Где я и где конечный автомат? Доклад Вадима Пацева о математике во фронтенде
— Меня зовут Вадим Пацев, я долгое время работаю в Яндексе, участвовал в таких проектах, как Я.ру, Музыка, Почта, Диск, а также в проектах вне Яндекса, это Roborace, система управления гонками беспилотных автомобилей, и ExperimentX — комплекс по анализу крови. Вообще, я люблю программировать, занимаюсь этим достаточно давно, и это одна из причин, почему я тут и хочу вам рассказать про всякие интересные вещи.
Intro
Сразу дисклеймер: я буду рассказывать о проекте не про Яндекс. Как вы заметили, оформление не яндексовое, и тут не будет ничего связанного с Яндексом. И еще один дисклеймер: все детали проекта вымышленные, любые совпадения с реальными проектами случайные, потому что так сложилось.
Я довольно много собеседую, и часто фронтенд-разработчики говорят мне в полушутку: мы форма-клепатели, делаем кнопочки, формы, простые вещи. И когда мы читаем или слышим про всякие конечные автоматы, математику, вероятности и так далее, встает вопрос: где я, а где все это? У нас простая сфера, мы делаем несложные вещи, и вообще, все это больше про дизайн, нежели про программирование.
Сегодня я хочу рассказать как раз не про формы и кнопки. Забавный момент: параллельно со мной идет секция Виталия Фридмана как раз про то, как правильно делать формы и кнопки в интернете. Я сегодня буду говорить не про это, а расскажу об одной нашей задаче, о том, как она развивалась и к чему мы пришли.
Но здесь важно не то, к какому конкретно мы техническому решению пришли, а то, какой подход мы использовали, то есть как нам удалось выйти за рамки задачи и текущего технического решения. И придумать что-то другое, более интересное и удобное на тот момент.
Я затрону концепцию конечного автомата — надеюсь, что вы с ней знакомы, — и еще одну математическую концепцию: цепи Маркова. Это некое продолжение конечного автомата, они довольно тесно связаны.
Контекст
Что это за задача, в каком контексте все происходило?
Мы работали с людьми искусства. Допустим, это были люди, которые делают кино. И они хотели сделать публичное мероприятие на сотни человек. Несколько площадок, здания, открытое пространство. В зданиях целые этажи, переходы между зданиями и так далее. Это несколько стоящих зданий, там можно получить интересный опыт.

Если вы когда-нибудь были в иммерсивном театре или на квестах, то примерно представляете, о чем речь. Вы попадаете в какое-то пространство, вас ставят в какие-то условия. В нашем случае мы забирали все гаджеты у людей, выдавали каждому персональное устройство, некий навигатор, который говорит, куда идти и что делать дальше.
Наша задача состояла в том, чтобы сделать софт для такого навигатора. Я беру устройство, мне говорят: «Иди вперед, увидишь темную комнату. Посмотри направо, налево, там могут быть какие-то актеры». Дальше начинается опыт, взаимодействие и так далее.
Раз мы тут на фронтенд-конференции, то допустим, что решение было написано на React Native, но это не так важно.
Важное уточнение: сразу стало понятно, что площадки довольно сложные с точки зрения логистики. Много этажей, открытые пространства и так далее. И мы не могли делать хорошее покрытие Wi-Fi. То есть наши устройства не всегда были в сети, вынуждены были работать автономно. Мы не могли централизованно с сервера управлять тем, как работают эти навигаторы.
Также устроители и режиссеры этого мероприятия не хотели, чтобы материалы с этого мероприятия уходили в сеть. То есть речь о персональном устройстве, у которого не всегда есть сеть и точно нет интернета.
Линейные сценарии
Итак, нам надо сделать навигацию, пошаговую инструкцию.

Окей, давайте сделаем простой сценарный движок: возьмем Redux и сделаем такую декларативную структуру, массив, в котором декларативно опишем каждый шаг.
В терминах Redux это будет некий action, который запускается и что-то показывает на экране. Опционально у него может быть другой action, то есть тот, который надо делать дальше. А также может быть фидбэк. То есть если мы показываем пользователю, где кнопки, то он выбирает одну из них и дальше либо идет по сценарию, по которому шел до этого, либо перекидывается на другой сценарий. Это обычный декларативный сценарий, который можно написать в терминах Redux.
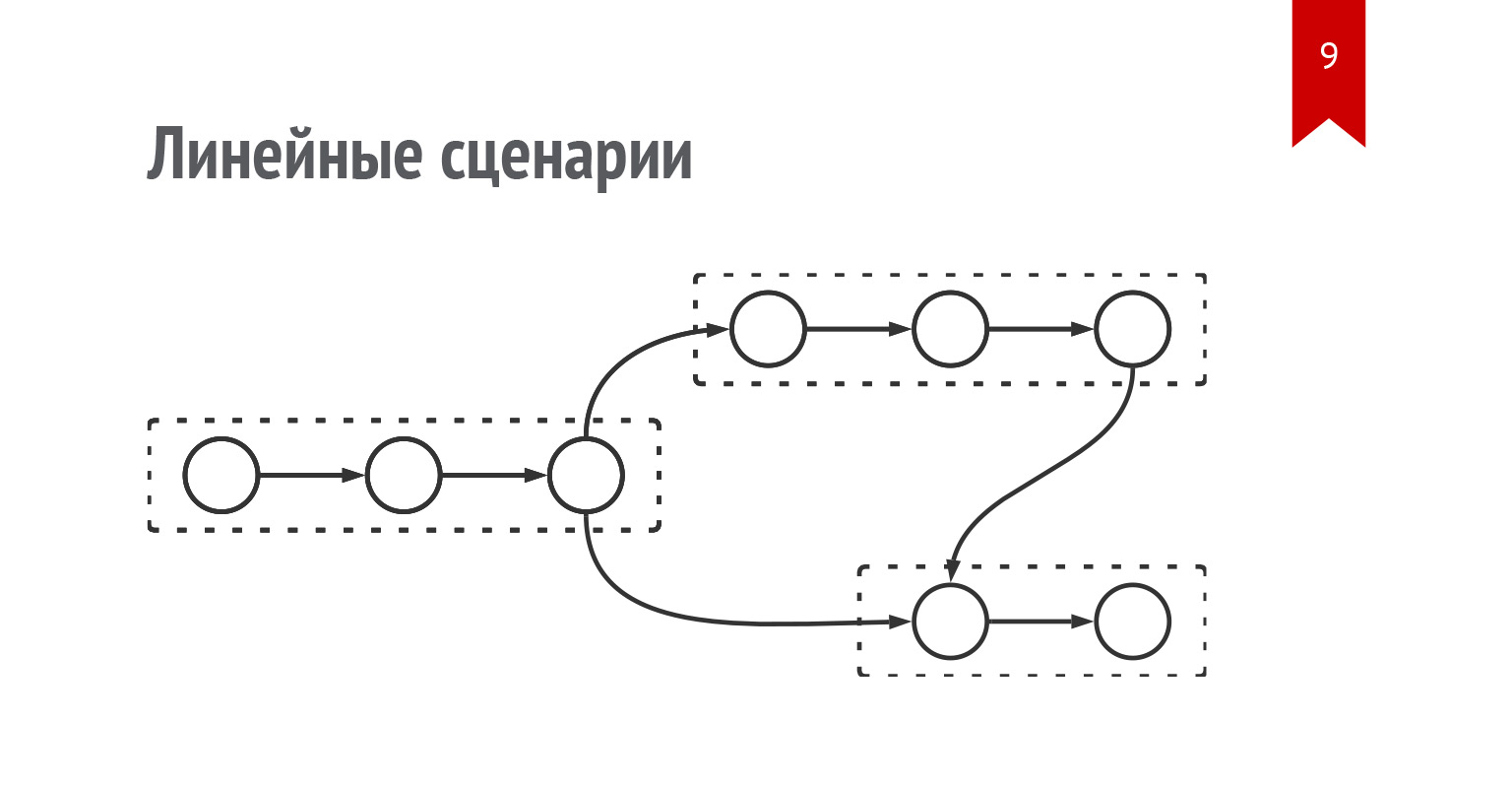
Схематично это выглядит так. Есть некий сценарий, массив. В нем есть несколько шагов. Каждый шаг описан. Дальше может быть несколько сценариев: из одного мы идем в другой и так далее. Также они могут ветвиться, то есть в конце каждого сценария мы можем либо рандомно выбирать переход на другой сценарий, либо показывать кнопки, и пользователь сам выберет, куда идти дальше.
Важно: то, что мы сделали на Redux, уже является конечным автоматом. Это математическая абстракция, модель дискретного устройства, имеющего один вход, один выход и в каждый момент времени находящегося в одном состоянии из множества возможных.
Наверное, для вас не секрет, что философия работы Redux связана с конечным автоматом. В машине состояний системы store определяет состояние, action вызывает работу reducers. Reducers изменяют состояние системы, система переводит в новое состояние store, то есть возникает новое состояние автомата.

Такое решение работает, и оно довольно простое. Мы берем обычный state management, предустановленный набор сценариев. Запускаем машинку. Она сама переключает шаги.
Так как есть изначально сформулированный сценарий, то сразу есть и некие рельсы, по которым идут пользователи. Это может работать офлайн, онлайн, неважно.
Мы можем изменять сценарий «на лету», каждый шаг. Если у нас есть сеть, мы можем перезапрашивать у сервера, получать новый набор сценариев. Дальше пользователь пойдет по другим рельсам. Могут быть всякие казусы: например, при обновлении сценария один на второй изменился порядок шагов, и пользователь на каком-то шаге два раза сходил туда-обратно. Такое бывает.

Мы сделали такое решение. Режиссеры и сценаристы подготовили нам пять-десять готовых сценариев. Мы их запрограммировали, сделали рельсы. Запустили сто участников на площадку.
Они походили, машинка поработала, поводила людей более-менее рандомно в смысле распределения сценариев по людям. Люди распределились по площадке, начали заходить в комнаты — все работало достаточно неплохо.
Стало понятно, что при таких масштабах, когда есть всего сто участников и пять-десять сценариев, нет необходимости в распределении ресурсов. Площадки довольно большие, комнат и актеров довольно много, на таких масштабах все работает весьма неплохо. На этом этапе задачу выполнили.
Но мы работаем с людьми искусства, есть великий режиссер, который решил, что делать надо не так. Он захотел совершенно другого масштаба мероприятия. Ему показалось, что сотня избранных, которые находятся в его мире, — это не совсем тот масштаб, который он хочет. Он хочет тысячу людей на площадке.

Также пять-десять сценариев — это тоже не совсем желаемое разнообразие. Хочется намного больше разных сценариев, намного больше вариативности того, что может происходить на площадке.
Также он хочет управлять судьбами людей, потоками, влиять на то, куда идет конкретный человек или группа. Нужна была некоторая админка, которая позволяет выбирать какое-то количество людей и направлять их в одну комнату, других людей направлять в другую комнату и уметь делать это вплоть до конкретного человека.
С одной стороны, это увеличило драму. С другой, это позволяло распределять нагрузку между ресурсами, которых не хватало. То есть при таком объеме, условно, темных комнат и актеров могло не хватить. Надо было руками разводить людей так, чтобы они не сталкивались головами в самых узких местах.
Окей, с точки зрения техники у нас остается примерно то же самое, наш сценарный движок работает хорошо. Мы можем добавить туда сколько угодно сценариев. Это требует разработки, но в целом это не очень сложная задача.
Но также у нас добавляется возможность при наличии сети в ключевые моменты просто переводить систему в нужное состояние извне. В нашем конкретном случае это были пуши. Когда устройство выходит на связь, оно получает пуш-сигнал, переводит машинку в нужное состояние, и мы идем дальше.
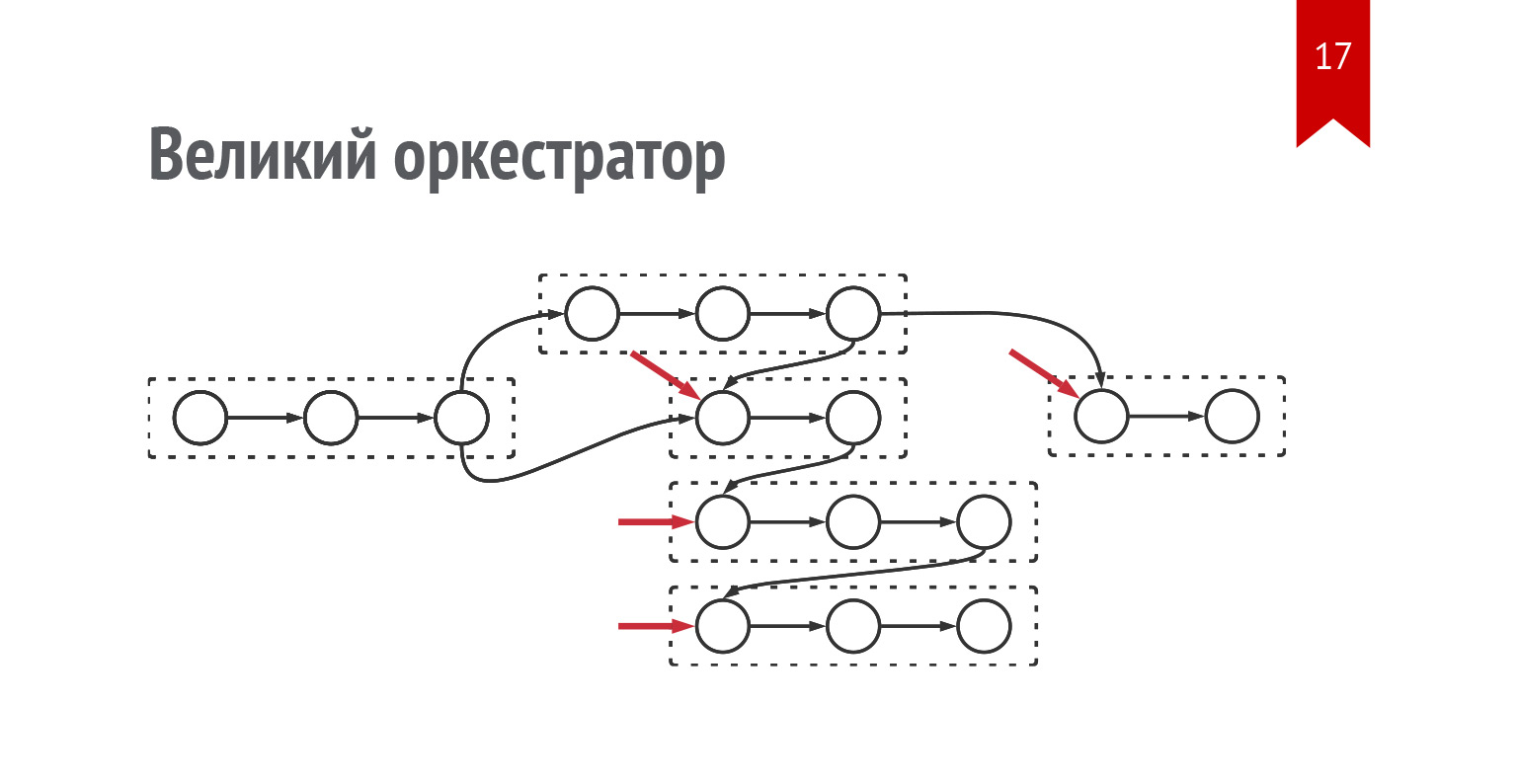
Схематично это выглядит так же. У нас есть сценарии. Мы умеем по шагам их проходить и переводить на другие сценарии. Их стало больше, вариативность увеличилась. Также появились красные переходы. Когда поступает внешний сигнал, мы переключаем систему сразу в нужное состояние. Дальше работа идет оттуда.
Мы начали тестировать это решение, и сразу стали видны проблемы. Первая проблема — люди, которые берут устройства, идут по указаниям, но почему-то сворачивают не направо, а налево, почему-то не нажимают на кнопки или нажимают на них не тогда, когда нужно, неправильно выполняют инструкции и так далее.
Операторы, которые управляли действиями по указке режиссера, тоже ошибались. Направляли людей не туда, куда нужно, и система очень зависела от человеческого фактора.
Кроме того, сразу стало понятно, что физические ресурсы — это бутылочное горлышко. На таком масштабе темных комнат не хватает, актеров не хватает, ничего не хватает.
Также непонятно, когда это бутылочное горлышко начнет мешать. Мы не можем прогнозировать, когда людям понадобится 100500 комнат: для этого надо синхронизировать работу всех операторов и всегда держать в уме, что сейчас люди могут пойти вот туда, а если мы нажмем на это, то здесь они столкнутся лбами. Сразу начинается хаос, с которым не понятно, что делать.
Что мы поняли? Нужна автоматическая логистика потоков. Нам нужно сделать такую систему, которая нивелирует человеческий фактор, автоматом может распределять людей по нужным трекам и включать нужные сценарии, чтобы это работало само.

Также нужен инструмент для моделирования. Сценарии, которые мы написали, рельсы, которые мы сделали, — не факт, что они хорошо работают в таких масштабах. Это надо проверять, нужен инструмент, который позволит нам сделать модель.
Дальше нужно сделать набор сценариев, запустить их. Машинки должны виртуально работать, перещелкивать сценарии и так далее. Люди куда-то идут, куда-то доходят. Мы сразу видим, насколько работают придуманные сценарии.
Вдобавок стало понятно, что даже в масштабе тысячи человек и 30 сценариев людям не очень нравится ходить по рельсам. На больших числах видно, что ты идешь параллельно с другими людьми по тем же рельсам. Сразу есть чувство, что ты получаешь такой же опыт, как все остальные, и в этом меньше магии, чем хотелось бы.
Лирическое отступление. Разработка чат-бота весьма похожа на то, что я описал. К вам приходят с задачей, говорят, что есть сценарии для взаимодействия с пользователями и их надо как-то спрограммировать. Приходит пользователь, ему задаются вопросы, шаги, он отвечает и получает какой-то результат. Могут быть разные сценарии и так далее, все абсолютно то же самое.
Но если вы разрабатывали чат-ботов или пользовались ими, то вам сразу видны эти рельсы, сразу видно: если происходит шаг вправо, шаг влево от сценария, то бот перестает тебя понимать. Теряется магия того, что ты общаешься с умным существом.
У нас примерно та же история: есть рельсы и любой шаг вправо-влево — ошибка. Это сразу ломает весь user experience. Требовалось другое решение.
У нас был опыт работы с чат-ботами, мы работали с Dialogflow. Это стартап, который впоследствии купил Google. Они сделали систему, которая позволяет строить нелинейные сценарии, как раз то, что нам было нужно.
Есть некоторая предметная область, с помощью которой можно строить сценарии так, что они становятся не очень похожи на рельсы. Нам было нужно именно это, мы применили их предметную область у себя. На самом деле это был качественный переход, потому что нам надо было уйти от простой state-машины к более сложному решению.
Конечный автомат
Из чего состоит более сложный конечный автомат?

У нас были декларативные сценарии и сигналы. Мы делаем три новых сущности, в которые конвертируем уже существующие сценарии. Это можно сделать автоматически. Новые сущности — это Activity (активность), Trigger и Interaction (взаимодействие).

Activity регистрирует то, что увидел пользователь, и его действия в ответ на это. Если ему просто что-то показали на экране, это просто регистрация того, что показали. Если ему показали кнопки, то мы записываем то, на какую кнопку он нажал.
Технически это тоже выглядит как декларативная структура. Interaction — взаимодействие, после которого это Activity произошло. Trigger — то, что вызвало это взаимодействие. Некий фидбек — это то, на что нажал пользователь, и так далее. Metadata — контекст, в котором это было сделано: сколько времени пользователь потратил на данную активность, какой был заряд батареи, какие биконы были вокруг.

Trigger запускает взаимодействие. Это тоже декларативная структура, она состоит из Interaction, того взаимодействия, которое мы запускаем; и из условия, при которых этот Trigger срабатывает. В нашем случае там мог быть либо определенный набор Activity, определенный контекст, который уже есть у пользователя, либо сигнал — то, что приходит извне.
Другими словами если извне поступает сигнал, срабатывают те Triggers, в условиях которых написано, что надо срабатывать по этому сигналу. Также есть вес данного Trigger относительно других, о нем я расскажу чуть позже.

Последнее — Interaction, более знакомая нам структура. Это стандартный Redux action, который меняет локальное состояние приложения, показывает на экране какие-то вещи, выполняет взаимодействие, то есть переводит локальную state-машину, которую мы делали до этого, в некое новое состояние.
Здесь важно, что в результате срабатывания этого взаимодействия регистрируется новая Activity, которая, в свою очередь, триггерит Trigger, и запускает новое взаимодействие.

Еще раз: Activity однозначно определяет состояние нового конечного автомата. У пользователя сначала нет никаких Activities, пустое состояние. Потом они начинают накапливаться.
Каждый раз, когда появляется новая Activity, появляется и новое состояние системы. Набор однозначен, так что система находится в однозначном состоянии.
У Trigger есть некоторые условия, которые завязаны на Activity, на эти состояния. И мы, имея одно состояние, выбираем набор Triggers, которые могут сейчас привести систему в новое состояние.
И есть Interaction, который переводит систему в новое состояние.
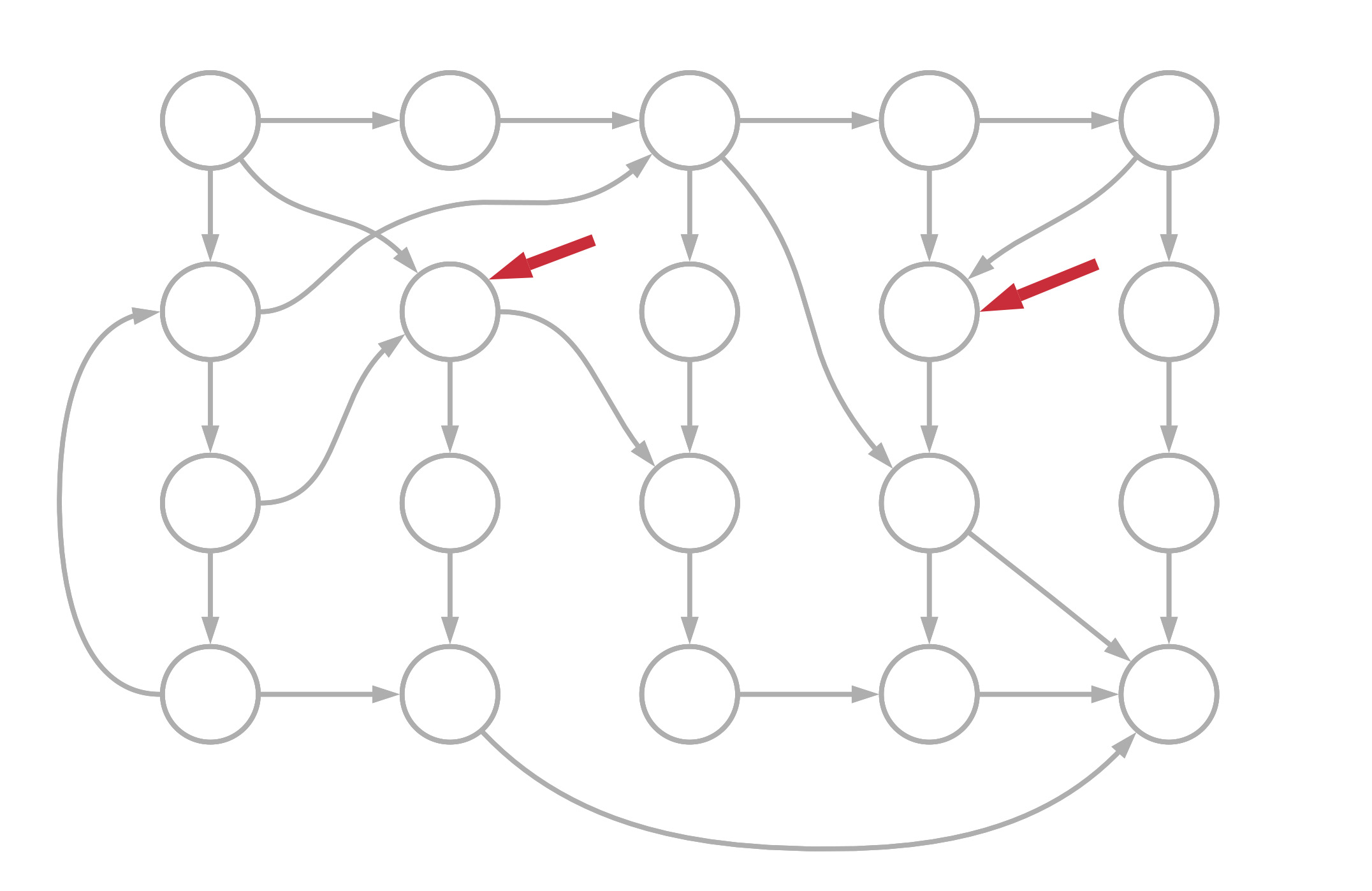
Схематично это выглядит так.
У нас имеется унекоторое множество состояний, в которых может быть система. Это возможный набор Activities, которые пользователь может собрать за свой путь.
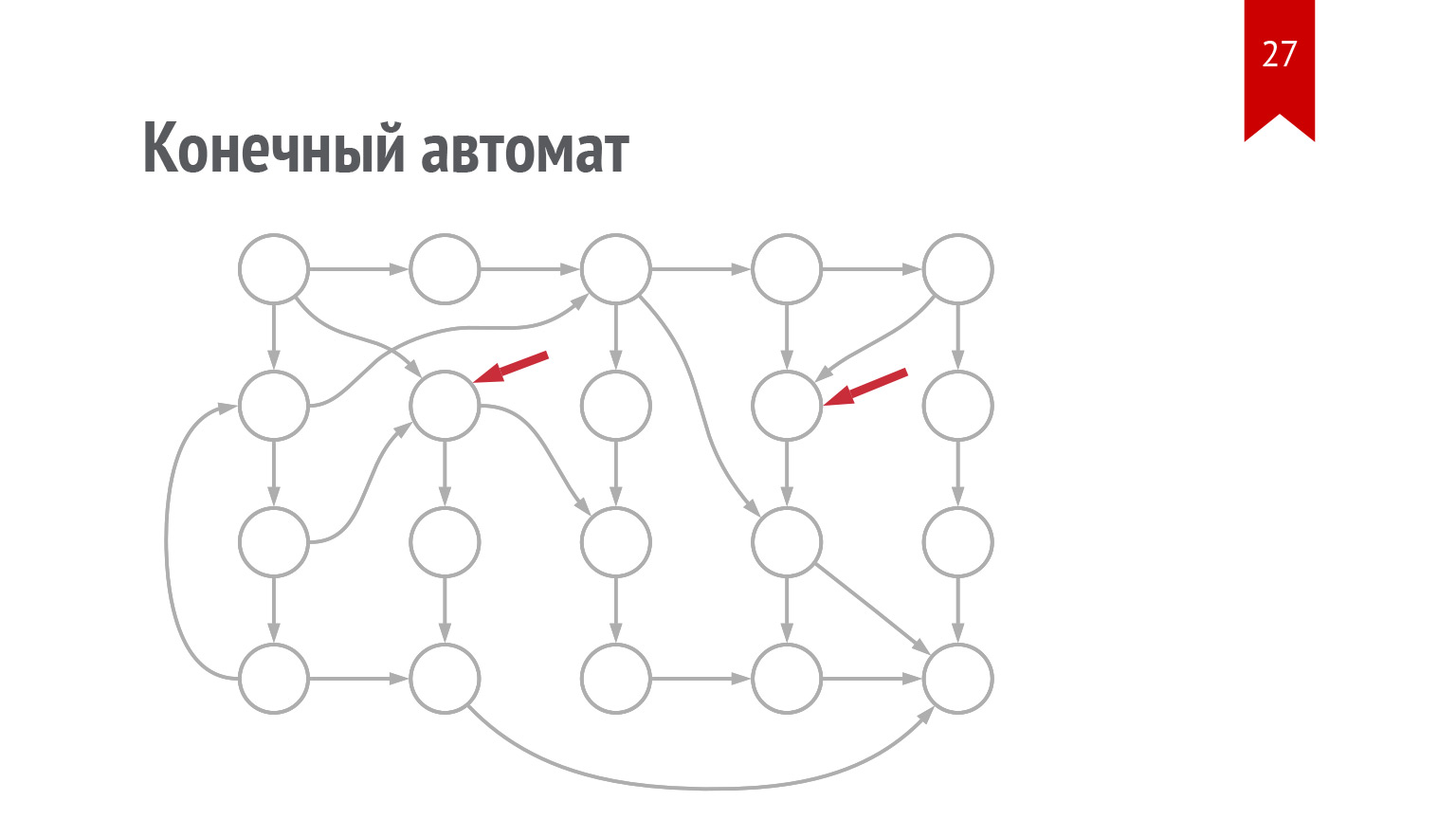
Существуют Triggers, которые определяют, как система переходит из одного состояния в другое. Они описаны в conditions. Там могут быть описаны сигналы, которые просто из любой точки приводят систему в любую другую точку. Это нужно для ручного управления. А Interactions осуществляют регистрацию нового Activity и переход в новое состояние.

Набор сущностей Trigger и Interaction, то есть два набора возможных переходов и нулевое пустое состояние определяют работу системы. Мы закидываем набор Trigger/Interaction, при нулевом состоянии срабатывает первый Trigger.
Регистрируется первая Activity. Срабатывает еще один Trigger, который запускает какой-то Interaction, регистрируется новая Activity. Система переходит в новое состояние, и так далее. Это такая автономная система, которая примерно так же, как до этого по сценариям, но уже чуть более сложным, начинает работать сама.
То, как мы регистрируем Activity, — большой источник аналитических данных. Мы не только регистрируем некий path, путь по всем возможным состояниям, но и регистрируем там метаданные: сколько времени понадобилось, какое было окружение и так далее. Из этого уже можно сделать некие выводы.
Также есть сигналы, которые позволяют безусловно перевести систему в новое состояние и влиять на нее извне.
Цепи Маркова
Дальше речь пойдет про цепи Маркова. К конечному автомату мы добавляем вероятности.
Еще одно лирическое отступление. Что такое вообще марковские процессы, цепи Маркова? Последовательность случайных событий с конечным или счетным числом исходов, где вероятность наступления каждого события зависит от состояния, достигнутого в предыдущем событии.
Грубо говоря, марковское свойство системы — это когда вероятность любого следующего перехода зависит только от текущего состояния, и не зависит от того, как пользователь в него попал.
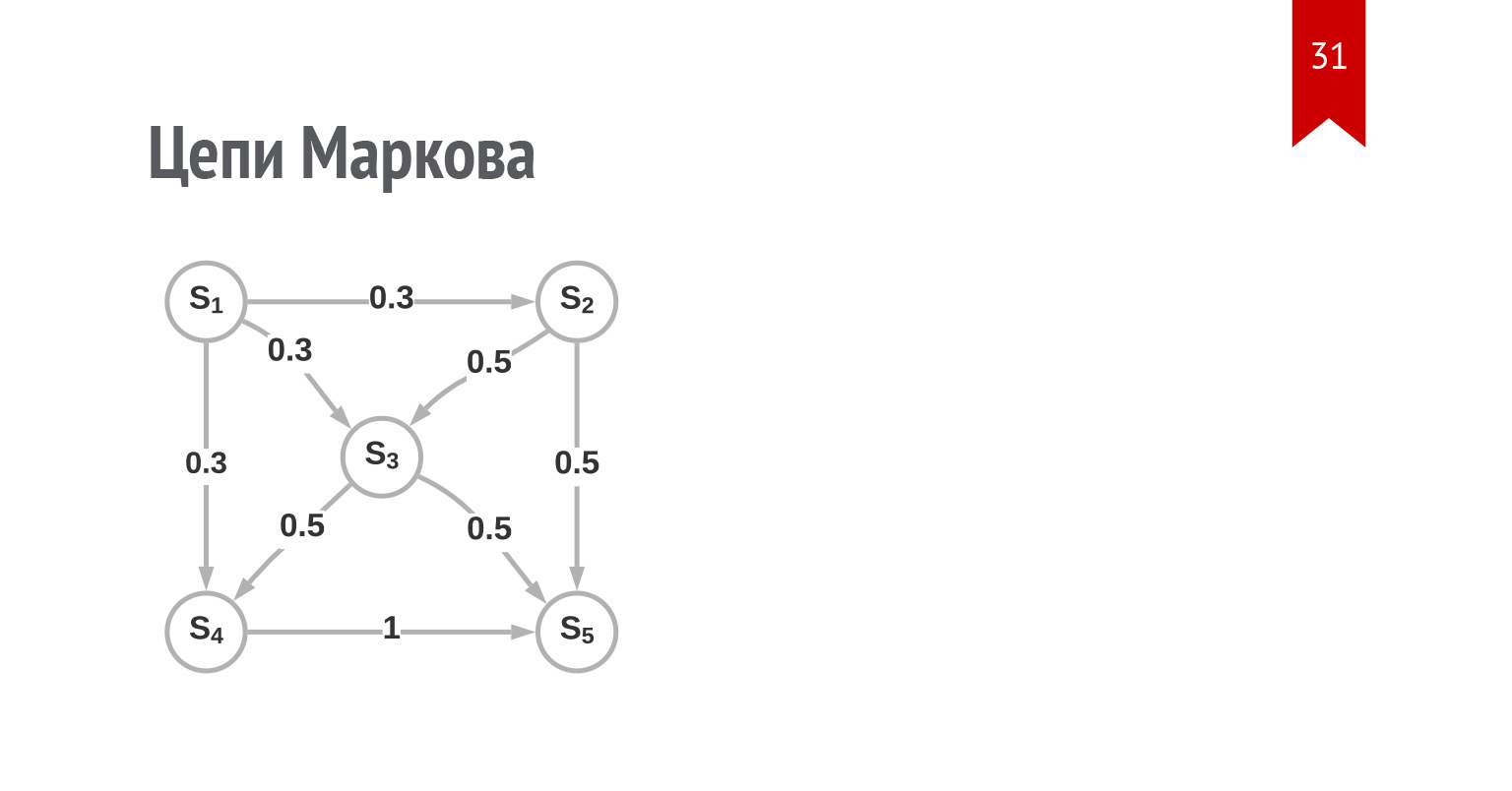
Схематично выглядит так. У нас есть некоторое количество возможных состояний. Для каждого состояния есть вычисленная вероятность перехода из состояния — например, из S1 в S3.
Вероятность, что дальше произойдет переход S3-S4 или S3-S5, никак не зависит от того, как мы попали в S3. Мы могли как-то по-другому попасть в это состояние, но с точки зрения этой картины ничего бы не изменилось. Это и есть, вкратце, марковское свойство системы.

В нашей системе, в конечном автомате, который у нас получился, соблюдается марковское свойство. У нас детерминированная система. Каждый раз регистрируется новое Activity. Мы попадаем в это состояние, и неважно, как мы туда дошли. Да, мы можем построить путь, по которому шел пользователь, но это неважно.
Дальше срабатывают какие-то Triggers, их может быть несколько. Тогда мы рандомно выбираем. Если Trigger один, тогда вероятность перехода в следующее состояние равняется единице.
Марковский процесс, которым мы усложнили наш конечный автомат, позволяет посчитать вероятность срабатывания Trigger через n шагов. Здесь написаны формулы, я могу их озвучить. Вероятность перехода из состояния j в состояние i за m шагов равна сумме вероятности перехода из i в k, умноженной на вероятность перехода из j в k при m минус первом шаге. Это простая формула, описывающая довольно сложные вычисления.
И мы можем грубо по этой формуле посчитать вероятности нахождения системы на определенном шаге. Также мы можем уточнить ее с помощью статистики, которую мы накопили по Trigger и Activity.
Итак, еще раз. Есть конечный автомат — множество состояний, в котором может находиться система. Есть Triggers, возможности перехода из одного состояния в другое.
Есть сигналы, которые переводят систему сразу в нужное состояние. И также есть вероятности перехода из одного состояния в другое, чтобы мы могли воспользоваться математическим аппаратом цепей Маркова.

Все это дает нам следующее. Мы можем с какой-то долей вероятности посчитать, в каком состоянии будет система через N шагов. Это дает нам довольно интересный инсайт. Например, через сколько шагов и какому количеству людей нужно будет воспользоваться каким-то ресурсом.
Либо мы можем понять, через какое время у нас с площадки уйдет сто человек и удастся запустить еще сто человек.
Также этот математический аппарат позволяет нам тестировать наборы Trigger/Interaction. Допустим, мы сделали набор Triggers, запускаем эту машинку. Проверяем ее на тысяче разных пользователей, которые рандомно нажимают на кнопки, рандомно делают выбор. Мы вычисляем вероятности, с которыми пользователи были в определенных участках, то есть в определенных состояниях нашей системы. И дальше понимаем, как вообще распределяются потоки, нагрузка и так далее.
Также можно понять, какие есть способы распределять пользователей по площадке. Тестируя Triggers, мы можем подобрать их так, чтобы в реальности потоки на площадке не столкнулись и площадка выдержала нагрузку, на которую рассчитана.

В итоге мы получили модель поведения пользователей. Она может быть реализована на клиенте и на сервере, она синхронизируется с помощью Activity, Trigger и Interaction. То есть мы, с одной стороны, с клиента, посылаем Activity в сторону сервера и тем самым уточняем модель, меняем состояние на сервере. И наоборот, можно одновременно изменять наборы Trigger и Interaction на борту телефонов и на сервере.
Это позволяет делать забавные вещи. Если есть модель и в реальности что-то происходит на площадке, то мы можем параллельно с помощью нейронных сетей на сервере прогонять эту модель на других наборах Trigger/Interaction и понимать, как мы можем изменять Trigger так, чтобы наша модель работала, потоки расходились и так далее.
Потом, когда мы поняли, что данное сочетание Trigger и Interaction работает лучше, мы посылаем его на клиента и жизнь на площадке начинает жить по этим новым правилам. Это можно делать несколько раз, если есть сеть.
Если сети нет, то система работает так же, как и работала, по старым правилам. Когда придут Activities, мы обновим модели на сервере, начнем заново обучать нашу систему и так далее.
Всегда есть некие вероятностные оценки потребности в том или ином ресурсе через какое-то время. Если мы замеряем, за сколько происходят шаги в тех или иных Triggers, то можем посчитать модели пользователей, которые есть сейчас на клиенте и сервере, и когда понадобятся такие-то ресурсы. И индикативно показать на дашборде людям, что сейчас нужно открыть новые комнаты либо вообще закрыть часть сценариев, потому что нет актеров. То есть в реальном времени реагировать на происходящее.
Также мы можем организовать очереди и, имея модели людей на площадке, моделировать эти очереди с помощью системы массового обслуживания.
Еще один забавный момент, к которому мы и стремились: мы предлагаем рандомные Interaction. То есть когда в системе всплывает несколько Triggers с одинаковым весом и одинаковой вероятностью перехода, система сама выбирает какой-то рандомный Trigger и у пользователя на экране появляются рандомные предложения либо рандомные истории.
Это по-настоящему персональный опыт: из-за того, что такое рандомное срабатывание у каждого свое, получается некая магия. То, что ты видел на экране своего телефона, немного отличается от того, что видят другие посетители.
Outro
Цепи Маркова, конечный автомат — всё, о чем я сейчас рассказал, — это всё в контексте фронтенда. У нас был React Native плюс Redux. Технически все это было сделано на фронтовых технологиях и находилось в поле ответственности фронтенд-разработчика.

Но нельзя сказать, что есть какой-то ряд задач, которые надо решать так. Основная мысль в другом. Мы делаем решение, потом сталкиваемся с новой проблемой. И тут мы можем сказать: окей, есть привычные для нас фронтовые решения, Redux и так далее. Но также мы можем оглянуться вокруг, посмотреть, какие, например, есть другие абстракции, заглянуть в теорию массового обслуживания, в построение чат-ботов. И вообще в те абстракции, которые уже есть в теории Computer Science и математики, статистики. И найти там какое-то вдохновение для более интересного и гибкого решения.
Полезно знать, что вокруг, какая есть теория, до чего вообще додумались люди за годы Computer Science в математике, чем это может быть полезно конкретно для меня в решении задачи прямо сейчас.
Чем больше кругозор, чем больше вы смотрите вокруг, тем больше шанс, что вы сможете найти подход к вашей задаче более эффективно, чем сейчас.
Также полезно смотреть, что делают другие люди в других областях. Например, как делают чат-боты, высокоуровневые системы. Это тоже может помочь вам сделать более эффективные и гибкие решения в ваших повседневных задачах.
Здесь я собрал несколько ссылок на материалы:
- Хорошая статья на Smashing Magazine про state-машины, там хорошо описано, как они работают поверх Redux.
- Цепи Маркова, краткое объяснение довольно простым языком на Brilliant.
- И очень хорошая видеолекция от профессора из MIT, в которой очень хорошо рассказывается математический аппарат цепей Маркова.
Спасибо за внимание.
Смотреть видео доклада
