тратим на это слишком много времени, не требуем строгой постановки. Это просто что-то, о чем нужно подумать на старте, а заполнять во время выполнения проекта. Когда мы понимаем, что проект уже чего-то достиг, мы способны сформулировать критерии успеха.
Гипотеза
Далее формулируем гипотезу — некоторое представление о том, чего мы хотим на самом деле добиться:
- Цель и целевая метрика.
- Прокси-метрика.
Они написаны на языке бизнеса, и это довольно сложно, потому что data scientist’ы не любят язык бизнеса. Они любят много говорить о технологиях, но мало думают о том, что требуется бизнесу и клиенту. Нужно специальным образом подводить человека к тому, чтобы он формулировал гипотезы с точки зрения потребностей бизнеса. Спрашивать, зачем нужна эта модель, какую ценность несет, и вытаскивать конкретную гипотезу. Как только мы несколько раз проделали это упражнение, выяснилось, что 30–40% гипотез никому не нужны.
Нет никакого смысла делать то, что не нужно заказчику, только потому что это интересно data scientist’ам. С другой стороны, нужно разграничивать, какие из ограничений действительно заданы жестко, а какие не следуют из технологических характеристик и являются скорее рекомендациями.
Когда есть набор гипотез, с которыми работает команда, процесс намного прозрачнее для бизнеса. Ему становится понятно, зачем выполняется каждая из задач, к чему команда стремится в итоге.
Бизнес-анализ
Как правило, data science-проекты не очень зрелые, бизнес-анализом по сути никто не занимается. Как задачу поставили, так ее и решают, не учитывая бизнес-контекст. На самом деле в data science-проекты полезно потихонечку добавлять:
- Customer Journey Map;
- Value Stream Map;
- Service Blue Print;
- Sales Funnel.
Понимание бизнес-контекста помогает понять, какую задачу мы решаем на самом деле.
Пример: крупный ритейл измеряет показатель NPS — насколько пользователи преданы компании. Data science-команда получила задачу установить, есть ли связь между NPS и доходом компании.
Нет ничего удивительного в том, что дать четкий ответ data science не смогли, потому что данные зашумлены. Эта задача, как корреляция всего со всем, — конечно, данные будут зашумлены. Но что, если попытаться понять, что на самом деле происходит внутри организации? Разобраться, как ведет себя пользователь? Как работает условная физика того, что человек делает, когда заходит в магазин?
Гипотезу «При росте NPS прибыль компании увеличивается» можно разбить на подгипотезы, которые уже можно проверить и получить полезную информацию, например:
- При росте NPS в городе растет средний чек.
- При росте NPS в городе растет среднее количество товаров в чеке.
- При большем NPS лояльные покупатели чаще ходят в магазины.
- При большем NPS лояльные покупатели больше тратят в наших магазинах (в среднем за месяц).
Проверив гипотезы такого типа, уже можно делать ценные выводы. Например, оказалось, что лояльные клиенты покупают дорогие товары определенной категории. Это понятный вывод, на основании которого можно строить какую-то дальнейшую стратегию.
Подробнее о работе с гипотезами рекомендую посмотреть в выступлении Адама Елдарова из YouDo на встрече сообщества LeanDS_RU. А мы переходим к следующей типовой проблеме в data science-проектах.
Члены команды не умеют взаимодействовать
Data scientist — общий термин, и, конечно, они бывают разные. Но в среднем data scientist’ы друг с другом не коллаборируют, как ни странно. Первое, что вы ожидаете от специалиста по data science — что он посоветуется с другим специалистом. Но чаще всего это не так: каждый берет свою задачу и тащит ее до какого-то промежуточного результата, а потом забрасывает через забор, например, к программистам. При этом коллаборации по дороге не происходит — ни у data scientist’ов друг с другом, ни между data scientist’ами и программистами. Это нужно иметь в виду и работать с этим.
Пайплайн (value stream)
Работая с data science-проектами, важно понимать отличие пайплайна от software engineering-проектов.

Пайплайн data science длинный, нужно проделать достаточно много работы, которая занимает существенное время:
- Провести бизнес-анализ.
- Подготовить данные.
- Моделирование.
- Оценить результаты.
- Задеплоить, причем это более сложный процесс, чем можно подумать.
- На A/B тестировании проверить, приносит ли внедрение новой модели пользу.
- И это еще не все, потом нужна поддержка.
Scrum в data science-проекте
Внедрение Scrum в проект с таким пайплайном спотыкается о серьезные проблемы.
Пайплайн очень длинный. Из-за этого запланировать и сделать что-то до конца внутри короткого двухнедельного спринта просто не успеть. Это приводит к тому, что каждый раз часть задач переходит на следующий спринт, а затем еще на следующий и т.д.
В отличие от Scrum в software engineering, где есть постоянный инкремент для демонстрации результатов, в data science нет материала сбора обратной связи. В разработке есть демо, можно показать продукт заинтересованным лицам, собрать обратную связи и работать с ней на следующих итерациях. В data science есть просто модель, например, рекомендательная. За спринт удалось повысить её точность с 60% до 65%. Подходит ли это для демо и что можно сделать с обратной связью по такому результату? Ничего.
Требования на спринт меняются. В data science есть итеративность между фазами подготовки данных (Data preparation) и моделирования (Modeling), где все может поменяться.
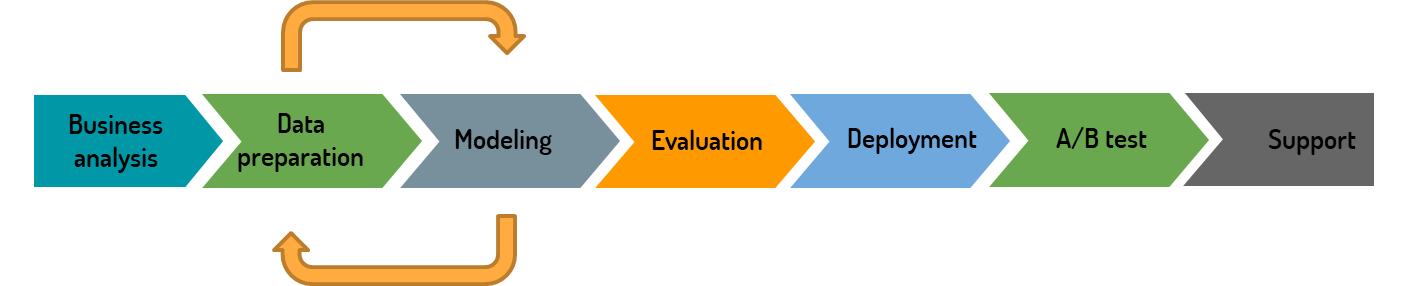
Например, появилась новая гипотеза, подготовили данные (это может случиться на второй день спринта), проверили гипотезу и всё, что запланировано до конца спринта, уже не имеет никакой ценности. Всё нужно переделывать, потому что концепция поменялась.
Поэтому классический Scrum не работает, от него надо отходить.
Когда не работает Scrum, как и в любой непонятной ситуации, мы дружно внедряем Канбан.
Канбан в data science проекте
На каком принципе его строить? Ближайший аналог из сферы software engineering — это Lean Startup. Lean Startup подразумевает, что есть гипотезы о том, что принесет ценность продукту. Процент гипотез, которые принесут пользу (big discovery) очень небольшой — максимум 10%.
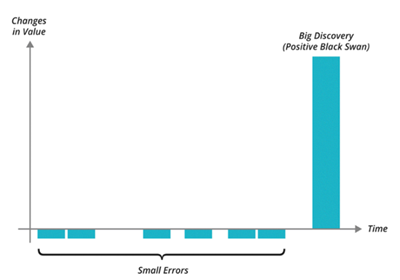
На старте мы, естественно, не знаем, какие именно гипотезы принесут пользу, а просто пробуем, пока что-то не получится. Для этого используется HADI-цикл.
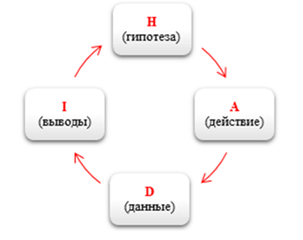
Примерно похожий процесс можно выстраивать в data science-проектах. Нормально, если 80% гипотез умрет. Мы просто постепенно двигаемся.
Для этого нужен Process Framework, в котором есть:
- роли и ответственности;
- артефакты;
- мероприятия;
- work Items (рабочие элементы).
Примерно так устроен Канбан:
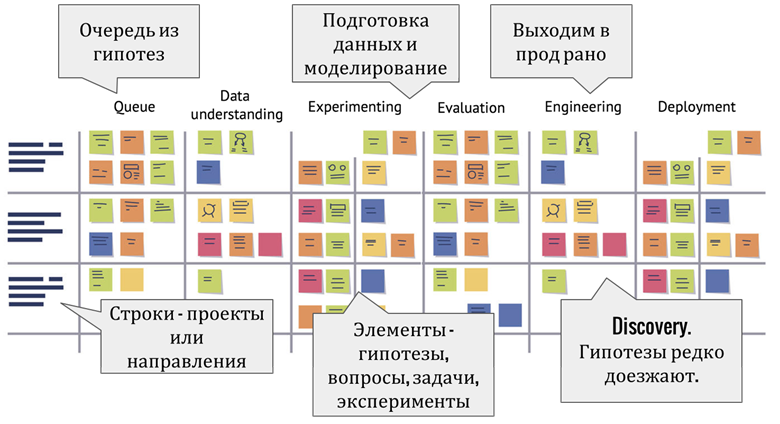
Заметьте, что моделирование и data preparation объединено в одну фазу, потому что иначе это очень неудобно по Канбану двигать: по сути работа с данными и эксперименты происходят в один и тот же момент.
Основные элементы схемы:
- Строки — проекты или направления. Например, часть работ может быть связана с автоматизацией пайплайна, а не с самими экспериментами.
- Элементы — гипотезы или группы вопросов. Если гипотезу с понятной метрикой еще не удается сформулировать, можно просто объединить несколько вопросов, чтобы data scientist попробовал найти ответы на них в данных.
- Очередь из приоритезированных гипотез. Расставить приоритет — задача product owner.
- Experimenting: подготовка данных и моделирование.
- Discovery. Далеко не все гипотезы доберутся до этапа реализации, поэтому концовка получается более-менее пустая.
В этом процессе важно постараться выйти в прод рано для того, чтобы все протестировать. Это сложный момент, потому что data scientist’ы часто хотят придерживаться waterfall-стиля и считают, что нужно сначала сделать крутую модель, а потом дотащить ее до прода. Этот подход не очень хорошо работает, потому что по дороге в прод что-нибудь оказывается не так: нет данных, нельзя протащить их на прод, недостаточно мощности на серверах и т.д. Если это выясняется в поздней стадии жизненного цикла, то приходится слишком многое переделывать.
Ограничивать working progress особенно важно в части «Data Understanding».
Цели этапа Data Understanding:
- Первичный анализ данных и его осознание командой.
- Верификация и валидация полученных данных с заказчиком.
- Уточнение постановки задачи при необходимости.
- Анализ достаточности данных.
В результате за 1–3 дня должны быть валидные данные и первые выводы по проекту.
Примеры бизнес-метрик, которые анализируются на этапе Data Understanding: размер данных, распределение, средние значения, корреляции, аномалии данных.
Проблема валидации начальных данных вытекает из все той же не построенной коммуникации. Data scientist’ы получая данные, не уточняют, насколько они могут быть некорректны, а сразу начинают с ними что-то делать. Заказчик, в свою очередь, по умолчанию думает, что команда убедится, что с данными все в порядке, или спросит.
Если при работе с данными появляются явные аномалии, то проблема вскрывается быстро. Но на практике лучше явным образом искать, что с данными не так, и уделять ограниченное время, например, 1–3 дня на первичную работу с данными. По сути на этом этапе команда data science занимается верификацией данных, чисткой, заполнением пропусков и т.п. и уточняет у постановщиков, соответствуют ли предельные характеристики реальному положению вещей.
С первыми компаниями мы работали так: ставили дедлайн команде, когда работа должна быть сделана; ребята работали с данными, ближе к концу срока показывали отчет клиенту. И почти всегда что-то шло не так, всегда что-то оказывалось неправильно понятым и клиент не принимал результат.
Поэтому процесс перестроили так, чтобы всегда были промежуточные результаты, которые нужно показывать и валидировать со специалистами в предметной области.
Конечно, это спорный вопрос, но я считаю, что это и есть результат работы data science-команды, по крайней мере до выхода в прод: что мы сегодня поняли, поработав с данными. Это и есть хороший промежуточный результат, на который можно посмотреть.
Если на стендапе выясняется, что ни одного «finding» не было, для нас это значит, что что-то идет не так, и мы обязательно выясняем, что случилось, есть ли какой-то блокер. Это помогает не терять времени на ситуации, когда data scientist уже подозревает, что текущая модель не принесет результатов, но надеется еще что-то из неё выжать.
Findings — сначала мы называли их insights, но пришли к выводу, что это все-таки преувеличение — порождают новые гипотезы, которые так же попадают на доску. Таким образом, в процессе нет итеративности — гипотезы просто двигаются по Канбану слева направо. В data science не надо прыгать туда-сюда, лучше начать прорабатывать новую гипотезу и не беспокоиться, если она провалится. Генерация новых гипотез вместо итерации повышает прозрачность.
Иногда сформулировать новую гипотезу не удается. Тогда можно ввести набор экспериментов. Эксперименты могут занимать достаточно много времени — одно обучение может длиться несколько дней — поэтому разумно повесить некоторый эксперимент.
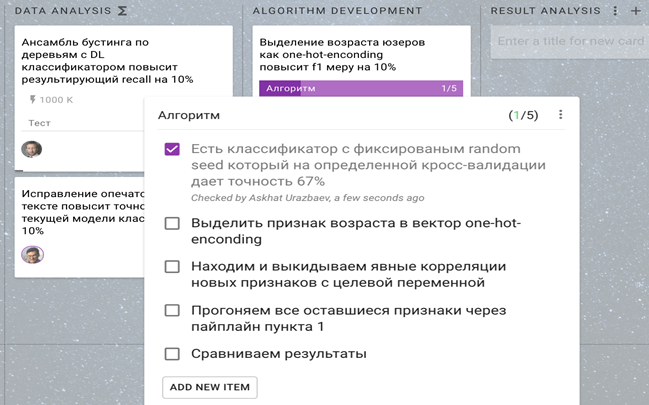
Эксперимент в этом примере сформулирован на языке data science, но по крайней мере у него есть связь с какой-то гипотезой, понятно, зачем он нужен.
Приоритезация гипотез:
- Рискованные в приоритете.
- От простых (эвристических) моделей к сложным.
- От дешевых гипотез к долгим и дорогим.
- Генерация гипотез — постоянный процесс. Инвестируйте время в новые гипотезы.
- Итоги исследований могут повлиять на постановку задачи.
Гипотезы лучше приоритезировать от простых к сложным, от дешевых и быстрых к долгим и дорогим. Это вроде бы очевидно, но на практике бывает сложно оценить, какие из гипотез дешевле проверить и какие из них могут принести больше пользы.
Также нужно учитывать, что постоянная генерация гипотез и итоги их проверки могут повлиять на постановку. Нормально, если вы сделали гипотезу и выяснили, что постановка неверная. Это естественный discovery-процесс.

Подводя итог проблеме взаимодействия, напомню:
- Ежедневные стендапы обеспечивают прозрачность.
- Этап ревью другим экспертом дает обратную связь.
- Ретроспектива настраивает процесс.
Низкое качество data science-продуктов
Особенность data science-продукта, его отличие от software engineering — модель всегда выдает результат. Она как-то обучена и, если подать валидный вход, что-то да выдаст. Нормально запущенная в прод рекомендательная система в любом случае будет что-то показывать. Но пользователь (конечный клиент) никогда не поймет, из-за чего он видит нерелевантные результаты: это баги или специфика обучения модели. Это основная причина низкого качества data science-продуктов.
А если баг все-таки есть, его очень трудно пофиксить. Допустим, заказчик замечает, что рекомендательная система показывает кеды, которые ему не нравятся, и не показывает интересные ему кроссовки. В разработке это решается так: «Ладно, через 2 дня покажу новый результат».
В data science это может быть еще 2 месяца работы, потому что, например, была ошибка в данных, на которых шло обучение. Её быстро обнаружить, но потом нужно найти новые данные и пройти с ними полный пайплайн проекта. И даже тогда система имеет ограниченную, не 100% точность, то есть заведомо есть вероятность, что результат работы модели будет ошибочным. Исправить этот баг вообще невозможно.
Baseline как MVP
Первое, что поможет повысить качество, — это baseline. Чтобы что-то улучшить, нужно понимать, с чем сравнивать. Первый baseline чаще всего вообще не основывается на ML.
Например, задача: по логотипу выдать название компании. Пока команда data science собирает данные и обучает модель, software-инженер, который не разбирается в ML, запустил самое простое и быстрое решение — забросить логотип в Google и вернуть первую ссылку. Конечно, точность будет не 100%, но это уже хороший ориентир. Который, к тому же, вполне может решить проблему пользователя.
Если быстро сделать самое простое базовое решение, можно обнаружить, что примерно 40% задач можно даже не доделывать. Если MVP решает проблему пользователя, то можно заняться чем-нибудь другим, чем-нибудь более полезным для продукта.
По моим наблюдениям есть два типа data scientist’ов:
- Переученные программисты — data scientist’ы, которые были раньше разработчиками ПО.
- Data scientist’ы после университетской скамьи, которые гораздо ближе к ученым, чем к инженерам.
Вторые любят Kaggle и думают, что главное в работе data scientist’а — это подбор правильных подходов и перебор моделей. Хотя на практике 80% успеха ML кроется не в модели, а в правильной подготовке данных.

Результаты работы data scientist’а как на картинке справа часто невоспроизводимы. У них что-то получается локально в Jupyter Notebook, но перенести это в прод и там воспроизвести результат задача максимально нетривиальная.
Тестирование? Зачем, мы же ученые, а не инженеры
Эта проблема свойственна классической науке. Мне очень нравится пример ученых из Гарварда Carmen Reinhart и Kenneth Rogoff, которые в 2010 году опубликовали работу «Growth in a Time of Debt». В статье утверждается, что в странах с большими внешними долгами, сильно ограничен рост ВВП. В течение нескольких лет некоторые страны действительно пытались поменять свою монетаристскую политику, чтобы уменьшить свои долги.

В 2013 году выяснилось, что авторы статьи допустили ошибку: в Excel не дотянули формулу до последней строки. В этом нет ничего удивительного, потому что во всем мире ученых оценивают по количеству опубликованных работ и индексу цитирования, а не качеству работы.
Data scientist’ы тоже ученые и тоже грешат таким подходом.
Конфигурационное управление
Выправить ситуацию поможет конфигурационное управление, как основа командной работы. Должно появиться управление версиями, грубо говоря data scientist’ы должны начать пользоваться Git. Не все понимают, зачем это нужно, объяснить довольно тяжело, но можно.
На воспроизводимость сработают автоматические проверки того, что построенная модель выдает именно то, что написано в отчете, и это всегда гарантируется. Для этого есть специальные инструменты, например: DVC, MLflow, neptune.ai. Основная их особенность — под версионным контролем находится не только код, но и данные.
Experiment review
Процесс аналогичный code review, так же как и code review бывает трех видов:
- Последовательное: один data scientist проводит ревью работы другого data scientist’а. Отличие от классической разработки в том, что они оба должны понимать контекст бизнес-задачи. Для этого как минимум два специалиста должны работать над конкретной бизнес-задачей, оба ходить на встречи с заказчиком и т.д.
- Параллельное: двое или более data scientist’ов параллельно работают над одним проектом и в конце дня сравнивают результаты. Эффект от такого подхода обнаружился случайно: в неразберихе по поводу очень срочной задачи по проверке результатов маркетинговой кампании за её выполнение взялись сразу два инженера. В результате один сказал, что эффекта от кампании нет, а другой — что эффект гигантский.
- Парная работа очень полезна в data science. Например, один может писать data science-код на Python, а второй в это время что-то уточнять на ноутбуке, а потом они меняются.
Experiment review позволяет повысить качество. Это важно, потому что ущерб от неверных расчетов может повышать стоимость команды в разы.
Подводя итоги, еще раз перечислю отличия data science от software engineering, которые нужно учитывать при построении процессов управления:
- Низкая зрелость индустрии data science. Сегодня data science очень напоминает то, что было в 90-х в software engineering.
- Длинный пайплайн из-за работы с данными.
- Discovery, а не delivery-процесс.
- Итог работы data science — несколько чисел.
- Модель работает всегда, находить и исправлять баги трудно.
Советую простой тест «Joel Test of Data Science Maturity» для оценки текущего положения дел в ваших data science проектах. Не стоит относиться к нему слишком серьезно, но тем не менее посмотреть, сколько очков получит ваша команда, может быть интересно и даст пищу для обсуждения проблем с командой.
При поддержке AvitoTech Онтико уже открыли доступ к видеозаписям всех докладов с TeamLead Conf — вот плейлист. Если хотите быть в курсе новостей вроде этой, то подпишитесь на рассылку или telegram-канал @TeamLeadChannel. А мы пока готовим питерский TeamLead Conf и принимаем заявки на доклады.
