Генерация под контролем: как обуздать мощные языковые модели
Intro
Если вы не проспали последние пару-тройку лет, то вы, конечно, слышали от трансформерах — архитектуре из каноничной Attention is all you need. Почему трансформеры так хороши? Например, они избегают рекуррентности, что дает им возможность эффективно создавать такое представление данных, в которое можно запихнуть очень много контекстной информации, что положительно сказывается на возможности генерации текстов и непревзойденной способности к transfer learning.
Трансформеры запустили лавину работ по language modelling — задаче, в которой модель подбирает следующее слово, учитывая вероятности предыдущих слов, то есть выучивая p(x), где x — текущий токен. Как можно догадаться, это задача совсем не требует разметки и потому в ней можно использовать огромные неаннотированные массивы текста. Уже обученная языковая модель может генерировать текст, да так хорошо, что авторы подчас отказываются выкладывать обученные модели.
Но что если мы хотим добавить немного «ручек» к генерации текста? Например, делать условную генерацию, задавая тему или контролируя другие атрибуты. Такая форма уже требует условной вероятности p(x|a), где a — это желаемый атрибут. Интересно? Поехали под кат!
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
Авторы статьи предлагают простой (поэтому и Plug and Play) и изящный подход к условной генерации, использующий тяжелую pre-trained language model (далее LM) и несколько простых классификаторов, тем самым семплируя из распределения вида p(x|a) ∝ p(a|x)p(x). Надо заметить, что исходная LM никак не модифицируется. Авторы предлагают две формы классификаторов, называемых в статье attribute models: BoW для контроля темы и линейный классификатор для контроля тональности. Авторы делают достаточно подробный разбор своих key contributions, сравнивая идеи и подходы своего метода с другими статьями. Одним из самых важных пунктов является легкость подхода и тут, пожалуй, достаточно посмотреть на эту табличку: 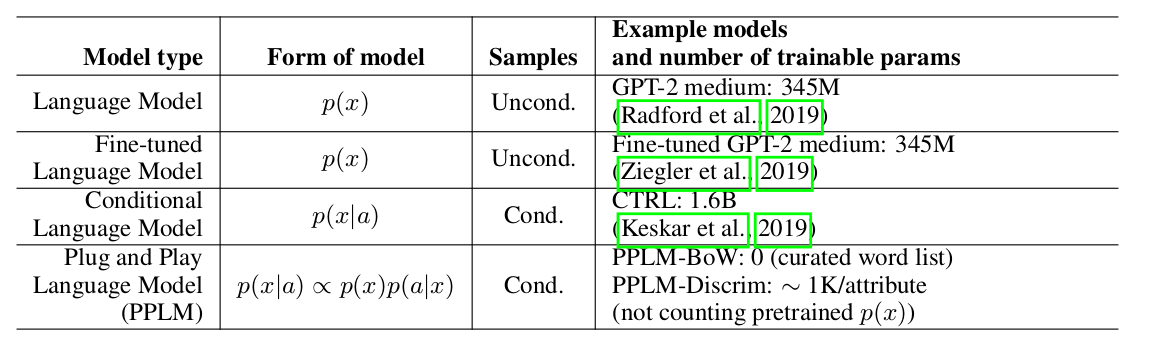
Видно, что по количеству параметров PPLM выигрывает у всех конкурентов.
Weighted decoding 2.0
Товарищи из Uber развивают идею weighted decoding: на каждом шаге предсказания языковая модель благоволит к тем токенам, которые участвуют в нужной нам теме. Например, мы хотим генерировать тексты про науку, тогда на каждой выдаче моделью вероятностного распределения над токенами мы будем повышать вероятности токенов про науку. Такой подход не требует дополнительных параметров, однако нужно поддерживать набор определенных ключевых слов для каждой темы. Кроме этого, такой подход слишком жадный и не повышает вероятности слов, которые косвенно связаны с темой, но не имеются в нашем изначальном наборе.
Ребята из Uber предлагают бороться с этим следующим образом: давайте менять распределение раньше, в скрытых векторах LM, повышая вероятности тех же интересных нам токенов. При этом, будем надеяться, что раз мы заранее подогрели вероятности ключевых слов, то и вероятности косвенных токенов (не из нашего тематического набора, но той же темы) тоже будут побольше. Авторы идут еще дальше и буквально переписывают историю (в коде функция даже называется perturb_past — вышеописанные изменения производятся не только для текущего шага модели, но и для набора предыдущих.
Как же это работает? На каждом шаге авторы смещают значения выходов слоев с предыдущих шагов в направлении повышения суммы двух log-likelihood: оригинальной модели p(x) и атрибута a нашей attribute model p(a|x). Это очень похоже на обучение модели, мы тоже делает своеобразный backward pass по ошибке предсказания нужного токена.
Почему нам нужно максимизировать оба log-likelihood? Авторы делятся отличной картинкой, объясняющей интуицию: 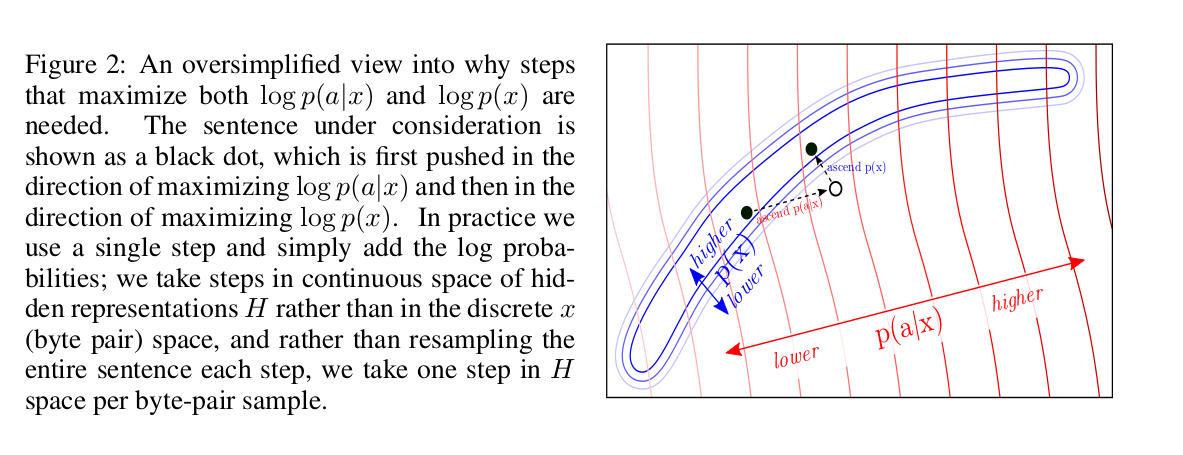
Вкратце, мы хотим смещаться в сторону желаемых атрибутов, при этом оставаясь в вероятностном пространстве выдачи оригинальной LM. Оставаясь в таком пространстве, мы оставляем fluency модели примерно на уровне исходной LM.
Давайте повнимательней посмотрим на то, как сэмплируют нужные нам слова: 
Сначала мы делаем forward pass через LM, чтобы оценить правдоподобие нужного нам атрибута с p(a|x) — нашей attribute model. Затем мы делаем backward pass, обновляя внутренние представления модели градиентами, полученными от attribute model, чтобы повысить правдоподобие токена, связанного с этим атрибутом. Наконец мы заново генерируем распределение над словарем, используя обновленные внутренние представления модели.
К сожалению, можно заметить что такой подход очень медленный: для обновления «прошлого» на глубину k нам нужно сделать k forward и backward pass«ов, каждый глубиной n. В то время как обычная LM делает всего один forward pass. И да, это действительно медленно: (попробуйте поставить num of iterations=3 и gen length=5, чтобы дождаться результата).
Впрочем, локально код (можно и в colab посмотреть, предварительно сделав копию ноутбука) работает пободрей, можно поиграть, например, для текста «the kitten» и тематики «military» можно получить такое:
- The kitten is a creature with no real personality, it is just a pet. You can use it as a combat item.
- The kitten that is now being called the «suspected killer» of a woman in a San Diego apartment complex was shot by another person who then shot him, according to authorities.
combat, shot, killer — слова, ассоциированные с тематикой military. Обычная LM выдаёт вполне невинные предложения:
- The kitten that escaped a cage has been rescued from a cat sanctuary in Texas.
- The cat, named «Lucky,» was found wandering in the back yard of the Humane Society at the time of the incident on Friday.
Немного о attribute models
Авторы предлагают две модели, BoW и discriminator. В первом случае тема задается набором ключевых слов и мы хотим получить логарифм суммы правдоподобий каждого из этих слов:

где p_t+1 — распределение на выходе LM, а w_i — i-ое ключевое слово.
Discriminator model позволяет сделать более сложное определение атрибута, чем простой BoW, это будет актуально, например, для изменения тональности или токсичности, а может даже и стиля текста. В этом случае модель принимает на вход усредненные по нескольким шагам эмбеддинги и предсказывает класс, предварительно обучившись на размеченном наборе примеров.
Результаты
Авторы показывают отличные результаты, сравнивая свой подход с LM, LM с weighted decoding и недавней моделью CTRL (conditional LM). Сравнивали fluency и тематичность сгенерированных текстов, оценка проводилась как людьми, так и подсчетом perplexity модели. В таблице ниже показано сравнение тематичности вариаций PPLM и других подходов: 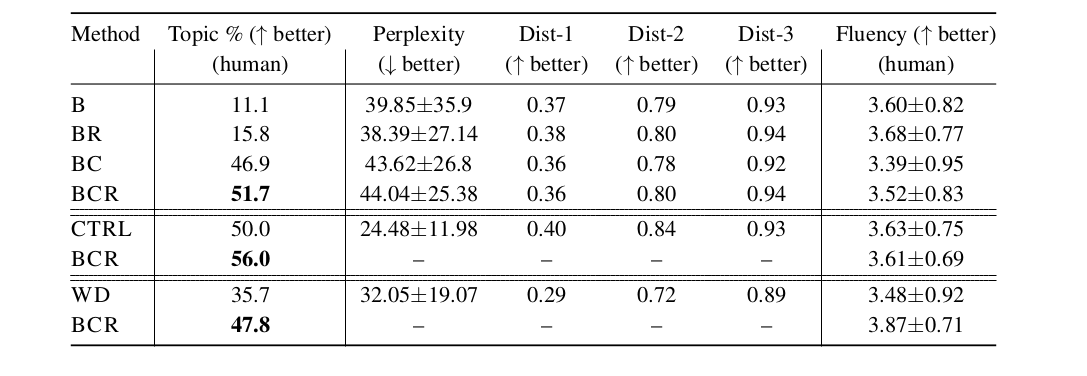
А здесь сравнение на задаче генерации текста заданной тональности: 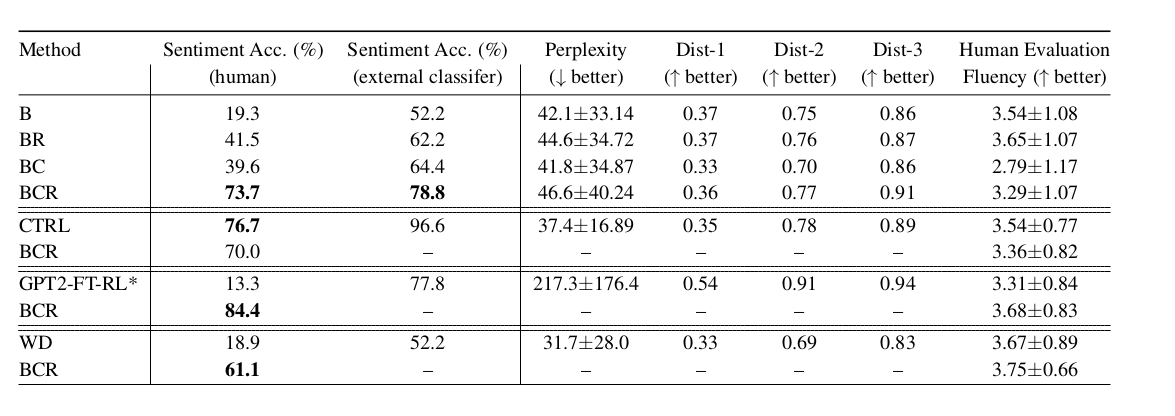
- B — baseline, GPT-2 LM;
- BR — то же самое, что и B, но семплирование было
rраз, а потом лучший сэмпл выбирался по ранжированию log-likelihood и фильтрации по скору дискриминатора; - BC — здесь уже применяется обновление скрытых представлений основной модели, семплирование проводится единожды;
- BCR — то же самое, что и BC, но семплирование было
rраз, а потом лучший сэмпл выбирался по ранжированию log-likelihood и фильтрации по скору дискриминатора; - CTRL — модель из статьи Keskar et al, 2019;
- GPT2-FT-RL — GPT2, fine-tuned с RL на оценках от людей;
- WD — weighted decoding, в котором выходы оптимизированы для максимизации
p(a|x);
Резюме
Один из основных плюсов подхода — его легкость и универсальность, нет привязки к архитектуре LM, а подход с дискриминатором позволяет гибко задавать желаемые атрибуты. Основным минусом является скорость, возможно, с методами какого-то более хитрого обновления слоёв это будет работать быстрей:)
