Функциональные тесты в Циан

Привет!
Меня зовут Тимофей, я Python-разработчик в команде Платформа компании Циан. Наша команда занимается разработкой инструментов для продуктовых разработчиков. Это и библиотеки: HTTP-клиент, веб-сервер, библиотеки доступа к базам данных, и средства мониторинга микросервисов и сайта в целом, и интеграция с CI/CD и многое другое.
Сегодня я расскажу про новый инструмент, который мы не так давно разработали — фреймворк для функциональных тестов.
Но для начала…
Для чего нужны тесты
Если коротко, то мы считаем, что тесты помогают зафиксировать поведение системы. Чтобы после написания нового функционала или рефакторинга старого, мы могли проверить, что всё, что было написано ранее не сломалось, и существующий функционал работает так же, как и до изменения.
Сначала любой код прост, на него может быть всего пара-тройка тест-кейсов. Такое количество кейсов можно проверить и руками. Но когда в проект придёт другой разработчик, он может не знать об этих кейсах и что-то сломать. А кодовая база только увеличивается, кейсов становится всё больше и больше, проверять всё руками уже не вариант.
Code-coverage
У нас в Циан принята политика покрывать код тестами. На ревью мы измеряем diff-coverage: процент затронутых в pull-request строк, которые покрыты тестами. На данный момент наш санитарный минимум — 80%, и мы готовимся к тому, чтобы автоматически отклонять pull-request с diff-coverage ниже этого числа. Таким образом новый код всегда почти полностью покрыт тестами.
К слову такой механизм очень удобен, когда код вообще не покрыт тестами, а новый код покрыть хочется. Плюс в отчете утилиты довольно удобно смотреть, не забыли ли какой-то важный участок кода, перед тобой на экране лишь diff, в котором красным подсвечены непокрытые строки:

Также в Циан разработчики пишут API-тесты, тестирующие микросервис в реальном окружении: dev, beta или даже prod, но на них мы не будем заострять внимание в этой статье.
Юнит-тесты
До недавнего времени у разработчиков Циан был лишь один инструмент получения заветного процента coverage — юнит-тесты. Но удобно ли это?
При всей нашей любви к юнит-тестам, они не являются серебряной пулей и имеют неприятные недостатки:
Не проверяют работу микросервиса целиком. То, что все компоненты системы правильно работают по отдельности совсем не значит, что система работает правильно целиком.
Ломаются при рефакторинге. Стоит нам разделить 2 класса на 3 — приходится переписывать тесты. Если не можем проверить рефакторинг существующими тестами, значит мы не можем быть уверены в том, что всё будет работать как и раньше. Даже можно сказать, что юнит-тесты «замораживают» архитектуру и не дают её менять.
И из-за этой проблемы разработчики попросту перестают рефакторить. Подсознательно страшно менять что-то, что нельзя проверить. Как говорится: работает — не трожь!
Решение
Мы решили, что больше так жить нельзя и разработчикам нужен новый инструмент для написания нового вида тестов. Мы назвали их функциональными тестами.
На деле это изолированные API тесты для микросервисов. Под API здесь понимается в прямом его смысле Application Programming Interface, то есть любые интерфейсы микросервиса, будь то HTTP API, кроны или RabbitMQ / Kafka консюмеры.
Для тестирования в докере поднимаются все нужные базы данных, брокер сообщений, HTTP Mock Server, а микросервис автоматически запускается с настройками, указывающими на них.
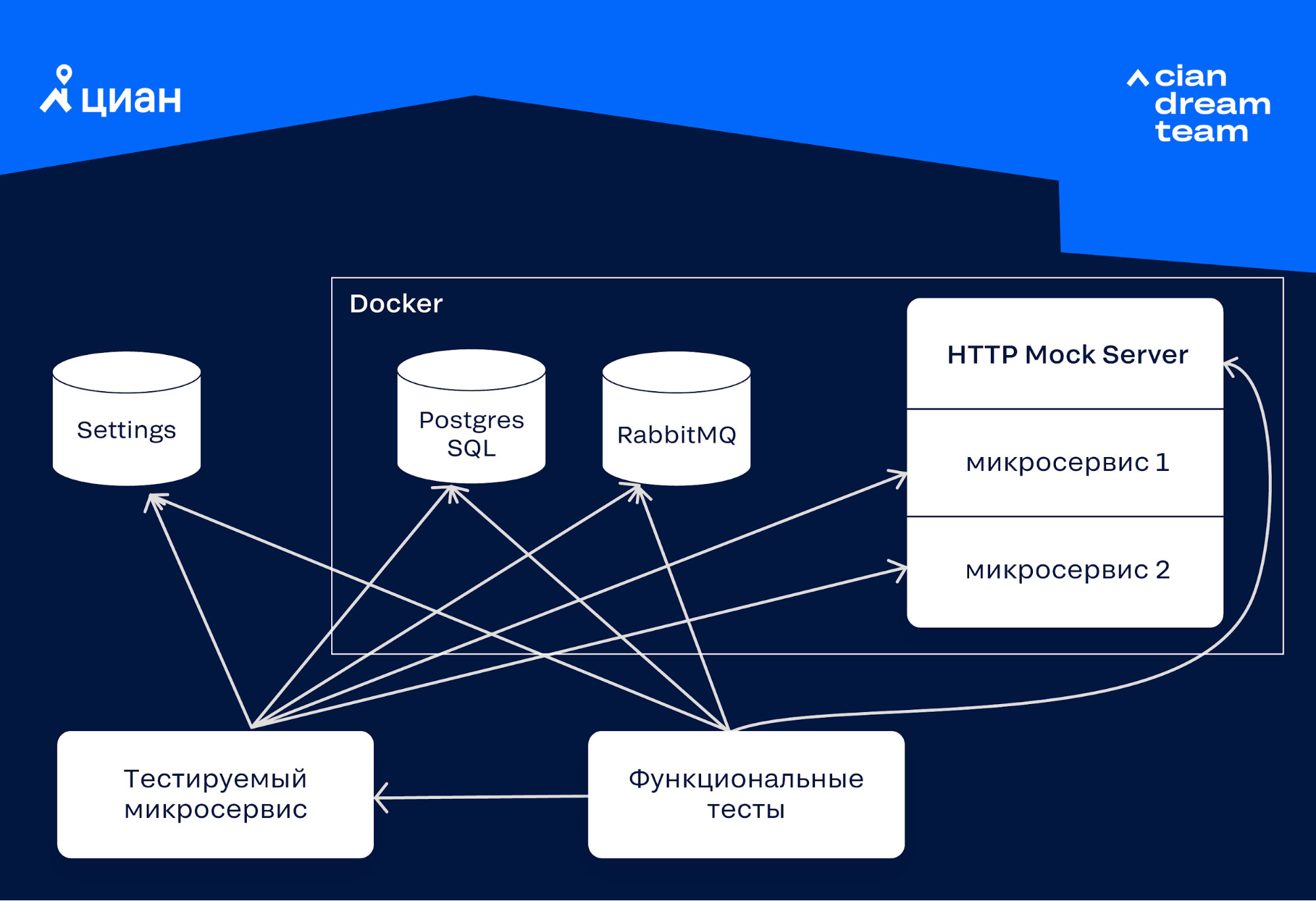
Такие тесты призваны:
- Улучшить качество, за счет тестирования многошаговых сценариев с вызовами API, обработкой сообщений RabbitMQ, запуском кронов.
- Увеличить скорость разработки, за счет уменьшения количества ручных проверок.
- Упростить рефакторинг, за счет проверки всего микросервиса целиком как black box, не вдаваясь в подробности, как он реализован внутри.
- Упростить покрытие кода, за счет сбора покрытия во время работы микросервиса и объединения его с покрытием юнит-тестов.
Инструмент решили делать кроссплатформенным, с возможностью тестировать как микросервисы на Python, так и на C#, а в будущем и на frontend микросервисы на NodeJS в интеграции с браузером. Для реализации выбрали язык Python и известный фреймворк pytest. Python-разработчикам он уже известен по юнит-тестами, C#-разработчики пишут на нём API-тесты. К тому же pytest позволяет писать довольно мощные плагины, чем мы и воспользовались.
Выкидываем юнит-тесты?
Конечно нет! Функциональные тесты тоже никоим образом не являются серебряной пулей, у них есть свои недостатки:
- Хоть такие тесты и довольно быстры, они всё равно медленней юнит-тестов. Особенно эта проблема заметна в параметризованных тестах.
- Труднее анализировать падение теста. Если бы мы реализовали какое-нибудь бинарное дерево внутри нашей программы, находить ошибки в нём по отчету функциональных тестов — нетривиальная задача.
- Не так стабильны, как юнит-тесты, что правда не мешает нам ронять CI-pipeline если хотя бы один тест упал.
- Некоторые сценарии невозможно, а если и возможно, то не рационально, проверять функциональными тестами, например конкурентный доступ к объектам в многопоточной среде.
Поэтому мы призываем наших разработчиков использовать разные виды тесты там, где они хороши.
Например в гипотетическом API регистрации пользователя можно покрыть все базовые сценарии функциональными тестами, а функцию проверки пароля на безопасность покрыть параметризованными юнит-тестами.
Возможности фреймворка
Конечно же для запуска тестов сначала нужно запустить все нужные базы данных и другие сервисы. Для этого мы используем собственный формат конфигурации микросервиса, называемый app.toml. В нём мы в унифицированном для всех используемых языков программирования уже описывали конфигурацию деплоя микросервиса, а теперь описываем и конфигурацию для тестов:
[[dependency]]
type = "postgres"
alias = "users"
[[dependency]]
type = "rabbitmq"Запускаем command line утилитой фреймворка:
cian-functional-test-utils deps upПод капотом этой команды считывается конфиг микросервиса, формируется docker-compose.yml и запускается привычный всем docker-compose up -d. Не советуем давать разработчикам «голый» docker-compose, фреймворк обычно лучше знает как запустить тот же Elasticsearch, чтобы он сносно работал и не съел всю оперативную память. Также свой формат позволяет описать нужные фреймворку метаданные контейнера, как например alias в нашем примере.
Далее в файле conftest.py опишем подготовку базы данных и процесс запуска микросервиса:
@pytest.fixture(scope='session', autouse=True)
async def start(runner, pg):
# Так как все микросервисы Циан имеют один и тот же интерфейс,
# фреймворк знает как их запускать и куда идти за health-check.
await runner.start_background_python_web()
# Можно запускать и тестировать не только HTTP API, но и RabbitMQ консюмеры, кроны
await runner.start_background_python_command('save-users-consumer')
@pytest.fixture(scope='session')
async def pg(postgres_service):
db = await postgres_service.create_database_by_alias('users')
# Используем `pathlib.Path` для кроссплатформенности.
await db.execute_scripts(Path('database_schemas') / 'postgres.sql')
return dbПодготовка завершена! А вот и первый тест:
async def test_v1_get_user(http, pg): # тот самый pg из conftest.py
# arrange
await pg.execute('INSERT INTO users (id, name) VALUES (1, "Bart")')
# act
response = await http.request('GET', '/v1/get-user/', params={'id': 1})
# assert
assert response.status == 200
assert response.data == {'id': 1, 'name': 'Bart'}Аналогично PostgreSQL есть поддержка MsSQL, Cassandra, Redis, Elasticsearch.
С HTTP API разобрались, теперь посмотрим как можно проверить работу консюмера:
async def test_save_users_consumer(pg, queue_service):
# arrange
# Перед каждым тестов все очереди RabbitMQ удаляются,
# нужно подождать, пока консюмер пересоздаст её.
await queue_service.wait_consumer(queue='save-users')
# act
await queue_service.publish(
exchange='users',
routing_key='user.created',
payload={'id':1, 'name': 'Bart'},
)
await asyncio.sleep(0.5) # Подождем немного, чтобы консюмер обработал сообщение
# assert
row = await pg.fetchrow('SELECT name FROM users WHERE id = 1')
assert row['name'] == 'Bart'Перед каждым тестом мы удаляем все очереди в RabbitMQ (наши консюмеры настроены переподключаться в таких случаях), чистим все таблицы в базах данных. Почему перед тестом? Чтобы можно было зайти в базу данных или в админку RabbitMQ и посмотреть что там лежит на момент падения теста.
Таким образом каждый тест выполняется в чистом окружении, в большинстве случаев нет разницы, какие тесты запускать и в каком порядке, результаты будет совпадать.
Да, иногда разница есть. К примеру у нас микросервисы могут иметь локальный кеш в оперативной памяти. Сбросить такой кеш без предоставления какого-то внешнего API невозможно. Мы выбрали довольно «грязное» решение: если микросервис запущен с определенной переменной окружения, на переданном в ней порту поднимается дополнительный HTTP-сервер, мы его зовём Management API. Так как все микросервисы для кеша используют нашу собственную библиотеку, нет никакой сложности сделать API, которая чистит его. И вся эта логика зашита в наших библиотеках, разработчикам ничего для этого делать не надо.
В итоге каждый процесс приложения поднимается с дополнительным HTTP-сервером. Перед тестом всем им фреймворк отправляет запрос на очистку локального кеша.
HTTP моки
Для HTTP-моков мы выбрали инструмент mountebank. Он умеет слушать несколько портов (по порту на подменяемый сервис) и настраивается полностью по HTTP. Работать с ним напрямую не очень удобно, поэтому мы сделали небольшую обертку, которая на практике выглядит так:
@pytest.fixture(scope='session')
async def users_mock(http_mock_service):
# Нужно лишь указать имя микросервиса, который мы хотим замокать,
# фреймворк автоматически добавит URL мока в настройки микросервиса.
return await http_mock_service.make_microservice_mock('users')
def test_something(users_mock):
# arrange
stub = await users_mock.add_stub(
method='GET',
path='/v1/get-user/',
response=MockResponse(body={'firstName': 'Bart', 'lastName': 'Simpson'}),
)
# act
# do something
# assert
# Проверяем, что запрос в мок был сделан с ?userId=234
request = (await stub.get_requests())[0]
assert request.params['userId'] == '234'Под капотом при создании мока микросервиса автоматически создаётся еще и stub, который на все запросы отвечает кодом 404. Стабы у mountebank хранятся в списке и приоретизируются порядком в нём. Если, к примеру, наш стаб с 404 будет первым в списке, то мы всегда будем получать 404, независимо от наличия других стабов, до них дело просто не дойдет. Так дело не пойдёт, поэтому создание стаба у нас всегда помещает его на предпоследнюю позицию в списке (перед 404). Чем раньше в коде объявлен стаб, тем он приоритетней.
Ещё интересной особенностью mountebank является то, что по-умолчанию запросы в моки не сохраняются. Реализовать с таким поведением тест выше было бы невозможно. Есть два решения:
- параметр recordRequests — плох тем, что скидывает запросы в общую кучу, а не сохраняет их для каждого стаба отдельно;
- параметр командой строки
--debug— идеально решает проблему.
Структура тестов
Как можно заметить, разработчику перед написанием самих тестов нужно написать session фикстуры на каждую используемую базу данных, HTTP-мок. Фикстура start, описывающая процесс запуска приложения, зависит от всех них и имеет параметр autouse=True. Таким образом перед запуском каких-либо тестов, инициализируются все базы данных и http-моки, запускаются процессы приложения.
Фреймворк имеет еще много разных возможностей, например:
- сбор логов приложения, для проверки логирования;
- сбор телеметрии statsd и graphite для её проверки;
- перехват отправляемых в RabbitMQ сообщений, для тестирования продюсеров.
Останавливаться на них не хочется, так как фреймворк проприетарный, и вам, скорее всего, это не очень интересно.
Документация
Если вы вдруг тоже решите сделать внутри своей компании подобный фреймворк, то вам точно не обойтись без написания документации к нему.
Мы проанализировали существующие инструменты и не нашли ничего лучше, чем старый добрый Sphinx. reStructuredText сначала ломал мозг, но, уже после пары страниц, начинаешь осознавать всю мощь этих инструментов.
Наша документация содержит:
- краткое описание, что вообще за тесты предстоит написать разработчику;
- статью по настройке окружения для их написания, что особенно актуально нашим C#-разработчикам;
- простые и более сложные примеры использования;
- API Reference, где можно посмотреть детальное описание всех классов и методов.
В итоге должна получиться такая документация, чтобы, прочитав её, новый разработчик мог сразу начать писать правильные функциональные тесты.
Type annotations
Python — язык с динамической типизацией. Лезть в документацию каждый раз, когда забыл имя нужного метода — неприятно и непродуктивно. Поэтому мы покрыли код фреймворка аннотациями типов по PEP 484.
Благодаря этому и поддержке pytest у PyCharm, IDE автодополняет методы фикстур как и в обычном коде:

Поддержка pytest есть и в других IDE от компании Jetbrains с установленным плагином Python Community Edition. Наши C#-разработчики используют Rider, для них, так привыкших к статической типизации и подсказкам IDE, это особенно важно.
Вывод
Как вы уже могли заметить, получившийся фреймворк сильно завязан на архитектуру микросервисов в Циан. Его невозможно использовать в других компаниях, поэтому нет никакого смысла выкладывать его в Open Source.
В этой статье мы хотим лишь показать, что разрабатка такого фреймворка по нашему мнению окупается:
- получаемым качеством;
- скоростью разработки;
- уменьшением технического долга на рефакторинг;
- наконец, счастьем разработчиков, которым надоело писать много иногда бесполезных юнит-тестов.
Мы не можем дать каких-то цифр, статистики, что оно реально так, это лишь наше субъективное мнение, основанное на опыте написания функциональных тестов у нас.
На этом, собственно, всё, задавайте вопросы в комментариях.
Спасибо за внимание.
